 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Joint Detection, Equalization and Decoding for Short-Packet Communications
Jul 12, 2022
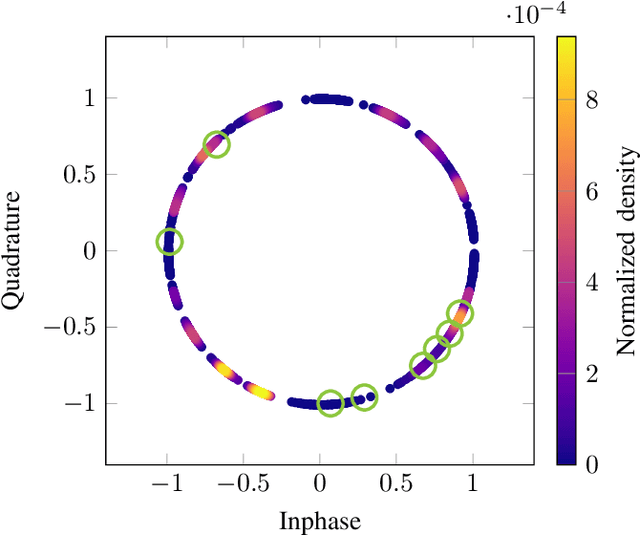
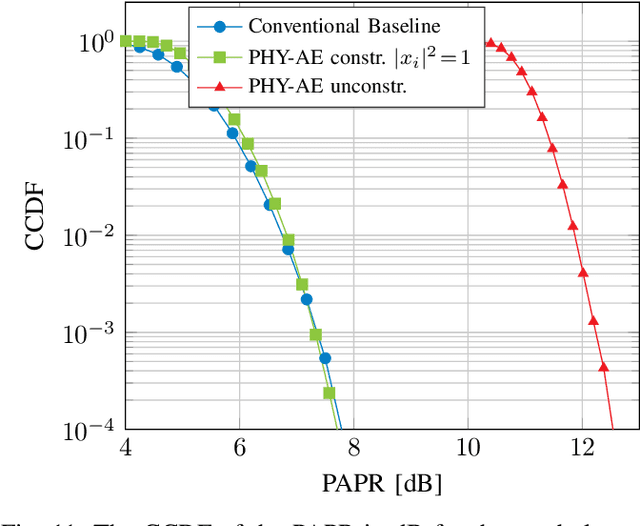
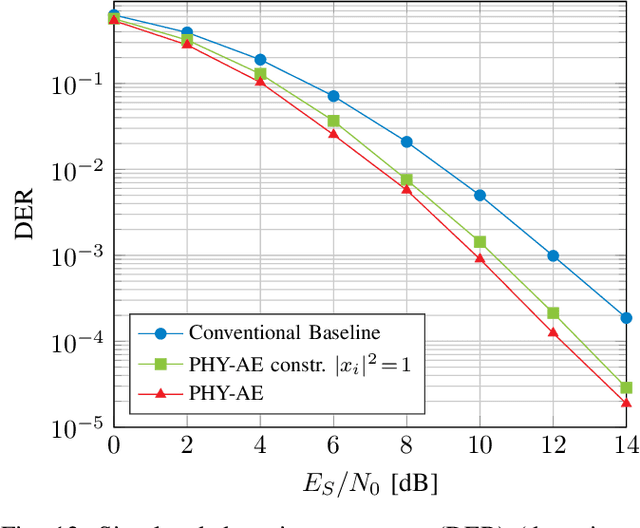
We propose and practically demonstrate a joint detection and decoding scheme for short-packet wireless communications in scenarios that require to first detect the presence of a message before actually decoding it. For this, we extend the recently proposed serial Turbo-autoencoder neural network (NN) architecture and train it to find short messages that can be, all "at once", detected, synchronized, equalized and decoded when sent over an unsynchronized channel with memory. The conceptional advantage of the proposed system stems from a holistic message structure with superimposed pilots for joint detection and decoding without the need of relying on a dedicated preamble. This results not only in higher spectral efficiency, but also translates into the possibility of shorter messages compared to using a dedicated preamble. We compare the detection error rate (DER), bit error rate (BER) and block error rate (BLER) performance of the proposed system with a hand-crafted state-of-the-art conventional baseline and our simulations show a significant advantage of the proposed autoencoder-based system over the conventional baseline in every scenario up to messages conveying k = 96 information bits. Finally, we practically evaluate and confirm the improved performance of the proposed system over-the-air (OTA) using a software-defined radio (SDR)-based measurement testbed.
