 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Is Lip Region-of-Interest Sufficient for Lipreading?
Jun 02, 2022
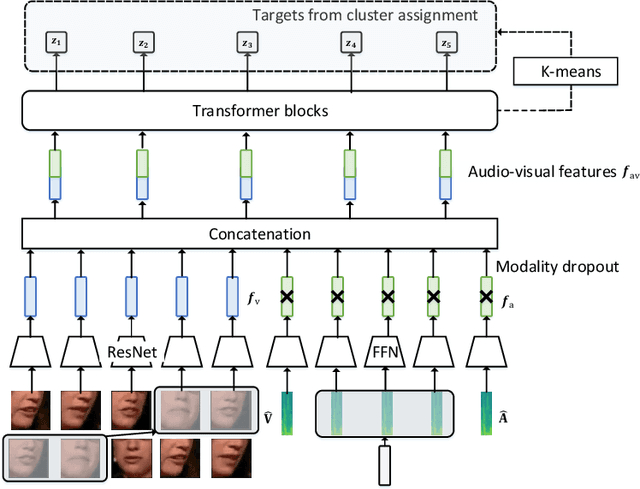
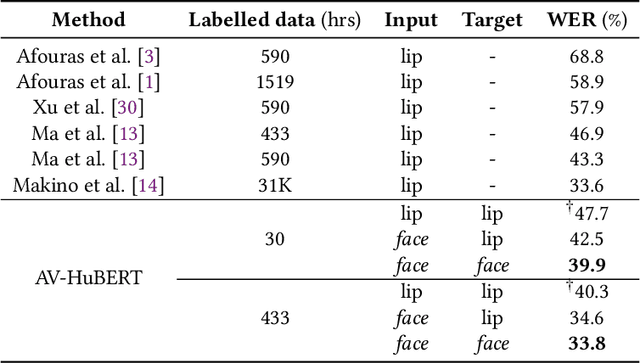

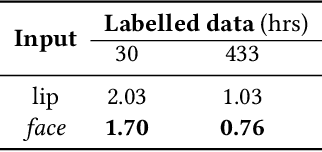
Lip region-of-interest (ROI) is conventionally used for visual input in the lipreading task. Few works have adopted the entire face as visual input because lip-excluded parts of the face are usually considered to be redundant and irrelevant to visual speech recognition. However, faces contain much more detailed information than lips, such as speakers' head pose, emotion, identity etc. We argue that such information might benefit visual speech recognition if a powerful feature extractor employing the entire face is trained. In this work, we propose to adopt the entire face for lipreading with self-supervised learning. AV-HuBERT, an audio-visual multi-modal self-supervised learning framework, was adopted in our experiments. Our experimental results showed that adopting the entire face achieved 16% relative word error rate (WER) reduction on the lipreading task, compared with the baseline method using lip as visual input. Without self-supervised pretraining, the model with face input achieved a higher WER than that using lip input in the case of limited training data (30 hours), while a slightly lower WER when using large amount of training data (433 hours).
The information of attribute uncertainties: what convolutional neural networks can learn about errors in input data
Aug 10, 2021

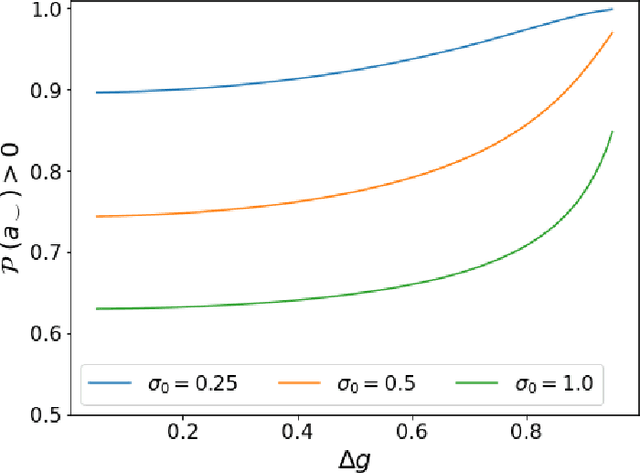
Errors in measurements are key to weighting the value of data, but are often neglected in Machine Learning (ML). We show how Convolutional Neural Networks (CNNs) are able to learn about the context and patterns of signal and noise, leading to improvements in the performance of classification methods. We construct a model whereby two classes of objects follow an underlying Gaussian distribution, and where the features (the input data) have varying, but known, levels of noise. This model mimics the nature of scientific data sets, where the noises arise as realizations of some random processes whose underlying distributions are known. The classification of these objects can then be performed using standard statistical techniques (e.g., least-squares minimization or Markov-Chain Monte Carlo), as well as ML techniques. This allows us to take advantage of a maximum likelihood approach to object classification, and to measure the amount by which the ML methods are incorporating the information in the input data uncertainties. We show that, when each data point is subject to different levels of noise (i.e., noises with different distribution functions), that information can be learned by the CNNs, raising the ML performance to at least the same level of the least-squares method -- and sometimes even surpassing it. Furthermore, we show that, with varying noise levels, the confidence of the ML classifiers serves as a proxy for the underlying cumulative distribution function, but only if the information about specific input data uncertainties is provided to the CNNs.
