 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A multi-model-based deep learning framework for short text multiclass classification with the imbalanced and extremely small data set
Jun 24, 2022
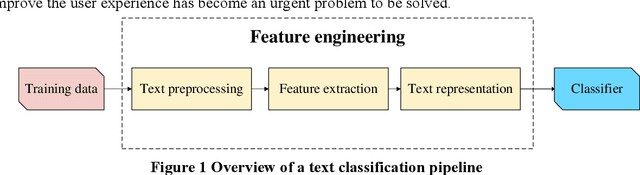
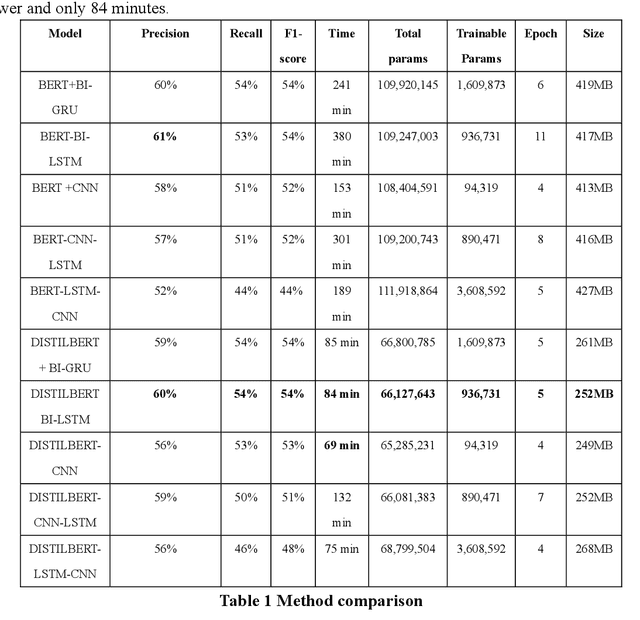
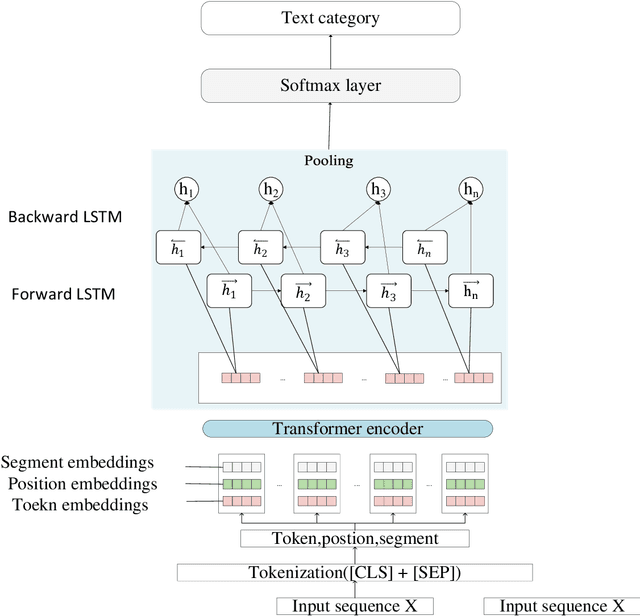

Text classification plays an important role in many practical applications. In the real world, there are extremely small datasets. Most existing methods adopt pre-trained neural network models to handle this kind of dataset. However, these methods are either difficult to deploy on mobile devices because of their large output size or cannot fully extract the deep semantic information between phrases and clauses. This paper proposes a multimodel-based deep learning framework for short-text multiclass classification with an imbalanced and extremely small data set. Our framework mainly includes five layers: The encoder layer uses DISTILBERT to obtain context-sensitive dynamic word vectors that are difficult to represent in traditional feature engineering methods. Since the transformer part of this layer is distilled, our framework is compressed. Then, we use the next two layers to extract deep semantic information. The output of the encoder layer is sent to a bidirectional LSTM network, and the feature matrix is extracted hierarchically through the LSTM at the word and sentence level to obtain the fine-grained semantic representation. After that, the max-pooling layer converts the feature matrix into a lower-dimensional matrix, preserving only the obvious features. Finally, the feature matrix is taken as the input of a fully connected softmax layer, which contains a function that can convert the predicted linear vector into the output value as the probability of the text in each classification. Extensive experiments on two public benchmarks demonstrate the effectiveness of our proposed approach on an extremely small data set. It retains the state-of-the-art baseline performance in terms of precision, recall, accuracy, and F1 score, and through the model size, training time, and convergence epoch, we can conclude that our method can be deployed faster and lighter on mobile devices.
