 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
QoE-Aware Resource Allocation for Semantic Communication Networks
May 28, 2022
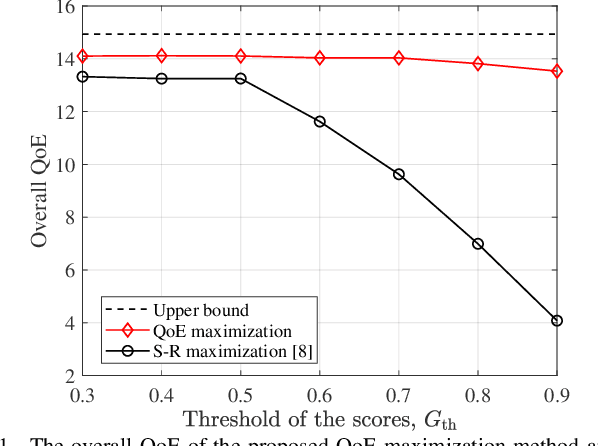
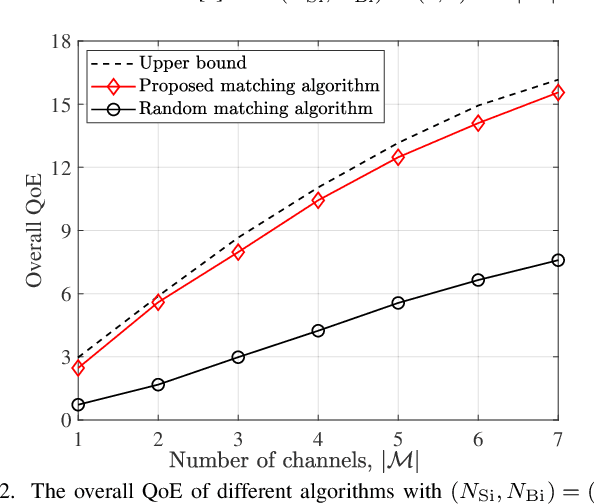
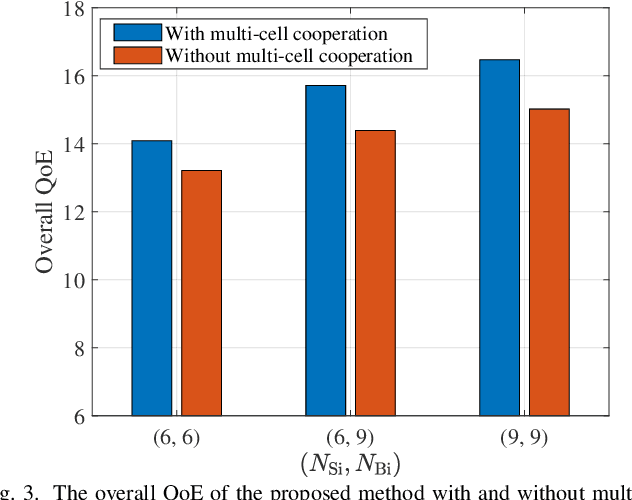
With the aim of accomplishing intelligence tasks, semantic communications transmit task-related information only, yielding significant performance gains over conventional communications. To guarantee user requirements for different types of tasks, we perform the semantic-aware resource allocation in a multi-cell multi-task network in this paper. Specifically, an approximate measure of semantic entropy is first developed to quantify the semantic information for different tasks, based on which a novel quality-of-experience (QoE) model is proposed. We formulate the QoE-aware semantic resource allocation in terms of the number of transmitted semantic symbols, channel assignment, and power allocation. To solve this problem, we first decouple it into two independent subproblems. The first one is to optimize the number of transmitted semantic symbols with given channel assignment and power allocation, which is solved by the exhaustive searching method. The second one is the channel assignment and power allocation subproblem, which is modeled as a many-to-one matching game and solved by the proposed low-complexity matching algorithm. Simulation results demonstrate the effectiveness and superiority of the proposed method on the overall QoE.
