 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Near-Optimal Primal-Dual Method for Off-Policy Learning in CMDP
Jul 13, 2022
As an important framework for safe Reinforcement Learning, the Constrained Markov Decision Process (CMDP) has been extensively studied in the recent literature. However, despite the rich results under various on-policy learning settings, there still lacks some essential understanding of the offline CMDP problems, in terms of both the algorithm design and the information theoretic sample complexity lower bound. In this paper, we focus on solving the CMDP problems where only offline data are available. By adopting the concept of the single-policy concentrability coefficient $C^*$, we establish an $\Omega\left(\frac{\min\left\{|\mathcal{S}||\mathcal{A}|,|\mathcal{S}|+I\right\} C^*}{(1-\gamma)^3\epsilon^2}\right)$ sample complexity lower bound for the offline CMDP problem, where $I$ stands for the number of constraints. By introducing a simple but novel deviation control mechanism, we propose a near-optimal primal-dual learning algorithm called DPDL. This algorithm provably guarantees zero constraint violation and its sample complexity matches the above lower bound except for an $\tilde{\mathcal{O}}((1-\gamma)^{-1})$ factor. Comprehensive discussion on how to deal with the unknown constant $C^*$ and the potential asynchronous structure on the offline dataset are also included.
VisFIS: Visual Feature Importance Supervision with Right-for-the-Right-Reason Objectives
Jun 22, 2022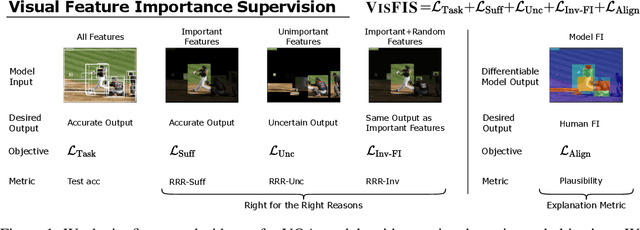
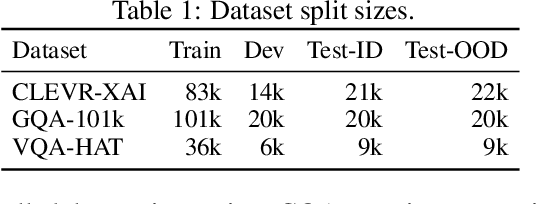
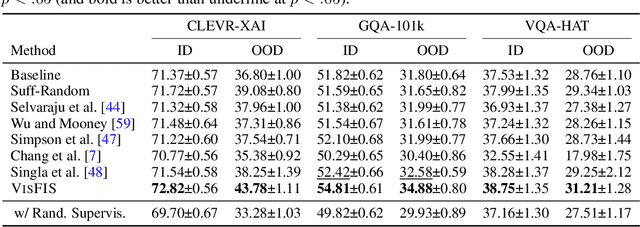
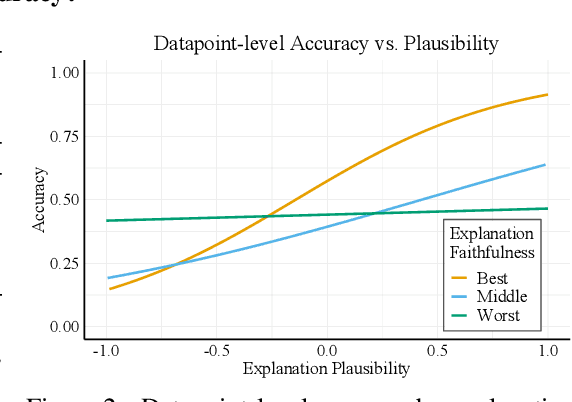
Many past works aim to improve visual reasoning in models by supervising feature importance (estimated by model explanation techniques) with human annotations such as highlights of important image regions. However, recent work has shown that performance gains from feature importance (FI) supervision for Visual Question Answering (VQA) tasks persist even with random supervision, suggesting that these methods do not meaningfully align model FI with human FI. In this paper, we show that model FI supervision can meaningfully improve VQA model accuracy as well as performance on several Right-for-the-Right-Reason (RRR) metrics by optimizing for four key model objectives: (1) accurate predictions given limited but sufficient information (Sufficiency); (2) max-entropy predictions given no important information (Uncertainty); (3) invariance of predictions to changes in unimportant features (Invariance); and (4) alignment between model FI explanations and human FI explanations (Plausibility). Our best performing method, Visual Feature Importance Supervision (VisFIS), outperforms strong baselines on benchmark VQA datasets in terms of both in-distribution and out-of-distribution accuracy. While past work suggests that the mechanism for improved accuracy is through improved explanation plausibility, we show that this relationship depends crucially on explanation faithfulness (whether explanations truly represent the model's internal reasoning). Predictions are more accurate when explanations are plausible and faithful, and not when they are plausible but not faithful. Lastly, we show that, surprisingly, RRR metrics are not predictive of out-of-distribution model accuracy when controlling for a model's in-distribution accuracy, which calls into question the value of these metrics for evaluating model reasoning. All supporting code is available at https://github.com/zfying/visfis
Eliminating Gradient Conflict in Reference-based Line-Art Colorization
Jul 16, 2022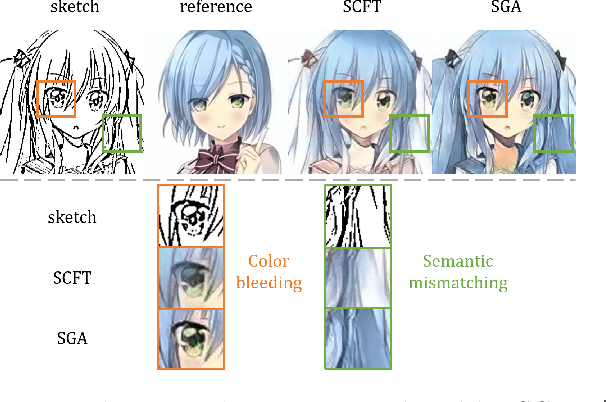
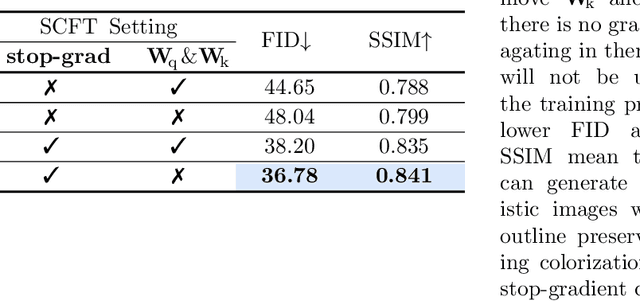
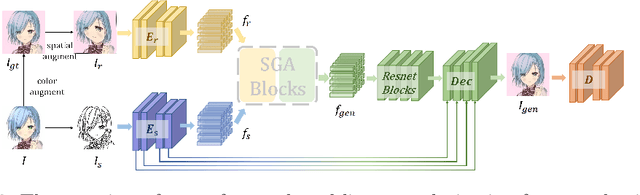
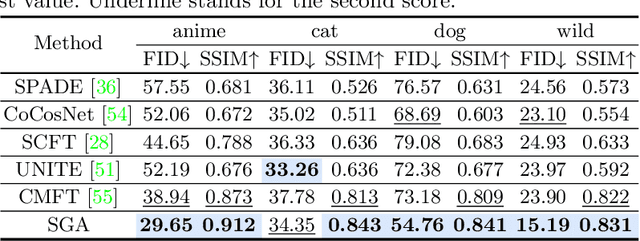
Reference-based line-art colorization is a challenging task in computer vision. The color, texture, and shading are rendered based on an abstract sketch, which heavily relies on the precise long-range dependency modeling between the sketch and reference. Popular techniques to bridge the cross-modal information and model the long-range dependency employ the attention mechanism. However, in the context of reference-based line-art colorization, several techniques would intensify the existing training difficulty of attention, for instance, self-supervised training protocol and GAN-based losses. To understand the instability in training, we detect the gradient flow of attention and observe gradient conflict among attention branches. This phenomenon motivates us to alleviate the gradient issue by preserving the dominant gradient branch while removing the conflict ones. We propose a novel attention mechanism using this training strategy, Stop-Gradient Attention (SGA), outperforming the attention baseline by a large margin with better training stability. Compared with state-of-the-art modules in line-art colorization, our approach demonstrates significant improvements in Fr\'echet Inception Distance (FID, up to 27.21%) and structural similarity index measure (SSIM, up to 25.67%) on several benchmarks. The code of SGA is available at https://github.com/kunkun0w0/SGA .
