 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Universal Adaptive Data Augmentation
Jul 14, 2022
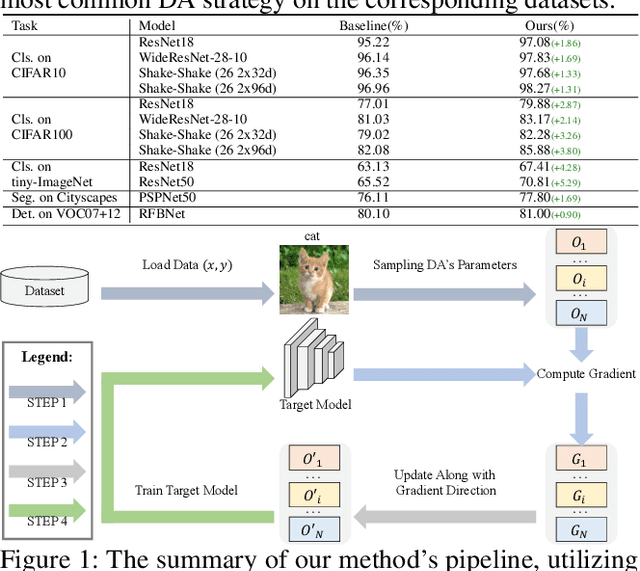
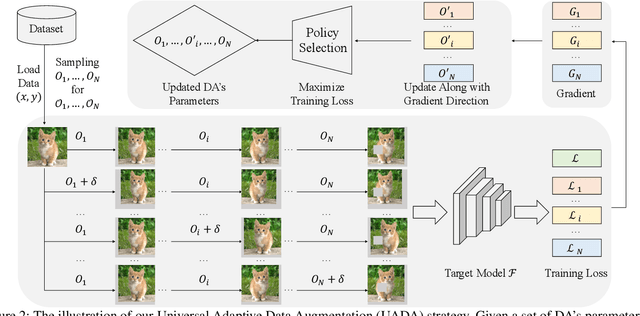
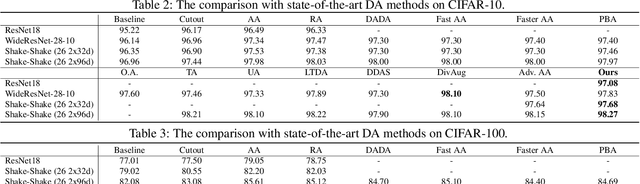
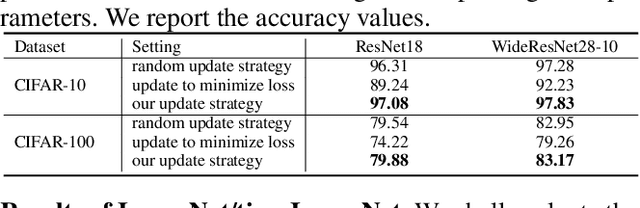
Existing automatic data augmentation (DA) methods either ignore updating DA's parameters according to the target model's state during training or adopt update strategies that are not effective enough. In this work, we design a novel data augmentation strategy called "Universal Adaptive Data Augmentation" (UADA). Different from existing methods, UADA would adaptively update DA's parameters according to the target model's gradient information during training: given a pre-defined set of DA operations, we randomly decide types and magnitudes of DA operations for every data batch during training, and adaptively update DA's parameters along the gradient direction of the loss concerning DA's parameters. In this way, UADA can increase the training loss of the target networks, and the target networks would learn features from harder samples to improve the generalization. Moreover, UADA is very general and can be utilized in numerous tasks, e.g., image classification, semantic segmentation and object detection. Extensive experiments with various models are conducted on CIFAR-10, CIFAR-100, ImageNet, tiny-ImageNet, Cityscapes, and VOC07+12 to prove the significant performance improvements brought by our proposed adaptive augmentation.
