 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dataset of Propaganda Techniques of the State-Sponsored Information Operation of the People's Republic of China
Jun 14, 2021
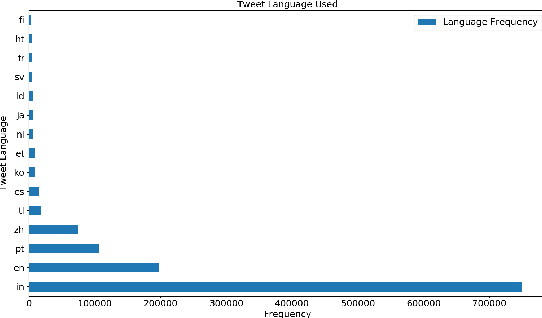

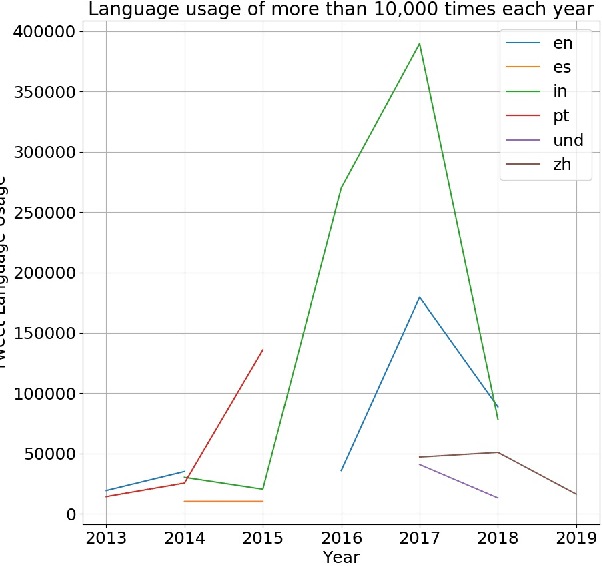

The digital media, identified as computational propaganda provides a pathway for propaganda to expand its reach without limit. State-backed propaganda aims to shape the audiences' cognition toward entities in favor of a certain political party or authority. Furthermore, it has become part of modern information warfare used in order to gain an advantage over opponents. Most of the current studies focus on using machine learning, quantitative, and qualitative methods to distinguish if a certain piece of information on social media is propaganda. Mainly conducted on English content, but very little research addresses Chinese Mandarin content. From propaganda detection, we want to go one step further to provide more fine-grained information on propaganda techniques that are applied. In this research, we aim to bridge the information gap by providing a multi-labeled propaganda techniques dataset in Mandarin based on a state-backed information operation dataset provided by Twitter. In addition to presenting the dataset, we apply a multi-label text classification using fine-tuned BERT. Potentially this could help future research in detecting state-backed propaganda online especially in a cross-lingual context and cross platforms identity consolidation.
Use-Case-Grounded Simulations for Explanation Evaluation
Jun 05, 2022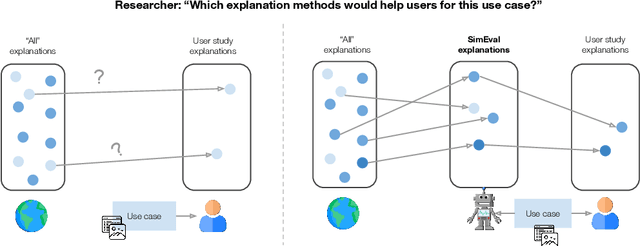
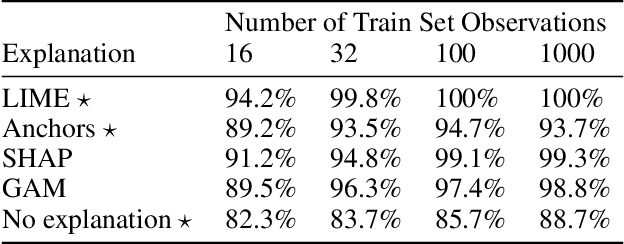
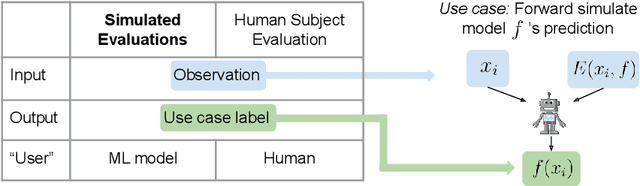
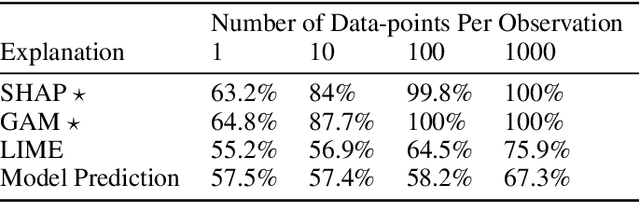
A growing body of research runs human subject evaluations to study whether providing users with explanations of machine learning models can help them with practical real-world use cases. However, running user studies is challenging and costly, and consequently each study typically only evaluates a limited number of different settings, e.g., studies often only evaluate a few arbitrarily selected explanation methods. To address these challenges and aid user study design, we introduce Use-Case-Grounded Simulated Evaluations (SimEvals). SimEvals involve training algorithmic agents that take as input the information content (such as model explanations) that would be presented to each participant in a human subject study, to predict answers to the use case of interest. The algorithmic agent's test set accuracy provides a measure of the predictiveness of the information content for the downstream use case. We run a comprehensive evaluation on three real-world use cases (forward simulation, model debugging, and counterfactual reasoning) to demonstrate that Simevals can effectively identify which explanation methods will help humans for each use case. These results provide evidence that SimEvals can be used to efficiently screen an important set of user study design decisions, e.g. selecting which explanations should be presented to the user, before running a potentially costly user study.
