 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Learning under Latent Label Shift
Jul 26, 2022

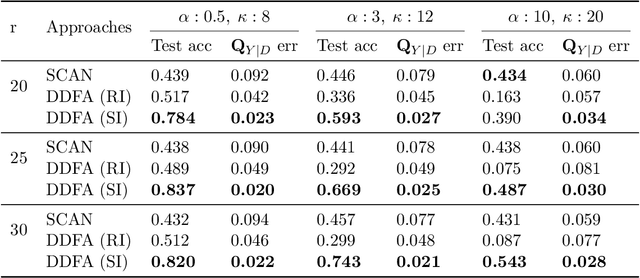

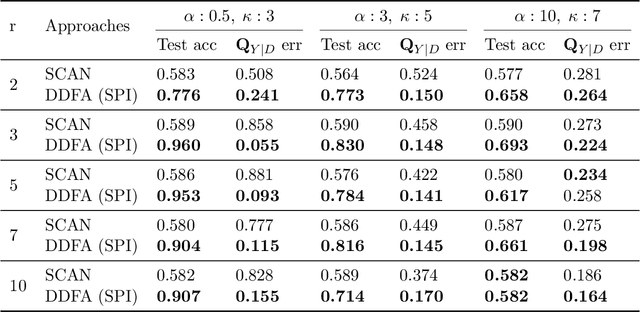
What sorts of structure might enable a learner to discover classes from unlabeled data? Traditional approaches rely on feature-space similarity and heroic assumptions on the data. In this paper, we introduce unsupervised learning under Latent Label Shift (LLS), where we have access to unlabeled data from multiple domains such that the label marginals $p_d(y)$ can shift across domains but the class conditionals $p(\mathbf{x}|y)$ do not. This work instantiates a new principle for identifying classes: elements that shift together group together. For finite input spaces, we establish an isomorphism between LLS and topic modeling: inputs correspond to words, domains to documents, and labels to topics. Addressing continuous data, we prove that when each label's support contains a separable region, analogous to an anchor word, oracle access to $p(d|\mathbf{x})$ suffices to identify $p_d(y)$ and $p_d(y|\mathbf{x})$ up to permutation. Thus motivated, we introduce a practical algorithm that leverages domain-discriminative models as follows: (i) push examples through domain discriminator $p(d|\mathbf{x})$; (ii) discretize the data by clustering examples in $p(d|\mathbf{x})$ space; (iii) perform non-negative matrix factorization on the discrete data; (iv) combine the recovered $p(y|d)$ with the discriminator outputs $p(d|\mathbf{x})$ to compute $p_d(y|x) \; \forall d$. With semi-synthetic experiments, we show that our algorithm can leverage domain information to improve state of the art unsupervised classification methods. We reveal a failure mode of standard unsupervised classification methods when feature-space similarity does not indicate true groupings, and show empirically that our method better handles this case. Our results establish a deep connection between distribution shift and topic modeling, opening promising lines for future work.
Effects of Augmented-Reality-Based Assisting Interfaces on Drivers' Object-wise Situational Awareness in Highly Autonomous Vehicles
Jun 06, 2022


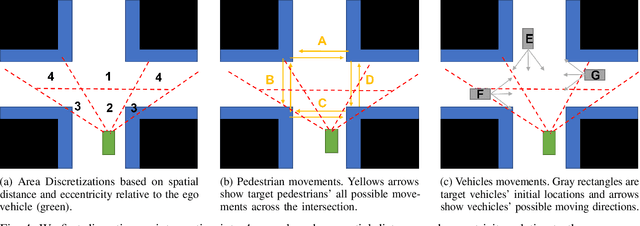
Although partially autonomous driving (AD) systems are already available in production vehicles, drivers are still required to maintain a sufficient level of situational awareness (SA) during driving. Previous studies have shown that providing information about the AD's capability using user interfaces can improve the driver's SA. However, displaying too much information increases the driver's workload and can distract or overwhelm the driver. Therefore, to design an efficient user interface (UI), it is necessary to understand its effect under different circumstances. In this paper, we focus on a UI based on augmented reality (AR), which can highlight potential hazards on the road. To understand the effect of highlighting on drivers' SA for objects with different types and locations under various traffic densities, we conducted an in-person experiment with 20 participants on a driving simulator. Our study results show that the effects of highlighting on drivers' SA varied by traffic densities, object locations and object types. We believe our study can provide guidance in selecting which object to highlight for the AR-based driver-assistance interface to optimize SA for drivers driving and monitoring partially autonomous vehicles.
