 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Time3D: End-to-End Joint Monocular 3D Object Detection and Tracking for Autonomous Driving
May 30, 2022
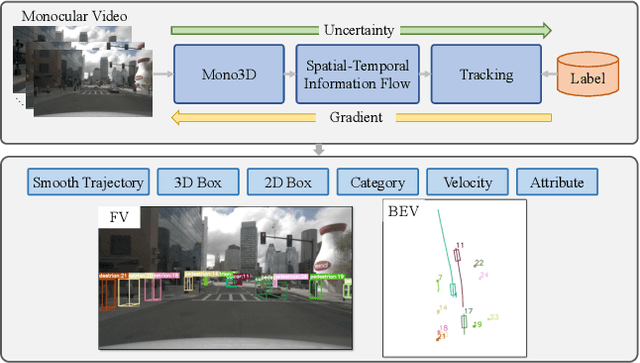
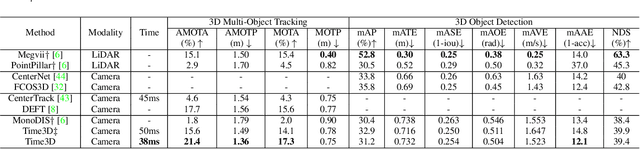
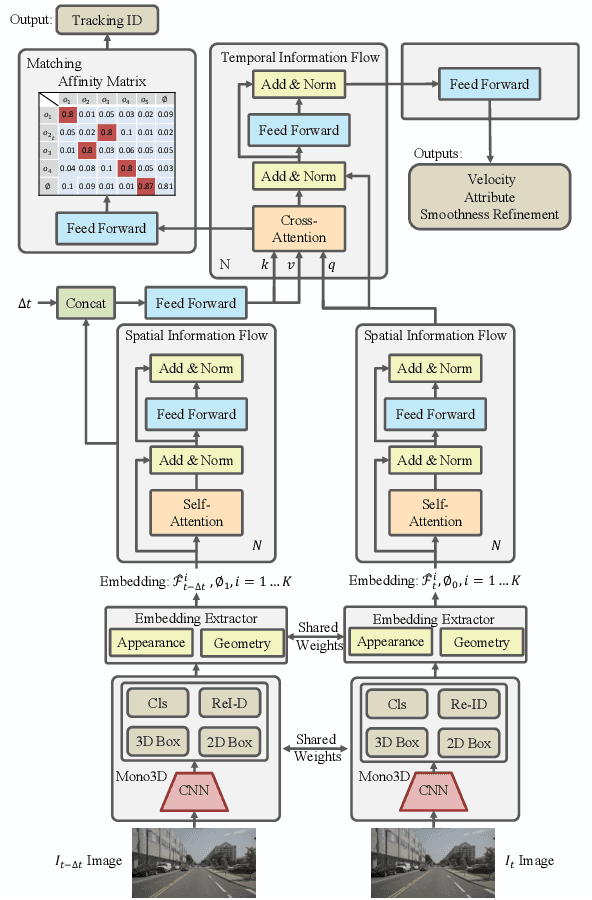
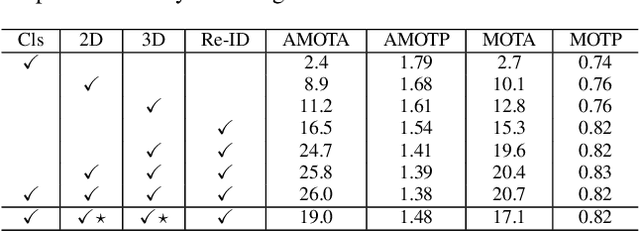
While separately leveraging monocular 3D object detection and 2D multi-object tracking can be straightforwardly applied to sequence images in a frame-by-frame fashion, stand-alone tracker cuts off the transmission of the uncertainty from the 3D detector to tracking while cannot pass tracking error differentials back to the 3D detector. In this work, we propose jointly training 3D detection and 3D tracking from only monocular videos in an end-to-end manner. The key component is a novel spatial-temporal information flow module that aggregates geometric and appearance features to predict robust similarity scores across all objects in current and past frames. Specifically, we leverage the attention mechanism of the transformer, in which self-attention aggregates the spatial information in a specific frame, and cross-attention exploits relation and affinities of all objects in the temporal domain of sequence frames. The affinities are then supervised to estimate the trajectory and guide the flow of information between corresponding 3D objects. In addition, we propose a temporal -consistency loss that explicitly involves 3D target motion modeling into the learning, making the 3D trajectory smooth in the world coordinate system. Time3D achieves 21.4\% AMOTA, 13.6\% AMOTP on the nuScenes 3D tracking benchmark, surpassing all published competitors, and running at 38 FPS, while Time3D achieves 31.2\% mAP, 39.4\% NDS on the nuScenes 3D detection benchmark.
