 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Eliminating Gradient Conflict in Reference-based Line-Art Colorization
Jul 20, 2022
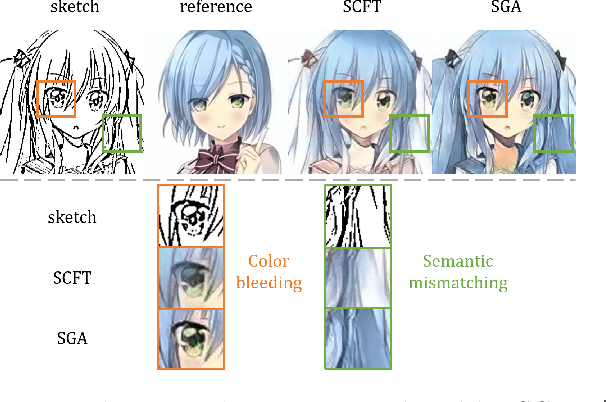
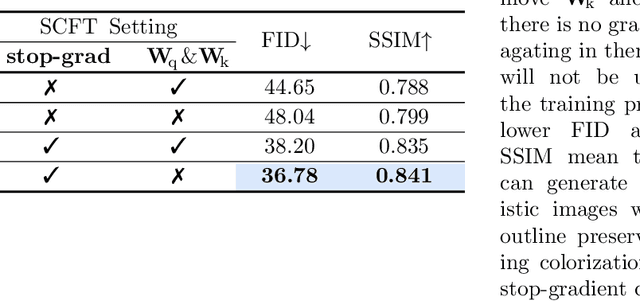
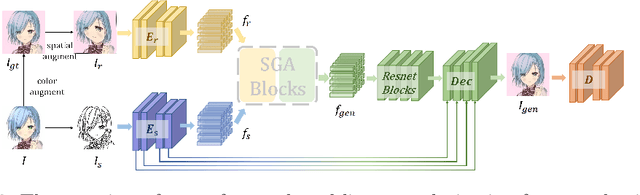
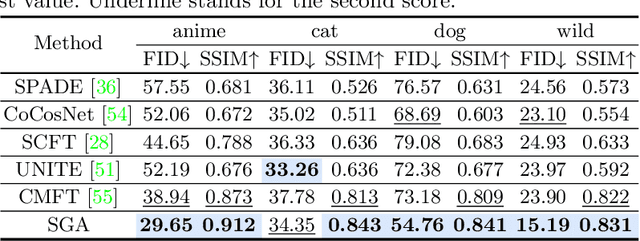
Reference-based line-art colorization is a challenging task in computer vision. The color, texture, and shading are rendered based on an abstract sketch, which heavily relies on the precise long-range dependency modeling between the sketch and reference. Popular techniques to bridge the cross-modal information and model the long-range dependency employ the attention mechanism. However, in the context of reference-based line-art colorization, several techniques would intensify the existing training difficulty of attention, for instance, self-supervised training protocol and GAN-based losses. To understand the instability in training, we detect the gradient flow of attention and observe gradient conflict among attention branches. This phenomenon motivates us to alleviate the gradient issue by preserving the dominant gradient branch while removing the conflict ones. We propose a novel attention mechanism using this training strategy, Stop-Gradient Attention (SGA), outperforming the attention baseline by a large margin with better training stability. Compared with state-of-the-art modules in line-art colorization, our approach demonstrates significant improvements in Fr\'echet Inception Distance (FID, up to 27.21%) and structural similarity index measure (SSIM, up to 25.67%) on several benchmarks. The code of SGA is available at https://github.com/kunkun0w0/SGA .
Towards Optimizing OCR for Accessibility
Jun 24, 2022



Visual cues such as structure, emphasis, and icons play an important role in efficient information foraging by sighted individuals and make for a pleasurable reading experience. Blind, low-vision and other print-disabled individuals miss out on these cues since current OCR and text-to-speech software ignore them, resulting in a tedious reading experience. We identify four semantic goals for an enjoyable listening experience, and identify syntactic visual cues that help make progress towards these goals. Empirically, we find that preserving even one or two visual cues in aural form significantly enhances the experience for listening to print content.
