 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
To Collaborate or Not in Distributed Statistical Estimation with Resource Constraints?
May 31, 2022
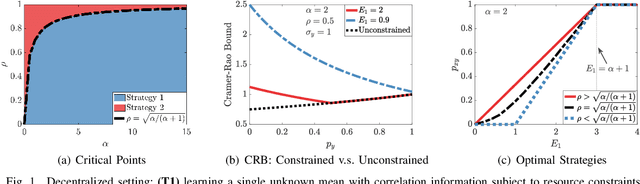
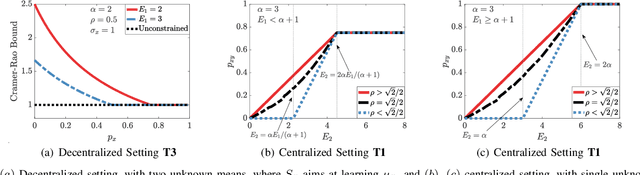
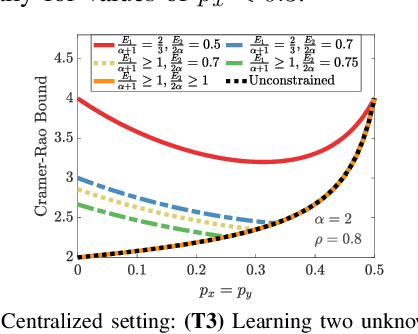
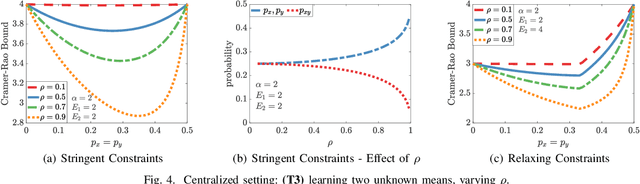
We study how the amount of correlation between observations collected by distinct sensors/learners affects data collection and collaboration strategies by analyzing Fisher information and the Cramer-Rao bound. In particular, we consider a simple setting wherein two sensors sample from a bivariate Gaussian distribution, which already motivates the adoption of various strategies, depending on the correlation between the two variables and resource constraints. We identify two particular scenarios: (1) where the knowledge of the correlation between samples cannot be leveraged for collaborative estimation purposes and (2) where the optimal data collection strategy involves investing scarce resources to collaboratively sample and transfer information that is not of immediate interest and whose statistics are already known, with the sole goal of increasing the confidence on an estimate of the parameter of interest. We discuss two applications, IoT DDoS attack detection and distributed estimation in wireless sensor networks, that may benefit from our results.
On Decentralizing Federated Reinforcement Learning in Multi-Robot Scenarios
Jul 19, 2022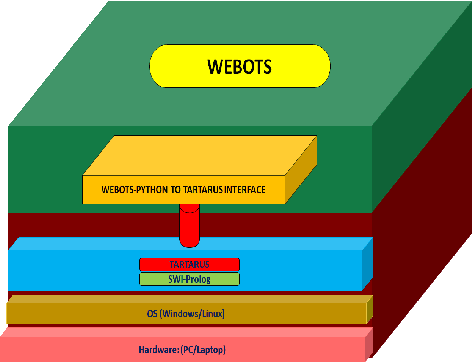
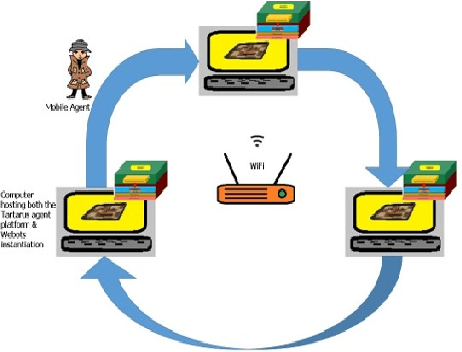

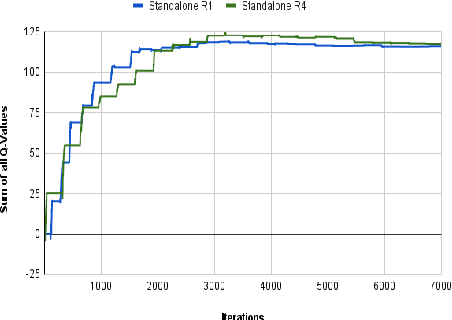
Federated Learning (FL) allows for collaboratively aggregating learned information across several computing devices and sharing the same amongst them, thereby tackling issues of privacy and the need of huge bandwidth. FL techniques generally use a central server or cloud for aggregating the models received from the devices. Such centralized FL techniques suffer from inherent problems such as failure of the central node and bottlenecks in channel bandwidth. When FL is used in conjunction with connected robots serving as devices, a failure of the central controlling entity can lead to a chaotic situation. This paper describes