Speech enhancement guided by contextual articulatory information
Nov 15, 2020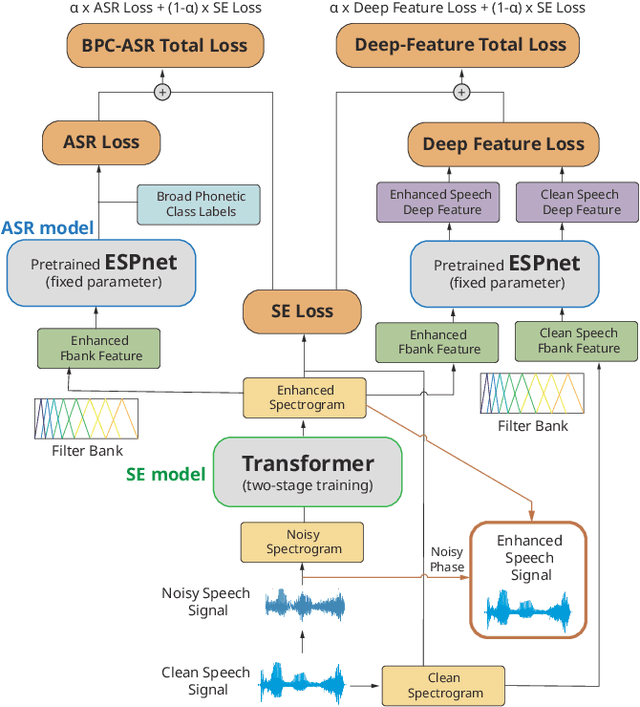
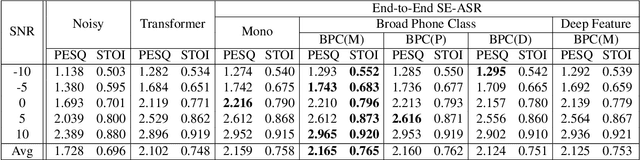
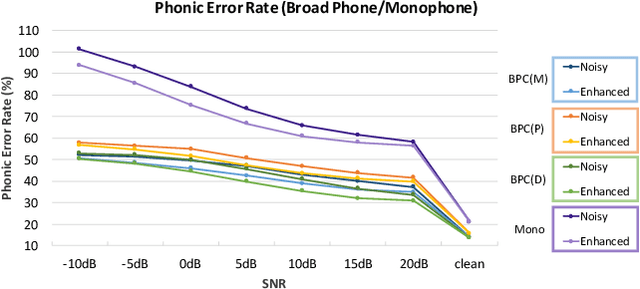
Previous studies have confirmed the effectiveness of leveraging articulatory information to attain improved speech enhancement (SE) performance. By augmenting the original acoustic features with the place/manner of articulatory features, the SE process can be guided to consider the articulatory properties of the input speech when performing enhancement. Hence, we believe that the contextual information of articulatory attributes should include useful information and can further benefit SE. In this study, we propose an SE system that incorporates contextual articulatory information; such information is obtained using broad phone class (BPC) end-to-end automatic speech recognition (ASR). Meanwhile, two training strategies are developed to train the SE system based on the BPC-based ASR: multitask-learning and deep-feature training strategies. Experimental results on the TIMIT dataset confirm that the contextual articulatory information facilitates an SE system in achieving better results. Moreover, in contrast to another SE system that is trained with monophonic ASR, the BPC-based ASR (providing contextual articulatory information) can improve the SE performance more effectively under different signal-to-noise ratios(SNR).
Self-Supervised-RCNN for Medical Image Segmentation with Limited Data Annotation
Jul 17, 2022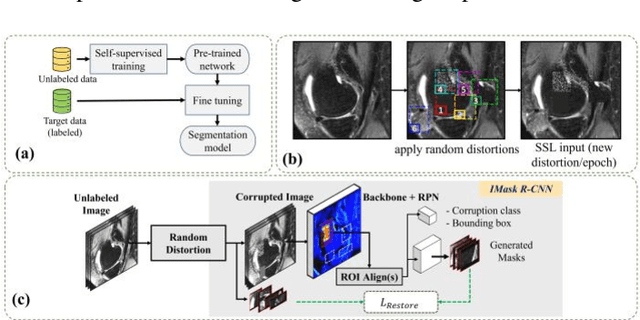
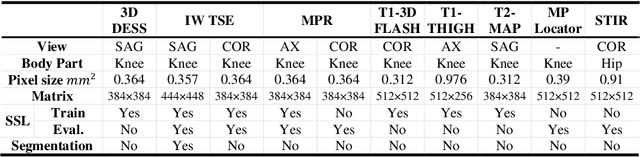
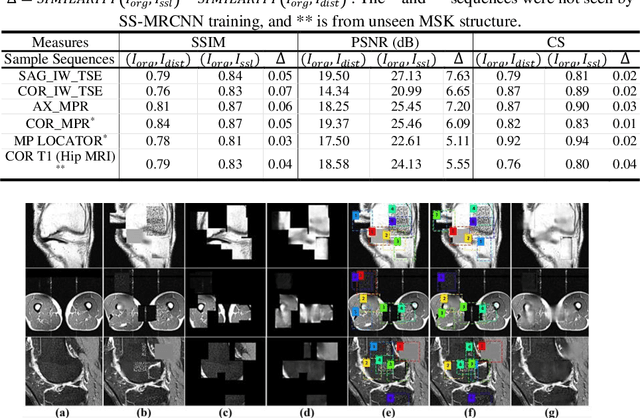
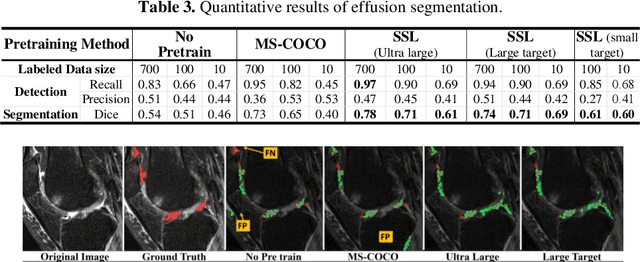
Many successful methods developed for medical image analysis that are based on machine learning use supervised learning approaches, which often require large datasets annotated by experts to achieve high accuracy. However, medical data annotation is time-consuming and expensive, especially for segmentation tasks. To solve the problem of learning with limited labeled medical image data, an alternative deep learning training strategy based on self-supervised pretraining on unlabeled MRI scans is proposed in this work. Our pretraining approach first, randomly applies different distortions to random areas of unlabeled images and then predicts the type of distortions and loss of information. To this aim, an improved version of Mask-RCNN architecture has been adapted