Graph Neural Network Bandits
Jul 13, 2022
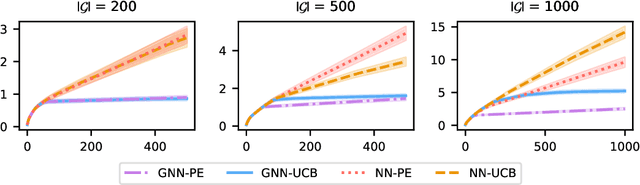
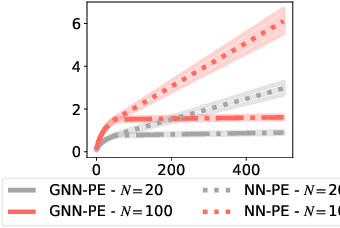
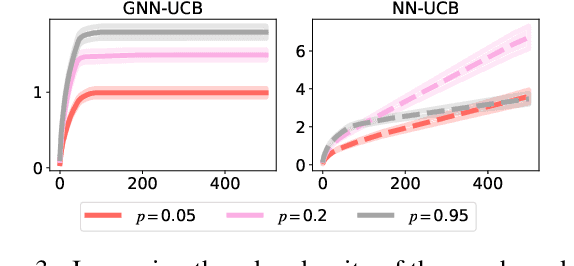
We consider the bandit optimization problem with the reward function defined over graph-structured data. This problem has important applications in molecule design and drug discovery, where the reward is naturally invariant to graph permutations. The key challenges in this setting are scaling to large domains, and to graphs with many nodes. We resolve these challenges by embedding the permutation invariance into our model. In particular, we show that graph neural networks (GNNs) can be used to estimate the reward function, assuming it resides in the Reproducing Kernel Hilbert Space of a permutation-invariant additive kernel. By establishing a novel connection between such kernels and the graph neural tangent kernel (GNTK), we introduce the first GNN confidence bound and use it to design a phased-elimination algorithm with sublinear regret. Our regret bound depends on the GNTK's maximum information gain, which we also provide a bound for. While the reward function depends on all $N$ node features, our guarantees are independent of the number of graph nodes $N$. Empirically, our approach exhibits competitive performance and scales well on graph-structured domains.
Deep Pneumonia: Attention-Based Contrastive Learning for Class-Imbalanced Pneumonia Lesion Recognition in Chest X-rays
Jul 23, 2022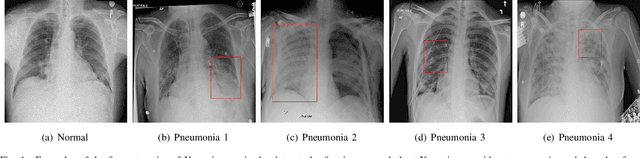
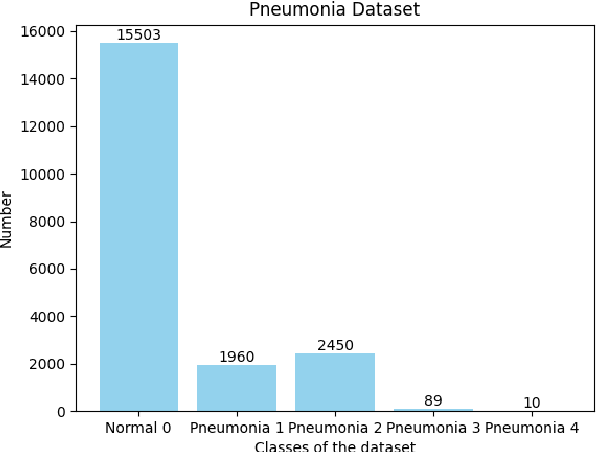
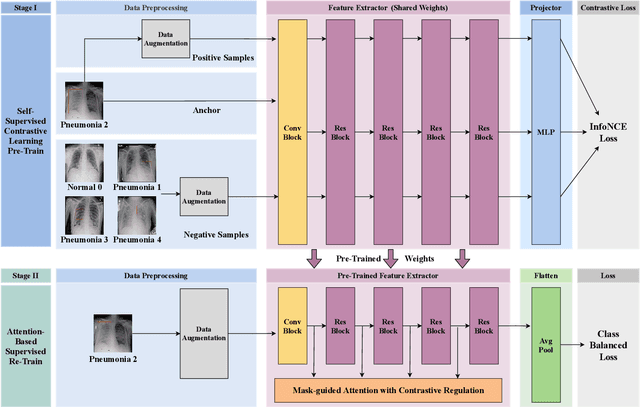
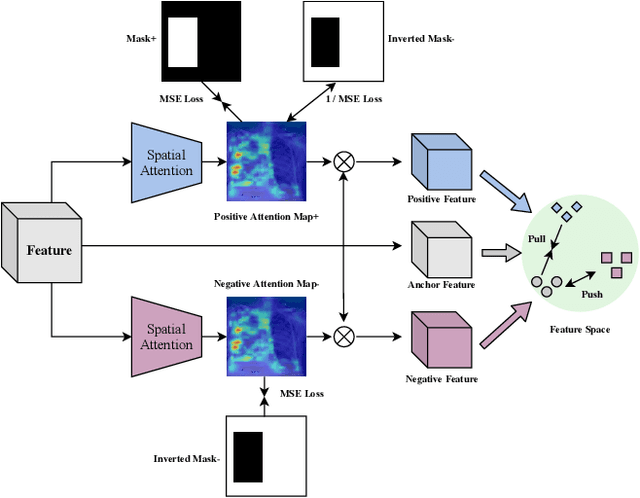
Computer-aided X-ray pneumonia lesion recognition is important for accurate diagnosis of pneumonia. With the emergence of deep learning, the identification accuracy of pneumonia has been greatly improved, but there are still some challenges due to the fuzzy appearance of chest X-rays. In this paper, we propose a deep learning framework named Attention-Based Contrastive Learning for Class-Imbalanced X-Ray Pneumonia