 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Leveraging Global Binary Masks for Structure Segmentation in Medical Images
May 13, 2022
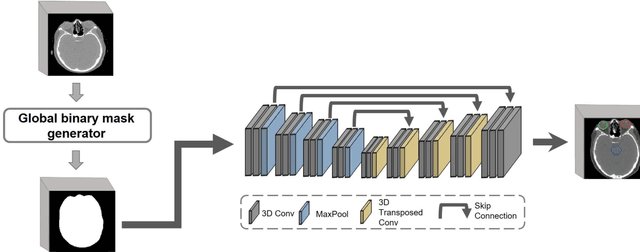
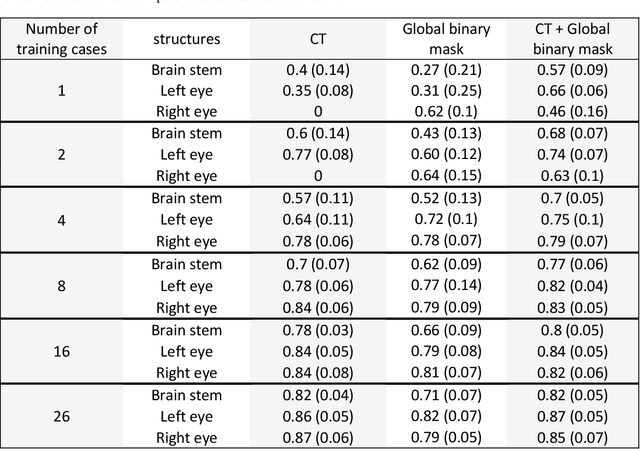
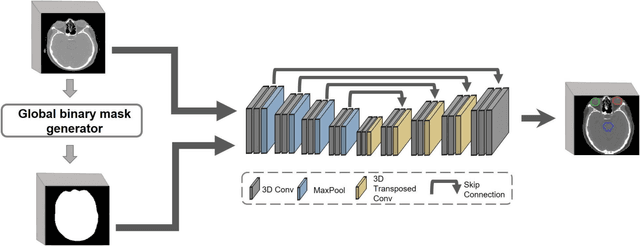
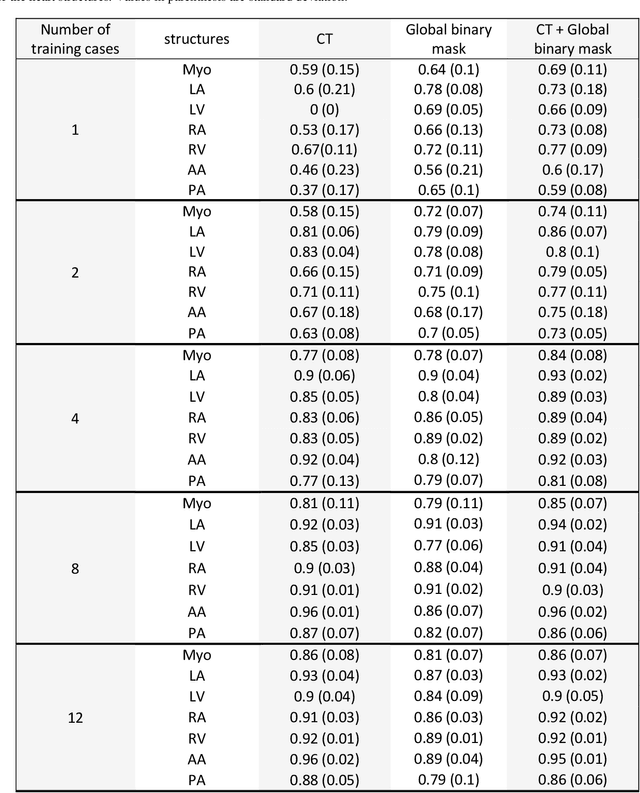
Deep learning (DL) models for medical image segmentation are highly influenced by intensity variations of input images and lack generalization due to primarily utilizing pixels' intensity information for inference. Acquiring sufficient training data is another challenge limiting models' applications. We proposed to leverage the consistency of organs' anatomical shape and position information in medical images. We introduced a framework leveraging recurring anatomical patterns through global binary masks for organ segmentation. Two scenarios were studied.1) Global binary masks were the only model's (i.e. U-Net) input, forcing exclusively encoding organs' position and shape information for segmentation/localization.2) Global binary masks were incorporated as an additional channel functioning as position/shape clues to mitigate training data scarcity. Two datasets of the brain and heart CT images with their ground-truth were split into (26:10:10) and (12:3:5) for training, validation, and test respectively. Training exclusively on global binary masks led to Dice scores of 0.77(0.06) and 0.85(0.04), with the average Euclidian distance of 3.12(1.43)mm and 2.5(0.93)mm relative to the center of mass of the ground truth for the brain and heart structures respectively. The outcomes indicate that a surprising degree of position and shape information is encoded through global binary masks. Incorporating global binary masks led to