Attention-driven Active Vision for Efficient Reconstruction of Plants and Targeted Plant Parts
Jun 21, 2022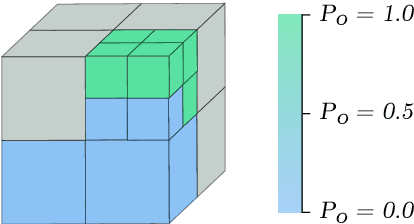
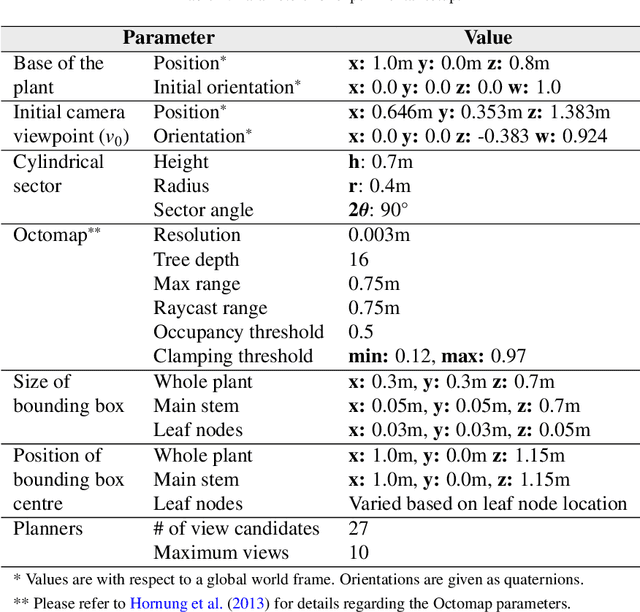
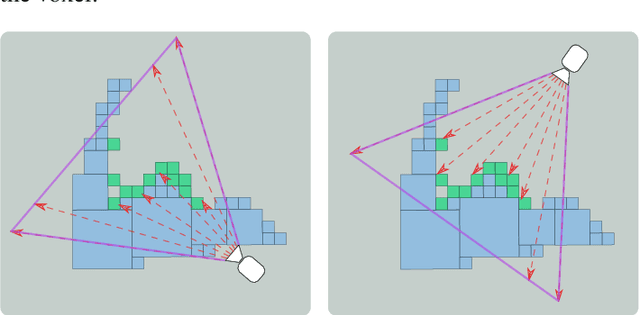
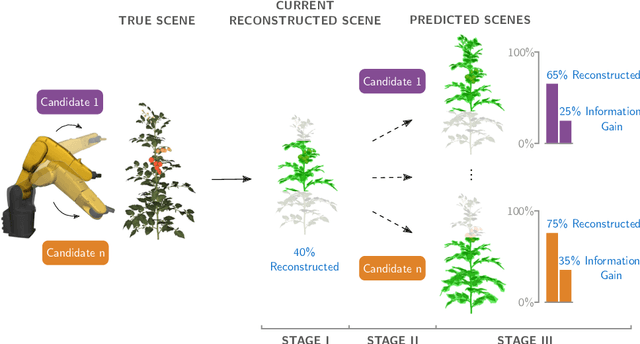
Visual reconstruction of tomato plants by a robot is extremely challenging due to the high levels of variation and occlusion in greenhouse environments. The paradigm of active-vision helps overcome these challenges by reasoning about previously acquired information and systematically planning camera viewpoints to gather novel information about the plant. However, existing active-vision algorithms cannot perform well on targeted perception objectives, such as the 3D reconstruction of leaf nodes, because they do not distinguish between the plant-parts that need to be reconstructed and the rest of the plant. In this paper, we propose an attention-driven active-vision algorithm that considers only the relevant plant-parts according to the task-at-hand. The proposed approach was evaluated in a simulated environment on the task of 3D reconstruction of tomato plants at varying levels of attention, namely the whole plant, the main stem and the leaf nodes. Compared to pre-defined and random approaches, our approach improves the accuracy of 3D reconstruction by 9.7% and 5.3% for the whole plant, 14.2% and 7.9% for the main stem, and 25.9% and 17.3% for the leaf nodes respectively within the first 3 viewpoints. Also, compared to pre-defined and random approaches, our approach reconstructs 80% of the whole plant and the main stem in 1 less viewpoint and 80% of the leaf nodes in 3 less viewpoints. We also demonstrated that the attention-driven NBV planner works effectively despite changes to the plant models, the amount of occlusion, the number of candidate viewpoints and the resolutions of reconstruction. By adding an attention mechanism to active-vision, it is possible to efficiently reconstruct the whole plant and targeted plant parts. We conclude that an attention mechanism for active-vision is necessary to significantly improve the quality of perception in complex agro-food environments.
