 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RESECT-SEG: Open access annotations of intra-operative brain tumor ultrasound images
Jul 13, 2022
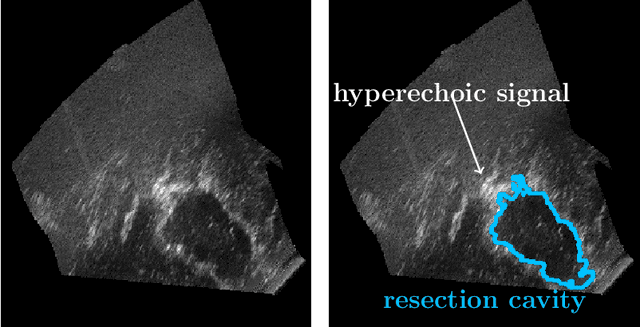
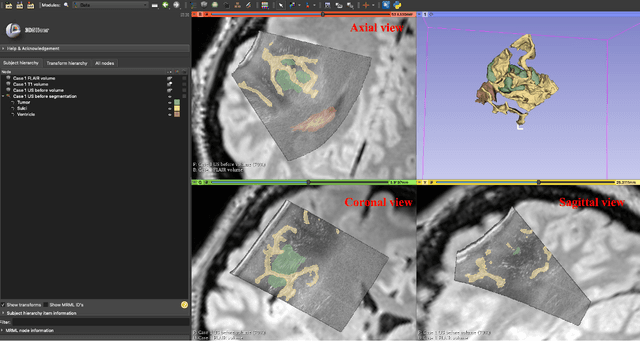
Purpose: Registration and segmentation of magnetic resonance (MR) and ultrasound (US) images play an essential role in surgical planning and resection of brain tumors. However, validating these techniques is challenging due to the scarcity of publicly accessible sources with high-quality ground truth information. To this end, we propose a unique annotation dataset of tumor tissues and resection cavities from the previously published RESECT dataset (Xiao et al. 2017) to encourage a more rigorous assessments of image processing techniques. Acquisition and validation methods: The RESECT database consists of MR and intraoperative US (iUS) images of 23 patients who underwent resection surgeries. The proposed dataset contains tumor tissues and resection cavity annotations of the iUS images. The quality of annotations were validated by two highly experienced neurosurgeons through several assessment criteria. Data format and availability: Annotations of tumor tissues and resection cavities are provided in 3D NIFTI formats. Both sets of annotations are accessible online in the \url{https://osf.io/6y4db}. Discussion and potential applications: The proposed database includes tumor tissue and resection cavity annotations from real-world clinical ultrasound brain images to evaluate segmentation and registration methods. These labels could also be used to train deep learning approaches. Eventually, this dataset should further improve the quality of image guidance in neurosurgery.
Subgraph Matching via Query-Conditioned Subgraph Matching Neural Networks and Bi-Level Tree Search
Jul 21, 2022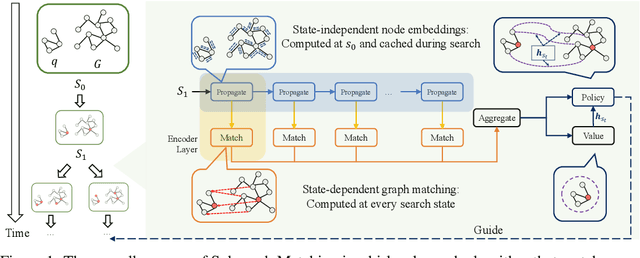
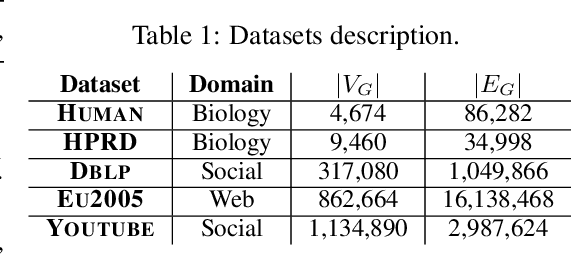
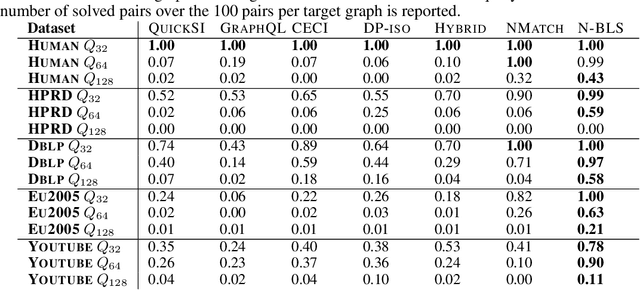
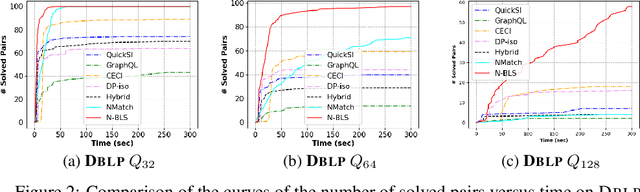