Reborn Mechanism: Rethinking the Negative Phase Information Flow in Convolutional Neural Network
Jun 13, 2021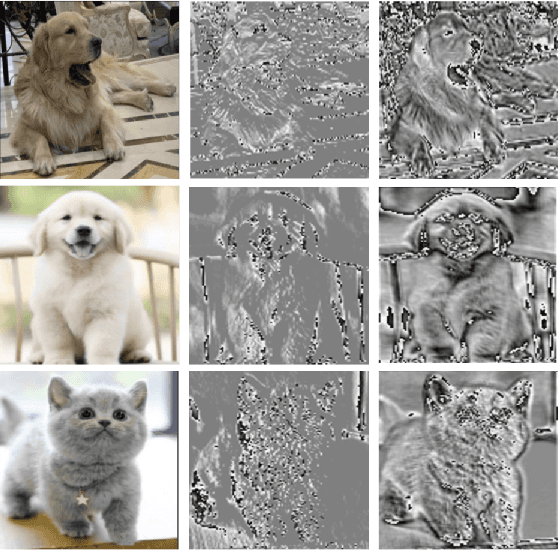
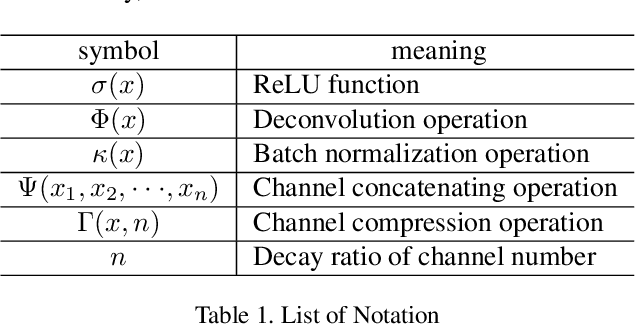
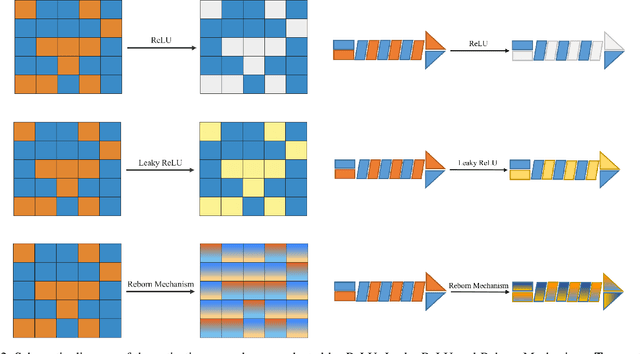
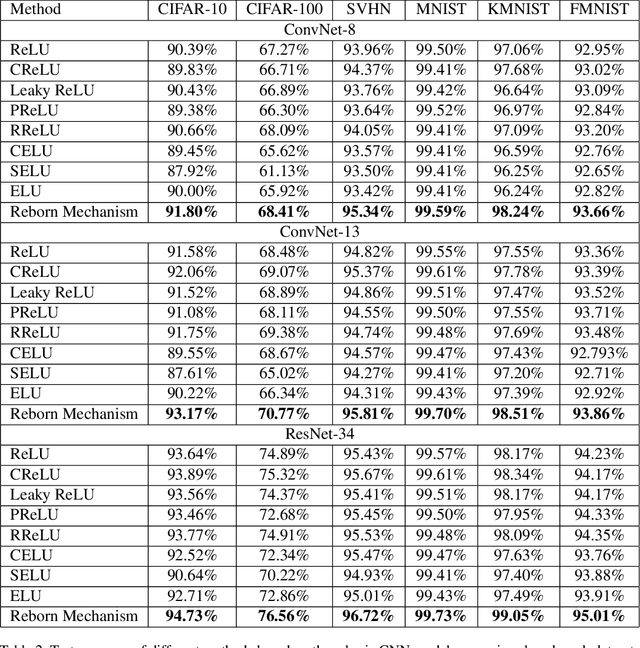
This paper proposes a novel nonlinear activation mechanism typically for convolutional neural network (CNN), named as reborn mechanism. In sharp contrast to ReLU which cuts off the negative phase value, the reborn mechanism enjoys the capacity to reborn and reconstruct dead neurons. Compared to other improved ReLU functions, reborn mechanism introduces a more proper way to utilize the negative phase information. Extensive experiments validate that this activation mechanism is able to enhance the model representation ability more significantly and make the better use of the input data information while maintaining the advantages of the original ReLU function. Moreover, reborn mechanism enables a non-symmetry that is hardly achieved by traditional CNNs and can act as a channel compensation method, offering competitive or even better performance but with fewer learned parameters than traditional methods. Reborn mechanism was tested on various benchmark datasets, all obtaining better performance than previous nonlinear activation functions.