Privacy-Preserving Face Recognition with Learnable Privacy Budgets in Frequency Domain
Jul 18, 2022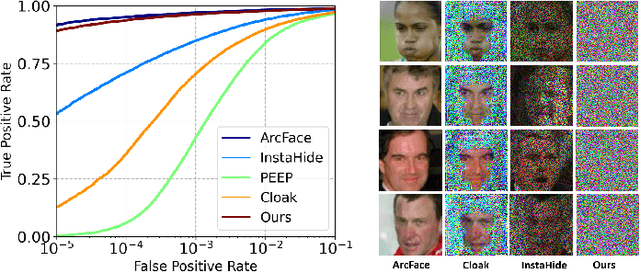

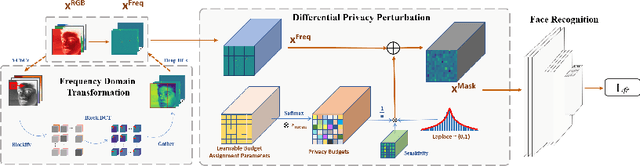
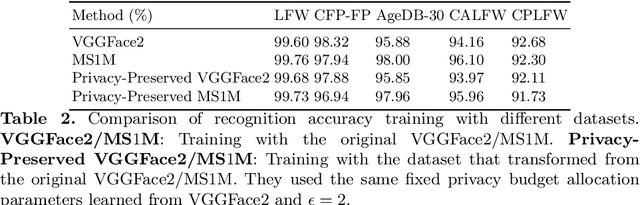
Face recognition technology has been used in many fields due to its high recognition accuracy, including the face unlocking of mobile devices, community access control systems, and city surveillance. As the current high accuracy is guaranteed by very deep network structures, facial images often need to be transmitted to third-party servers with high computational power for inference. However, facial images visually reveal the user's identity information. In this process, both untrusted service providers and malicious users can significantly increase the risk of a personal privacy breach. Current privacy-preserving approaches to face recognition are often accompanied by many side effects, such as a significant increase in inference time or a noticeable decrease in recognition accuracy. This paper proposes a privacy-preserving face recognition method using differential privacy in the frequency domain. Due to the utilization of differential privacy, it offers a guarantee of privacy in theory. Meanwhile, the loss of accuracy is very slight. This method first converts the original image to the frequency domain and removes the direct component termed DC. Then a privacy budget allocation method can be learned based on the loss of the back-end face recognition network within the differential privacy framework. Finally, it adds the corresponding noise to the frequency domain features. Our method performs very well with several classical face recognition test sets according to the extensive experiments.
Deep Parametric 3D Filters for Joint Video Denoising and Illumination Enhancement in Video Super Resolution
Jul 05, 2022

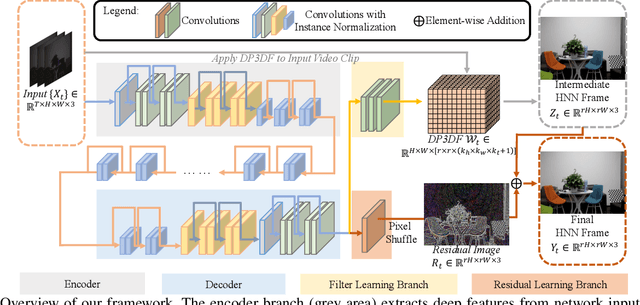
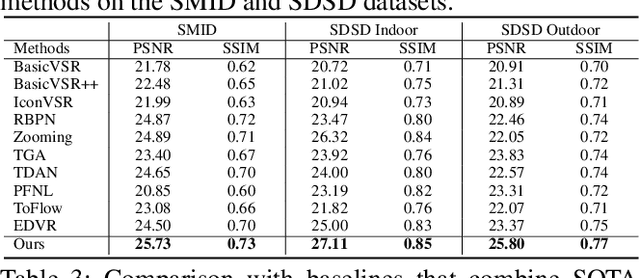
Despite the quality improvement brought by the recent methods, video super-resolution (SR) is still very challenging, especially for videos that are low-light and noisy. The current best solution is to subsequently employ best models of video SR, denoising, and illumination enhancement, but doing so often lowers the image quality, due to the inconsistency between the models. This paper presents a new parametric representation called the Deep Parametric 3D Filters (DP3DF), which incorporates local spatiotemporal information to enable simultaneous denoising, illumination enhancement, and SR efficiently in a single encoder-and-decoder network. Also, a dynamic residual frame is jointly learned with the DP3DF via a shared backbone to further boost the SR quality. We performed extensive experiments, including a large-scale user study, to show our method's effectiveness. Our method consistently surpasses the best state-of-the-art methods on all the challenging real datasets with top PSNR and user ratings, yet having a very fast run time.
