 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Trial2Vec: Zero-Shot Clinical Trial Document Similarity Search using Self-Supervision
Jun 29, 2022
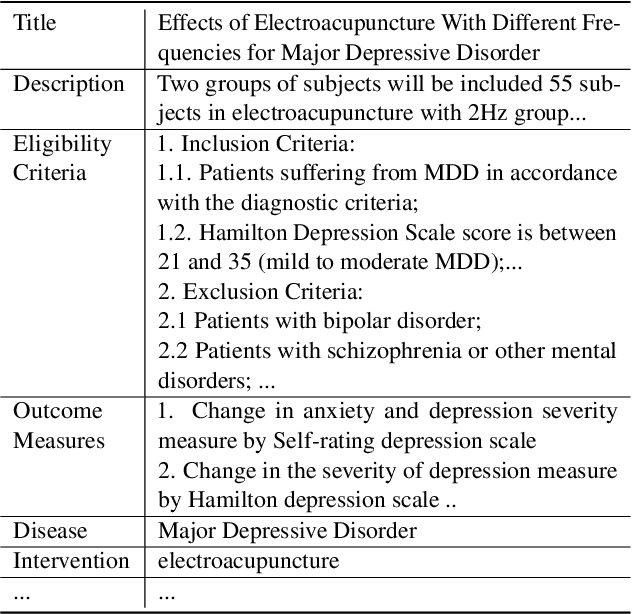
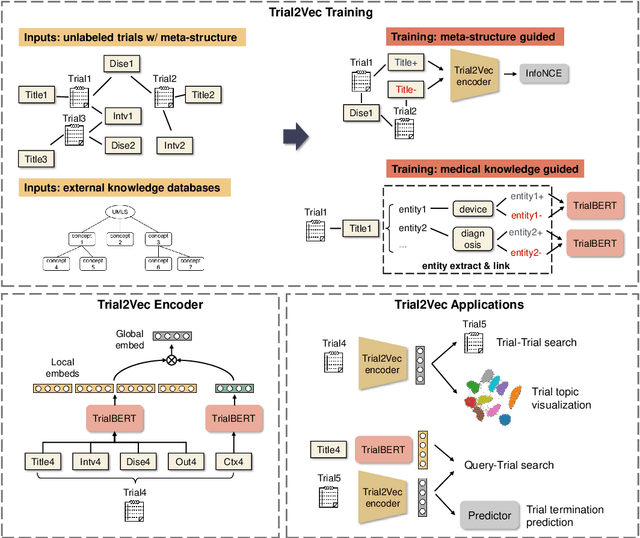
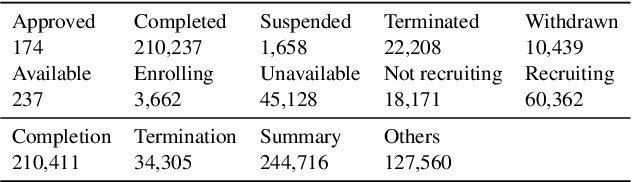
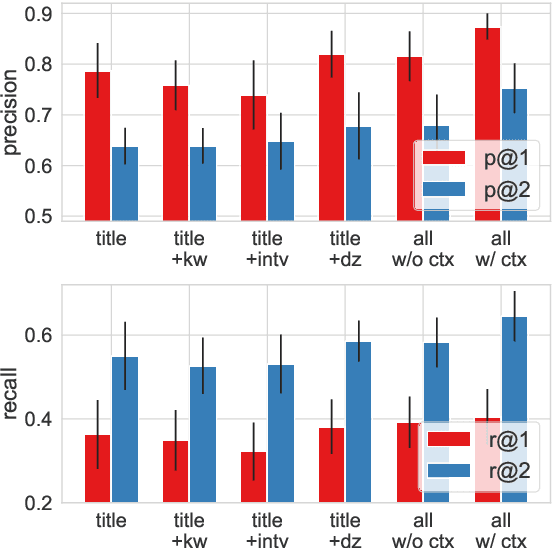
Clinical trials are essential for drug development but are extremely expensive and time-consuming to conduct. It is beneficial to study similar historical trials when designing a clinical trial. However, lengthy trial documents and lack of labeled data make trial similarity search difficult. We propose a zero-shot clinical trial retrieval method, Trial2Vec, which learns through self-supervision without annotating similar clinical trials. Specifically, the meta-structure of trial documents (e.g., title, eligibility criteria, target disease) along with clinical knowledge (e.g., UMLS knowledge base https://www.nlm.nih.gov/research/umls/index.html) are leveraged to automatically generate contrastive samples. Besides, Trial2Vec encodes trial documents considering meta-structure thus producing compact embeddings aggregating multi-aspect information from the whole document. We show that our method yields medically interpretable embeddings by visualization and it gets a 15% average improvement over the best baselines on precision/recall for trial retrieval, which is evaluated on our labeled 1600 trial pairs. In addition, we prove the pre-trained embeddings benefit the downstream trial outcome prediction task over 240k trials.
