 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Guardian Angel: A Novel Walking Aid for the Visually Impaired
Jun 20, 2022

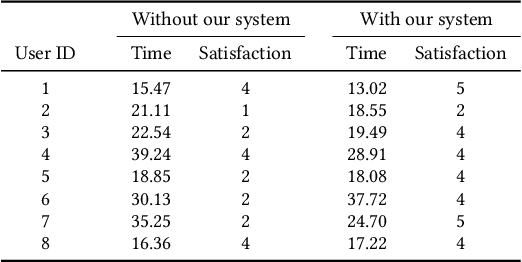
This work introduces Guardian Angel, an Android App that assists visually impaired people to avoid danger in complex traffic environment. The system, consisting of object detection by pretrained YOLO model, distance estimation and moving direction estimation, provides information about surrounding vehicles and alarms users of potential danger without expensive special purpose device. With an experiment of 8 subjects, we corroborate that in terms of satisfaction score in pedestrian-crossing experiment with the assistance of our App using a smartphone is better than when without under 99% confidence level. The time needed to cross a road is shorter on average with the assistance of our system, however, not reaching significant difference by our experiment. The App has been released in Google Play Store, open to the public for free.
Frequency Hopping Joint Radar-Communications with Hybrid Sub-pulse Frequency and Duration
Apr 26, 2022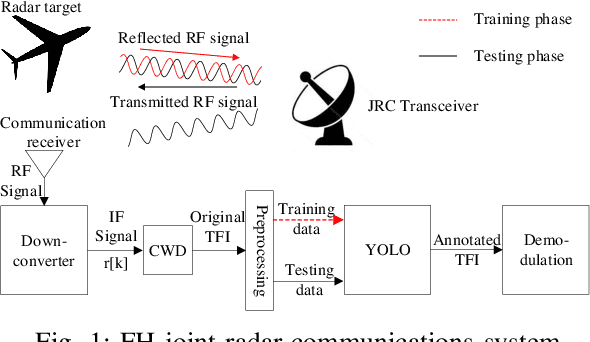
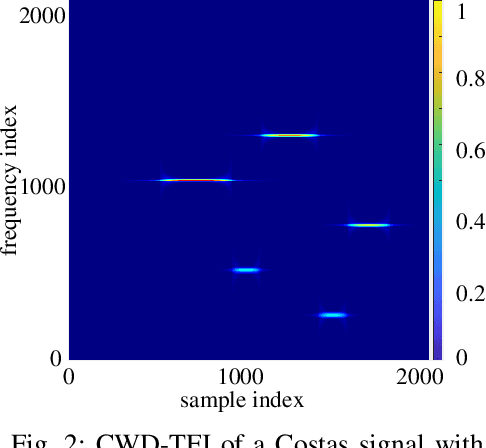
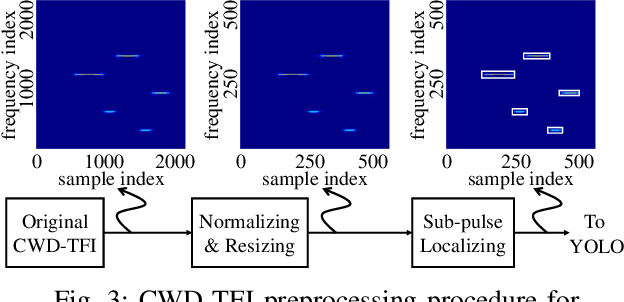
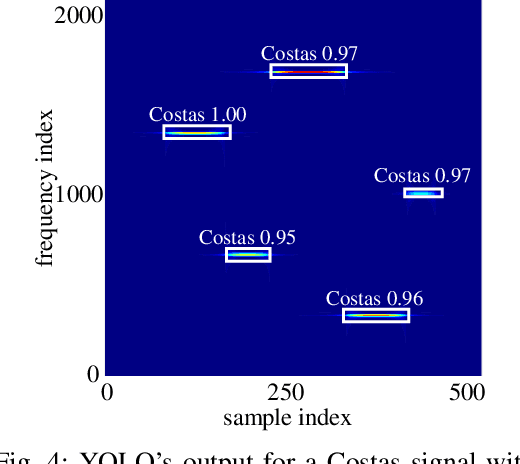
Frequency-hopping (FH) joint radar-communications (JRC) can offer excellent security for integrated sensing and communication systems. However, existing JRC schemes mainly embed information using only the sub-pulse frequencies and hence the data rate is limited. In this paper, we propose to use both sub-pulse frequencies and durations for information modulation, leading to higher communication data rates. For information demodulation, we propose a novel scheme by using the time-frequency analysis (TFA) technique and a "you only look once" (YOLO)-based detection system. As such, our system does not require channel estimation, simplifying the transmission signal frame design. Simulation results demonstrate the effectiveness of our scheme, and show that it is robust against the Doppler shift and timing offset between the transceiver and the communication receiver.
