 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Motion Compensated Frequency Selective Extrapolation for Error Concealment in Video Coding
Jul 01, 2022
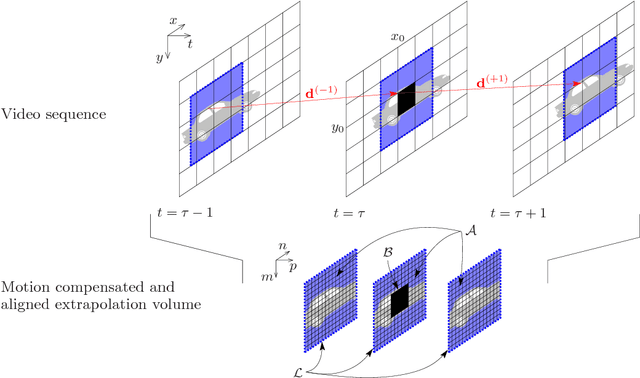
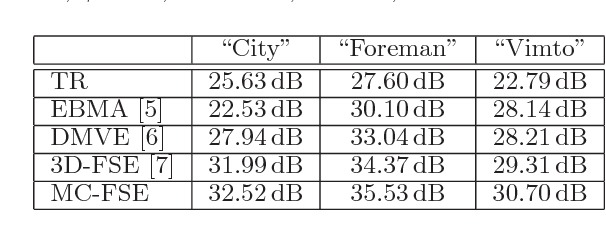
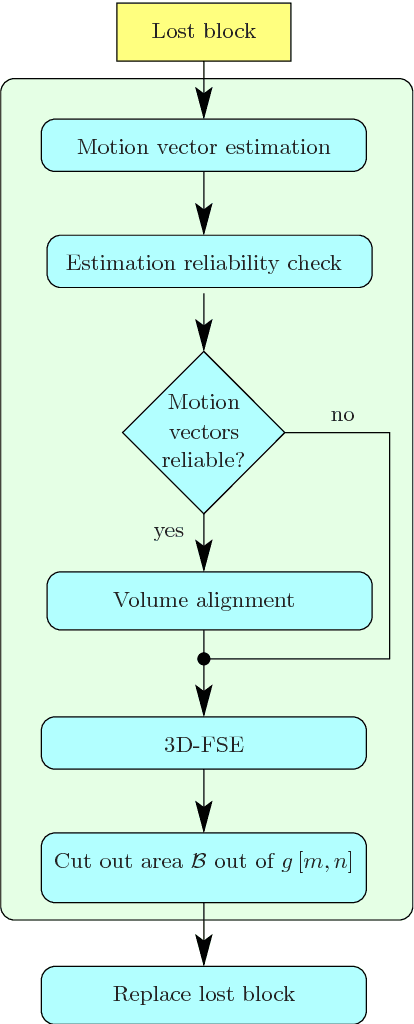
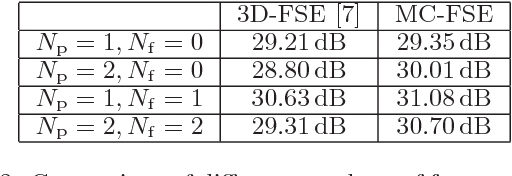
Although wireless and IP-based access to video content gives a new degree of freedom to the viewers, the risk of severe block losses caused by transmission errors is always present. The purpose of this paper is to present a new method for concealing block losses in erroneously received video sequences. For this, a motion compensated data set is generated around the lost block. Based on this aligned data set, a model of the signal is created that continues the signal into the lost areas. Since spatial as well as temporal informations are used for the model generation, the proposed method is superior to methods that use either spatial or temporal information for concealment. Furthermore it outperforms current state of the art spatio-temporal concealment algorithms by up to 1.4 dB in PSNR.