IITP in COLIEE@ICAIL 2019: Legal Information Retrieval usingBM25 and BERT
Apr 17, 2021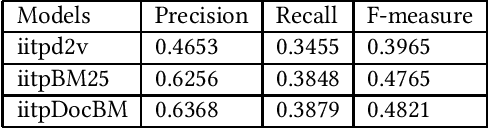
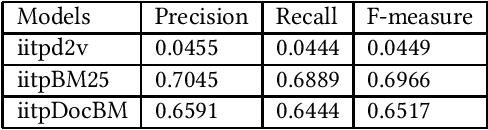
Natural Language Processing (NLP) and Information Retrieval (IR) in the judicial domain is an essential task. With the advent of availability domain-specific data in electronic form and aid of different Artificial intelligence (AI) technologies, automated language processing becomes more comfortable, and hence it becomes feasible for researchers and developers to provide various automated tools to the legal community to reduce human burden. The Competition on Legal Information Extraction/Entailment (COLIEE-2019) run in association with the International Conference on Artificial Intelligence and Law (ICAIL)-2019 has come up with few challenging tasks. The shared defined four sub-tasks (i.e. Task1, Task2, Task3 and Task4), which will be able to provide few automated systems to the judicial system. The paper presents our working note on the experiments carried out as a part of our participation in all the sub-tasks defined in this shared task. We make use of different Information Retrieval(IR) and deep learning based approaches to tackle these problems. We obtain encouraging results in all these four sub-tasks.
Rate-Optimal Contextual Online Matching Bandit
May 07, 2022
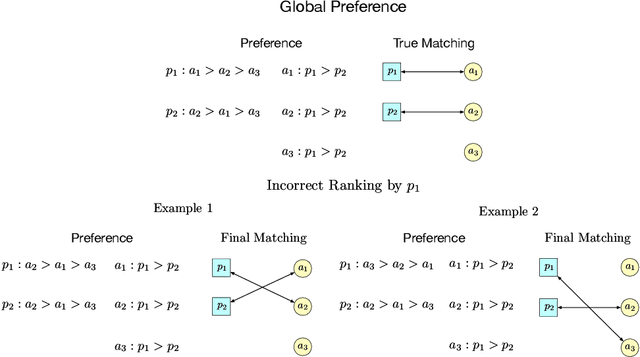
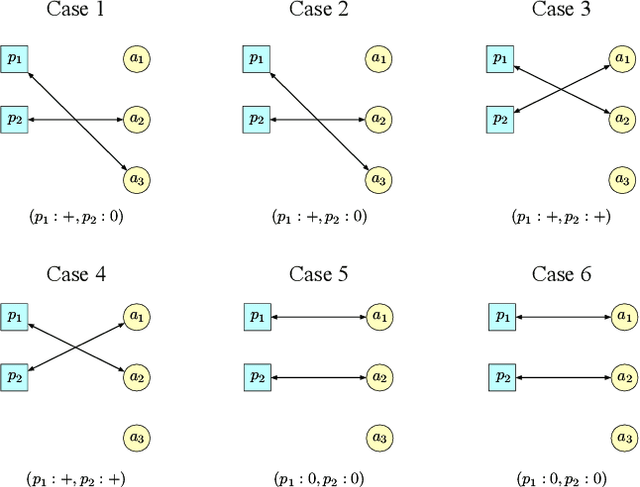
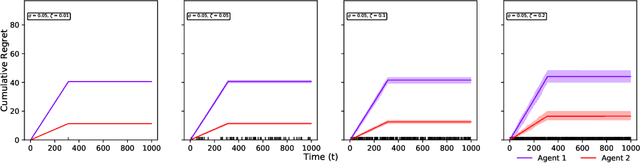
Two-sided online matching platforms have been employed in various markets. However, agents' preferences in present market are usually implicit and unknown and must be learned from data. With the growing availability of side information involved in the decision process, modern online matching methodology demands the capability to track preference dynamics for agents based on their contextual information. This motivates us to consider a novel Contextual Online Matching Bandit prOblem (COMBO), which allows dynamic preferences in matching decisions. Existing works