Dataset of Propaganda Techniques of the State-Sponsored Information Operation of the People's Republic of China
Jun 14, 2021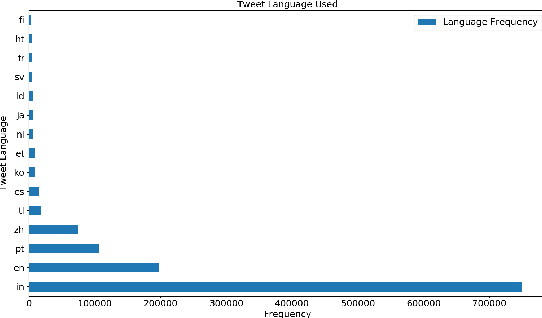

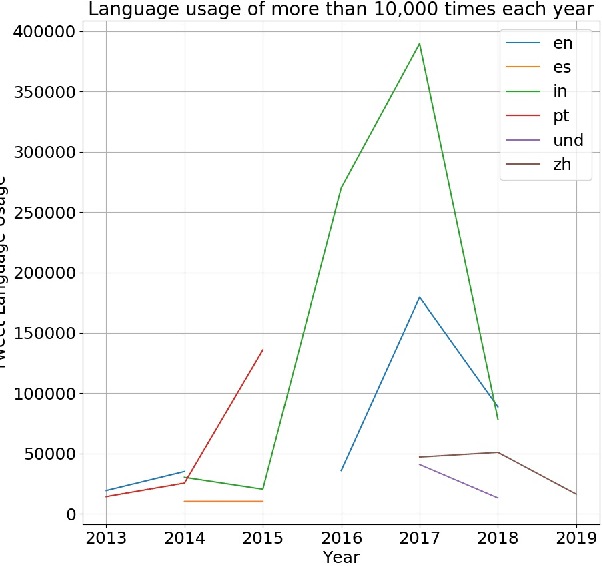

The digital media, identified as computational propaganda provides a pathway for propaganda to expand its reach without limit. State-backed propaganda aims to shape the audiences' cognition toward entities in favor of a certain political party or authority. Furthermore, it has become part of modern information warfare used in order to gain an advantage over opponents. Most of the current studies focus on using machine learning, quantitative, and qualitative methods to distinguish if a certain piece of information on social media is propaganda. Mainly conducted on English content, but very little research addresses Chinese Mandarin content. From propaganda detection, we want to go one step further to provide more fine-grained information on propaganda techniques that are applied. In this research, we aim to bridge the information gap by providing a multi-labeled propaganda techniques dataset in Mandarin based on a state-backed information operation dataset provided by Twitter. In addition to presenting the dataset, we apply a multi-label text classification using fine-tuned BERT. Potentially this could help future research in detecting state-backed propaganda online especially in a cross-lingual context and cross platforms identity consolidation.
Decision-making with E-admissibility given a finite assessment of choices
Apr 15, 2022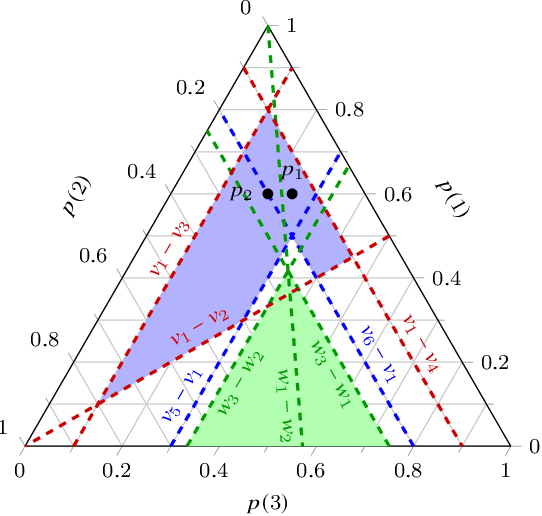
Given information about which options a decision-maker definitely rejects from given finite sets of options, we study the implications for decision-making with E-admissibility. This means that from any finite set of options, we reject those options that no probability mass function compatible with the given information gives the highest expected utility. We use the mathematical framework of choice functions to specify choices and rejections, and specify the available information in the form of conditions on such functions. We characterise the most conservative extension of the given information to a choice function that makes choices based on E-admissibility, and provide an algorithm that computes this extension by solving linear feasibility problems.