Hierarchical Spherical CNNs with Lifting-based Adaptive Wavelets for Pooling and Unpooling
May 31, 2022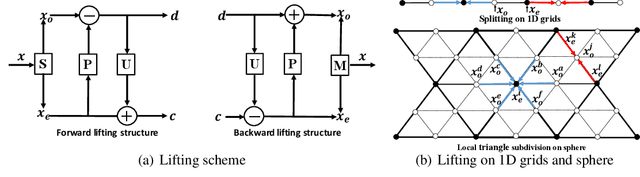
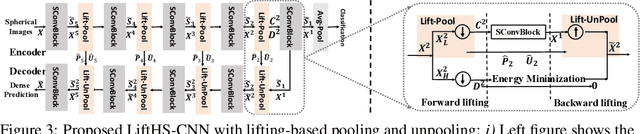


Pooling and unpooling are two essential operations in constructing hierarchical spherical convolutional neural networks (HS-CNNs) for comprehensive feature learning in the spherical domain. Most existing models employ downsampling-based pooling, which will inevitably incur information loss and cannot adapt to different spherical signals and tasks. Besides, the preserved information after pooling cannot be well restored by the subsequent unpooling to characterize the desirable features for a task. In this paper, we propose a novel framework of HS-CNNs with a lifting structure to learn adaptive spherical wavelets for pooling and unpooling, dubbed LiftHS-CNN, which ensures a more efficient hierarchical feature learning for both image- and pixel-level tasks. Specifically, adaptive spherical wavelets are learned with a lifting structure that consists of trainable lifting operators (i.e., update and predict operators). With this learnable lifting structure, we can adaptively partition a signal into two sub-bands containing low- and high-frequency components, respectively, and thus generate a better down-scaled representation for pooling by preserving more information in the low-frequency sub-band. The update and predict operators are parameterized with graph-based attention to jointly consider the signal's characteristics and the underlying geometries. We further show that particular properties are promised by the learned wavelets, ensuring the spatial-frequency localization for better exploiting the signal's correlation in both spatial and frequency domains. We then propose an unpooling operation that is invertible to the lifting-based pooling, where an inverse wavelet transform is performed by using the learned lifting operators to restore an up-scaled representation. Extensive empirical evaluations on various spherical domain tasks validate the superiority of the proposed LiftHS-CNN.
Transport-Oriented Feature Aggregation for Speaker Embedding Learning
Jun 26, 2022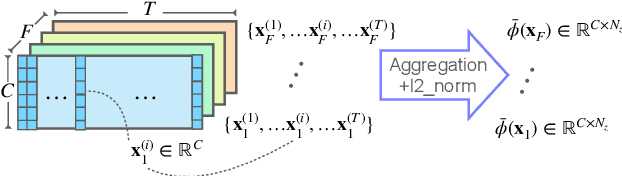

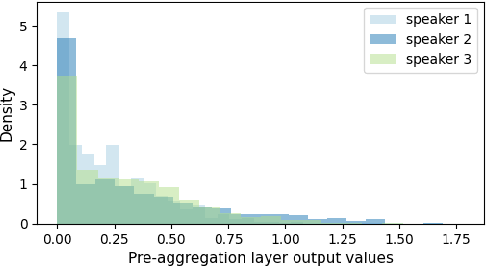
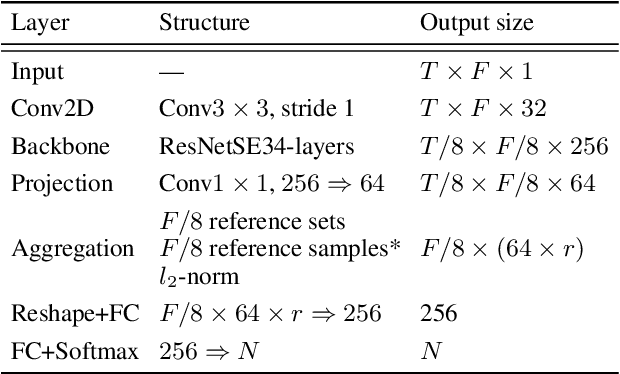
Pooling is needed to aggregate frame-level features into utterance-level representations for speaker modeling. Given the success of statistics-based pooling methods, we hypothesize that speaker characteristics are well represented in the statistical distribution over the pre-aggregation layer's output, and propose to use transport-oriented feature aggregation for deriving speaker embeddings. The aggregated representation encodes the geometric structure of the underlying feature distribution, which is expected to contain valuable speaker-specific information that may not be represented by the commonly used statistical measures like mean and variance. The original transport-oriented feature aggregation is also extended to a weighted-frame version to incorporate the attention mechanism. Experiments on speaker verification with the Voxceleb dataset show improvement over statistics pooling and its attentive variant.
