 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
IDPS Signature Classification with a Reject Option and the Incorporation of Expert Knowledge
Jul 19, 2022
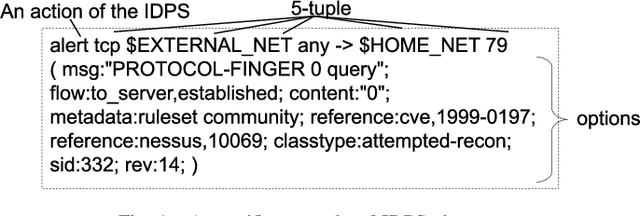
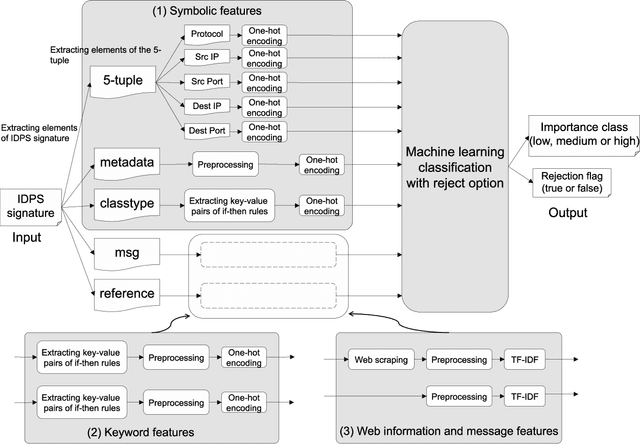
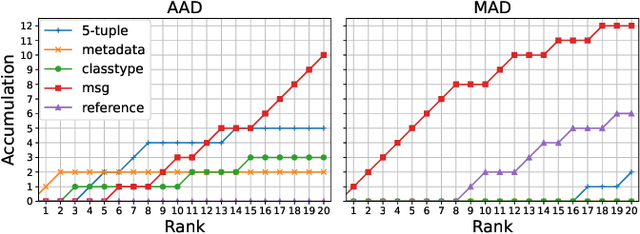
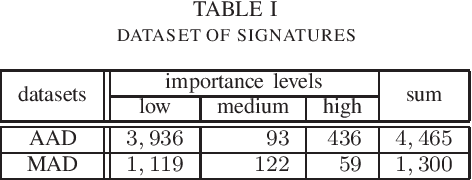
As the importance of intrusion detection and prevention systems (IDPSs) increases, great costs are incurred to manage the signatures that are generated by malicious communication pattern files. Experts in network security need to classify signatures by importance for an IDPS to work. We propose and evaluate a machine learning signature classification model with a reject option (RO) to reduce the cost of setting up an IDPS. To train the proposed model, it is essential to design features that are effective for signature classification. Experts classify signatures with predefined if-then rules. An if-then rule returns a label of low, medium, high, or unknown importance based on keyword matching of the elements in the signature. Therefore, we first design two types of features, symbolic features (SFs) and keyword features (KFs), which are used in keyword matching for the if-then rules. Next, we design web information and message features (WMFs) to capture the properties of signatures that do not match the if-then rules. The WMFs are extracted as term frequency-inverse document frequency (TF-IDF) features of the message text in the signatures. The features are obtained by web scraping from the referenced external attack identification systems described in the signature. Because failure needs to be minimized in the classification of IDPS signatures, as in the medical field, we consider introducing a RO in our proposed model. The effectiveness of the proposed classification model is evaluated in experiments with two real datasets composed of signatures labeled by experts: a dataset that can be classified with if-then rules and a dataset with elements that do not match an if-then rule. In the experiment, the proposed model is evaluated. In both cases, the combined SFs and WMFs performed better than the combined SFs and KFs. In addition, we also performed feature analysis.