a mobile agent based paradigm to decentralize FL in multi-robot scenarios. Using Webots, a popular free open-source robot simulator, and Tartarus, a mobile agent platform, we present a methodology to decentralize federated learning in a set of connected robots. With Webots running on different connected computing systems, we show how mobile agents can perform the task of Decentralized Federated Reinforcement Learning (dFRL). Results obtained from experiments carried out using Q-learning and SARSA by aggregating their corresponding Q-tables, show the viability of using decentralized FL in the domain of robotics. Since the proposed work can be used in conjunction with other learning algorithms and also real robots, it can act as a vital tool for the study of decentralized FL using heterogeneous learning algorithms concurrently in multi-robot scenarios.
Bilingual Mutual Information Based Adaptive Training for Neural Machine Translation
May 27, 2021


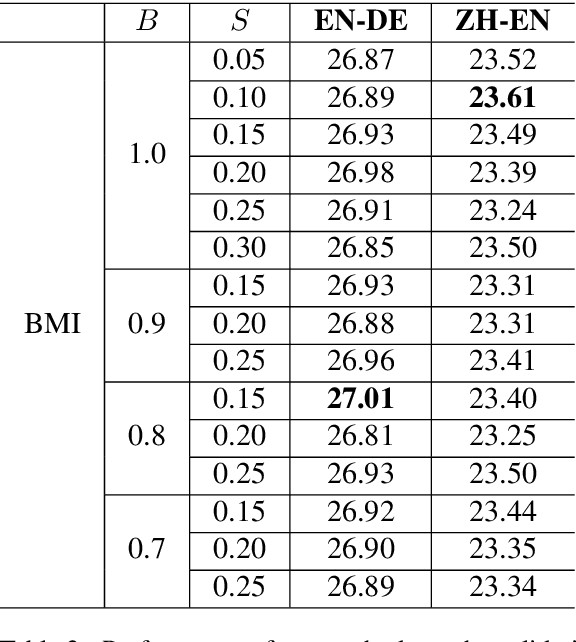
Recently, token-level adaptive training has achieved promising improvement in machine translation, where the cross-entropy loss function is adjusted by assigning different training weights to different tokens, in order to alleviate the token imbalance problem. However, previous approaches only use static word frequency information in the target language without considering the source language, which is insufficient for bilingual tasks like machine translation. In this paper, we propose a novel bilingual mutual information (BMI) based adaptive objective, which measures the learning difficulty for each target token from the perspective of bilingualism, and assigns an adaptive weight accordingly to improve token-level adaptive training. This method assigns larger training weights to tokens with higher BMI, so that easy tokens are updated with coarse granularity while difficult tokens are updated with fine granularity. Experimental results on WMT14 English-to-German and WMT19 Chinese-to-English demonstrate the superiority of our approach compared with the Transformer baseline and previous token-level adaptive training approaches. Further analyses confirm that our method can improve the lexical diversity.
