 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamic Prefix-Tuning for Generative Template-based Event Extraction
May 12, 2022
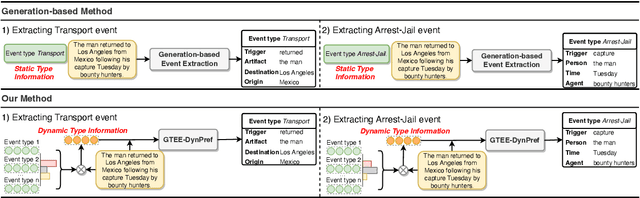
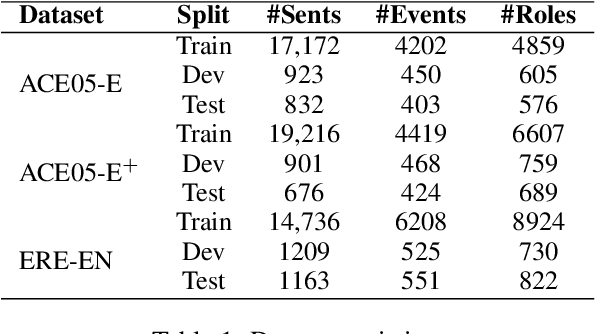
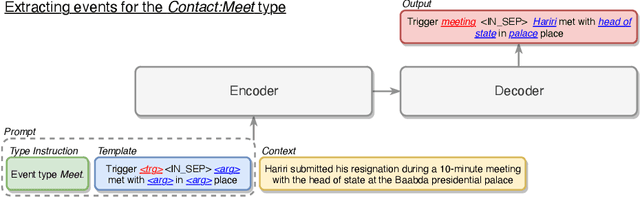
We consider event extraction in a generative manner with template-based conditional generation. Although there is a rising trend of casting the task of event extraction as a sequence generation problem with prompts, these generation-based methods have two significant challenges, including using suboptimal prompts and static event type information. In this paper, we propose a generative template-based event extraction method with dynamic prefix (GTEE-DynPref) by integrating context information with type-specific prefixes to learn a context-specific prefix for each context. Experimental results show that our model achieves competitive results with the state-of-the-art classification-based model OneIE on ACE 2005 and achieves the best performances on ERE. Additionally, our model is proven to be portable to new types of events effectively.
Orthogonal Matrix Retrieval with Spatial Consensus for 3D Unknown-View Tomography
Jul 06, 2022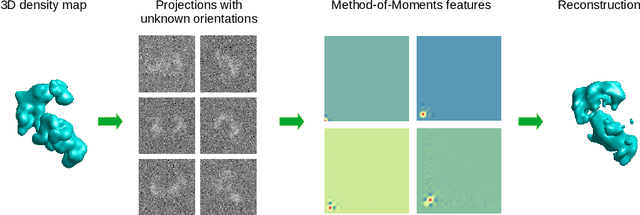
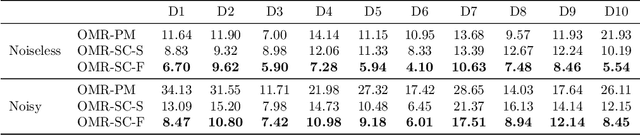

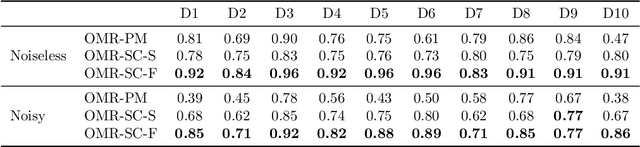
Unknown-view tomography (UVT) reconstructs a 3D density map from its 2D projections at unknown, random orientations. A line of work starting with Kam (1980) employs the method of moments (MoM) with rotation-invariant Fourier features to solve UVT in the frequency domain, assuming that the orientations are uniformly distributed. This line of work includes the recent orthogonal matrix retrieval (OMR) approaches based on matrix factorization, which, while elegant, either require side information about the density that is not available, or fail to be sufficiently robust. In order for OMR to break free from those restrictions, we propose to jointly recover the density map and the orthogonal matrices by requiring that they be mutually consistent. We regularize the resulting non-convex optimization problem by a denoised reference projection and a nonnegativity constraint. This is enabled by the new closed-form expressions for spatial autocorrelation features. Further, we design an easy-to-compute initial density map which effectively mitigates the non-convexity of the reconstruction problem. Experimental results show that the proposed OMR with spatial consensus is more robust and performs significantly better than the previous state-of-the-art OMR approach in the typical low-SNR scenario of 3D UVT.