Hyperspectral Image Classification With Contrastive Graph Convolutional Network
May 11, 2022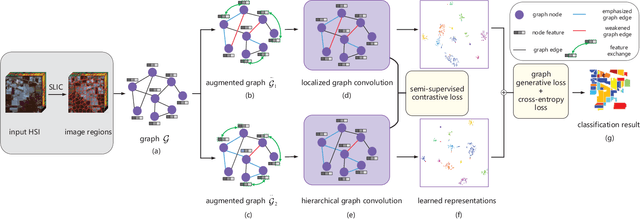
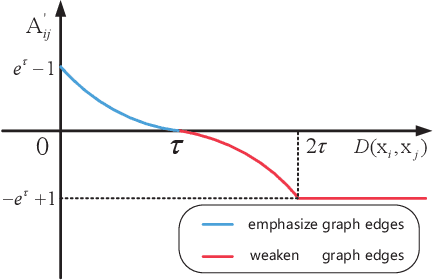

Recently, Graph Convolutional Network (GCN) has been widely used in Hyperspectral Image (HSI) classification due to its satisfactory performance. However, the number of labeled pixels is very limited in HSI, and thus the available supervision information is usually insufficient, which will inevitably degrade the representation ability of most existing GCN-based methods. To enhance the feature representation ability, in this paper, a GCN model with contrastive learning is proposed to explore the supervision signals contained in both spectral information and spatial relations, which is termed Contrastive Graph Convolutional Network (ConGCN), for HSI classification. First, in order to mine sufficient supervision signals from spectral information, a semi-supervised contrastive loss function is utilized to maximize the agreement between different views of the same node or the nodes from the same land cover category. Second, to extract the precious yet implicit spatial relations in HSI, a graph generative loss function is leveraged to explore supplementary supervision signals contained in the graph topology. In addition, an adaptive graph augmentation technique is designed to flexibly incorporate the spectral-spatial priors of HSI, which helps facilitate the subsequent contrastive representation learning. The extensive experimental results on four typical benchmark datasets firmly demonstrate the effectiveness of the proposed ConGCN in both qualitative and quantitative aspects.
Bottleneck Problems: Information and Estimation-Theoretic View
Nov 12, 2020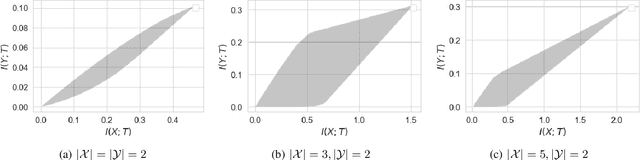
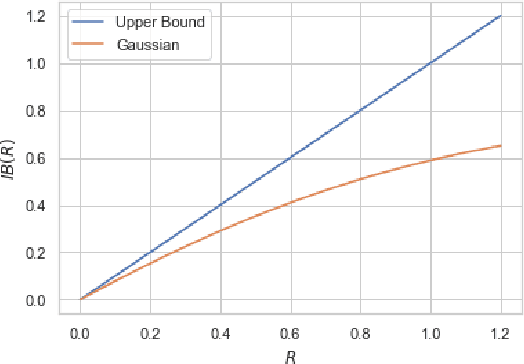
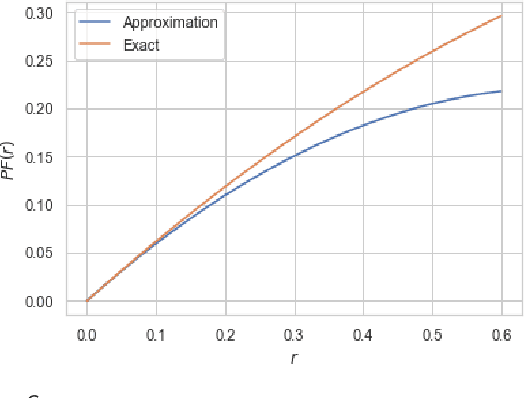
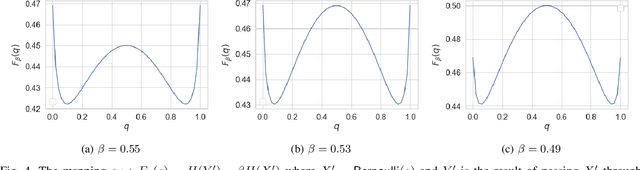
Information bottleneck (IB) and privacy funnel (PF) are two closely related optimization problems which have found applications in machine learning, design of privacy algorithms, capacity problems (e.g., Mrs. Gerber's Lemma), strong data processing inequalities, among others. In this work, we first investigate the functional properties of IB and PF through a unified theoretical framework. We then connect them to three information-theoretic coding problems, namely hypothesis testing against independence, noisy source coding and dependence dilution. Leveraging these connections, we prove a new cardinality bound for the auxiliary variable in IB, making its computation more tractable for discrete random variables. In the second part, we introduce a general family of optimization problems, termed as \textit{bottleneck problems}, by replacing mutual information in IB and PF with other notions of mutual information, namely $f$-information and Arimoto's mutual information. We then argue that, unlike IB and PF, these problems lead to easily interpretable guarantee in a variety of inference tasks with statistical constraints on accuracy and privacy. Although the underlying optimization problems are non-convex, we develop a technique to evaluate bottleneck problems in closed form by equivalently expressing them in terms of lower convex or upper concave envelope of certain functions. By applying this technique to binary case, we derive closed form expressions for several bottleneck problems.
