 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Non-stationarity Characteristics in Dynamic Vehicular ISAC Channels at 28 GHz
Mar 01, 2024
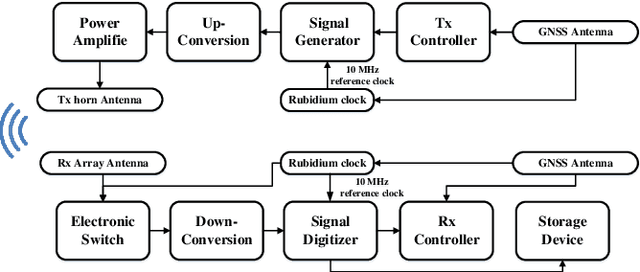

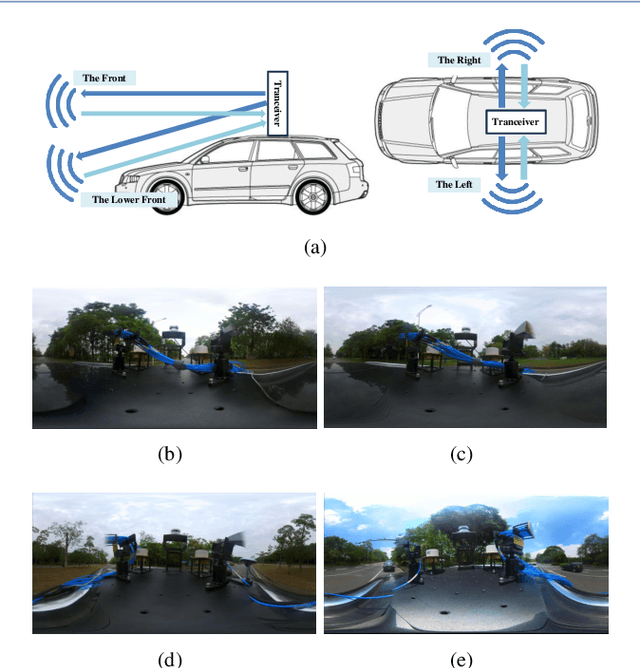
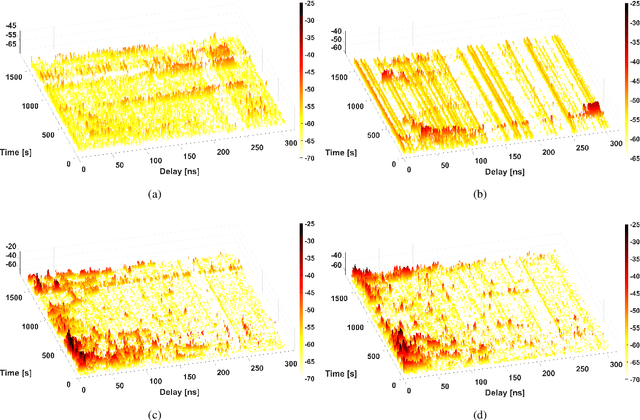
Integrated sensing and communications (ISAC) is a potential technology of 6G, aiming to enable end-to-end information processing ability and native perception capability for future communication systems. As an important part of the ISAC application scenarios, ISAC aided vehicle-to-everything (V2X) can improve the traffic efficiency and safety through intercommunication and synchronous perception. It is necessary to carry out measurement, characterization, and modeling for vehicular ISAC channels as the basic theoretical support for system design. In this paper, dynamic vehicular ISAC channel measurements at 28 GHz are carried out and provide data for the characterization of non-stationarity characteristics. Based on the actual measurements, this paper analyzes the time-varying PDPs, RMSDS and non-stationarity characteristics of front, lower front, left and right perception directions in a complicated V2X scenarios. The research in this paper can enrich the investigation of vehicular ISAC channels and enable the analysis and design of vehicular ISAC systems.