to localize the distortion location and recover the original image pixels. The effectiveness of the proposed method for segmentation tasks in different pre-training and fine-tuning scenarios is evaluated based on the Osteoarthritis Initiative dataset. Using this self-supervised pretraining method improved the Dice score by 20% compared to training from scratch. The proposed self-supervised learning is simple, effective, and suitable for different ranges of medical image analysis tasks including anomaly detection, segmentation, and classification.
PrePARE: Predictive Proprioception for Agile Failure Event Detection in Robotic Exploration of Extreme Terrains
Jul 30, 2022
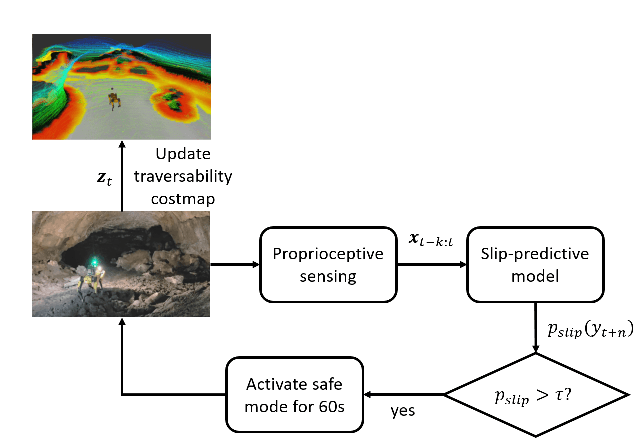

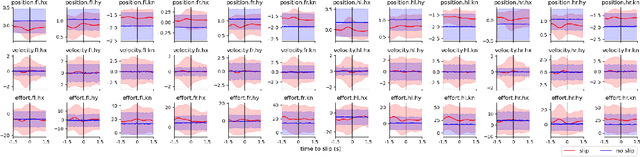
Legged robots can traverse a wide variety of terrains, some of which may be challenging for wheeled robots, such as stairs or highly uneven surfaces. However, quadruped robots face stability challenges on slippery surfaces. This can be resolved by adjusting the robot's locomotion by switching to more conservative and stable locomotion modes, such as crawl mode (where three feet are in contact with the ground always) or amble mode (where one foot touches down at a time) to prevent potential falls. To tackle these challenges, we propose an approach to learn a model from past robot experience for predictive detection of potential failures. Accordingly, we trigger gait switching merely based on proprioceptive sensory information. To learn this predictive model, we propose a semi-supervised process for detecting and annotating ground truth slip events in two stages: We first detect abnormal occurrences in the time series sequences of the gait data using an unsupervised anomaly detector, and then, the anomalies are verified with expert human knowledge in a replay simulation to assert the event of a slip. These annotated slip events are then used as ground truth examples to train an ensemble decision learner for predicting slip probabilities across terrains for traversability. We analyze our model on data recorded by a legged robot on multiple sites with slippery terrain. We demonstrate that a potential slip event can be predicted up to 720 ms ahead of a potential fall with an average precision greater than 0.95 and an average F-score of 0.82. Finally, we validate our approach in real-time by deploying it on a legged robot and switching its gait mode based on slip event detection.