Long-term Leap Attention, Short-term Periodic Shift for Video Classification
Jul 12, 2022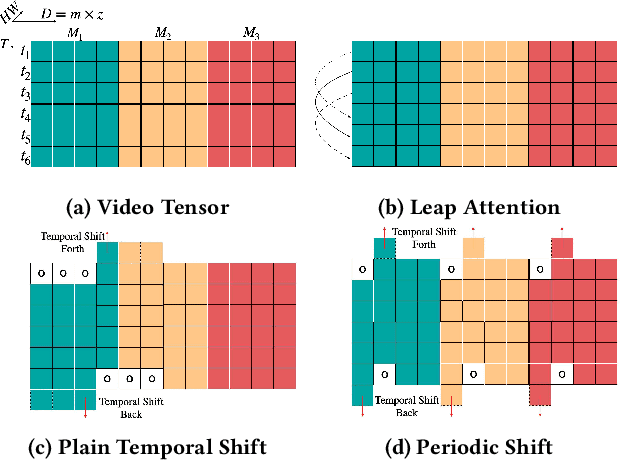
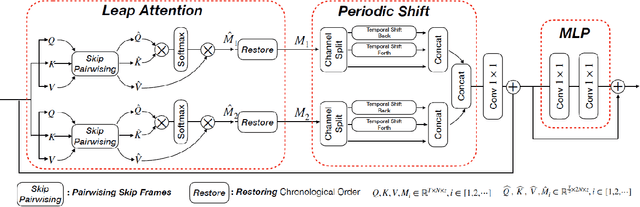

Video transformer naturally incurs a heavier computation burden than a static vision transformer, as the former processes $T$ times longer sequence than the latter under the current attention of quadratic complexity $(T^2N^2)$. The existing works treat the temporal axis as a simple extension of spatial axes, focusing on shortening the spatio-temporal sequence by either generic pooling or local windowing without utilizing temporal redundancy. However, videos naturally contain redundant information between neighboring frames; thereby, we could potentially suppress attention on visually similar frames in a dilated manner. Based on this hypothesis, we propose the LAPS, a long-term ``\textbf{\textit{Leap Attention}}'' (LA), short-term ``\textbf{\textit{Periodic Shift}}'' (\textit{P}-Shift) module for video transformers, with $(2TN^2)$ complexity. Specifically, the ``LA'' groups long-term frames into pairs, then refactors each discrete pair via attention. The ``\textit{P}-Shift'' exchanges features between temporal neighbors to confront the loss of short-term dynamics. By replacing a vanilla 2D attention with the LAPS, we could adapt a static transformer into a video one, with zero extra parameters and neglectable computation overhead ($\sim$2.6\%). Experiments on the standard Kinetics-400 benchmark demonstrate that our LAPS transformer could achieve competitive performances in terms of accuracy, FLOPs, and Params among CNN and transformer SOTAs. We open-source our project in \sloppy \href{https://github.com/VideoNetworks/LAPS-transformer}{\textit{\color{magenta}{https://github.com/VideoNetworks/LAPS-transformer}}} .