significantly higher accuracy relative to the model trained on only CT images in small subsets of training data; the performance improved by 4.3-125.3% and 1.3-48.1% for 1-8 training cases of the brain and heart datasets respectively. The findings imply the advantages of utilizing global binary masks for building generalizable models and to compensate for training data scarcity.
Beyond mAP: Re-evaluating and Improving Performance in Instance Segmentation with Semantic Sorting and Contrastive Flow
Jul 04, 2022
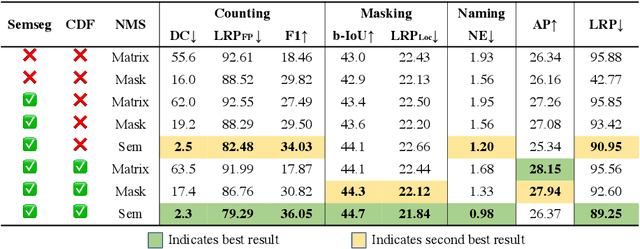
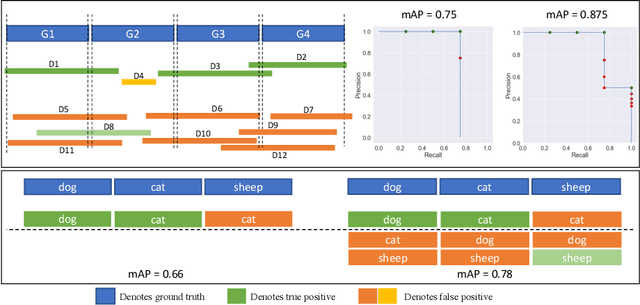

Top-down instance segmentation methods improve mAP by hedging bets on low-confidence predictions to match a ground truth. Moreover, the query-key paradigm of top-down methods leads to the instance merging problem. An excessive number of duplicate predictions leads to the (over)counting error, and the independence of category and localization branches leads to the naming error. The de-facto mAP metric doesn't capture these errors, as we show that a trivial dithering scheme can simultaneously increase mAP with hedging errors. To this end, we propose two graph-based metrics that quantifies the amount of hedging both inter-and intra-class. We conjecture the source of the hedging problem is due to feature merging and propose a) Contrastive Flow Field to encode contextual differences between instances as a supervisory signal, and b) Semantic Sorting and NMS step to suppress duplicates and incorrectly categorized prediction. Ablations show that our method encodes contextual information better than baselines, and experiments on COCO our method simultaneously reduces merging and hedging errors compared to state-of-the-art instance segmentation methods.
