 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Light Field Raindrop Removal via 4D Re-sampling
May 26, 2022
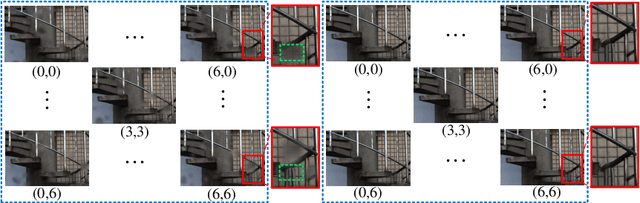


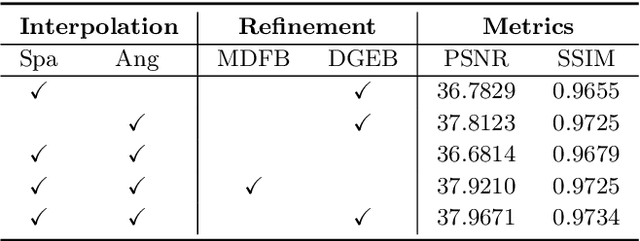
The Light Field Raindrop Removal (LFRR) aims to restore the background areas obscured by raindrops in the Light Field (LF). Compared with single image, the LF provides more abundant information by regularly and densely sampling the scene. Since raindrops have larger disparities than the background in the LF, the majority of texture details occluded by raindrops are visible in other views. In this paper, we propose a novel LFRR network by directly utilizing the complementary pixel information of raindrop-free areas in the input raindrop LF, which consists of the re-sampling module and the refinement module. Specifically, the re-sampling module generates a new LF which is less polluted by raindrops through re-sampling position predictions and the proposed 4D interpolation. The refinement module improves the restoration of the completely occluded background areas and corrects the pixel error caused by 4D interpolation. Furthermore, we carefully build the first real scene LFRR dataset for model training and validation. Experiments demonstrate that the proposed method can effectively remove raindrops and achieves state-of-the-art performance in both background restoration and view consistency maintenance.
The least-control principle for learning at equilibrium
Jul 04, 2022



Equilibrium systems are a powerful way to express neural computations. As special cases, they include models of great current interest in both neuroscience and machine learning, such as equilibrium recurrent neural networks, deep equilibrium models, or meta-learning. Here, we present a new principle for learning such systems with a temporally- and spatially-local rule. Our principle casts learning as a least-control problem, where we first introduce an optimal controller to lead the system towards a solution state, and then define learning as reducing the amount of control needed to reach such a state. We show that incorporating learning signals within a dynamics as an optimal control enables transmitting credit assignment information in previously unknown ways, avoids storing intermediate states in memory, and does not rely on infinitesimal learning signals. In practice, our principle leads to strong performance matching that of leading gradient-based learning methods when applied to an array of problems involving recurrent neural networks and meta-learning. Our results shed light on how the brain might learn and offer new ways of approaching a broad class of machine learning problems.
