 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Feature Aggregation in Zero-Shot Cross-Lingual Transfer Using Multilingual BERT
May 17, 2022
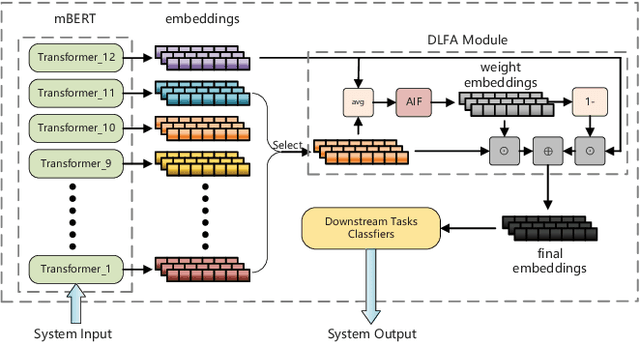
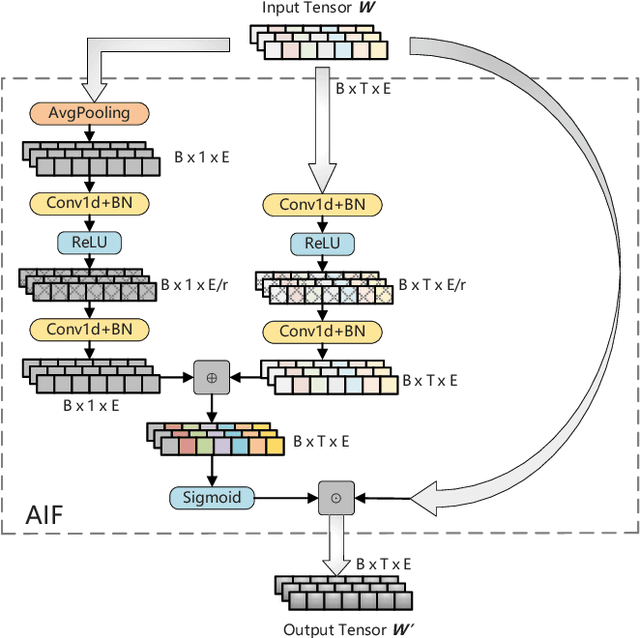
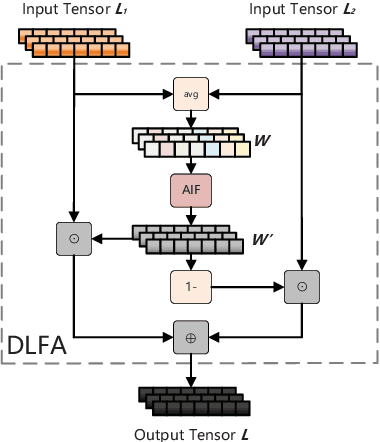
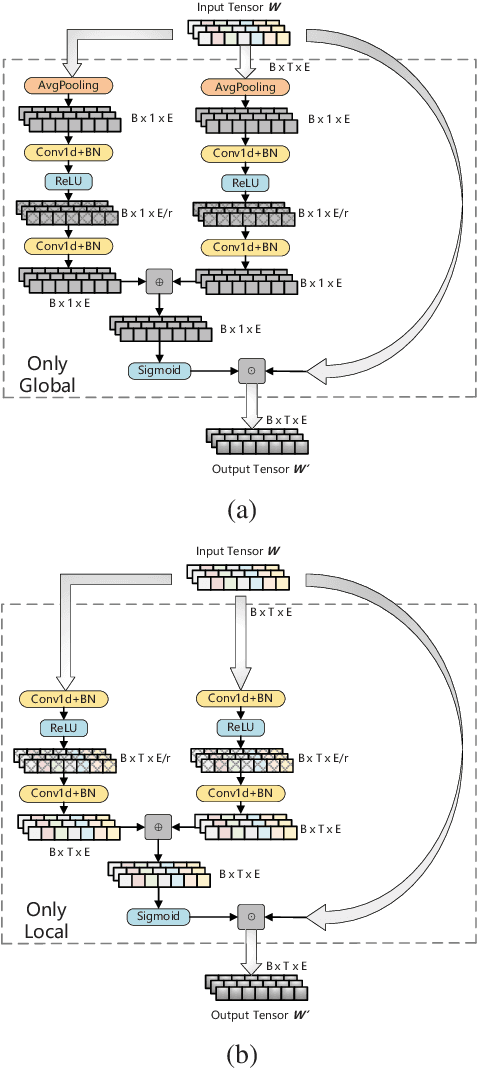
Multilingual BERT (mBERT), a language model pre-trained on large multilingual corpora, has impressive zero-shot cross-lingual transfer capabilities and performs surprisingly well on zero-shot POS tagging and Named Entity Recognition (NER), as well as on cross-lingual model transfer. At present, the mainstream methods to solve the cross-lingual downstream tasks are always using the last transformer layer's output of mBERT as the representation of linguistic information. In this work, we explore the complementary property of lower layers to the last transformer layer of mBERT. A feature aggregation module based on an attention mechanism is proposed to fuse the information contained in different layers of mBERT. The experiments are conducted on four zero-shot cross-lingual transfer datasets, and the proposed method obtains performance improvements on key multilingual benchmark tasks XNLI (+1.5 %), PAWS-X (+2.4 %), NER (+1.2 F1), and POS (+1.5 F1). Through the analysis of the experimental results, we prove that the layers before the last layer of mBERT can provide extra useful information for cross-lingual downstream tasks and explore the interpretability of mBERT empirically.