The information of attribute uncertainties: what convolutional neural networks can learn about errors in input data
Aug 10, 2021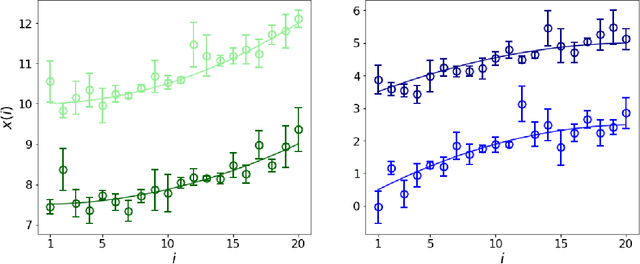

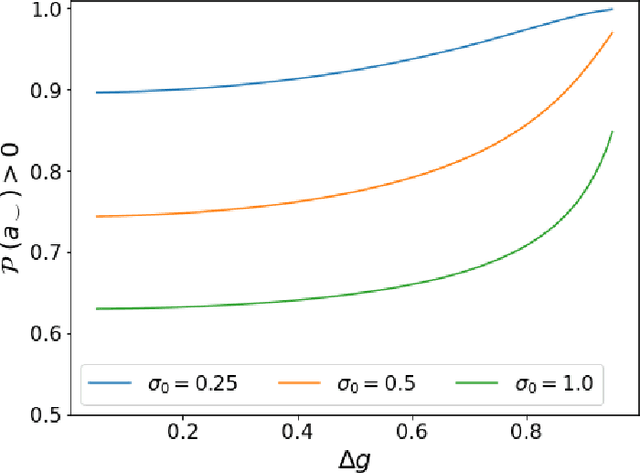
Errors in measurements are key to weighting the value of data, but are often neglected in Machine Learning (ML). We show how Convolutional Neural Networks (CNNs) are able to learn about the context and patterns of signal and noise, leading to improvements in the performance of classification methods. We construct a model whereby two classes of objects follow an underlying Gaussian distribution, and where the features (the input data) have varying, but known, levels of noise. This model mimics the nature of scientific data sets, where the noises arise as realizations of some random processes whose underlying distributions are known. The classification of these objects can then be performed using standard statistical techniques (e.g., least-squares minimization or Markov-Chain Monte Carlo), as well as ML techniques. This allows us to take advantage of a maximum likelihood approach to object classification, and to measure the amount by which the ML methods are incorporating the information in the input data uncertainties. We show that, when each data point is subject to different levels of noise (i.e., noises with different distribution functions), that information can be learned by the CNNs, raising the ML performance to at least the same level of the least-squares method -- and sometimes even surpassing it. Furthermore, we show that, with varying noise levels, the confidence of the ML classifiers serves as a proxy for the underlying cumulative distribution function, but only if the information about specific input data uncertainties is provided to the CNNs.
Robust Generalization despite Distribution Shift via Minimum Discriminating Information
Jun 08, 2021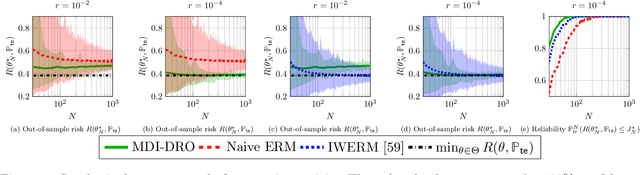
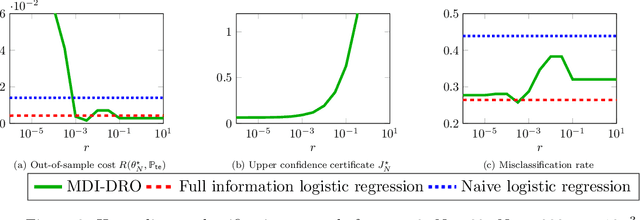
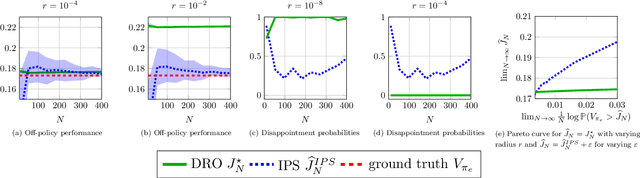
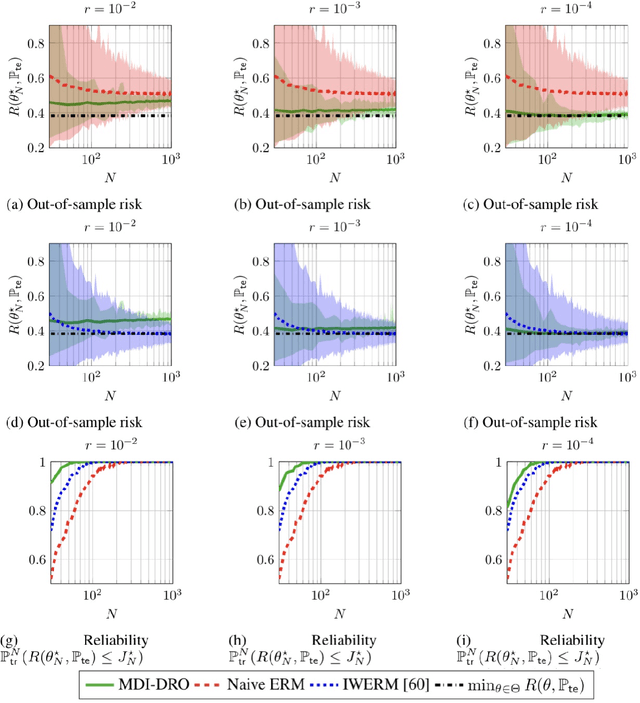