Rate-Optimal Contextual Online Matching Bandit
May 07, 2022
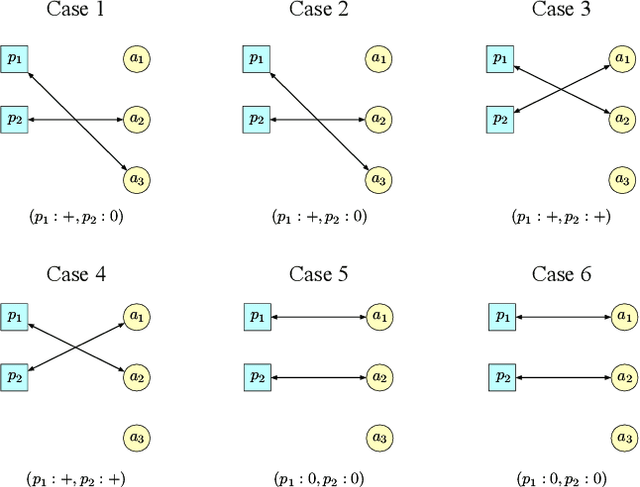
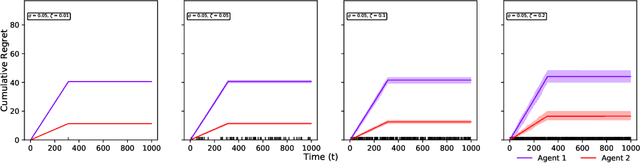
Two-sided online matching platforms have been employed in various markets. However, agents' preferences in present market are usually implicit and unknown and must be learned from data. With the growing availability of side information involved in the decision process, modern online matching methodology demands the capability to track preference dynamics for agents based on their contextual information. This motivates us to consider a novel Contextual Online Matching Bandit prOblem (COMBO), which allows dynamic preferences in matching decisions. Existing works focus on multi-armed bandit with static preference, but this is insufficient: the two-sided preference changes as along as one-side's contextual information updates, resulting in non-static matching. In this paper, we propose a Centralized Contextual - Explore Then Commit (CC-ETC) algorithm to adapt to the COMBO. CC-ETC solves online matching with dynamic preference. In theory, we show that CC-ETC achieves a sublinear regret upper bound O(log(T)) and is a rate-optimal algorithm by proving a matching lower bound. In the experiments, we demonstrate that CC-ETC is robust to variant preference schemes, dimensions of contexts, reward noise levels, and contexts variation levels.
