 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Measuring Information Transfer in Neural Networks
Sep 16, 2020
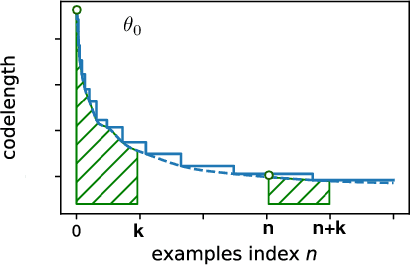
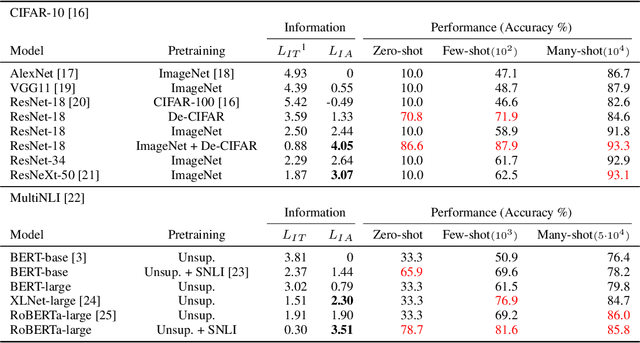
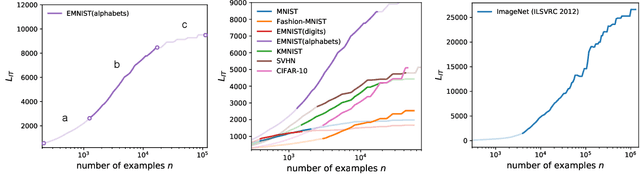
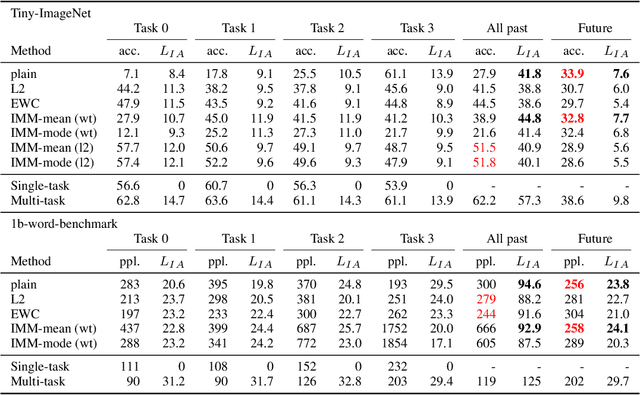
Estimation of the information content in a neural network model can be prohibitive, because of difficulty in finding an optimal codelength of the model. We propose to use a surrogate measure to bypass directly estimating model information. The proposed Information Transfer ($L_{IT}$) is a measure of model information based on prequential coding. $L_{IT}$ is theoretically connected to model information, and is consistently correlated with model information in experiments. We show that $L_{IT}$ can be used as a measure of generalizable knowledge in a model or a dataset. Therefore, $L_{IT}$ can serve as an analytical tool in deep learning. We apply $L_{IT}$ to compare and dissect information in datasets, evaluate representation models in transfer learning, and analyze catastrophic forgetting and continual learning algorithms. $L_{IT}$ provides an informational perspective which helps us discover new insights into neural network learning.
