 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Localizing the Recurrent Laryngeal Nerve via Ultrasound with a Bayesian Shape Framework
Jun 30, 2022
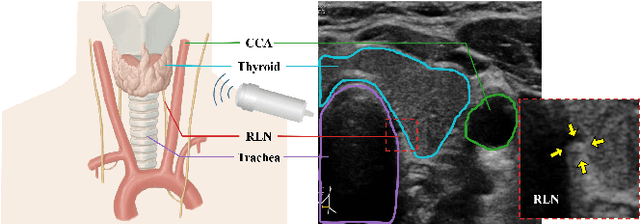
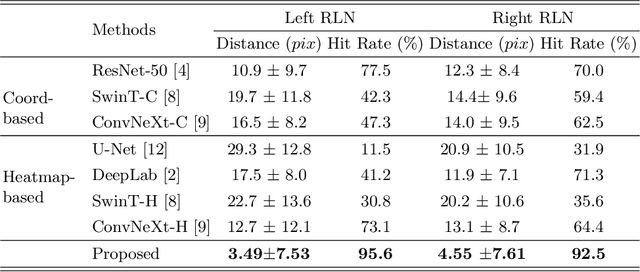
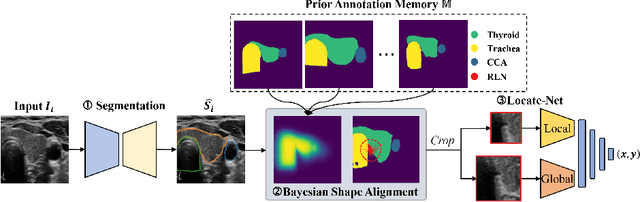
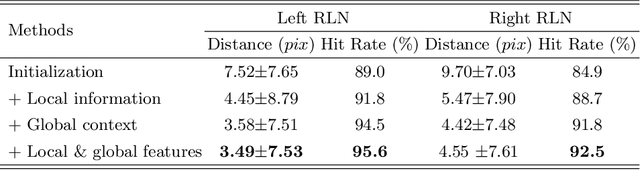
Tumor infiltration of the recurrent laryngeal nerve (RLN) is a contraindication for robotic thyroidectomy and can be difficult to detect via standard laryngoscopy. Ultrasound (US) is a viable alternative for RLN detection due to its safety and ability to provide real-time feedback. However, the tininess of the RLN, with a diameter typically less than 3mm, poses significant challenges to the accurate localization of the RLN. In this work, we propose a knowledge-driven framework for RLN localization, mimicking the standard approach surgeons take to identify the RLN according to its surrounding organs. We construct a prior anatomical model based on the inherent relative spatial relationships between organs. Through Bayesian shape alignment (BSA), we obtain the candidate coordinates of the center of a region of interest (ROI) that encloses the RLN. The ROI allows a decreased field of view for determining the refined centroid of the RLN using a dual-path identification network, based on multi-scale semantic information. Experimental results indicate that the proposed method achieves superior hit rates and substantially smaller distance errors compared with state-of-the-art methods.
