 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Convolutional Attention Based Deep Network Solution for UAV Network Attack Recognition over Fading Channels and Interference
Jul 16, 2022
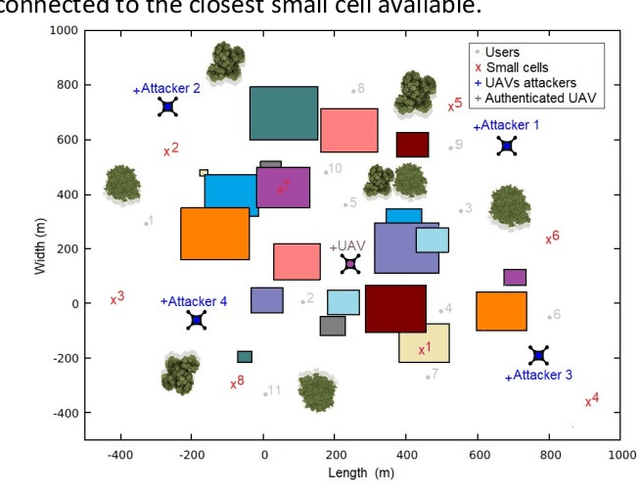
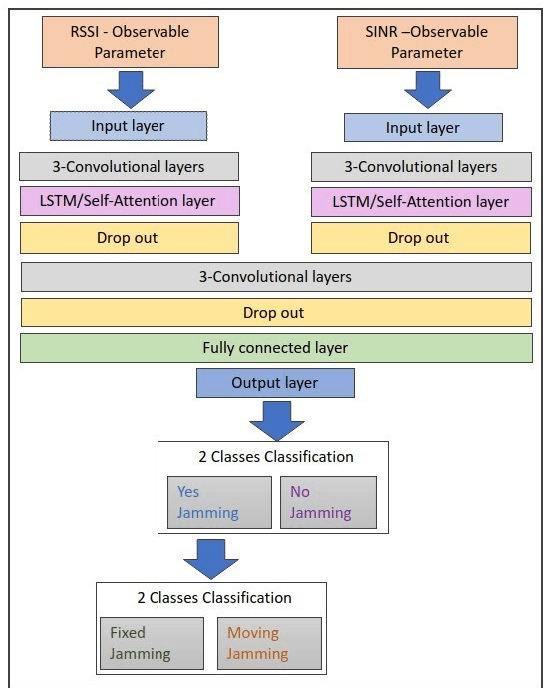

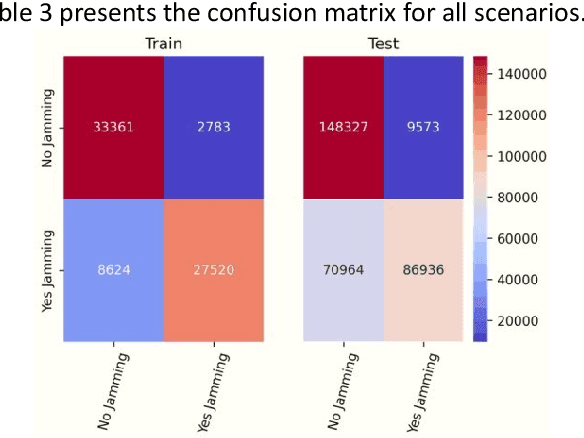
When users exchange data with Unmanned Aerial vehicles - (UAVs) over air-to-ground (A2G) wireless communication networks, they expose the link to attacks that could increase packet loss and might disrupt connectivity. For example, in emergency deliveries, losing control information (i.e data related to the UAV control communication) might result in accidents that cause UAV destruction and damage to buildings or other elements in a city. To prevent these problems, these issues must be addressed in 5G and 6G scenarios. This research offers a deep learning (DL) approach for detecting attacks in UAVs equipped with orthogonal frequency division multiplexing (OFDM) receivers on Clustered Delay Line (CDL) channels in highly complex scenarios involving authenticated terrestrial users, as well as attackers in unknown locations. We use the two observable parameters available in 5G UAV connections: the Received Signal Strength Indicator (RSSI) and the Signal to Interference plus Noise Ratio (SINR). The prospective algorithm is generalizable regarding attack identification, which does not occur during training. Further, it can identify all the attackers in the environment with 20 terrestrial users. A deeper investigation into the timing requirements for recognizing attacks show that after training, the minimum time necessary after the attack begins is 100 ms, and the minimum attack power is 2 dBm, which is the same power that the authenticated UAV uses. Our algorithm also detects moving attackers from a distance of 500 m.