Evidential Temporal-aware Graph-based Social Event Detection via Dempster-Shafer Theory
May 24, 2022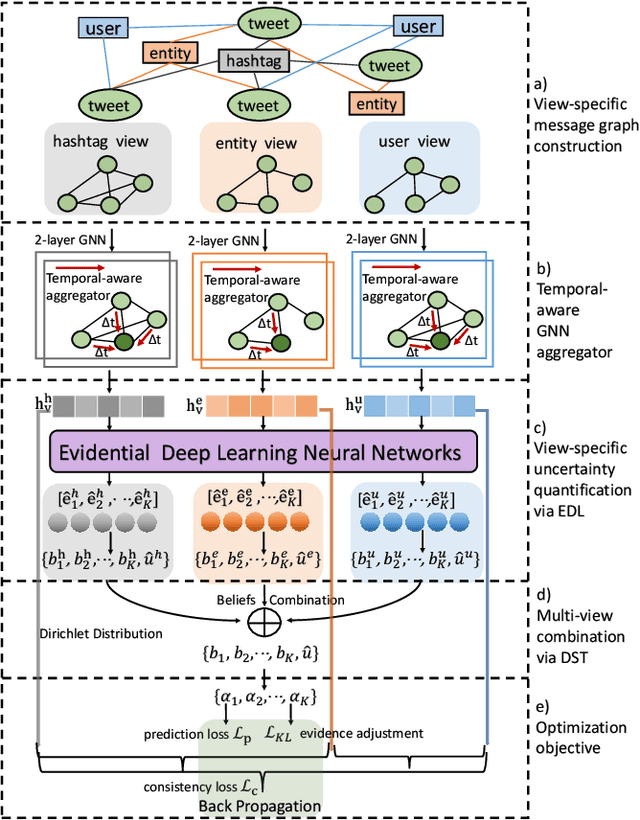
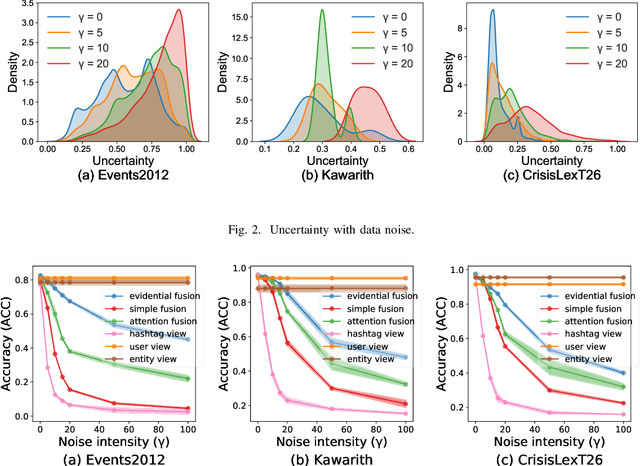
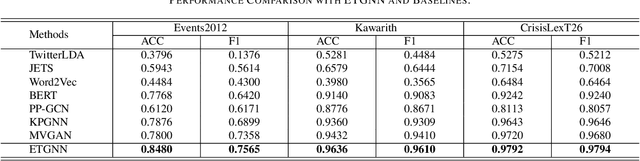
The rising popularity of online social network services has attracted lots of research on mining social media data, especially on mining social events. Social event detection, due to its wide applications, has now become a trivial task. State-of-the-art approaches exploiting Graph Neural Networks (GNNs) usually follow a two-step strategy: 1) constructing text graphs based on various views (\textit{co-user}, \textit{co-entities} and \textit{co-hashtags}); and 2) learning a unified text representation by a specific GNN model. Generally, the results heavily rely on the quality of the constructed graphs and the specific message passing scheme. However, existing methods have deficiencies in both aspects: 1) They fail to recognize the noisy information induced by unreliable views. 2) Temporal information which works as a vital indicator of events is neglected in most works. To this end, we propose ETGNN, a novel Evidential Temporal-aware Graph Neural Network. Specifically, we construct view-specific graphs whose nodes are the texts and edges are determined by several types of shared elements respectively. To incorporate temporal information into the message passing scheme, we introduce a novel temporal-aware aggregator which assigns weights to neighbours according to an adaptive time exponential decay formula. Considering the view-specific uncertainty, the representations of all views are converted into mass functions through evidential deep learning (EDL) neural networks, and further combined via Dempster-Shafer theory (DST) to make the final detection. Experimental results on three real-world datasets demonstrate the effectiveness of ETGNN in accuracy, reliability and robustness in social event detection.