Depth-CUPRL: Depth-Imaged Contrastive Unsupervised Prioritized Representations in Reinforcement Learning for Mapless Navigation of Unmanned Aerial Vehicles
Jul 01, 2022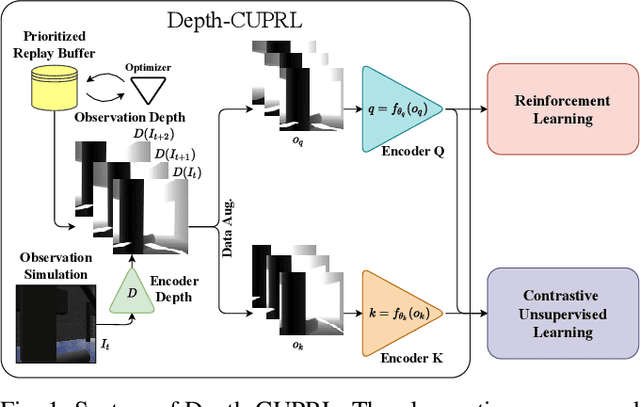
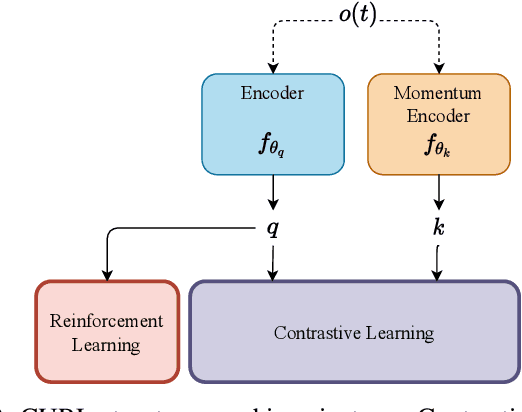
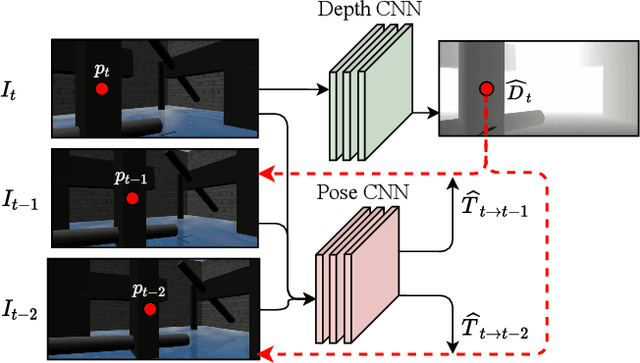
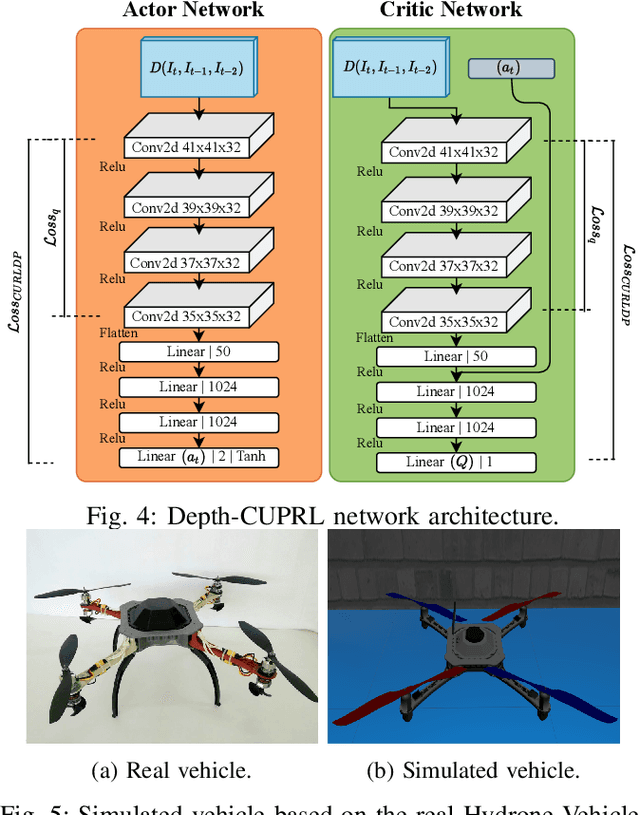
Reinforcement Learning (RL) has presented an impressive performance in video games through raw pixel imaging and continuous control tasks. However, RL performs poorly with high-dimensional observations such as raw pixel images. It is generally accepted that physical state-based RL policies such as laser sensor measurements give a more sample-efficient result than learning by pixels. This work presents a new approach that extracts information from a depth map estimation to teach an RL agent to perform the mapless navigation of Unmanned Aerial Vehicle (UAV). We propose the Depth-Imaged Contrastive Unsupervised Prioritized Representations in Reinforcement Learning(Depth-CUPRL) that estimates the depth of images with a prioritized replay memory. We used a combination of RL and Contrastive Learning to lead with the problem of RL based on images. From the analysis of the results with Unmanned Aerial Vehicles (UAVs), it is possible to conclude that our Depth-CUPRL approach is effective for the decision-making and outperforms state-of-the-art pixel-based approaches in the mapless navigation capability.