Two-Stage COVID19 Classification Using BERT Features
Jun 29, 2022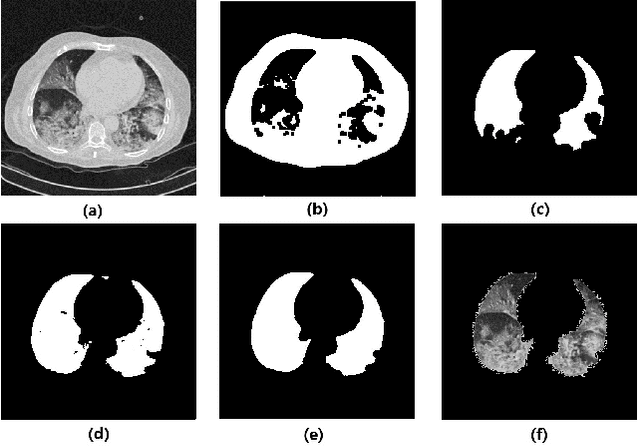
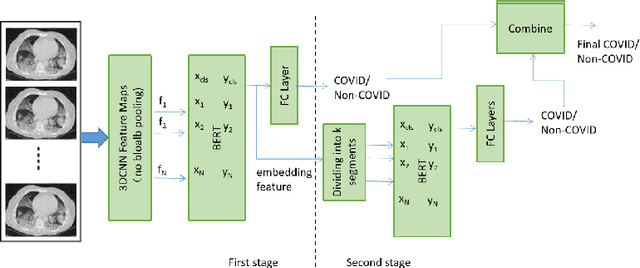
We propose an automatic COVID1-19 diagnosis framework from lung CT-scan slice images using double BERT feature extraction. In the first BERT feature extraction, A 3D-CNN is first used to extract CNN internal feature maps. Instead of using the global average pooling, a late BERT temporal pooing is used to aggregate the temporal information in these feature maps, followed by a classification layer. This 3D-CNN-BERT classification network is first trained on sampled fixed number of slice images from every original CT scan volume. In the second stage, the 3D-CNN-BERT embedding features are extracted on all slice images of every CT scan volume, and these features are averaged into a fixed number of segments. Then another BERT network is used to aggregate these multiple features into a single feature followed by another classification layer. The classification results of both stages are combined to generate final outputs. On the validation dataset, we achieve macro F1 score of 0.9164.
Cascading Residual Graph Convolutional Network for Multi-Behavior Recommendation
May 26, 2022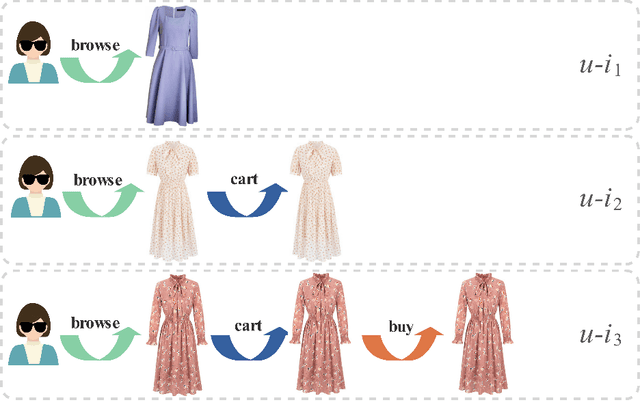

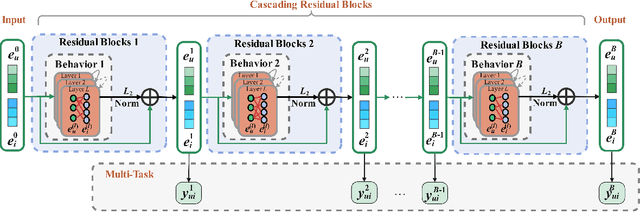
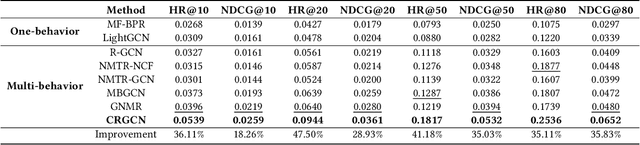
Multi-behavior recommendation exploits multiple types of user-item interactions to alleviate the data sparsity problem faced by the traditional models that often utilize only one type of interaction for recommendation. In real scenarios, users often take a sequence of actions to interact with an item, in order to get more information about the item and thus accurately evaluate whether an item fits personal preference. Those interaction behaviors often obey a certain order, and different behaviors reveal different information or aspects of user preferences towards the target item. Most existing multi-behavior recommendation methods take the strategy to first extract information from different behaviors separately and then fuse them for final prediction. However, they have not exploited the connections between different behaviors to learn user preferences. Besides, they often introduce complex model structures and more parameters to model multiple behaviors, largely increasing the space and time complexity. In this work, we propose a lightweight multi-behavior recommendation model named Cascading Residual Graph Convolutional Network (CRGCN for short), which can explicitly exploit the connections between different behaviors into the embedding learning process without introducing any additional parameters. In particular, we design a cascading residual graph convolutional network structure, which enables our model to learn user preferences by continuously refining user embeddings across different types of behaviors. The multi-task learning method is adopted to jointly optimize our model based on different behaviors. Extensive experimental results on two real-world benchmark datasets show that CRGCN can substantially outperform state-of-the-art methods. Further studies also analyze the effects of leveraging multi-behaviors in different numbers and orders on the final performance.