A Comparative Study on Application of Class-Imbalance Learning for Severity Prediction of Adverse Events Following Immunization
Jun 20, 2022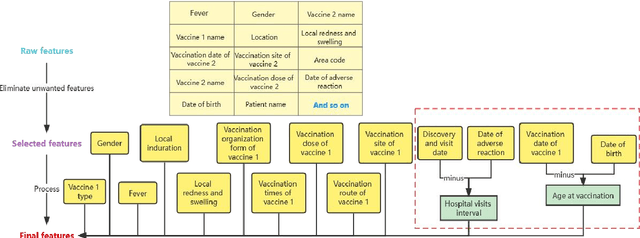
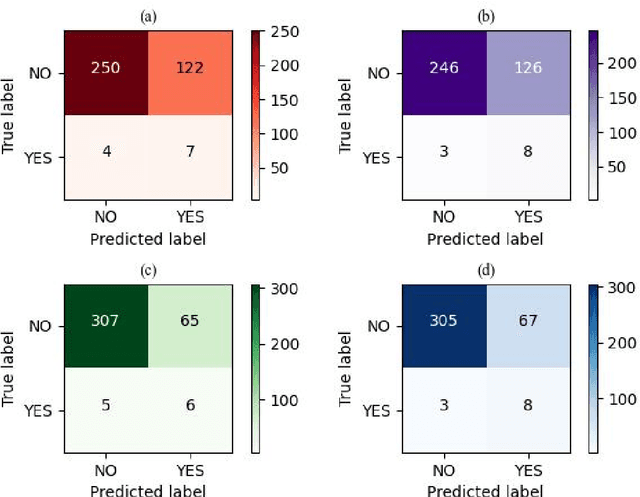


In collaboration with the Liaoning CDC, China, we propose a prediction system to predict the subsequent hospitalization of children with adverse reactions based on data on adverse events following immunization. We extracted multiple features from the data, and selected "hospitalization or not" as the target for classification. Since the data are imbalanced, we used various class-imbalance learning methods for training and improved the RUSBoost algorithm. Experimental results show that the improved RUSBoost has the highest Area Under the ROC Curve on the target among these algorithms. Additionally, we compared these class-imbalance learning methods with some common machine learning algorithms. We combined the improved RUSBoost with dynamic web resource development techniques to build an evaluation system with information entry and vaccination response prediction capabilities for relevant medical practitioners.
Direction-Aware Adaptive Online Neural Speech Enhancement with an Augmented Reality Headset in Real Noisy Conversational Environments
Jul 15, 2022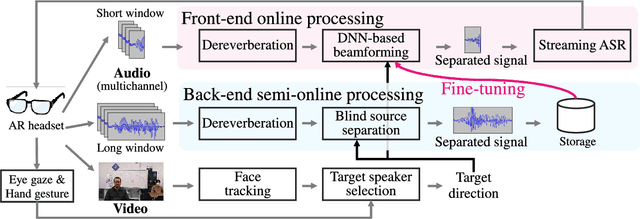

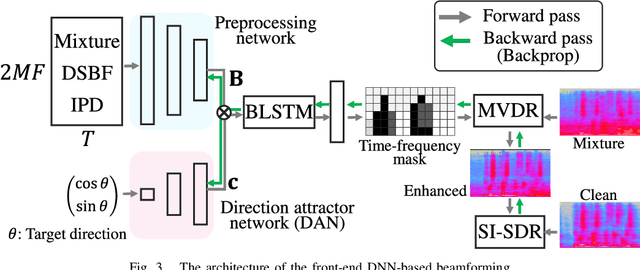
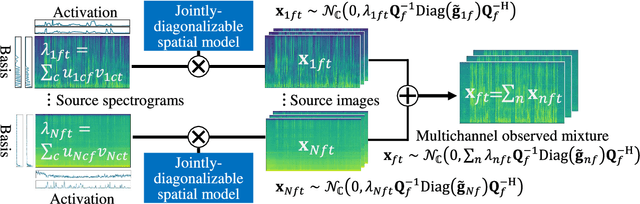
This paper describes the practical response- and performance-aware development of online speech enhancement for an augmented reality (AR) headset that helps a user understand conversations made in real noisy echoic environments (e.g., cocktail party). One may use a state-of-the-art blind source separation method called fast multichannel nonnegative matrix factorization (FastMNMF) that works well in various environments thanks to its unsupervised nature. Its heavy computational cost, however, prevents its application to real-time processing. In contrast, a supervised beamforming method that uses a deep neural network (DNN) for estimating spatial information of speech and noise readily fits real-time processing, but suffers from drastic performance degradation in mismatched conditions. Given such complementary characteristics, we propose a dual-process robust online speech enhancement method based on DNN-based beamforming with FastMNMF-guided adaptation. FastMNMF (back end) is performed in a mini-batch style and the noisy and enhanced speech pairs are used together with the original parallel training data for updating the direction-aware DNN (front end) with backpropagation at a computationally-allowable interval. This method is used with a blind dereverberation method called weighted prediction error (WPE) for transcribing the noisy reverberant speech of a speaker, which can be detected from video or selected by a user's hand gesture or eye gaze, in a streaming manner and spatially showing the transcriptions with an AR technique. Our experiment showed that the word error rate was improved by more than 10 points with the run-time adaptation using only twelve minutes of observation.