NSNet: Non-saliency Suppression Sampler for Efficient Video Recognition
Jul 21, 2022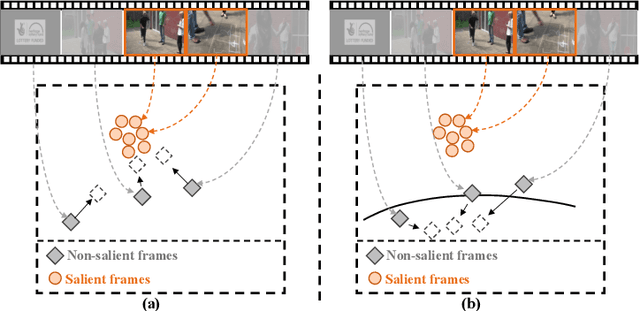
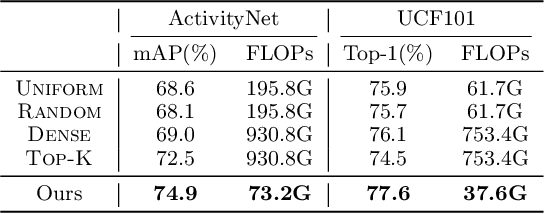

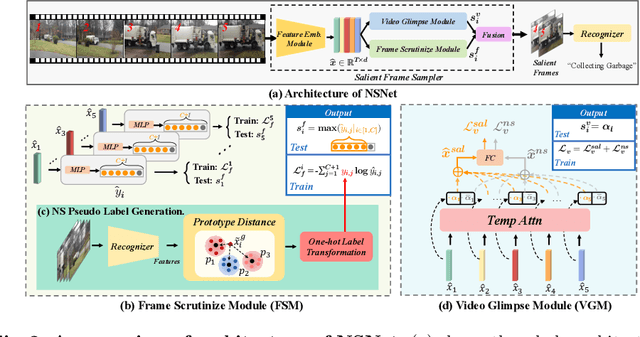
It is challenging for artificial intelligence systems to achieve accurate video recognition under the scenario of low computation costs. Adaptive inference based efficient video recognition methods typically preview videos and focus on salient parts to reduce computation costs. Most existing works focus on complex networks learning with video classification based objectives. Taking all frames as positive samples, few of them pay attention to the discrimination between positive samples (salient frames) and negative samples (non-salient frames) in supervisions. To fill this gap, in this paper, we propose a novel Non-saliency Suppression Network (NSNet), which effectively suppresses the responses of non-salient frames. Specifically, on the frame level, effective pseudo labels that can distinguish between salient and non-salient frames are generated to guide the frame saliency learning. On the video level, a temporal attention module is learned under dual video-level supervisions on both the salient and the non-salient representations. Saliency measurements from both two levels are combined for exploitation of multi-granularity complementary information. Extensive experiments conducted on four well-known benchmarks verify our NSNet not only achieves the state-of-the-art accuracy-efficiency trade-off but also present a significantly faster (2.4~4.3x) practical inference speed than state-of-the-art methods. Our project page is at https://lawrencexia2008.github.io/projects/nsnet .