SC-Transformer++: Structured Context Transformer for Generic Event Boundary Detection
Jun 25, 2022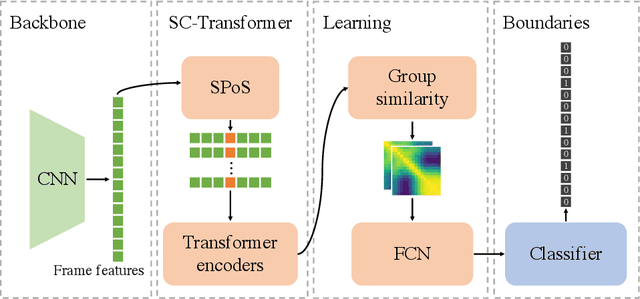
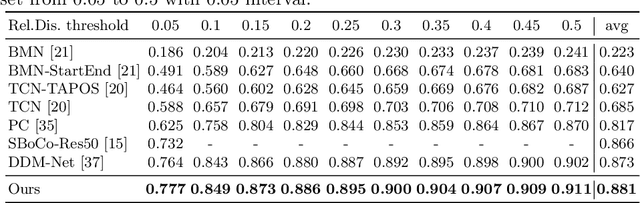
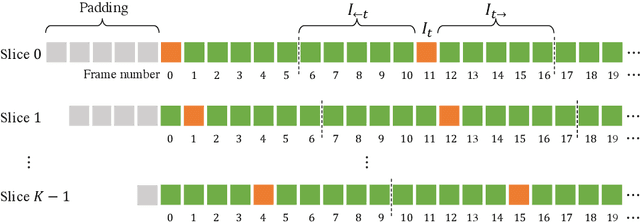
This report presents the algorithm used in the submission of Generic Event Boundary Detection (GEBD) Challenge at CVPR 2022. In this work, we improve the existing Structured Context Transformer (SC-Transformer) method for GEBD. Specifically, a transformer decoder module is added after transformer encoders to extract high quality frame features. The final classification is performed jointly on the results of the original binary classifier and a newly introduced multi-class classifier branch. To enrich motion information, optical flow is introduced as a new modality. Finally, model ensemble is used to further boost performance. The proposed method achieves 86.49% F1 score on Kinetics-GEBD test set. which improves 2.86% F1 score compared to the previous SOTA method.
CPrune: Compiler-Informed Model Pruning for Efficient Target-Aware DNN Execution
Jul 04, 2022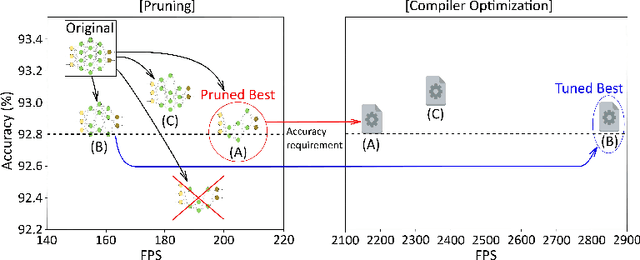
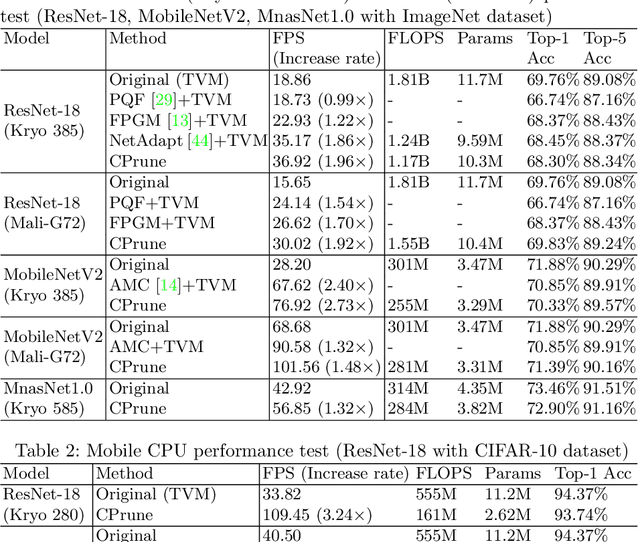
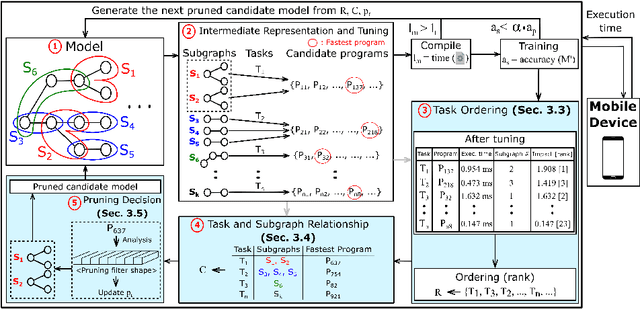
Mobile devices run deep learning models for various purposes, such as image classification and speech recognition. Due to the resource constraints of mobile devices, researchers have focused on either making a lightweight deep neural network (DNN) model using model pruning or generating an efficient code using compiler optimization. Surprisingly, we found that the straightforward integration between model compression and compiler auto-tuning often does not produce the most efficient model for a target device. We propose CPrune, a compiler-informed model pruning for efficient target-aware DNN execution to support an application with a required target accuracy. CPrune makes a lightweight DNN model through informed pruning based on the structural information of subgraphs built during the compiler tuning process. Our experimental results show that CPrune increases the DNN execution speed up to 2.73x compared to the state-of-the-art TVM auto-tune while satisfying the accuracy requirement.