Latency Minimization for mmWave D2D Mobile Edge Computing Systems: Joint Task Allocation and Hybrid Beamforming Design
Jul 17, 2022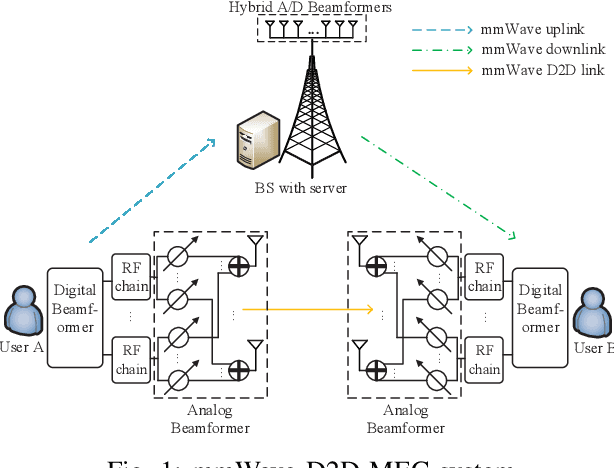
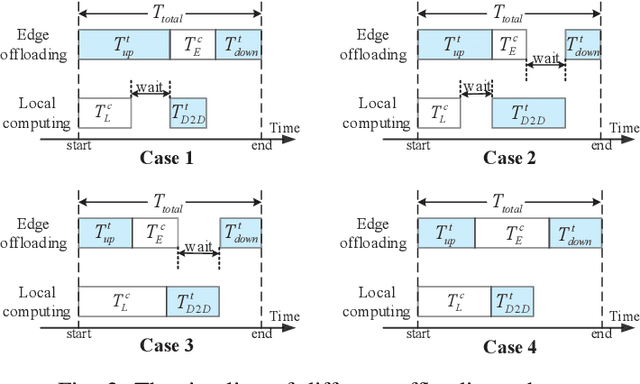
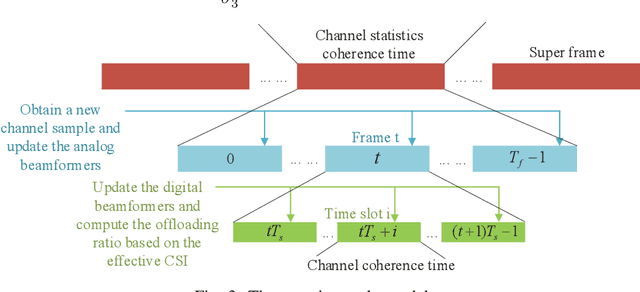
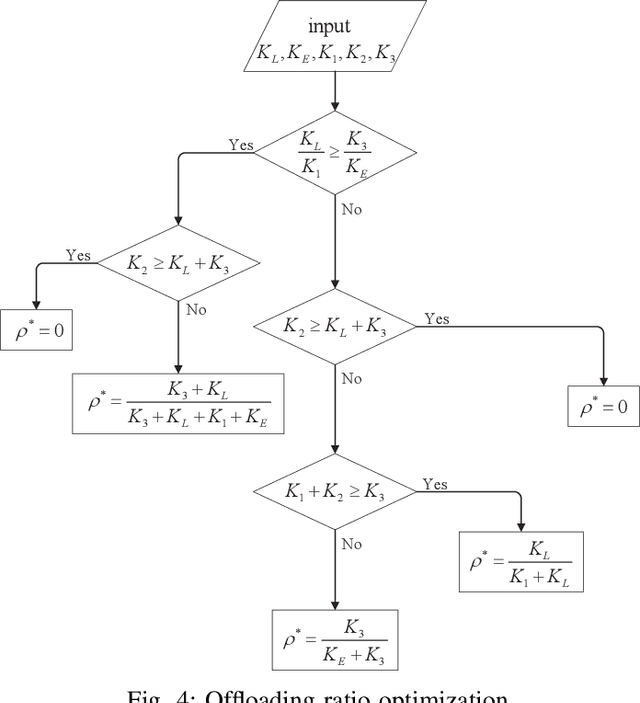
Mobile edge computing (MEC) and millimeter wave (mmWave) communications are capable of significantly reducing the network's delay and enhancing its capacity. In this paper we investigate a mmWave and device-to-device (D2D) assisted MEC system, in which user A carries out some computational tasks and shares the results with user B with the aid of a base station (BS). We propose a novel two-timescale joint hybrid beamforming and task allocation algorithm to reduce the system latency whilst cut down the required signaling overhead. Specifically, the high-dimensional analog beamforming matrices are updated in a frame-based manner based on the channel state information (CSI) samples, where each frame consists of a number of time slots, while the low-dimensional digital beamforming matrices and the offloading ratio are optimized more frequently relied on the low-dimensional effective channel matrices in each time slot. A stochastic successive convex approximation (SSCA) based algorithm is developed to design the long-term analog beamforming matrices. As for the short-term variables, the digital beamforming matrices are optimized relying on the innovative penalty-concave convex procedure (penalty-CCCP) for handling the mmWave non-linear transmit power constraint, and the offloading ratio can be obtained via the derived closed-form solution. Simulation results verify the effectiveness of the proposed algorithm by comparing the benchmarks.