Unified BERT for Few-shot Natural Language Understanding
Jun 24, 2022
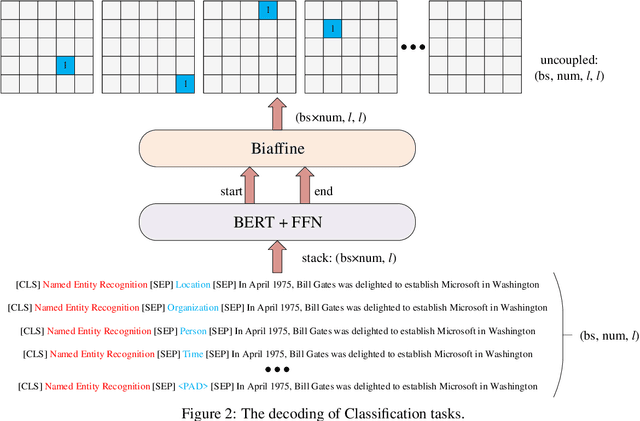
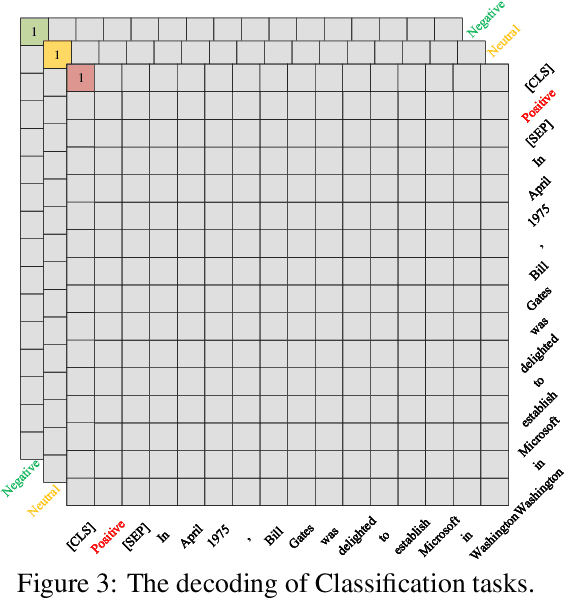

Even as pre-trained language models share a semantic encoder, natural language understanding suffers from a diversity of output schemas. In this paper, we propose UBERT, a unified bidirectional language understanding model based on BERT framework, which can universally model the training objects of different NLU tasks through a biaffine network. Specifically, UBERT encodes prior knowledge from various aspects, uniformly constructing learning representations across multiple NLU tasks, which is conducive to enhancing the ability to capture common semantic understanding. Using the biaffine to model scores pair of the start and end position of the original text, various classification and extraction structures can be converted into a universal, span-decoding approach. Experiments show that UBERT achieves the state-of-the-art performance on 7 NLU tasks, 14 datasets on few-shot and zero-shot setting, and realizes the unification of extensive information extraction and linguistic reasoning tasks.