Hard Attention Control By Mutual Information Maximization
Mar 10, 2021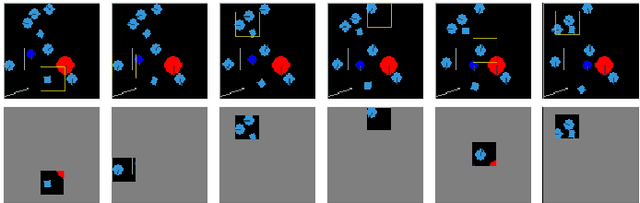

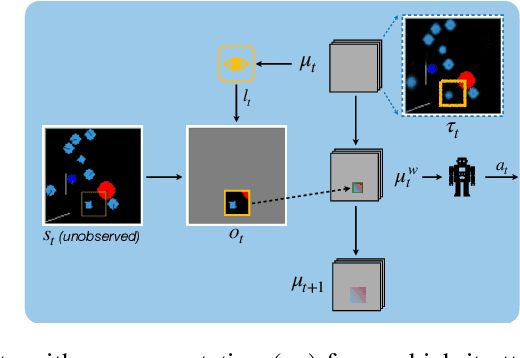
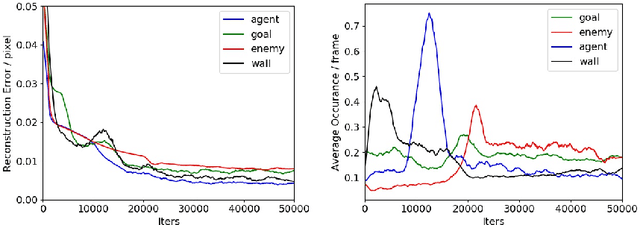
Biological agents have adopted the principle of attention to limit the rate of incoming information from the environment. One question that arises is if an artificial agent has access to only a limited view of its surroundings, how can it control its attention to effectively solve tasks? We propose an approach for learning how to control a hard attention window by maximizing the mutual information between the environment state and the attention location at each step. The agent employs an internal world model to make predictions about its state and focuses attention towards where the predictions may be wrong. Attention is trained jointly with a dynamic memory architecture that stores partial observations and keeps track of the unobserved state. We demonstrate that our approach is effective in predicting the full state from a sequence of partial observations. We also show that the agent's internal representation of the surroundings, a live mental map, can be used for control in two partially observable reinforcement learning tasks. Videos of the trained agent can be found at https://sites.google.com/view/hard-attention-control.
Towards Optimizing OCR for Accessibility
Jun 21, 2022



Visual cues such as structure, emphasis, and icons play an important role in efficient information foraging by sighted individuals and make for a pleasurable reading experience. Blind, low-vision and other print-disabled individuals miss out on these cues since current OCR and text-to-speech software ignore them, resulting in a tedious reading experience. We identify four semantic goals for an enjoyable listening experience, and identify syntactic visual cues that help make progress towards these goals. Empirically, we find that preserving even one or two visual cues in aural form significantly enhances the experience for listening to print content.
* Published at Accessibility, Vision, and Autonomy Meet, CVPR 2022 Workshop
Learned Video Compression via Heterogeneous Deformable Compensation Network
Jul 11, 2022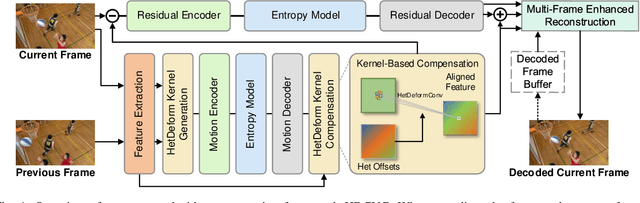


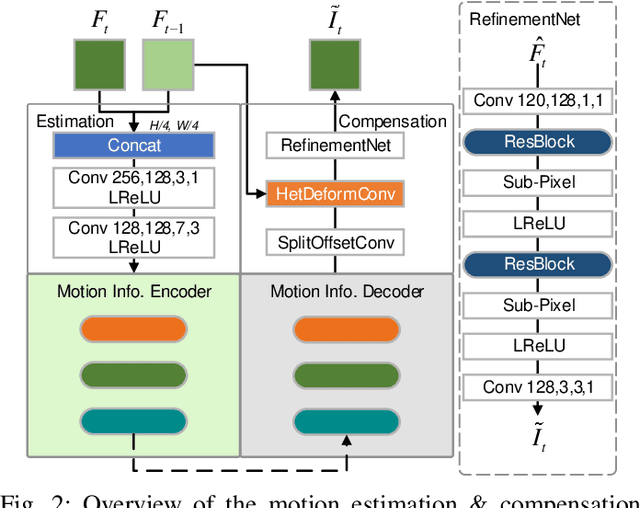
Learned video compression has recently emerged as an essential research topic in developing advanced video compression technologies, where motion compensation is considered one of the most challenging issues. In this paper, we propose a learned video compression framework via heterogeneous deformable compensation strategy (HDCVC) to tackle the problems of unstable compression performance caused by single-size deformable kernels in downsampled feature domain. More specifically, instead of utilizing optical flow warping or single-size-kernel deformable alignment, the proposed algorithm extracts features from the two adjacent frames to estimate content-adaptive heterogeneous deformable (HetDeform) kernel offsets. Then we transform the reference features with the HetDeform convolution to accomplish motion compensation. Moreover, we design a Spatial-Neighborhood-Conditioned Divisive Normalization (SNCDN) to achieve more effective data Gaussianization combined with the Generalized Divisive Normalization. Furthermore, we propose a multi-frame enhanced reconstruction module for exploiting context and temporal information for final quality enhancement. Experimental results indicate that HDCVC achieves superior performance than the recent state-of-the-art learned video compression approaches.