NDGGNET-A Node Independent Gate based Graph Neural Networks
May 11, 2022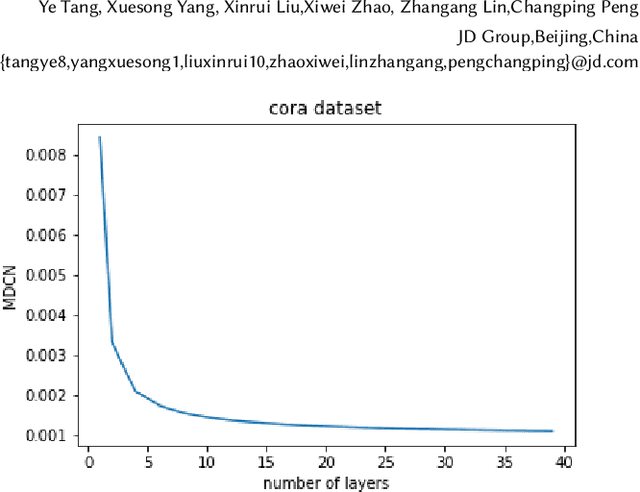
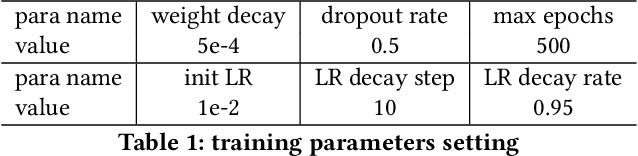
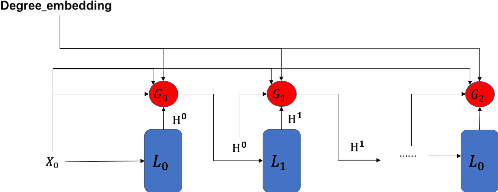
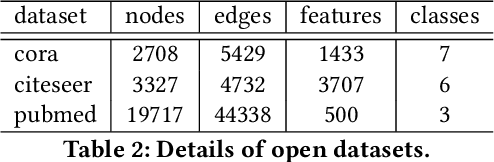
Graph Neural Networks (GNNs) is an architecture for structural data, and has been adopted in a mass of tasks and achieved fabulous results, such as link prediction, node classification, graph classification and so on. Generally, for a certain node in a given graph, a traditional GNN layer can be regarded as an aggregation from one-hop neighbors, thus a set of stacked layers are able to fetch and update node status within multi-hops. For nodes with sparse connectivity, it is difficult to obtain enough information through a single GNN layer as not only there are only few nodes directly connected to them but also can not propagate the high-order neighbor information. However, as the number of layer increases, the GNN model is prone to over-smooth for nodes with the dense connectivity, which resulting in the decrease of accuracy. To tackle this issue, in this thesis, we define a novel framework that allows the normal GNN model to accommodate more layers. Specifically, a node-degree based gate is employed to adjust weight of layers dynamically, that try to enhance the information aggregation ability and reduce the probability of over-smoothing. Experimental results show that our proposed model can effectively increase the model depth and perform well on several datasets.