Semi-supervised Time Domain Target Speaker Extraction with Attention
Jun 18, 2022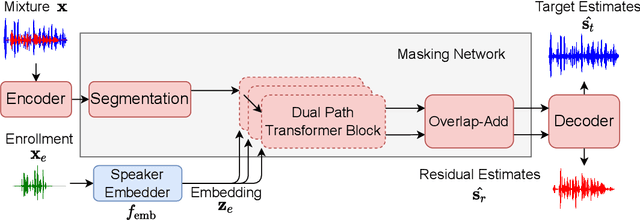

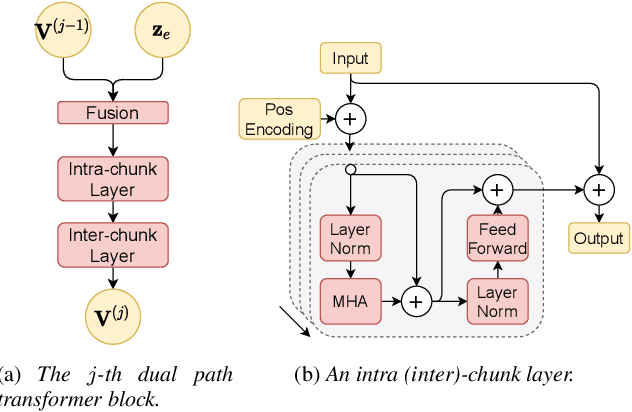
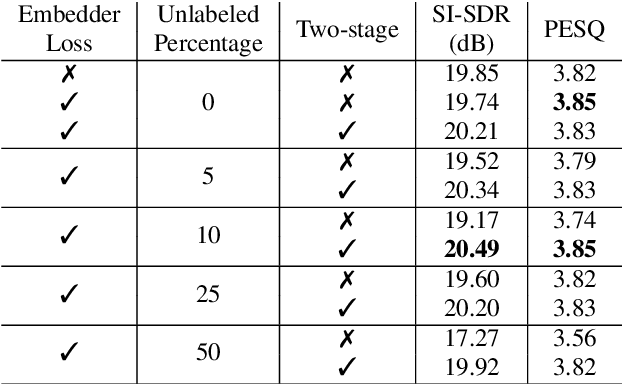
In this work, we propose Exformer, a time-domain architecture for target speaker extraction. It consists of a pre-trained speaker embedder network and a separator network based on transformer encoder blocks. We study multiple methods to combine speaker information with the input mixture, and the resulting Exformer architecture obtains superior extraction performance compared to prior time-domain networks. Furthermore, we investigate a two-stage procedure to train the model using mixtures without reference signals upon a pre-trained supervised model. Experimental results show that the proposed semi-supervised learning procedure improves the performance of the supervised baselines.