The Neural Race Reduction: Dynamics of Abstraction in Gated Networks
Jul 21, 2022
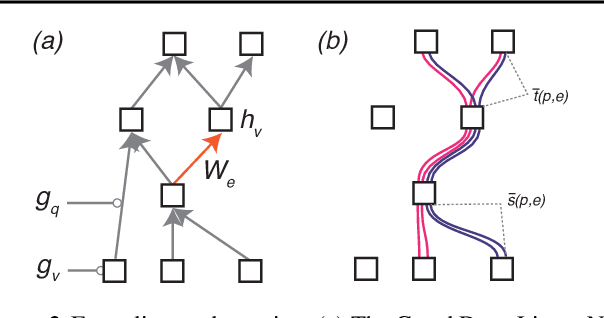
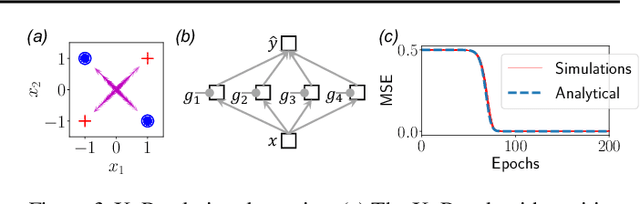
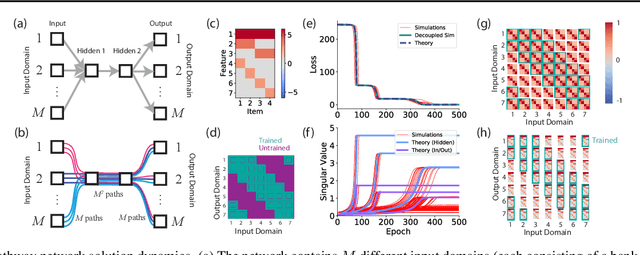
Our theoretical understanding of deep learning has not kept pace with its empirical success. While network architecture is known to be critical, we do not yet understand its effect on learned representations and network behavior, or how this architecture should reflect task structure.In this work, we begin to address this gap by introducing the Gated Deep Linear Network framework that schematizes how pathways of information flow impact learning dynamics within an architecture. Crucially, because of the gating, these networks can compute nonlinear functions of their input. We derive an exact reduction and, for certain cases, exact solutions to the dynamics of learning. Our analysis demonstrates that the learning dynamics in structured networks can be conceptualized as a neural race with an implicit bias towards shared representations, which then govern the model's ability to systematically generalize, multi-task, and transfer. We validate our key insights on naturalistic datasets and with relaxed assumptions. Taken together, our work gives rise to general hypotheses relating neural architecture to learning and provides a mathematical approach towards understanding the design of more complex architectures and the role of modularity and compositionality in solving real-world problems. The code and results are available at https://www.saxelab.org/gated-dln .