When Does Syntax Mediate Neural Language Model Performance? Evidence from Dropout Probes
Apr 20, 2022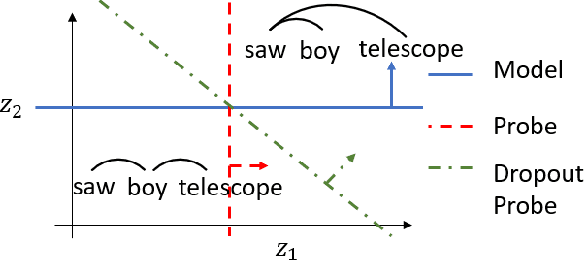
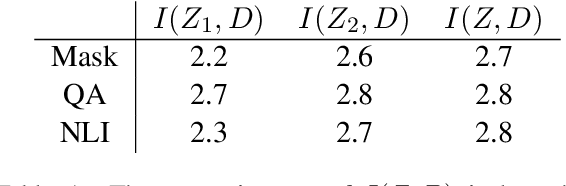
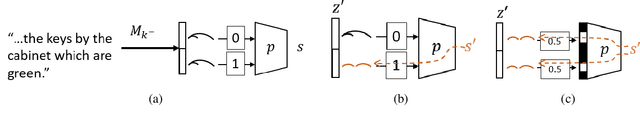

Recent causal probing literature reveals when language models and syntactic probes use similar representations. Such techniques may yield "false negative" causality results: models may use representations of syntax, but probes may have learned to use redundant encodings of the same syntactic information. We demonstrate that models do encode syntactic information redundantly and introduce a new probe design that guides probes to consider all syntactic information present in embeddings. Using these probes, we find evidence for the use of syntax in models where prior methods did not, allowing us to boost model performance by injecting syntactic information into representations.
Continuous Temporal Graph Networks for Event-Based Graph Data
May 31, 2022
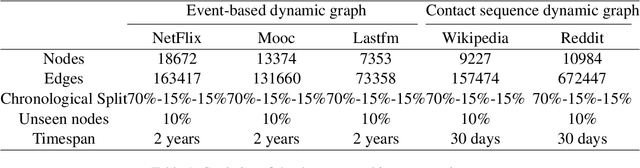
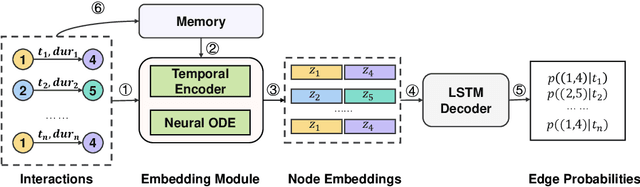
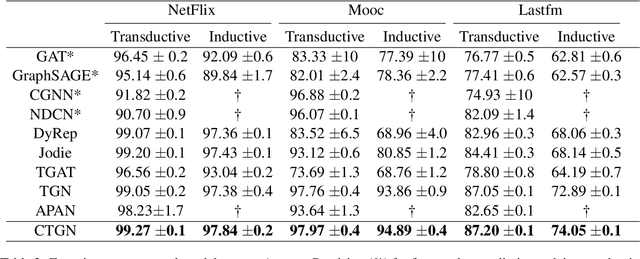
There has been an increasing interest in modeling continuous-time dynamics of temporal graph data. Previous methods encode time-evolving relational information into a low-dimensional representation by specifying discrete layers of neural networks, while real-world dynamic graphs often vary continuously over time. Hence, we propose Continuous Temporal Graph Networks (CTGNs) to capture the continuous dynamics of temporal graph data. We use both the link starting timestamps and link duration as evolving information to model the continuous dynamics of nodes. The key idea is to use neural ordinary differential equations (ODE) to characterize the continuous dynamics of node representations over dynamic graphs. We parameterize ordinary differential equations using a novel graph neural network. The existing dynamic graph networks can be considered as a specific discretization of CTGNs. Experiment results on both transductive and inductive tasks demonstrate the effectiveness of our proposed approach over competitive baselines.