Tell Me Something That Will Help Me Trust You: A Survey of Trust Calibration in Human-Agent Interaction
May 06, 2022
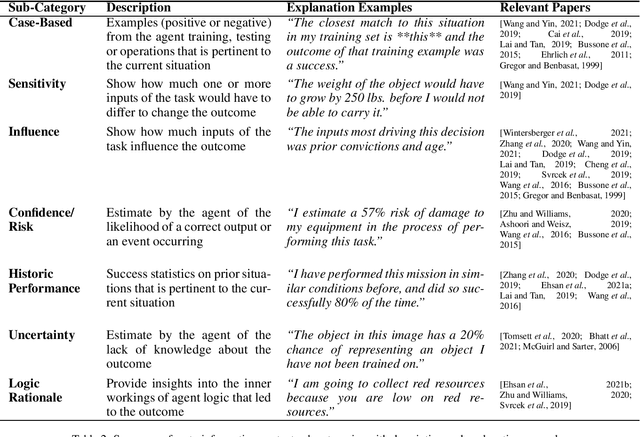
When a human receives a prediction or recommended course of action from an intelligent agent, what additional information, beyond the prediction or recommendation itself, does the human require from the agent to decide whether to trust or reject the prediction or recommendation? In this paper we survey literature in the area of trust between a single human supervisor and a single agent subordinate to determine the nature and extent of this additional information and to characterize it into a taxonomy that can be leveraged by future researchers and intelligent agent practitioners. By examining this question from a human-centered, information-focused point of view, we can begin to compare and contrast different implementations and also provide insight and directions for future work.
Point-to-Box Network for Accurate Object Detection via Single Point Supervision
Jul 14, 2022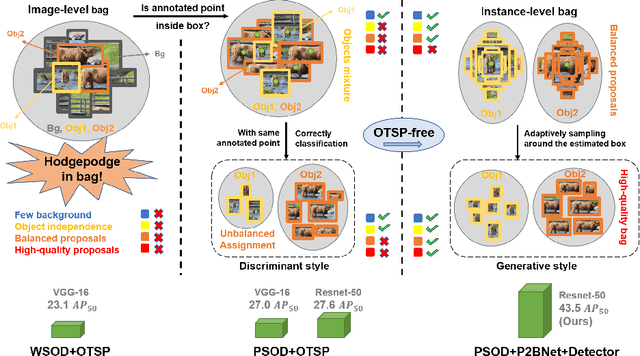
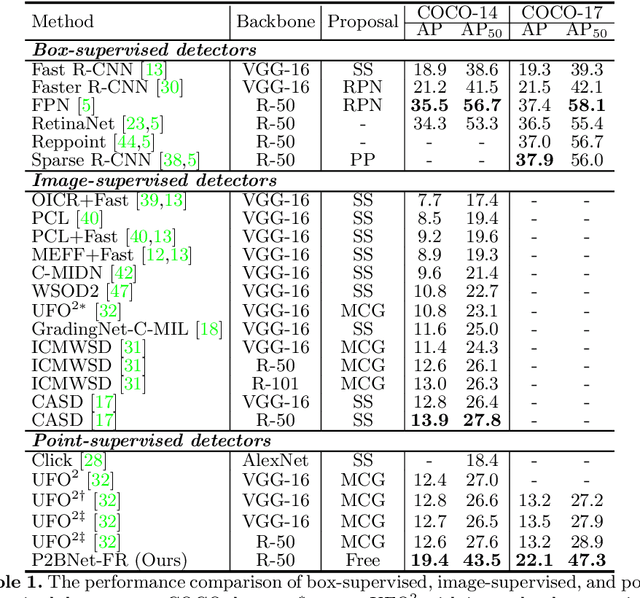
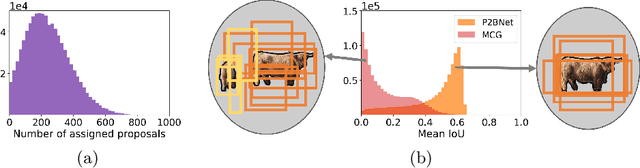
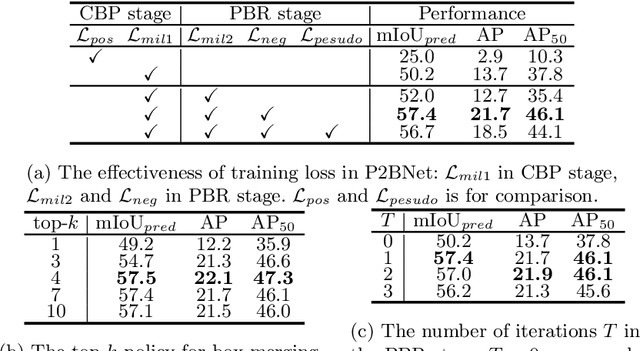
Object detection using single point supervision has received increasing attention over the years. In this paper, we attribute such a large performance gap to the failure of generating high-quality proposal bags which are crucial for multiple instance learning (MIL). To address this problem, we introduce a lightweight alternative to the off-the-shelf proposal (OTSP) method and thereby create the Point-to-Box Network (P2BNet), which can construct an inter-objects balanced proposal bag by generating proposals in an anchor-like way. By fully investigating the accurate position information, P2BNet further constructs an instance-level bag, avoiding the mixture of multiple objects. Finally, a coarse-to-fine policy in a cascade fashion is utilized to improve the IoU between proposals and ground-truth (GT). Benefiting from these strategies, P2BNet is able to produce high-quality instance-level bags for object detection. P2BNet improves the mean average precision (AP) by more than 50% relative to the previous best PSOD method on the MS COCO dataset. It also demonstrates the great potential to bridge the performance gap between point supervised and bounding-box supervised detectors. The code will be released at github.com/ucas-vg/P2BNet.