Keep your Distance: Determining Sampling and Distance Thresholds in Machine Learning Monitoring
Jul 11, 2022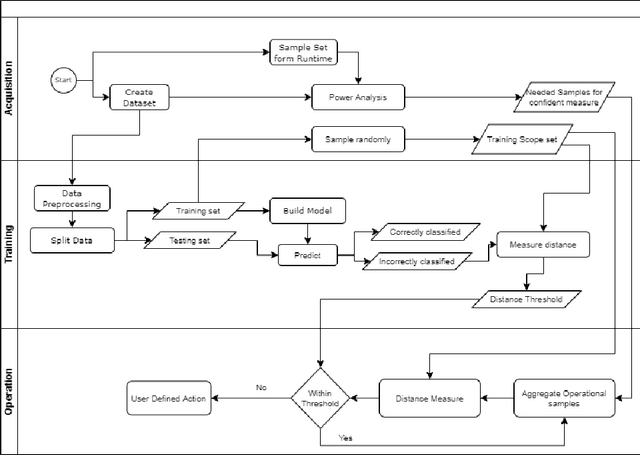

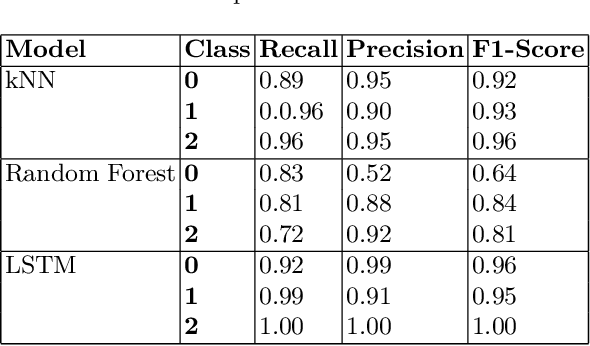
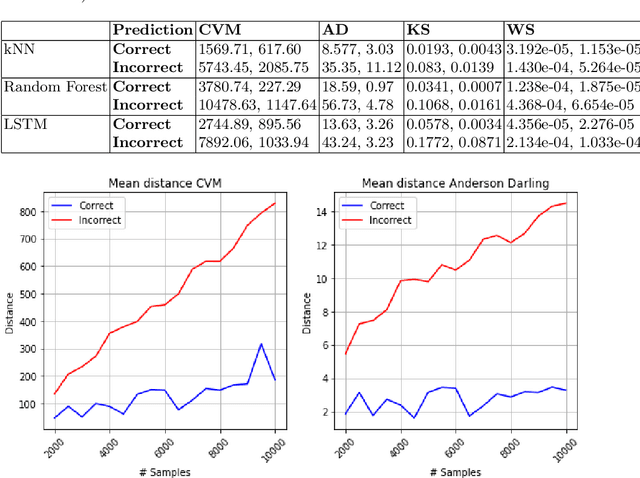
Machine Learning~(ML) has provided promising results in recent years across different applications and domains. However, in many cases, qualities such as reliability or even safety need to be ensured. To this end, one important aspect is to determine whether or not ML components are deployed in situations that are appropriate for their application scope. For components whose environments are open and variable, for instance those found in autonomous vehicles, it is therefore important to monitor their operational situation to determine its distance from the ML components' trained scope. If that distance is deemed too great, the application may choose to consider the ML component outcome unreliable and switch to alternatives, e.g. using human operator input instead. SafeML is a model-agnostic approach for performing such monitoring, using distance measures based on statistical testing of the training and operational datasets. Limitations in setting SafeML up properly include the lack of a systematic approach for determining, for a given application, how many operational samples are needed to yield reliable distance information as well as to determine an appropriate distance threshold. In this work, we address these limitations by providing a practical approach and demonstrate its use in a well known traffic sign recognition problem, and on an example using the CARLA open-source automotive simulator.