SSD-Faster Net: A Hybrid Network for Industrial Defect Inspection
Jul 03, 2022
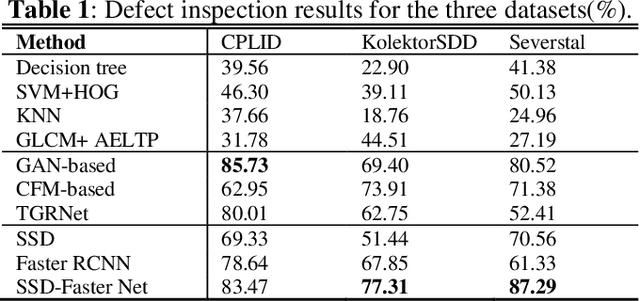
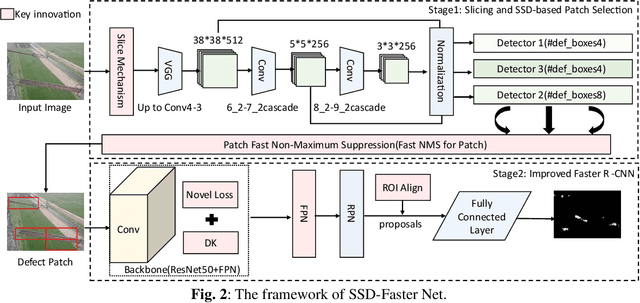
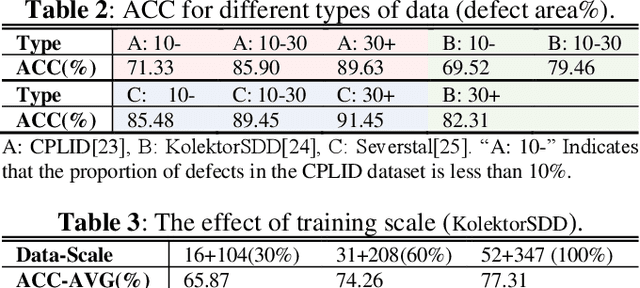
The quality of industrial components is critical to the production of special equipment such as robots. Defect inspection of these components is an efficient way to ensure quality. In this paper, we propose a hybrid network, SSD-Faster Net, for industrial defect inspection of rails, insulators, commutators etc. SSD-Faster Net is a two-stage network, including SSD for quickly locating defective blocks, and an improved Faster R-CNN for defect segmentation. For the former, we propose a novel slice localization mechanism to help SSD scan quickly. The second stage is based on improved Faster R-CNN, using FPN, deformable kernel(DK) to enhance representation ability. It fuses multi-scale information, and self-adapts the receptive field. We also propose a novel loss function and use ROI Align to improve accuracy. Experiments show that our SSD-Faster Net achieves an average accuracy of 84.03%, which is 13.42% higher than the nearest competitor based on Faster R-CNN, 4.14% better than GAN-based methods, more than 10% higher than that of DNN-based detectors. And the computing speed is improved by nearly 7%, which proves its robustness and superior performance.
Active Programming by Example with a Natural Language Prior
May 25, 2022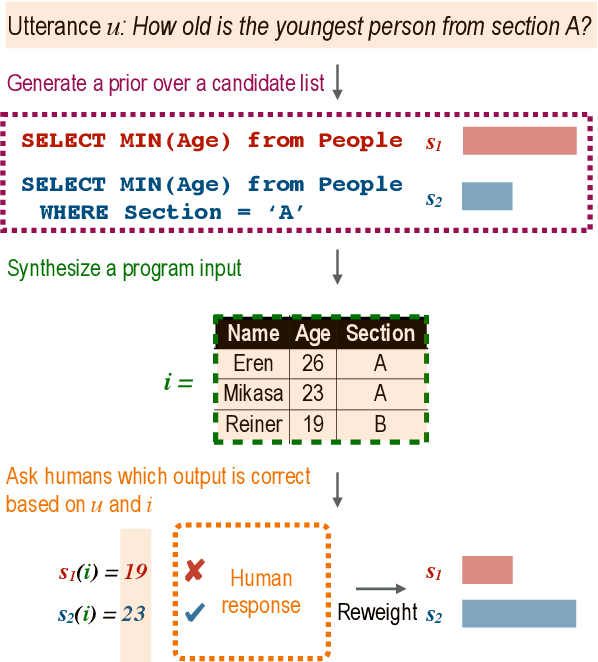
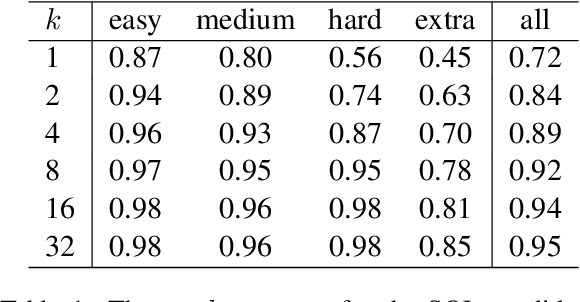

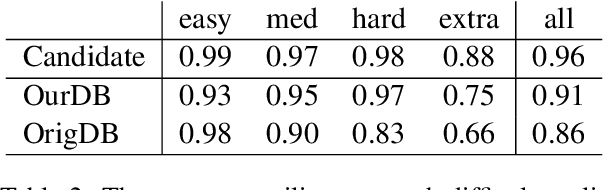
We introduce APEL, a new framework that enables non-programmers to indirectly annotate natural language utterances with executable meaning representations, such as SQL programs. Based on a natural language utterance, we first run a seed semantic parser to generate a prior over a list of candidate programs. To obtain information about which candidate is correct, we synthesize an input on which the more likely programs tend to produce different outputs, and ask an annotator which output is appropriate for the utterance. Hence, the annotator