Points2NeRF: Generating Neural Radiance Fields from 3D point cloud
Jun 02, 2022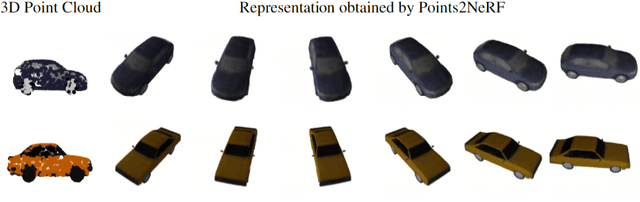



Contemporary registration devices for 3D visual information, such as LIDARs and various depth cameras, capture data as 3D point clouds. In turn, such clouds are challenging to be processed due to their size and complexity. Existing methods address this problem by fitting a mesh to the point cloud and rendering it instead. This approach, however, leads to the reduced fidelity of the resulting visualization and misses color information of the objects crucial in computer graphics applications. In this work, we propose to mitigate this challenge by representing 3D objects as Neural Radiance Fields (NeRFs). We leverage a hypernetwork paradigm and train the model to take a 3D point cloud with the associated color values and return a NeRF network's weights that reconstruct 3D objects from input 2D images. Our method provides efficient 3D object representation and offers several advantages over the existing approaches, including the ability to condition NeRFs and improved generalization beyond objects seen in training. The latter we also confirmed in the results of our empirical evaluation.
Point Cloud Semantic Segmentation using Multi Scale Sparse Convolution Neural Network
May 09, 2022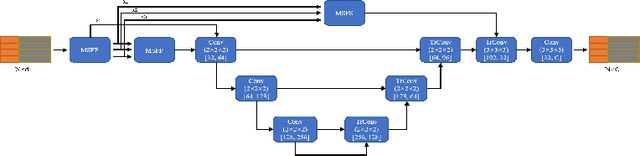
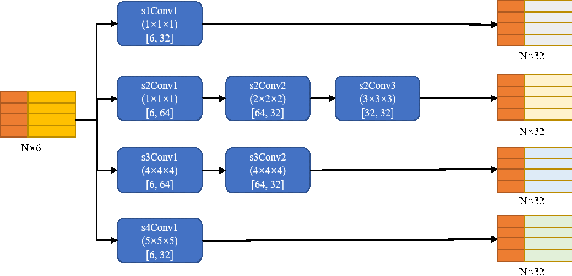
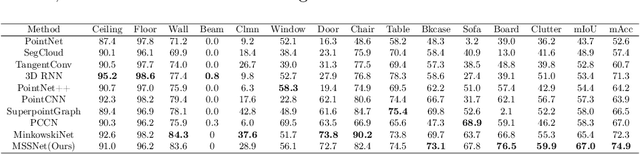
Point clouds have the characteristics of disorder, unstructured and sparseness.Aiming at the problem of the non-structural nature of point clouds, thanks to the excellent performance of convolutional neural networks in image processing, one of the solutions is to extract features from point clouds based on two-dimensional convolutional neural networks. The three-dimensional information carried in the point cloud can be converted to two-dimensional, and then processed by a two-dimensional convolutional neural network, and finally back-projected to three-dimensional.In the process of projecting 3D information to 2D and back-projection, certain information loss will inevitably be caused to the point cloud and category inconsistency will be introduced in the back-projection stage;Another solution is the voxel-based point cloud segmentation method, which divides the point cloud into small grids one by one.However, the point cloud is sparse, and the direct use of 3D convolutional neural network inevitably wastes computing resources. In this paper, we propose a feature extraction module based on multi-scale ultra-sparse convolution and a feature selection module based on channel attention, and build a point cloud segmentation network framework based on this.By introducing multi-scale sparse convolution, network could capture richer feature information based on convolution kernels of different sizes, improving the segmentation result of point cloud segmentation.