TINYCD: A (Not So) Deep Learning Model For Change Detection
Jul 26, 2022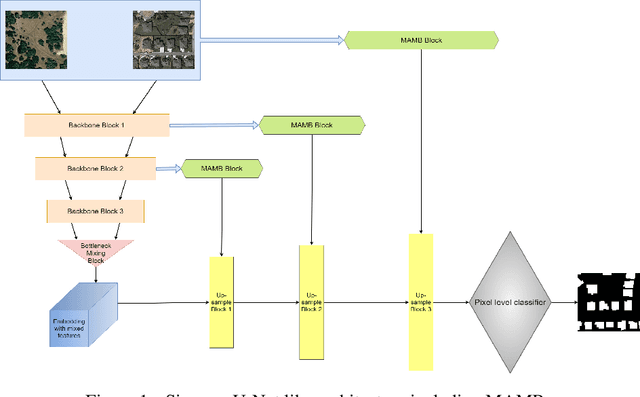
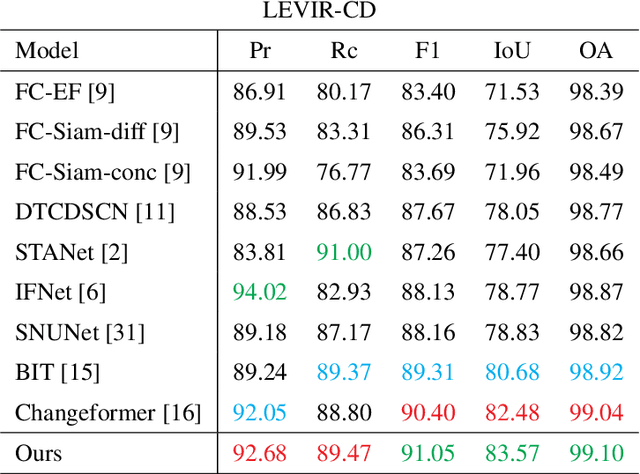
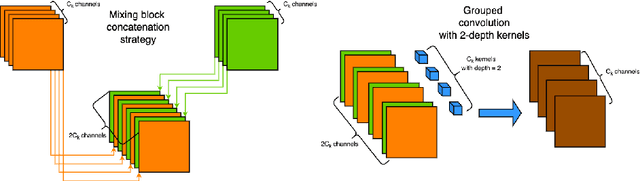
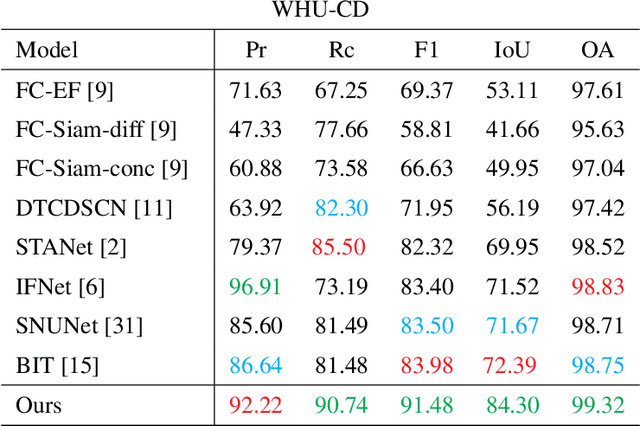
The aim of change detection (CD) is to detect changes occurred in the same area by comparing two images of that place taken at different times. The challenging part of the CD is to keep track of the changes the user wants to highlight, such as new buildings, and to ignore changes due to external factors such as environmental, lighting condition, fog or seasonal changes. Recent developments in the field of deep learning enabled researchers to achieve outstanding performance in this area. In particular, different mechanisms of space-time attention allowed to exploit the spatial features that are extracted from the models and to correlate them also in a temporal way by exploiting both the available images. The downside is that the models have become increasingly complex and large, often unfeasible for edge applications. These are limitations when the models must be applied to the industrial field or in applications requiring real-time performances. In this work we propose a novel model, called TinyCD, demonstrating to be both lightweight and effective, able to achieve performances comparable or even superior to the current state of the art with 13-150X fewer parameters. In our approach we have exploited the importance of low-level features to compare images. To do this, we use only few backbone blocks. This strategy allow us to keep the number of network parameters low. To compose the features extracted from the two images, we introduce a novel, economical in terms of parameters, mixing block capable of cross correlating features in both space and time domains. Finally, to fully exploit the information contained in the computed features, we define the PW-MLP block able to perform a pixel wise classification. Source code, models and results are available here: https://github.com/AndreaCodegoni/Tiny_model_4_CD