Channel Estimation and Signal Detection for MIMO-AFDM under Doubly Selective Channels
Jun 26, 2022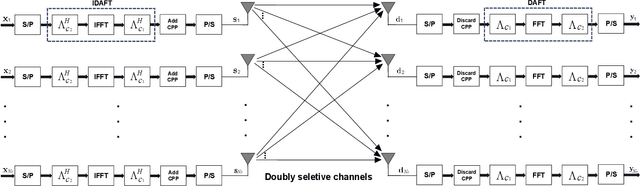
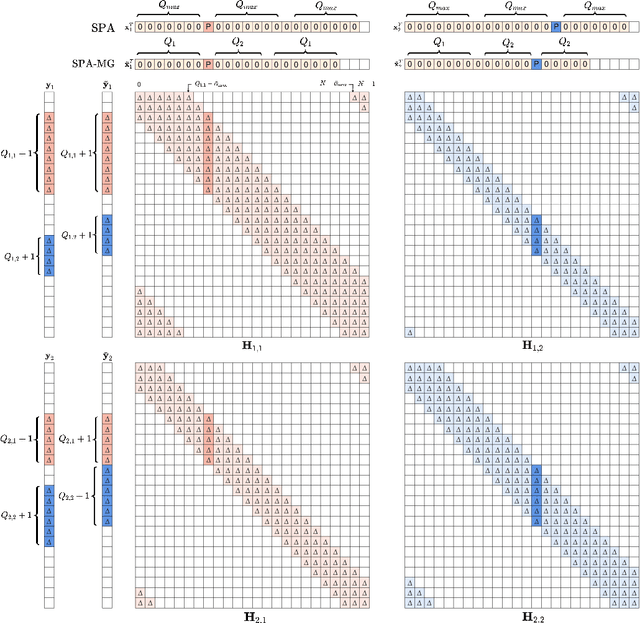
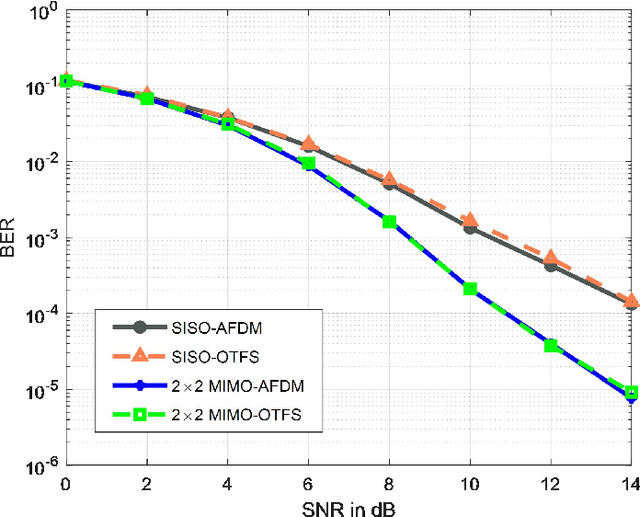
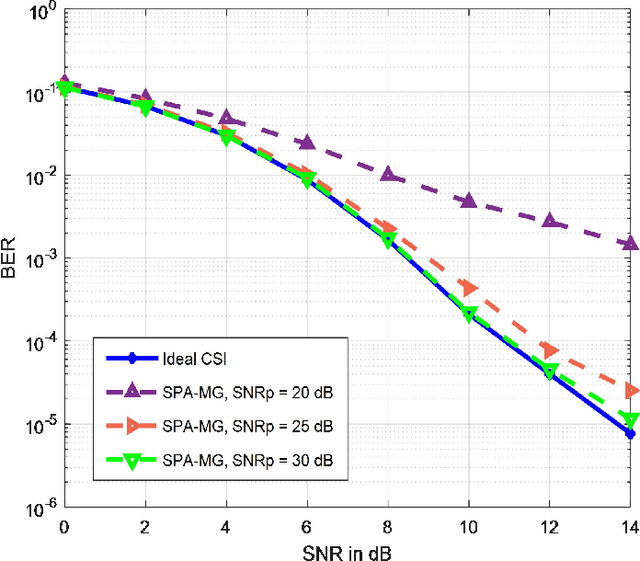
On the heels of orthogonal time frequency space (OTFS) modulation, the recently discovered affine frequency division multiplexing (AFDM) is a promising waveform for the sixth-generation wireless network due to its strong delay-doppler resilience against the double dispersive channels. With the superiorities of high multiplexing and diversity gain of multiple-input multiple-output (MIMO), we derive a vectorized input-output formulation of the MIMO-AFDM system. Correspondingly, we also propose an efficient single pilot aided with minimum guard (SPA-MG) scheme to perform channel estimation in the discrete affine Fourier transform (DAFT) domain. Furthermore, the message passing based iterative detector is explored for signal detection. Finally, the bit error ratio (BER) performances are simulated under doubly selective channels. It is worth emphasizing that the MIMO-AFDM system can achieve outstanding performance similar to MIMO-OTFS. Additionally, compared to ideal channel state information, our proposed SPA-MG scheme is verified to provide marginal difference with the least overhead.