Mobility-Aware Cooperative Caching in Vehicular Edge Computing Based on Asynchronous Federated and Deep Reinforcement Learning
Aug 02, 2022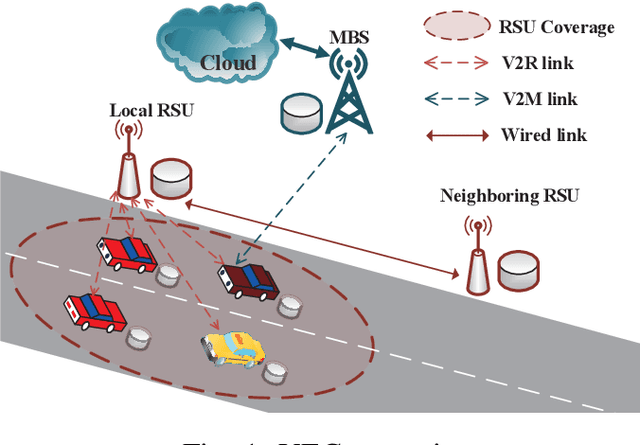
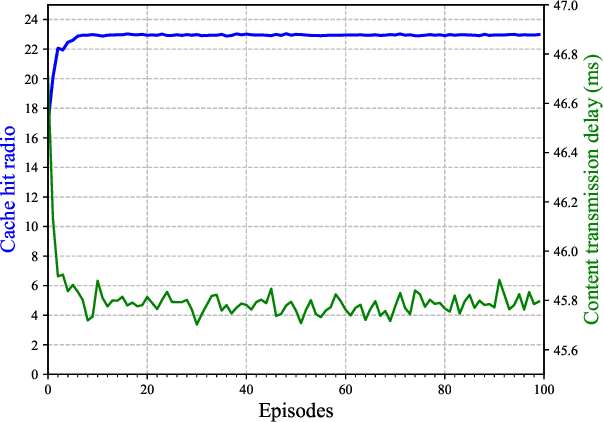
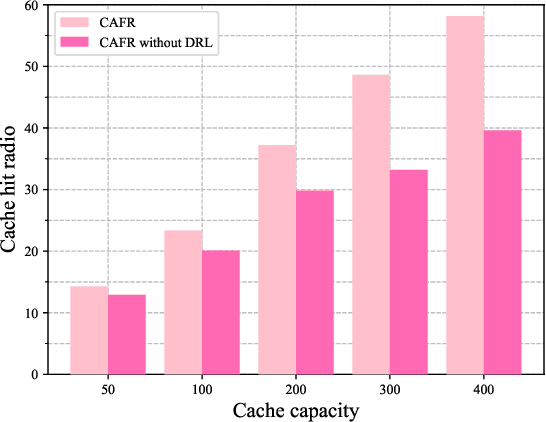
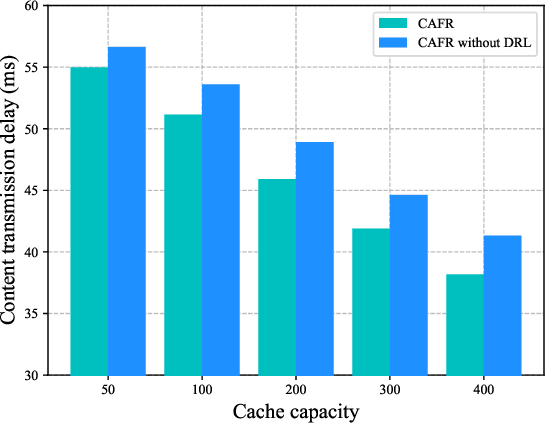
The vehicular edge computing (VEC) can cache contents in different RSUs at the network edge to support the real-time vehicular applications. In VEC, owing to the high-mobility characteristics of vehicles, it is necessary to cache the user data in advance and learn the most popular and interesting contents for vehicular users. Since user data usually contains privacy information, users are reluctant to share their data with others. To solve this problem, traditional federated learning (FL) needs to update the global model synchronously through aggregating all users' local models to protect users' privacy. However, vehicles may frequently drive out of the coverage area of the VEC before they achieve their local model trainings and thus the local models cannot be uploaded as expected, which would reduce the accuracy of the global model. In addition, the caching capacity of the local RSU is limited and the popular contents are diverse, thus the size of the predicted popular contents usually exceeds the cache capacity of the local RSU. Hence, the VEC should cache the predicted popular contents in different RSUs while considering the content transmission delay. In this paper, we consider the mobility of vehicles and propose a cooperative Caching scheme in the VEC based on Asynchronous Federated and deep Reinforcement learning (CAFR). We first consider the mobility of vehicles and propose an asynchronous FL algorithm to obtain an accurate global model, and then propose an algorithm to predict the popular contents based on the global model. In addition, we consider the mobility of vehicles and propose a deep reinforcement learning algorithm to obtain the optimal cooperative caching location for the predicted popular contents in order to optimize the content transmission delay. Extensive experimental results have demonstrated that the CAFR scheme outperforms other baseline caching schemes.