Multi-scale Information Assembly for Image Matting
Jan 07, 2021Image matting is a long-standing problem in computer graphics and vision, mostly identified as the accurate estimation of the foreground in input images. We argue that the foreground objects can be represented by different-level information, including the central bodies, large-grained boundaries, refined details, etc. Based on this observation, in this paper, we propose a multi-scale information assembly framework (MSIA-matte) to pull out high-quality alpha mattes from single RGB images. Technically speaking, given an input image, we extract advanced semantics as our subject content and retain initial CNN features to encode different-level foreground expression, then combine them by our well-designed information assembly strategy. Extensive experiments can prove the effectiveness of the proposed MSIA-matte, and we can achieve state-of-the-art performance compared to most existing matting networks.
GrabQC: Graph based Query Contextualization for automated ICD coding
Jul 14, 2022Automated medical coding is a process of codifying clinical notes to appropriate diagnosis and procedure codes automatically from the standard taxonomies such as ICD (International Classification of Diseases) and CPT (Current Procedure Terminology). The manual coding process involves the identification of entities from the clinical notes followed by querying a commercial or non-commercial medical codes Information Retrieval (IR) system that follows the Centre for Medicare and Medicaid Services (CMS) guidelines. We propose to automate this manual process by automatically constructing a query for the IR system using the entities auto-extracted from the clinical notes. We propose \textbf{GrabQC}, a \textbf{Gra}ph \textbf{b}ased \textbf{Q}uery \textbf{C}ontextualization method that automatically extracts queries from the clinical text, contextualizes the queries using a Graph Neural Network (GNN) model and obtains the ICD Codes using an external IR system. We also propose a method for labelling the dataset for training the model. We perform experiments on two datasets of clinical text in three different setups to assert the effectiveness of our approach. The experimental results show that our proposed method is better than the compared baselines in all three settings.