AttX: Attentive Cross-Connections for Fusion of Wearable Signals in Emotion Recognition
Jun 09, 2022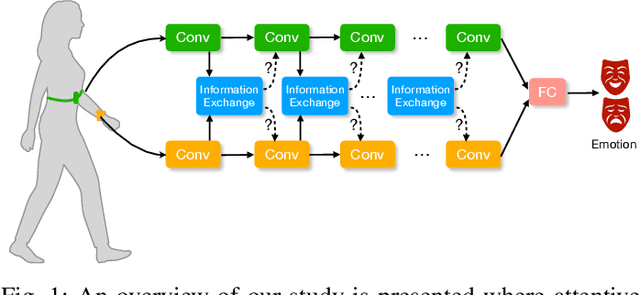
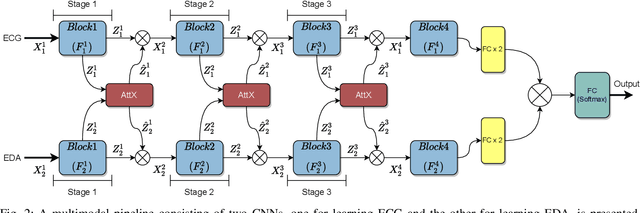
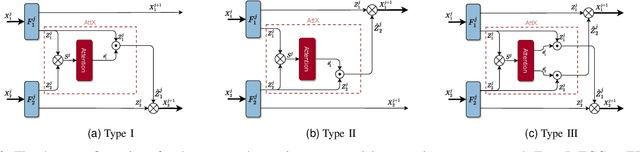
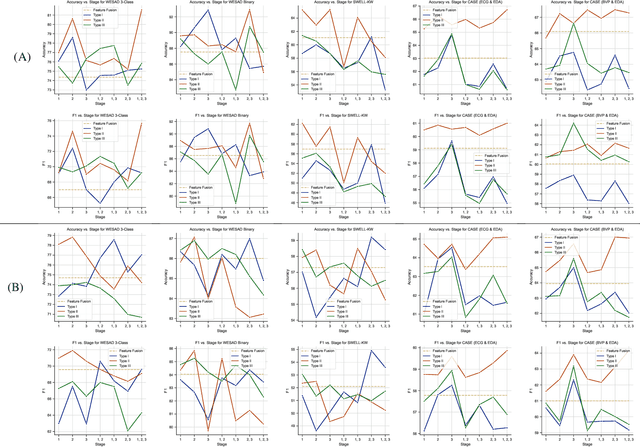
We propose cross-modal attentive connections, a new dynamic and effective technique for multimodal representation learning from wearable data. Our solution can be integrated into any stage of the pipeline, i.e., after any convolutional layer or block, to create intermediate connections between individual streams responsible for processing each modality. Additionally, our method benefits from two properties. First, it can share information uni-directionally (from one modality to the other) or bi-directionally. Second, it can be integrated into multiple stages at the same time to further allow network gradients to be exchanged in several touch-points. We perform extensive experiments on three public multimodal wearable datasets, WESAD, SWELL-KW, and CASE, and demonstrate that our method can effectively regulate and share information between different modalities to learn better representations. Our experiments further demonstrate that once integrated into simple CNN-based multimodal solutions (2, 3, or 4 modalities), our method can result in superior or competitive performance to state-of-the-art and outperform a variety of baseline uni-modal and classical multimodal methods.