Finding Optimal Policy for Queueing Models: New Parameterization
Jun 21, 2022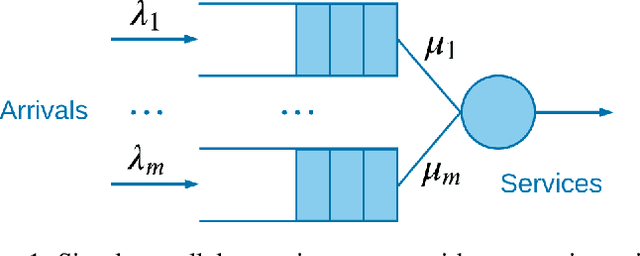

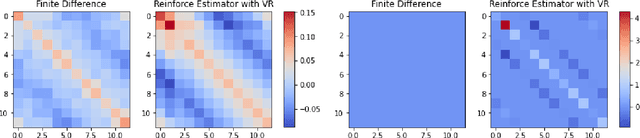

Queueing systems appear in many important real-life applications including communication networks, transportation and manufacturing systems. Reinforcement learning (RL) framework is a suitable model for the queueing control problem where the underlying dynamics are usually unknown and the agent receives little information from the environment to navigate. In this work, we investigate the optimization aspects of the queueing model as a RL environment and provide insight to learn the optimal policy efficiently. We propose a new parameterization of the policy by using the intrinsic properties of queueing network systems. Experiments show good performance of our methods with various load conditions from light to heavy traffic.
DelightfulTTS 2: End-to-End Speech Synthesis with Adversarial Vector-Quantized Auto-Encoders
Jul 11, 2022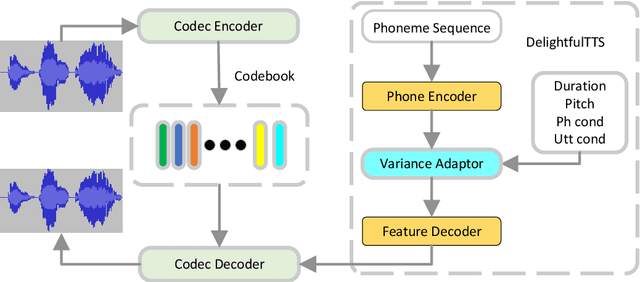
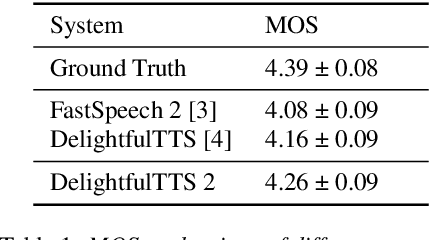
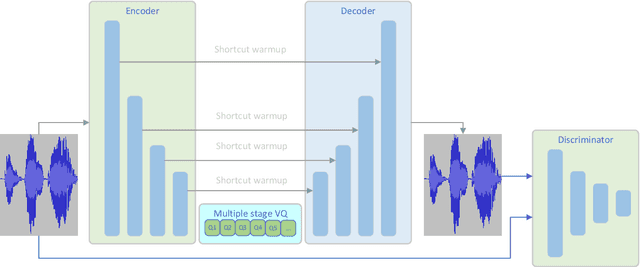
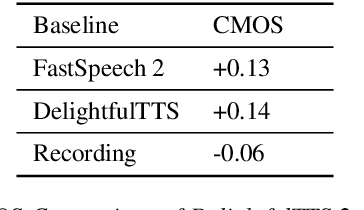
Current text to speech (TTS) systems usually leverage a cascaded acoustic model and vocoder pipeline with mel-spectrograms as the intermediate representations, which suffer from two limitations: 1) the acoustic model and vocoder are separately trained instead of jointly optimized, which incurs cascaded errors; 2) the intermediate speech representations (e.g., mel-spectrogram) are pre-designed and lose phase information, which are sub-optimal. To solve these problems, in this paper, we develop DelightfulTTS 2, a new end-to-end speech synthesis system with automatically learned speech representations and