Towards Privacy-Preserving Person Re-identification via Person Identify Shift
Jul 15, 2022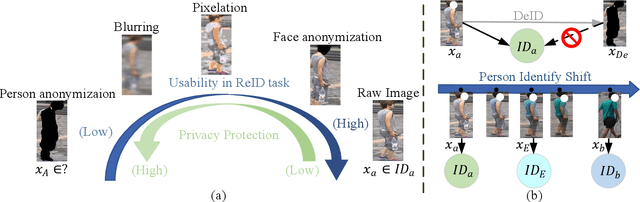
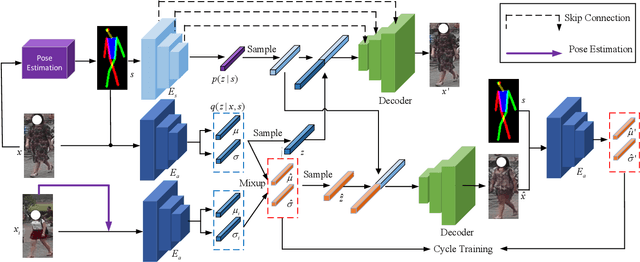


Recently privacy concerns of person re-identification (ReID) raise more and more attention and preserving the privacy of the pedestrian images used by ReID methods become essential. De-identification (DeID) methods alleviate privacy issues by removing the identity-related of the ReID data. However, most of the existing DeID methods tend to remove all personal identity-related information and compromise the usability of de-identified data on the ReID task. In this paper, we aim to develop a technique that can achieve a good trade-off between privacy protection and data usability for person ReID. To achieve this, we propose a novel de-identification method designed explicitly for person ReID, named Person Identify Shift (PIS). PIS removes the absolute identity in a pedestrian image while preserving the identity relationship between image pairs. By exploiting the interpolation property of variational auto-encoder, PIS shifts each pedestrian image from the current identity to another with a new identity, resulting in images still preserving the relative identities. Experimental results show that our method has a better trade-off between privacy-preserving and model performance than existing de-identification methods and can defend against human and model attacks for data privacy.
Local Byte Fusion for Neural Machine Translation
May 23, 2022
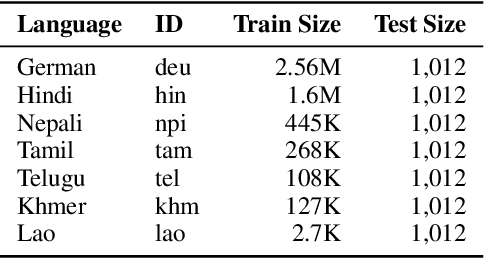
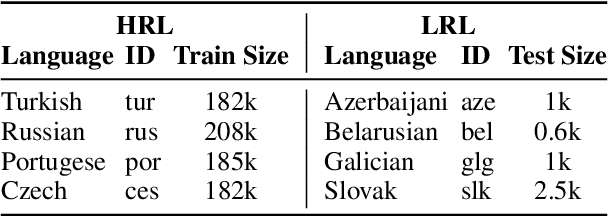
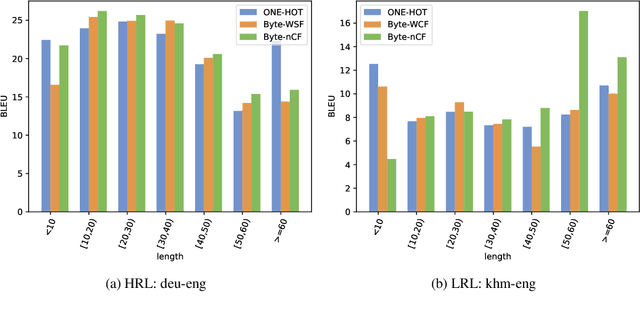
Subword tokenization schemes are the dominant technique used in current NLP models. However, such schemes can be rigid and tokenizers built on one corpus do not adapt well to other parallel corpora. It has also been observed that in multilingual corpora, subword tokenization schemes over-segment low-resource languages leading to a drop in translation performance. A simple alternative to subword tokenizers is byte-based methods i.e. tokenization into byte sequences using encoding schemes such as UTF-8. Byte tokens often represent inputs at a sub-character granularity i.e. one character can be represented by a sequence of multiple byte tokens. This results in byte sequences that are significantly longer than character sequences. Enforcing aggregation of local information in the lower layers can guide the model to build higher-level semantic information. We propose a Local Byte Fusion (LOBEF) method for byte-based machine translation -- utilizing byte $n$-gram and word boundaries -- to aggregate local semantic information. Extensive experiments on multilingual translation, zero-shot cross-lingual transfer, and domain adaptation reveal a consistent improvement over traditional byte-based models and even over subword techniques. Further analysis also indicates that our byte-based models are parameter-efficient and can be trained faster than subword models.