Wayformer: Motion Forecasting via Simple & Efficient Attention Networks
Jul 12, 2022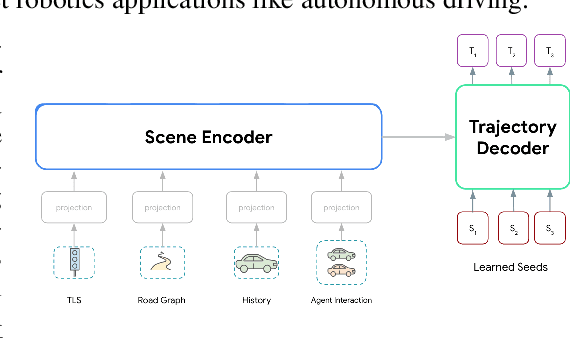
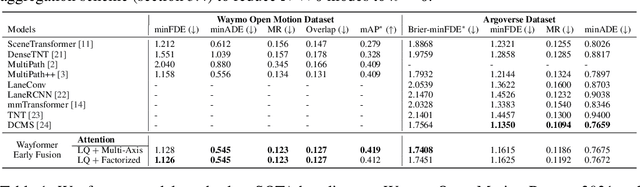
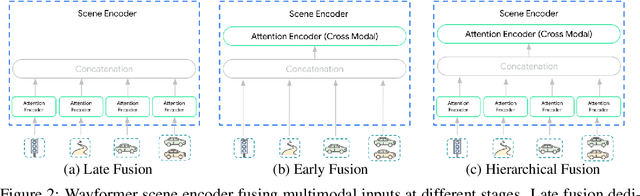
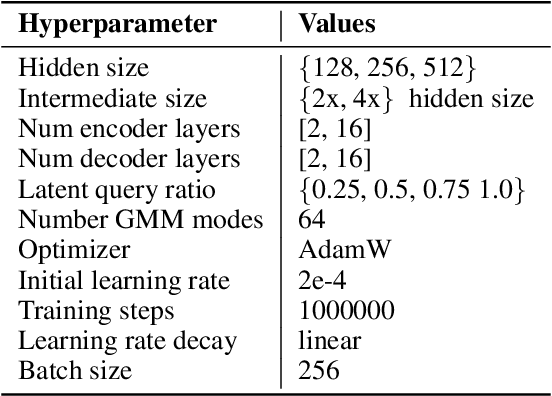
Motion forecasting for autonomous driving is a challenging task because complex driving scenarios result in a heterogeneous mix of static and dynamic inputs. It is an open problem how best to represent and fuse information about road geometry, lane connectivity, time-varying traffic light state, and history of a dynamic set of agents and their interactions into an effective encoding. To model this diverse set of input features, many approaches proposed to design an equally complex system with a diverse set of modality specific modules. This results in systems that are difficult to scale, extend, or tune in rigorous ways to trade off quality and efficiency. In this paper, we present Wayformer, a family of attention based architectures for motion forecasting that are simple and homogeneous. Wayformer offers a compact model description consisting of an attention based scene encoder and a decoder. In the scene encoder we study the choice of early, late and hierarchical fusion of the input modalities. For each fusion type we explore strategies to tradeoff efficiency and quality via factorized attention or latent query attention. We show that early fusion, despite