Hybrid Skip: A Biologically Inspired Skip Connection for the UNet Architecture
Jul 11, 2022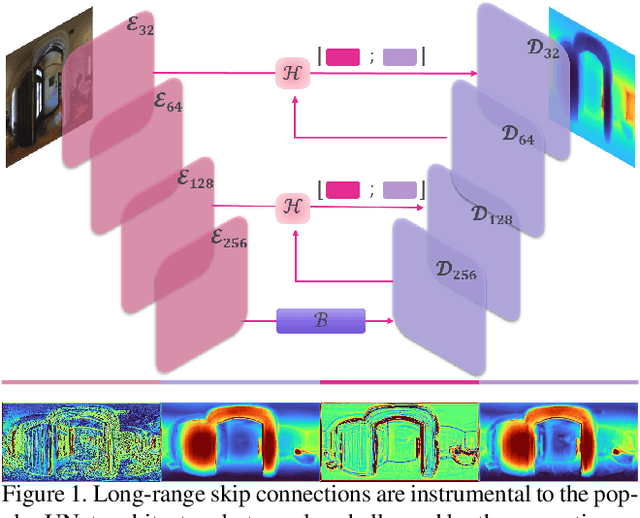

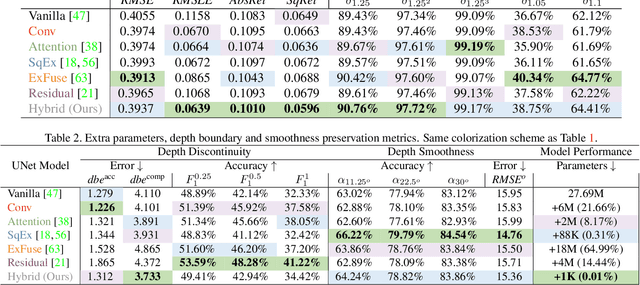
In this work we introduce a biologically inspired long-range skip connection for the UNet architecture that relies on the perceptual illusion of hybrid images, being images that simultaneously encode two images. The fusion of early encoder features with deeper decoder ones allows UNet models to produce finer-grained dense predictions. While proven in segmentation tasks, the network's benefits are down-weighted for dense regression tasks as these long-range skip connections additionally result in texture transfer artifacts. Specifically for depth estimation, this hurts smoothness and introduces false positive edges which are detrimental to the task due to the depth maps' piece-wise smooth nature. The proposed HybridSkip connections show improved performance in balancing the trade-off between edge preservation, and the minimization of texture transfer artifacts that hurt smoothness. This is achieved by the proper and balanced exchange of information that Hybrid-Skip connections offer between the high and low frequency, encoder and decoder features, respectively.
* Project page at https://vcl3d.github.io/HybridSkip/
Knowledge Graph Induction enabling Recommending and Trend Analysis: A Corporate Research Community Use Case
Jul 18, 2022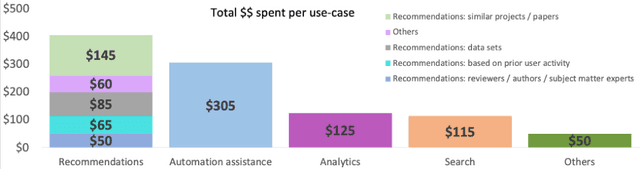

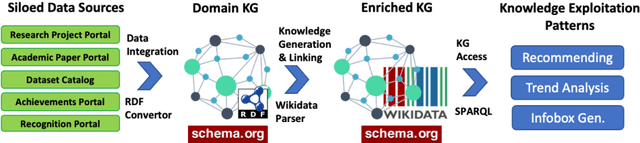
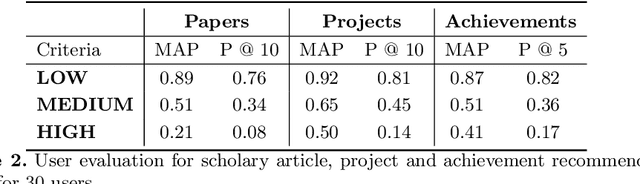
A research division plays an important role of driving innovation in an organization. Drawing insights, following trends, keeping abreast of new research, and formulating strategies are increasingly becoming more challenging for both researchers and executives as the amount of information grows in both velocity and volume. In this paper we present a use case of how a corporate research community, IBM Research, utilizes Semantic Web technologies to induce a unified Knowledge Graph from both structured and textual data obtained by integrating various applications used by the community related to research projects, academic papers, datasets, achievements and recognition. In order to make the Knowledge Graph more accessible to application developers, we identified a set of common patterns for exploiting the induced knowledge and exposed them as APIs. Those patterns were born out of user research which identified the most valuable use cases or user pain points to be alleviated. We outline two distinct scenarios: recommendation and analytics for business use. We will discuss these scenarios in detail and provide an empirical evaluation on entity recommendation specifically. The methodology used and the lessons learned from this work can be applied to other organizations facing similar challenges.