Adversarial Consistency for Single Domain Generalization in Medical Image Segmentation
Jun 29, 2022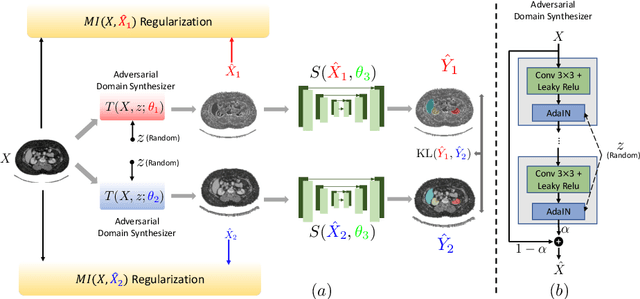
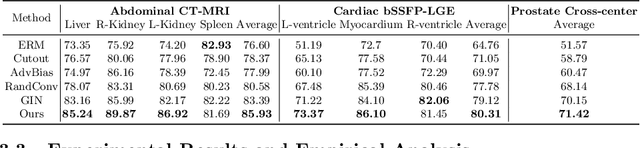
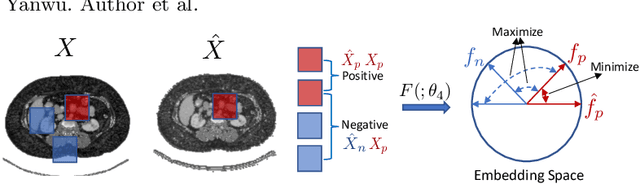
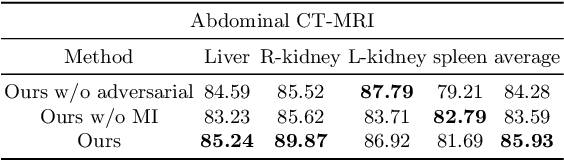
An organ segmentation method that can generalize to unseen contrasts and scanner settings can significantly reduce the need for retraining of deep learning models. Domain Generalization (DG) aims to achieve this goal. However, most DG methods for segmentation require training data from multiple domains during training. We propose a novel adversarial domain generalization method for organ segmentation trained on data from a \emph{single} domain. We synthesize the new domains via learning an adversarial domain synthesizer (ADS) and presume that the synthetic domains cover a large enough area of plausible distributions so that unseen domains can be interpolated from synthetic domains. We propose a mutual information regularizer to enforce the semantic consistency between images from the synthetic domains, which can be estimated by patch-level contrastive learning. We evaluate our method for various organ segmentation for unseen modalities, scanning protocols, and scanner sites.
Efficient Multi-Task RGB-D Scene Analysis for Indoor Environments
Jul 10, 2022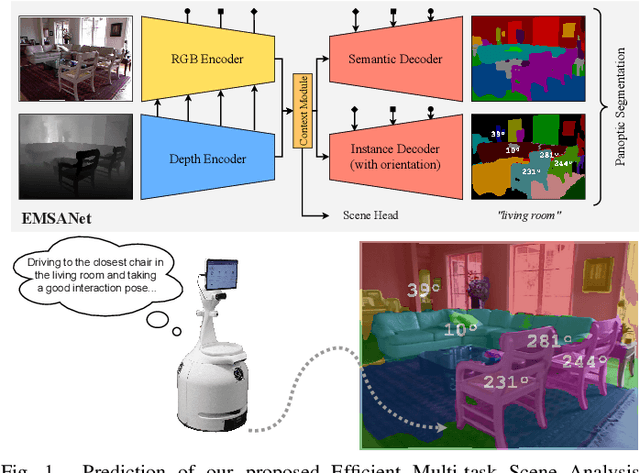
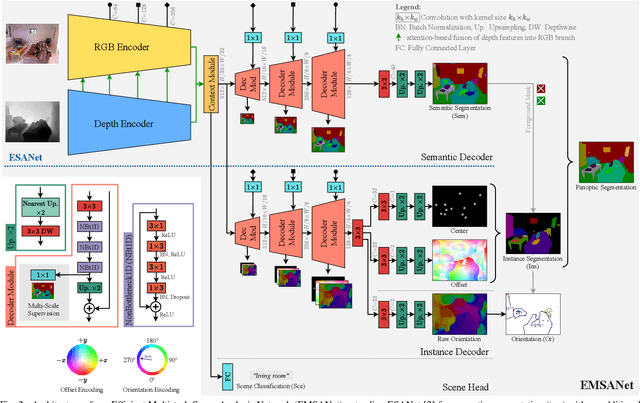
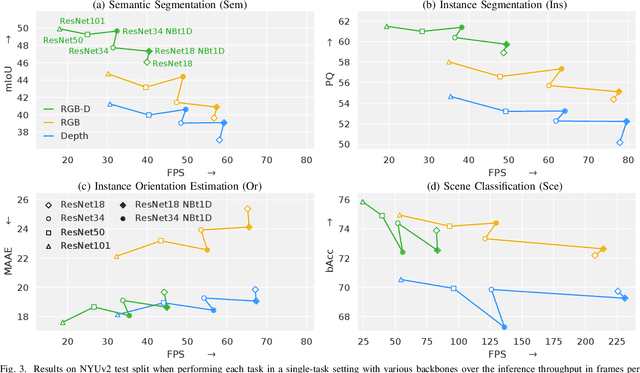
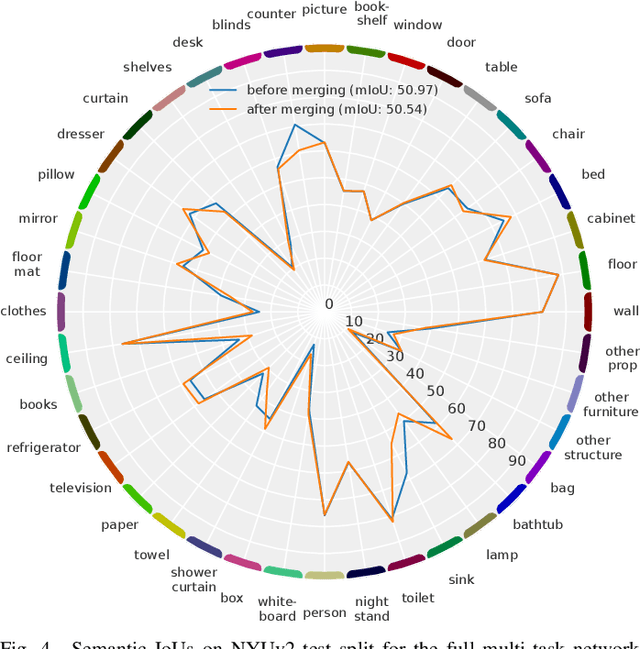
Semantic scene understanding is essential for mobile agents acting in various environments. Although semantic segmentation already provides a lot of information, details about individual objects as well as the general scene are missing but required for many real-world applications. However, solving multiple tasks separately is expensive and cannot be accomplished in real time given limited computing and battery capabilities on a mobile platform. In this paper, we propose an efficient multi-task approach for RGB-D scene