GLD-Net: Improving Monaural Speech Enhancement by Learning Global and Local Dependency Features with GLD Block
Jun 30, 2022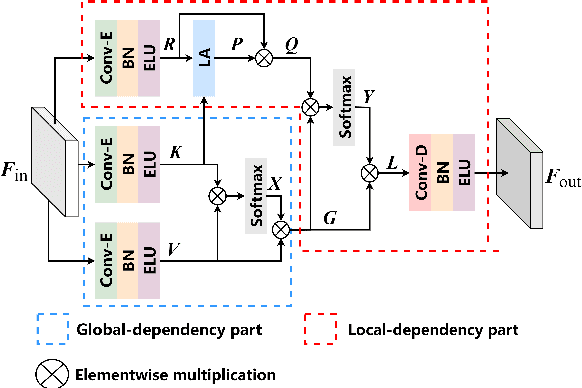
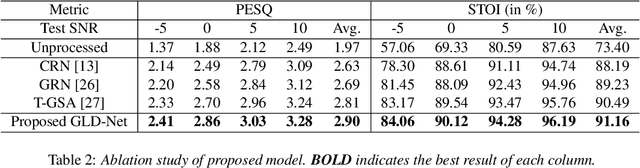
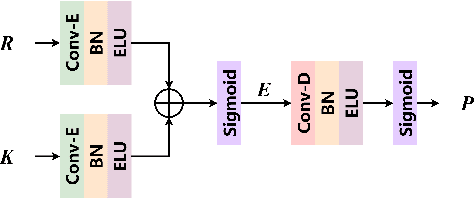

For monaural speech enhancement, contextual information is important for accurate speech estimation. However, commonly used convolution neural networks (CNNs) are weak in capturing temporal contexts since they only build blocks that process one local neighborhood at a time. To address this problem, we learn from human auditory perception to introduce a two-stage trainable reasoning mechanism, referred as global-local dependency (GLD) block. GLD blocks capture long-term dependency of time-frequency bins both in global level and local level from the noisy spectrogram to help detecting correlations among speech part, noise part, and whole noisy input. What is more, we conduct a monaural speech enhancement network called GLD-Net, which adopts encoder-decoder architecture and consists of speech object branch, interference branch, and global noisy branch. The extracted speech feature at global-level and local-level are efficiently reasoned and aggregated in each of the branches. We compare the proposed GLD-Net with existing state-of-art methods on WSJ0 and DEMAND dataset. The results show that GLD-Net outperforms the state-of-the-art methods in terms of PESQ and STOI.
Unified BERT for Few-shot Natural Language Understanding
Jun 24, 2022
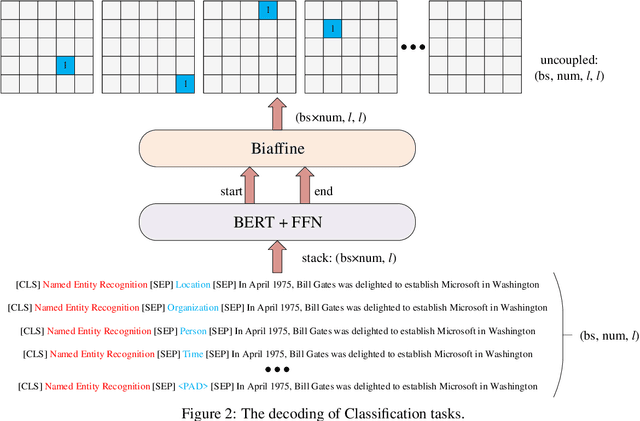
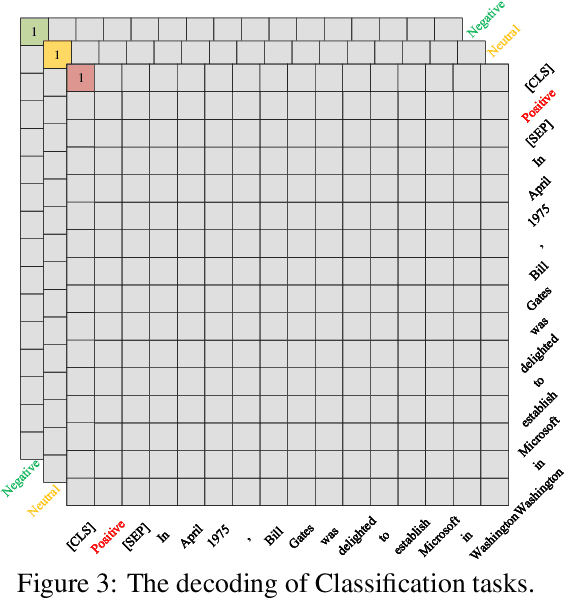