Training models that perform well under distribution shifts is a central challenge in machine learning. In this paper, we introduce a modeling framework where, in addition to training data, we have partial structural knowledge of the shifted test distribution. We employ the principle of minimum discriminating information to embed the available prior knowledge, and use distributionally robust optimization to account for uncertainty due to the limited samples. By leveraging large deviation results, we obtain explicit generalization bounds with respect to the unknown shifted distribution. Lastly, we demonstrate the versatility of our framework by demonstrating it on two rather distinct applications: (1) training classifiers on systematically biased data and (2) off-policy evaluation in Markov Decision Processes.
Use-Case-Grounded Simulations for Explanation Evaluation
Jun 05, 2022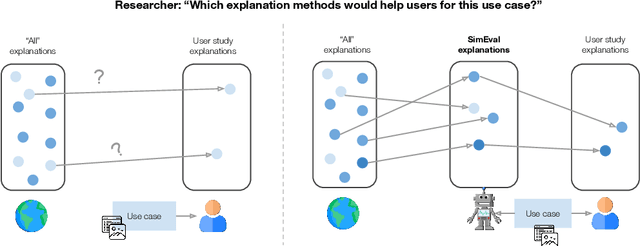
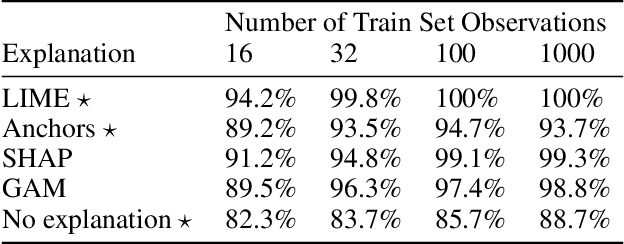
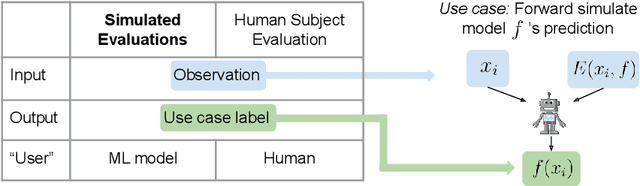
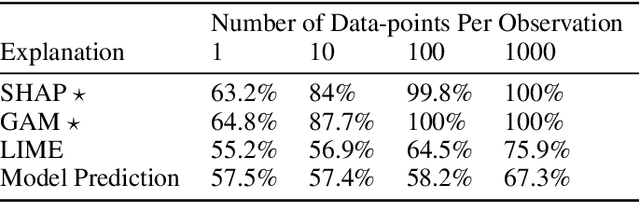
A growing body of research runs human subject evaluations to study whether providing users with explanations of machine learning models can help them with practical real-world use cases. However, running user studies is challenging and costly, and consequently each study typically only evaluates a limited number of different settings, e.g., studies often only evaluate a few arbitrarily selected explanation methods. To address these challenges and aid user study design, we introduce Use-Case-Grounded Simulated Evaluations (SimEvals). SimEvals involve training algorithmic agents that take as input the information content (such as model explanations) that would be presented to each participant in a human subject study, to predict answers to the use case of interest. The algorithmic agent's test set accuracy provides a measure of the predictiveness of the information content for the downstream use case. We run a comprehensive evaluation on three real-world use cases (forward simulation, model debugging, and counterfactual reasoning) to demonstrate that Simevals can effectively identify which explanation methods will help humans for each use case. These results provide evidence that SimEvals can be used to efficiently screen an important set of user study design decisions, e.g. selecting which explanations should be presented to the user, before running a potentially costly user study.