Node Embedding using Mutual Information and Self-Supervision based Bi-level Aggregation
Apr 27, 2021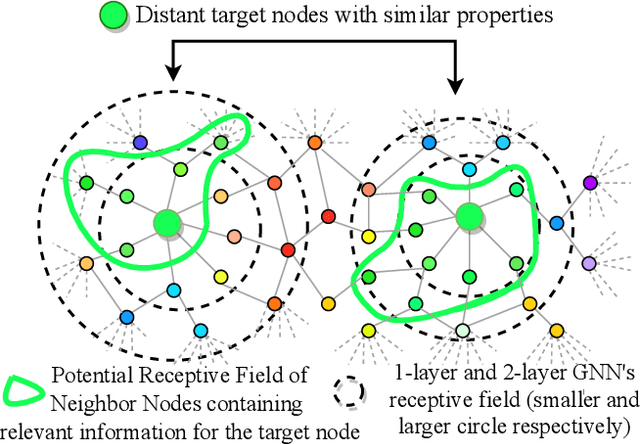
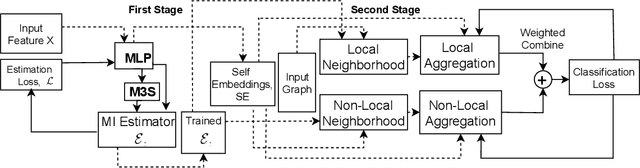

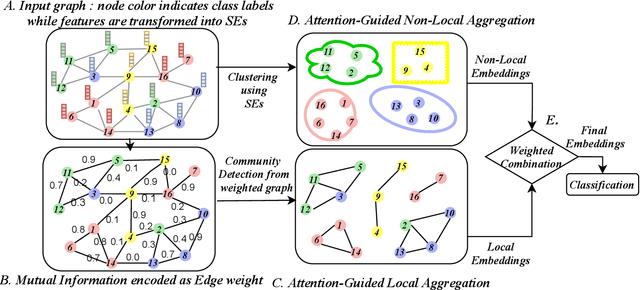
Graph Neural Networks (GNNs) learn low dimensional representations of nodes by aggregating information from their neighborhood in graphs. However, traditional GNNs suffer from two fundamental shortcomings due to their local ($l$-hop neighborhood) aggregation scheme. First, not all nodes in the neighborhood carry relevant information for the target node. Since GNNs do not exclude noisy nodes in their neighborhood, irrelevant information gets aggregated, which reduces the quality of the representation. Second, traditional GNNs also fail to capture long-range non-local dependencies between nodes. To address these limitations, we exploit mutual information (MI) to define two types of neighborhood, 1) \textit{Local Neighborhood} where nodes are densely connected within a community and each node would share higher MI with its neighbors, and 2) \textit{Non-Local Neighborhood} where MI-based node clustering is introduced to assemble informative but graphically distant nodes in the same cluster. To generate node presentations, we combine the embeddings generated by bi-level aggregation - local aggregation to aggregate features from local neighborhoods to avoid noisy information and non-local aggregation to aggregate features from non-local neighborhoods. Furthermore, we leverage self-supervision learning to estimate MI with few labeled data. Finally, we show that our model significantly outperforms the state-of-the-art methods in a wide range of assortative and disassortative graphs.