Entropy-Based Feature Extraction For Real-Time Semantic Segmentation
Jul 07, 2022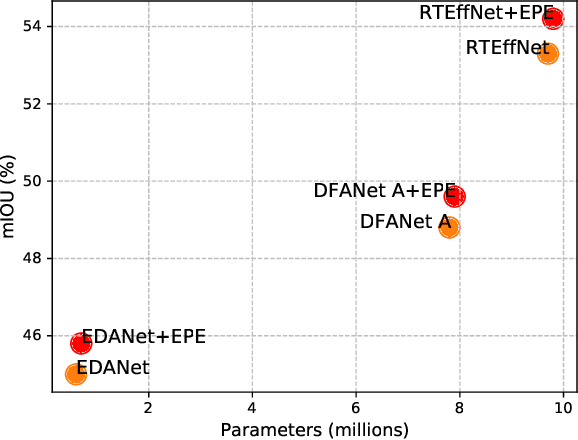
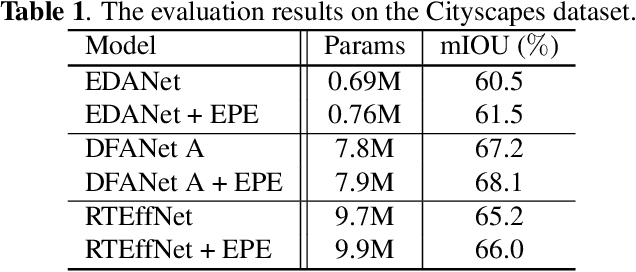
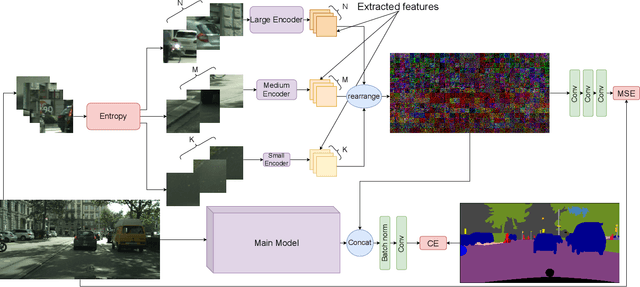

This paper introduces an efficient patch-based computational module, coined Entropy-based Patch Encoder (EPE) module, for resource-constrained semantic segmentation. The EPE module consists of three lightweight fully-convolutional encoders, each extracting features from image patches with a different amount of entropy. Patches with high entropy are being processed by the encoder with the largest number of parameters, patches with moderate entropy are processed by the encoder with a moderate number of parameters, and patches with low entropy are processed by the smallest encoder. The intuition behind the module is the following: as patches with high entropy contain more information, they need an encoder with more parameters, unlike low entropy patches, which can be processed using a small encoder. Consequently, processing part of the patches via the smaller encoder can significantly reduce the computational cost of the module. Experiments show that EPE can boost the performance of existing real-time semantic segmentation models with a slight increase in the computational cost. Specifically, EPE increases the mIOU performance of DFANet A by 0.9% with only 1.2% increase in the number of parameters and the mIOU performance of EDANet by 1% with 10% increase of the model parameters.