Information Theoretic Secure Aggregation with User Dropouts
Jan 19, 2021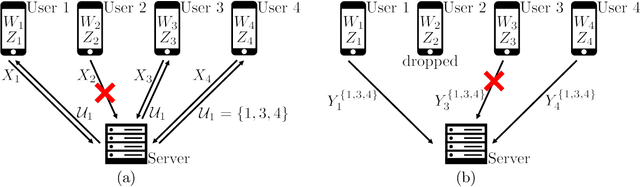
In the robust secure aggregation problem, a server wishes to learn and only learn the sum of the inputs of a number of users while some users may drop out (i.e., may not respond). The identity of the dropped users is not known a priori and the server needs to securely recover the sum of the remaining surviving users. We consider the following minimal two-round model of secure aggregation. Over the first round, any set of no fewer than $U$ users out of $K$ users respond to the server and the server wants to learn the sum of the inputs of all responding users. The remaining users are viewed as dropped. Over the second round, any set of no fewer than $U$ users of the surviving users respond (i.e., dropouts are still possible over the second round) and from the information obtained from the surviving users over the two rounds, the server can decode the desired sum. The security constraint is that even if the server colludes with any $T$ users and the messages from the dropped users are received by the server (e.g., delayed packets), the server is not able to infer any additional information beyond the sum in the information theoretic sense. For this information theoretic secure aggregation problem, we characterize the optimal communication cost. When $U \leq T$, secure aggregation is not feasible, and when $U > T$, to securely compute one symbol of the sum, the minimum number of symbols sent from each user to the server is $1$ over the first round, and $1/(U-T)$ over the second round.
A Weakly-Supervised Iterative Graph-Based Approach to Retrieve COVID-19 Misinformation Topics