jointly optimized acoustic model and vocoder. Specifically, 1) we propose a new codec network based on vector-quantized auto-encoders with adversarial training (VQ-GAN) to extract intermediate frame-level speech representations (instead of traditional representations like mel-spectrograms) and reconstruct speech waveform; 2) we jointly optimize the acoustic model (based on DelightfulTTS) and the vocoder (the decoder of VQ-GAN), with an auxiliary loss on the acoustic model to predict intermediate speech representations. Experiments show that DelightfulTTS 2 achieves a CMOS gain +0.14 over DelightfulTTS, and more method analyses further verify the effectiveness of the developed system.
Solutions for Fine-grained and Long-tailed Snake Species Recognition in SnakeCLEF 2022
Jul 04, 2022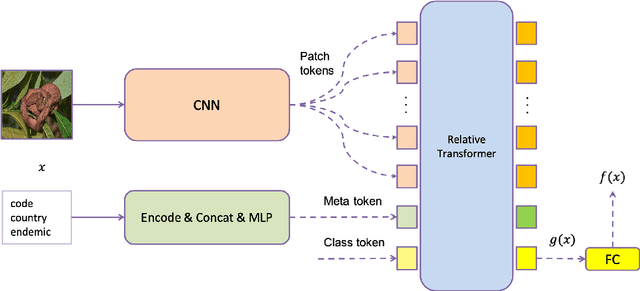
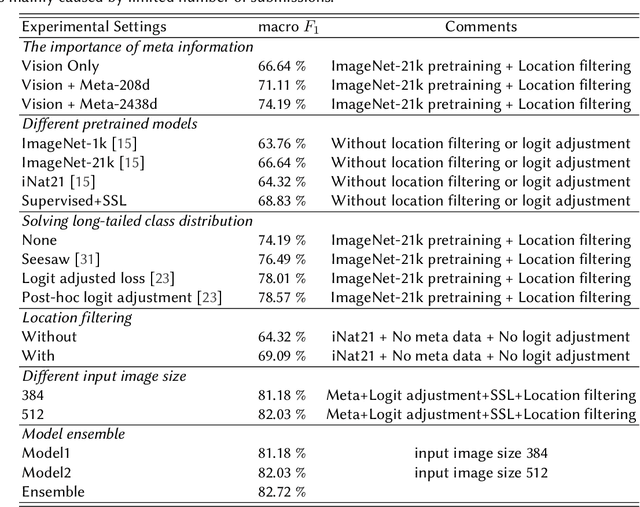

Automatic snake species recognition is important because it has vast potential to help lower deaths and disabilities caused by snakebites. We introduce our solution in SnakeCLEF 2022 for fine-grained snake species recognition on a heavy long-tailed class distribution. First, a network architecture is designed to extract and fuse features from multiple modalities, i.e. photograph from visual modality and geographic locality information from language modality. Then, logit adjustment based methods are studied to relieve the impact caused by the severe class imbalance. Next, a combination of supervised and self-supervised learning method is proposed to make full use of the dataset, including both labeled training data and unlabeled testing data. Finally, post processing strategies, such as multi-scale and multi-crop test-time-augmentation, location filtering and model ensemble, are employed for better performance. With an ensemble of several different models, a private score 82.65%, ranking the 3rd, is achieved on the final leaderboard.