CASIMIR: A Corpus of Scientific Articles enhanced with Multiple Author-Integrated Revisions
Mar 01, 2024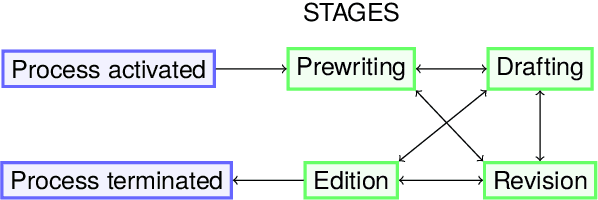
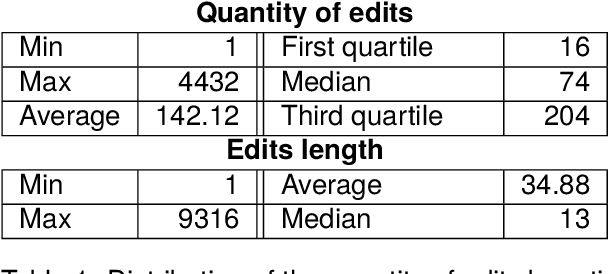


Writing a scientific article is a challenging task as it is a highly codified and specific genre, consequently proficiency in written communication is essential for effectively conveying research findings and ideas. In this article, we propose an original textual resource on the revision step of the writing process of scientific articles. This new dataset, called CASIMIR, contains the multiple revised versions of 15,646 scientific articles from OpenReview, along with their peer reviews. Pairs of consecutive versions of an article are aligned at sentence-level while keeping paragraph location information as metadata for supporting future revision studies at the discourse level. Each pair of revised sentences is enriched with automatically extracted edits and associated revision intention. To assess the initial quality on the dataset, we conducted a qualitative study of several state-of-the-art text revision approaches and compared various evaluation metrics. Our experiments led us to question the relevance of the current evaluation methods for the text revision task.
Bias Mitigation in Fine-tuning Pre-trained Models for Enhanced Fairness and Efficiency
Mar 01, 2024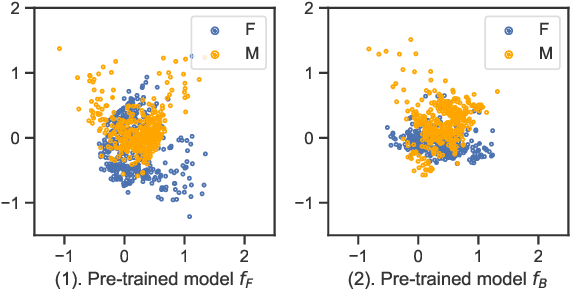
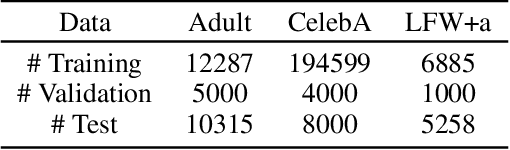
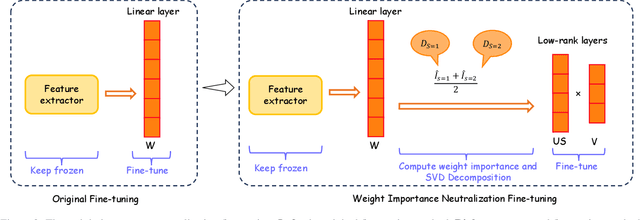
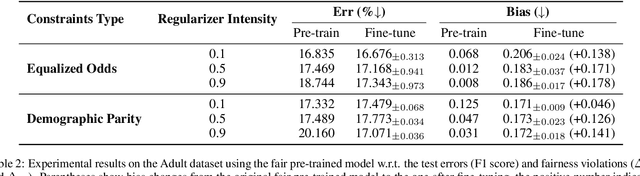
Fine-tuning pre-trained models is a widely employed technique in numerous real-world applications. However, fine-tuning these models on new tasks can lead to unfair outcomes. This is due to the absence of generalization guarantees for fairness properties, regardless of whether the original pre-trained model was developed with fairness considerations. To tackle this issue, we introduce an efficient and robust fine-tuning framework specifically designed to mitigate biases in new tasks. Our empirical analysis shows that the parameters in the pre-trained model that affect predictions for different demographic groups are different, so based on this observation, we employ a transfer learning strategy that neutralizes the importance of these influential weights, determined using Fisher information across demographic groups. Additionally, we integrate this weight importance neutralization strategy with a matrix factorization technique, which provides a low-rank approximation of the weight matrix using fewer parameters, reducing the computational demands. Experiments on multiple pre-trained models and new tasks demonstrate the effectiveness of our method.