Decentralized Multi-AGV Task Allocation based on Multi-Agent Reinforcement Learning with Information Potential Field Rewards
Aug 16, 2021
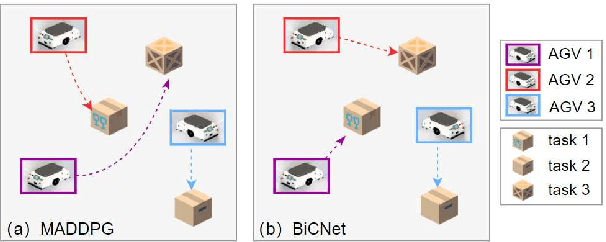
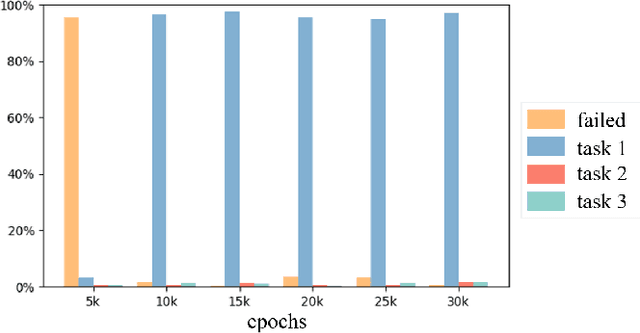
Automated Guided Vehicles (AGVs) have been widely used for material handling in flexible shop floors. Each product requires various raw materials to complete the assembly in production process. AGVs are used to realize the automatic handling of raw materials in different locations. Efficient AGVs task allocation strategy can reduce transportation costs and improve distribution efficiency. However, the traditional centralized approaches make high demands on the control center's computing power and real-time capability. In this paper, we present decentralized solutions to achieve flexible and self-organized AGVs task allocation. In particular, we propose two improved multi-agent reinforcement learning algorithms, MADDPG-IPF (Information Potential Field) and BiCNet-IPF, to realize the coordination among AGVs adapting to different scenarios. To address the reward-sparsity issue, we propose a reward shaping strategy based on information potential field, which provides stepwise rewards and implicitly guides the AGVs to different material targets. We conduct experiments under different settings (3 AGVs and 6 AGVs), and the experiment results indicate that, compared with baseline methods, our work obtains up to 47\% task response improvement and 22\% training iterations reduction.