its simplicity of construction, is not only modality agnostic but also achieves state-of-the-art results on both Waymo Open MotionDataset (WOMD) and Argoverse leaderboards, demonstrating the effectiveness of our design philosophy
Auditing Visualizations: Transparency Methods Struggle to Detect Anomalous Behavior
Jun 27, 2022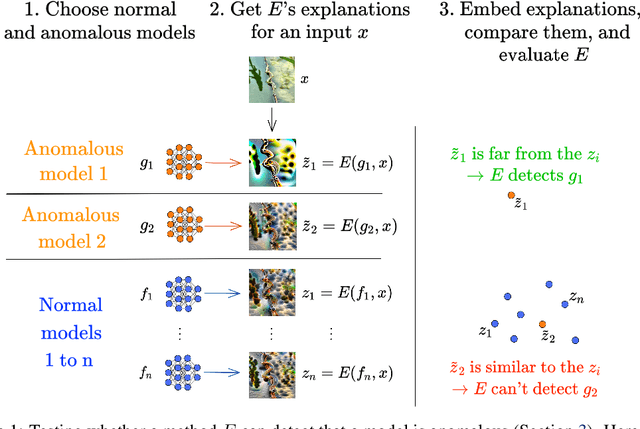

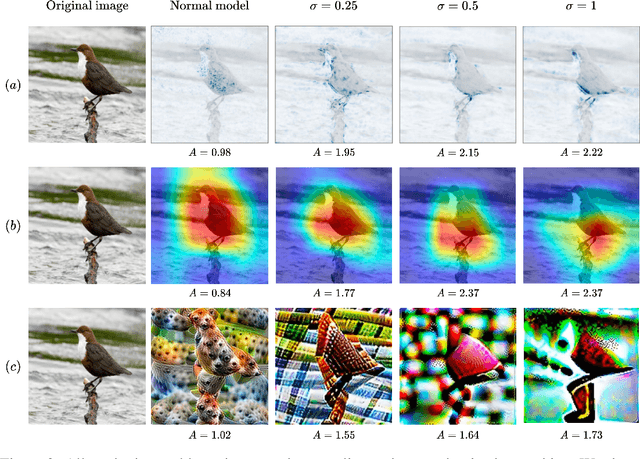
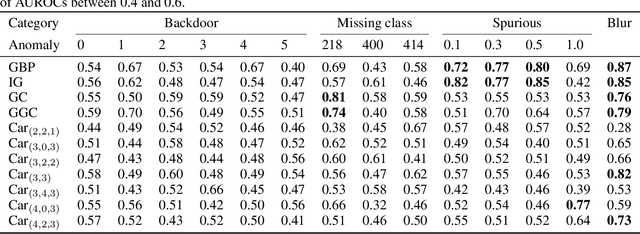
Transparency methods such as model visualizations provide information that outputs alone might miss, since they describe the internals of neural networks. But can we trust that model explanations reflect model behavior? For instance, can they diagnose abnormal behavior such as backdoors or shape bias? To evaluate model explanations, we define a model as anomalous if it differs from a reference set of normal models, and we test whether transparency methods assign different explanations to anomalous and normal models. We find that while existing methods can detect stark anomalies such as shape bias or adversarial training, they struggle to identify more subtle anomalies such as models trained on incomplete data. Moreover, they generally fail to distinguish the inputs that induce anomalous behavior, e.g. images containing a backdoor trigger. These results reveal new blind spots in existing model explanations, pointing to the need for further method development.