Active Programming by Example with a Natural Language Prior
May 25, 2022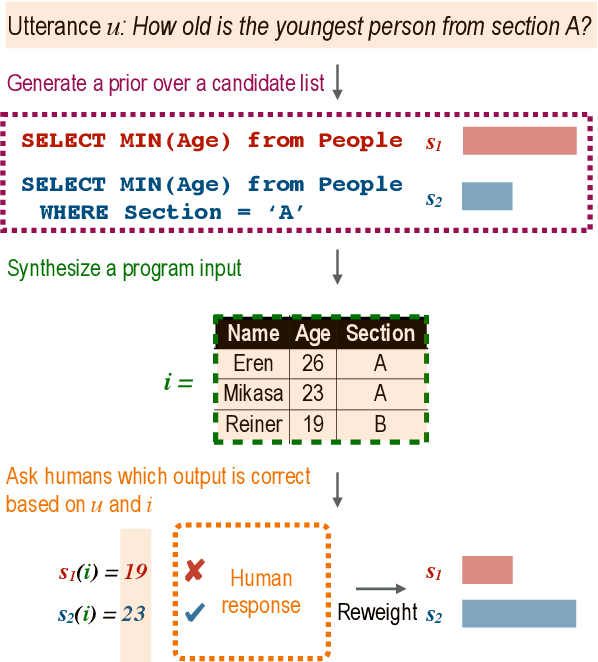
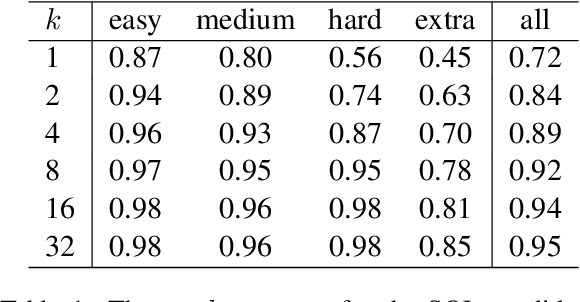

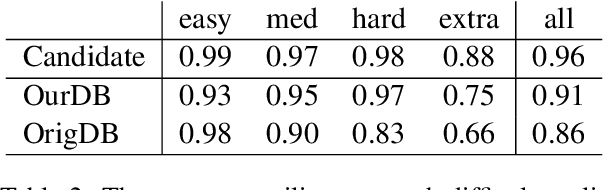
We introduce APEL, a new framework that enables non-programmers to indirectly annotate natural language utterances with executable meaning representations, such as SQL programs. Based on a natural language utterance, we first run a seed semantic parser to generate a prior over a list of candidate programs. To obtain information about which candidate is correct, we synthesize an input on which the more likely programs tend to produce different outputs, and ask an annotator which output is appropriate for the utterance. Hence, the annotator does not have to directly inspect the programs. To further reduce effort required from annotators, we aim to synthesize simple input databases that nonetheless have high information gain. With human annotators and Bayesian inference to handle annotation errors, we outperform Codex's top-1 performance (59%) and achieve the same accuracy as the original expert annotators (75%), by soliciting answers for each utterance on only 2 databases with an average of 9 records each. In contrast, it would be impractical to solicit outputs on the original 30K-record databases provided by SPIDER
A Survey of Decentralized Online Learning
May 01, 2022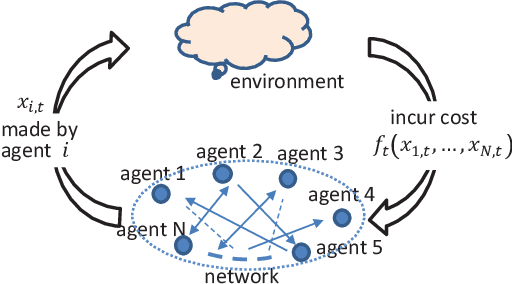

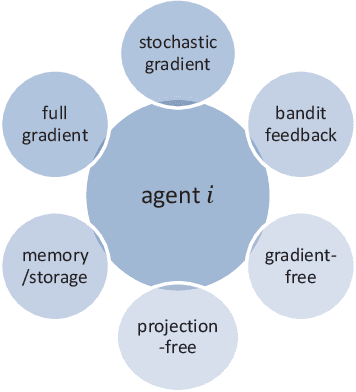
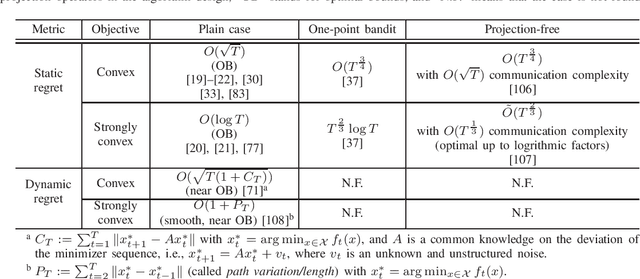
Decentralized online learning (DOL) has been increasingly researched in the last decade, mostly motivated by its wide applications in sensor networks, commercial buildings, robotics (e.g., decentralized target tracking and formation control), smart grids, deep learning, and so forth. In this problem, there are a network of agents who may be cooperative (i.e., decentralized online optimization) or noncooperative (i.e., online game) through local information exchanges, and the local cost function of each agent is often time-varying in dynamic and even adversarial environments. At each time, a decision must be made by each agent based on historical information at hand without knowing future information on cost functions. Although this problem has been extensively studied in the last decade, a comprehensive survey is lacking. Therefore, this paper provides a thorough overview of DOL from the perspective of problem settings, communication, computation, and performances. In addition, some potential future directions are also discussed in details.