Unsupervised Context Aware Sentence Representation Pretraining for Multi-lingual Dense Retrieval
Jun 07, 2022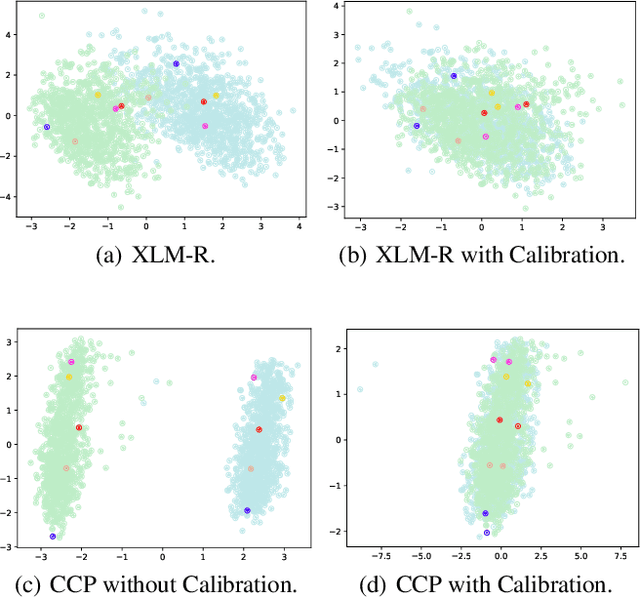

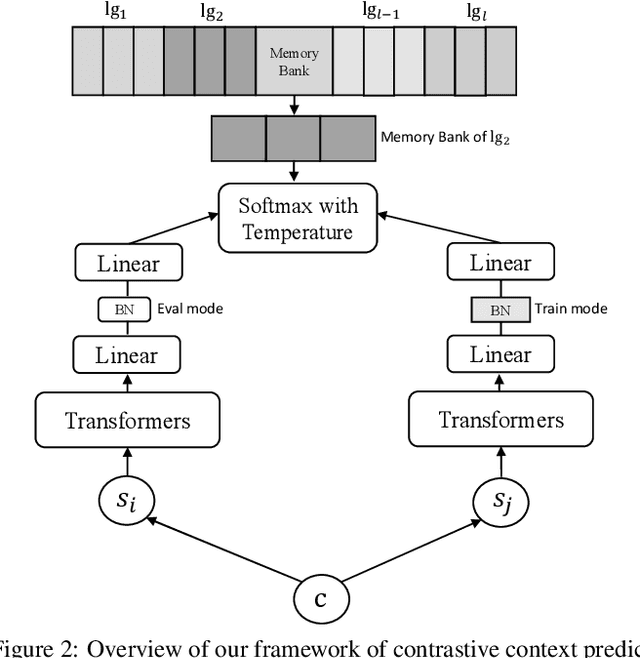

Recent research demonstrates the effectiveness of using pretrained language models (PLM) to improve dense retrieval and multilingual dense retrieval. In this work, we present a simple but effective monolingual pretraining task called contrastive context prediction~(CCP) to learn sentence representation by modeling sentence level contextual relation. By pushing the embedding of sentences in a local context closer and pushing random negative samples away, different languages could form isomorphic structure, then sentence pairs in two different languages will be automatically aligned. Our experiments show that model collapse and information leakage are very easy to happen during contrastive training of language model, but language-specific memory bank and asymmetric batch normalization operation play an essential role in preventing collapsing and information leakage, respectively. Besides, a post-processing for sentence embedding is also very effective to achieve better retrieval performance. On the multilingual sentence retrieval task Tatoeba, our model achieves new SOTA results among methods without using bilingual data. Our model also shows larger gain on Tatoeba when transferring between non-English pairs. On two multi-lingual query-passage retrieval tasks, XOR Retrieve and Mr.TYDI, our model even achieves two SOTA results in both zero-shot and supervised setting among all pretraining models using bilingual data.