CrossCBR: Cross-view Contrastive Learning for Bundle Recommendation
Jun 08, 2022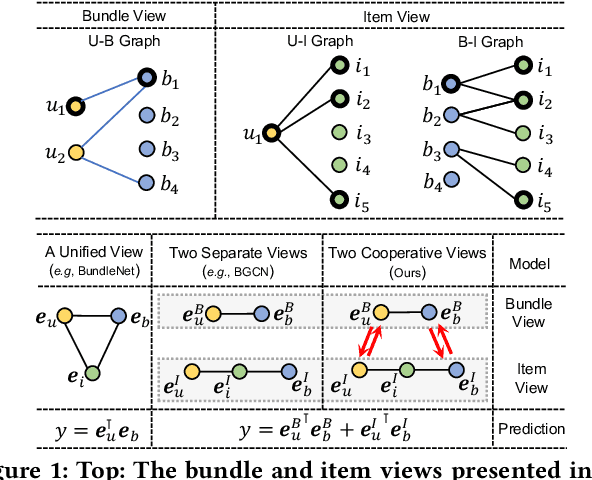
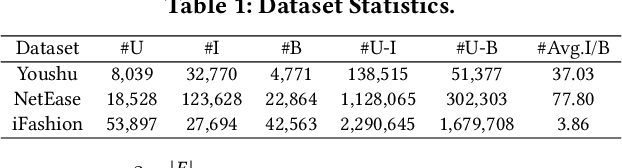
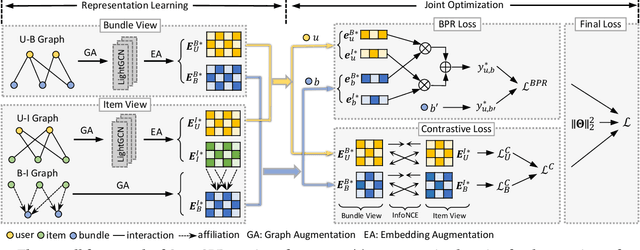
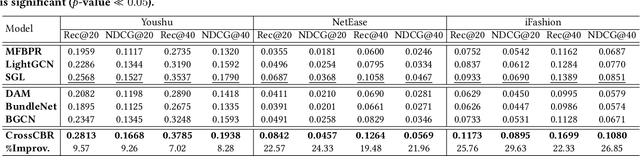
Bundle recommendation aims to recommend a bundle of related items to users, which can satisfy the users' various needs with one-stop convenience. Recent methods usually take advantage of both user-bundle and user-item interactions information to obtain informative representations for users and bundles, corresponding to bundle view and item view, respectively. However, they either use a unified view without differentiation or loosely combine the predictions of two separate views, while the crucial cooperative association between the two views' representations is overlooked. In this work, we propose to model the cooperative association between the two different views through cross-view contrastive learning. By encouraging the alignment of the two separately learned views, each view can distill complementary information from the other view, achieving mutual enhancement. Moreover, by enlarging the dispersion of different users/bundles, the self-discrimination of representations is enhanced. Extensive experiments on three public datasets demonstrate that our method outperforms SOTA baselines by a large margin. Meanwhile, our method requires minimal parameters of three set of embeddings (user, bundle, and item) and the computational costs are largely reduced due to more concise graph structure and graph learning module. In addition, various ablation and model studies demystify the working mechanism and justify our hypothesis. Codes and datasets are available at https://github.com/mysbupt/CrossCBR.
* 9 pages, 5 figures, 5 tables
Robust Generalization despite Distribution Shift via Minimum Discriminating Information
Jun 08, 2021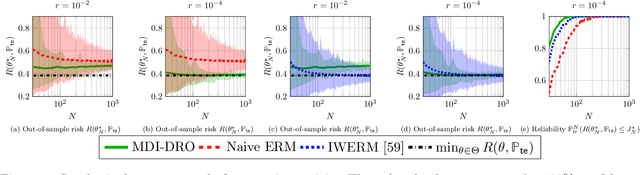
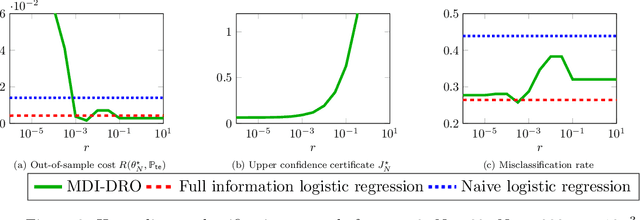
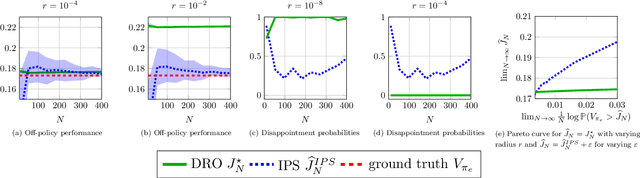
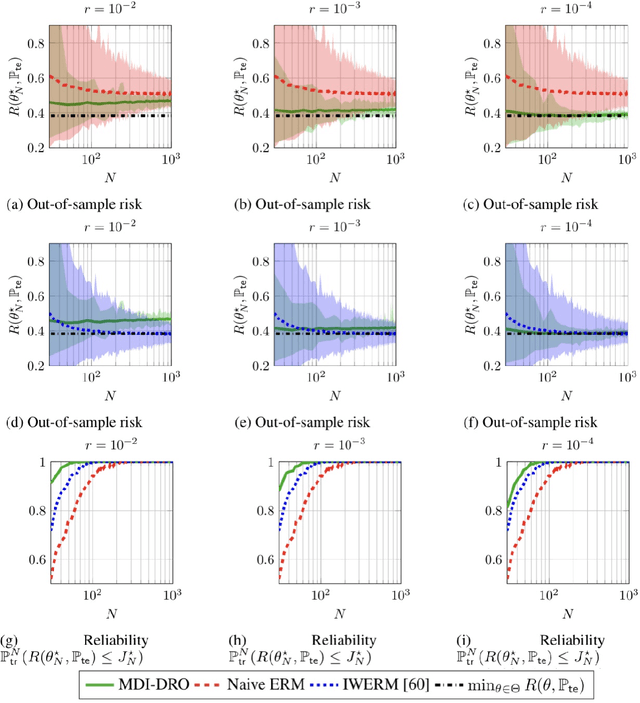
Training models that perform well under distribution shifts is a central challenge in machine learning. In this paper, we introduce a modeling framework where, in addition to training data, we have partial structural knowledge of the shifted test distribution. We employ the principle of minimum discriminating information to embed the available prior knowledge, and use distributionally robust optimization to account for uncertainty due to the limited samples. By leveraging large deviation results, we obtain explicit generalization bounds with respect to the unknown shifted distribution. Lastly, we demonstrate the versatility of our framework by demonstrating it on two rather distinct applications: (1) training classifiers on systematically biased data and (2) off-policy evaluation in Markov Decision Processes.