Memory-Efficient Learned Image Compression with Pruned Hyperprior Module
Jun 21, 2022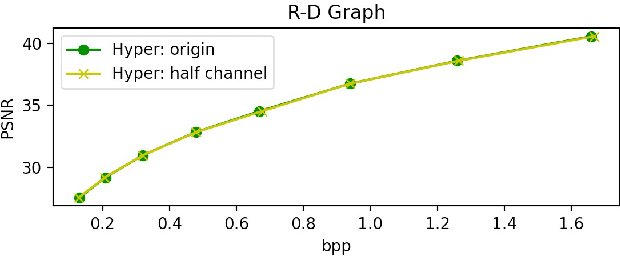

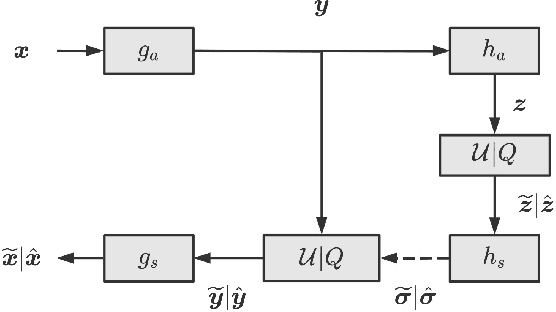
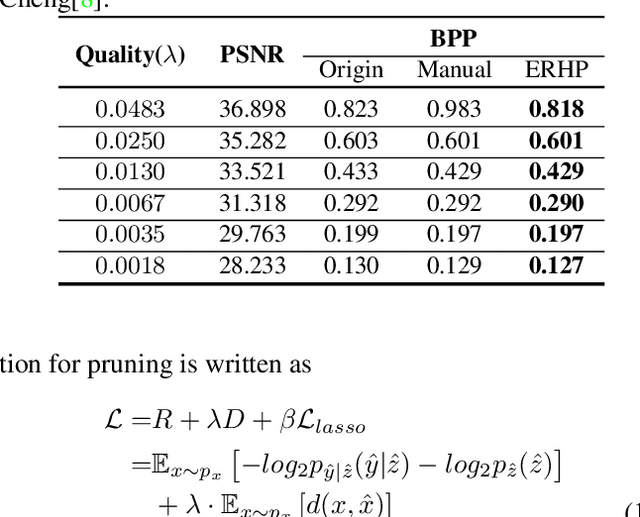
Learned Image Compression (LIC) gradually became more and more famous in these years. The hyperprior-module-based LIC models have achieved remarkable rate-distortion performance. However, the memory cost of these LIC models is too large to actually apply them to various devices, especially to portable or edge devices. The parameter scale is directly linked with memory cost. In our research, we found the hyperprior module is not only highly over-parameterized, but also its latent representation contains redundant information. Therefore, we propose a novel pruning method named ERHP in this paper to efficiently reduce the memory cost of hyperprior module, while improving the network performance. The experiments show our method is effective, reducing at least 22.6% parameters in the whole model while achieving better rate-distortion performance.