Recent advances have shown the success of using reinforcement learning and search to solve NP-hard graph-related tasks, such as Traveling Salesman Optimization, Graph Edit Distance computation, etc. However, it remains unclear how one can efficiently and accurately detect the occurrences of a small query graph in a large target graph, which is a core operation in graph database search, biomedical analysis, social group finding, etc. This task is called Subgraph Matching which essentially performs subgraph isomorphism check between a query graph and a large target graph. One promising approach to this classical problem is the "learning-to-search" paradigm, where a reinforcement learning (RL) agent is designed with a learned policy to guide a search algorithm to quickly find the solution without any solved instances for supervision. However, for the specific task of Subgraph Matching, though the query graph is usually small given by the user as input, the target graph is often orders-of-magnitude larger. It poses challenges to the neural network design and can lead to solution and reward sparsity. In this paper, we propose N-BLS with two innovations to tackle the challenges: (1) A novel encoder-decoder neural network architecture to dynamically compute the matching information between the query and the target graphs at each search state; (2) A Monte Carlo Tree Search enhanced bi-level search framework for training the policy and value networks. Experiments on five large real-world target graphs show that N-BLS can significantly improve the subgraph matching performance.
CHARM: A Hierarchical Deep Learning Model for Classification of Complex Human Activities Using Motion Sensors
Jul 16, 2022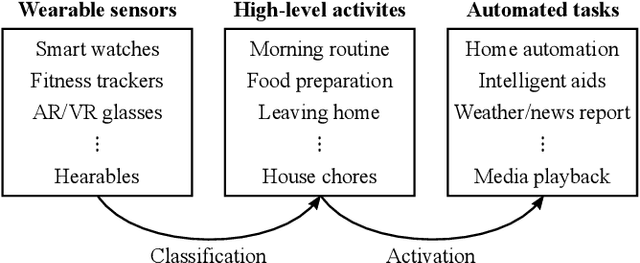
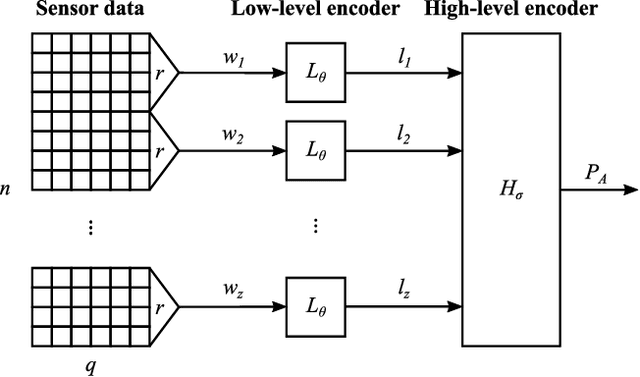
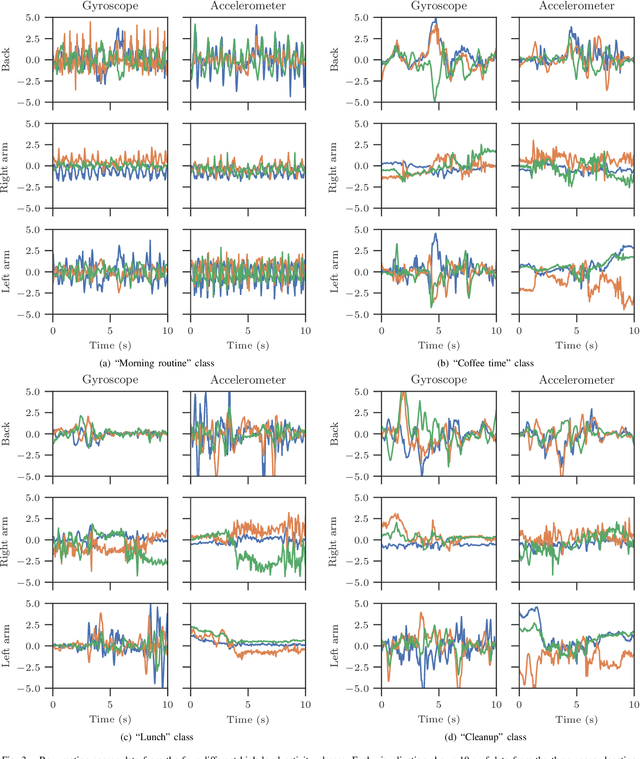
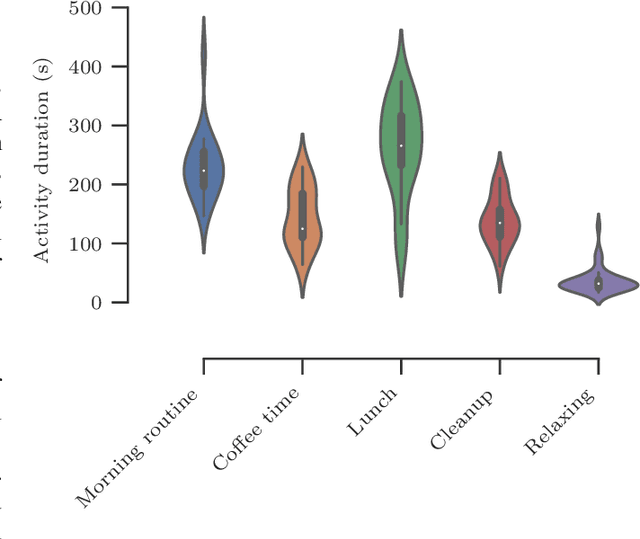
In this paper, we report a hierarchical deep learning model for classification of complex human activities using motion sensors. In contrast to traditional Human Activity Recognition (HAR) models used for event-based activity recognition, such as step counting, fall detection, and gesture identification, this new deep learning model, which we refer to as CHARM (Complex Human Activity Recognition Model), is aimed for recognition