Learnable Model-Driven Performance Prediction and Optimization for Imperfect MIMO System: Framework and Application
Jun 30, 2022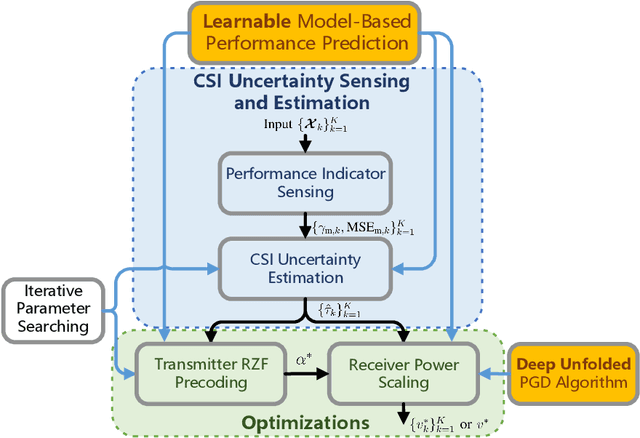
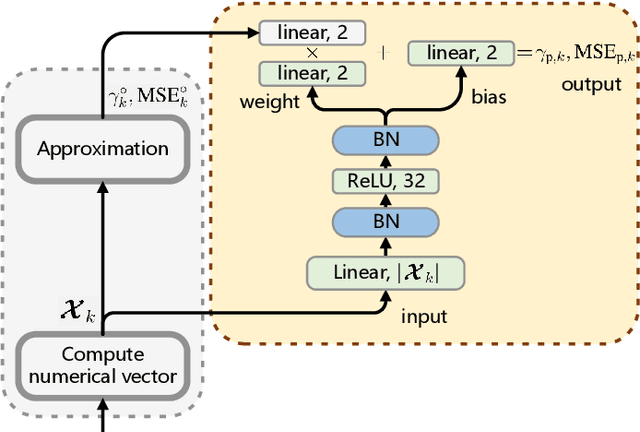
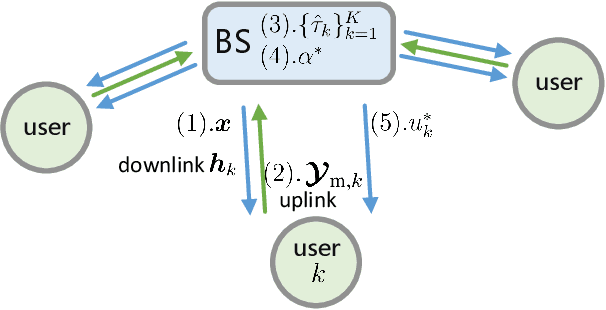
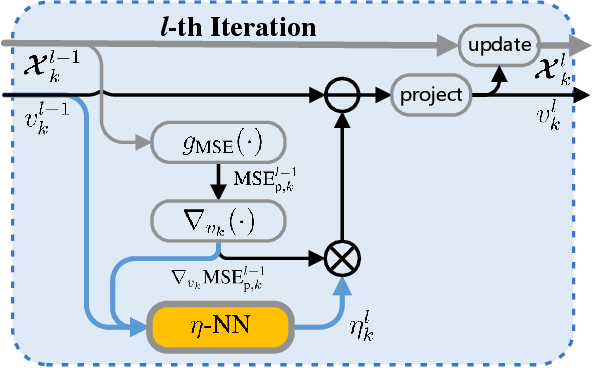
State-of-the-art schemes for performance analysis and optimization of multiple-input multiple-output systems generally experience degradation or even become invalid in dynamic complex scenarios with unknown interference and channel state information (CSI) uncertainty. To adapt to the challenging settings and better accomplish these network auto-tuning tasks, we propose a generic learnable model-driven framework in this paper. To explain how the proposed framework works, we consider regularized zero-forcing precoding as a usage instance and design a light-weight neural network for refined prediction of sum rate and detection error based on coarse model-driven approximations. Then, we estimate the CSI uncertainty on the learned predictor in an iterative manner and, on this basis, optimize the transmit regularization term and subsequent receive power scaling factors. A deep unfolded projected gradient descent based algorithm is proposed for power scaling, which achieves favorable trade-off between convergence rate and robustness.