analysis~(EMSANet) that simultaneously performs semantic and instance segmentation~(panoptic segmentation), instance orientation estimation, and scene classification. We show that all tasks can be accomplished using a single neural network in real time on a mobile platform without diminishing performance - by contrast, the individual tasks are able to benefit from each other. In order to evaluate our multi-task approach, we extend the annotations of the common RGB-D indoor datasets NYUv2 and SUNRGB-D for instance segmentation and orientation estimation. To the best of our knowledge, we are the first to provide results in such a comprehensive multi-task setting for indoor scene analysis on NYUv2 and SUNRGB-D.
Learning-based Monocular 3D Reconstruction of Birds: A Contemporary Survey
Jul 10, 2022
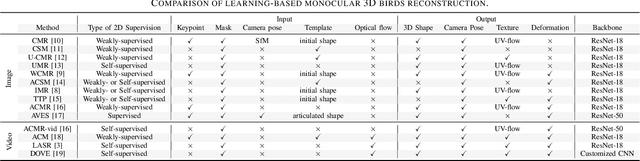
In nature, the collective behavior of animals, such as flying birds is dominated by the interactions between individuals of the same species. However, the study of such behavior among the bird species is a complex process that humans cannot perform using conventional visual observational techniques such as focal sampling in nature. For social animals such as birds, the mechanism of group formation can help ecologists understand the relationship between social cues and their visual characteristics over time (e.g., pose and shape). But, recovering the varying pose and shapes of flying birds is a highly challenging problem. A widely-adopted solution to tackle this bottleneck is to extract the pose and shape information from 2D image to 3D correspondence. Recent advances in 3D vision have led to a number of impressive works on the 3D shape and pose estimation, each with different pros and cons. To the best of our knowledge, this work is the first attempt to provide an overview of recent advances in 3D bird reconstruction based on monocular vision, give both computer vision and biology researchers an overview of existing approaches, and compare their characteristics.