of high-level human activities that are composed of multiple different low-level activities in a non-deterministic sequence, such as meal preparation, house chores, and daily routines. CHARM not only quantitatively outperforms state-of-the-art supervised learning approaches for high-level activity recognition in terms of average accuracy and F1 scores, but also automatically learns to recognize low-level activities, such as manipulation gestures and locomotion modes, without any explicit labels for such activities. This opens new avenues for Human-Machine Interaction (HMI) modalities using wearable sensors, where the user can choose to associate an automated task with a high-level activity, such as controlling home automation (e.g., robotic vacuum cleaners, lights, and thermostats) or presenting contextually relevant information at the right time (e.g., reminders, status updates, and weather/news reports). In addition, the ability to learn low-level user activities when trained using only high-level activity labels may pave the way to semi-supervised learning of HAR tasks that are inherently difficult to label.
Temporal Lift Pooling for Continuous Sign Language Recognition
Jul 18, 2022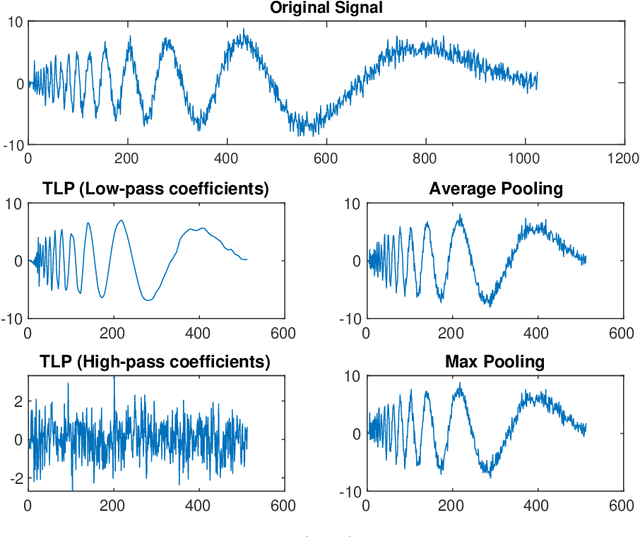
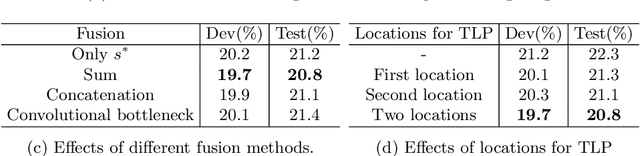

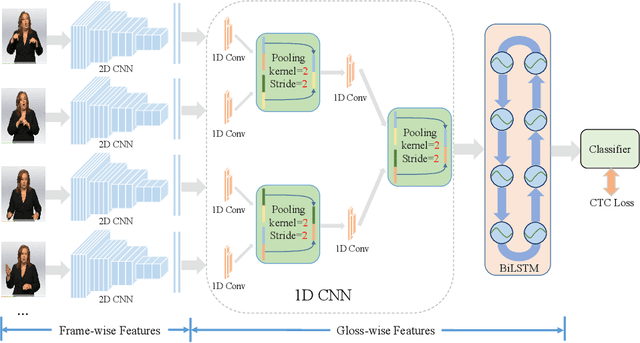
Pooling methods are necessities for modern neural networks for increasing receptive fields and lowering down computational costs. However, commonly used hand-crafted pooling approaches, e.g., max pooling and average pooling, may not well preserve discriminative features. While many researchers have elaborately designed various pooling variants in spatial domain to handle these limitations with much progress, the temporal aspect is rarely visited where directly applying hand-crafted methods or these specialized spatial variants may not be optimal. In this paper, we derive temporal lift pooling (TLP) from the Lifting Scheme in signal processing to intelligently downsample features of different temporal hierarchies. The Lifting Scheme factorizes input signals into various sub-bands with different frequency, which can