Inspector: Pixel-Based Automated Game Testing via Exploration, Detection, and Investigation
Jul 18, 2022
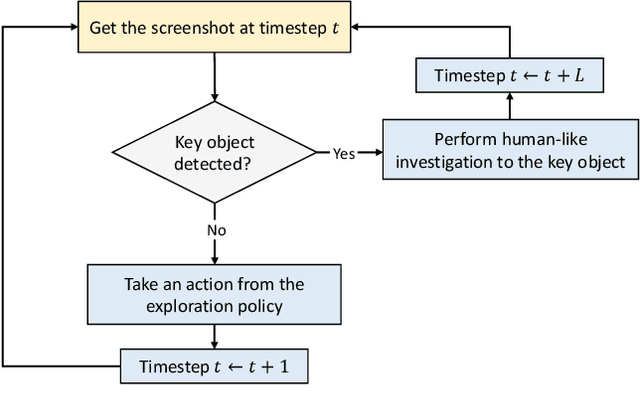

Deep reinforcement learning (DRL) has attracted much attention in automated game testing. Early attempts rely on game internal information for game space exploration, thus requiring deep integration with games, which is inconvenient for practical applications. In this work, we propose using only screenshots/pixels as input for automated game testing and build a general game testing agent, Inspector, that can be easily applied to different games without deep integration with games. In addition to covering all game space for testing, our agent tries to take human-like behaviors to interact with key objects in a game, since some bugs usually happen in player-object interactions. Inspector is based on purely pixel inputs and comprises three key modules: game space explorer, key object detector, and human-like object investigator. Game space explorer aims to explore the whole game space by using a curiosity-based reward function with pixel inputs. Key object detector aims to detect key objects in a game, based on a small number of labeled screenshots. Human-like object investigator aims to mimic human behaviors for investigating key objects via imitation learning. We conduct experiments on two popular video games: Shooter Game and Action RPG Game. Experiment results demonstrate the effectiveness of Inspector in exploring game space, detecting key objects, and investigating objects. Moreover, Inspector successfully discovers two potential bugs in those two games. The demo video of Inspector is available at https://github.com/Inspector-GameTesting/Inspector-GameTesting.
Eliciting and Learning with Soft Labels from Every Annotator
Jul 02, 2022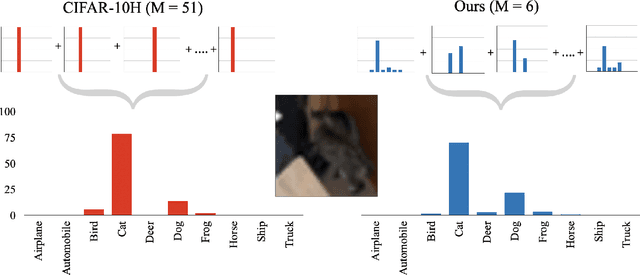

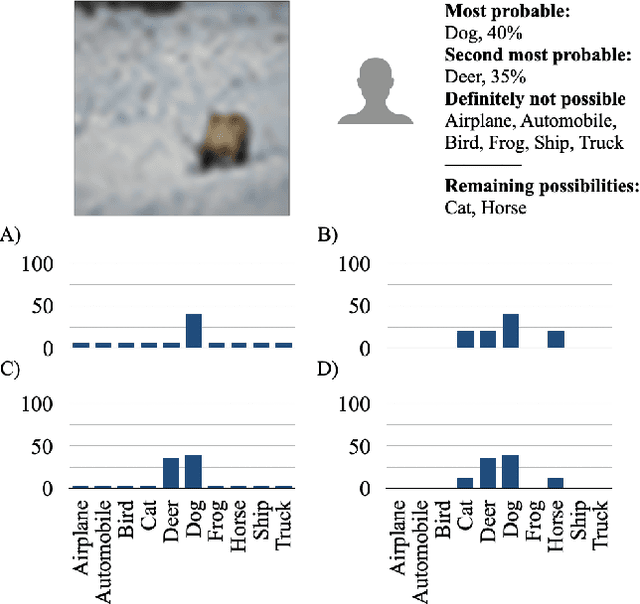

The labels used to train machine learning (ML) models are of paramount importance. Typically for ML classification tasks, datasets contain hard labels, yet learning using soft labels has been shown to yield benefits for model generalization, robustness, and calibration. Earlier work found success in forming soft labels from multiple annotators' hard labels; however, this approach may not converge to the best labels and necessitates many annotators, which can be expensive and inefficient. We focus on efficiently eliciting soft labels from individual annotators. We collect and release a dataset of soft labels for CIFAR-10 via a crowdsourcing study ($N=242$). We demonstrate that learning with our labels achieves comparable model performance to prior approaches while requiring far fewer annotators. Our elicitation methodology therefore shows promise towards enabling practitioners to enjoy the benefits of improved model performance and reliability with fewer annotators, and serves as a guide for future dataset curators on the benefits of leveraging richer information, such as categorical uncertainty, from individual annotators.