Multiview Contrastive Learning for Completely Blind Video Quality Assessment of User Generated Content
Jul 13, 2022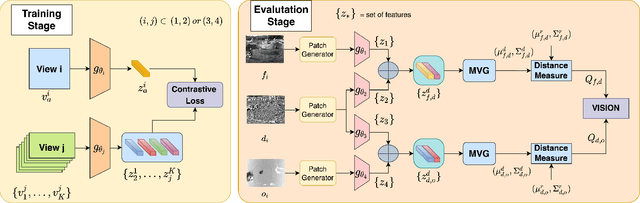
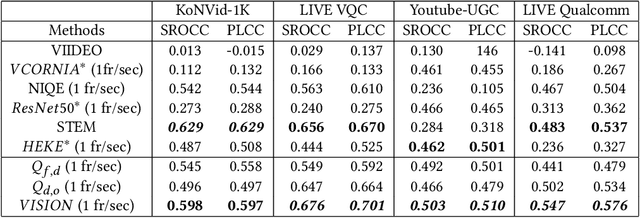
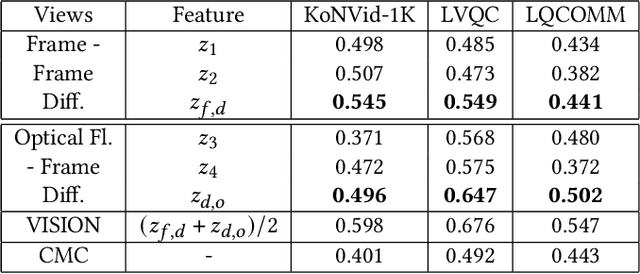
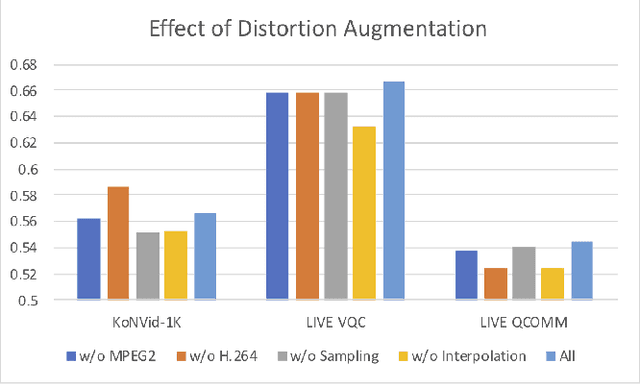
Completely blind video quality assessment (VQA) refers to a class of quality assessment methods that do not use any reference videos, human opinion scores or training videos from the target database to learn a quality model. The design of this class of methods is particularly important since it can allow for superior generalization in performance across various datasets. We consider the design of completely blind VQA for user generated content. While several deep feature extraction methods have been considered in supervised and weakly supervised settings, such approaches have not been studied in the context of completely blind VQA. We bridge this gap by presenting a self-supervised multiview contrastive learning framework to learn spatio-temporal quality representations. In particular, we capture the common information between frame differences and frames by treating them as a pair of views and similarly obtain the shared representations between frame differences and optical flow. The resulting features are then compared with a corpus of pristine natural video patches to predict the quality of the distorted video. Detailed experiments on multiple camera captured VQA datasets reveal the superior performance of our method over other features when evaluated without training on human scores.
Eliminating Gradient Conflict in Reference-based Line-Art Colorization
Jul 16, 2022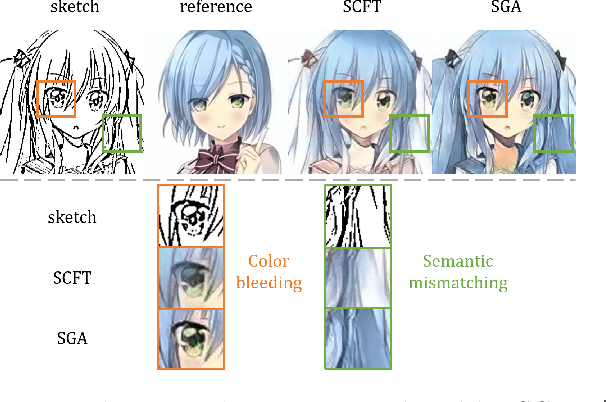
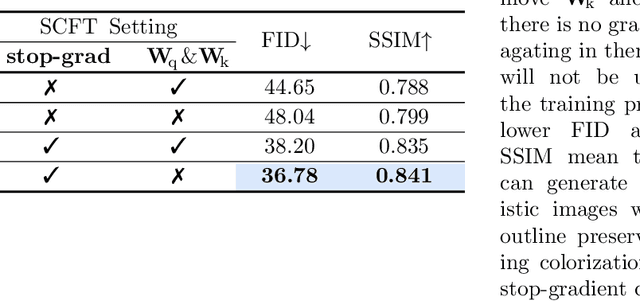
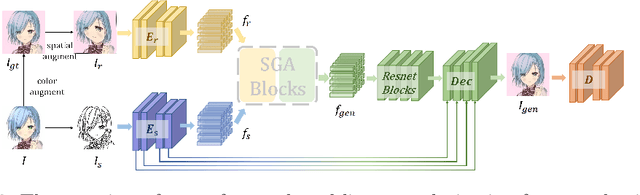
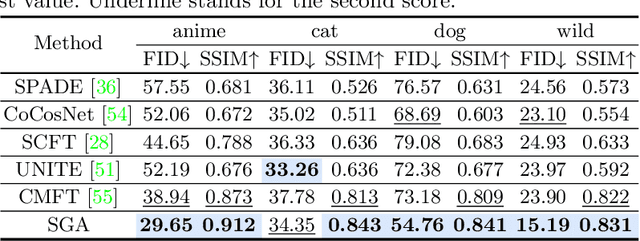
Reference-based line-art colorization is a challenging task in computer vision. The color, texture, and shading are rendered based on an abstract sketch, which heavily relies on the precise long-range dependency modeling between the sketch and reference. Popular techniques to bridge the cross-modal information and model the long-range dependency employ the attention mechanism. However, in the context of reference-based line-art colorization, several techniques would intensify