be viewed as different temporal movement patterns. Our TLP is a three-stage procedure, which performs signal decomposition, component weighting and information fusion to generate a refined downsized feature map. We select a typical temporal task with long sequences, i.e. continuous sign language recognition (CSLR), as our testbed to verify the effectiveness of TLP. Experiments on two large-scale datasets show TLP outperforms hand-crafted methods and specialized spatial variants by a large margin (1.5%) with similar computational overhead. As a robust feature extractor, TLP exhibits great generalizability upon multiple backbones on various datasets and achieves new state-of-the-art results on two large-scale CSLR datasets. Visualizations further demonstrate the mechanism of TLP in correcting gloss borders. Code is released.
STVGFormer: Spatio-Temporal Video Grounding with Static-Dynamic Cross-Modal Understanding
Jul 06, 2022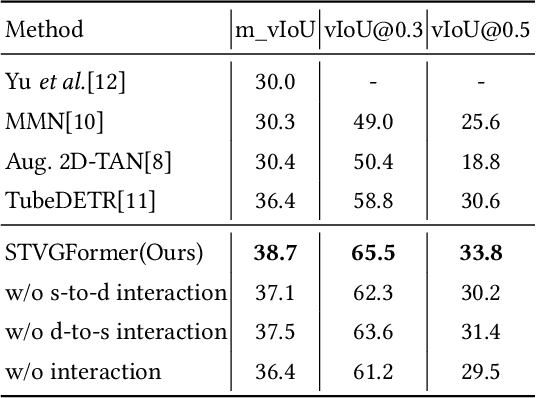
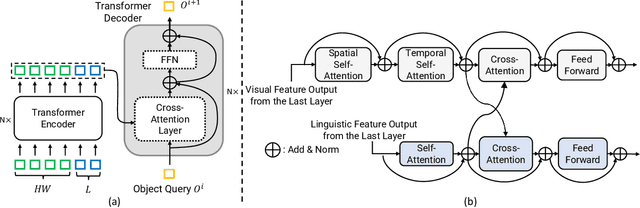
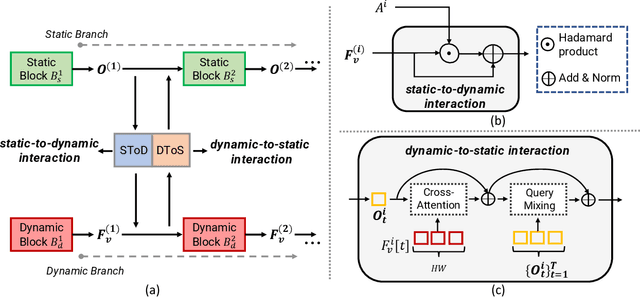
In this technical report, we introduce our solution to human-centric spatio-temporal video grounding task. We propose a concise and effective framework named STVGFormer, which models spatiotemporal visual-linguistic dependencies with a static branch and a dynamic branch. The static branch performs cross-modal understanding in a single frame and learns to localize the target object spatially according to intra-frame visual cues like object appearances. The dynamic branch performs cross-modal understanding across multiple frames. It learns to predict the starting and ending time of the target moment according to dynamic visual cues like motions. Both the static and dynamic branches are designed as cross-modal transformers. We further design a novel static-dynamic interaction block to enable the static and dynamic branches to transfer useful and complementary information from each other, which is shown to be effective to improve the prediction on hard cases. Our proposed method achieved 39.6% vIoU and won the first place in the HC-STVG track of the 4th Person in Context Challenge.