A Contextual Combinatorial Semi-Bandit Approach to Network Bottleneck Identification
Jun 16, 2022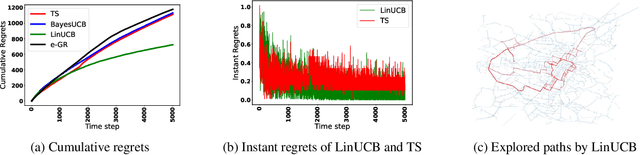
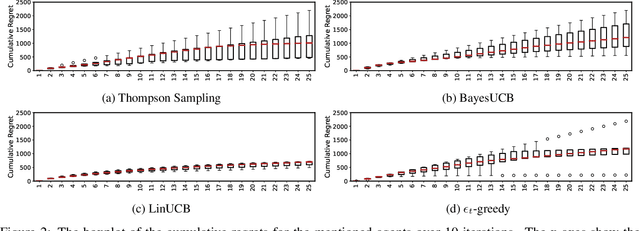
Bottleneck identification is a challenging task in network analysis, especially when the network is not fully specified. To address this task, we develop a unified online learning framework based on combinatorial semi-bandits that performs bottleneck identification alongside learning the specifications of the underlying network. Within this framework, we adapt and investigate several combinatorial semi-bandit methods such as epsilon-greedy, LinUCB, BayesUCB, and Thompson Sampling. Our framework is able to employ contextual information in the form of contextual bandits. We evaluate our framework on the real-world application of road networks and demonstrate its effectiveness in different settings.
DuetFace: Collaborative Privacy-Preserving Face Recognition via Channel Splitting in the Frequency Domain
Jul 15, 2022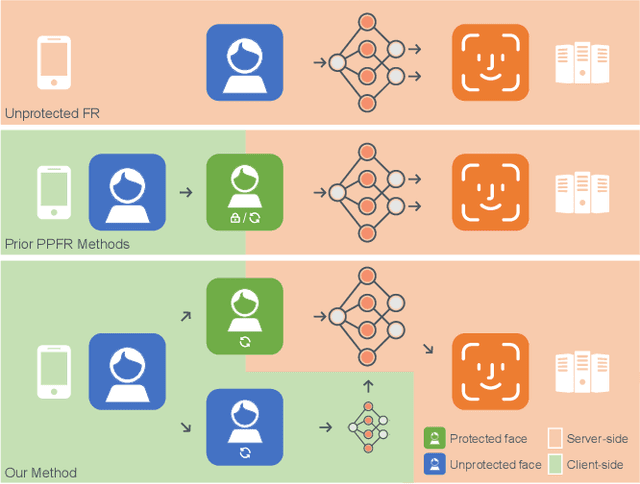
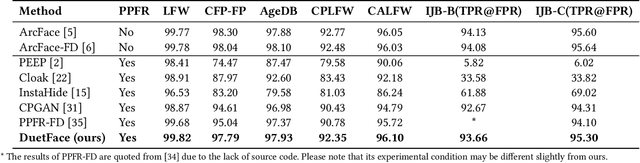
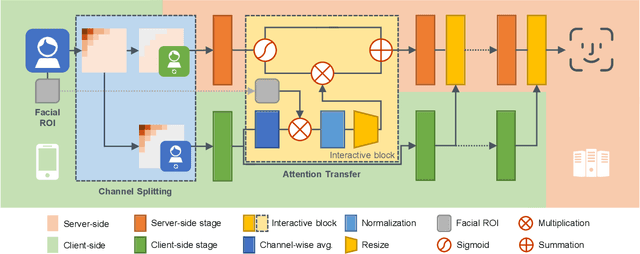
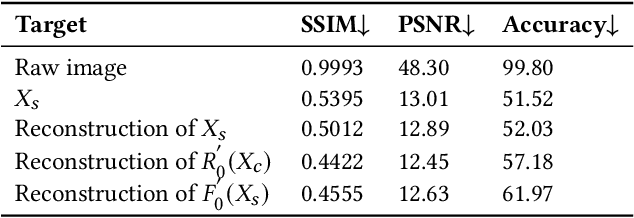
With the wide application of face recognition systems, there is rising concern that original face images could be exposed to malicious intents and consequently cause personal privacy breaches. This paper presents DuetFace, a novel privacy-preserving face recognition method that employs collaborative inference in the frequency domain. Starting from a counterintuitive discovery that face recognition can achieve surprisingly good performance with only visually indistinguishable high-frequency channels, this method designs a credible split of frequency channels by their cruciality for visualization and operates the server-side model on non-crucial channels. However, the model degrades in its attention to facial features due to the missing visual information. To compensate, the method introduces a plug-in interactive block to allow attention transfer from the client-side by producing a feature mask. The mask is further refined by deriving and overlaying a