Depth-CUPRL: Depth-Imaged Contrastive Unsupervised Prioritized Representations in Reinforcement Learning for Mapless Navigation of Unmanned Aerial Vehicles
Jun 30, 2022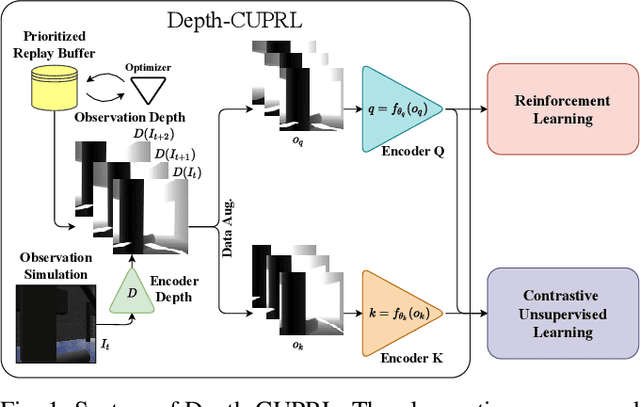
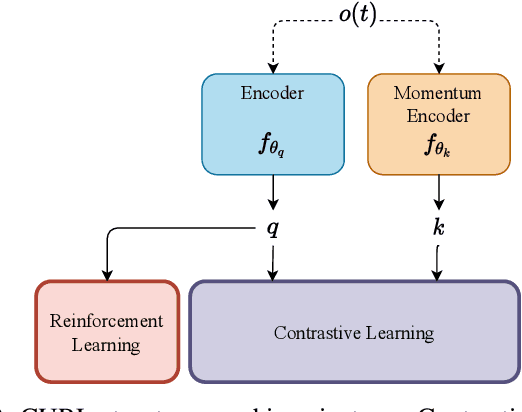
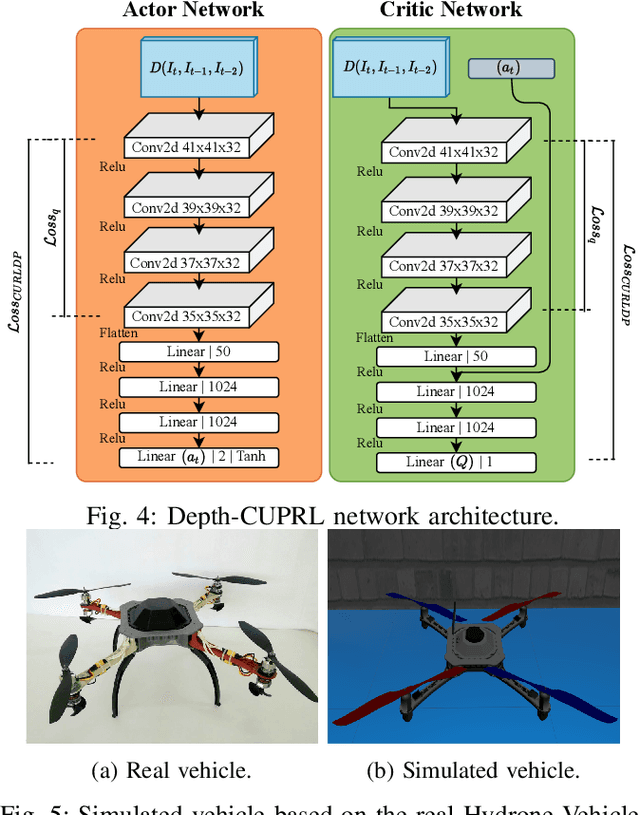
Reinforcement Learning (RL) has presented an impressive performance in video games through raw pixel imaging and continuous control tasks. However, RL performs poorly with high-dimensional observations such as raw pixel images. It is generally accepted that physical state-based RL policies such as laser sensor measurements give a more sample-efficient result than learning by pixels. This work presents a new approach that extracts information from a depth map estimation to teach an RL agent to perform the mapless navigation of Unmanned Aerial Vehicle (UAV). We propose the Depth-Imaged Contrastive Unsupervised Prioritized Representations in Reinforcement Learning(Depth-CUPRL) that estimates the depth of images with a prioritized replay memory. We used a combination of RL and Contrastive Learning to lead with the problem of RL based on images. From the analysis of the results with Unmanned Aerial Vehicles (UAVs), it is possible to conclude that our Depth-CUPRL approach is effective for the decision-making and outperforms state-of-the-art pixel-based approaches in the mapless navigation capability.