LaT: Latent Translation with Cycle-Consistency for Video-Text Retrieval
Jul 11, 2022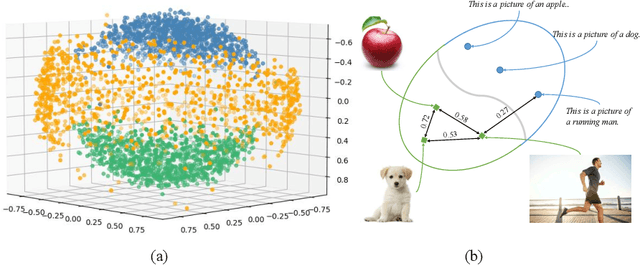
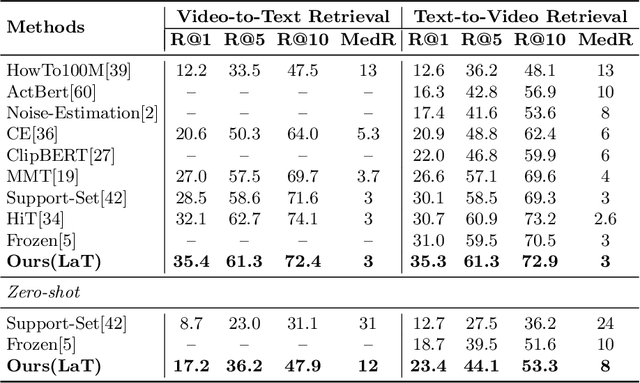
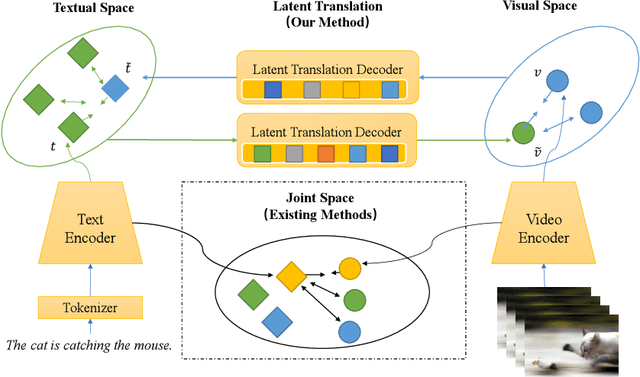
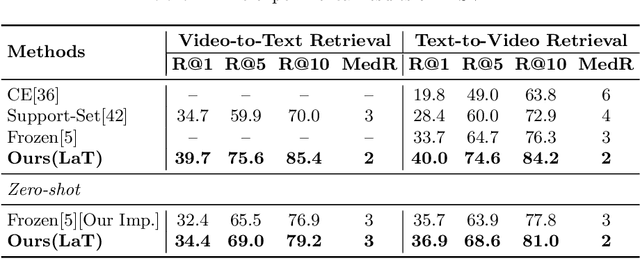
Video-text retrieval is a class of cross-modal representation learning problems, where the goal is to select the video which corresponds to the text query between a given text query and a pool of candidate videos. The contrastive paradigm of vision-language pretraining has shown promising success with large-scale datasets and unified transformer architecture, and demonstrated the power of a joint latent space. Despite this, the intrinsic divergence between the visual domain and textual domain is still far from being eliminated, and projecting different modalities into a joint latent space might result in the distorting of the information inside the single modality. To overcome the above issue, we present a novel mechanism for learning the translation relationship from a source modality space $\mathcal{S}$ to a target modality space $\mathcal{T}$ without the need for a joint latent space, which bridges the gap between visual and textual domains. Furthermore, to keep cycle consistency between translations, we adopt a cycle loss involving both forward translations from $\mathcal{S}$ to the predicted target space $\mathcal{T'}$, and backward translations from $\mathcal{T'}$ back to $\mathcal{S}$. Extensive experiments conducted on MSR-VTT, MSVD, and DiDeMo datasets demonstrate the superiority and effectiveness of our LaT approach compared with vanilla state-of-the-art methods.
Innovative Cognitive Approaches for Joint Radar Clutter Classification and Multiple Target Detection in Heterogeneous Environments
Jul 08, 2022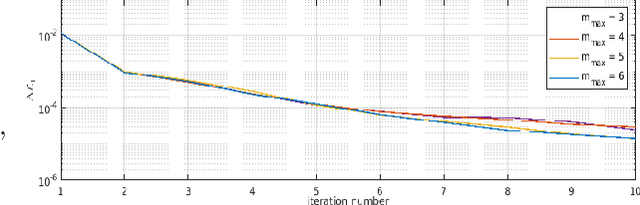
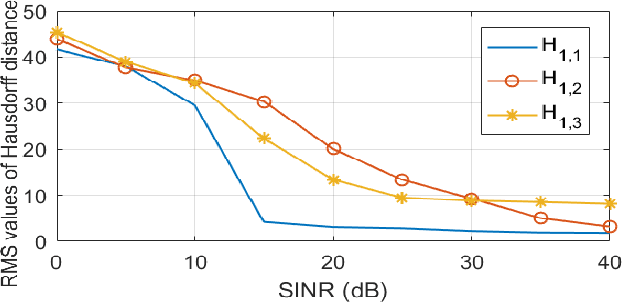
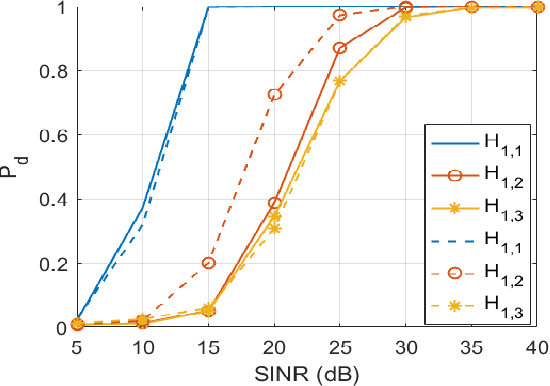
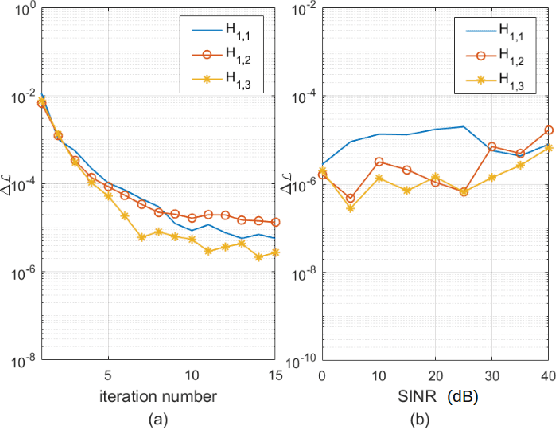
The joint adaptive detection of multiple point-like targets in scenarios characterized by different clutter types is still an open problem in the radar community. In this paper, we provide a solution to this problem by devising detection architectures capable of classifying the range bins according to their clutter properties and detecting possible multiple targets whose positions and number are unknown. Remarkably, the information provided by the proposed architectures makes the system aware of the surrounding environment and can be exploited to enhance the entire detection and estimation performance of the system. At the design stage, we assume three different signal models and apply the latent variable model in conjunction with estimation procedures based upon the expectation-maximization algorithm. In addition, for some models, the maximization step cannot be computed in closed-form (at least to the best of authors' knowledge) and, hence, suitable approximations are pursued, whereas, in other cases, the maximization is exact. The performance of the proposed architectures is assessed over synthetic data and shows that they can be effective in heterogeneous scenarios providing an initial snapshot of the radar operating scenario.