Hierarchical Spherical CNNs with Lifting-based Adaptive Wavelets for Pooling and Unpooling
May 31, 2022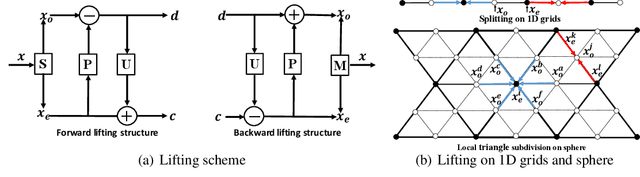
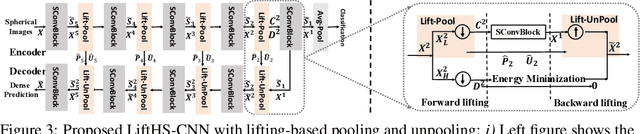


Pooling and unpooling are two essential operations in constructing hierarchical spherical convolutional neural networks (HS-CNNs) for comprehensive feature learning in the spherical domain. Most existing models employ downsampling-based pooling, which will inevitably incur information loss and cannot adapt to different spherical signals and tasks. Besides, the preserved information after pooling cannot be well restored by the subsequent unpooling to characterize the desirable features for a task. In this paper, we propose a novel framework of HS-CNNs with a lifting structure to learn adaptive spherical wavelets for pooling and unpooling, dubbed LiftHS-CNN, which ensures a more efficient hierarchical feature learning for both image- and pixel-level tasks. Specifically, adaptive spherical wavelets are learned with a lifting structure that consists of trainable lifting operators (i.e., update and predict operators). With this learnable lifting structure, we can adaptively partition a signal into two sub-bands containing low- and high-frequency components, respectively, and thus generate a better down-scaled representation for pooling by preserving more information in the low-frequency sub-band. The update and predict operators are parameterized with graph-based attention to jointly consider the signal's characteristics and the underlying geometries. We further show that particular properties are promised by the learned wavelets, ensuring the spatial-frequency localization for better exploiting the signal's correlation in both spatial and frequency domains. We then propose an unpooling operation that is invertible to the lifting-based pooling, where an inverse wavelet transform is performed by using the learned lifting operators to restore an up-scaled representation. Extensive empirical evaluations on various spherical domain tasks validate the superiority of the proposed LiftHS-CNN.
Enhanced graph-learning schemes driven by similar distributions of motifs
Jul 11, 2022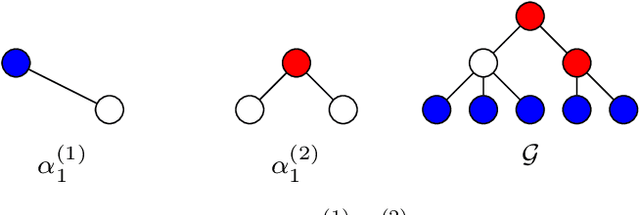
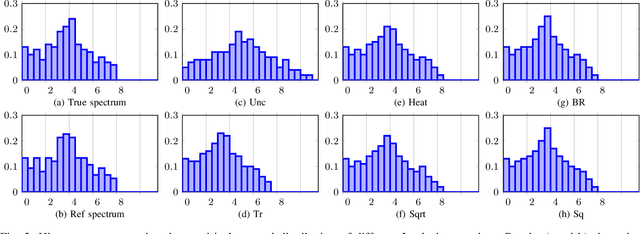