Stability of Weighted Majority Voting under Estimated Weights
Jul 13, 2022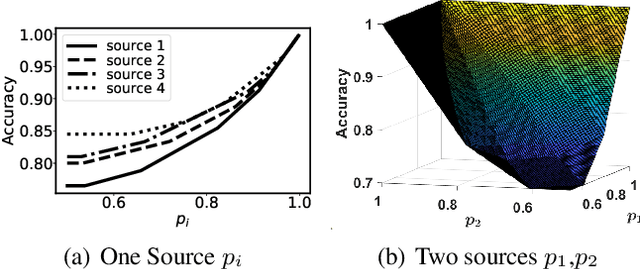
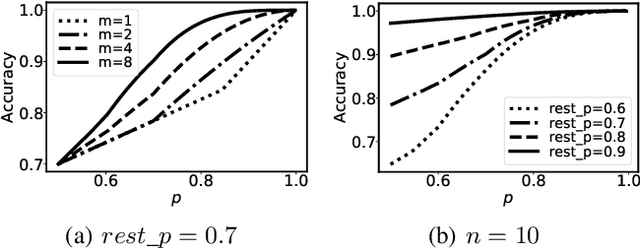
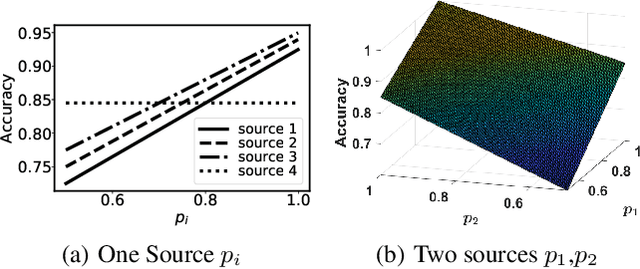
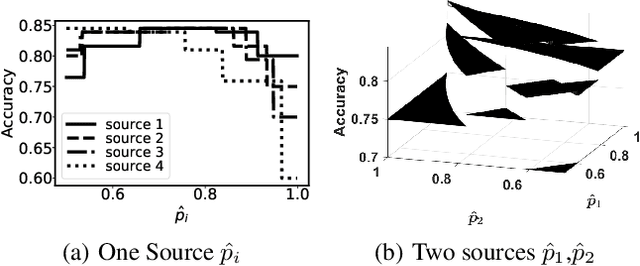
Weighted Majority Voting (WMV) is a well-known optimal decision rule for collective decision making, given the probability of sources to provide accurate information (trustworthiness). However, in reality, the trustworthiness is not a known quantity to the decision maker - they have to rely on an estimate called trust. A (machine learning) algorithm that computes trust is called unbiased when it has the property that it does not systematically overestimate or underestimate the trustworthiness. To formally analyse the uncertainty to the decision process, we introduce and analyse two important properties of such unbiased trust values: stability of correctness and stability of optimality. Stability of correctness means that the decision accuracy that the decision maker believes they achieved is equal to the actual accuracy. We prove stability of correctness holds. Stability of optimality means that the decisions made based on trust, are equally good as they would have been if they were based on trustworthiness. Stability of optimality does not hold. We analyse the difference between the two, and bounds thereon. We also present an overview of how sensitive decision correctness is to changes in trust and trustworthiness.