Anomaly-aware multiple instance learning for rare anemia disorder classification
Jul 04, 2022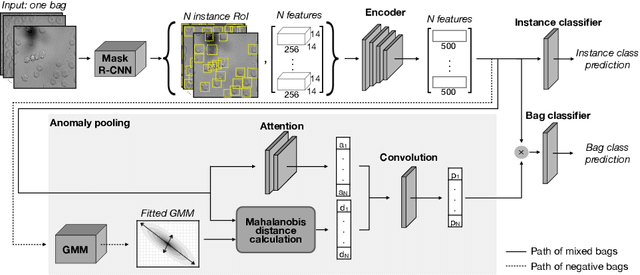

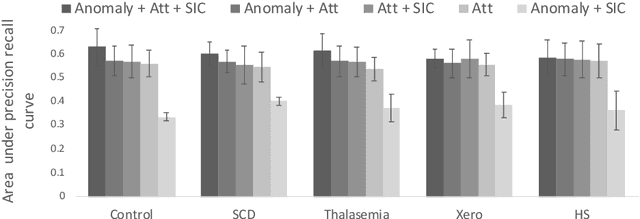
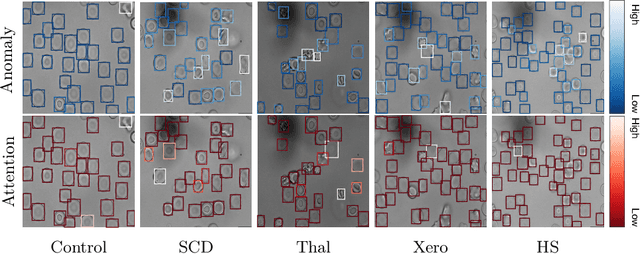
Deep learning-based classification of rare anemia disorders is challenged by the lack of training data and instance-level annotations. Multiple Instance Learning (MIL) has shown to be an effective solution, yet it suffers from low accuracy and limited explainability. Although the inclusion of attention mechanisms has addressed these issues, their effectiveness highly depends on the amount and diversity of cells in the training samples. Consequently, the poor machine learning performance on rare anemia disorder classification from blood samples remains unresolved. In this paper, we propose an interpretable pooling method for MIL to address these limitations. By benefiting from instance-level information of negative bags (i.e., homogeneous benign cells from healthy individuals), our approach increases the contribution of anomalous instances. We show that our strategy outperforms standard MIL classification algorithms and provides a meaningful explanation behind its decisions. Moreover, it can denote anomalous instances of rare blood diseases that are not seen during the training phase.
Technical Report: Assisting Backdoor Federated Learning with Whole Population Knowledge Alignment
Jul 25, 2022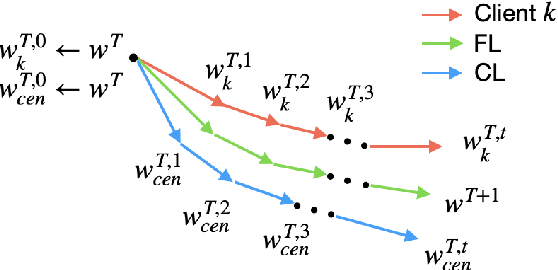

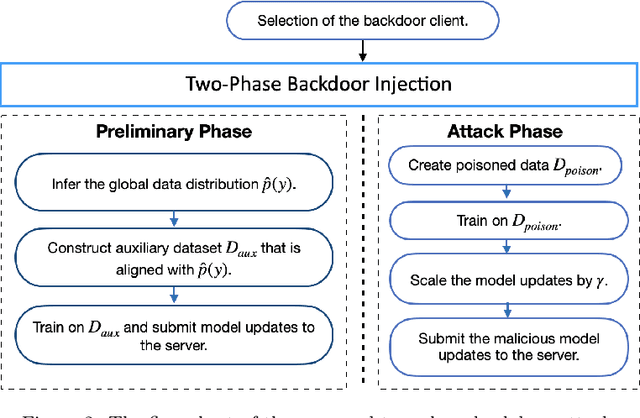
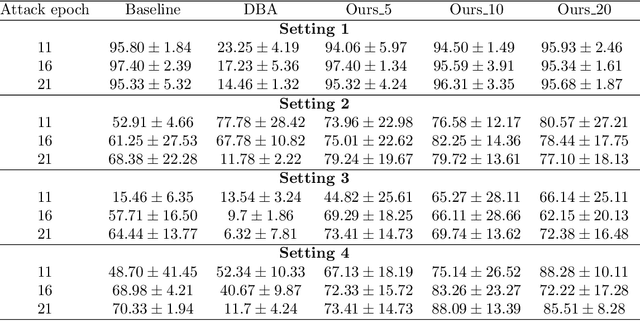
Due to the distributed nature of Federated Learning (FL), researchers have uncovered that FL is vulnerable to backdoor attacks, which aim at injecting a sub-task into the FL without corrupting the performance of the main task. Single-shot backdoor attack achieves high accuracy on both the main task and backdoor sub-task when injected at the FL model convergence. However, the early-injected single-shot backdoor attack is ineffective because: (1) the maximum backdoor effectiveness is not reached at injection because of the dilution effect from normal local updates; (2) the backdoor effect decreases quickly as the backdoor will be overwritten by the newcoming normal local updates. In this paper, we strengthen the early-injected single-shot backdoor attack utilizing FL model information leakage. We show that the FL convergence can be expedited if the client trains on a dataset that mimics the distribution and gradients of the whole population. Based