Log Barriers for Safe Black-box Optimization with Application to Safe Reinforcement Learning
Jul 21, 2022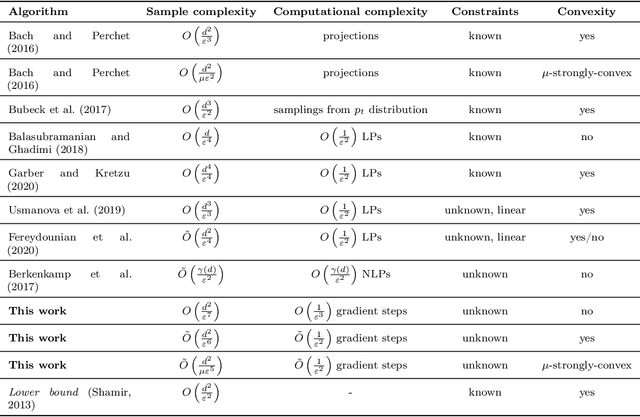
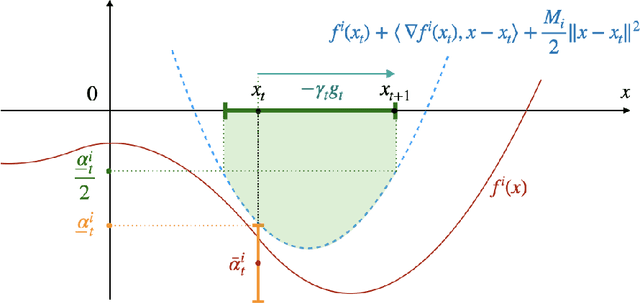
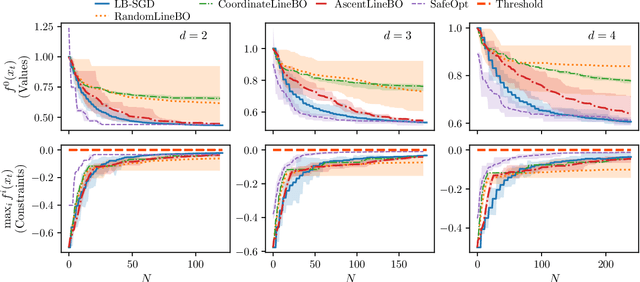
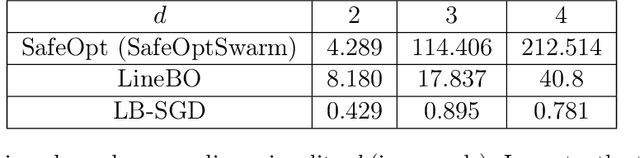
Optimizing noisy functions online, when evaluating the objective requires experiments on a deployed system, is a crucial task arising in manufacturing, robotics and many others. Often, constraints on safe inputs are unknown ahead of time, and we only obtain noisy information, indicating how close we are to violating the constraints. Yet, safety must be guaranteed at all times, not only for the final output of the algorithm. We introduce a general approach for seeking a stationary point in high dimensional non-linear stochastic optimization problems in which maintaining safety during learning is crucial. Our approach called LB-SGD is based on applying stochastic gradient descent (SGD) with a carefully chosen adaptive step size to a logarithmic barrier approximation of the original problem. We provide a complete convergence analysis of non-convex, convex, and strongly-convex smooth constrained problems, with first-order and zeroth-order feedback. Our approach yields efficient updates and scales better with dimensionality compared to existing approaches. We empirically compare the sample complexity and the computational cost of our method with existing safe learning approaches. Beyond synthetic benchmarks, we demonstrate the effectiveness of our approach on minimizing constraint violation in policy search tasks in safe reinforcement learning (RL).