Lesion Recognition (denoted as Deep Pneumonia). We adopt self-supervised contrastive learning strategy to pre-train the model without using extra pneumonia data for fully mining the limited available dataset. In order to leverage the location information of the lesion area that the doctor has painstakingly marked, we propose mask-guided hard attention strategy and feature learning with contrastive regulation strategy which are applied on the attention map and the extracted features respectively to guide the model to focus more attention on the lesion area where contains more discriminative features for improving the recognition performance. In addition, we adopt Class-Balanced Loss instead of traditional Cross-Entropy as the loss function of classification to tackle the problem of serious class imbalance between different classes of pneumonia in the dataset. The experimental results show that our proposed framework can be used as a reliable computer-aided pneumonia diagnosis system to assist doctors to better diagnose pneumonia cases accurately.
6D Camera Relocalization in Visually Ambiguous Extreme Environments
Jul 13, 2022
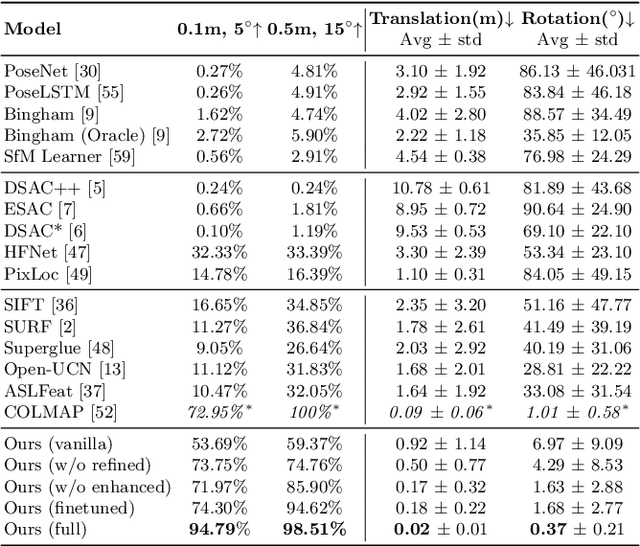
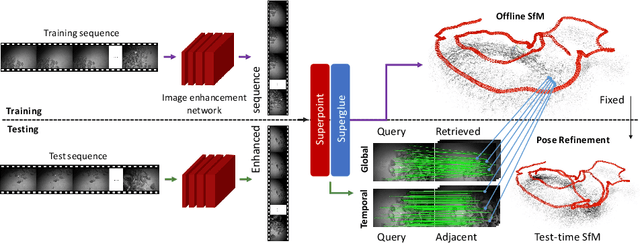
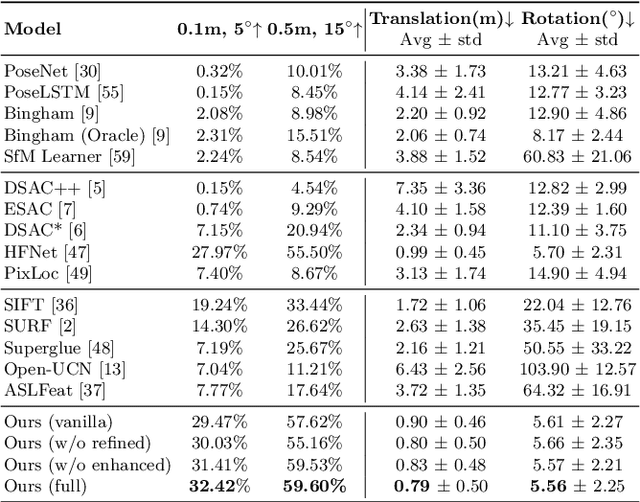
We propose a novel method to reliably estimate the pose of a camera given a sequence of images acquired in extreme environments such as deep seas or extraterrestrial terrains. Data acquired under these challenging conditions are corrupted by textureless surfaces, image degradation, and presence of repetitive and highly ambiguous structures. When naively deployed, the state-of-the-art methods can fail in those scenarios as confirmed by our empirical analysis. In this paper, we attempt to make camera relocalization work in these extreme situations. To this end, we propose: (i) a hierarchical localization system, where we leverage temporal information and (ii) a novel environment-aware image enhancement method to boost the robustness and accuracy. Our extensive experimental results