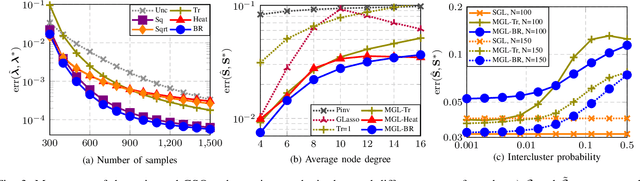
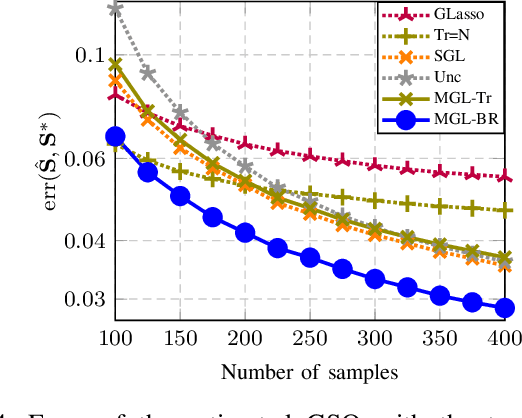
This paper looks at the task of network topology inference, where the goal is to learn an unknown graph from nodal observations. One of the novelties of the approach put forth is the consideration of prior information about the density of motifs of the unknown graph to enhance the inference of classical Gaussian graphical models. Dealing with the density of motifs directly constitutes a challenging combinatorial task. However, we note that if two graphs have similar motif densities, one can show that the expected value of a polynomial applied to their empirical spectral distributions will be similar. Guided by this, we first assume that we have a reference graph that is related to the sought graph (in the sense of having similar motif densities) and then, we exploit this relation by incorporating a similarity constraint and a regularization term in the network topology inference optimization problem. The (non-)convexity of the optimization problem is discussed and a computational efficient alternating majorization-minimization algorithm is designed. We assess the performance of the proposed method through exhaustive numerical experiments where different constraints are considered and compared against popular baselines algorithms on both synthetic and real-world datasets.
Deep Partial Least Squares for Empirical Asset Pricing
Jun 20, 2022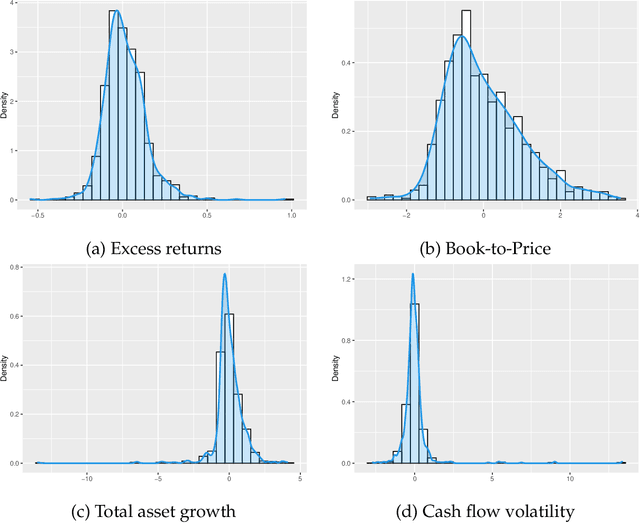
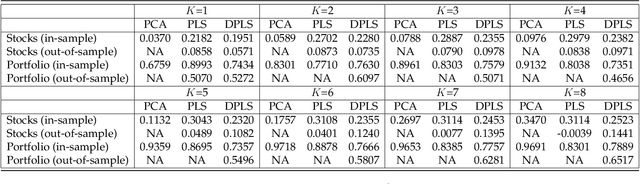
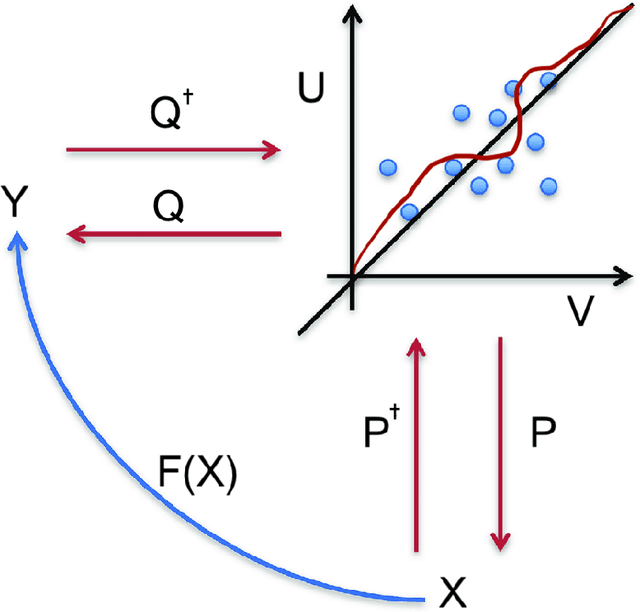

We use deep partial least squares (DPLS) to estimate an asset pricing model for individual stock returns that exploits conditioning information in a flexible and dynamic way while attributing excess returns to a small set of statistical risk factors. The novel contribution is to resolve the non-linear factor structure, thus advancing the current paradigm of deep learning in empirical asset pricing which uses linear stochastic discount factors under an assumption of Gaussian asset returns and factors. This non-linear factor structure is extracted by using projected least squares to jointly project firm characteristics and asset returns on to a subspace of latent factors and using deep