May 19, 2022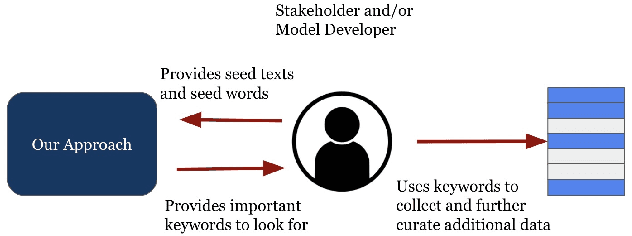
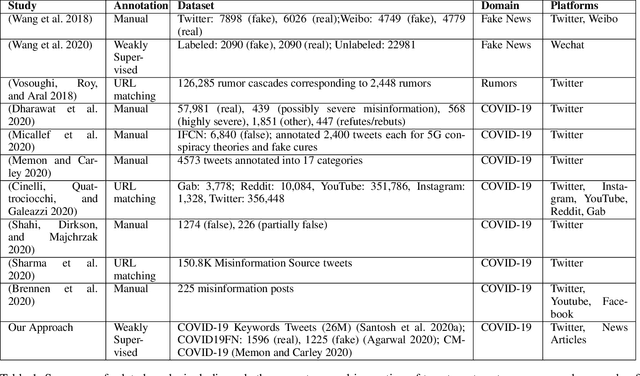
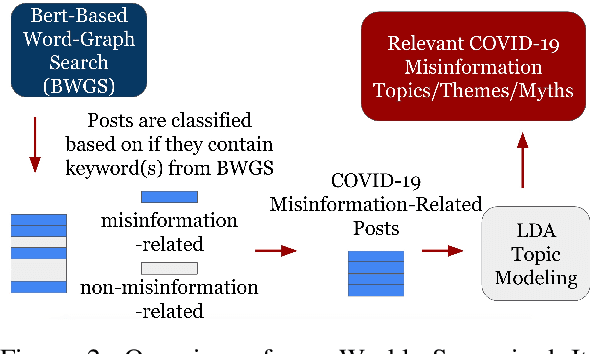
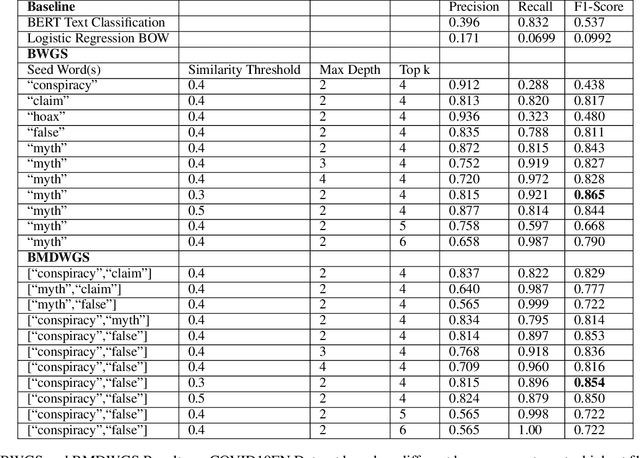
The COVID-19 pandemic has been accompanied by an `infodemic' -- of accurate and inaccurate health information across social media. Detecting misinformation amidst dynamically changing information landscape is challenging; identifying relevant keywords and posts is arduous due to the large amount of human effort required to inspect the content and sources of posts. We aim to reduce the resource cost of this process by introducing a weakly-supervised iterative graph-based approach to detect keywords, topics, and themes related to misinformation, with a focus on COVID-19. Our approach can successfully detect specific topics from general misinformation-related seed words in a few seed texts. Our approach utilizes the BERT-based Word Graph Search (BWGS) algorithm that builds on context-based neural network embeddings for retrieving misinformation-related posts. We utilize Latent Dirichlet Allocation (LDA) topic modeling for obtaining misinformation-related themes from the texts returned by BWGS. Furthermore, we propose the BERT-based Multi-directional Word Graph Search (BMDWGS) algorithm that utilizes greater starting context information for misinformation extraction. In addition to a qualitative analysis of our approach, our quantitative analyses show that BWGS and BMDWGS are effective in extracting misinformation-related content compared to common baselines in low data resource settings. Extracting such content is useful for uncovering prevalent misconceptions and concerns and for facilitating precision public health messaging campaigns to improve health behaviors.