demonstrate superior performance in favor of our method under two extreme settings: localizing an autonomous underwater vehicle and localizing a planetary rover in a Mars-like desert. In addition, our method achieves comparable performance with state-of-the-art methods on the indoor benchmark (7-Scenes dataset) using only 20% training data.
DC-BENCH: Dataset Condensation Benchmark
Jul 20, 2022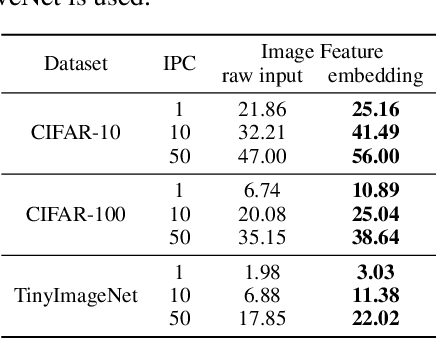
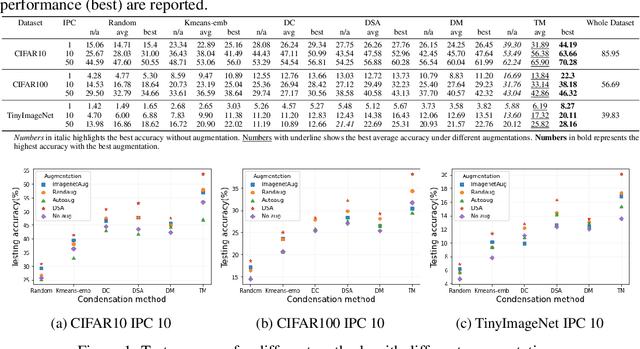
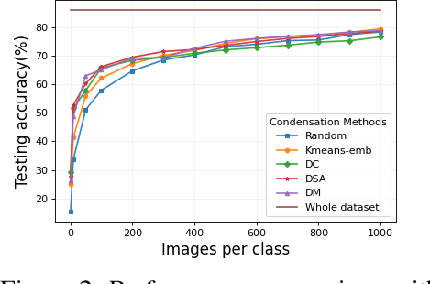
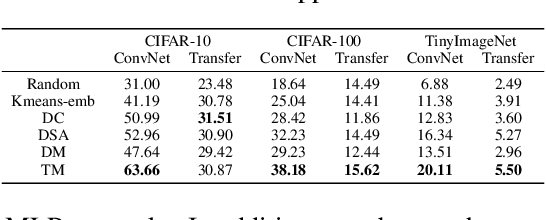
Dataset Condensation is a newly emerging technique aiming at learning a tiny dataset that captures the rich information encoded in the original dataset. As the size of datasets contemporary machine learning models rely on becomes increasingly large, condensation methods become a prominent direction for accelerating network training and reducing data storage. Despite numerous methods have been proposed in this rapidly growing field, evaluating and comparing different condensation methods is non-trivial and still remains an open issue. The quality of condensed dataset are often shadowed by many critical contributing factors to the end performance, such as data augmentation and model architectures. The lack of a systematic way to evaluate and compare condensation methods not only hinders our understanding of existing techniques, but also discourages practical usage of the synthesized datasets. This work provides the first large-scale standardized benchmark on Dataset Condensation. It consists of a suite of evaluations to comprehensively reflect the generability and effectiveness of condensation methods through the lens of their generated dataset. Leveraging this benchmark, we conduct a large-scale study of current condensation methods, and report many insightful findings that open up new possibilities for future development. The benchmark library, including evaluators, baseline methods, and generated datasets, is open-sourced to facilitate future research and application.