focus on multi-armed bandit with static preference, but this is insufficient: the two-sided preference changes as along as one-side's contextual information updates, resulting in non-static matching. In this paper, we propose a Centralized Contextual - Explore Then Commit (CC-ETC) algorithm to adapt to the COMBO. CC-ETC solves online matching with dynamic preference. In theory, we show that CC-ETC achieves a sublinear regret upper bound O(log(T)) and is a rate-optimal algorithm by proving a matching lower bound. In the experiments, we demonstrate that CC-ETC is robust to variant preference schemes, dimensions of contexts, reward noise levels, and contexts variation levels.
Is Lip Region-of-Interest Sufficient for Lipreading?
May 28, 2022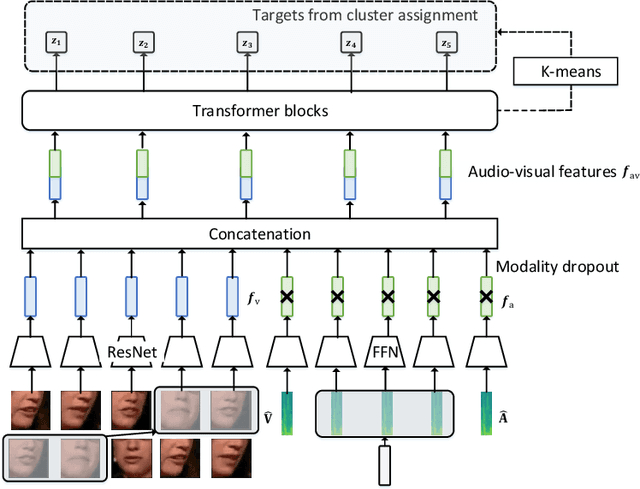
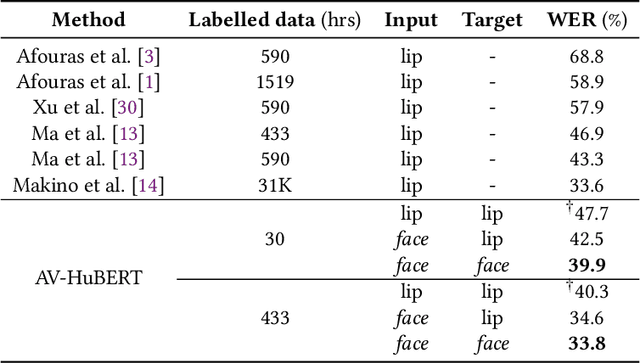

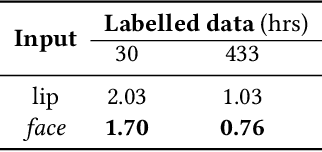
Lip region-of-interest (ROI) is conventionally used for visual input in the lipreading task. Few works have adopted the entire face as visual input because lip-excluded parts of the face are usually considered to be redundant and irrelevant to visual speech recognition. However, faces contain much more detailed information than lips, such as speakers' head pose, emotion, identity etc. We argue that such information might benefit visual speech recognition if a powerful feature extractor employing the entire face is trained. In this work, we propose to adopt the entire face for lipreading with self-supervised learning. AV-HuBERT, an audio-visual multi-modal self-supervised learning framework, was adopted in our experiments. Our experimental results showed that adopting the entire face achieved 16% relative word error rate (WER) reduction on the lipreading task, compared with the baseline method using lip as visual input. Without self-supervised pretraining, the model with face input achieved a higher WER than that using lip input in the case of limited training data (30 hours), while a slightly lower WER when using large amount of training data (433 hours).