A multi-level interpretable sleep stage scoring system by infusing experts' knowledge into a deep network architecture
Jul 11, 2022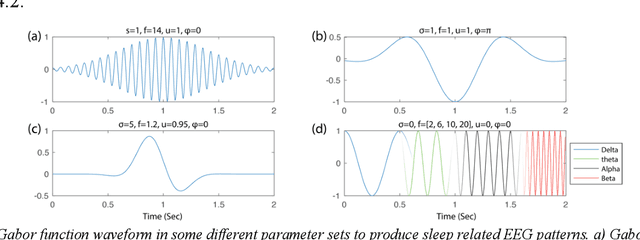
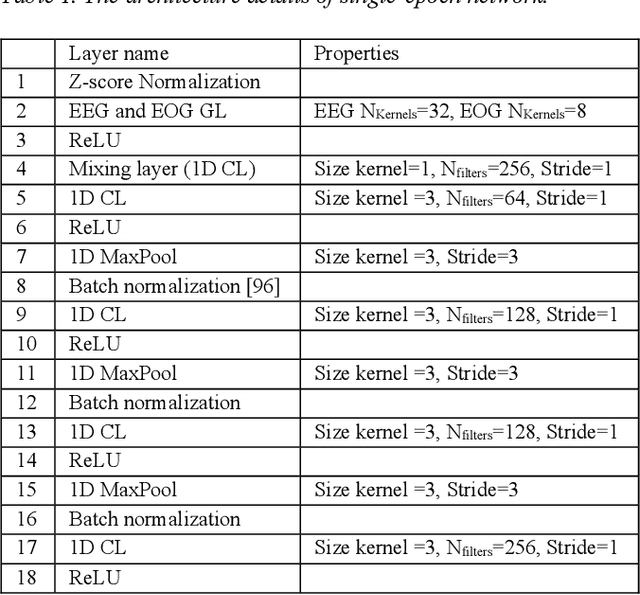
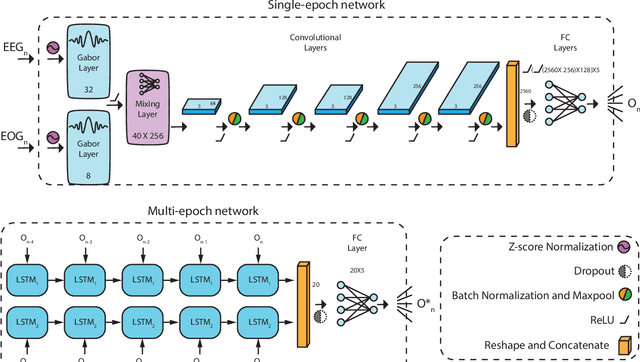
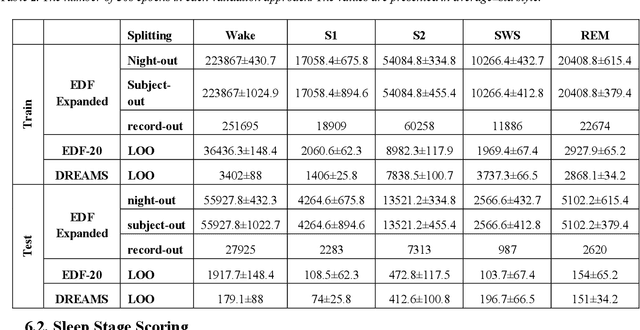
In recent years, deep learning has shown potential and efficiency in a wide area including computer vision, image and signal processing. Yet, translational challenges remain for user applications due to a lack of interpretability of algorithmic decisions and results. This black box problem is particularly problematic for high-risk applications such as medical-related decision-making. The current study goal was to design an interpretable deep learning system for time series classification of electroencephalogram (EEG) for sleep stage scoring as a step toward designing a transparent system. We have developed an interpretable deep neural network that includes a kernel-based layer based on a set of principles used for sleep scoring by human experts in the visual analysis of polysomnographic records. A kernel-based convolutional layer was defined and used as the first layer of the system and made available for user interpretation. The trained system and its results were interpreted in four levels from the microstructure of EEG signals, such as trained kernels and the effect of each kernel on the detected stages, to macrostructures, such as the transition between stages. The proposed system demonstrated greater performance than prior studies and the results of interpretation showed that the system learned information which was consistent with expert knowledge.