Towards Intrinsic Common Discriminative Features Learning for Face Forgery Detection using Adversarial Learning
Jul 08, 2022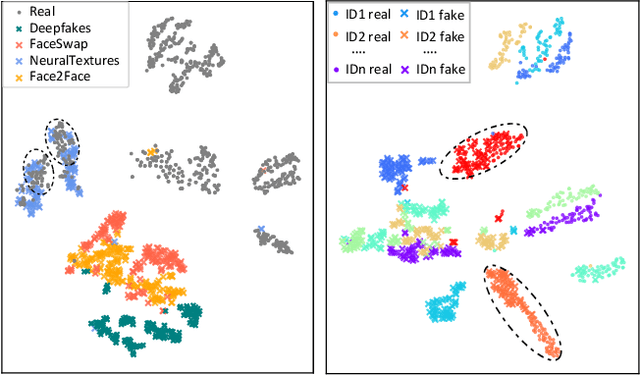
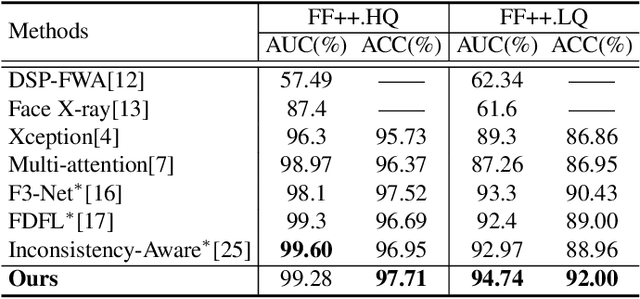
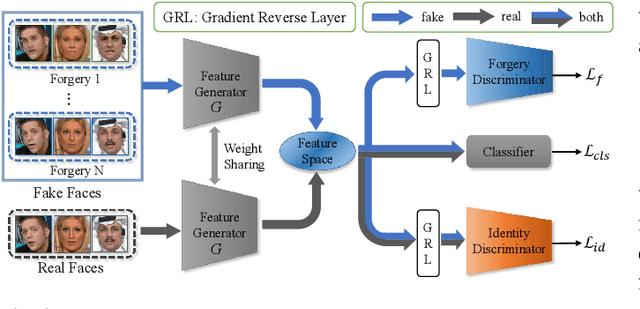
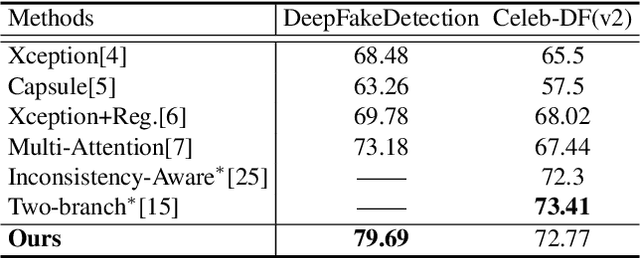
Existing face forgery detection methods usually treat face forgery detection as a binary classification problem and adopt deep convolution neural networks to learn discriminative features. The ideal discriminative features should be only related to the real/fake labels of facial images. However, we observe that the features learned by vanilla classification networks are correlated to unnecessary properties, such as forgery methods and facial identities. Such phenomenon would limit forgery detection performance especially for the generalization ability. Motivated by this, we propose a novel method which utilizes adversarial learning to eliminate the negative effect of different forgery methods and facial identities, which helps classification network to learn intrinsic common discriminative features for face forgery detection. To leverage data lacking ground truth label of facial identities, we design a special identity discriminator based on similarity information derived from off-the-shelf face recognition model. With the help of adversarial learning, our face forgery detection model learns to extract common discriminative features through eliminating the effect of forgery methods and facial identities. Extensive experiments demonstrate the effectiveness of the proposed method under both intra-dataset and cross-dataset evaluation settings.