LAE: Language-Aware Encoder for Monolingual and Multilingual ASR
Jun 05, 2022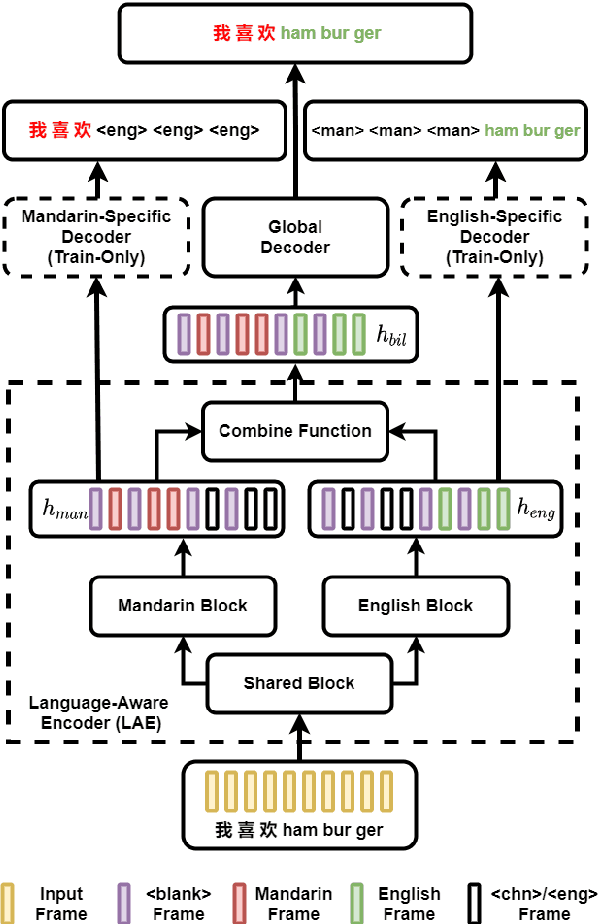
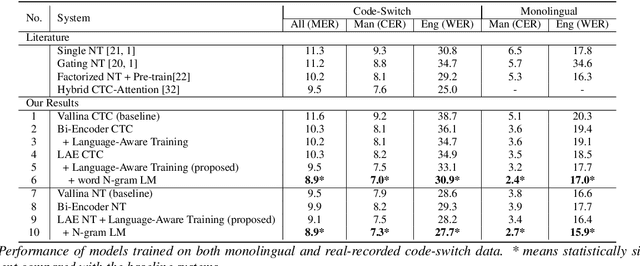
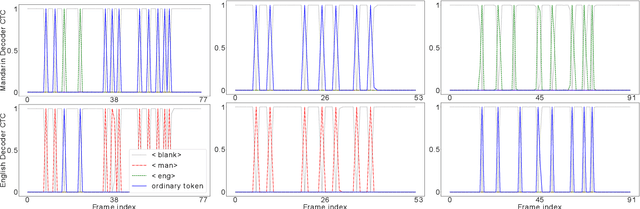
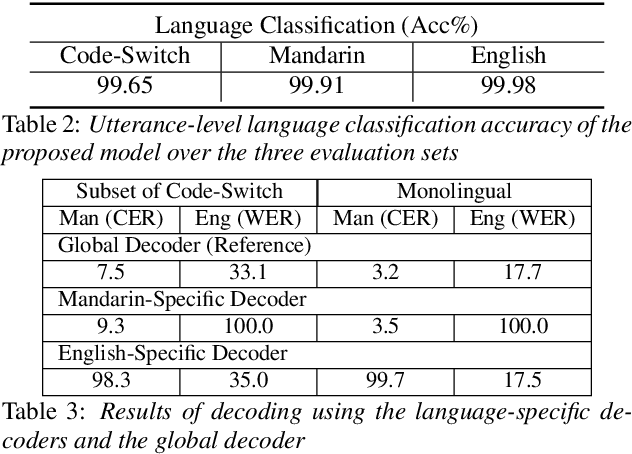
Despite the rapid progress in automatic speech recognition (ASR) research, recognizing multilingual speech using a unified ASR system remains highly challenging. Previous works on multilingual speech recognition mainly focus on two directions: recognizing multiple monolingual speech or recognizing code-switched speech that uses different languages interchangeably within a single utterance. However, a pragmatic multilingual recognizer is expected to be compatible with both directions. In this work, a novel language-aware encoder (LAE) architecture is proposed to handle both situations by disentangling language-specific information and generating frame-level language-aware representations during encoding. In the LAE, the primary encoding is implemented by the shared block while the language-specific blocks are used to extract specific representations for each language. To learn language-specific information discriminatively, a language-aware training method is proposed to optimize the language-specific blocks in LAE. Experiments conducted on Mandarin-English code-switched speech suggest that the proposed LAE is capable of discriminating different languages in frame-level and shows superior performance on both monolingual and multilingual ASR tasks. With either a real-recorded or simulated code-switched dataset, the proposed LAE achieves statistically significant improvements on both CTC and neural transducer systems. Code is released