does not have to directly inspect the programs. To further reduce effort required from annotators, we aim to synthesize simple input databases that nonetheless have high information gain. With human annotators and Bayesian inference to handle annotation errors, we outperform Codex's top-1 performance (59%) and achieve the same accuracy as the original expert annotators (75%), by soliciting answers for each utterance on only 2 databases with an average of 9 records each. In contrast, it would be impractical to solicit outputs on the original 30K-record databases provided by SPIDER
NDGGNET-A Node Independent Gate based Graph Neural Networks
May 11, 2022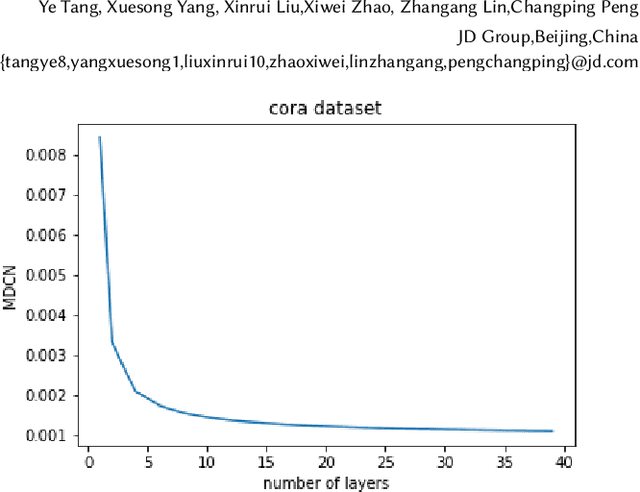
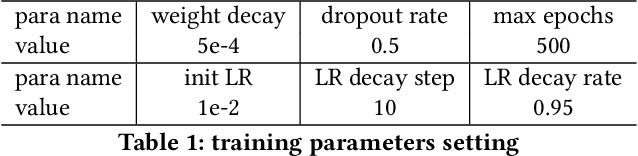
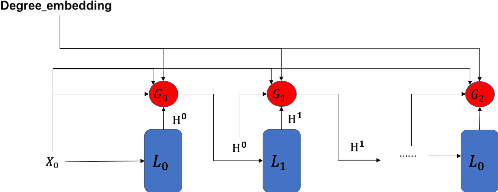
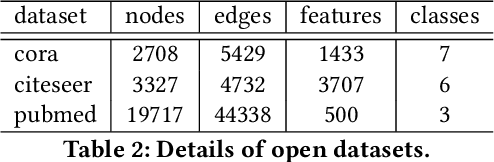
Graph Neural Networks (GNNs) is an architecture for structural data, and has been adopted in a mass of tasks and achieved fabulous results, such as link prediction, node classification, graph classification and so on. Generally, for a certain node in a given graph, a traditional GNN layer can be regarded as an aggregation from one-hop neighbors, thus a set of stacked layers are able to fetch and update node status within multi-hops. For nodes with sparse connectivity, it is difficult to obtain enough information through a single GNN layer as not only there are only few nodes directly connected to them but also can not propagate the high-order neighbor information. However, as the number of layer increases, the GNN model is prone to over-smooth for nodes with the dense connectivity, which resulting in the decrease of accuracy. To tackle this issue, in this thesis, we define a novel framework that allows the normal GNN model to accommodate more layers. Specifically, a node-degree based gate is employed to adjust weight of layers dynamically, that try to enhance the information aggregation ability and reduce the probability of over-smoothing. Experimental results show that our proposed model can effectively increase the model depth and perform well on several datasets.