Channel Estimation and Signal Detection for MIMO-AFDM under Doubly Selective Channels
Jun 26, 2022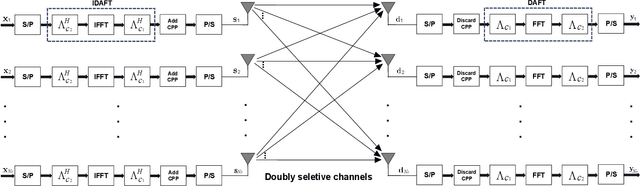
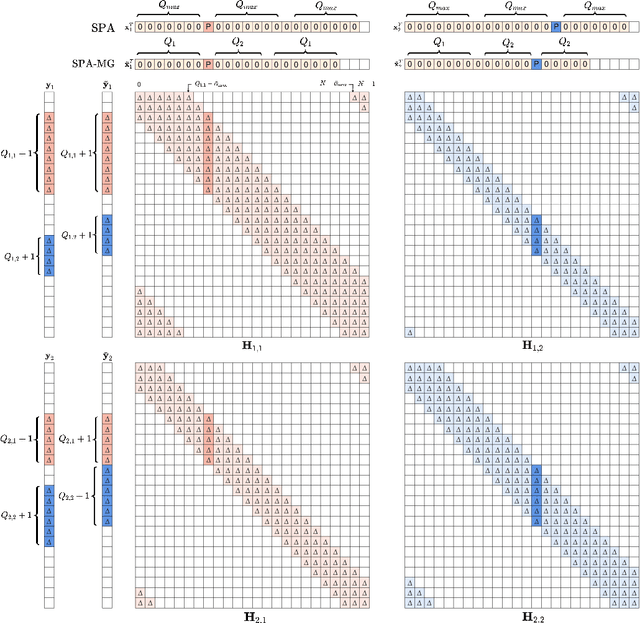
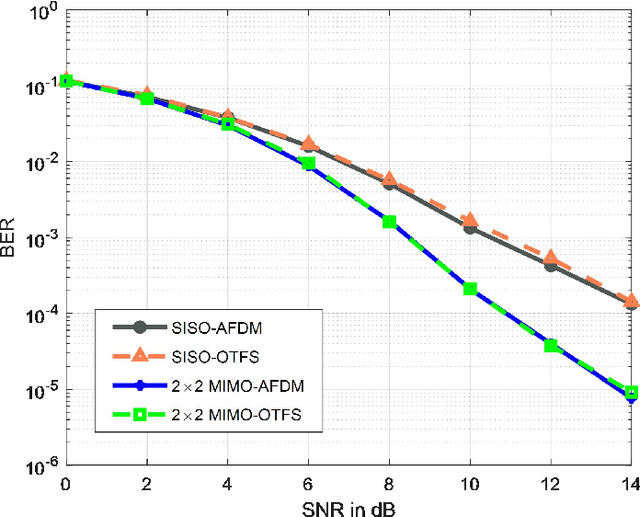
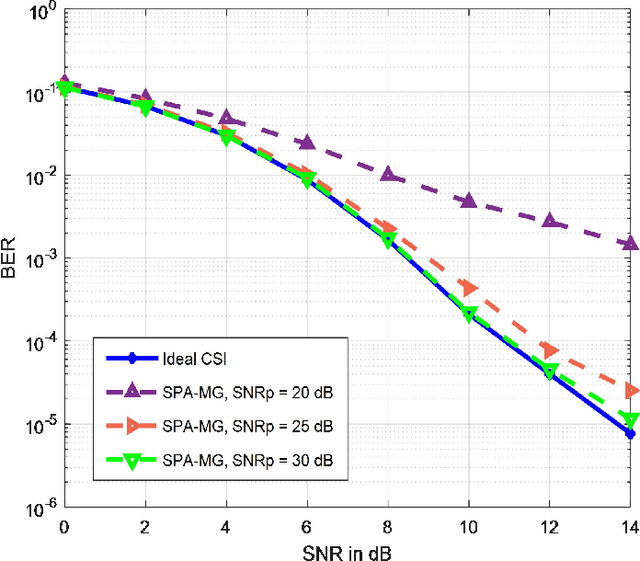
On the heels of orthogonal time frequency space (OTFS) modulation, the recently discovered affine frequency division multiplexing (AFDM) is a promising waveform for the sixth-generation wireless network due to its strong delay-doppler resilience against the double dispersive channels. With the superiorities of high multiplexing and diversity gain of multiple-input multiple-output (MIMO), we derive a vectorized input-output formulation of the MIMO-AFDM system. Correspondingly, we also propose an efficient single pilot aided with minimum guard (SPA-MG) scheme to perform channel estimation in the discrete affine Fourier transform (DAFT) domain. Furthermore, the message passing based iterative detector is explored for signal detection. Finally, the bit error ratio (BER) performances are simulated under doubly selective channels. It is