Pose-based Tremor Classification for Parkinson's Disease Diagnosis from Video
Jul 14, 2022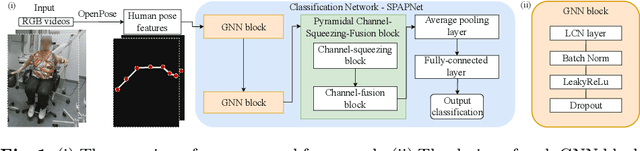
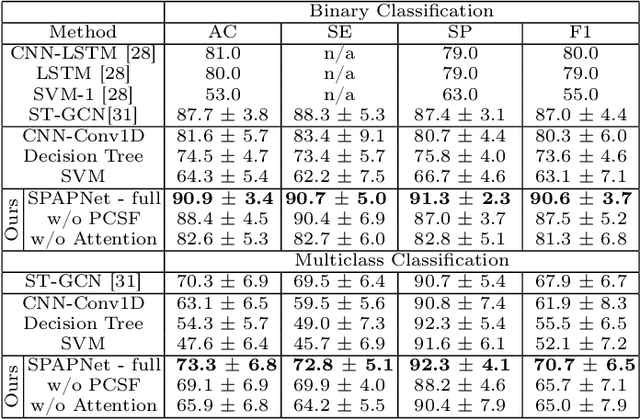
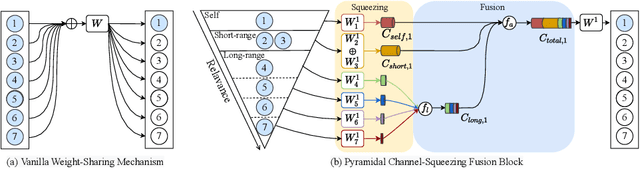
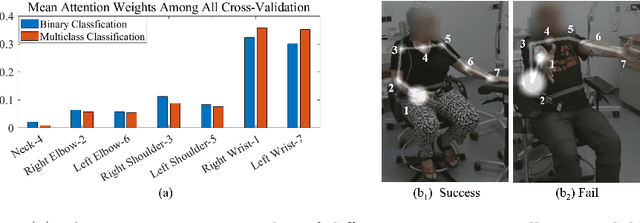
Parkinson's disease (PD) is a progressive neurodegenerative disorder that results in a variety of motor dysfunction symptoms, including tremors, bradykinesia, rigidity and postural instability. The diagnosis of PD mainly relies on clinical experience rather than a definite medical test, and the diagnostic accuracy is only about 73-84% since it is challenged by the subjective opinions or experiences of different medical experts. Therefore, an efficient and interpretable automatic PD diagnosis system is valuable for supporting clinicians with more robust diagnostic decision-making. To this end, we propose to classify Parkinson's tremor since it is one of the most predominant symptoms of PD with strong generalizability. Different from other computer-aided time and resource-consuming Parkinson's Tremor (PT) classification systems that rely on wearable sensors, we propose SPAPNet, which only requires consumer-grade non-intrusive video recording of camera-facing human movements as input to provide undiagnosed patients with low-cost PT classification results as a PD warning sign. For the first time, we propose to use a novel attention module with a lightweight pyramidal channel-squeezing-fusion architecture to extract relevant PT information and filter the noise efficiently. This design aids in improving both classification performance and system interpretability. Experimental results show that our system outperforms state-of-the-arts by achieving a balanced accuracy of 90.9% and an F1-score of 90.6% in classifying PT with the non-PT class.