Decentralized Multi-AGV Task Allocation based on Multi-Agent Reinforcement Learning with Information Potential Field Rewards
Aug 16, 2021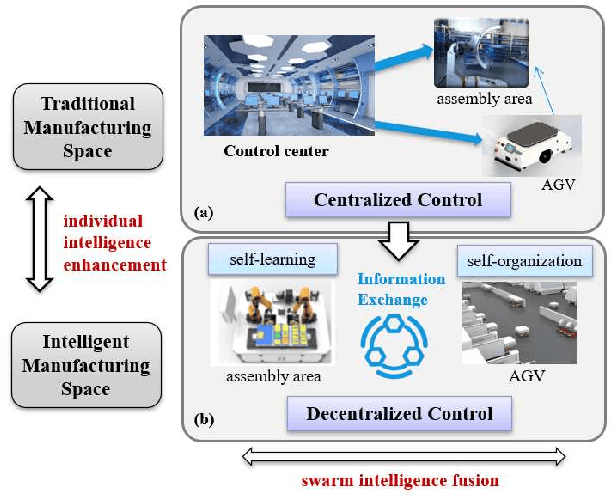
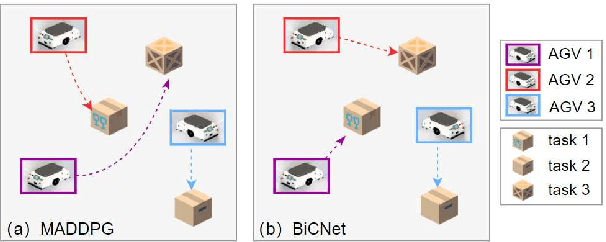
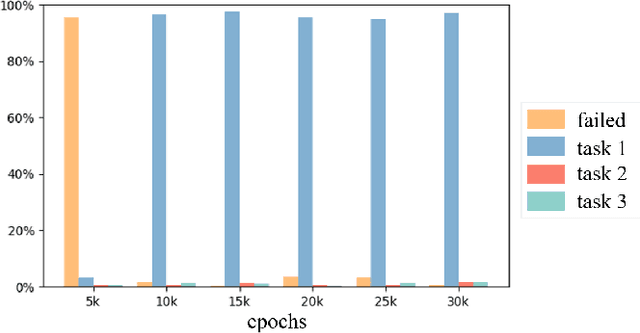
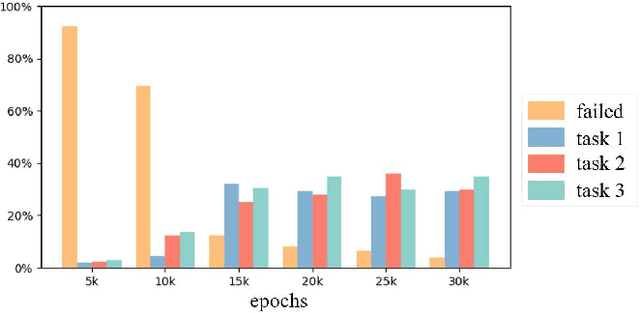
Automated Guided Vehicles (AGVs) have been widely used for material handling in flexible shop floors. Each product requires various raw materials to complete the assembly in production process. AGVs are used to realize the automatic handling of raw materials in different locations. Efficient AGVs task allocation strategy can reduce transportation costs and improve distribution efficiency. However, the traditional centralized approaches make high demands on the control center's computing power and real-time capability. In this paper, we present decentralized solutions to achieve flexible and self-organized AGVs task allocation. In particular, we propose two improved multi-agent reinforcement learning algorithms, MADDPG-IPF (Information Potential Field) and BiCNet-IPF, to realize the coordination among AGVs adapting to different scenarios. To address the reward-sparsity issue, we propose a reward shaping strategy based on information potential field, which provides stepwise rewards and implicitly guides the AGVs to different material targets. We conduct experiments under different settings (3 AGVs and 6 AGVs), and the experiment results indicate that, compared with baseline methods, our work obtains up to 47\% task response improvement and 22\% training iterations reduction.