Upper Limb Movement Recognition utilising EEG and EMG Signals for Rehabilitative Robotics
Jul 18, 2022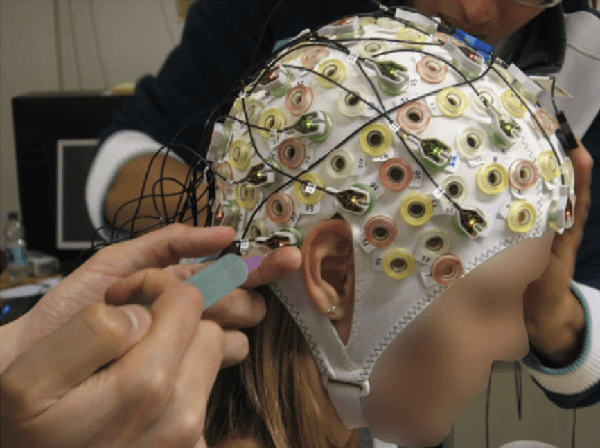
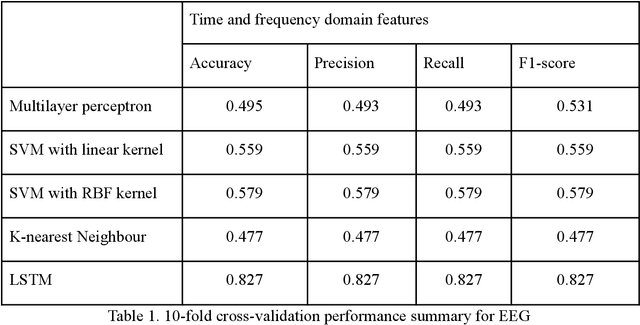
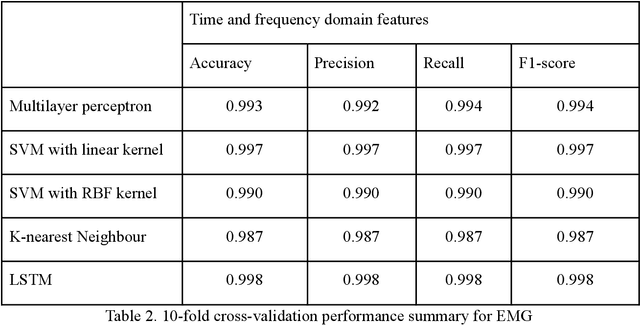
Upper limb movement classification, which maps input signals to the target activities, is one of the crucial areas in the control of rehabilitative robotics. Classifiers are trained for the rehabilitative system to comprehend the desires of the patient whose upper limbs do not function properly. Electromyography (EMG) signals and Electroencephalography (EEG) signals are used widely for upper limb movement classification. By analysing the classification results of the real-time EEG and EMG signals, the system can understand the intention of the user and predict the events that one would like to carry out. Accordingly, it will provide external help to the user to assist one to perform the activities. However, not all users process effective EEG and EMG signals due to the noisy environment. The noise in the real-time data collection process contaminates the effectiveness of the data. Moreover, not all patients process strong EMG signals due to muscle damage and neuromuscular disorder. To address these issues, we would like to propose a novel decision-level multisensor fusion technique. In short, the system will integrate EEG signals with EMG signals, retrieve effective information from both sources to understand and predict the desire of the user, and thus provide assistance. By testing out the proposed technique on a publicly available WAY-EEG-GAL dataset, which contains EEG and EMG signals that were recorded simultaneously, we manage to conclude the feasibility and effectiveness of the novel system.