learning to learn the non-linear map from the factor loadings to the asset returns. The result of capturing this non-linear risk factor structure is to characterize anomalies in asset returns by both linear risk factor exposure and interaction effects. Thus the well known ability of deep learning to capture outliers, shed lights on the role of convexity and higher order terms in the latent factor structure on the factor risk premia. On the empirical side, we implement our DPLS factor models and exhibit superior performance to LASSO and plain vanilla deep learning models. Furthermore, our network training times are significantly reduced due to the more parsimonious architecture of DPLS. Specifically, using 3290 assets in the Russell 1000 index over a period of December 1989 to January 2018, we assess our DPLS factor model and generate information ratios that are approximately 1.2x greater than deep learning. DPLS explains variation and pricing errors and identifies the most prominent latent factors and firm characteristics.
Points2NeRF: Generating Neural Radiance Fields from 3D point cloud
Jun 02, 2022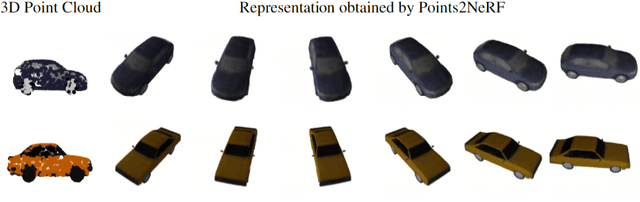



Contemporary registration devices for 3D visual information, such as LIDARs and various depth cameras, capture data as 3D point clouds. In turn, such clouds are challenging to be processed due to their size and complexity. Existing methods address this problem by fitting a mesh to the point cloud and rendering it instead. This approach, however, leads to the reduced fidelity of the resulting visualization and misses color information of the objects crucial in computer graphics applications. In this work, we propose to mitigate this challenge by representing 3D objects as Neural Radiance Fields (NeRFs). We leverage a hypernetwork paradigm and train the model to take a 3D point cloud with the associated color values and return a NeRF network's weights that reconstruct 3D objects from input 2D images. Our method provides efficient 3D object representation and offers several advantages over the existing approaches, including the ability to condition NeRFs and improved generalization beyond objects seen in training. The latter we also confirmed in the results of our empirical evaluation.