Controllable and Lossless Non-Autoregressive End-to-End Text-to-Speech
Jul 13, 2022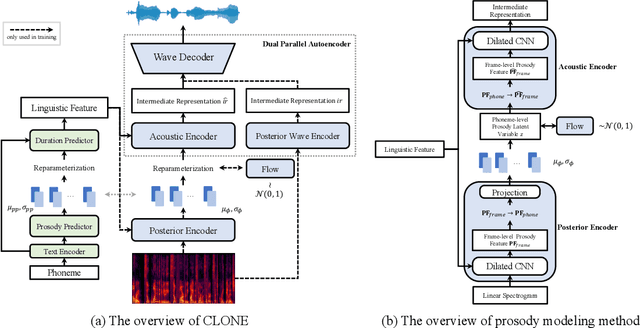
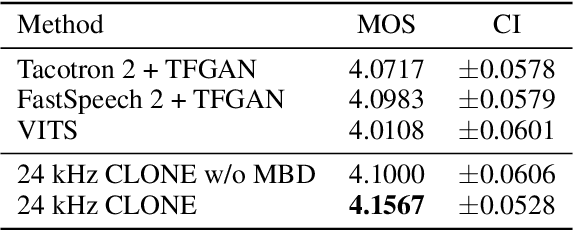
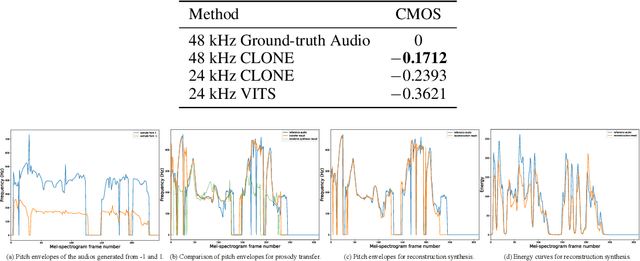

Some recent studies have demonstrated the feasibility of single-stage neural text-to-speech, which does not need to generate mel-spectrograms but generates the raw waveforms directly from the text. Single-stage text-to-speech often faces two problems: a) the one-to-many mapping problem due to multiple speech variations and b) insufficiency of high frequency reconstruction due to the lack of supervision of ground-truth acoustic features during training. To solve the a) problem and generate more expressive speech, we propose a novel phoneme-level prosody modeling method based on a variational autoencoder with normalizing flows to model underlying prosodic information in speech. We also use the prosody predictor to support end-to-end expressive speech synthesis. Furthermore, we propose the dual parallel autoencoder to introduce supervision of the ground-truth acoustic features during training to solve the b) problem enabling our model to generate high-quality speech. We compare the synthesis quality with state-of-the-art text-to-speech systems on an internal expressive English dataset. Both qualitative and quantitative evaluations demonstrate the superiority and robustness of our method for lossless speech generation while also showing a strong capability in prosody modeling.
Teachers in concordance for pseudo-labeling of 3D sequential data
Jul 13, 2022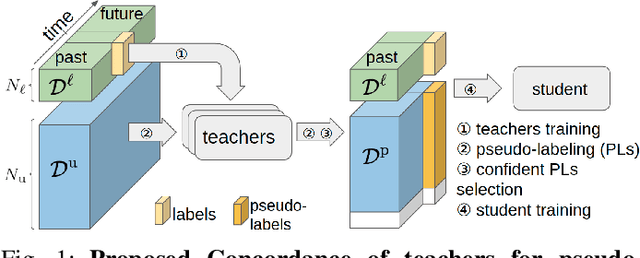
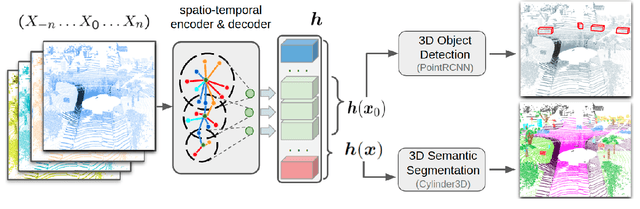

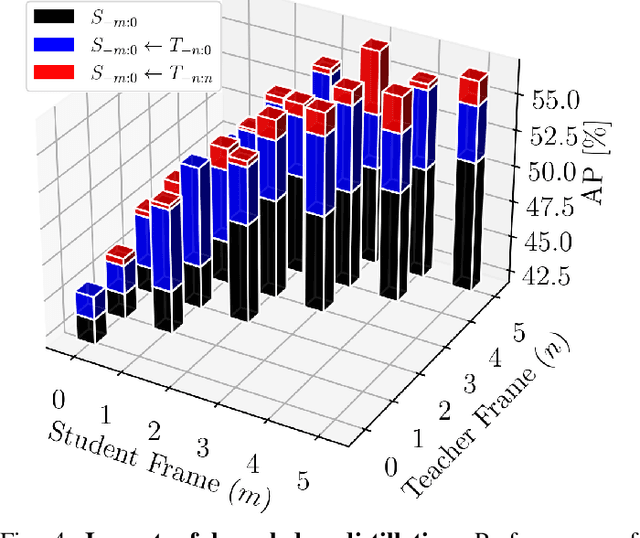
Automatic pseudo-labeling is a powerful tool to tap into large amounts of sequential unlabeled data. It is especially appealing in safety-critical applications of autonomous driving where performance requirements are extreme, datasets large, and manual labeling is very challenging. We propose to leverage the