worth emphasizing that the MIMO-AFDM system can achieve outstanding performance similar to MIMO-OTFS. Additionally, compared to ideal channel state information, our proposed SPA-MG scheme is verified to provide marginal difference with the least overhead.
CAiRE in DialDoc21: Data Augmentation for Information-Seeking Dialogue System
Jun 07, 2021
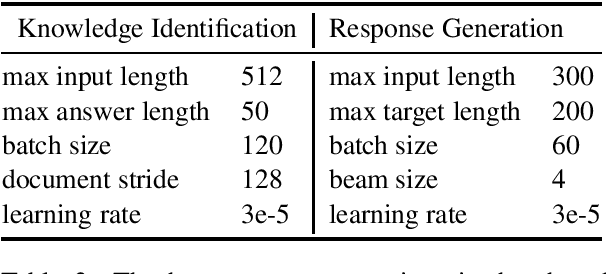
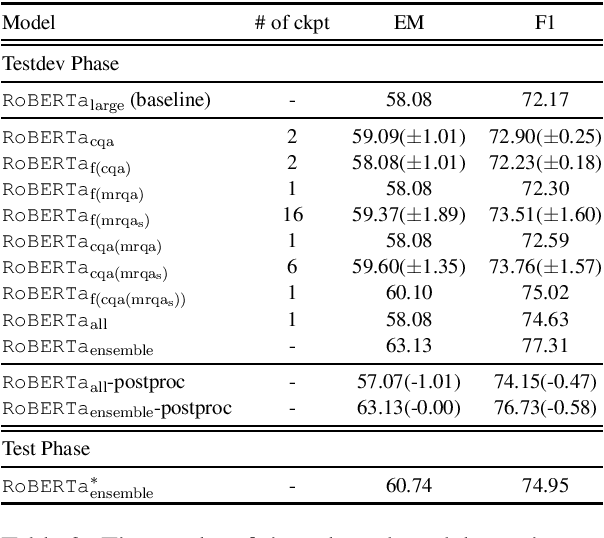
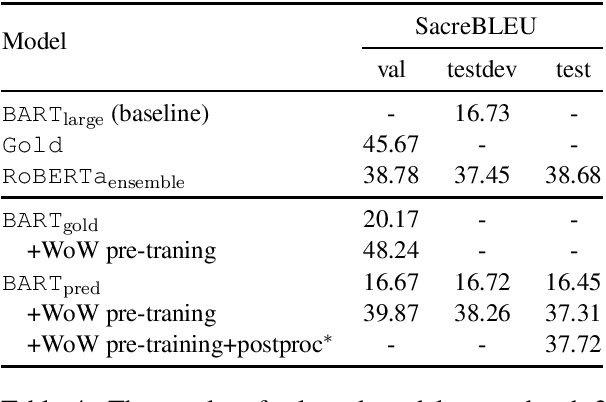
Information-seeking dialogue systems, including knowledge identification and response generation, aim to respond to users with fluent, coherent, and informative responses based on users' needs, which. To tackle this challenge, we utilize data augmentation methods and several training techniques with the pre-trained language models to learn a general pattern of the task and thus achieve promising performance. In DialDoc21 competition, our system achieved 74.95 F1 score and 60.74 Exact Match score in subtask 1, and 37.72 SacreBLEU score in subtask 2. Empirical analysis is provided to explain the effectiveness of our approaches.