Epsilon-Greedy Thompson Sampling to Bayesian Optimization
Mar 01, 2024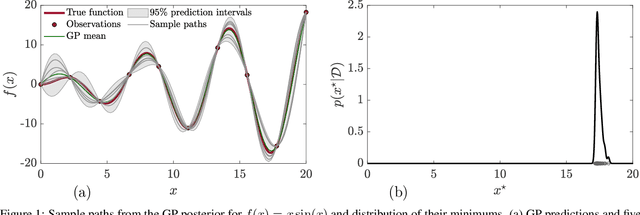
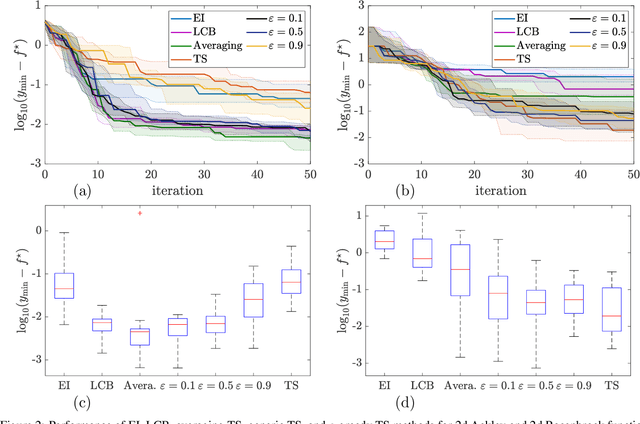
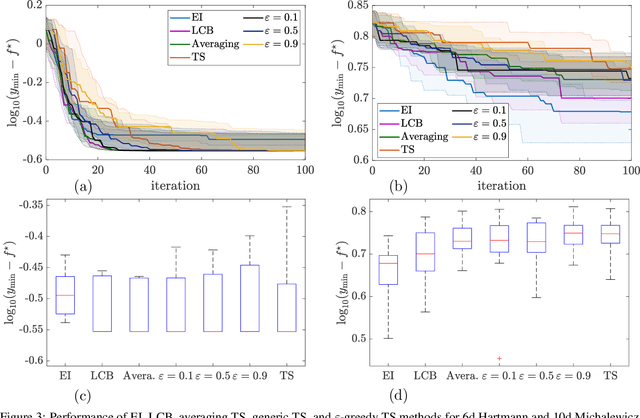
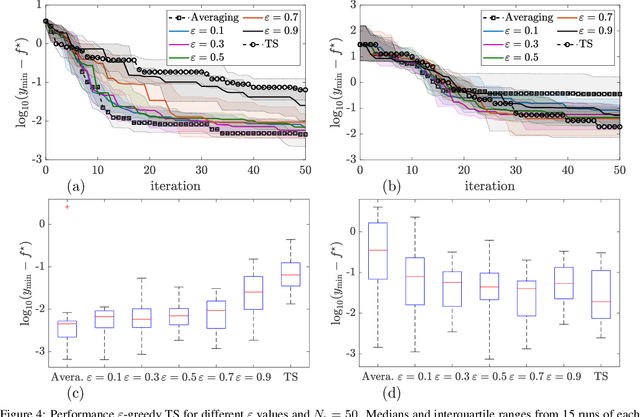
Thompson sampling (TS) serves as a solution for addressing the exploitation-exploration dilemma in Bayesian optimization (BO). While it prioritizes exploration by randomly generating and maximizing sample paths of Gaussian process (GP) posteriors, TS weakly manages its exploitation by gathering information about the true objective function after each exploration is performed. In this study, we incorporate the epsilon-greedy ($\varepsilon$-greedy) policy, a well-established selection strategy in reinforcement learning, into TS to improve its exploitation. We first delineate two extremes of TS applied for BO, namely the generic TS and a sample-average TS. The former and latter promote exploration and exploitation, respectively. We then use $\varepsilon$-greedy policy to randomly switch between the two extremes. A small value of $\varepsilon \in (0,1)$ prioritizes exploitation, and vice versa. We empirically show that $\varepsilon$-greedy TS with an appropriate $\varepsilon$ is better than one of its two extremes and competes with the other.