facial region of interest (ROI). Extensive experiments on multiple datasets validate the effectiveness of the proposed method in protecting face images from undesired visual inspection, reconstruction, and identification while maintaining high task availability and performance. Results show that the proposed method achieves a comparable recognition accuracy and computation cost to the unprotected ArcFace and outperforms the state-of-the-art privacy-preserving methods. The source code is available at https://github.com/Tencent/TFace/tree/master/recognition/tasks/duetface.
End-to-end speech recognition modeling from de-identified data
Jul 12, 2022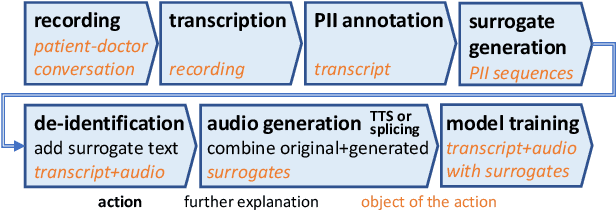
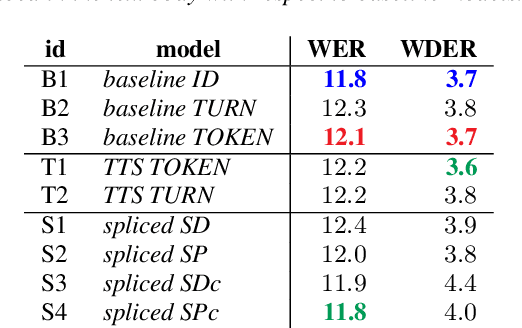
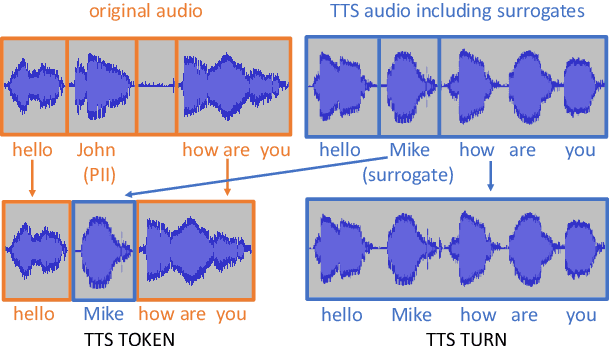
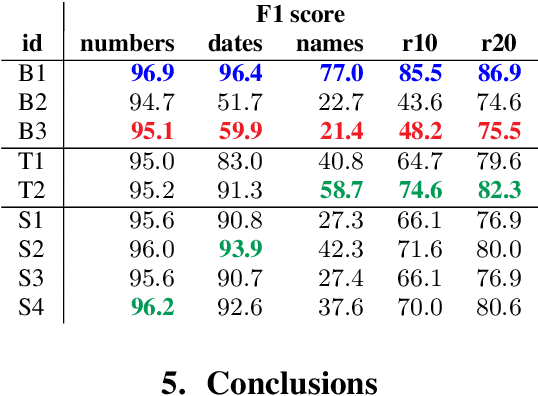
De-identification of data used for automatic speech recognition modeling is a critical component in protecting privacy, especially in the medical domain. However, simply removing all personally identifiable information (PII) from end-to-end model training data leads to a significant performance degradation in particular for the recognition of names, dates, locations, and words from similar categories. We propose and evaluate a two-step method for partially recovering this loss. First, PII is identified, and each occurrence is replaced with a random word sequence of the same category. Then, corresponding audio is produced via text-to-speech or by splicing together matching audio fragments extracted from the corpus. These artificial audio/label pairs, together with speaker turns from the original data without PII, are used to train models. We evaluate the performance of this method on in-house data of medical conversations and observe a recovery of almost the entire performance degradation in the general word error rate while still maintaining a strong diarization performance. Our main focus is the improvement of recall and precision in the recognition of PII-related words. Depending on the PII category, between $50\% - 90\%$ of the performance degradation can be recovered using our proposed method.