Non-invasive Self-attention for Side Information Fusion in Sequential Recommendation
Mar 05, 2021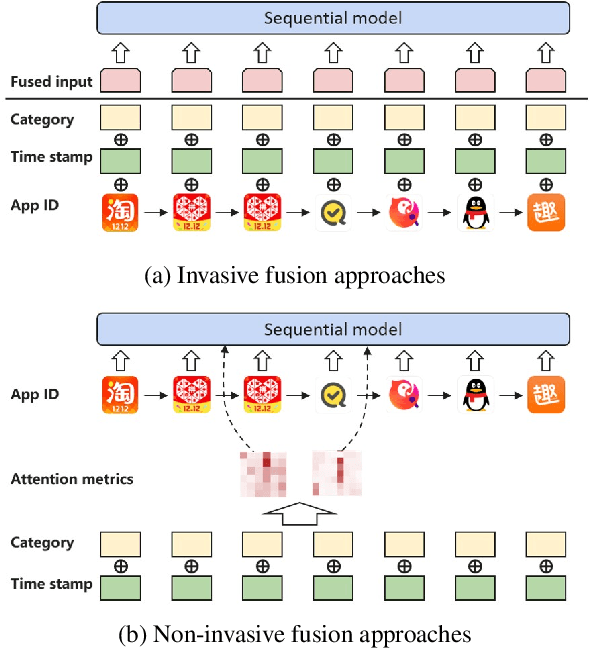

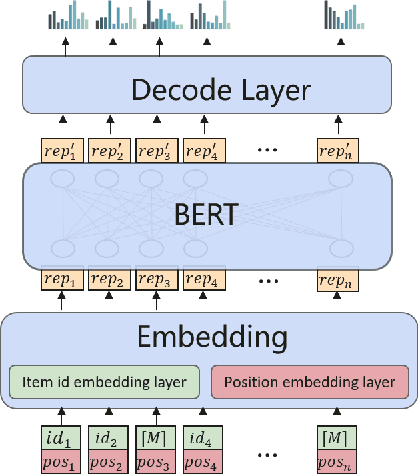

Sequential recommender systems aim to model users' evolving interests from their historical behaviors, and hence make customized time-relevant recommendations. Compared with traditional models, deep learning approaches such as CNN and RNN have achieved remarkable advancements in recommendation tasks. Recently, the BERT framework also emerges as a promising method, benefited from its self-attention mechanism in processing sequential data. However, one limitation of the original BERT framework is that it only considers one input source of the natural language tokens. It is still an open question to leverage various types of information under the BERT framework. Nonetheless, it is intuitively appealing to utilize other side information, such as item category or tag, for more comprehensive depictions and better recommendations. In our pilot experiments, we found naive approaches, which directly fuse types of side information into the item embeddings, usually bring very little or even negative effects. Therefore, in this paper, we propose the NOninVasive self-attention mechanism (NOVA) to leverage side information effectively under the BERT framework. NOVA makes use of side information to generate better attention distribution, rather than directly altering the item embedding, which may cause information overwhelming. We validate the NOVA-BERT model on both public and commercial datasets, and our method can stably outperform the state-of-the-art models with negligible computational overheads.