GLD-Net: Improving Monaural Speech Enhancement by Learning Global and Local Dependency Features with GLD Block
Jun 30, 2022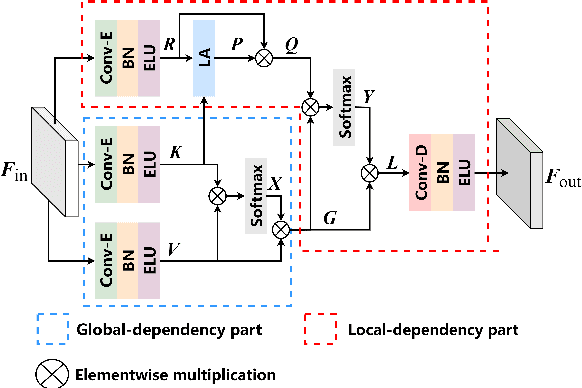
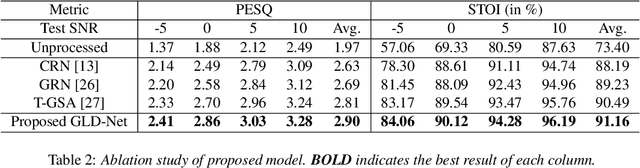
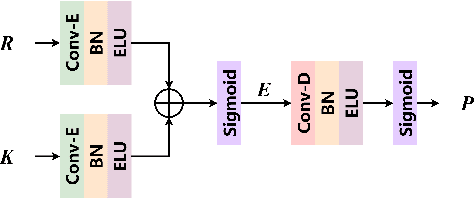

For monaural speech enhancement, contextual information is important for accurate speech estimation. However, commonly used convolution neural networks (CNNs) are weak in capturing temporal contexts since they only build blocks that process one local neighborhood at a time. To address this problem, we learn from human auditory perception to introduce a two-stage trainable reasoning mechanism, referred as global-local dependency (GLD) block. GLD blocks capture long-term dependency of time-frequency bins both in global level and local level from the noisy spectrogram to help detecting correlations among speech part, noise part, and whole noisy input. What is more, we conduct a monaural speech enhancement network called GLD-Net, which adopts encoder-decoder architecture and consists of speech object branch, interference branch, and global noisy branch. The extracted speech feature at global-level and local-level are efficiently reasoned and aggregated in each of the branches. We compare the proposed GLD-Net with existing state-of-art methods on WSJ0 and DEMAND dataset. The results show that GLD-Net outperforms the state-of-the-art methods in terms of PESQ and STOI.
Unified BERT for Few-shot Natural Language Understanding
Jun 24, 2022
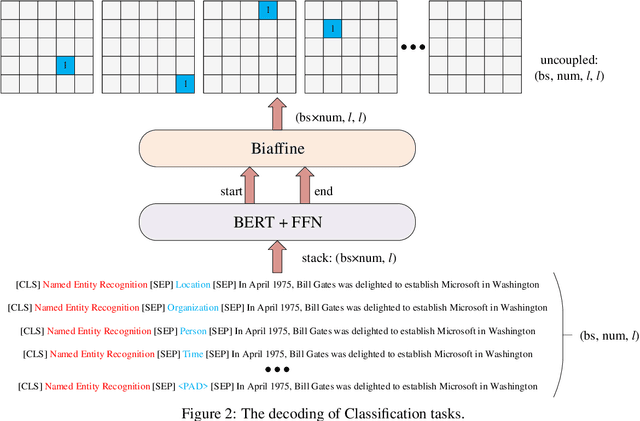
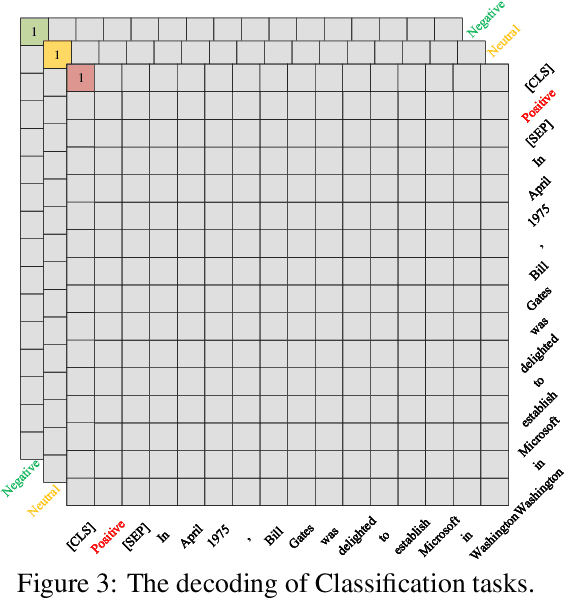

Even as pre-trained language models share a semantic encoder, natural language understanding suffers from a diversity of output schemas. In this paper, we propose UBERT, a unified bidirectional language understanding model based on BERT framework, which can universally model the training objects of different NLU tasks through a biaffine network. Specifically, UBERT encodes prior knowledge from