sequentiality of the captures to boost the pseudo-labeling technique in a teacher-student setup via training multiple teachers, each with access to different temporal information. This set of teachers, dubbed Concordance, provides higher quality pseudo-labels for the student training than standard methods. The output of multiple teachers is combined via a novel pseudo-label confidence-guided criterion. Our experimental evaluation focuses on the 3D point cloud domain in urban driving scenarios. We show the performance of our method applied to multiple model architectures with tasks of 3D semantic segmentation and 3D object detection on two benchmark datasets. Our method, using only 20% of manual labels, outperforms some of the fully supervised methods. Special performance boost is achieved for classes rarely appearing in the training data, e.g., bicycles and pedestrians. The implementation of our approach is publicly available at https://github.com/ctu-vras/T-Concord3D.
Fast-Spanning Ant Colony Optimisation (FaSACO) for Mobile Robot Coverage Path Planning
May 31, 2022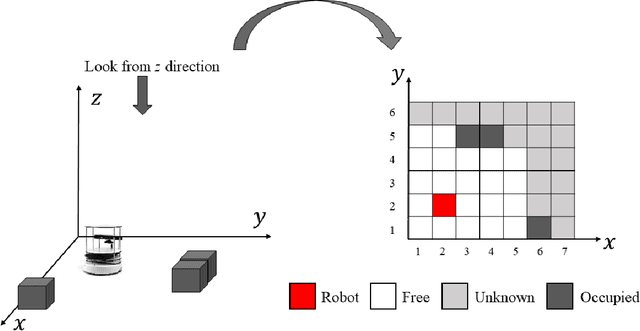
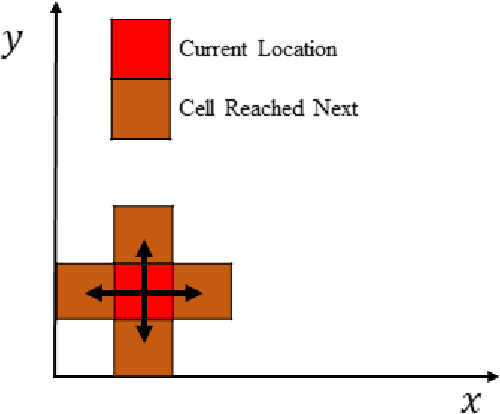
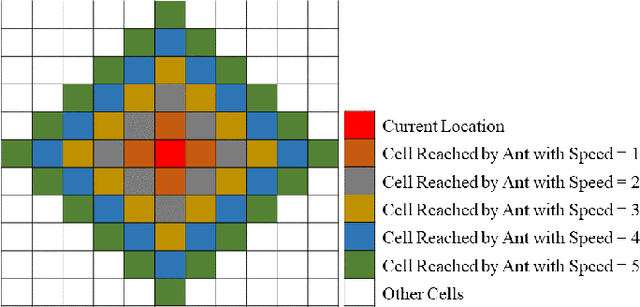
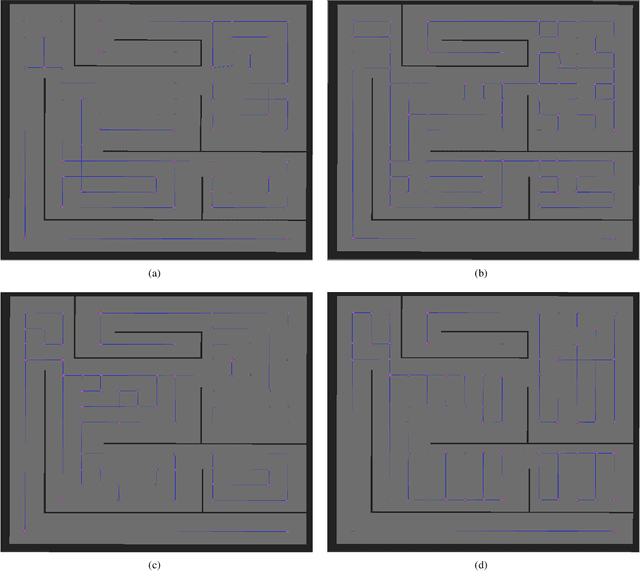
Coverage path planning acts as a key component for applications such as mobile robot vacuum cleaners and hospital disinfecting robots. However, the coverage path planning problem remains a challenge due to its NP-hard nature. Bio-inspired algorithms such as Ant Colony Optimisation (ACO) have been exploited to solve the problem because they can utilise heuristic information to mitigate the path planning complexity. This paper proposes a new variant of ACO - the Fast-Spanning Ant Colony Optimisation (FaSACO), where ants can explore the environment with various velocities. By doing so, ants with higher velocities can find targets or obstacles faster and keep lower velocity ants informed by communicating such information via trail pheromones. This mechanism ensures the optimal path is found while reducing the overall path planning time. Experimental results show that FaSACO is $19.3-32.3\%$ more efficient than ACO, and re-covers $6.9-12.5\%$ fewer cells than ACO. This makes FaSACO more appealing in real-time and energy-limited applications.