Self-supervised models of audio effectively explain human cortical responses to speech
May 27, 2022

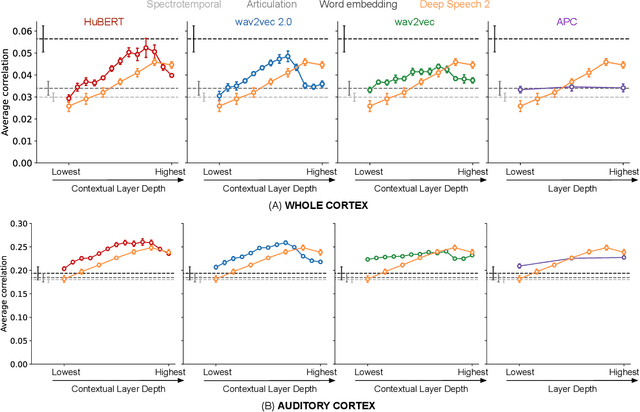
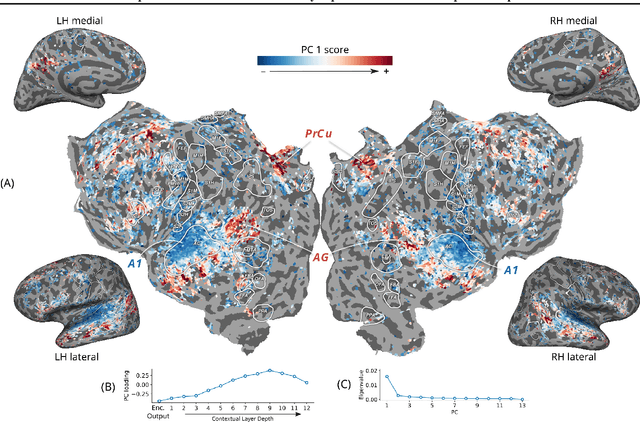
Self-supervised language models are very effective at predicting high-level cortical responses during language comprehension. However, the best current models of lower-level auditory processing in the human brain rely on either hand-constructed acoustic filters or representations from supervised audio neural networks. In this work, we capitalize on the progress of self-supervised speech representation learning (SSL) to create new state-of-the-art models of the human auditory system. Compared against acoustic baselines, phonemic features, and supervised models, representations from the middle layers of self-supervised models (APC, wav2vec, wav2vec 2.0, and HuBERT) consistently yield the best prediction performance for fMRI recordings within the auditory cortex (AC). Brain areas involved in low-level auditory processing exhibit a preference for earlier SSL model layers, whereas higher-level semantic areas prefer later layers. We show that these trends are due to the models' ability to encode information at multiple linguistic levels (acoustic, phonetic, and lexical) along their representation depth. Overall, these results show that self-supervised models effectively capture the hierarchy of information relevant to different stages of speech processing in human cortex.
Learning Task-relevant Representations for Generalization via Characteristic Functions of Reward Sequence Distributions
May 20, 2022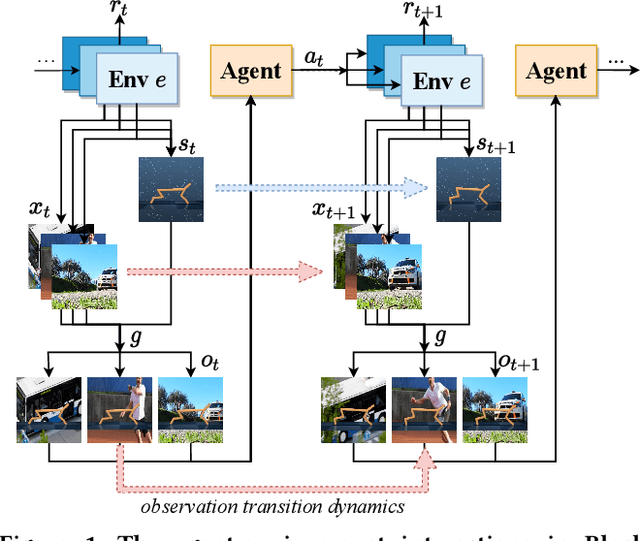
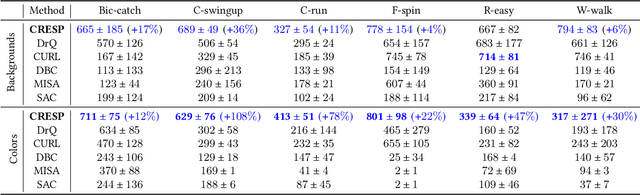
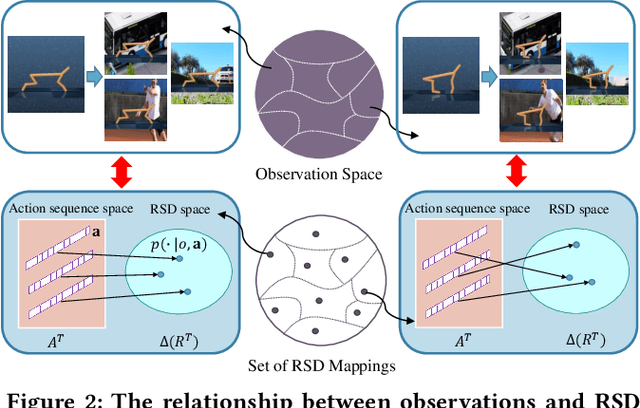
Generalization across different environments with the same tasks is critical for successful applications of visual reinforcement learning (RL) in real scenarios. However, visual distractions -- which are common in real scenes -- from high-dimensional observations can be hurtful to the learned representations in visual RL, thus degrading the performance of generalization. To tackle this problem, we propose a novel approach, namely Characteristic Reward Sequence Prediction (CRESP), to extract the task-relevant information by learning reward sequence distributions (RSDs), as the reward signals are task-relevant in RL and invariant to visual distractions. Specifically, to effectively capture the task-relevant information via RSDs, CRESP introduces an auxiliary task -- that is, predicting the characteristic functions of RSDs -- to learn task-relevant representations, because we can well approximate the high-dimensional distributions by leveraging the corresponding characteristic functions. Experiments demonstrate that CRESP significantly improves the performance of generalization on unseen environments, outperforming several state-of-the-arts on DeepMind Control tasks with different visual distractions.