Collaborative Quantization Embeddings for Intra-Subject Prostate MR Image Registration
Jul 14, 2022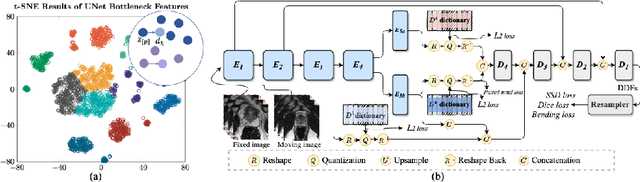
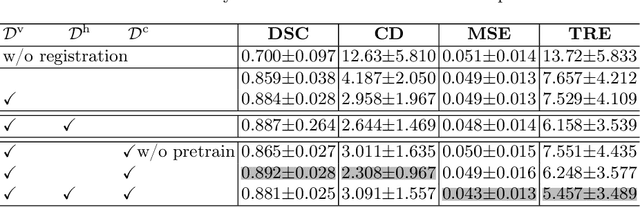
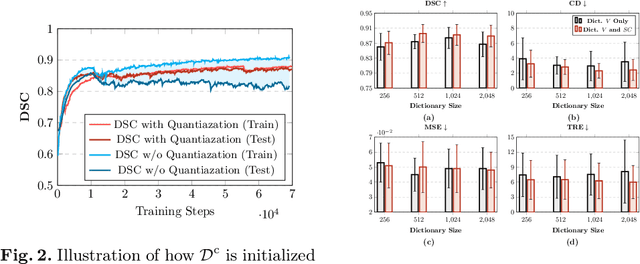
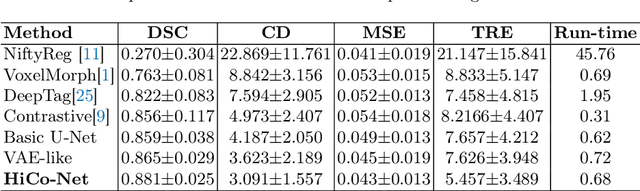
Image registration is useful for quantifying morphological changes in longitudinal MR images from prostate cancer patients. This paper describes a development in improving the learning-based registration algorithms, for this challenging clinical application often with highly variable yet limited training data. First, we report that the latent space can be clustered into a much lower dimensional space than that commonly found as bottleneck features at the deep layer of a trained registration network. Based on this observation, we propose a hierarchical quantization method, discretizing the learned feature vectors using a jointly-trained dictionary with a constrained size, in order to improve the generalisation of the registration networks. Furthermore, a novel collaborative dictionary is independently optimised to incorporate additional prior information, such as the segmentation of the gland or other regions of interest, in the latent quantized space. Based on 216 real clinical images from 86 prostate cancer patients, we show the efficacy of both the designed components. Improved registration accuracy was obtained with statistical significance, in terms of both Dice on gland and target registration error on corresponding landmarks, the latter of which achieved 5.46 mm, an improvement of 28.7\% from the baseline without quantization. Experimental results also show that the difference in performance was indeed minimised between training and testing data.