the existing training difficulty of attention, for instance, self-supervised training protocol and GAN-based losses. To understand the instability in training, we detect the gradient flow of attention and observe gradient conflict among attention branches. This phenomenon motivates us to alleviate the gradient issue by preserving the dominant gradient branch while removing the conflict ones. We propose a novel attention mechanism using this training strategy, Stop-Gradient Attention (SGA), outperforming the attention baseline by a large margin with better training stability. Compared with state-of-the-art modules in line-art colorization, our approach demonstrates significant improvements in Fr\'echet Inception Distance (FID, up to 27.21%) and structural similarity index measure (SSIM, up to 25.67%) on several benchmarks. The code of SGA is available at https://github.com/kunkun0w0/SGA .
A Near-Optimal Primal-Dual Method for Off-Policy Learning in CMDP
Jul 13, 2022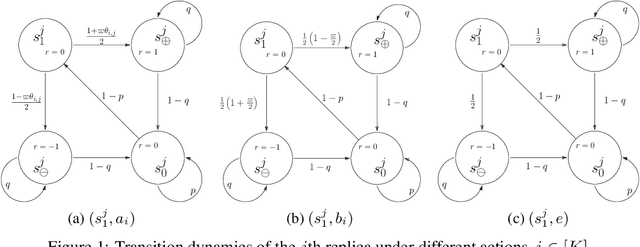
As an important framework for safe Reinforcement Learning, the Constrained Markov Decision Process (CMDP) has been extensively studied in the recent literature. However, despite the rich results under various on-policy learning settings, there still lacks some essential understanding of the offline CMDP problems, in terms of both the algorithm design and the information theoretic sample complexity lower bound. In this paper, we focus on solving the CMDP problems where only offline data are available. By adopting the concept of the single-policy concentrability coefficient $C^*$, we establish an $\Omega\left(\frac{\min\left\{|\mathcal{S}||\mathcal{A}|,|\mathcal{S}|+I\right\} C^*}{(1-\gamma)^3\epsilon^2}\right)$ sample complexity lower bound for the offline CMDP problem, where $I$ stands for the number of constraints. By introducing a simple but novel deviation control mechanism, we propose a near-optimal primal-dual learning algorithm called DPDL. This algorithm provably guarantees zero constraint violation and its sample complexity matches the above lower bound except for an $\tilde{\mathcal{O}}((1-\gamma)^{-1})$ factor. Comprehensive discussion on how to deal with the unknown constant $C^*$ and the potential asynchronous structure on the offline dataset are also included.
