 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Feature Selection Based on Orthogonal Constraints and Polygon Area
Feb 25, 2024
The goal of feature selection is to choose the optimal subset of features for a recognition task by evaluating the importance of each feature, thereby achieving effective dimensionality reduction. Currently, proposed feature selection methods often overlook the discriminative dependencies between features and labels. To address this problem, this paper introduces a novel orthogonal regression model incorporating the area of a polygon. The model can intuitively capture the discriminative dependencies between features and labels. Additionally, this paper employs a hybrid non-monotone linear search method to efficiently tackle the non-convex optimization challenge posed by orthogonal constraints. Experimental results demonstrate that our approach not only effectively captures discriminative dependency information but also surpasses traditional methods in reducing feature dimensions and enhancing classification performance.
Bootstrapping Cognitive Agents with a Large Language Model
Feb 25, 2024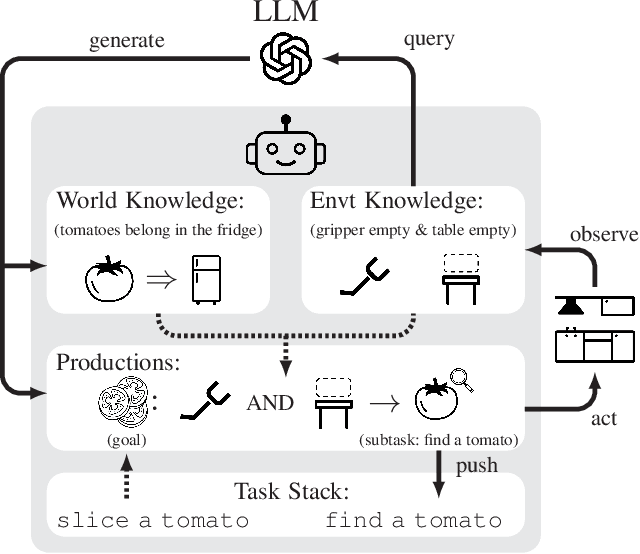
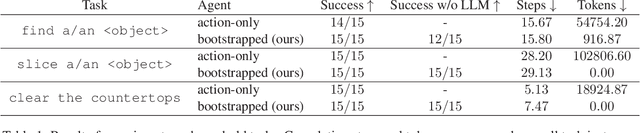
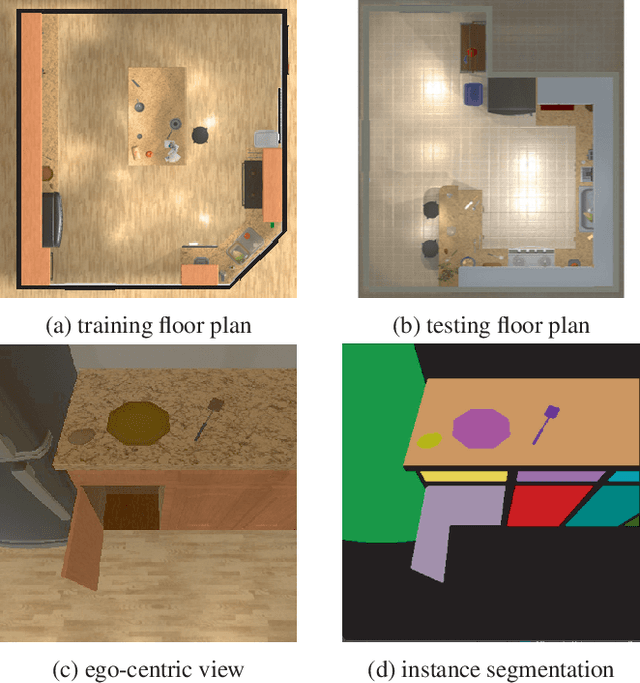
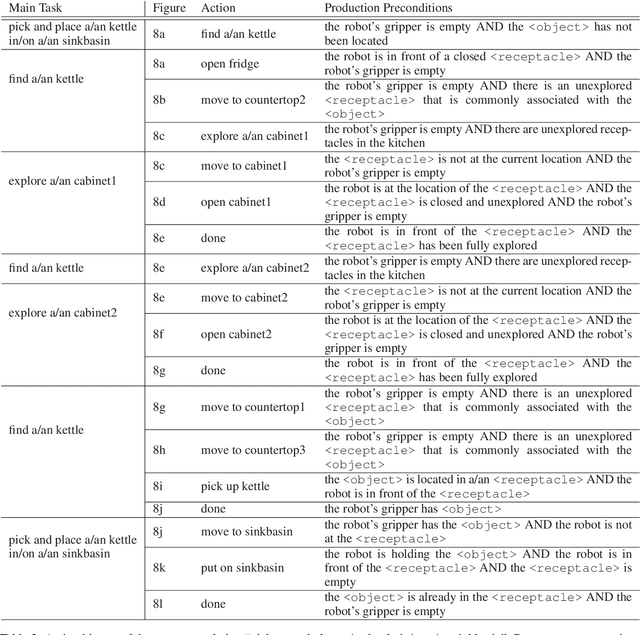
Large language models contain noisy general knowledge of the world, yet are hard to train or fine-tune. On the other hand cognitive architectures have excellent interpretability and are flexible to update but require a lot of manual work to instantiate. In this work, we combine the best of both worlds: bootstrapping a cognitive-based model with the noisy knowledge encoded in large language models. Through an embodied agent doing kitchen tasks, we show that our proposed framework yields better efficiency compared to an agent based entirely on large language models. Our experiments indicate that large language models are a good source of information for cognitive architectures, and the cognitive architecture in turn can verify and update the knowledge of large language models to a specific domain.