Adaptive frequency prior for frequency selective reconstruction of images from non-regular subsampling
Jul 14, 2022
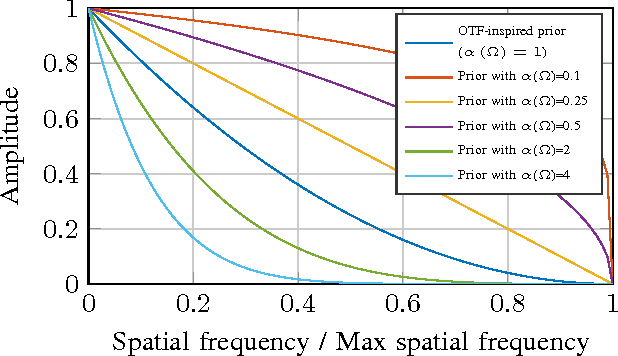
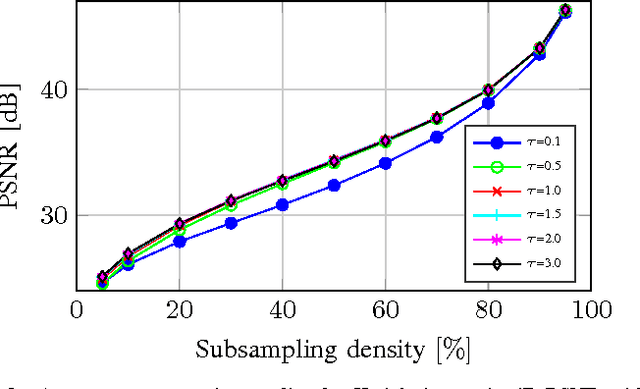
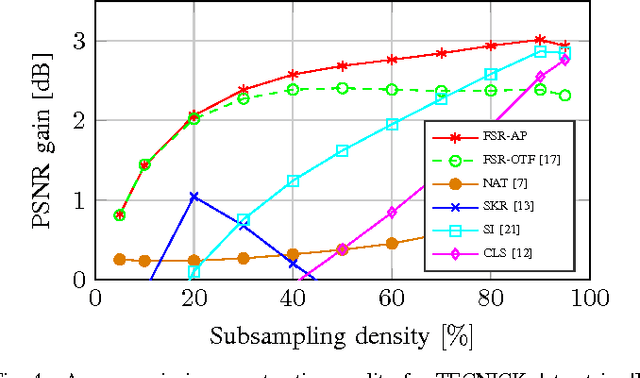
Image signals typically are defined on a rectangular two-dimensional grid. However, there exist scenarios where this is not fulfilled and where the image information only is available for a non-regular subset of pixel position. For processing, transmitting or displaying such an image signal, a re-sampling to a regular grid is required. Recently, Frequency Selective Reconstruction (FSR) has been proposed as a very effective sparsity-based algorithm for solving this under-determined problem. For this, FSR iteratively generates a model of the signal in the Fourier-domain. In this context, a fixed frequency prior inspired by the optical transfer function is used for favoring low-frequency content. However, this fixed prior is often too strict and may lead to a reduced reconstruction quality. To resolve this weakness, this paper proposes an adaptive frequency prior which takes the local density of the available samples into account. The proposed adaptive prior allows for a very high reconstruction quality, yielding gains of up to 0.6 dB PSNR over the fixed prior, independently of the density of the available samples. Compared to other state-of-the-art algorithms, visually noticeable gains of several dB are possible.