Multi-Auxiliary Augmented Collaborative Variational Auto-encoder for Tag Recommendation
Apr 20, 2022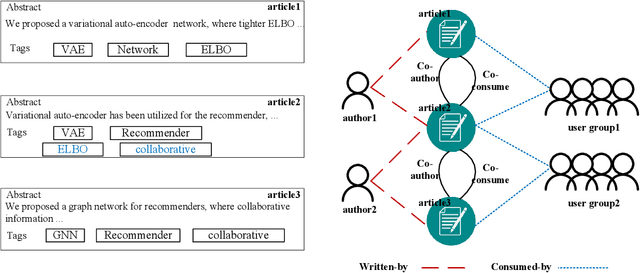
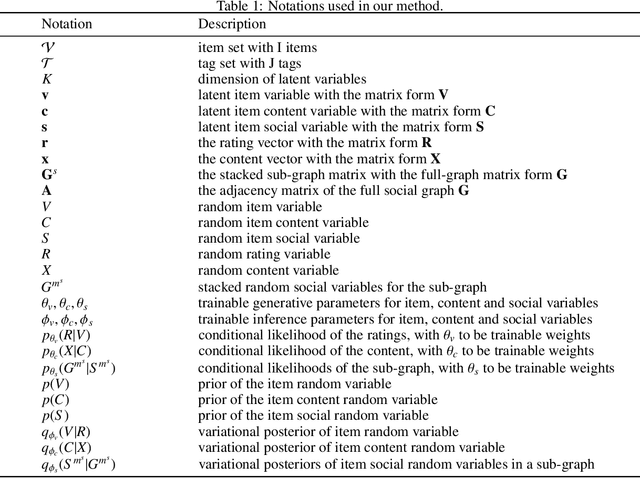
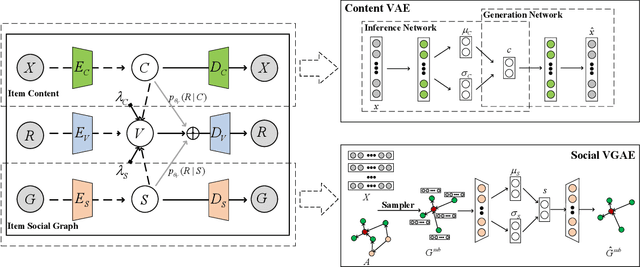
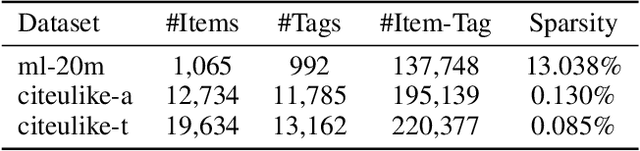
Recommending appropriate tags to items can facilitate content organization, retrieval, consumption and other applications, where hybrid tag recommender systems have been utilized to integrate collaborative information and content information for better recommendations. In this paper, we propose a multi-auxiliary augmented collaborative variational auto-encoder (MA-CVAE) for tag recommendation, which couples item collaborative information and item multi-auxiliary information, i.e., content and social graph, by defining a generative process. Specifically, the model learns deep latent embeddings from different item auxiliary information using variational auto-encoders (VAE), which could form a generative distribution over each auxiliary information by introducing a latent variable parameterized by deep neural network. Moreover, to recommend tags for new items, item multi-auxiliary latent embeddings are utilized as a surrogate through the item decoder for predicting recommendation probabilities of each tag, where reconstruction losses are added in the training phase to constrict the generation for feedback predictions via different auxiliary embeddings. In addition, an inductive variational graph auto-encoder is designed where new item nodes could be inferred in the test phase, such that item social embeddings could be exploited for new items. Extensive experiments on MovieLens and citeulike datasets demonstrate the effectiveness of our method.