Automated Audio Captioning: an Overview of Recent Progress and New Challenges
May 12, 2022
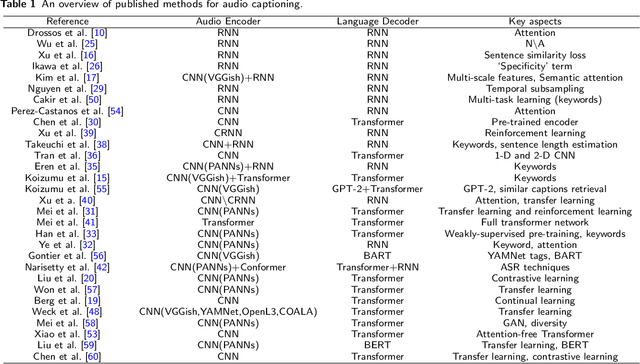
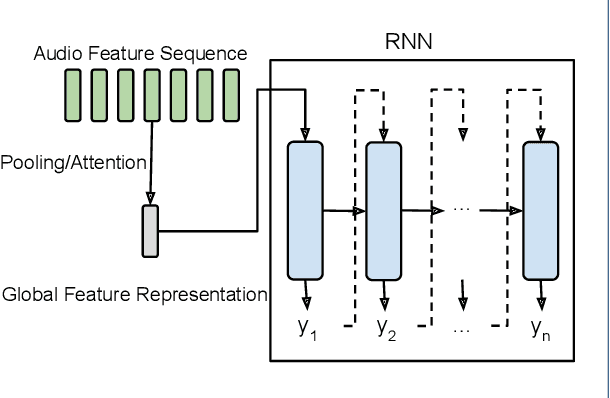
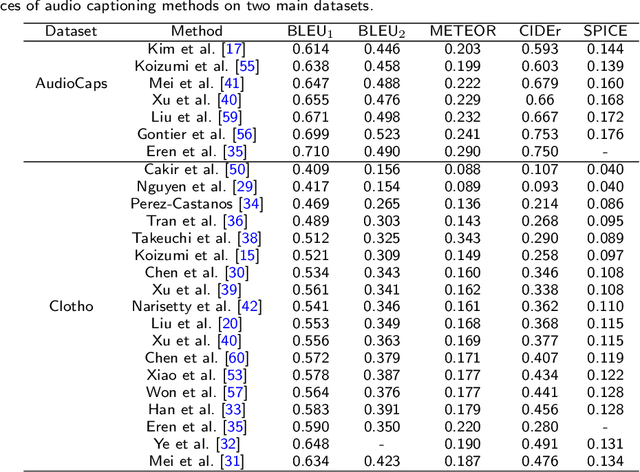
Automated audio captioning is a cross-modal translation task that aims to generate natural language descriptions for given audio clips. This task has received increasing attention with the release of freely available datasets in recent years. The problem has been addressed predominantly with deep learning techniques. Numerous approaches have been proposed, such as investigating different neural network architectures, exploiting auxiliary information such as keywords or sentence information to guide caption generation, and employing different training strategies, which have greatly facilitated the development of this field. In this paper, we present a comprehensive review of the published contributions in automated audio captioning, from a variety of existing approaches to evaluation metrics and datasets. Moreover, we discuss open challenges and envisage possible future research directions.