Downlink Power Minimization in Intelligent Reconfigurable Surface-Aided Security Classification Wireless Communications System
Jun 11, 2022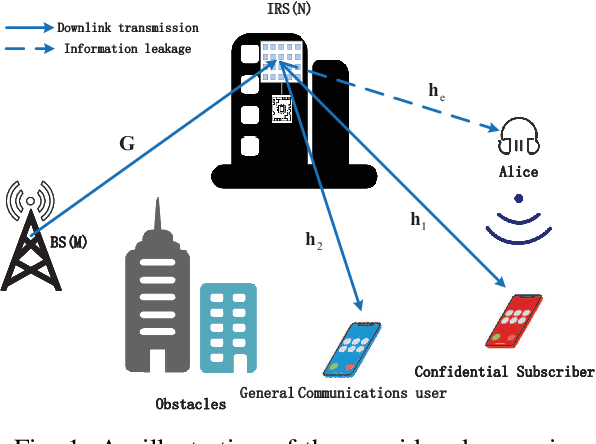
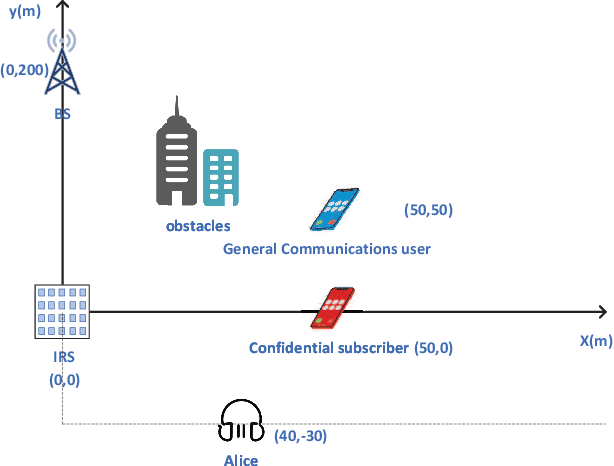
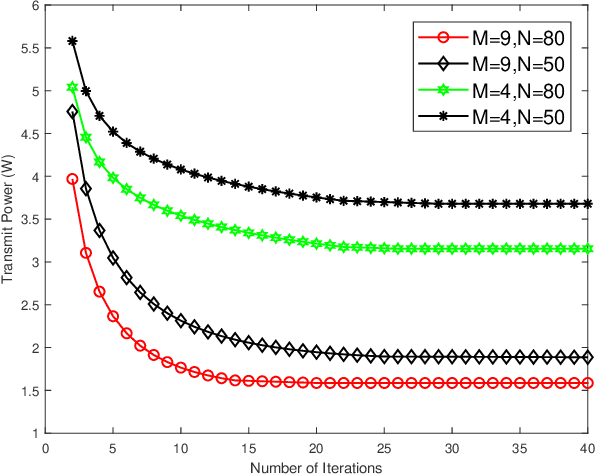
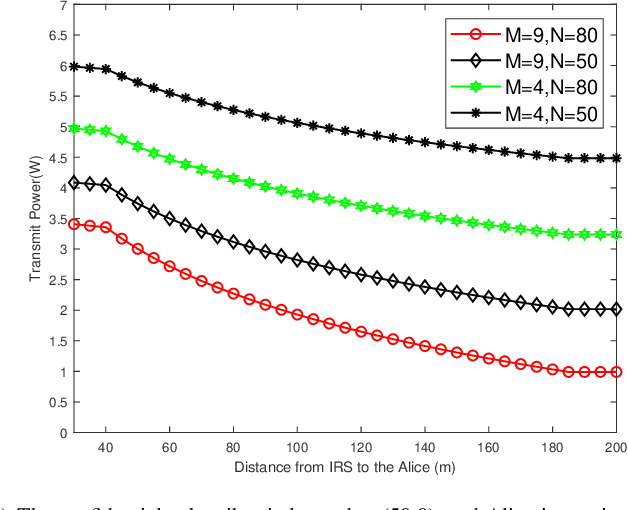
User privacy protection is considered a critical issue in wireless networks, which drives the demand for various secure information interaction techniques. In this paper, we introduce an intelligent reflecting surface (IRS)-aided security classification wireless communication system, which reduces the transmit power of the base station (BS) by classifying users with different security requirements. Specifically, we divide the users into confidential subscribers with secure communication requirements and general communication users with simple communication requirements. During the communication period, we guarantee the secure rate of the confidential subscribers while ensuring the service quality of the general communication users, thereby reducing the transmit power of the BS. To realize such a secure and green information transmission, the BS implements a beamforming design on the transmitted signal superimposed with artificial noise (AN) and then broadcasts it to users with the assistance of the IRS's reflection. We develop an alternating optimization framework to minimize the BS downlink power with respect to the active beamformers of the BS, the AN vector at the BS, and the reflection phase shifts of the IRS. A successive convex approximation (SCA) method is proposed so that the nonconvex beamforming problems can be converted to tractable convex forms. The simulation results demonstrate that the proposed algorithm is convergent and can reduce the transmit power by 20\% compared to the best benchmark scheme.