Memory Efficient Patch-based Training for INR-based GANs
Jul 04, 2022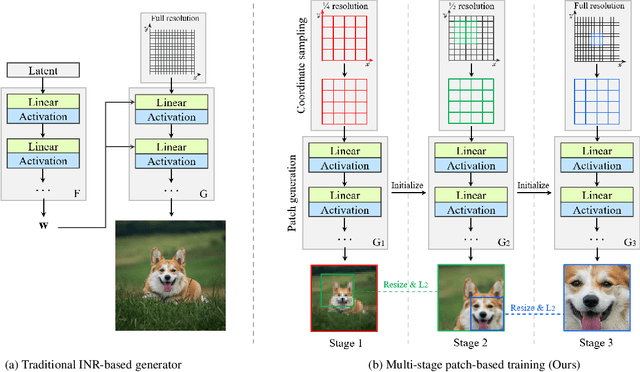
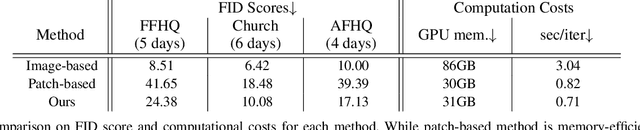


Recent studies have shown remarkable progress in GANs based on implicit neural representation (INR) - an MLP that produces an RGB value given its (x, y) coordinate. They represent an image as a continuous version of the underlying 2D signal instead of a 2D array of pixels, which opens new horizons for GAN applications (e.g., zero-shot super-resolution, image outpainting). However, training existing approaches require a heavy computational cost proportional to the image resolution, since they compute an MLP operation for every (x, y) coordinate. To alleviate this issue, we propose a multi-stage patch-based training, a novel and scalable approach that can train INR-based GANs with a flexible computational cost regardless of the image resolution. Specifically, our method allows to generate and discriminate by patch to learn the local details of the image and learn global structural information by a novel reconstruction loss to enable efficient GAN training. We conduct experiments on several benchmark datasets to demonstrate that our approach enhances baseline models in GPU memory while maintaining FIDs at a reasonable level.
Vaccine Discourse on Twitter During the COVID-19 Pandemic
Jul 23, 2022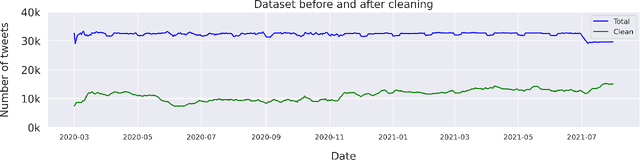

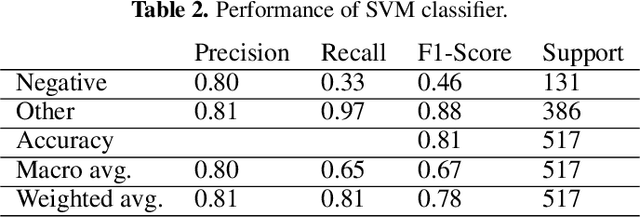
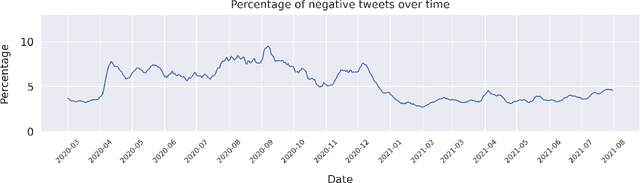
Since the onset of the COVID-19 pandemic, vaccines have been an important topic in public discourse. The discussions around vaccines are polarized as some see them as an important measure to end the pandemic, and others are hesitant or find them harmful. This study investigates posts related to COVID-19 vaccines on Twitter and focuses on those which have a negative stance toward vaccines. A dataset of 16,713,238 English tweets related to COVID-19 vaccines was collected covering the period from March 1, 2020, to July 31, 2021. We used the Scikit-learn Python library to apply a support vector machine (SVM) classifier to identify the tweets with a negative stance toward the COVID-19 vaccines. A total of 5,163 tweets were used to train the classifier, out of which a subset of 2,484 tweets were manually annotated by us and made publicly available. We used the BERTtopic model to extract and investigate the topics discussed within the negative tweets and how they changed over time. We show that the negativity with respect to COVID-19 vaccines has decreased over time along with the vaccine roll-outs. We identify 37 topics of discussion and present their respective importance over time. We show that popular topics consist of conspiratorial discussions such as 5G towers and microchips, but also contain legitimate concerns around vaccination safety and side effects as well as concerns about policies. Our study shows that even unpopular opinions or conspiracy theories can become widespread when paired with a widely popular discussion topic such as COVID-19 vaccines. Understanding the concerns and the discussed topics and how they change over time is essential for policymakers and public health authorities to provide better and in-time information and policies, to facilitate vaccination of the population in future similar crises.