Aligning Correlation Information for Domain Adaptation in Action Recognition
Jul 11, 2021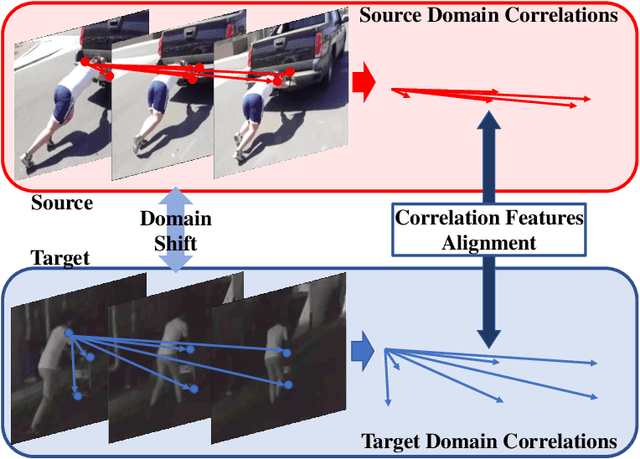
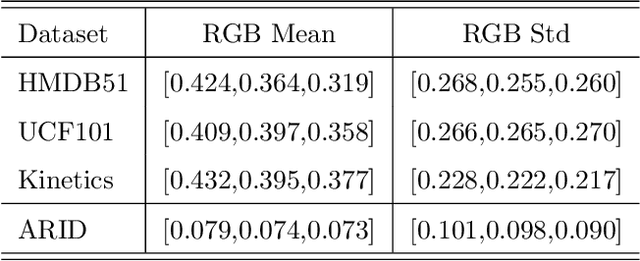
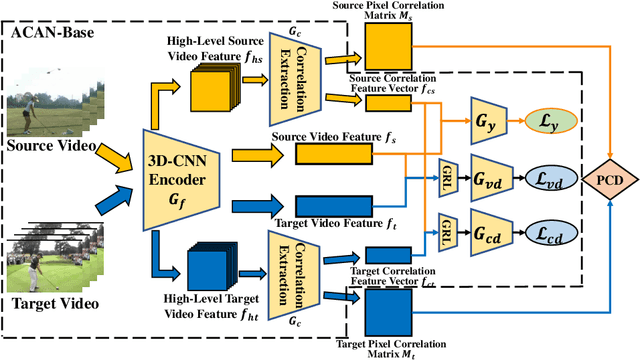

Domain adaptation (DA) approaches address domain shift and enable networks to be applied to different scenarios. Although various image DA approaches have been proposed in recent years, there is limited research towards video DA. This is partly due to the complexity in adapting the different modalities of features in videos, which includes the correlation features extracted as long-term dependencies of pixels across spatiotemporal dimensions. The correlation features are highly associated with action classes and proven their effectiveness in accurate video feature extraction through the supervised action recognition task. Yet correlation features of the same action would differ across domains due to domain shift. Therefore we propose a novel Adversarial Correlation Adaptation Network (ACAN) to align action videos by aligning pixel correlations. ACAN aims to minimize the distribution of correlation information, termed as Pixel Correlation Discrepancy (PCD). Additionally, video DA research is also limited by the lack of cross-domain video datasets with larger domain shifts. We, therefore, introduce a novel HMDB-ARID dataset with a larger domain shift caused by a larger statistical difference between domains. This dataset is built in an effort to leverage current datasets for dark video classification. Empirical results demonstrate the state-of-the-art performance of our proposed ACAN for both existing and the new video DA datasets.