Privacy-Preserving Face Recognition with Learnable Privacy Budgets in Frequency Domain
Jul 19, 2022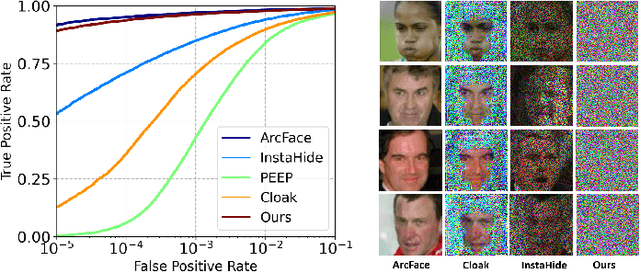

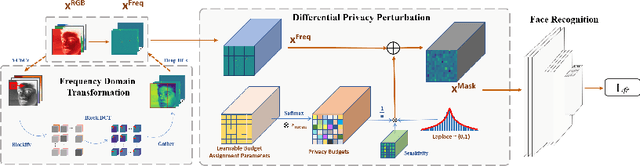
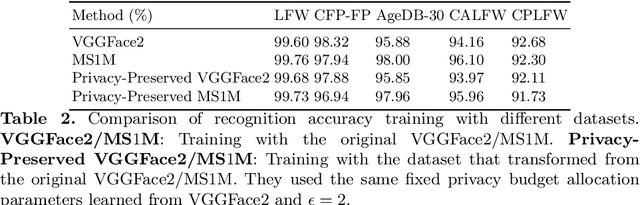
Face recognition technology has been used in many fields due to its high recognition accuracy, including the face unlocking of mobile devices, community access control systems, and city surveillance. As the current high accuracy is guaranteed by very deep network structures, facial images often need to be transmitted to third-party servers with high computational power for inference. However, facial images visually reveal the user's identity information. In this process, both untrusted service providers and malicious users can significantly increase the risk of a personal privacy breach. Current privacy-preserving approaches to face recognition are often accompanied by many side effects, such as a significant increase in inference time or a noticeable decrease in recognition accuracy. This paper proposes a privacy-preserving face recognition method using differential privacy in the frequency domain. Due to the utilization of differential privacy, it offers a guarantee of privacy in theory. Meanwhile, the loss of accuracy is very slight. This method first converts the original image to the frequency domain and removes the direct component termed DC. Then a privacy budget allocation method can be learned based on the loss of the back-end face recognition network within the differential privacy framework. Finally, it adds the corresponding noise to the frequency domain features. Our method performs very well with several classical face recognition test sets according to the extensive experiments.