An efficient Deep Spatio-Temporal Context Aware decision Network (DST-CAN) for Predictive Manoeuvre Planning
May 20, 2022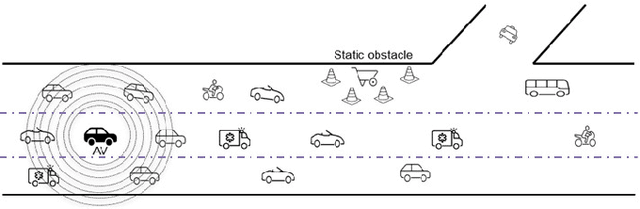
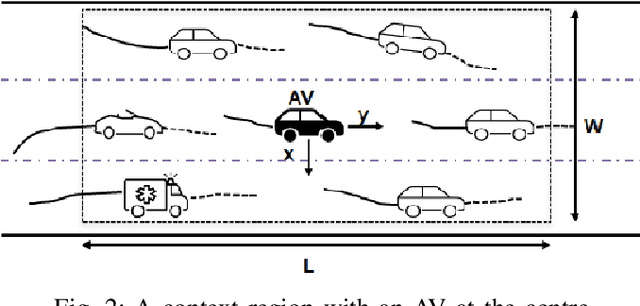
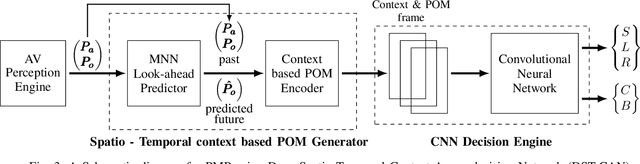
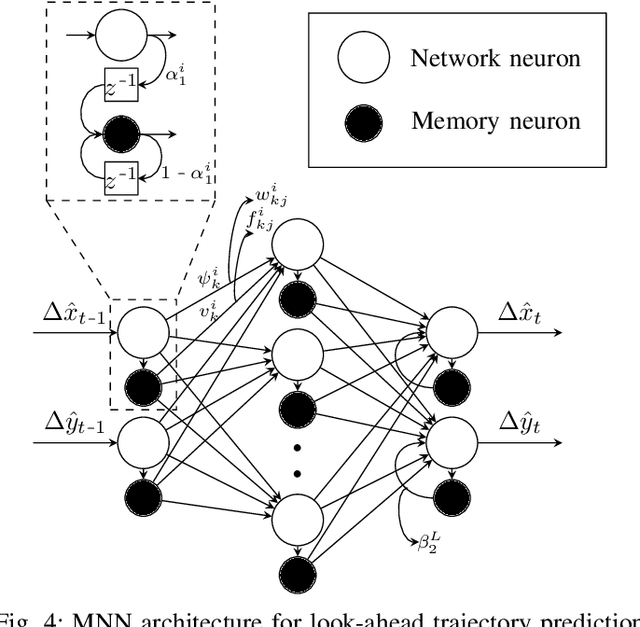
To ensure the safety and efficiency of its maneuvers, an Autonomous Vehicle (AV) should anticipate the future intentions of surrounding vehicles using its sensor information. If an AV can predict its surrounding vehicles' future trajectories, it can make safe and efficient manoeuvre decisions. In this paper, we present such a Deep Spatio-Temporal Context-Aware decision Network (DST-CAN) model for predictive manoeuvre planning of AVs. A memory neuron network is used to predict future trajectories of its surrounding vehicles. The driving environment's spatio-temporal information (past, present, and predicted future trajectories) are embedded into a context-aware grid. The proposed DST-CAN model employs these context-aware grids as inputs to a convolutional neural network to understand the spatial relationships between the vehicles and determine a safe and efficient manoeuvre decision. The DST-CAN model also uses information of human driving behavior on a highway. Performance evaluation of DST-CAN has been carried out using two publicly available NGSIM US-101 and I-80 datasets. Also, rule-based ground truth decisions have been compared with those generated by DST-CAN. The results clearly show that DST-CAN can make much better decisions with 3-sec of predicted trajectories of neighboring vehicles compared to currently existing methods that do not use this prediction.