FiLM: Frequency improved Legendre Memory Model for Long-term Time Series Forecasting
May 24, 2022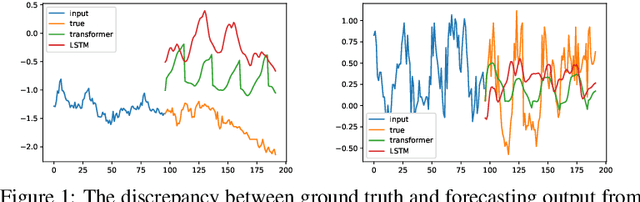
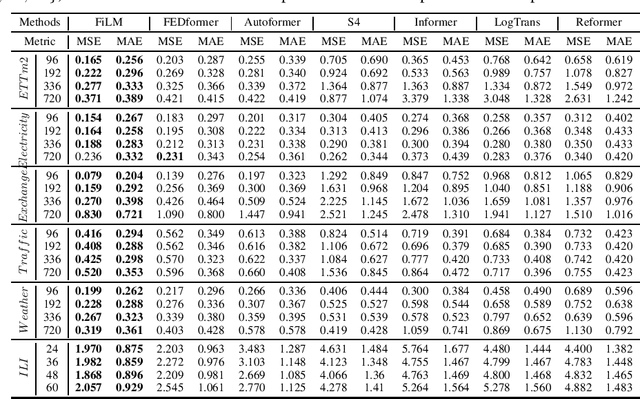
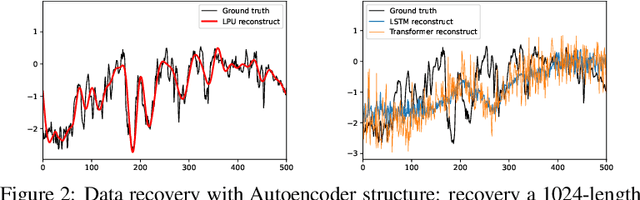
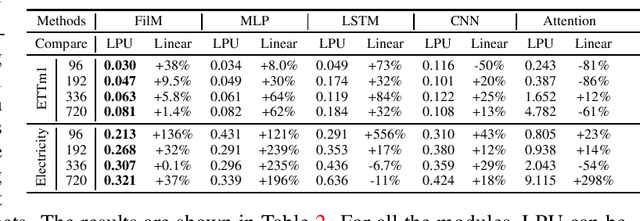
Recent studies have shown that deep learning models such as RNNs and Transformers have brought significant performance gains for long-term forecasting of time series because they effectively utilize historical information. We found, however, that there is still great room for improvement in how to preserve historical information in neural networks while avoiding overfitting to noise presented in the history. Addressing this allows better utilization of the capabilities of deep learning models. To this end, we design a \textbf{F}requency \textbf{i}mproved \textbf{L}egendre \textbf{M}emory model, or {\bf FiLM}: it applies Legendre Polynomials projections to approximate historical information, uses Fourier projection to remove noise, and adds a low-rank approximation to speed up computation. Our empirical studies show that the proposed FiLM significantly improves the accuracy of state-of-the-art models in multivariate and univariate long-term forecasting by (\textbf{20.3\%}, \textbf{22.6\%}), respectively. We also demonstrate that the representation module developed in this work can be used as a general plug-in to improve the long-term prediction performance of other deep learning modules. Code will be released soon.