IDTrust: Deep Identity Document Quality Detection with Bandpass Filtering
Mar 01, 2024
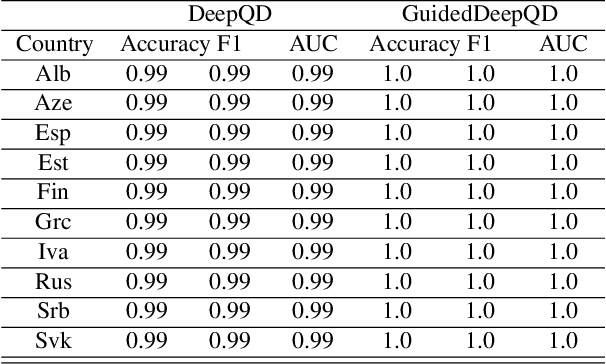
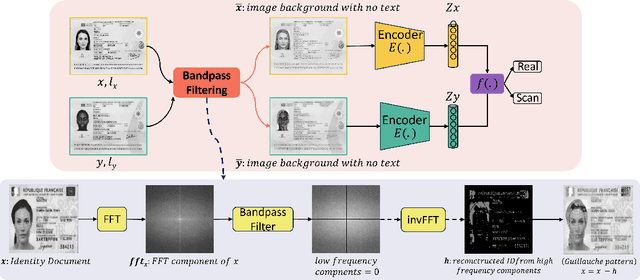
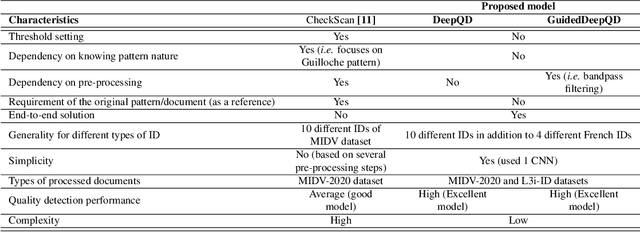
The increasing use of digital technologies and mobile-based registration procedures highlights the vital role of personal identity documents (IDs) in verifying users and safeguarding sensitive information. However, the rise in counterfeit ID production poses a significant challenge, necessitating the development of reliable and efficient automated verification methods. This paper introduces IDTrust, a deep-learning framework for assessing the quality of IDs. IDTrust is a system that enhances the quality of identification documents by using a deep learning-based approach. This method eliminates the need for relying on original document patterns for quality checks and pre-processing steps for alignment. As a result, it offers significant improvements in terms of dataset applicability. By utilizing a bandpass filtering-based method, the system aims to effectively detect and differentiate ID quality. Comprehensive experiments on the MIDV-2020 and L3i-ID datasets identify optimal parameters, significantly improving discrimination performance and effectively distinguishing between original and scanned ID documents.