CAiRE in DialDoc21: Data Augmentation for Information-Seeking Dialogue System
Jun 07, 2021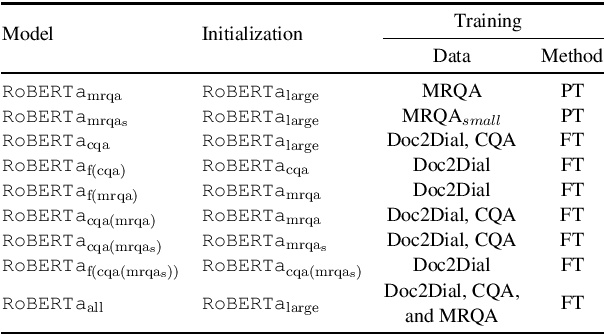
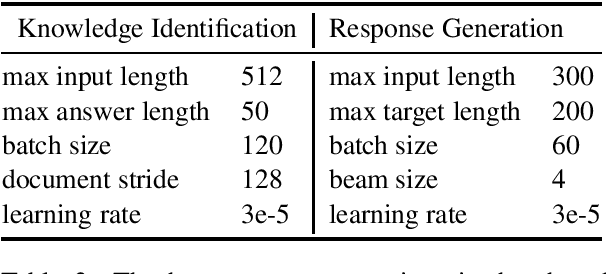
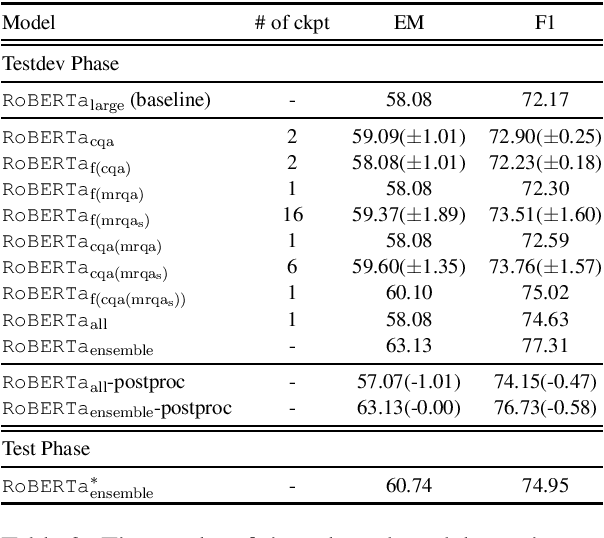
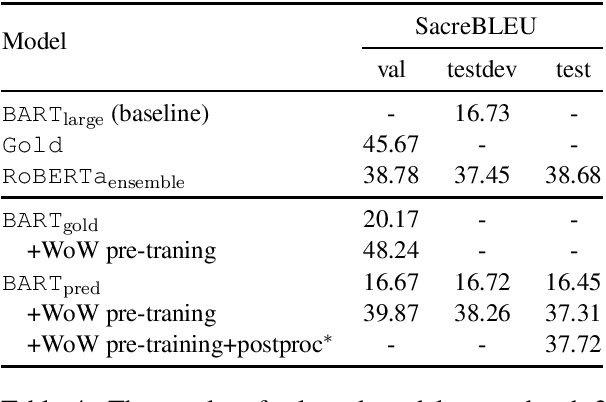
Information-seeking dialogue systems, including knowledge identification and response generation, aim to respond to users with fluent, coherent, and informative responses based on users' needs, which. To tackle this challenge, we utilize data augmentation methods and several training techniques with the pre-trained language models to learn a general pattern of the task and thus achieve promising performance. In DialDoc21 competition, our system achieved 74.95 F1 score and 60.74 Exact Match score in subtask 1, and 37.72 SacreBLEU score in subtask 2. Empirical analysis is provided to explain the effectiveness of our approaches.
Modeling Beats and Downbeats with a Time-Frequency Transformer
May 29, 2022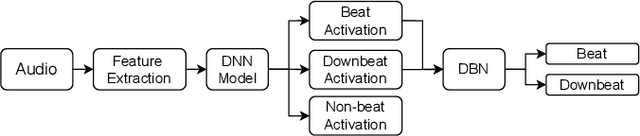
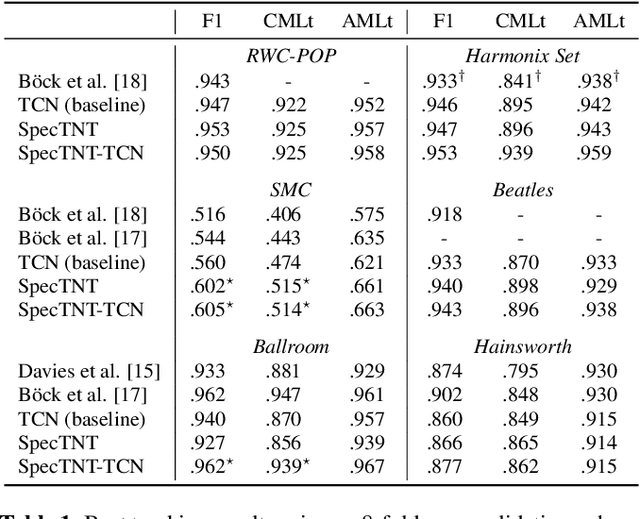
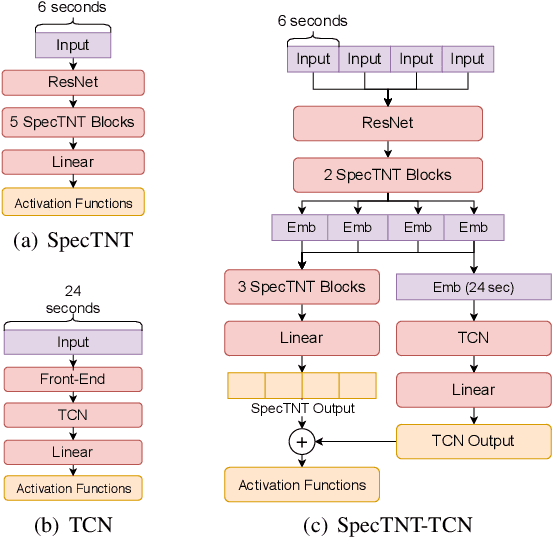
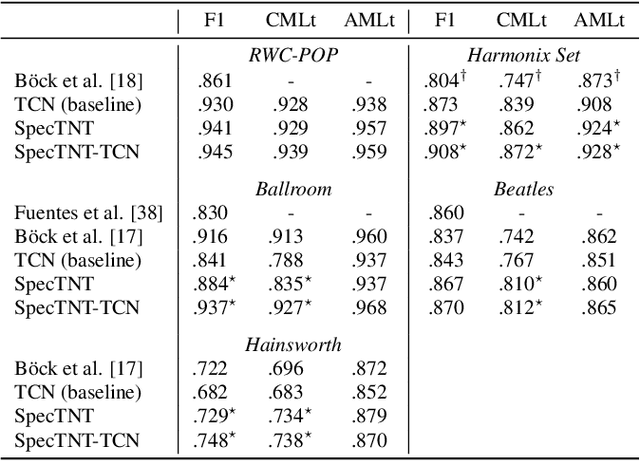
Transformer is a successful deep neural network (DNN) architecture that has shown its versatility not only in natural language processing but also in music information retrieval (MIR). In this paper, we present a novel Transformer-based approach to tackle beat and downbeat tracking. This approach employs SpecTNT (Spectral-Temporal Transformer in Transformer), a variant of Transformer that models both spectral and temporal dimensions of a time-frequency input of music audio. A SpecTNT model uses a stack of blocks, where each consists of two levels of Transformer encoders. The lower-level (or spectral) encoder handles the spectral features and enables the model to pay attention to harmonic components of each frame. Since downbeats indicate bar boundaries and are often accompanied by harmonic changes, this step may help downbeat modeling. The upper-level (or temporal) encoder aggregates useful local spectral information to pay attention to beat/downbeat positions. We also propose an architecture that combines SpecTNT with a state-of-the-art model, Temporal Convolutional Networks (TCN), to further improve the performance. Extensive experiments demonstrate that our approach can significantly outperform TCN in downbeat tracking while maintaining comparable result in beat tracking.