Push--Pull with Device Sampling
Jun 08, 2022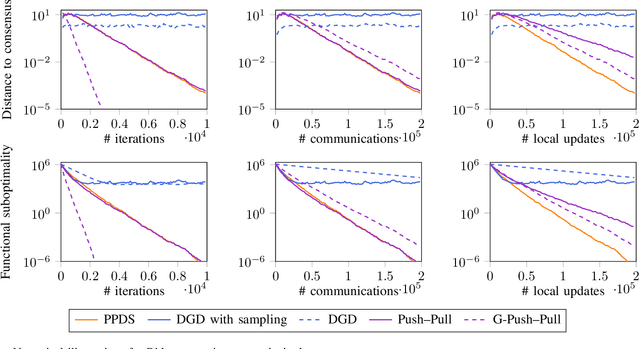
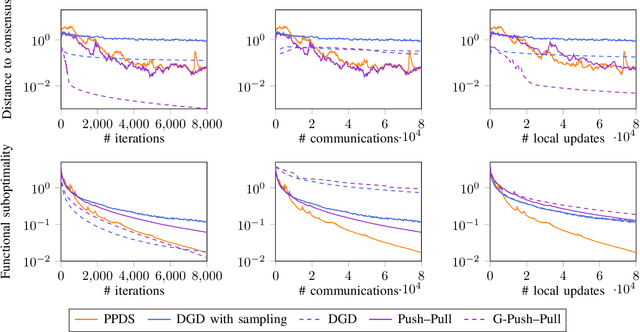
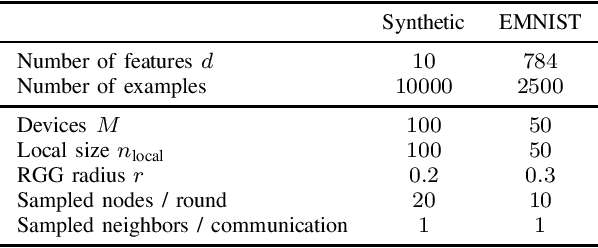
We consider decentralized optimization problems in which a number of agents collaborate to minimize the average of their local functions by exchanging over an underlying communication graph. Specifically, we place ourselves in an asynchronous model where only a random portion of nodes perform computation at each iteration, while the information exchange can be conducted between all the nodes and in an asymmetric fashion. For this setting, we propose an algorithm that combines gradient tracking and variance reduction over the entire network. This enables each node to track the average of the gradients of the objective functions. Our theoretical analysis shows that the algorithm converges linearly, when the local objective functions are strongly convex, under mild connectivity conditions on the expected mixing matrices. In particular, our result does not require the mixing matrices to be doubly stochastic. In the experiments, we investigate a broadcast mechanism that transmits information from computing nodes to their neighbors, and confirm the linear convergence of our method on both synthetic and real-world datasets.