Bilingual Mutual Information Based Adaptive Training for Neural Machine Translation
May 26, 2021


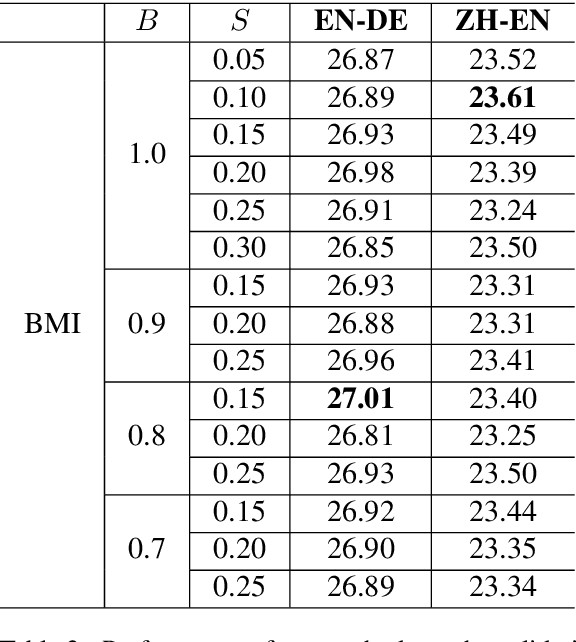
Recently, token-level adaptive training has achieved promising improvement in machine translation, where the cross-entropy loss function is adjusted by assigning different training weights to different tokens, in order to alleviate the token imbalance problem. However, previous approaches only use static word frequency information in the target language without considering the source language, which is insufficient for bilingual tasks like machine translation. In this paper, we propose a novel bilingual mutual information (BMI) based adaptive objective, which measures the learning difficulty for each target token from the perspective of bilingualism, and assigns an adaptive weight accordingly to improve token-level adaptive training. This method assigns larger training weights to tokens with higher BMI, so that easy tokens are updated with coarse granularity while difficult tokens are updated with fine granularity. Experimental results on WMT14 English-to-German and WMT19 Chinese-to-English demonstrate the superiority of our approach compared with the Transformer baseline and previous token-level adaptive training approaches. Further analyses confirm that our method can improve the lexical diversity.
AMS-Net: Adaptive Multiscale Sparse Neural Network with Interpretable Basis Expansion for Multiphase Flow Problems
Jul 24, 2022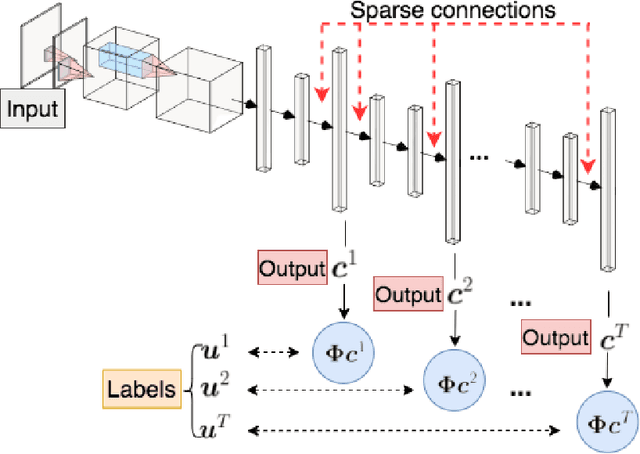
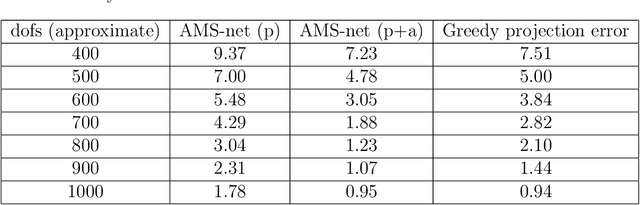
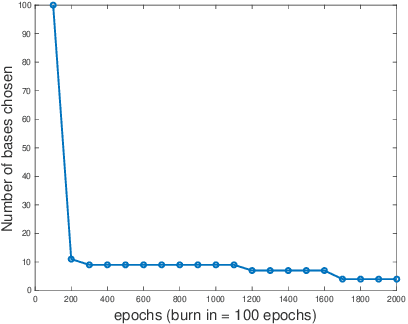
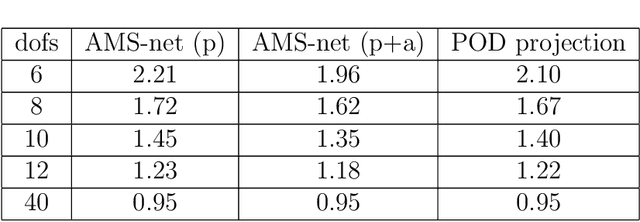
In this work, we propose an adaptive sparse learning algorithm that can be applied to learn the physical processes and obtain a sparse representation of the solution given a large snapshot space. Assume that there is a rich class of precomputed basis functions that can be used to approximate the quantity of interest. We then design a neural network architecture to learn the coefficients of solutions in the spaces which are spanned by these basis functions. The information of the basis functions are incorporated in the loss function, which minimizes the differences between the downscaled reduced order solutions and reference solutions at multiple time steps. The network contains multiple submodules and the solutions at different time steps can be learned simultaneously. We propose some strategies in the learning framework to identify important degrees of freedom. To find a sparse solution representation, a soft thresholding operator is applied to enforce the sparsity of the output coefficient vectors of the neural network. To avoid over-simplification and enrich the approximation space, some degrees of freedom can be added back to the system through a greedy algorithm. In both scenarios, that is, removing and adding degrees of freedom, the corresponding network connections are pruned or reactivated guided by the magnitude of the solution coefficients obtained from the network outputs. The proposed adaptive learning process is applied to some toy case examples to demonstrate that it can achieve a good basis selection and accurate approximation. More numerical tests are performed on two-phase multiscale flow problems to show the capability and interpretability of the proposed method on complicated applications.