various aspects, uniformly constructing learning representations across multiple NLU tasks, which is conducive to enhancing the ability to capture common semantic understanding. Using the biaffine to model scores pair of the start and end position of the original text, various classification and extraction structures can be converted into a universal, span-decoding approach. Experiments show that UBERT achieves the state-of-the-art performance on 7 NLU tasks, 14 datasets on few-shot and zero-shot setting, and realizes the unification of extensive information extraction and linguistic reasoning tasks.
SSD-Faster Net: A Hybrid Network for Industrial Defect Inspection
Jul 03, 2022
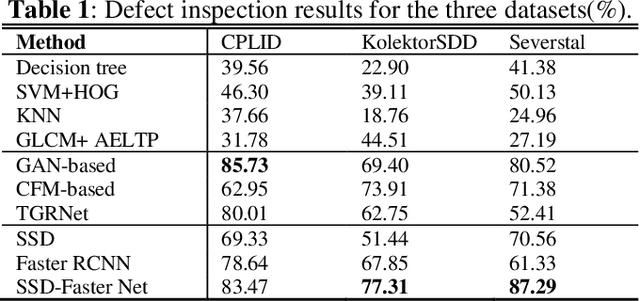
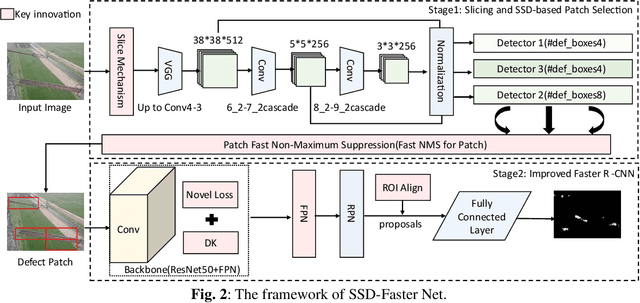
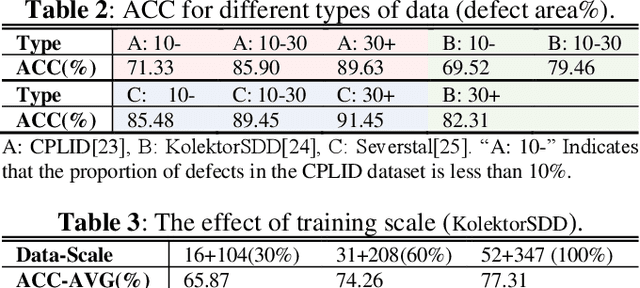
The quality of industrial components is critical to the production of special equipment such as robots. Defect inspection of these components is an efficient way to ensure quality. In this paper, we propose a hybrid network, SSD-Faster Net, for industrial defect inspection of rails, insulators, commutators etc. SSD-Faster Net is a two-stage network, including SSD for quickly locating defective blocks, and an improved Faster R-CNN for defect segmentation. For the former, we propose a novel slice localization mechanism to help SSD scan quickly. The second stage is based on improved Faster R-CNN, using FPN, deformable kernel(DK) to enhance representation ability. It fuses multi-scale information, and self-adapts the receptive field. We also propose a novel loss function and use ROI Align to improve accuracy. Experiments show that our SSD-Faster Net achieves an average accuracy of 84.03%, which is 13.42% higher than the nearest competitor based on Faster R-CNN, 4.14% better than GAN-based methods, more than 10% higher than that of DNN-based detectors. And the computing speed is improved by nearly 7%, which proves its robustness and superior performance.