Learning multi-scale functional representations of proteins from single-cell microscopy data
May 24, 2022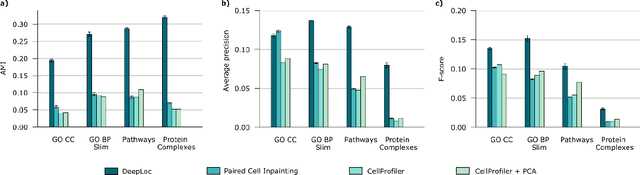
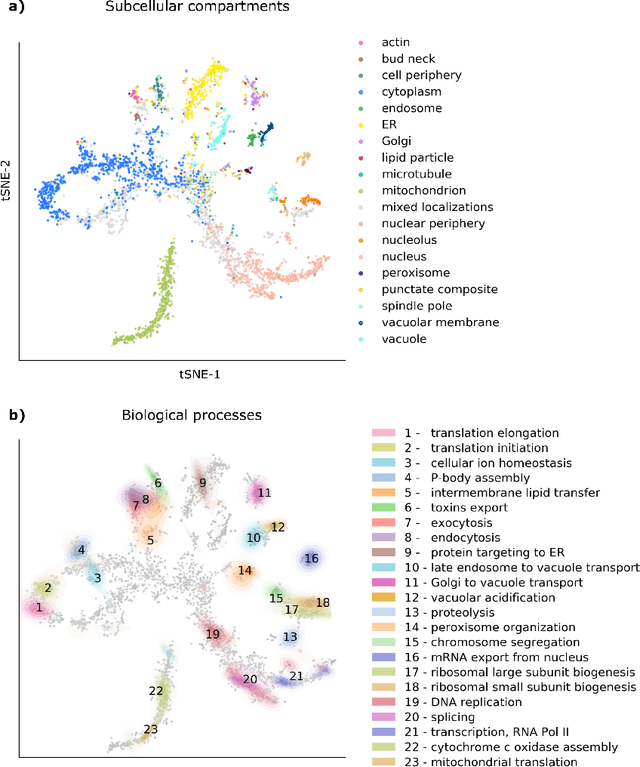
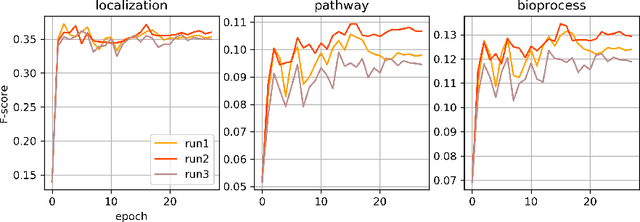
Protein function is inherently linked to its localization within the cell, and fluorescent microscopy data is an indispensable resource for learning representations of proteins. Despite major developments in molecular representation learning, extracting functional information from biological images remains a non-trivial computational task. Current state-of-the-art approaches use autoencoder models to learn high-quality features by reconstructing images. However, such methods are prone to capturing noise and imaging artifacts. In this work, we revisit deep learning models used for classifying major subcellular localizations, and evaluate representations extracted from their final layers. We show that simple convolutional networks trained on localization classification can learn protein representations that encapsulate diverse functional information, and significantly outperform autoencoder-based models. We also propose a robust evaluation strategy to assess quality of protein representations across different scales of biological function.