Even as pre-trained language models share a semantic encoder, natural language understanding suffers from a diversity of output schemas. In this paper, we propose UBERT, a unified bidirectional language understanding model based on BERT framework, which can universally model the training objects of different NLU tasks through a biaffine network. Specifically, UBERT encodes prior knowledge from various aspects, uniformly constructing learning representations across multiple NLU tasks, which is conducive to enhancing the ability to capture common semantic understanding. Using the biaffine to model scores pair of the start and end position of the original text, various classification and extraction structures can be converted into a universal, span-decoding approach. Experiments show that UBERT achieves the state-of-the-art performance on 7 NLU tasks, 14 datasets on few-shot and zero-shot setting, and realizes the unification of extensive information extraction and linguistic reasoning tasks.
Explain to Not Forget: Defending Against Catastrophic Forgetting with XAI
May 04, 2022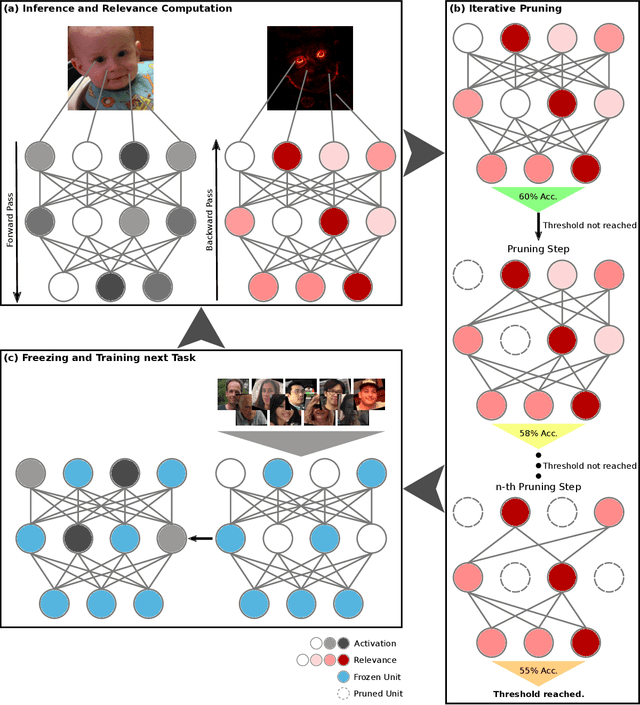
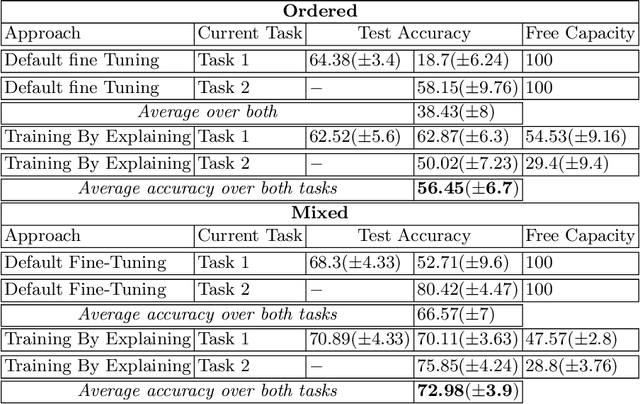
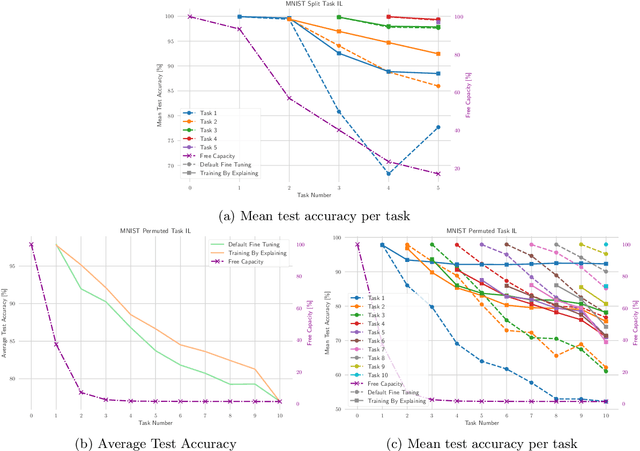
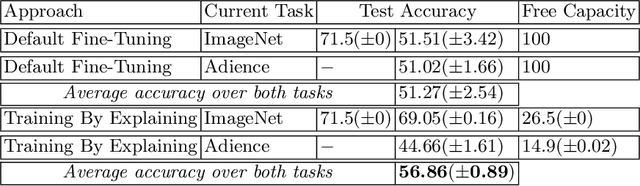
The ability to continuously process and retain new information like we do naturally as humans is a feat that is highly sought after when training neural networks. Unfortunately, the traditional optimization algorithms often require large amounts of data available during training time and updates wrt. new data are difficult after the training process has been completed. In fact, when new data or tasks arise, previous progress may be lost as neural networks are prone to catastrophic forgetting. Catastrophic forgetting describes the phenomenon when a neural network completely forgets previous knowledge when given new information. We propose a novel training algorithm called training by explaining