"Why do so?" -- A Practical Perspective on Machine Learning Security
Jul 11, 2022
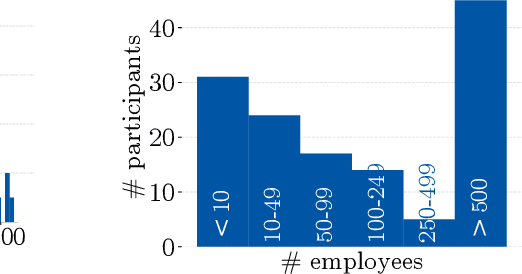
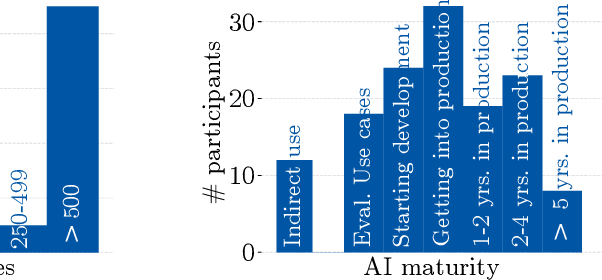

Despite the large body of academic work on machine learning security, little is known about the occurrence of attacks on machine learning systems in the wild. In this paper, we report on a quantitative study with 139 industrial practitioners. We analyze attack occurrence and concern and evaluate statistical hypotheses on factors influencing threat perception and exposure. Our results shed light on real-world attacks on deployed machine learning. On the organizational level, while we find no predictors for threat exposure in our sample, the amount of implement defenses depends on exposure to threats or expected likelihood to become a target. We also provide a detailed analysis of practitioners' replies on the relevance of individual machine learning attacks, unveiling complex concerns like unreliable decision making, business information leakage, and bias introduction into models. Finally, we find that on the individual level, prior knowledge about machine learning security influences threat perception. Our work paves the way for more research about adversarial machine learning in practice, but yields also insights for regulation and auditing.
Multimodal Dialogue State Tracking
Jun 16, 2022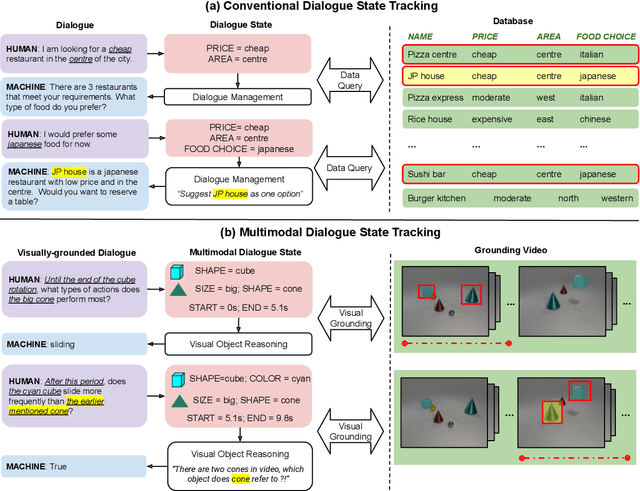
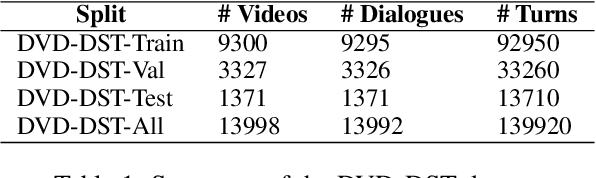
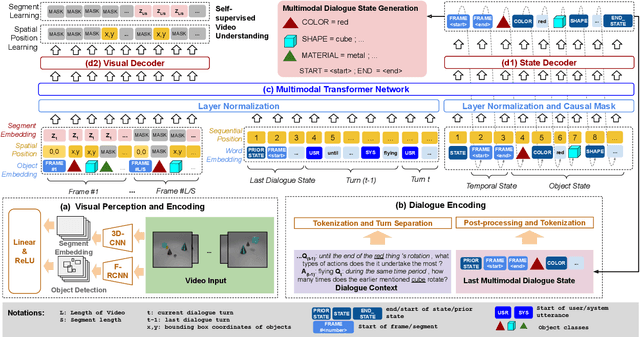
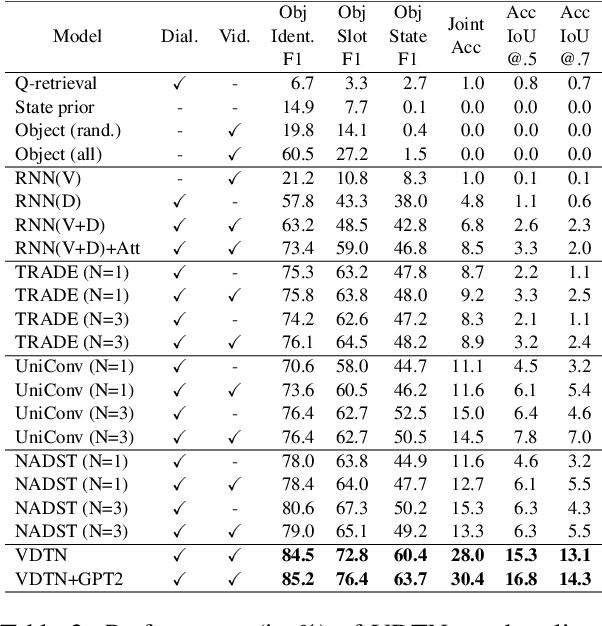
Designed for tracking user goals in dialogues, a dialogue state tracker is an essential component in a dialogue system. However, the research of dialogue state tracking has largely been limited to unimodality, in which slots and slot values are limited by knowledge domains (e.g. restaurant domain with slots of restaurant name and price range) and are defined by specific database schema. In this paper, we propose to extend the definition of dialogue state tracking to multimodality. Specifically, we introduce a novel dialogue state