CSI-based Indoor Localization via Attention-Augmented Residual Convolutional Neural Network
May 11, 2022
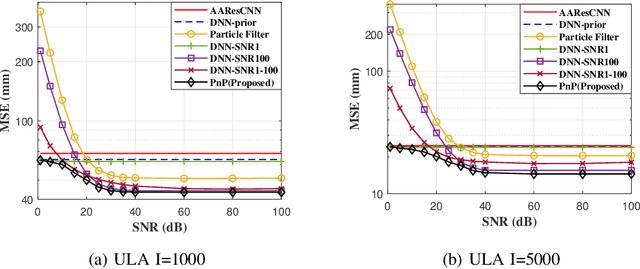
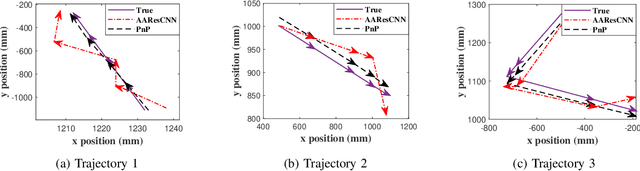
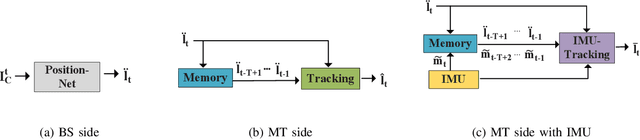
Deep learning has been widely adopted for channel state information (CSI)-fingerprinting indoor localization systems. These systems usually consist of two main parts, i.e., a positioning network that learns the mapping from high-dimensional CSI to physical locations and a tracking system that utilizes historical CSI to reduce the positioning error. This paper presents a new localization system with high accuracy and generality. On the one hand, the receptive field of the existing convolutional neural network (CNN)-based positioning networks is limited, restricting their performance as useful information in CSI is not explored thoroughly. As a solution, we propose a novel attention-augmented Residual CNN to utilize the local information and global context in CSI exhaustively. On the other hand, considering the generality of a tracking system, we decouple the tracking system from the CSI environments so that one tracking system for all environments becomes possible. Specifically, we remodel the tracking problem as a denoising task and solve it with deep trajectory prior. Furthermore, we investigate how the precision difference of inertial measurement units will adversely affect the tracking performance and adopt plug-and-play to solve the precision difference problem. Experiments show the superiority of our methods over existing approaches in performance and generality improvement.
Class Prior Estimation under Covariate Shift -- no Problem?
Jun 06, 2022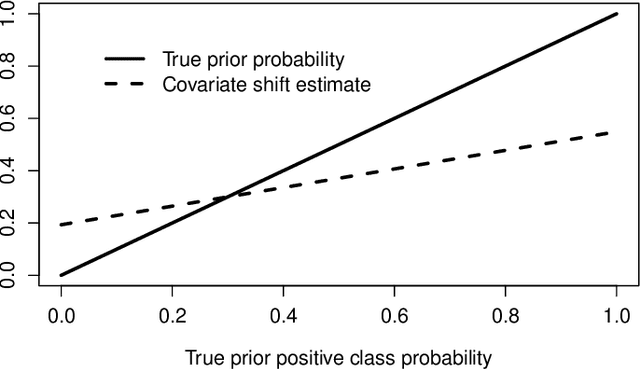
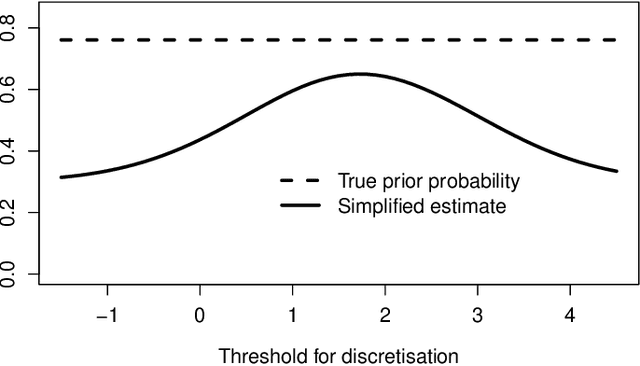
We show that in the context of classification the property of source and target distributions to be related by covariate shift may break down when the information content captured in the covariates is reduced, for instance by discretization of the covariates, dropping some of them, or by any transformation of the covariates even if it is domain-invariant. The consequences of this observation for class prior estimation under covariate shift are discussed. A probing algorithm as alternative approach to class prior estimation under covariate shift is proposed.