Can Language Understand Depth?
Jul 03, 2022
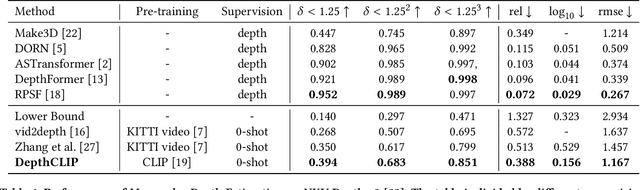
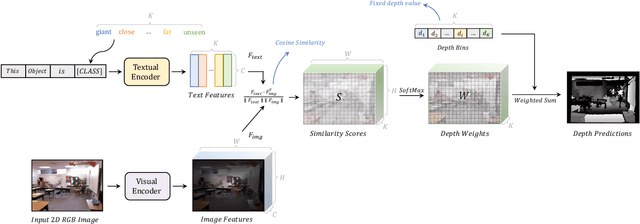
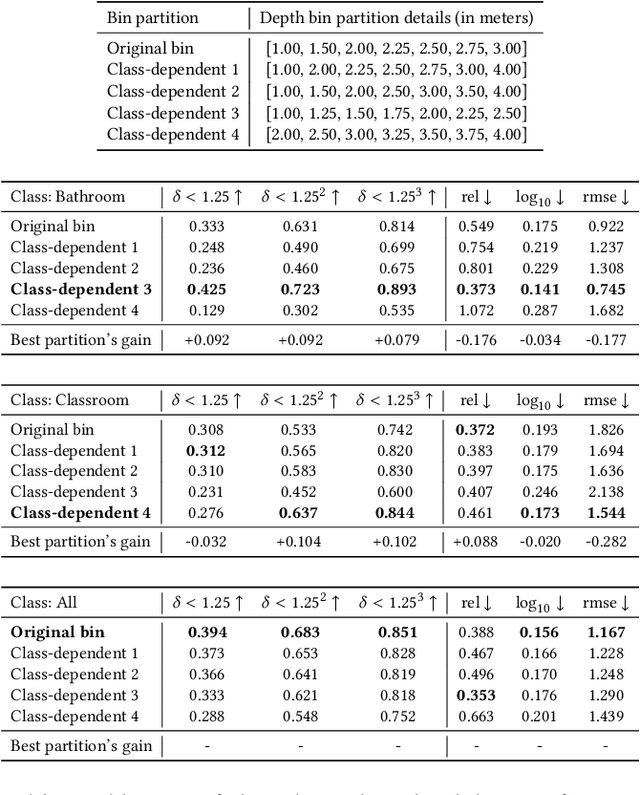
Besides image classification, Contrastive Language-Image Pre-training (CLIP) has accomplished extraordinary success for a wide range of vision tasks, including object-level and 3D space understanding. However, it's still challenging to transfer semantic knowledge learned from CLIP into more intricate tasks of quantified targets, such as depth estimation with geometric information. In this paper, we propose to apply CLIP for zero-shot monocular depth estimation, named DepthCLIP. We found that the patches of the input image could respond to a certain semantic distance token and then be projected to a quantified depth bin for coarse estimation. Without any training, our DepthCLIP surpasses existing unsupervised methods and even approaches the early fully-supervised networks. To our best knowledge, we are the first to conduct zero-shot adaptation from the semantic language knowledge to quantified downstream tasks and perform zero-shot monocular depth estimation. We hope our work could cast a light on future research. The code is available at https://github.com/Adonis-galaxy/DepthCLIP.