Improving Acne Image Grading with Label Distribution Smoothing
Mar 01, 2024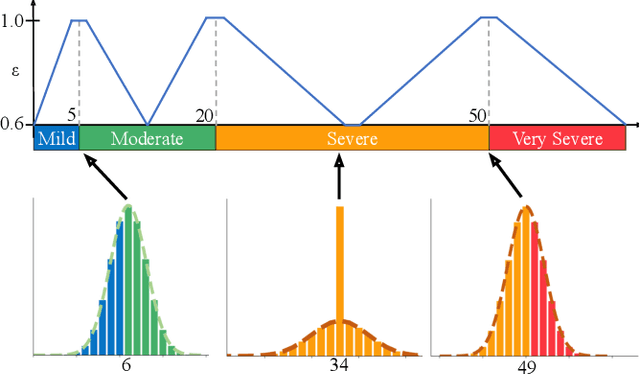
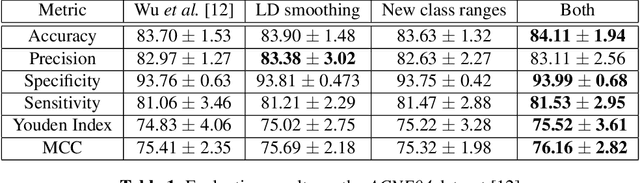
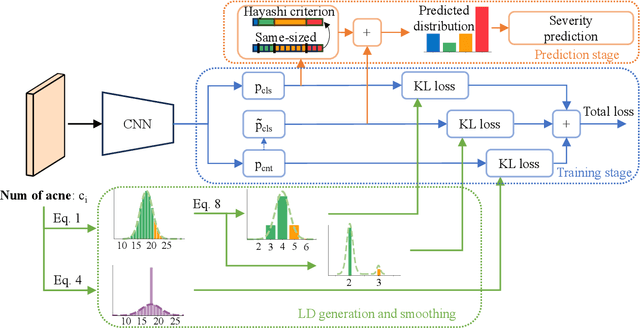

Acne, a prevalent skin condition, necessitates precise severity assessment for effective treatment. Acne severity grading typically involves lesion counting and global assessment. However, manual grading suffers from variability and inefficiency, highlighting the need for automated tools. Recently, label distribution learning (LDL) was proposed as an effective framework for acne image grading, but its effectiveness is hindered by severity scales that assign varying numbers of lesions to different severity grades. Addressing these limitations, we proposed to incorporate severity scale information into lesion counting by combining LDL with label smoothing, and to decouple if from global assessment. A novel weighting scheme in our approach adjusts the degree of label smoothing based on the severity grading scale. This method helped to effectively manage label uncertainty without compromising class distinctiveness. Applied to the benchmark ACNE04 dataset, our model demonstrated improved performance in automated acne grading, showcasing its potential in enhancing acne diagnostics. The source code is publicly available at http://github.com/openface-io/acne-lds.
FlaKat: A Machine Learning-Based Categorization Framework for Flaky Tests
Mar 01, 2024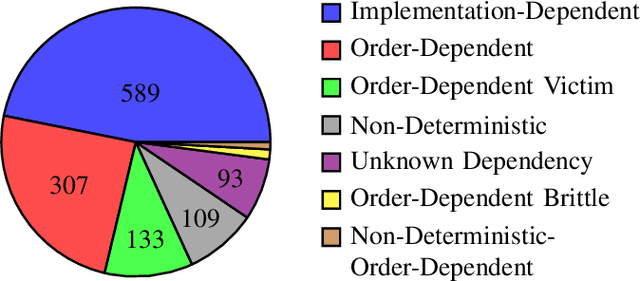

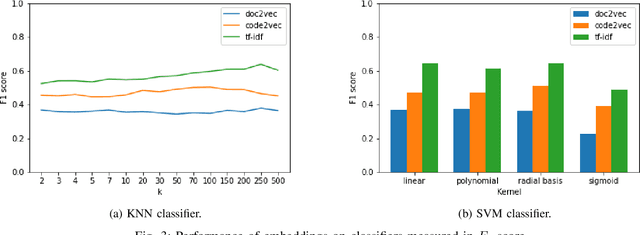
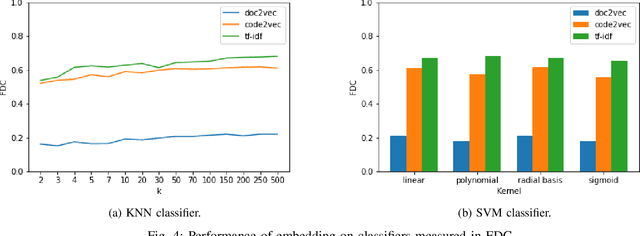
Flaky tests can pass or fail non-deterministically, without alterations to a software system. Such tests are frequently encountered by developers and hinder the credibility of test suites. State-of-the-art research incorporates machine learning solutions into flaky test detection and achieves reasonably good accuracy. Moreover, the majority of automated flaky test repair solutions are designed for specific types of flaky tests. This research work proposes a novel categorization framework, called FlaKat, which uses machine-learning classifiers for fast and accurate prediction of the category of a given flaky test that reflects its root cause. Sampling techniques are applied to address the imbalance between flaky test categories in the International Dataset of Flaky Test (IDoFT). A new evaluation metric, called Flakiness Detection Capacity (FDC), is proposed for measuring the accuracy of classifiers from the perspective of information theory and provides proof for its effectiveness. The final FDC results are also in agreement with F1 score regarding which classifier yields the best flakiness classification.