The DLCC Node Classification Benchmark for Analyzing Knowledge Graph Embeddings
Jul 13, 2022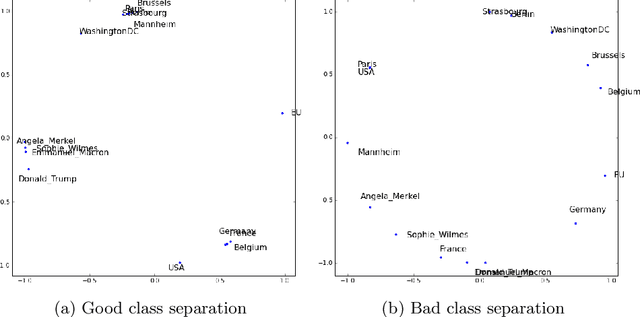
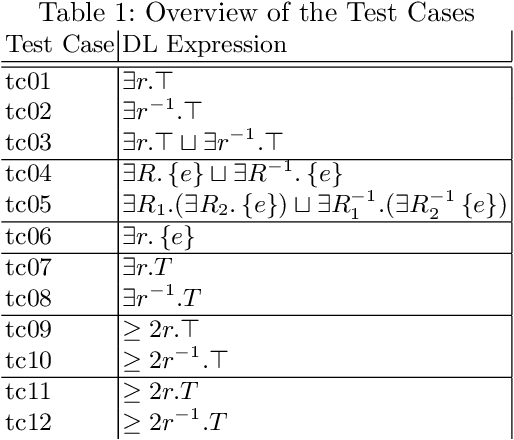
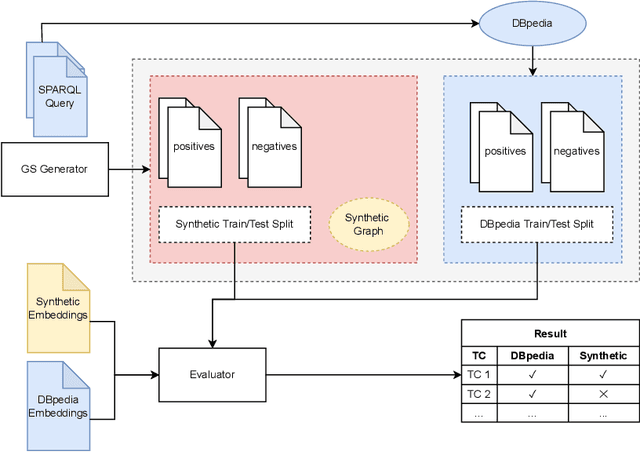
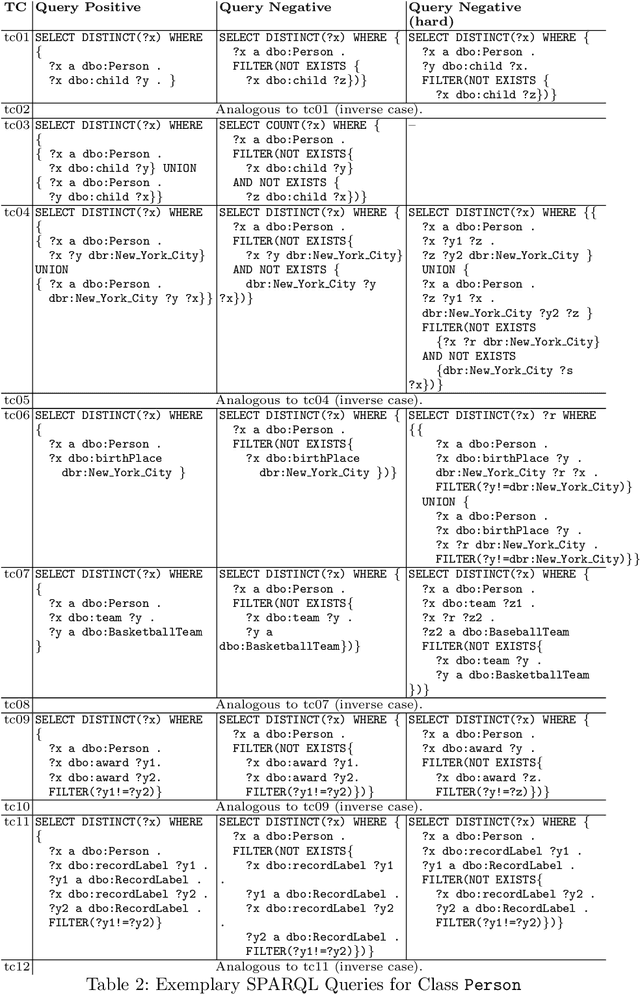
Knowledge graph embedding is a representation learning technique that projects entities and relations in a knowledge graph to continuous vector spaces. Embeddings have gained a lot of uptake and have been heavily used in link prediction and other downstream prediction tasks. Most approaches are evaluated on a single task or a single group of tasks to determine their overall performance. The evaluation is then assessed in terms of how well the embedding approach performs on the task at hand. Still, it is hardly evaluated (and often not even deeply understood) what information the embedding approaches are actually learning to represent. To fill this gap, we present the DLCC (Description Logic Class Constructors) benchmark, a resource to analyze embedding approaches in terms of which kinds of classes they can represent. Two gold standards are presented, one based on the real-world knowledge graph DBpedia and one synthetic gold standard. In addition, an evaluation framework is provided that implements an experiment protocol so that researchers can directly use the gold standard. To demonstrate