Multi-View Vision-to-Geometry Knowledge Transfer for 3D Point Cloud Shape Analysis
Jul 07, 2022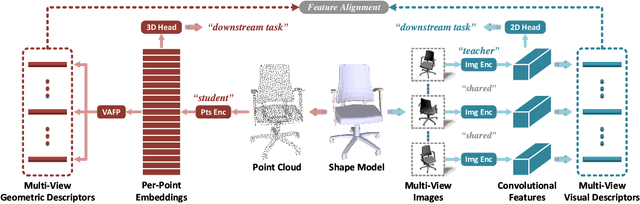
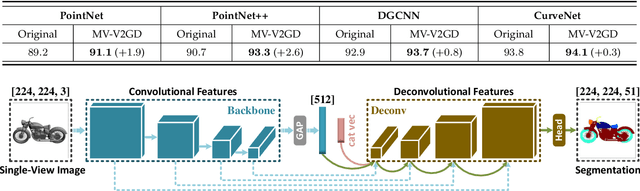


As two fundamental representation modalities of 3D objects, 2D multi-view images and 3D point clouds reflect shape information from different aspects of visual appearances and geometric structures. Unlike deep learning-based 2D multi-view image modeling, which demonstrates leading performances in various 3D shape analysis tasks, 3D point cloud-based geometric modeling still suffers from insufficient learning capacity. In this paper, we innovatively construct a unified cross-modal knowledge transfer framework, which distills discriminative visual descriptors of 2D images into geometric descriptors of 3D point clouds. Technically, under a classic teacher-student learning paradigm, we propose multi-view vision-to-geometry distillation, consisting of a deep 2D image encoder as teacher and a deep 3D point cloud encoder as student. To achieve heterogeneous feature alignment, we further propose visibility-aware feature projection, through which per-point embeddings can be aggregated into multi-view geometric descriptors. Extensive experiments on 3D shape classification, part segmentation, and unsupervised learning validate the superiority of our method. We will make the code and data publicly available.
Ray-Space Motion Compensation for Lenslet Plenoptic Video Coding
Jul 01, 2022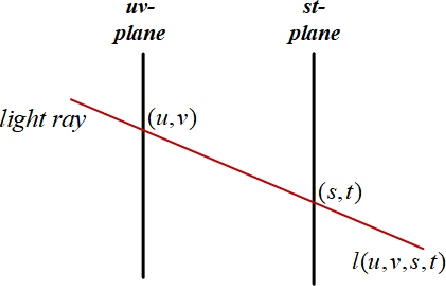
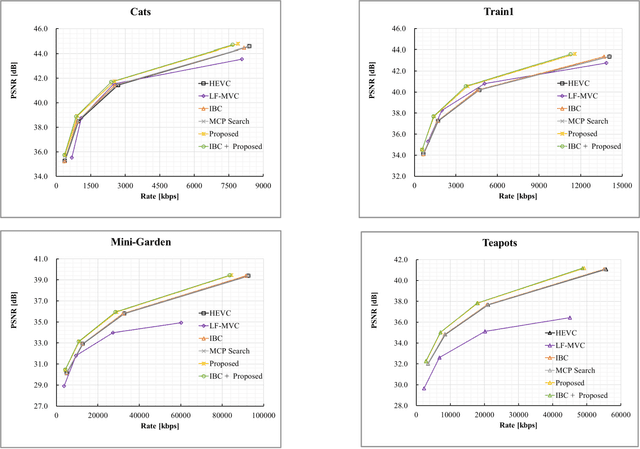
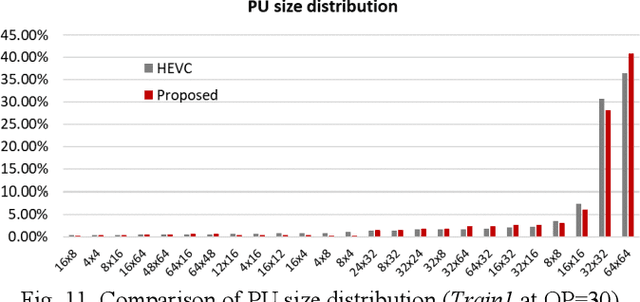
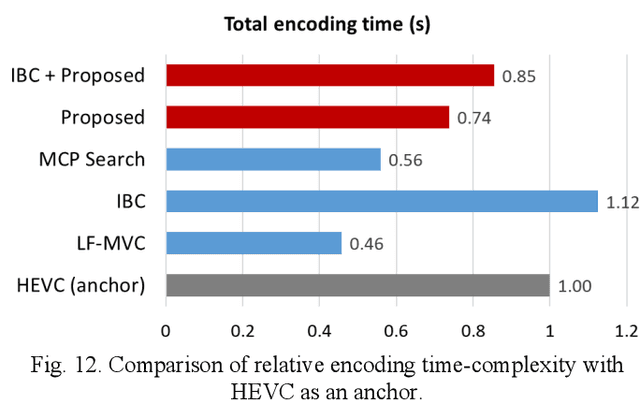