Participation and Data Valuation in IoT Data Markets through Distributed Coalitions
Jun 17, 2022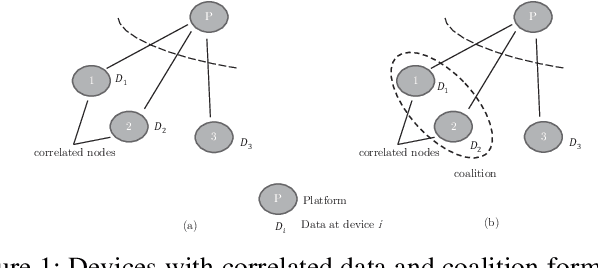
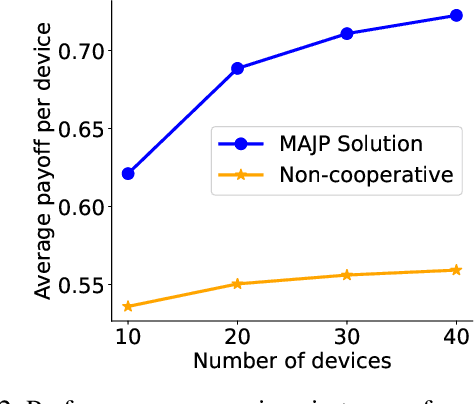
This paper considers a market for Internet of Things (IoT) data that is used to train machine learning models. The data is supplied to the market platform through a network and the price of the data is controlled based on the value it brings to the machine learning model. We explore the correlation property of data in a game-theoretical setting to eventually derive a simplified distributed solution for a data trading mechanism that emphasizes the mutual benefit of devices and the market. The key proposal is an efficient algorithm for markets that jointly addresses the challenges of availability and heterogeneity in participation, as well as the transfer of trust and the economic value of data exchange in IoT networks. The proposed approach establishes the data market by reinforcing collaboration opportunities between devices with correlated data to avoid information leakage. Therein, we develop a network-wide optimization problem that maximizes the social value of coalition among the IoT devices of similar data types; at the same time, it minimizes the cost due to network externalities, i.e., the impact of information leakage due to data correlation, as well as the opportunity costs. Finally, we reveal the structure of the formulated problem as a distributed coalition game and solve it following the simplified split-and-merge algorithm. Simulation results show the efficacy of our proposed mechanism design toward a trusted IoT data market, with up to 32.72% gain in the average payoff for each seller.
SC-Transformer++: Structured Context Transformer for Generic Event Boundary Detection
Jun 25, 2022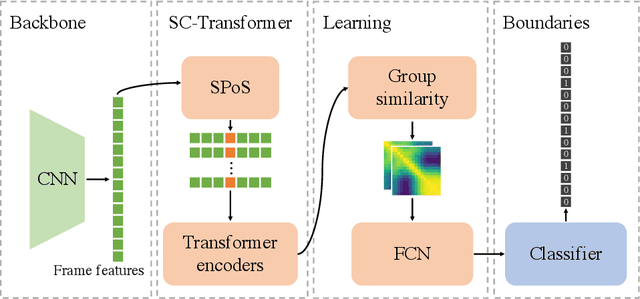
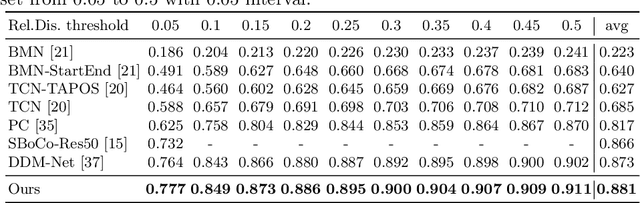
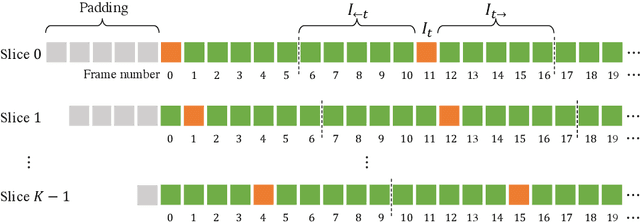
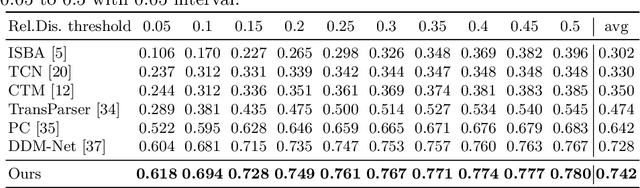
This report presents the algorithm used in the submission of Generic Event Boundary Detection (GEBD) Challenge at CVPR 2022. In this work, we improve the existing Structured Context Transformer (SC-Transformer) method for GEBD. Specifically, a transformer decoder module is added after transformer encoders to extract high quality frame features. The final classification is performed jointly on the results of the original binary classifier and a newly introduced multi-class classifier branch. To enrich motion information, optical flow is introduced as a new modality. Finally, model ensemble is used to further boost performance. The proposed method achieves 86.49% F1 score on Kinetics-GEBD test set. which improves 2.86% F1 score compared to the previous SOTA method.