SDR-Former: A Siamese Dual-Resolution Transformer for Liver Lesion Classification Using 3D Multi-Phase Imaging
Feb 27, 2024Automated classification of liver lesions in multi-phase CT and MR scans is of clinical significance but challenging. This study proposes a novel Siamese Dual-Resolution Transformer (SDR-Former) framework, specifically designed for liver lesion classification in 3D multi-phase CT and MR imaging with varying phase counts. The proposed SDR-Former utilizes a streamlined Siamese Neural Network (SNN) to process multi-phase imaging inputs, possessing robust feature representations while maintaining computational efficiency. The weight-sharing feature of the SNN is further enriched by a hybrid Dual-Resolution Transformer (DR-Former), comprising a 3D Convolutional Neural Network (CNN) and a tailored 3D Transformer for processing high- and low-resolution images, respectively. This hybrid sub-architecture excels in capturing detailed local features and understanding global contextual information, thereby, boosting the SNN's feature extraction capabilities. Additionally, a novel Adaptive Phase Selection Module (APSM) is introduced, promoting phase-specific intercommunication and dynamically adjusting each phase's influence on the diagnostic outcome. The proposed SDR-Former framework has been validated through comprehensive experiments on two clinical datasets: a three-phase CT dataset and an eight-phase MR dataset. The experimental results affirm the efficacy of the proposed framework. To support the scientific community, we are releasing our extensive multi-phase MR dataset for liver lesion analysis to the public. This pioneering dataset, being the first publicly available multi-phase MR dataset in this field, also underpins the MICCAI LLD-MMRI Challenge. The dataset is accessible at:https://bit.ly/3IyYlgN.
Determinants of LLM-assisted Decision-Making
Feb 27, 2024Decision-making is a fundamental capability in everyday life. Large Language Models (LLMs) provide multifaceted support in enhancing human decision-making processes. However, understanding the influencing factors of LLM-assisted decision-making is crucial for enabling individuals to utilize LLM-provided advantages and minimize associated risks in order to make more informed and better decisions. This study presents the results of a comprehensive literature analysis, providing a structural overview and detailed analysis of determinants impacting decision-making with LLM support. In particular, we explore the effects of technological aspects of LLMs, including transparency and prompt engineering, psychological factors such as emotions and decision-making styles, as well as decision-specific determinants such as task difficulty and accountability. In addition, the impact of the determinants on the decision-making process is illustrated via multiple application scenarios. Drawing from our analysis, we develop a dependency framework that systematizes possible interactions in terms of reciprocal interdependencies between these determinants. Our research reveals that, due to the multifaceted interactions with various determinants, factors such as trust in or reliance on LLMs, the user's mental model, and the characteristics of information processing are identified as significant aspects influencing LLM-assisted decision-making processes. Our findings can be seen as crucial for improving decision quality in human-AI collaboration, empowering both users and organizations, and designing more effective LLM interfaces. Additionally, our work provides a foundation for future empirical investigations on the determinants of decision-making assisted by LLMs.
PLReMix: Combating Noisy Labels with Pseudo-Label Relaxed Contrastive Representation Learning
Feb 27, 2024Recently, the application of Contrastive Representation Learning (CRL) in learning with noisy labels (LNL) has shown promising advancements due to its remarkable ability to learn well-distributed representations for better distinguishing noisy labels. However, CRL is mainly used as a pre-training technique, leading to a complicated multi-stage training pipeline. We also observed that trivially combining CRL with supervised LNL methods decreases performance. Using different images from the same class as negative pairs in CRL creates optimization conflicts between CRL and the supervised loss. To address these two issues, we propose an end-to-end PLReMix framework that avoids the complicated pipeline by introducing a Pseudo-Label Relaxed (PLR) contrastive loss to alleviate the conflicts between losses. This PLR loss constructs a reliable negative set of each sample by filtering out its inappropriate negative pairs that overlap at the top k indices of prediction probabilities, leading to more compact semantic clusters than vanilla CRL. Furthermore, a two-dimensional Gaussian Mixture Model (GMM) is adopted to distinguish clean and noisy samples by leveraging semantic information and model outputs simultaneously, which is expanded on the previously widely used one-dimensional form. The PLR loss and a semi-supervised loss are simultaneously applied to train on the GMM divided clean and noisy samples. Experiments on multiple benchmark datasets demonstrate the effectiveness of the proposed method. Our proposed PLR loss is scalable, which can be easily integrated into other LNL methods and boost their performance. Codes will be available.