Predicting Hate Intensity of Twitter Conversation Threads
Jun 20, 2022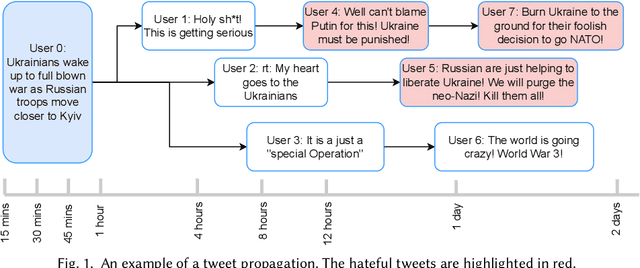
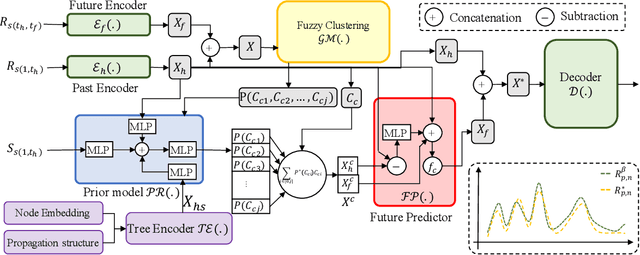
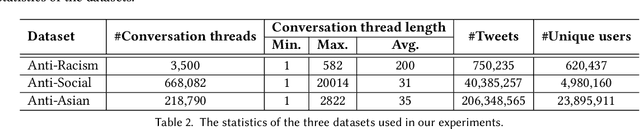
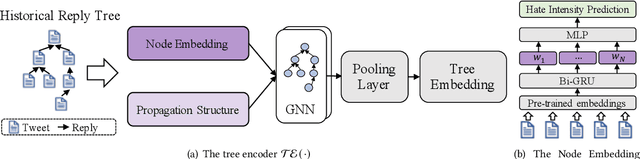
Tweets are the most concise form of communication in online social media, wherein a single tweet has the potential to make or break the discourse of the conversation. Online hate speech is more accessible than ever, and stifling its propagation is of utmost importance for social media companies and users for congenial communication. Most of the research barring a recent few has focused on classifying an individual tweet regardless of the tweet thread/context leading up to that point. One of the classical approaches to curb hate speech is to adopt a reactive strategy after the hate speech postage. The ex-post facto strategy results in neglecting subtle posts that do not show the potential to instigate hate speech on their own but may portend in the subsequent discussion ensuing in the post's replies. In this paper, we propose DRAGNET++, which aims to predict the intensity of hatred that a tweet can bring in through its reply chain in the future. It uses the semantic and propagating structure of the tweet threads to maximize the contextual information leading up to and the fall of hate intensity at each subsequent tweet. We explore three publicly available Twitter datasets -- Anti-Racism contains the reply tweets of a collection of social media discourse on racist remarks during US political and Covid-19 background; Anti-Social presents a dataset of 40 million tweets amidst the COVID-19 pandemic on anti-social behaviours; and Anti-Asian presents Twitter datasets collated based on anti-Asian behaviours during COVID-19 pandemic. All the curated datasets consist of structural graph information of the Tweet threads. We show that DRAGNET++ outperforms all the state-of-the-art baselines significantly. It beats the best baseline by an 11% margin on the Person correlation coefficient and a decrease of 25% on RMSE for the Anti-Racism dataset with a similar performance on the other two datasets.
Scalable K-FAC Training for Deep Neural Networks with Distributed Preconditioning
Jun 30, 2022

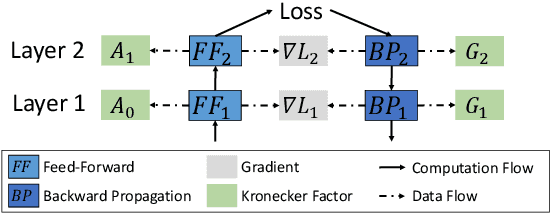
The second-order optimization methods, notably the D-KFAC (Distributed Kronecker Factored Approximate Curvature) algorithms, have gained traction on accelerating deep neural network (DNN) training on GPU clusters. However, existing D-KFAC algorithms require to compute and communicate a large volume of second-order information, i.e., Kronecker factors (KFs), before preconditioning gradients, resulting in large computation and communication overheads as well as a high memory footprint. In this paper, we propose DP-KFAC, a novel distributed preconditioning scheme that distributes the KF constructing tasks at different DNN layers to different workers. DP-KFAC not only retains the convergence property of the existing D-KFAC algorithms but also enables three benefits: reduced computation overhead in constructing KFs, no communication of KFs, and low memory footprint. Extensive experiments on a 64-GPU cluster show that DP-KFAC reduces the computation overhead by 1.55x-1.65x, the communication cost by 2.79x-3.15x, and the memory footprint by 1.14x-1.47x in each second-order update compared to the state-of-the-art D-KFAC methods.