the use of DLCC, we compare multiple embedding approaches using the gold standards. We find that many DL constructors on DBpedia are actually learned by recognizing different correlated patterns than those defined in the gold standard and that specific DL constructors, such as cardinality constraints, are particularly hard to be learned for most embedding approaches.
Interpretable Melody Generation from Lyrics with Discrete-Valued Adversarial Training
Jun 30, 2022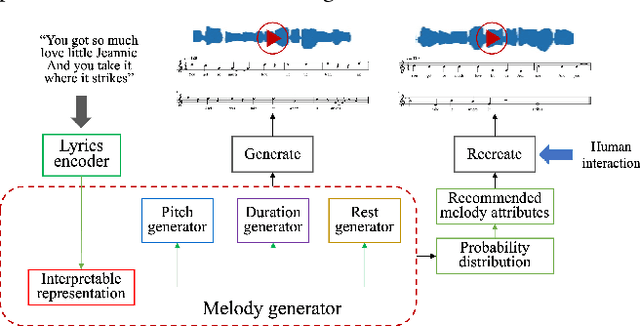

Generating melody from lyrics is an interesting yet challenging task in the area of artificial intelligence and music. However, the difficulty of keeping the consistency between input lyrics and generated melody limits the generation quality of previous works. In our proposal, we demonstrate our proposed interpretable lyrics-to-melody generation system which can interact with users to understand the generation process and recreate the desired songs. To improve the reliability of melody generation that matches lyrics, mutual information is exploited to strengthen the consistency between lyrics and generated melodies. Gumbel-Softmax is exploited to solve the non-differentiability problem of generating discrete music attributes by Generative Adversarial Networks (GANs). Moreover, the predicted probabilities output by the generator is utilized to recommend music attributes. Interacting with our lyrics-to-melody generation system, users can listen to the generated AI song as well as recreate a new song by selecting from recommended music attributes.