High-Cardinality Geometrical Constellation Shaping for the Nonlinear Fibre Channel
May 09, 2022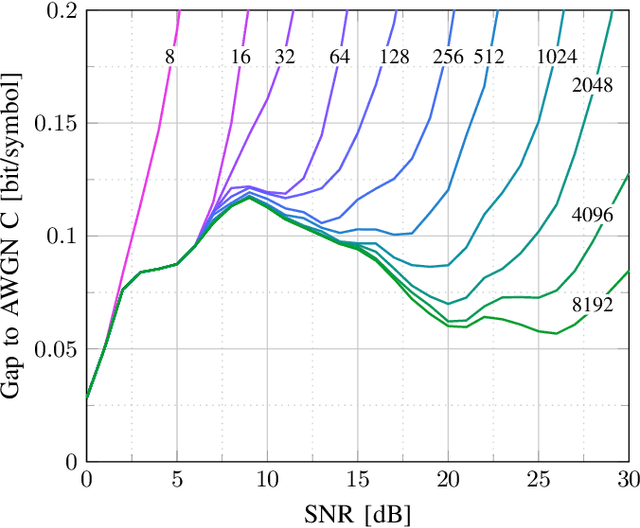
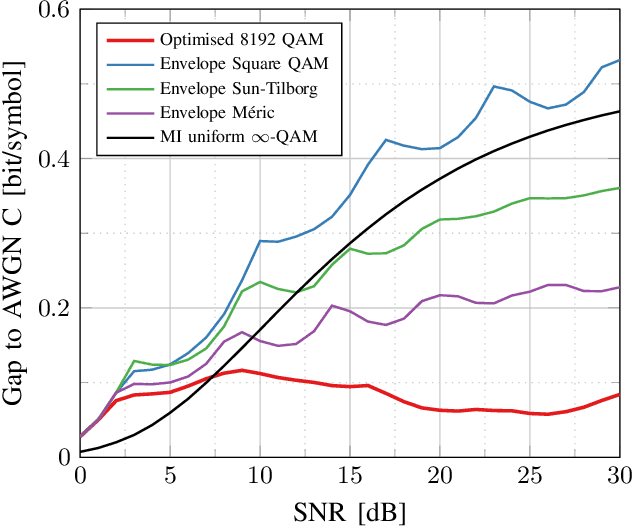
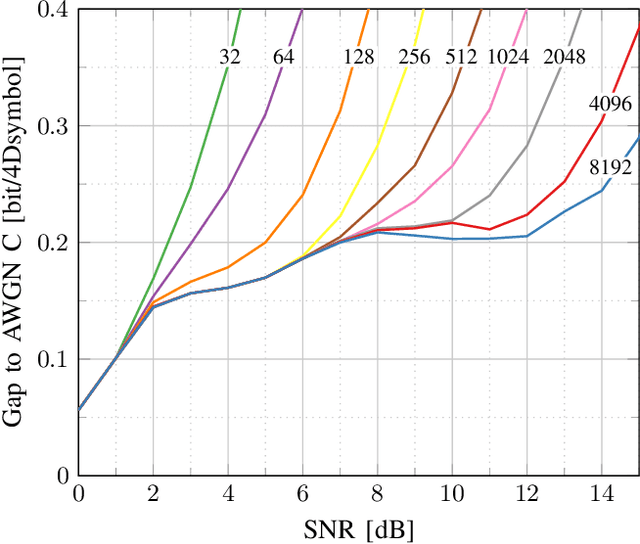
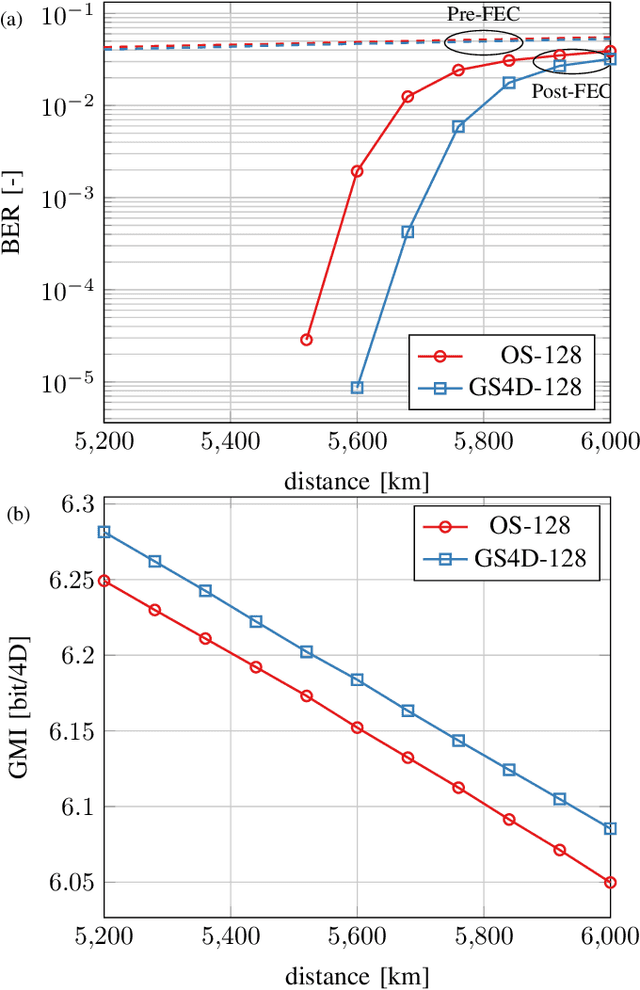
This paper presents design methods for highly efficient optimisation of geometrically shaped constellations to maximise data throughput in optical communications. It describes methods to analytically calculate the information-theoretical loss and the gradient of this loss as a function of the input constellation shape. The gradients of the \ac{MI} and \ac{GMI} are critical to the optimisation of geometrically-shaped constellations. It presents the analytical derivative of the achievable information rate metrics with respect to the input constellation. The proposed method allows for improved design of higher cardinality and higher-dimensional constellations for optimising both linear and nonlinear fibre transmission throughput. Near-capacity achieving constellations with up to 8192 points for both 2 and 4 dimensions, with generalised mutual information (GMI) within 0.06 bit/2Dsymbol of additive white Gaussian noise channel (AWGN) capacity, are presented. Additionally, a design algorithm reducing the design computation time from days to minutes is introduced, allowing the presentation of optimised constellations for both linear AWGN and nonlinear fibre channels for a wide range of signal-to-noise ratios.