Frequency Hopping Joint Radar-Communications with Hybrid Sub-pulse Frequency and Duration
Apr 26, 2022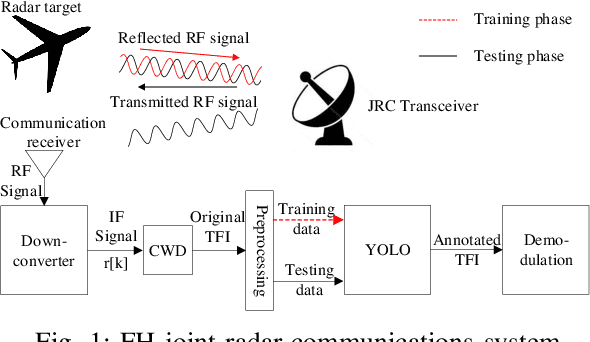
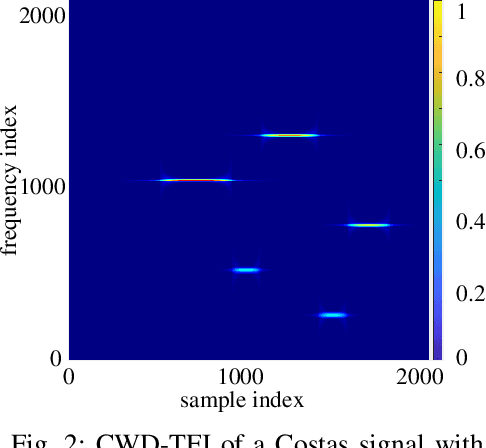
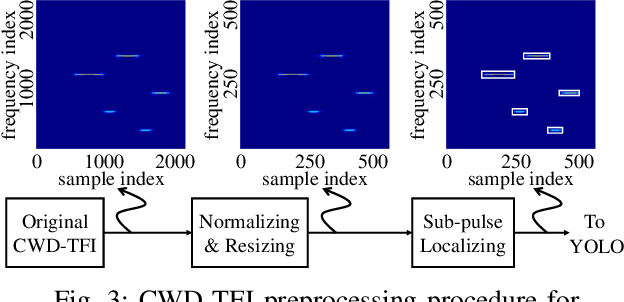
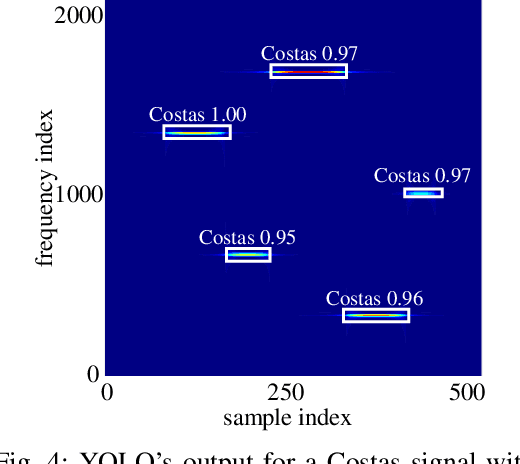
Frequency-hopping (FH) joint radar-communications (JRC) can offer excellent security for integrated sensing and communication systems. However, existing JRC schemes mainly embed information using only the sub-pulse frequencies and hence the data rate is limited. In this paper, we propose to use both sub-pulse frequencies and durations for information modulation, leading to higher communication data rates. For information demodulation, we propose a novel scheme by using the time-frequency analysis (TFA) technique and a "you only look once" (YOLO)-based detection system. As such, our system does not require channel estimation, simplifying the transmission signal frame design. Simulation results demonstrate the effectiveness of our scheme, and show that it is robust against the Doppler shift and timing offset between the transceiver and the communication receiver.
Discovering novel systemic biomarkers in photos of the external eye
Jul 19, 2022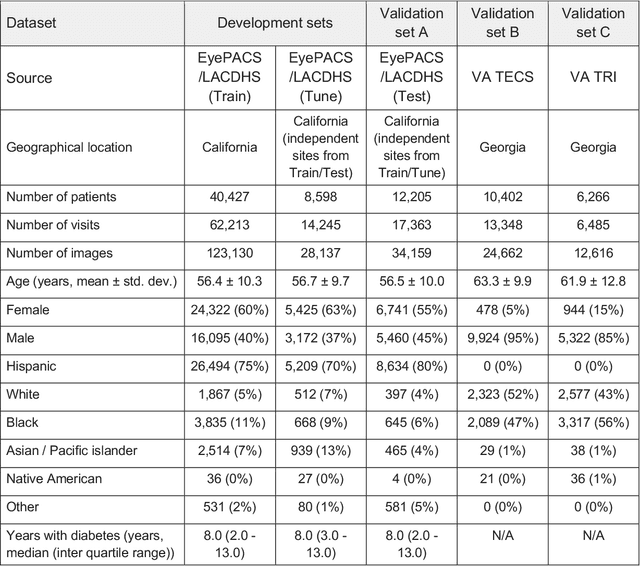
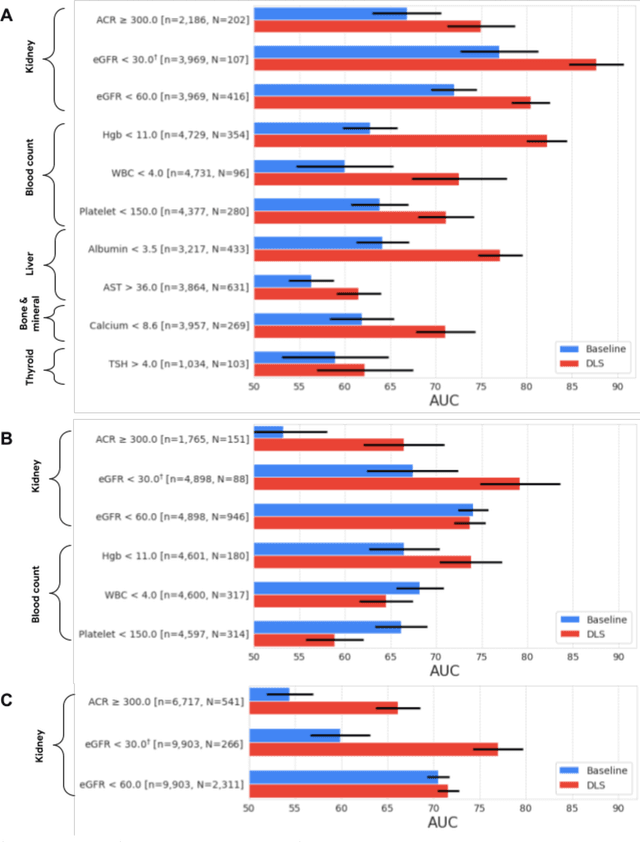
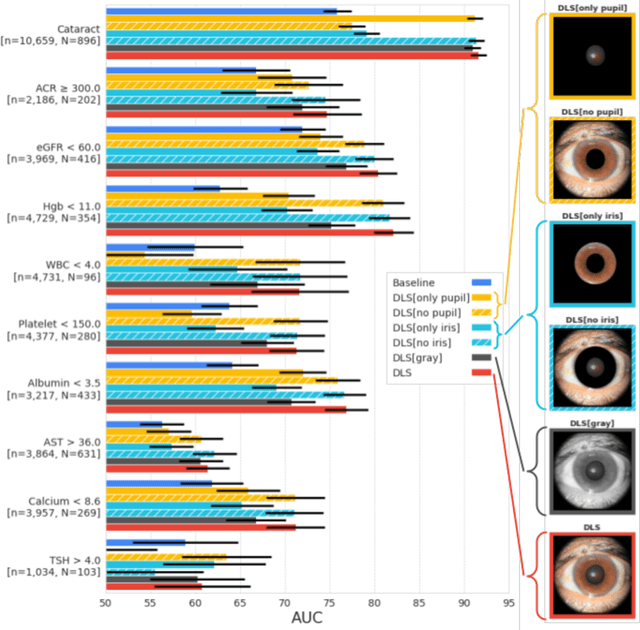
External eye photos were recently shown to reveal signs of diabetic retinal disease and elevated HbA1c. In this paper, we evaluate if external eye photos contain information about additional systemic medical conditions. We developed a deep learning system (DLS) that