CellCentroidFormer: Combining Self-attention and Convolution for Cell Detection
Jun 01, 2022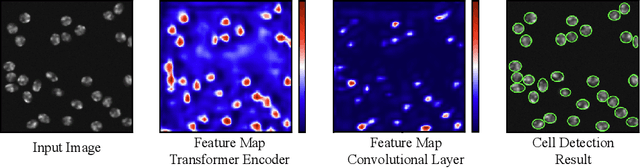
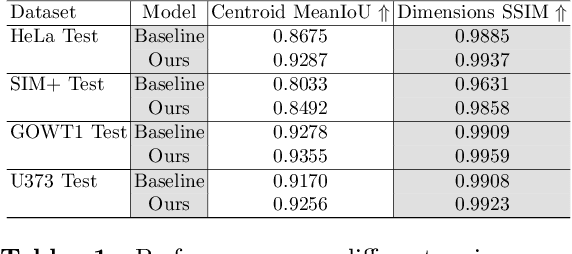
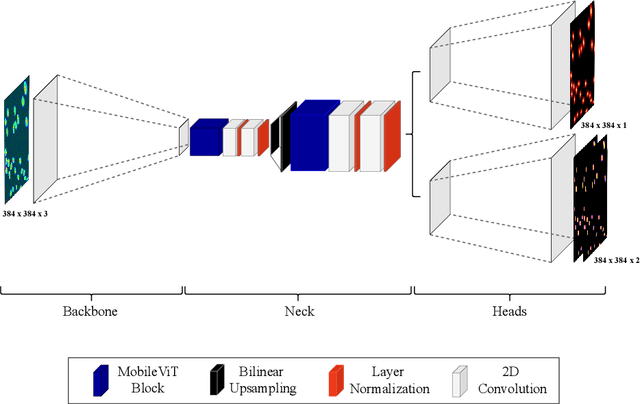

Cell detection in microscopy images is important to study how cells move and interact with their environment. Most recent deep learning-based methods for cell detection use convolutional neural networks (CNNs). However, inspired by the success in other computer vision applications, vision transformers (ViTs) are also used for this purpose. We propose a novel hybrid CNN-ViT model for cell detection in microscopy images to exploit the advantages of both types of deep learning models. We employ an efficient CNN, that was pre-trained on the ImageNet dataset, to extract image features and utilize transfer learning to reduce the amount of required training data. Extracted image features are further processed by a combination of convolutional and transformer layers, so that the convolutional layers can focus on local information and the transformer layers on global information. Our centroid-based cell detection method represents cells as ellipses and is end-to-end trainable. Furthermore, we show that our proposed model can outperform a fully convolutional baseline model on four different 2D microscopy datasets. Code is available at: https://github.com/roydenwa/cell-centroid-former
Real-Time Gesture Recognition with Virtual Glove Markers
Jul 06, 2022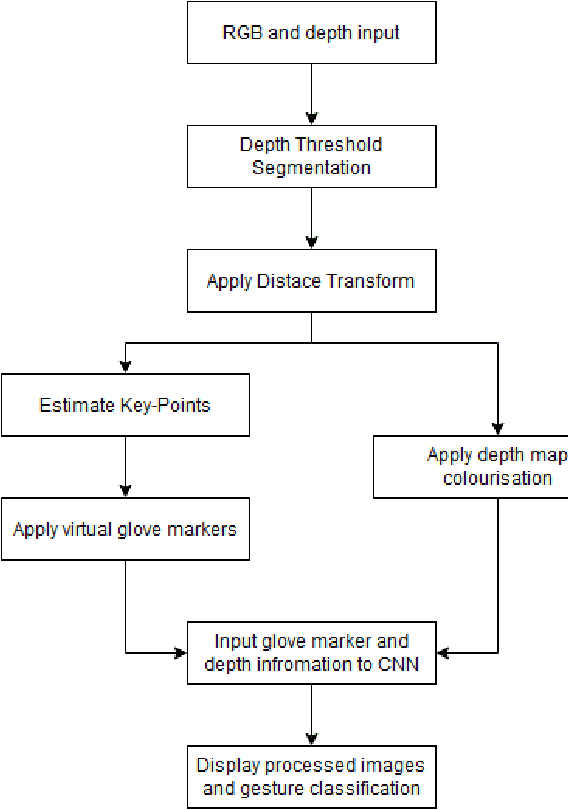



Due to the universal non-verbal natural communication approach that allows for effective communication between humans, gesture recognition technology has been steadily developing over the previous few decades. Many different strategies have been presented in research articles based on gesture recognition to try to create an effective system to send non-verbal natural communication information to computers, using both physical sensors and computer vision. Hyper accurate real-time systems, on the other hand, have only recently began to occupy the study field, with each adopting a range of methodologies due to past limits such as usability, cost, speed, and accuracy. A real-time computer vision-based human-computer interaction tool for gesture recognition applications that acts as a natural user interface is proposed. Virtual glove markers on users hands will be created and used as input to a deep learning model for the real-time recognition of gestures. The results obtained show that the proposed system would be effective in real-time applications including social interaction through telepresence and rehabilitation.