on this observation, we proposed a two-phase backdoor attack, which includes a preliminary phase for the subsequent backdoor attack. In the preliminary phase, the attacker-controlled client first launches a whole population distribution inference attack and then trains on a locally crafted dataset that is aligned with both the gradient and inferred distribution. Benefiting from the preliminary phase, the later injected backdoor achieves better effectiveness as the backdoor effect will be less likely to be diluted by the normal model updates. Extensive experiments are conducted on MNIST dataset under various data heterogeneity settings to evaluate the effectiveness of the proposed backdoor attack. Results show that the proposed backdoor outperforms existing backdoor attacks in both success rate and longevity, even when defense mechanisms are in place.
ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning
Jul 18, 2022
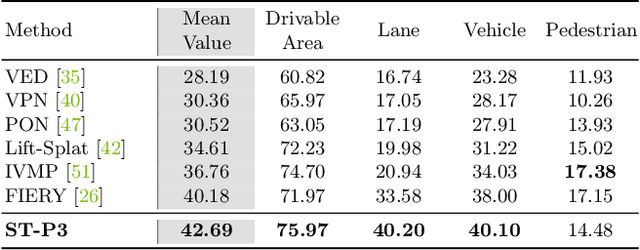
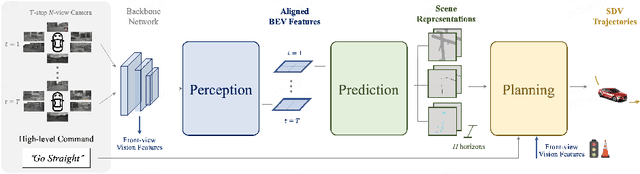
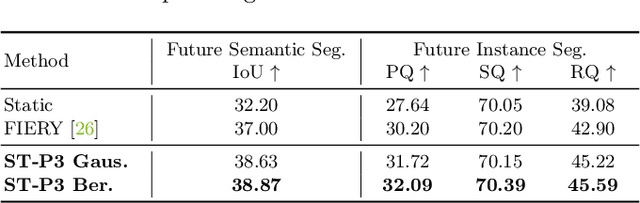
Many existing autonomous driving paradigms involve a multi-stage discrete pipeline of tasks. To better predict the control signals and enhance user safety, an end-to-end approach that benefits from joint spatial-temporal feature learning is desirable. While there are some pioneering works on LiDAR-based input or implicit design, in this paper we formulate the problem in an interpretable vision-based setting. In particular, we propose a spatial-temporal feature learning scheme towards a set of more representative features for perception, prediction and planning tasks simultaneously, which is called ST-P3. Specifically, an egocentric-aligned accumulation technique is proposed to preserve geometry information in 3D space before the bird's eye view transformation for perception; a dual pathway modeling is devised to take past motion variations into account for future prediction; a temporal-based refinement unit is introduced to compensate for recognizing vision-based elements for planning. To the best of our knowledge, we are the first to systematically investigate each part of an interpretable end-to-end vision-based autonomous driving system. We benchmark our approach against previous state-of-the-arts on both open-loop nuScenes dataset as well as closed-loop CARLA simulation. The results show the effectiveness of our method. Source code, model and protocol details are made publicly available at https://github.com/OpenPerceptionX/ST-P3.