Enhancing Privacy against Inversion Attacks in Federated Learning by using Mixing Gradients Strategies
Apr 26, 2022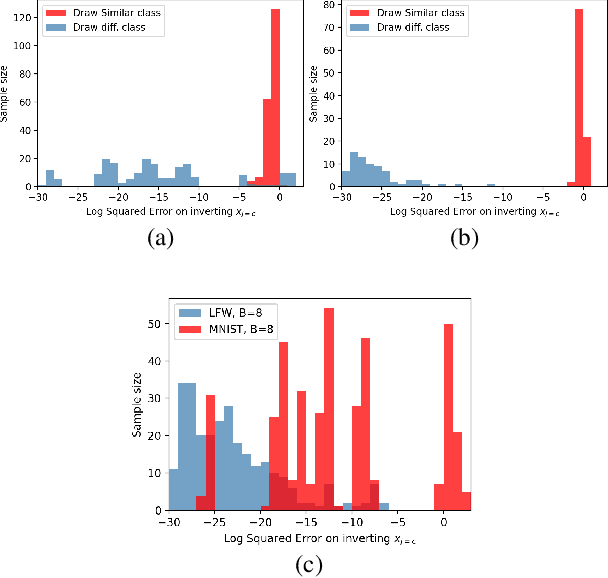

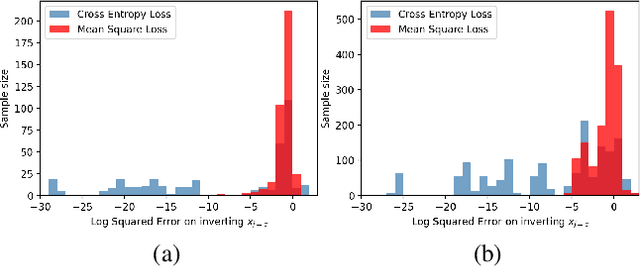
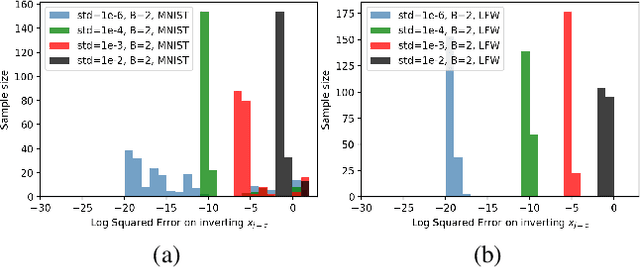
Federated learning reduces the risk of information leakage, but remains vulnerable to attacks. We investigate how several neural network design decisions can defend against gradients inversion attacks. We show that overlapping gradients provides numerical resistance to gradient inversion on the highly vulnerable dense layer. Specifically, we propose to leverage batching to maximise mixing of gradients by choosing an appropriate loss function and drawing identical labels. We show that otherwise it is possible to directly recover all vectors in a mini-batch without any numerical optimisation due to the de-mixing nature of the cross entropy loss. To accurately assess data recovery, we introduce an absolute variation distance (AVD) metric for information leakage in images, derived from total variation. In contrast to standard metrics, e.g. Mean Squared Error or Structural Similarity Index, AVD offers a continuous metric for extracting information in noisy images. Finally, our empirical results on information recovery from various inversion attacks and training performance supports our defense strategies. These strategies are also shown to be useful for deep convolutional neural networks such as LeNET for image recognition. We hope that this study will help guide the development of further strategies that achieve a trustful federation policy.
Can Language Models Capture Graph Semantics? From Graphs to Language Model and Vice-Versa
Jun 18, 2022
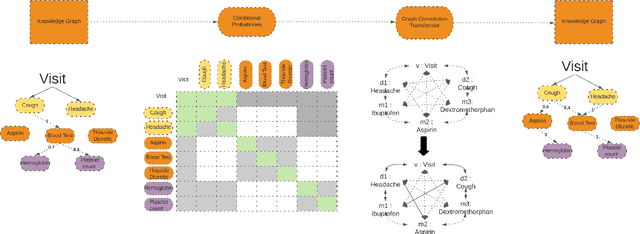
Knowledge Graphs are a great resource to capture semantic knowledge in terms of entities and relationships between the entities. However, current deep learning models takes as input distributed representations or vectors. Thus, the graph is compressed in a vectorized representation. We conduct a study to examine if the deep learning model can compress a graph and then output the same graph with most of the semantics intact. Our experiments show that Transformer models are not able to express the full semantics of the input knowledge graph. We find that this is due to the disparity between the directed, relationship and type based information contained in a Knowledge Graph and the fully connected token-token undirected graphical interpretation of the Transformer Attention matrix.