InsMix: Towards Realistic Generative Data Augmentation for Nuclei Instance Segmentation
Jun 30, 2022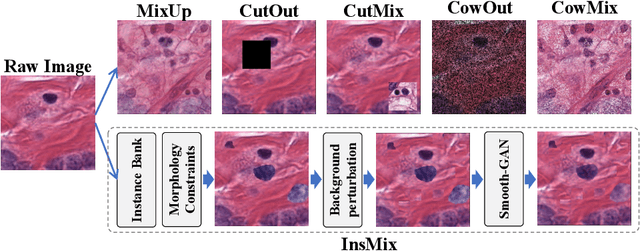
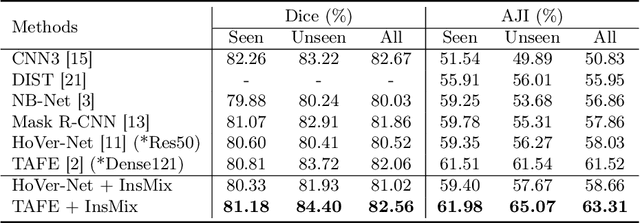
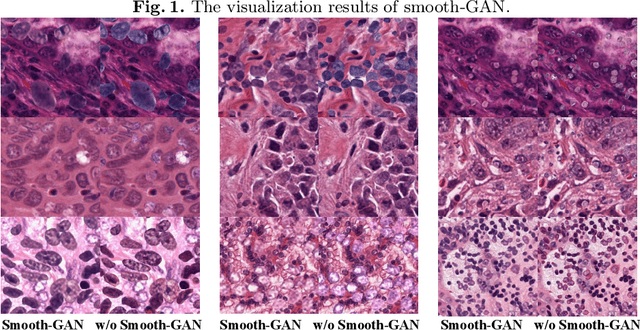
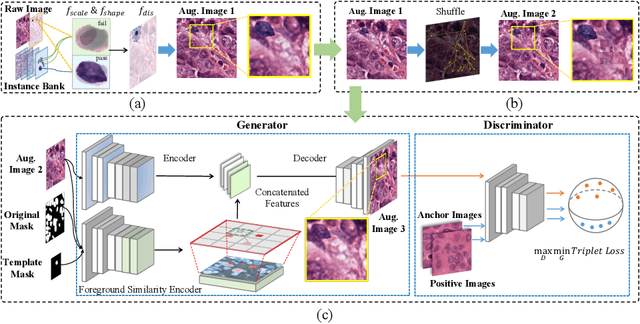
Nuclei Segmentation from histology images is a fundamental task in digital pathology analysis. However, deep-learning-based nuclei segmentation methods often suffer from limited annotations. This paper proposes a realistic data augmentation method for nuclei segmentation, named InsMix, that follows a Copy-Paste-Smooth principle and performs morphology-constrained generative instance augmentation. Specifically, we propose morphology constraints that enable the augmented images to acquire luxuriant information about nuclei while maintaining their morphology characteristics (e.g., geometry and location). To fully exploit the pixel redundancy of the background and improve the model's robustness, we further propose a background perturbation method, which randomly shuffles the background patches without disordering the original nuclei distribution. To achieve contextual consistency between original and template instances, a smooth-GAN is designed with a foreground similarity encoder (FSE) and a triplet loss. We validated the proposed method on two datasets, i.e., Kumar and CPS datasets. Experimental results demonstrate the effectiveness of each component and the superior performance achieved by our method to the state-of-the-art methods.