High-Cardinality Geometrical Constellation Shaping for the Nonlinear Fibre Channel
May 09, 2022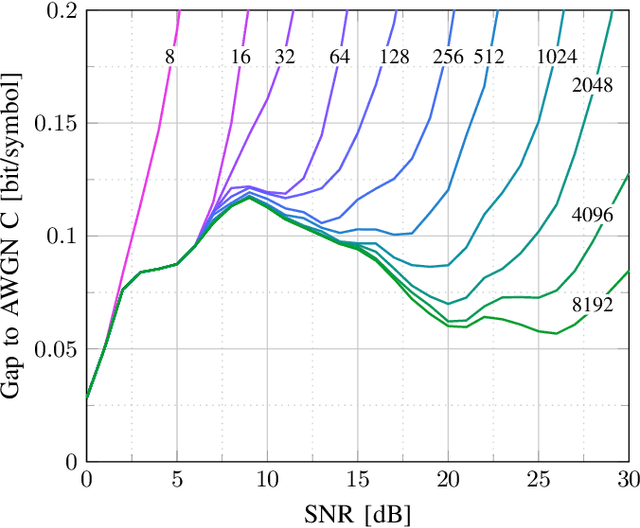
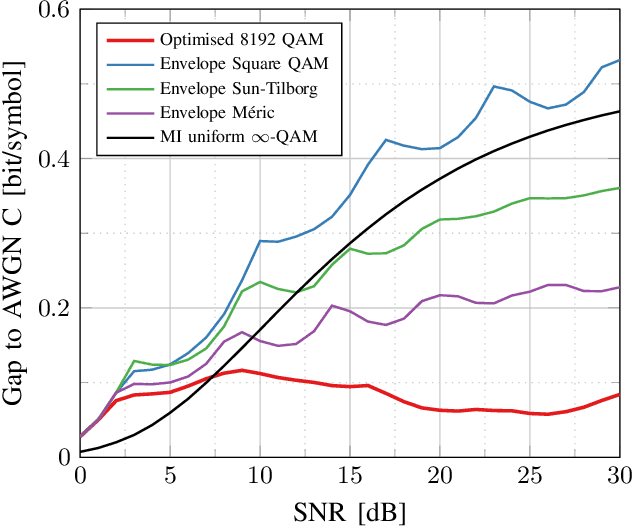
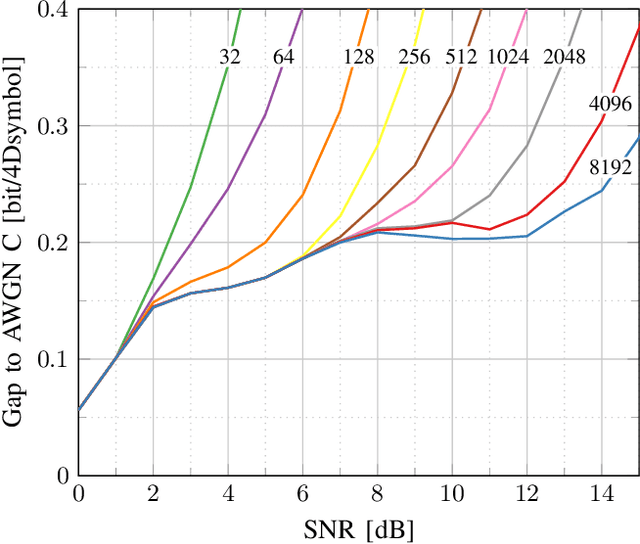
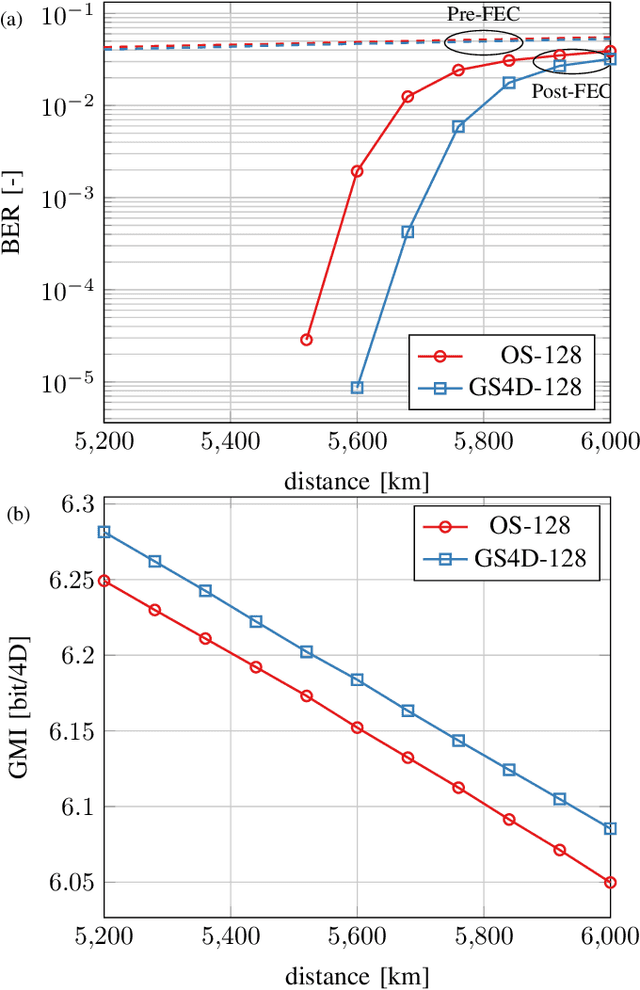
This paper presents design methods for highly efficient optimisation of geometrically shaped constellations to maximise data throughput in optical communications. It describes methods to analytically calculate the information-theoretical loss and the gradient of this loss as a function of the input constellation shape. The gradients of the \ac{MI} and \ac{GMI} are critical to the optimisation of geometrically-shaped constellations. It presents the analytical derivative of the achievable information rate metrics with respect to the input constellation. The proposed method allows for improved design of higher cardinality and higher-dimensional constellations for optimising both linear and nonlinear fibre transmission throughput. Near-capacity achieving constellations with up to 8192 points for both 2 and 4 dimensions, with generalised mutual information (GMI) within 0.06 bit/2Dsymbol of additive white Gaussian noise channel (AWGN) capacity, are presented. Additionally, a design algorithm reducing the design computation time from days to minutes is introduced, allowing the presentation of optimised constellations for both linear AWGN and nonlinear fibre channels for a wide range of signal-to-noise ratios.