tracking task to track the information of visual objects that are mentioned in video-grounded dialogues. Each new dialogue utterance may introduce a new video segment, new visual objects, or new object attributes, and a state tracker is required to update these information slots accordingly. We created a new synthetic benchmark and designed a novel baseline, Video-Dialogue Transformer Network (VDTN), for this task. VDTN combines both object-level features and segment-level features and learns contextual dependencies between videos and dialogues to generate multimodal dialogue states. We optimized VDTN for a state generation task as well as a self-supervised video understanding task which recovers video segment or object representations. Finally, we trained VDTN to use the decoded states in a response prediction task. Together with comprehensive ablation and qualitative analysis, we discovered interesting insights towards building more capable multimodal dialogue systems.
Identifying public values and spatial conflicts in urban planning
Jul 18, 2022
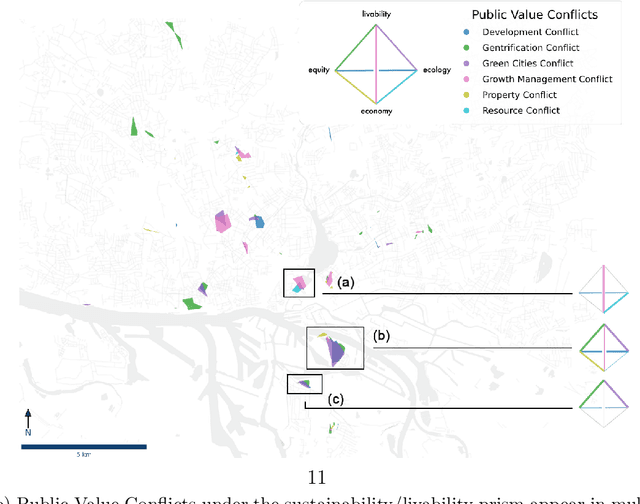
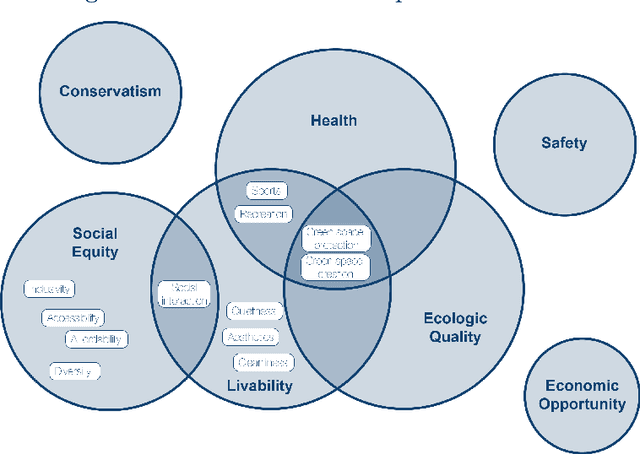
Identifying the diverse and often competing values of citizens, and resolving the consequent public value conflicts, are of significant importance for inclusive and integrated urban development. Scholars have highlighted that relational, value-laden urban space gives rise to many diverse conflicts that vary both spatially and temporally. Although notions of public value conflicts have been conceived in theory, there are very few empirical studies that identify such values and their conflicts in urban space. Building on public value theory and using a case-study mixed-methods approach, this paper proposes a new approach to empirically investigate public value conflicts in urban space. Using unstructured participatory data of 4,528 citizen contributions from a Public Participation Geographic Information Systems in Hamburg, Germany, natural language processing and spatial clustering techniques are used to identify