Toward Consistent and Efficient Map-based Visual-inertial Localization: Theory Framework and Filter Design
Apr 26, 2022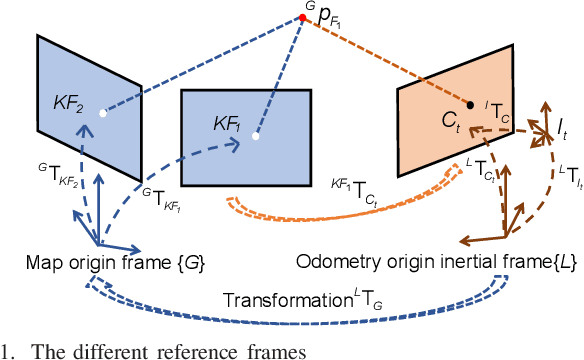
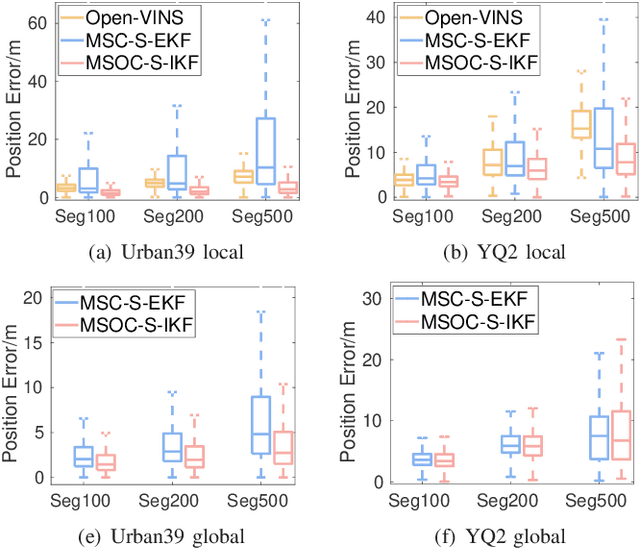
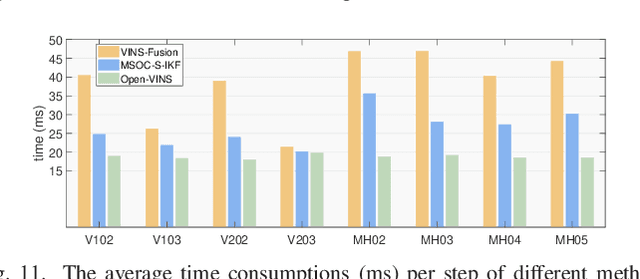
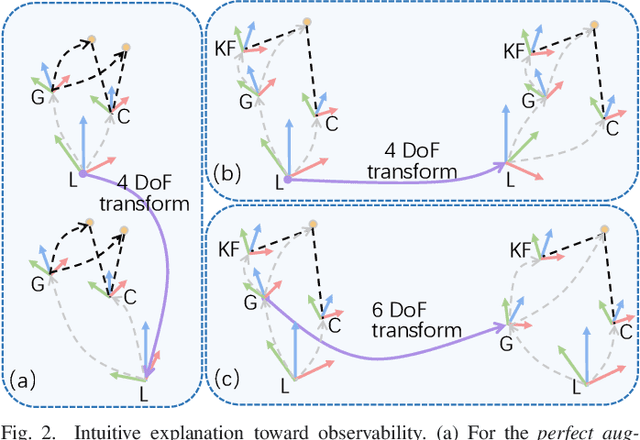
This paper focuses on designing a consistent and efficient filter for map-based visual-inertial localization. First, we propose a new Lie group with its algebra, based on which a novel invariant extended Kalman filter (invariant EKF) is designed. We theoretically prove that, when we do not consider the uncertainty of the map information, the proposed invariant EKF can naturally maintain the correct observability properties of the system. To consider the uncertainty of the map information, we introduce a Schmidt filter. With the Schmidt filter, the uncertainty of the map information can be taken into consideration to avoid over-confident estimation while the computation cost only increases linearly with the size of the map keyframes. In addition, we introduce an easily implemented observability-constrained technique because directly combining the invariant EKF with the Schmidt filter cannot maintain the correct observability properties of the system that considers the uncertainty of the map information. Finally, we validate our proposed system's high consistency, accuracy, and efficiency via extensive simulations and real-world experiments.