Data-aided Active User Detection with a User Activity Extraction Network for Grant-free SCMA Systems
May 22, 2022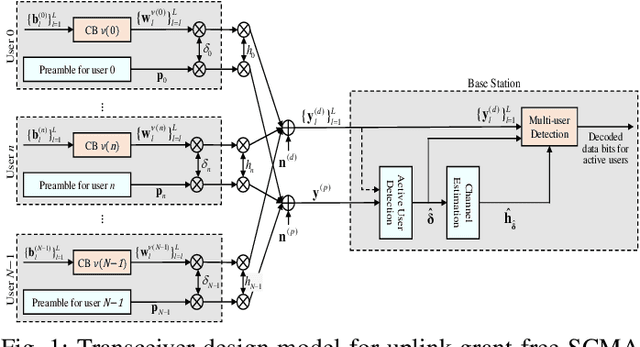
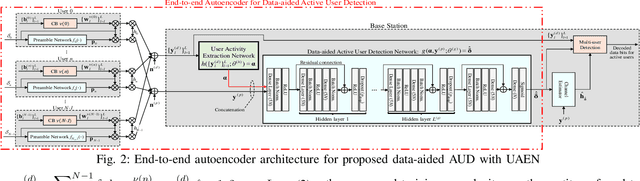
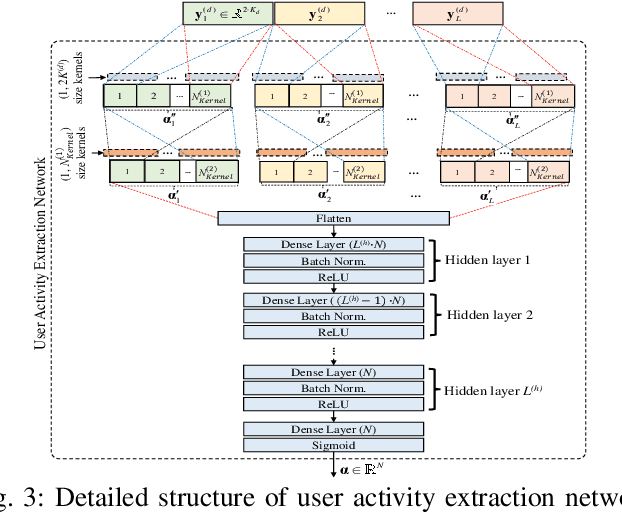
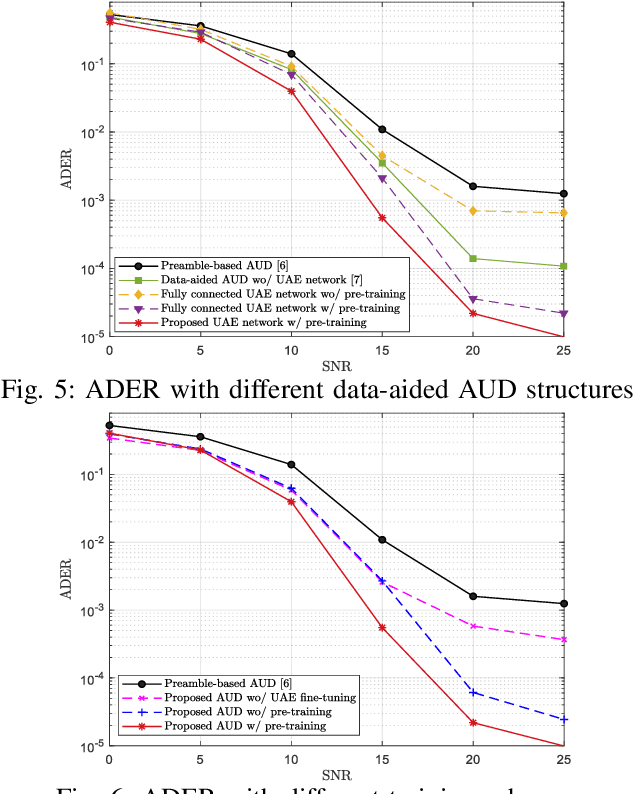
In grant-free sparse code multiple access system, joint optimization of contention resources for users and active user detection (AUD) at the receiver is a complex combinatorial problem. To this end, we propose a deep learning-based data-aided AUD scheme which extracts a priori user activity information via a novel user activity extraction network (UAEN). This is enabled by an end-to-end training of an autoencoder (AE), which simultaneously optimizes the contention resources, i.e., preamble sequences, each associated with one of the codebooks, and extraction of user activity information from both preamble and data transmission. Furthermore, we propose self-supervised pre-training scheme for the UAEN, which ensures the convergence of offline end-to-end training. Simulation results demonstrated that the proposed AUD scheme achieved 3 to 5dB gain at a target activity detection error rate of ${{10}^{-3}}$ compared to the state-of-the-art DL-based AUD schemes.