areas of potential value conflicts. Four expert workshops assess and interpret these quantitative findings. Integrating both quantitative and qualitative results, 19 general public values and a total of 9 archetypical conflicts are identified. On the basis of these results, this paper proposes a new conceptual tool of Public Value Spheres that extends the theoretical notion of public-value conflicts and helps to further account for the value-laden nature of urban space.
MNet: Rethinking 2D/3D Networks for Anisotropic Medical Image Segmentation
May 10, 2022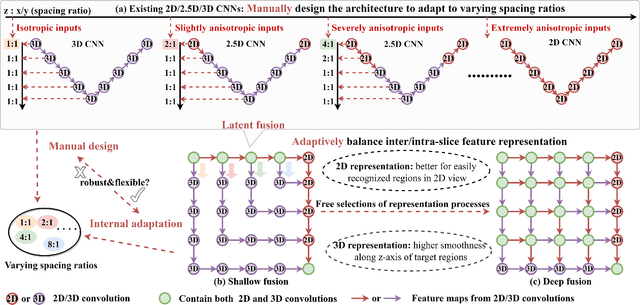
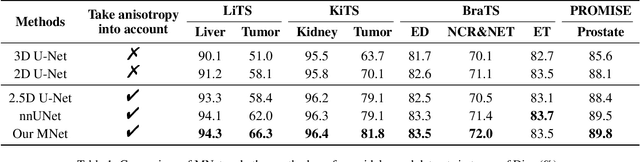
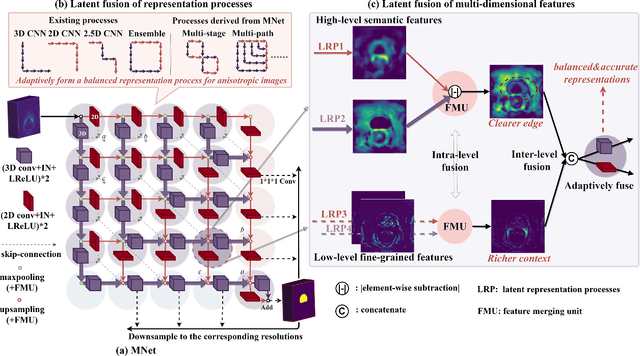

The nature of thick-slice scanning causes severe inter-slice discontinuities of 3D medical images, and the vanilla 2D/3D convolutional neural networks (CNNs) fail to represent sparse inter-slice information and dense intra-slice information in a balanced way, leading to severe underfitting to inter-slice features (for vanilla 2D CNNs) and overfitting to noise from long-range slices (for vanilla 3D CNNs). In this work, a novel mesh network (MNet) is proposed to balance the spatial representation inter axes via learning. 1) Our MNet latently fuses plenty of representation processes by embedding multi-dimensional convolutions deeply into basic modules, making the selections of representation processes flexible, thus balancing representation for sparse inter-slice information and dense intra-slice information adaptively. 2) Our MNet latently fuses multi-dimensional features inside each basic module, simultaneously taking the advantages of 2D (high segmentation accuracy of the easily recognized regions in 2D view) and 3D (high smoothness of 3D organ contour) representations, thus obtaining more accurate modeling for target regions. Comprehensive experiments are performed on four public datasets (CT\&MR), the results consistently demonstrate the proposed MNet outperforms the other methods. The code and datasets are available at: https://github.com/zfdong-code/MNet