Farewell to Mutual Information: Variational Distillation for Cross-Modal Person Re-Identification
Apr 07, 2021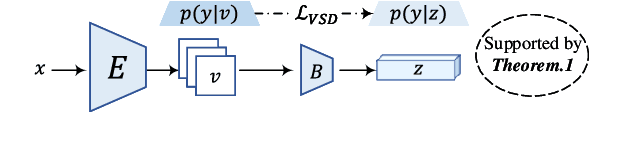
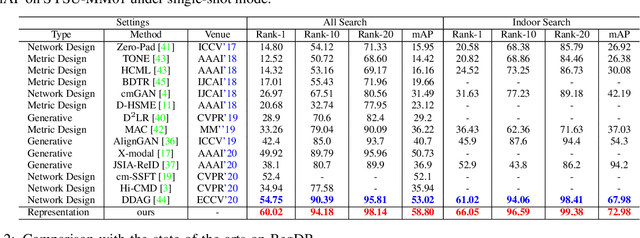
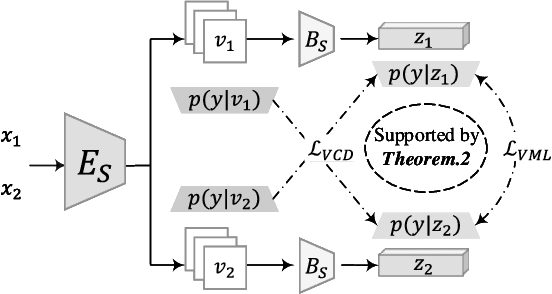
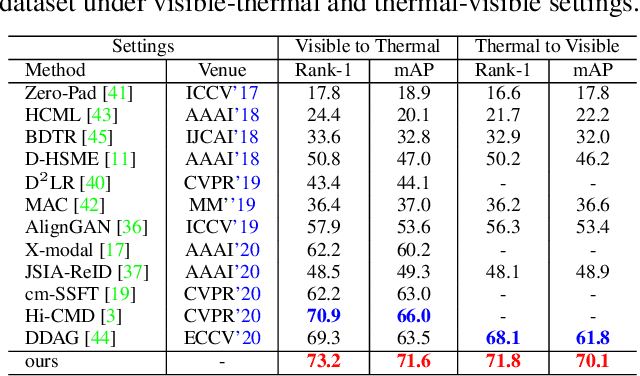
The Information Bottleneck (IB) provides an information theoretic principle for representation learning, by retaining all information relevant for predicting label while minimizing the redundancy. Though IB principle has been applied to a wide range of applications, its optimization remains a challenging problem which heavily relies on the accurate estimation of mutual information. In this paper, we present a new strategy, Variational Self-Distillation (VSD), which provides a scalable, flexible and analytic solution to essentially fitting the mutual information but without explicitly estimating it. Under rigorously theoretical guarantee, VSD enables the IB to grasp the intrinsic correlation between representation and label for supervised training. Furthermore, by extending VSD to multi-view learning, we introduce two other strategies, Variational Cross-Distillation (VCD) and Variational Mutual-Learning (VML), which significantly improve the robustness of representation to view-changes by eliminating view-specific and task-irrelevant information. To verify our theoretically grounded strategies, we apply our approaches to cross-modal person Re-ID, and conduct extensive experiments, where the superior performance against state-of-the-art methods are demonstrated. Our intriguing findings highlight the need to rethink the way to estimate mutual