Plenoptic images and videos bearing rich information demand a tremendous amount of data storage and high transmission cost. While there has been much study on plenoptic image coding, investigations into plenoptic video coding have been very limited. We investigate the motion compensation for plenoptic video coding from a slightly different perspective by looking at the problem in the ray-space domain instead of in the conventional pixel domain. Here, we develop a novel motion compensation scheme for lenslet video under two sub-cases of ray-space motion, that is, integer ray-space motion and fractional ray-space motion. The proposed new scheme of light field motion-compensated prediction is designed such that it can be easily integrated into well-known video coding techniques such as HEVC. Experimental results compared to relevant existing methods have shown remarkable compression efficiency with an average gain of 19.63% and a peak gain of 29.1%.
Semi-unsupervised Learning for Time Series Classification
Jul 07, 2022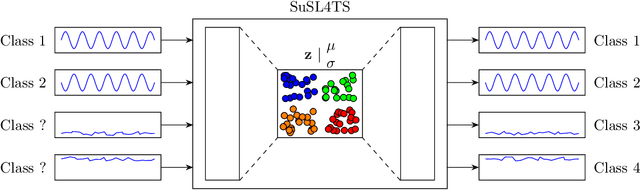


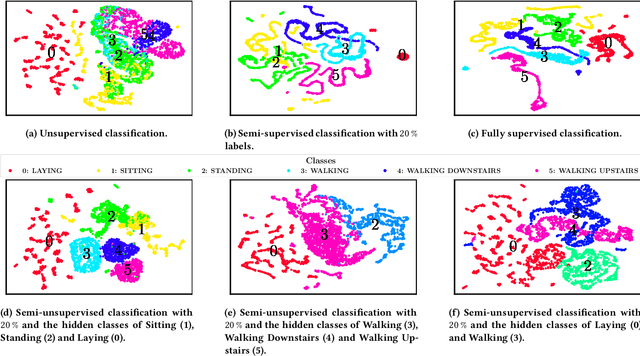
Time series are ubiquitous and therefore inherently hard to analyze and ultimately to label or cluster. With the rise of the Internet of Things (IoT) and its smart devices, data is collected in large amounts any given second. The collected data is rich in information, as one can detect accidents (e.g. cars) in real time, or assess injury/sickness over a given time span (e.g. health devices). Due to its chaotic nature and massive amounts of datapoints, timeseries are hard to label manually. Furthermore new classes within the data could emerge over time (contrary to e.g. handwritten digits), which would require relabeling the data. In this paper we present SuSL4TS, a deep generative Gaussian mixture model for semi-unsupervised learning, to classify time series data. With our approach we can alleviate manual labeling steps, since we can detect sparsely labeled classes (semi-supervised) and identify emerging classes hidden in the data (unsupervised). We demonstrate the efficacy of our approach with established time series classification datasets from different domains.