Cancer Subtyping by Improved Transcriptomic Features Using Vector Quantized Variational Autoencoder
Jul 20, 2022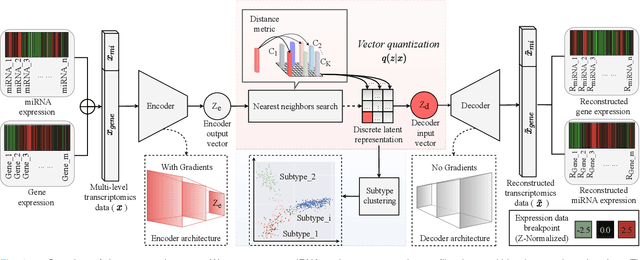
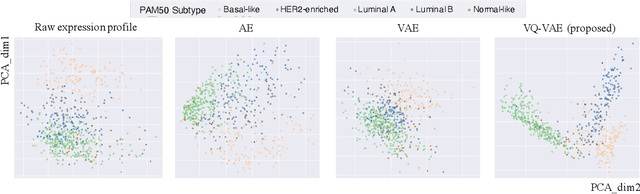
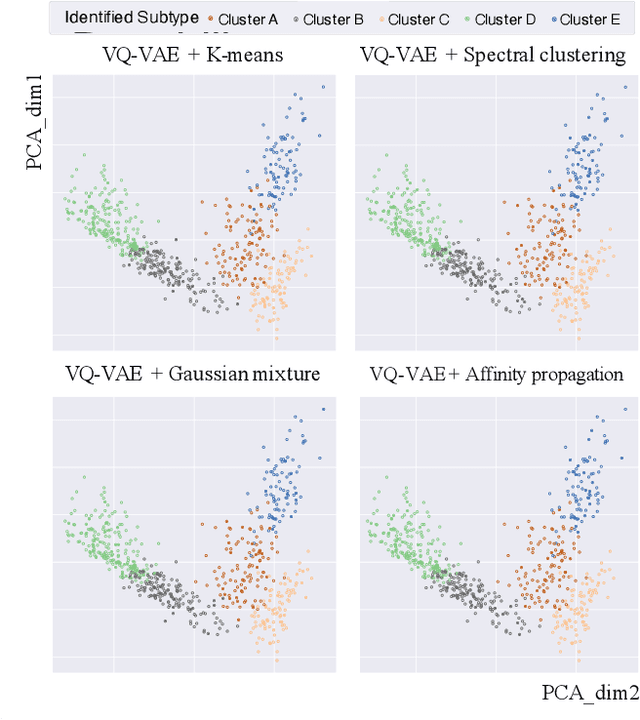
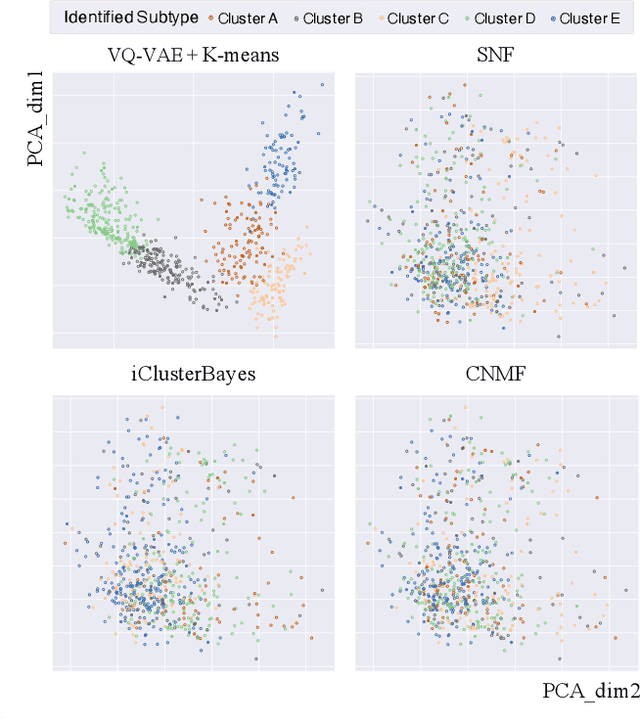
Defining and separating cancer subtypes is essential for facilitating personalized therapy modality and prognosis of patients. The definition of subtypes has been constantly recalibrated as a result of our deepened understanding. During this recalibration, researchers often rely on clustering of cancer data to provide an intuitive visual reference that could reveal the intrinsic characteristics of subtypes. The data being clustered are often omics data such as transcriptomics that have strong correlations to the underlying biological mechanism. However, while existing studies have shown promising results, they suffer from issues associated with omics data: sample scarcity and high dimensionality. As such, existing methods often impose unrealistic assumptions to extract useful features from the data while avoiding overfitting to spurious correlations. In this paper, we propose to leverage a recent strong generative model, Vector Quantized Variational AutoEncoder (VQ-VAE), to tackle the data issues and extract informative latent features that are crucial to the quality of subsequent clustering by retaining only information relevant to reconstructing the input. VQ-VAE does not impose strict assumptions and hence its latent features are better representations of the input, capable of yielding superior clustering performance with any mainstream clustering method. Extensive experiments and medical analysis on multiple datasets comprising 10 distinct cancers demonstrate the VQ-VAE clustering results can significantly and robustly improve prognosis over prevalent subtyping systems.