Model-based Unbiased Learning to Rank
Jul 26, 2022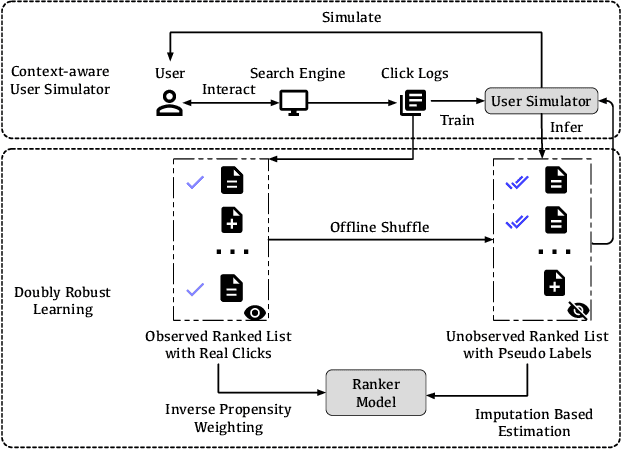
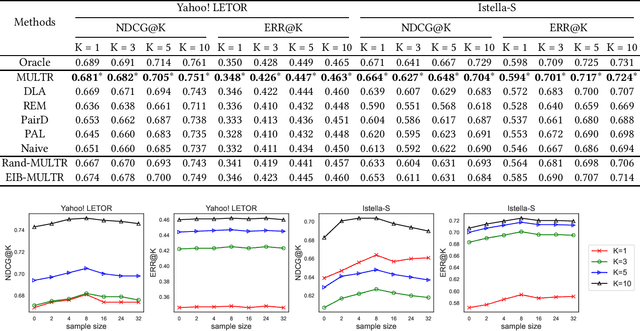
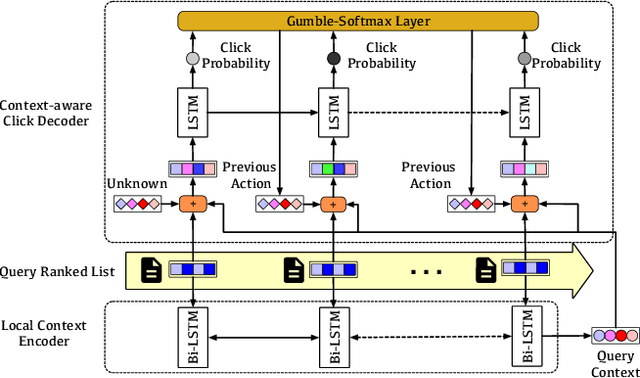
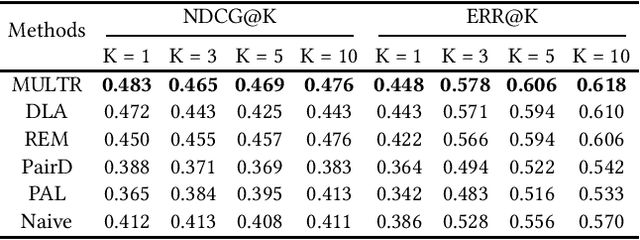
Unbiased Learning to Rank~(ULTR) that learns to rank documents with biased user feedback data is a well-known challenge in information retrieval. Existing methods in unbiased learning to rank typically rely on click modeling or inverse propensity weighting~(IPW). Unfortunately, the search engines are faced with severe long-tail query distribution, where neither click modeling nor IPW can handle well. Click modeling suffers from data sparsity problem since the same query-document pair appears limited times on tail queries; IPW suffers from high variance problem since it is highly sensitive to small propensity score values. Therefore, a general debiasing framework that works well under tail queries is in desperate need. To address this problem, we propose a model-based unbiased learning-to-rank framework. Specifically, we develop a general context-aware user simulator to generate pseudo clicks for unobserved ranked lists to train rankers, which addresses the data sparsity problem. In addition, considering the discrepancy between pseudo clicks and actual clicks, we take the observation of a ranked list as the treatment variable and further incorporate inverse propensity weighting with pseudo labels in a doubly robust way. The derived bias and variance indicate that the proposed model-based method is more robust than existing methods. Finally, extensive experiments on benchmark datasets, including simulated datasets and real click logs, demonstrate that the proposed model-based method consistently performs outperforms state-of-the-art methods in various scenarios.