I Don't Need $\mathbf{u}$: Identifiable Non-Linear ICA Without Side Information
Jun 09, 2021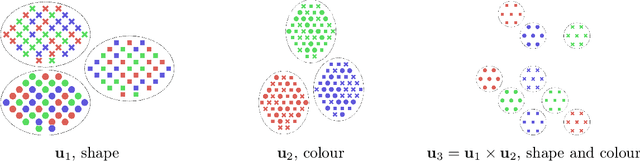
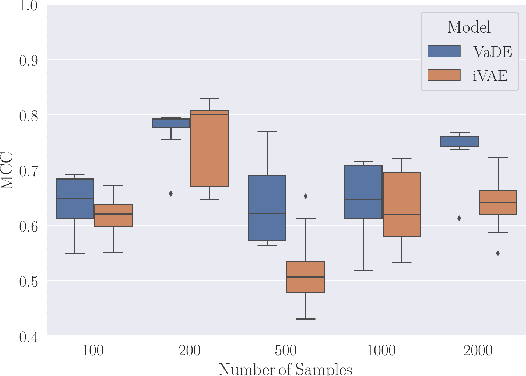

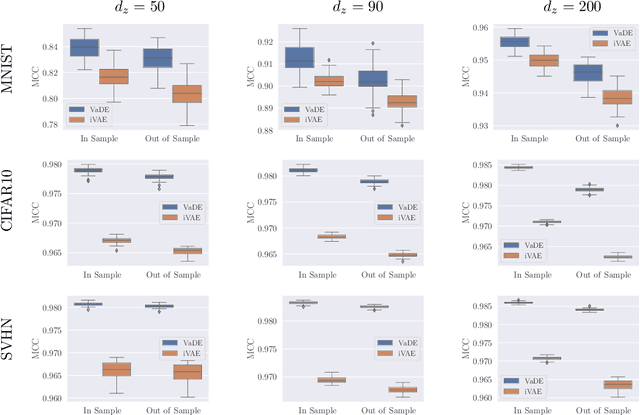
In this work we introduce a new approach for identifiable non-linear ICA models. Recently there has been a renaissance in identifiability results in deep generative models, not least for non-linear ICA. These prior works, however, have assumed access to a sufficiently-informative auxiliary set of observations, denoted $\mathbf{u}$. We show here how identifiability can be obtained in the absence of this side-information, rendering possible fully-unsupervised identifiable non-linear ICA. While previous theoretical results have established the impossibility of identifiable non-linear ICA in the presence of infinitely-flexible universal function approximators, here we rely on the intrinsically-finite modelling capacity of any particular chosen parameterisation of a deep generative model. In particular, we focus on generative models which perform clustering in their latent space -- a model structure which matches previous identifiable models, but with the learnt clustering providing a synthetic form of auxiliary information. We evaluate our proposals using VAEs, on synthetic and image datasets, and find that the learned clusterings function effectively: deep generative models with latent clusterings are empirically identifiable, to the same degree as models which rely on side information.