Hyperbolic Relevance Matching for Neural Keyphrase Extraction
May 04, 2022


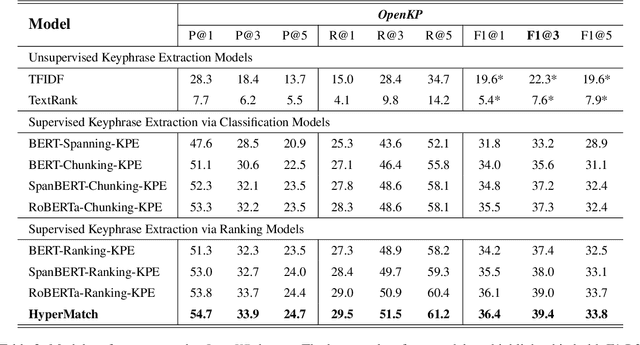
Keyphrase extraction is a fundamental task in natural language processing and information retrieval that aims to extract a set of phrases with important information from a source document. Identifying important keyphrase is the central component of the keyphrase extraction task, and its main challenge is how to represent information comprehensively and discriminate importance accurately. In this paper, to address these issues, we design a new hyperbolic matching model (HyperMatch) to represent phrases and documents in the same hyperbolic space and explicitly estimate the phrase-document relevance via the Poincar\'e distance as the important score of each phrase. Specifically, to capture the hierarchical syntactic and semantic structure information, HyperMatch takes advantage of the hidden representations in multiple layers of RoBERTa and integrates them as the word embeddings via an adaptive mixing layer. Meanwhile, considering the hierarchical structure hidden in the document, HyperMatch embeds both phrases and documents in the same hyperbolic space via a hyperbolic phrase encoder and a hyperbolic document encoder. This strategy can further enhance the estimation of phrase-document relevance due to the good properties of hyperbolic space. In this setting, the keyphrase extraction can be taken as a matching problem and effectively implemented by minimizing a hyperbolic margin-based triplet loss. Extensive experiments are conducted on six benchmarks and demonstrate that HyperMatch outperforms the state-of-the-art baselines.
Variational Transformer: A Framework Beyond the Trade-off between Accuracy and Diversity for Image Captioning
May 28, 2022
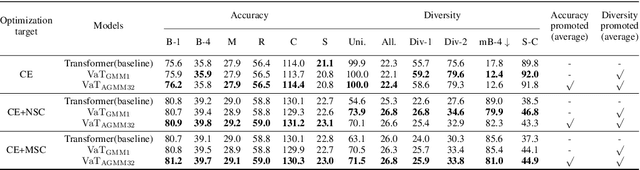
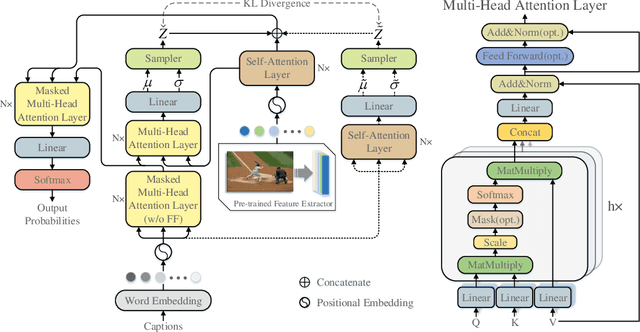
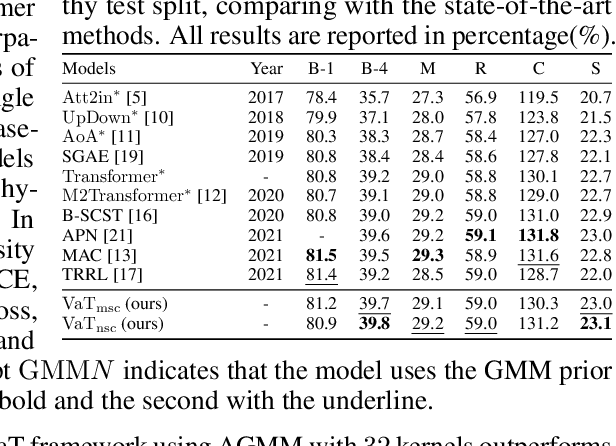
Accuracy and Diversity are two essential metrizable manifestations in generating natural and semantically correct captions. Many efforts have been made to enhance one of them with another decayed due to the trade-off gap. However, compromise does not make the progress. Decayed diversity makes the captioner a repeater, and decayed accuracy makes it a fake advisor. In this work, we exploit a novel Variational Transformer framework to improve accuracy and diversity simultaneously. To ensure accuracy, we introduce the "Invisible Information Prior" along with the "Auto-selectable GMM" to instruct the encoder to learn the precise language information and object relation in different scenes. To ensure diversity, we propose the "Range-Median Reward" baseline to retain more diverse candidates with higher rewards during the RL-based training process. Experiments show that our method achieves the simultaneous promotion of accuracy (CIDEr) and diversity (self-CIDEr), up to 1.1 and 4.8 percent, compared with the baseline. Also, our method outperforms others under the newly proposed measurement of the trade-off gap, with at least 3.55 percent promotion.