VisFIS: Visual Feature Importance Supervision with Right-for-the-Right-Reason Objectives
Jun 22, 2022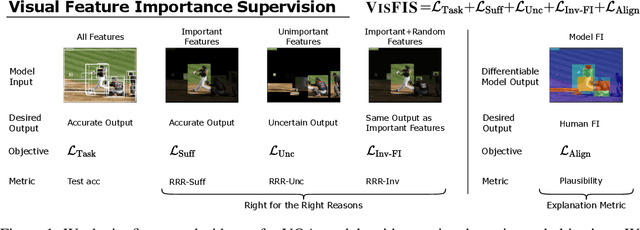
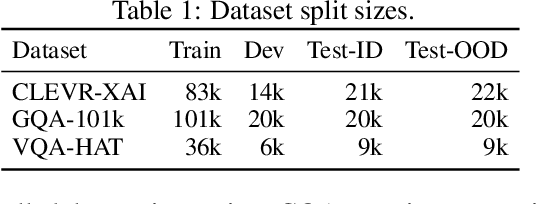
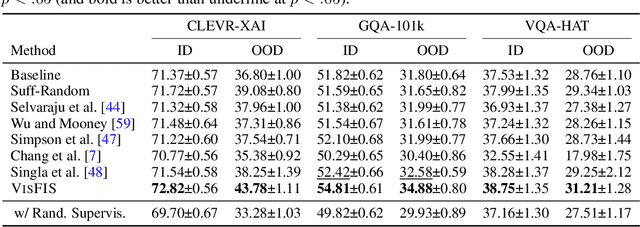
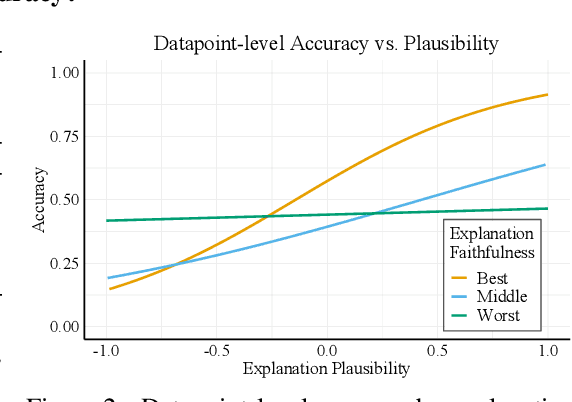
Many past works aim to improve visual reasoning in models by supervising feature importance (estimated by model explanation techniques) with human annotations such as highlights of important image regions. However, recent work has shown that performance gains from feature importance (FI) supervision for Visual Question Answering (VQA) tasks persist even with random supervision, suggesting that these methods do not meaningfully align model FI with human FI. In this paper, we show that model FI supervision can meaningfully improve VQA model accuracy as well as performance on several Right-for-the-Right-Reason (RRR) metrics by optimizing for four key model objectives: (1) accurate predictions given limited but sufficient information (Sufficiency); (2) max-entropy predictions given no important information (Uncertainty); (3) invariance of predictions to changes in unimportant features (Invariance); and (4) alignment between model FI explanations and human FI explanations (Plausibility). Our best performing method, Visual Feature Importance Supervision (VisFIS), outperforms strong baselines on benchmark VQA datasets in terms of both in-distribution and out-of-distribution accuracy. While past work suggests that the mechanism for improved accuracy is through improved explanation plausibility, we show that this relationship depends crucially on explanation faithfulness (whether explanations truly represent the model's internal reasoning). Predictions are more accurate when explanations are plausible and faithful, and not when they are