Data Representativeness in Accessibility Datasets: A Meta-Analysis
Jul 16, 2022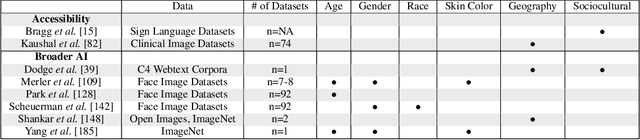
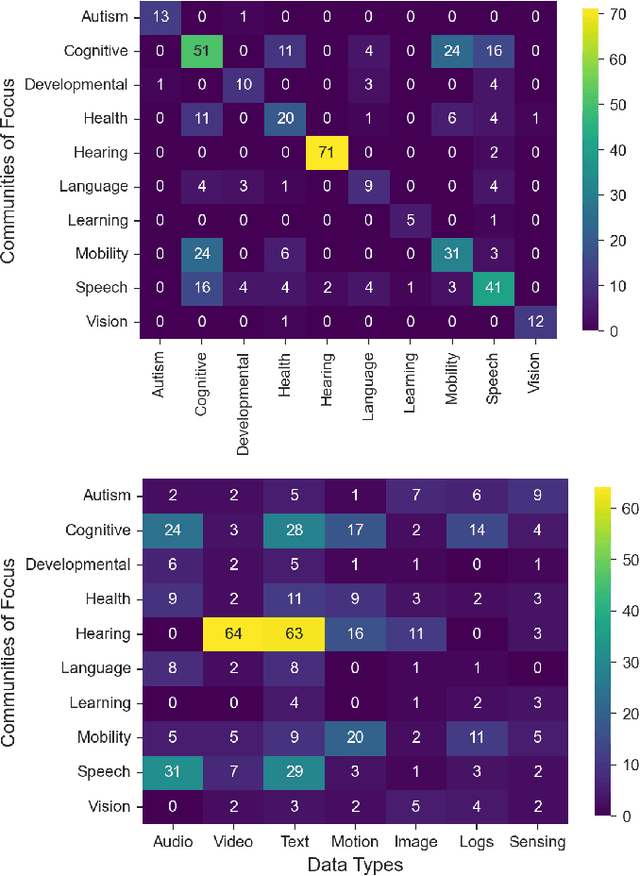
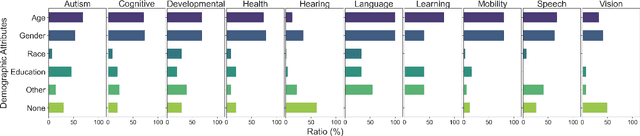
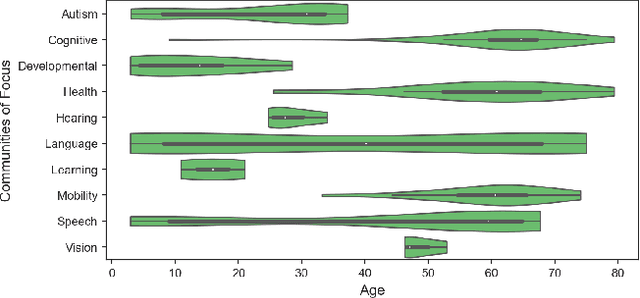
As data-driven systems are increasingly deployed at scale, ethical concerns have arisen around unfair and discriminatory outcomes for historically marginalized groups that are underrepresented in training data. In response, work around AI fairness and inclusion has called for datasets that are representative of various demographic groups.In this paper, we contribute an analysis of the representativeness of age, gender, and race & ethnicity in accessibility datasets - datasets sourced from people with disabilities and older adults - that can potentially play an important role in mitigating bias for inclusive AI-infused applications. We examine the current state of representation within datasets sourced by people with disabilities by reviewing publicly-available information of 190 datasets, we call these accessibility datasets. We find that accessibility datasets represent diverse ages, but have gender and race representation gaps. Additionally, we investigate how the sensitive and complex nature of demographic variables makes classification difficult and inconsistent (e.g., gender, race & ethnicity), with the source of labeling often unknown. By reflecting on the current challenges and opportunities for representation of disabled data contributors, we hope our effort expands the space of possibility for greater inclusion of marginalized communities in AI-infused systems.
Network Report: A Structured Description for Network Datasets
Jun 08, 2022
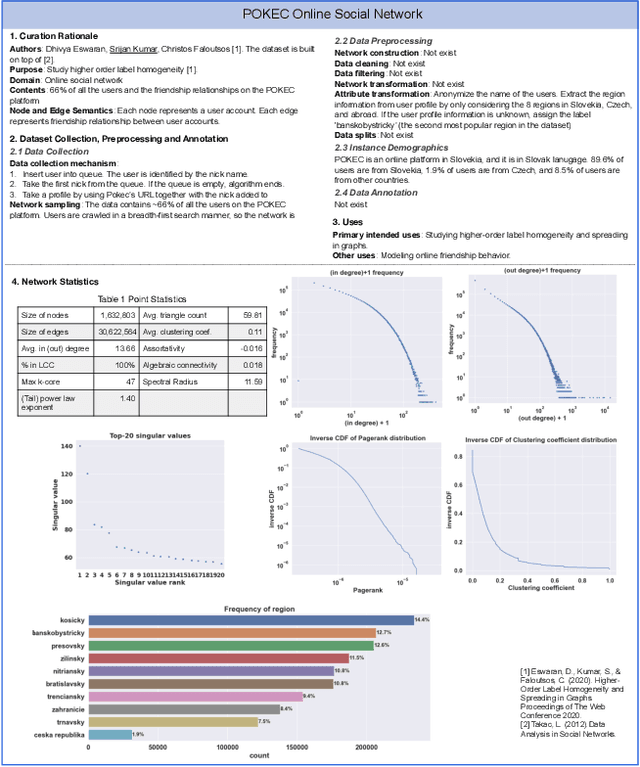

The rapid development of network science and technologies depends on shareable datasets. Currently, there is no standard practice for reporting and sharing network datasets. Some network dataset providers only share links, while others provide some contexts or basic statistics. As a result, critical information may be unintentionally dropped, and network dataset consumers may misunderstand or overlook critical aspects. Inappropriately using a network dataset can lead to severe consequences (e.g., discrimination) especially when machine learning models on networks are deployed in high-stake domains. Challenges arise as networks are often used across different domains (e.g., network science, physics, etc) and have complex structures. To facilitate the communication between network dataset providers and consumers, we propose network report. A network report is a structured description that summarizes and contextualizes a network dataset. Network report extends the idea of dataset reports (e.g., Datasheets for Datasets) from prior work with network-specific descriptions of the non-i.i.d. nature, demographic information, network characteristics, etc. We hope network reports encourage transparency and accountability in network research and development across different fields.