HTCInfoMax: A Global Model for Hierarchical Text Classification via Information Maximization
Apr 12, 2021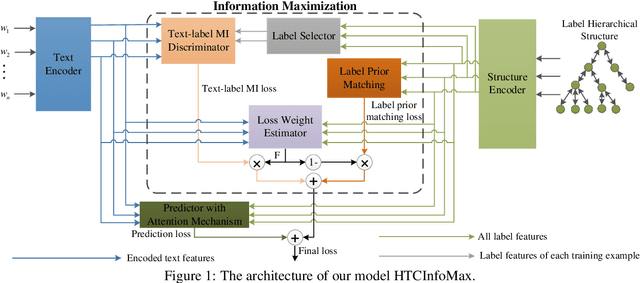
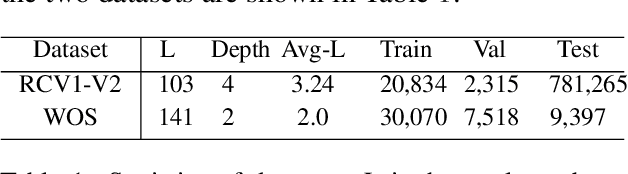
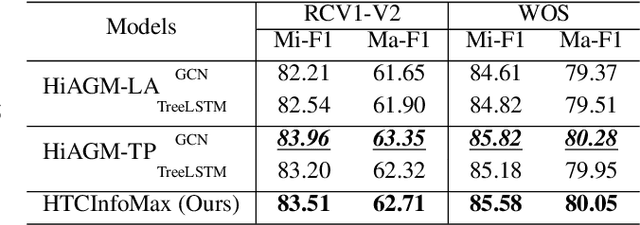
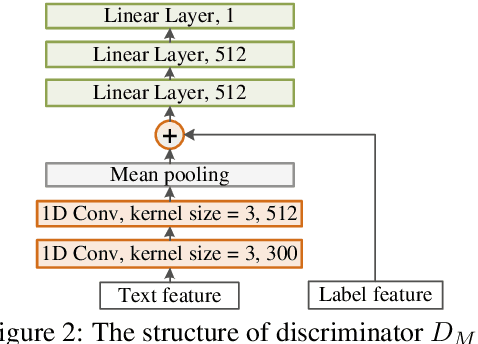
The current state-of-the-art model HiAGM for hierarchical text classification has two limitations. First, it correlates each text sample with all labels in the dataset which contains irrelevant information. Second, it does not consider any statistical constraint on the label representations learned by the structure encoder, while constraints for representation learning are proved to be helpful in previous work. In this paper, we propose HTCInfoMax to address these issues by introducing information maximization which includes two modules: text-label mutual information maximization and label prior matching. The first module can model the interaction between each text sample and its ground truth labels explicitly which filters out irrelevant information. The second one encourages the structure encoder to learn better representations with desired characteristics for all labels which can better handle label imbalance in hierarchical text classification. Experimental results on two benchmark datasets demonstrate the effectiveness of the proposed HTCInfoMax.
SYNERgy between SYNaptic consolidation and Experience Replay for general continual learning
Jun 08, 2022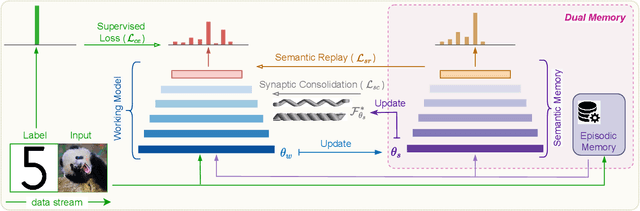
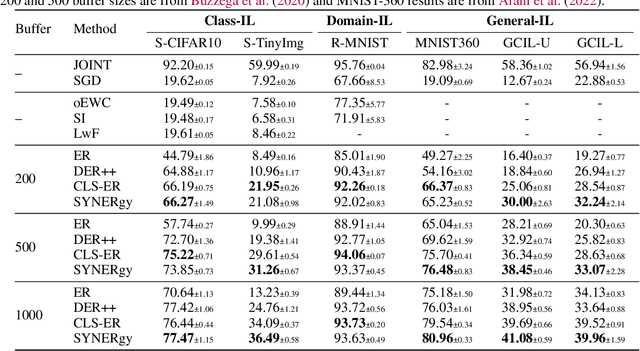
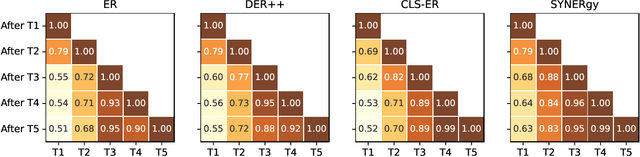
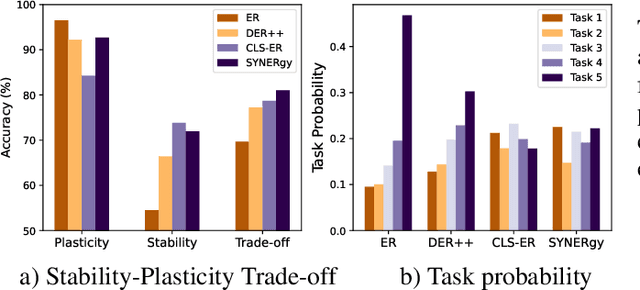
Continual learning (CL) in the brain is facilitated by a complex set of mechanisms. This includes the interplay of multiple memory systems for consolidating information as posited by the complementary learning systems (CLS) theory and synaptic consolidation for protecting the acquired knowledge from erasure. Thus, we propose a general CL method that creates a synergy between SYNaptic consolidation and dual memory Experience Replay (SYNERgy). Our method maintains a semantic memory that accumulates and consolidates information across the tasks and interacts with the episodic memory for effective replay. It further employs synaptic consolidation by tracking the importance of parameters during the training trajectory and anchoring them to the consolidated parameters in the semantic memory. To the best of our knowledge, our study is the first to employ dual memory experience replay in conjunction with synaptic consolidation that is suitable for general CL whereby the network does not utilize task boundaries or task labels during training or inference. Our evaluation on various challenging CL scenarios and characteristics analyses demonstrate the efficacy of incorporating both synaptic consolidation and CLS theory in enabling effective CL in DNNs.