FAST functional connectivity implicates P300 connectivity in working memory deficits in Alzheimer's disease
Feb 28, 2024Measuring transient functional connectivity is an important challenge in Electroencephalogram (EEG) research. Here, the rich potential for insightful, discriminative information of brain activity offered by high temporal resolution is confounded by the inherent noise of the medium and the spurious nature of correlations computed over short temporal windows. We propose a novel methodology to overcome these problems called Filter Average Short-Term (FAST) functional connectivity. First, long-term, stable, functional connectivity is averaged across an entire study cohort for a given pair of Visual Short Term Memory (VSTM) tasks. The resulting average connectivity matrix, containing information on the strongest general connections for the tasks, is used as a filter to analyse the transient high temporal resolution functional connectivity of individual subjects. In simulations, we show that this method accurately discriminates differences in noisy Event-Related Potentials (ERPs) between two conditions where standard connectivity and other comparable methods fail. We then apply this to analyse activity related to visual short-term memory binding deficits in two cohorts of familial and sporadic Alzheimer's disease. Reproducible significant differences were found in the binding task with no significant difference in the shape task in the P300 ERP range. This allows new sensitive measurements of transient functional connectivity, which can be implemented to obtain results of clinical significance.
Digging Into Normal Incorporated Stereo Matching
Feb 28, 2024Despite the remarkable progress facilitated by learning-based stereo-matching algorithms, disparity estimation in low-texture, occluded, and bordered regions still remains a bottleneck that limits the performance. To tackle these challenges, geometric guidance like plane information is necessary as it provides intuitive guidance about disparity consistency and affinity similarity. In this paper, we propose a normal incorporated joint learning framework consisting of two specific modules named non-local disparity propagation(NDP) and affinity-aware residual learning(ARL). The estimated normal map is first utilized for calculating a non-local affinity matrix and a non-local offset to perform spatial propagation at the disparity level. To enhance geometric consistency, especially in low-texture regions, the estimated normal map is then leveraged to calculate a local affinity matrix, providing the residual learning with information about where the correction should refer and thus improving the residual learning efficiency. Extensive experiments on several public datasets including Scene Flow, KITTI 2015, and Middlebury 2014 validate the effectiveness of our proposed method. By the time we finished this work, our approach ranked 1st for stereo matching across foreground pixels on the KITTI 2015 dataset and 3rd on the Scene Flow dataset among all the published works.
DecisionNCE: Embodied Multimodal Representations via Implicit Preference Learning
Feb 28, 2024Multimodal pretraining has emerged as an effective strategy for the trinity of goals of representation learning in autonomous robots: 1) extracting both local and global task progression information; 2) enforcing temporal consistency of visual representation; 3) capturing trajectory-level language grounding. Most existing methods approach these via separate objectives, which often reach sub-optimal solutions. In this paper, we propose a universal unified objective that can simultaneously extract meaningful task progression information from image sequences and seamlessly align them with language instructions. We discover that via implicit preferences, where a visual trajectory inherently aligns better with its corresponding language instruction than mismatched pairs, the popular Bradley-Terry model can transform into representation learning through proper reward reparameterizations. The resulted framework, DecisionNCE, mirrors an InfoNCE-style objective but is distinctively tailored for decision-making tasks, providing an embodied representation learning framework that elegantly extracts both local and global task progression features, with temporal consistency enforced through implicit time contrastive learning, while ensuring trajectory-level instruction grounding via multimodal joint encoding. Evaluation on both simulated and real robots demonstrates that DecisionNCE effectively facilitates diverse downstream policy learning tasks, offering a versatile solution for unified representation and reward learning. Project Page: https://2toinf.github.io/DecisionNCE/