MM-ALT: A Multimodal Automatic Lyric Transcription System
Jul 13, 2022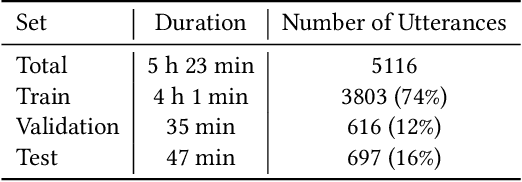
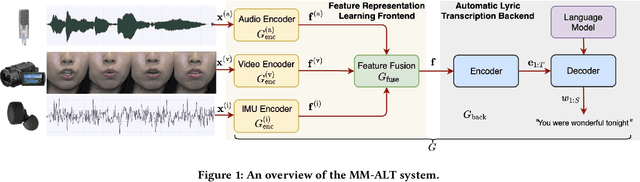
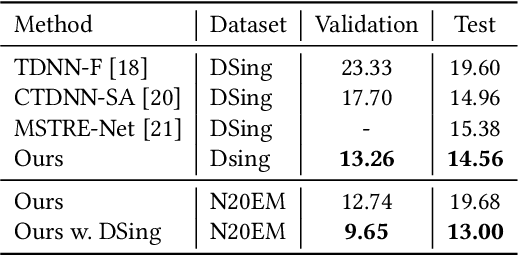
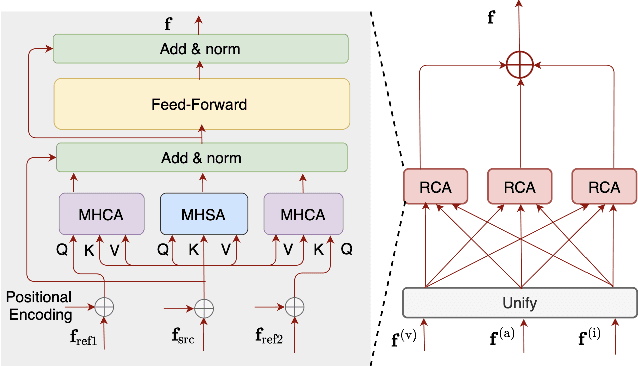
Automatic lyric transcription (ALT) is a nascent field of study attracting increasing interest from both the speech and music information retrieval communities, given its significant application potential. However, ALT with audio data alone is a notoriously difficult task due to instrumental accompaniment and musical constraints resulting in degradation of both the phonetic cues and the intelligibility of sung lyrics. To tackle this challenge, we propose the MultiModal Automatic Lyric Transcription system (MM-ALT), together with a new dataset, N20EM, which consists of audio recordings, videos of lip movements, and inertial measurement unit (IMU) data of an earbud worn by the performing singer. We first adapt the wav2vec 2.0 framework from automatic speech recognition (ASR) to the ALT task. We then propose a video-based ALT method and an IMU-based voice activity detection (VAD) method. In addition, we put forward the Residual Cross Attention (RCA) mechanism to fuse data from the three modalities (i.e., audio, video, and IMU). Experiments show the effectiveness of our proposed MM-ALT system, especially in terms of noise robustness.