Waveform Design and Hybrid Duplex Exploiting Radar Features for Joint Communication and Sensing
Jul 07, 2022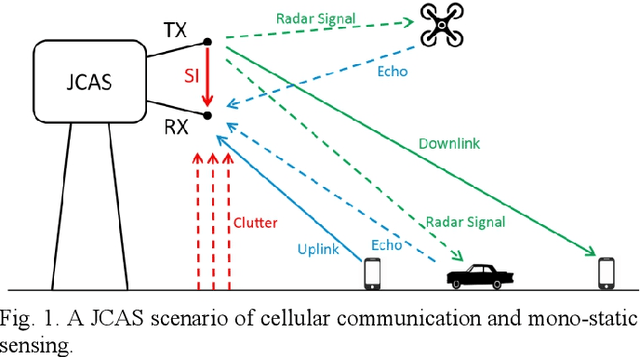
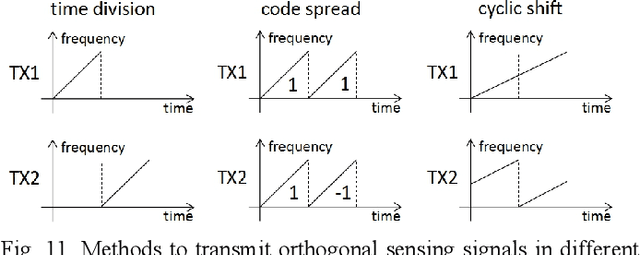
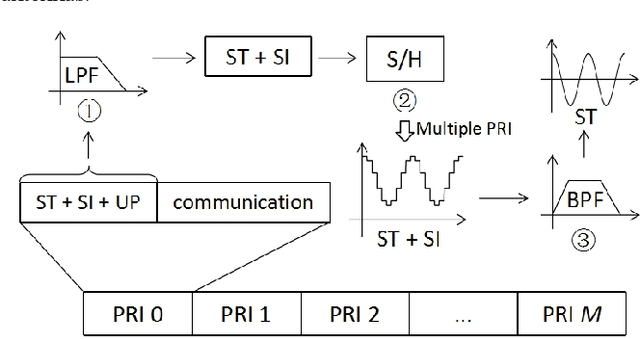
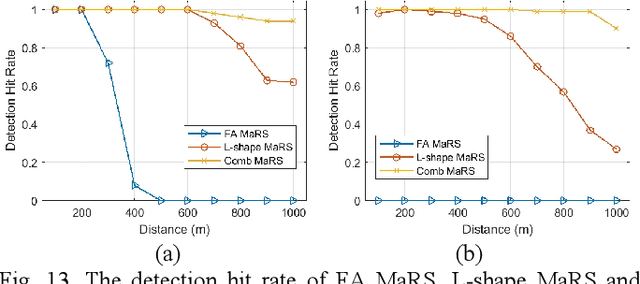
Joint communication and sensing (JCAS) is a very promising 6G technology, which attracts more and more research attention. Unlike communication, radar has many unique features in terms of waveform criteria, self-interference cancellation (SIC), aperture-dependent resolution, and virtual aperture. This paper proposes a waveform design named max-aperture radar slicing (MaRS) to gain a large time-frequency aperture, which reuses the orthogonal frequency division multiplexing (OFDM) hardware and occupies only a tiny fraction of OFDM resources. The proposed MaRS keeps the radar advantages of constant modulus, zero auto-correlation, and simple SIC. Joint space-time processing algorithms are proposed to recover the range-velocity-angle information from strong clutters. Furthermore, this paper proposes a hybrid-duplex JCAS scheme where communication is half-duplex while radar is full-duplex. In this scheme, the half-duplex communication antenna array is reused, and a small sensing-dedicated antenna array is specially designed. Using these two arrays, a large space-domain aperture is virtually formed to greatly improve the angle resolution. The numerical results show that the proposed MaRS and hybrid-duplex schemes achieve a high sensing resolution with less than 0.4% OFDM resources and gain an almost 100% hit rate for both car and UAV detection at a range up to 1 km.