SpeechGPT-Gen: Scaling Chain-of-Information Speech Generation
Jan 25, 2024Benefiting from effective speech modeling, current Speech Large Language Models (SLLMs) have demonstrated exceptional capabilities in in-context speech generation and efficient generalization to unseen speakers. However, the prevailing information modeling process is encumbered by certain redundancies, leading to inefficiencies in speech generation. We propose Chain-of-Information Generation (CoIG), a method for decoupling semantic and perceptual information in large-scale speech generation. Building on this, we develop SpeechGPT-Gen, an 8-billion-parameter SLLM efficient in semantic and perceptual information modeling. It comprises an autoregressive model based on LLM for semantic information modeling and a non-autoregressive model employing flow matching for perceptual information modeling. Additionally, we introduce the novel approach of infusing semantic information into the prior distribution to enhance the efficiency of flow matching. Extensive experimental results demonstrate that SpeechGPT-Gen markedly excels in zero-shot text-to-speech, zero-shot voice conversion, and speech-to-speech dialogue, underscoring CoIG's remarkable proficiency in capturing and modeling speech's semantic and perceptual dimensions. Code and models are available at https://github.com/0nutation/SpeechGPT.
GraphEdit: Large Language Models for Graph Structure Learning
Feb 23, 2024Graph Structure Learning (GSL) focuses on capturing intrinsic dependencies and interactions among nodes in graph-structured data by generating novel graph structures. Graph Neural Networks (GNNs) have emerged as promising GSL solutions, utilizing recursive message passing to encode node-wise inter-dependencies. However, many existing GSL methods heavily depend on explicit graph structural information as supervision signals, leaving them susceptible to challenges such as data noise and sparsity. In this work, we propose GraphEdit, an approach that leverages large language models (LLMs) to learn complex node relationships in graph-structured data. By enhancing the reasoning capabilities of LLMs through instruction-tuning over graph structures, we aim to overcome the limitations associated with explicit graph structural information and enhance the reliability of graph structure learning. Our approach not only effectively denoises noisy connections but also identifies node-wise dependencies from a global perspective, providing a comprehensive understanding of the graph structure. We conduct extensive experiments on multiple benchmark datasets to demonstrate the effectiveness and robustness of GraphEdit across various settings. We have made our model implementation available at: https://github.com/HKUDS/GraphEdit.
A Feature Matching Method Based on Multi-Level Refinement Strategy
Feb 25, 2024Feature matching is a fundamental and crucial process in visual SLAM, and precision has always been a challenging issue in feature matching. In this paper, based on a multi-level fine matching strategy, we propose a new feature matching method called KTGP-ORB. This method utilizes the similarity of local appearance in the Hamming space generated by feature descriptors to establish initial correspondences. It combines the constraint of local image motion smoothness, uses the GMS algorithm to enhance the accuracy of initial matches, and finally employs the PROSAC algorithm to optimize matches, achieving precise matching based on global grayscale information in Euclidean space. Experimental results demonstrate that the KTGP-ORB method reduces the error by an average of 29.92% compared to the ORB algorithm in complex scenes with illumination variations and blur.
Optimistic Thompson Sampling for No-Regret Learning in Unknown Games
Feb 25, 2024This work tackles the complexities of multi-player scenarios in \emph{unknown games}, where the primary challenge lies in navigating the uncertainty of the environment through bandit feedback alongside strategic decision-making. We introduce Thompson Sampling (TS)-based algorithms that exploit the information of opponents' actions and reward structures, leading to a substantial reduction in experimental budgets -- achieving over tenfold improvements compared to conventional approaches. Notably, our algorithms demonstrate that, given specific reward structures, the regret bound depends logarithmically on the total action space, significantly alleviating the curse of multi-player. Furthermore, we unveil the \emph{Optimism-then-NoRegret} (OTN) framework, a pioneering methodology that seamlessly incorporates our advancements with established algorithms, showcasing its utility in practical scenarios such as traffic routing and radar sensing in the real world.
On Performance of RIS-Aided Fluid Antenna Systems
Feb 25, 2024This letter studies the performance of reconfigurable intelligent surface (RIS)-aided communications for a fluid antenna system (FAS) enabled receiver. Specifically, a fixed singleantenna base station (BS) transmits information through a RIS to a mobile user (MU) which is equipped with a planar fluid antenna in the absence of a direct link.We first analyze the spatial correlation structures among the positions (or ports) in the planar FAS, and then derive the joint distribution of the equivalent channel gain at the user by exploiting the central limit theorem. Furthermore, we obtain compact analytical expressions for the outage probability (OP) and delay outage rate (DOR). Numerical results illustrate that using FAS with only one activated port into the RIS-aided communication network can greatly enhance the performance, when compared to traditional antenna systems (TAS).