Towards Unified Conversational Recommender Systems via Knowledge-Enhanced Prompt Learning
Jun 19, 2022
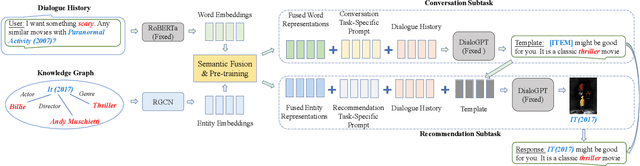
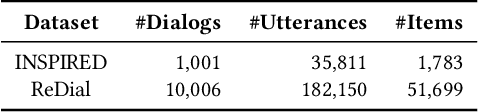
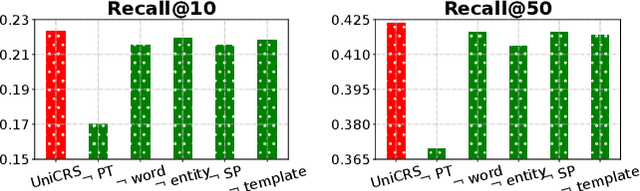
Conversational recommender systems (CRS) aim to proactively elicit user preference and recommend high-quality items through natural language conversations. Typically, a CRS consists of a recommendation module to predict preferred items for users and a conversation module to generate appropriate responses. To develop an effective CRS, it is essential to seamlessly integrate the two modules. Existing works either design semantic alignment strategies, or share knowledge resources and representations between the two modules. However, these approaches still rely on different architectures or techniques to develop the two modules, making it difficult for effective module integration. To address this problem, we propose a unified CRS model named UniCRS based on knowledge-enhanced prompt learning. Our approach unifies the recommendation and conversation subtasks into the prompt learning paradigm, and utilizes knowledge-enhanced prompts based on a fixed pre-trained language model (PLM) to fulfill both subtasks in a unified approach. In the prompt design, we include fused knowledge representations, task-specific soft tokens, and the dialogue context, which can provide sufficient contextual information to adapt the PLM for the CRS task. Besides, for the recommendation subtask, we also incorporate the generated response template as an important part of the prompt, to enhance the information interaction between the two subtasks. Extensive experiments on two public CRS datasets have demonstrated the effectiveness of our approach.
Effectiveness of Transformer Models on IoT Security Detection in StackOverflow Discussions
Jul 29, 2022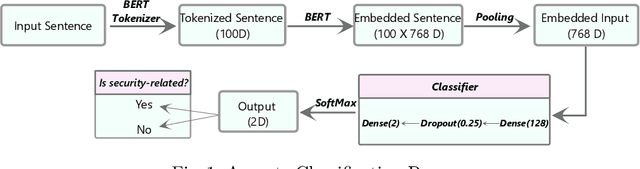
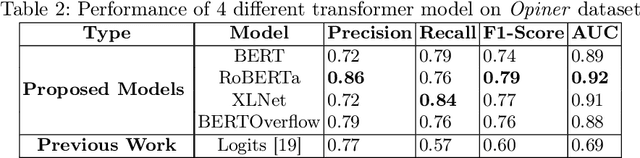
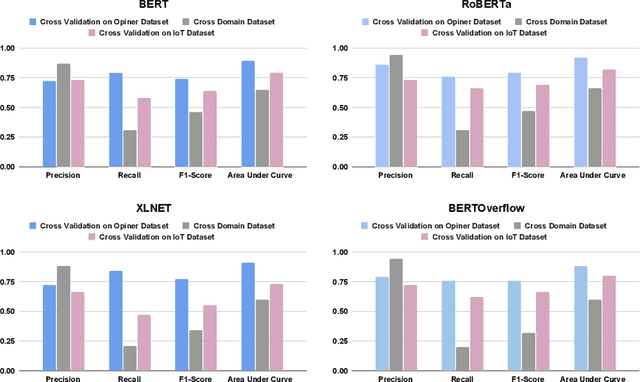
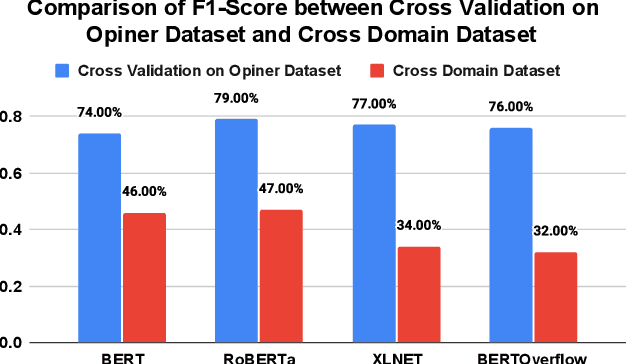
The Internet of Things (IoT) is an emerging concept that directly links to the billions of physical items, or "things", that are connected to the Internet and are all gathering and exchanging information between devices and systems. However, IoT devices were not built with security in mind, which might lead to security vulnerabilities in a multi-device system. Traditionally, we investigated IoT issues by polling IoT developers and specialists. This technique, however, is not scalable since surveying all IoT developers is not feasible. Another way to look into IoT issues is to look at IoT developer discussions on major online development forums like Stack Overflow (SO). However, finding discussions that are relevant to IoT issues is challenging since