takes external eye photos as input and predicts multiple systemic parameters, such as those related to the liver (albumin, AST); kidney (eGFR estimated using the race-free 2021 CKD-EPI creatinine equation, the urine ACR); bone & mineral (calcium); thyroid (TSH); and blood count (Hgb, WBC, platelets). Development leveraged 151,237 images from 49,015 patients with diabetes undergoing diabetic eye screening in 11 sites across Los Angeles county, CA. Evaluation focused on 9 pre-specified systemic parameters and leveraged 3 validation sets (A, B, C) spanning 28,869 patients with and without diabetes undergoing eye screening in 3 independent sites in Los Angeles County, CA, and the greater Atlanta area, GA. We compared against baseline models incorporating available clinicodemographic variables (e.g. age, sex, race/ethnicity, years with diabetes). Relative to the baseline, the DLS achieved statistically significant superior performance at detecting AST>36, calcium<8.6, eGFR<60, Hgb<11, platelets<150, ACR>=300, and WBC<4 on validation set A (a patient population similar to the development sets), where the AUC of DLS exceeded that of the baseline by 5.2-19.4%. On validation sets B and C, with substantial patient population differences compared to the development sets, the DLS outperformed the baseline for ACR>=300 and Hgb<11 by 7.3-13.2%. Our findings provide further evidence that external eye photos contain important biomarkers of systemic health spanning multiple organ systems. Further work is needed to investigate whether and how these biomarkers can be translated into clinical impact.