Energy Trees: Regression and Classification With Structured and Mixed-Type Covariates
Jul 10, 2022
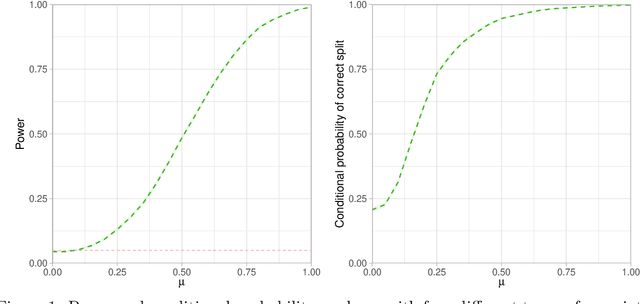
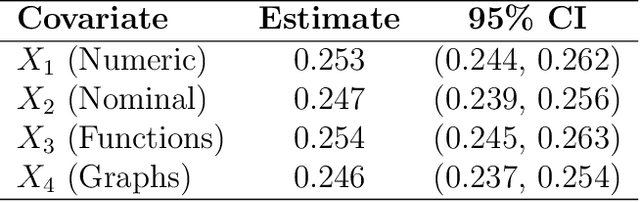
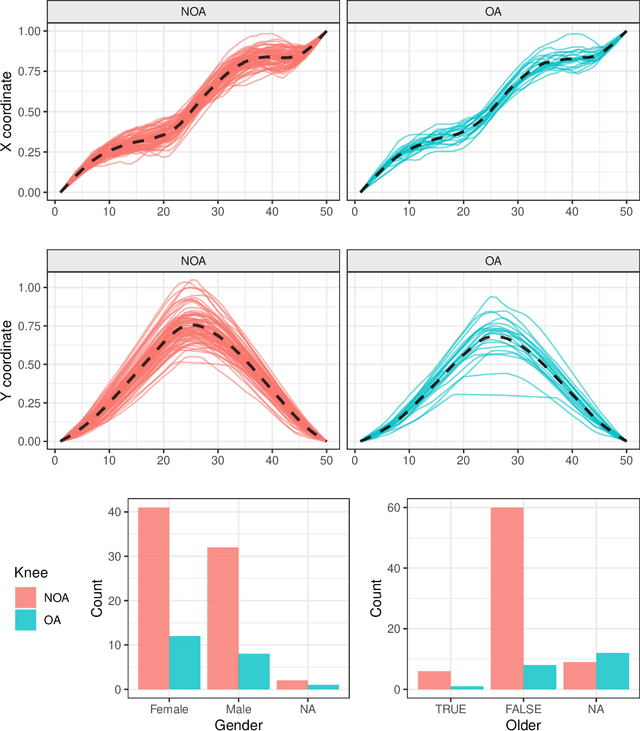
The continuous growth of data complexity requires methods and models that adequately account for non-trivial structures, as any simplification may induce loss of information. Many analytical tools have been introduced to work with complex data objects in their original form, but such tools can typically deal with single-type variables only. In this work, we propose Energy Trees as a model for regression and classification tasks where covariates are potentially both structured and of different types. Energy Trees incorporate Energy Statistics to generalize Conditional Trees, from which they inherit statistically sound foundations, interpretability, scale invariance, and lack of distributional assumptions. We focus on functions and graphs as structured covariates and we show how the model can be easily adapted to work with almost any other type of variable. Through an extensive simulation study, we highlight the good performance of our proposal in terms of variable selection and robustness to overfitting. Finally, we validate the model's predictive ability through two empirical analyses with human biological data.