Monocular Depth Estimation Using Cues Inspired by Biological Vision Systems
Apr 21, 2022
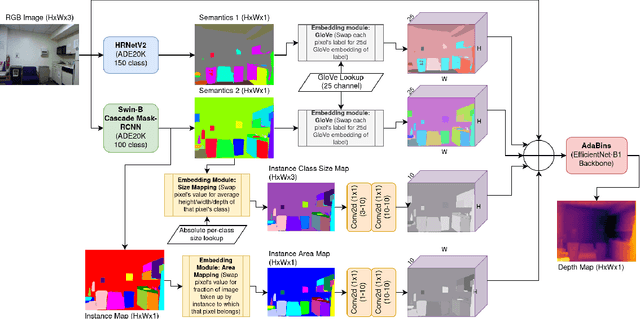
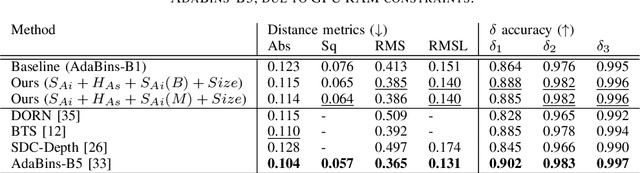
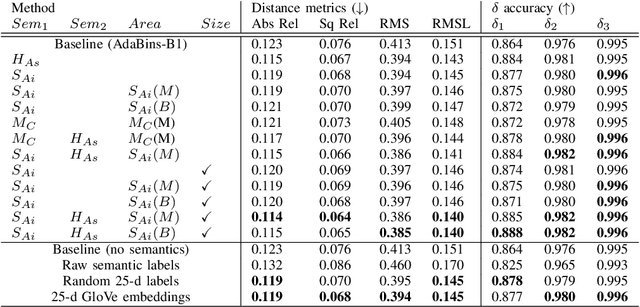
Monocular depth estimation (MDE) aims to transform an RGB image of a scene into a pixelwise depth map from the same camera view. It is fundamentally ill-posed due to missing information: any single image can have been taken from many possible 3D scenes. Part of the MDE task is, therefore, to learn which visual cues in the image can be used for depth estimation, and how. With training data limited by cost of annotation or network capacity limited by computational power, this is challenging. In this work we demonstrate that explicitly injecting visual cue information into the model is beneficial for depth estimation. Following research into biological vision systems, we focus on semantic information and prior knowledge of object sizes and their relations, to emulate the biological cues of relative size, familiar size, and absolute size. We use state-of-the-art semantic and instance segmentation models to provide external information, and exploit language embeddings to encode relational information between classes. We also provide a prior on the average real-world size of objects. This external information overcomes the limitation in data availability, and ensures that the limited capacity of a given network is focused on known-helpful cues, therefore improving performance. We experimentally validate our hypothesis and evaluate the proposed model on the widely used NYUD2 indoor depth estimation benchmark. The results show improvements in depth prediction when the semantic information, size prior and instance size are explicitly provided along with the RGB images, and our method can be easily adapted to any depth estimation system.