plausible but not faithful. Lastly, we show that, surprisingly, RRR metrics are not predictive of out-of-distribution model accuracy when controlling for a model's in-distribution accuracy, which calls into question the value of these metrics for evaluating model reasoning. All supporting code is available at https://github.com/zfying/visfis
Stability of Weighted Majority Voting under Estimated Weights
Jul 13, 2022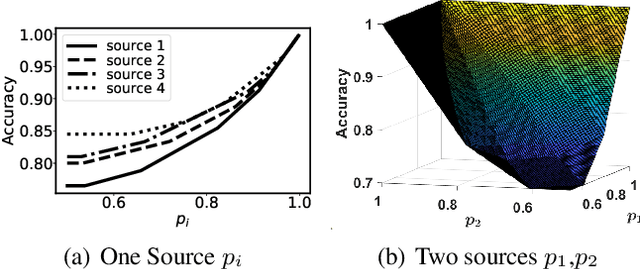
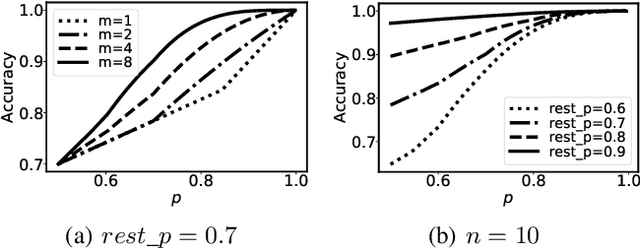
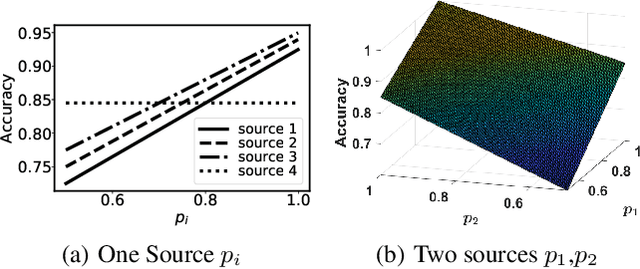
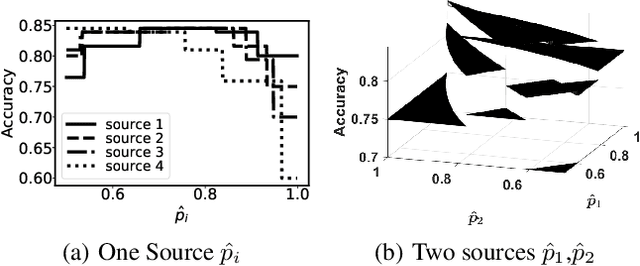
Weighted Majority Voting (WMV) is a well-known optimal decision rule for collective decision making, given the probability of sources to provide accurate information (trustworthiness). However, in reality, the trustworthiness is not a known quantity to the decision maker - they have to rely on an estimate called trust. A (machine learning) algorithm that computes trust is called unbiased when it has the property that it does not systematically overestimate or underestimate the trustworthiness. To formally analyse the uncertainty to the decision process, we introduce and analyse two important properties of such unbiased trust values: stability of correctness and stability of optimality. Stability of correctness means that the decision accuracy that the decision maker believes they achieved is equal to the actual accuracy. We prove stability of correctness holds. Stability of optimality means that the decisions made based on trust, are equally good as they would have been if they were based on trustworthiness. Stability of optimality does not hold. We analyse the difference between the two, and bounds thereon. We also present an overview of how sensitive decision correctness is to changes in trust and trustworthiness.