they are frequently not categorized with IoT-related terms. In this paper, we present the "IoT Security Dataset", a domain-specific dataset of 7147 samples focused solely on IoT security discussions. As there are no automated tools to label these samples, we manually labeled them. We further employed multiple transformer models to automatically detect security discussions. Through rigorous investigations, we found that IoT security discussions are different and more complex than traditional security discussions. We demonstrated a considerable performance loss (up to 44%) of transformer models on cross-domain datasets when we transferred knowledge from a general-purpose dataset "Opiner", supporting our claim. Thus, we built a domain-specific IoT security detector with an F1-Score of 0.69. We have made the dataset public in the hope that developers would learn more about the security discussion and vendors would enhance their concerns about product security.
Unsupervised Contrastive Learning of Image Representations from Ultrasound Videos with Hard Negative Mining
Jul 26, 2022
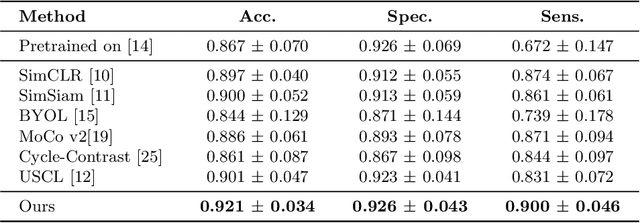
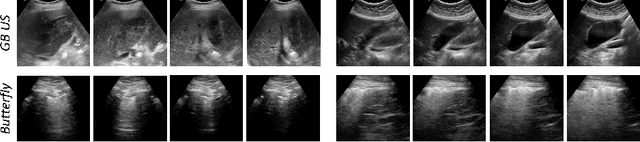
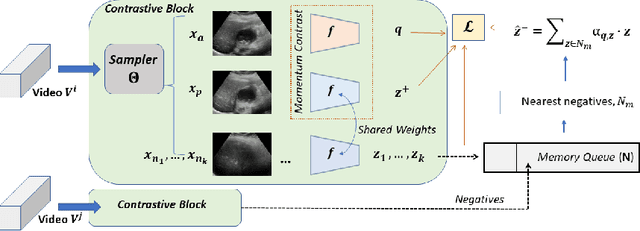
Rich temporal information and variations in viewpoints make video data an attractive choice for learning image representations using unsupervised contrastive learning (UCL) techniques. State-of-the-art (SOTA) contrastive learning techniques consider frames within a video as positives in the embedding space, whereas the frames from other videos are considered negatives. We observe that unlike multiple views of an object in natural scene videos, an Ultrasound (US) video captures different 2D slices of an organ. Hence, there is almost no similarity between the temporally distant frames of even the same US video. In this paper we propose to instead utilize such frames as hard negatives. We advocate mining both intra-video and cross-video negatives in a hardness-sensitive negative mining curriculum in a UCL framework to learn rich image representations. We deploy our framework to learn the representations of Gallbladder (GB) malignancy from US videos. We also construct the first large-scale US video dataset containing 64 videos and 15,800 frames for learning GB representations. We show that the standard ResNet50 backbone trained with our framework improves the accuracy of models pretrained with SOTA UCL techniques as well as supervised pretrained models on ImageNet for the GB malignancy detection task by 2-6%. We further validate the generalizability of our method on a publicly available lung US image dataset of COVID-19 pathologies and show an improvement of 1.5% compared to SOTA. Source code, dataset, and models are available at https://gbc-iitd.github.io/usucl.