in which we leverage Layer-wise Relevance Propagation in order to retain the information a neural network has already learned in previous tasks when training on new data. The method is evaluated on a range of benchmark datasets as well as more complex data. Our method not only successfully retains the knowledge of old tasks within the neural networks but does so more resource-efficiently than other state-of-the-art solutions.
Preference Enhanced Social Influence Modeling for Network-Aware Cascade Prediction
Apr 18, 2022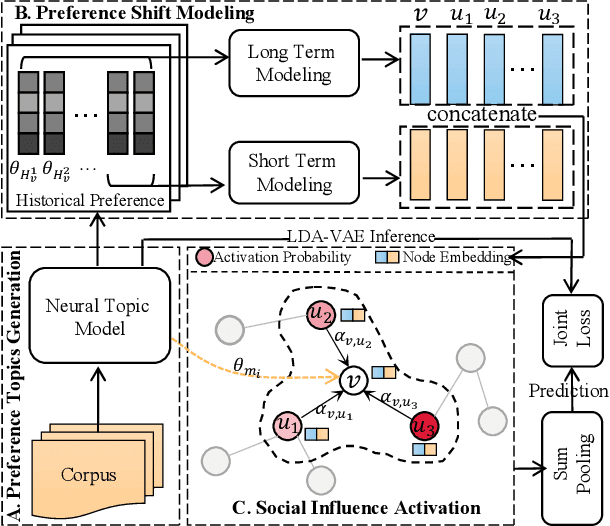
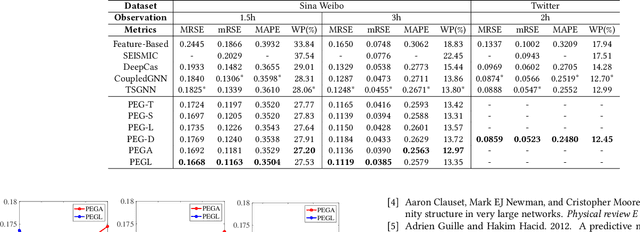
Network-aware cascade size prediction aims to predict the final reposted number of user-generated information via modeling the propagation process in social networks. Estimating the user's reposting probability by social influence, namely state activation plays an important role in the information diffusion process. Therefore, Graph Neural Networks (GNN), which can simulate the information interaction between nodes, has been proved as an effective scheme to handle this prediction task. However, existing studies including GNN-based models usually neglect a vital factor of user's preference which influences the state activation deeply. To that end, we propose a novel framework to promote cascade size prediction by enhancing the user preference modeling according to three stages, i.e., preference topics generation, preference shift modeling, and social influence activation. Our end-to-end method makes the user activating process of information diffusion more adaptive and accurate. Extensive experiments on two large-scale real-world datasets have clearly demonstrated the effectiveness of our proposed model compared to state-of-the-art baselines.