Explain to Not Forget: Defending Against Catastrophic Forgetting with XAI
May 04, 2022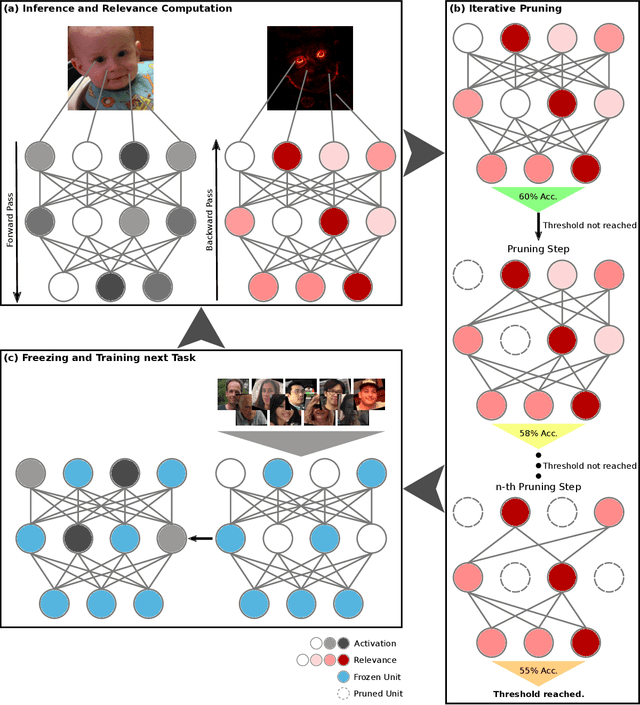
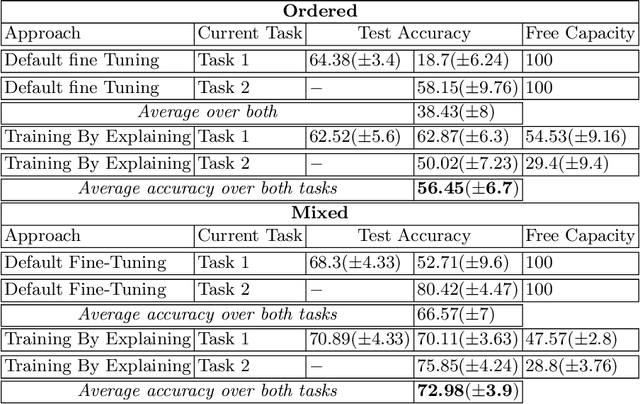
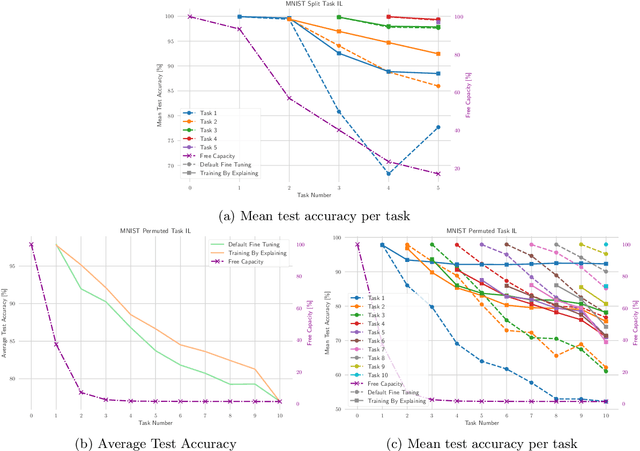
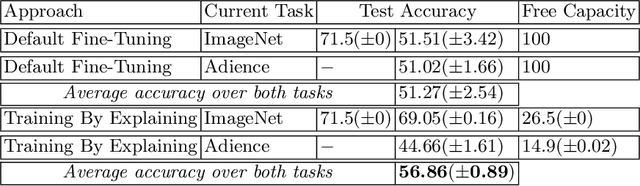
The ability to continuously process and retain new information like we do naturally as humans is a feat that is highly sought after when training neural networks. Unfortunately, the traditional optimization algorithms often require large amounts of data available during training time and updates wrt. new data are difficult after the training process has been completed. In fact, when new data or tasks arise, previous progress may be lost as neural networks are prone to catastrophic forgetting. Catastrophic forgetting describes the phenomenon when a neural network completely forgets previous knowledge when given new information. We propose a novel training algorithm called training by explaining in which we leverage Layer-wise Relevance Propagation in order to retain the information a neural network has already learned in previous tasks when training on new data. The method is evaluated on a range of benchmark datasets as well as more complex data. Our method not only successfully retains the knowledge of old tasks within the neural networks but does so more resource-efficiently than other state-of-the-art solutions.