Entity-aware Transformers for Entity Search
May 02, 2022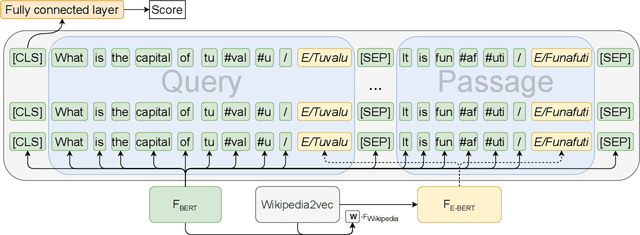

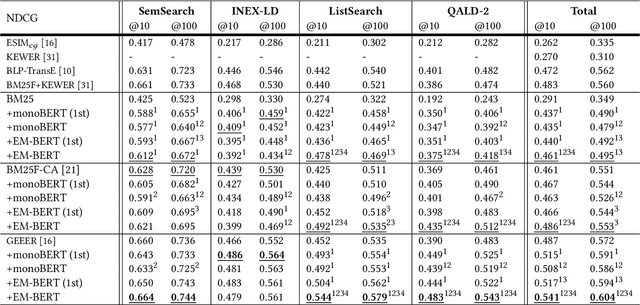
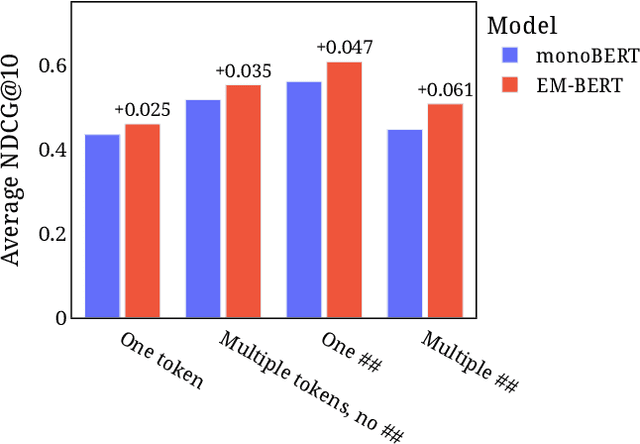
Pre-trained language models such as BERT have been a key ingredient to achieve state-of-the-art results on a variety of tasks in natural language processing and, more recently, also in information retrieval.Recent research even claims that BERT is able to capture factual knowledge about entity relations and properties, the information that is commonly obtained from knowledge graphs. This paper investigates the following question: Do BERT-based entity retrieval models benefit from additional entity information stored in knowledge graphs? To address this research question, we map entity embeddings into the same input space as a pre-trained BERT model and inject these entity embeddings into the BERT model. This entity-enriched language model is then employed on the entity retrieval task. We show that the entity-enriched BERT model improves effectiveness on entity-oriented queries over a regular BERT model, establishing a new state-of-the-art result for the entity retrieval task, with substantial improvements for complex natural language queries and queries requesting a list of entities with a certain property. Additionally, we show that the entity information provided by our entity-enriched model particularly helps queries related to less popular entities. Last, we observe empirically that the entity-enriched BERT models enable fine-tuning on limited training data, which otherwise would not be feasible due to the known instabilities of BERT in few-sample fine-tuning, thereby contributing to data-efficient training of BERT for entity search.