SceneTrilogy: On Scene Sketches and its Relationship with Text and Photo
Apr 25, 2022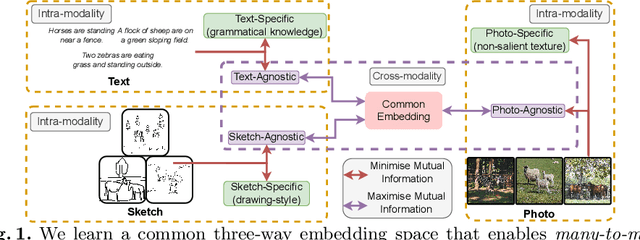
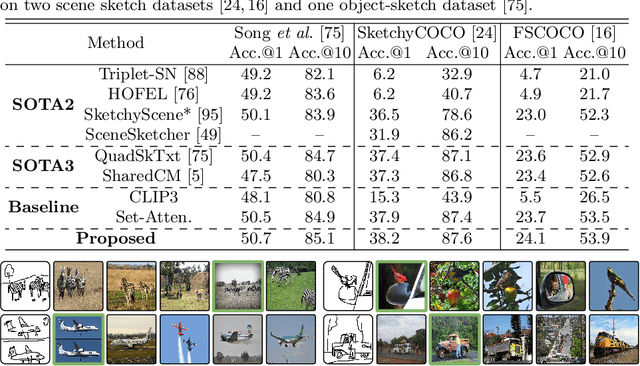
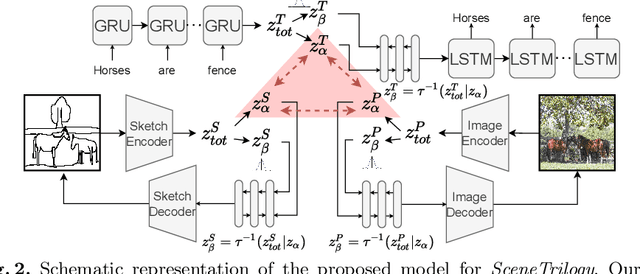

We for the first time extend multi-modal scene understanding to include that of free-hand scene sketches. This uniquely results in a trilogy of scene data modalities (sketch, text, and photo), where each offers unique perspectives for scene understanding, and together enable a series of novel scene-specific applications across discriminative (retrieval) and generative (captioning) tasks. Our key objective is to learn a common three-way embedding space that enables many-to-many modality interactions (e.g, sketch+text $\rightarrow$ photo retrieval). We importantly leverage the information bottleneck theory to achieve this goal, where we (i) decouple intra-modality information by minimising the mutual information between modality-specific and modality-agnostic components via a conditional invertible neural network, and (ii) align \textit{cross-modalities information} by maximising the mutual information between their modality-agnostic components using InfoNCE, with a specific multihead attention mechanism to allow many-to-many modality interactions. We spell out a few insights on the complementarity of each modality for scene understanding, and study for the first time a series of scene-specific applications like joint sketch- and text-based image retrieval, sketch captioning.
Multi-scale Information Assembly for Image Matting
Jan 07, 2021Image matting is a long-standing problem in computer graphics and vision, mostly identified as the accurate estimation of the foreground in input images. We argue that the foreground objects can be represented by different-level information, including the central bodies, large-grained boundaries, refined details, etc. Based on this observation, in this paper, we propose a multi-scale information assembly framework (MSIA-matte) to pull out high-quality alpha mattes from single RGB images. Technically speaking, given an input image, we extract advanced semantics as our subject content and retain initial CNN features to encode different-level foreground expression, then combine them by our well-designed information assembly strategy. Extensive experiments can prove the effectiveness of the proposed MSIA-matte, and we can achieve state-of-the-art performance compared to most existing matting networks.
Unsupervised Learning under Latent Label Shift
Jul 26, 2022
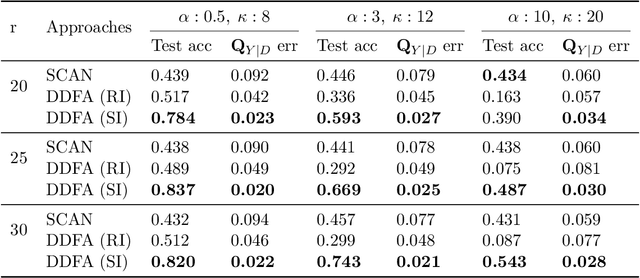

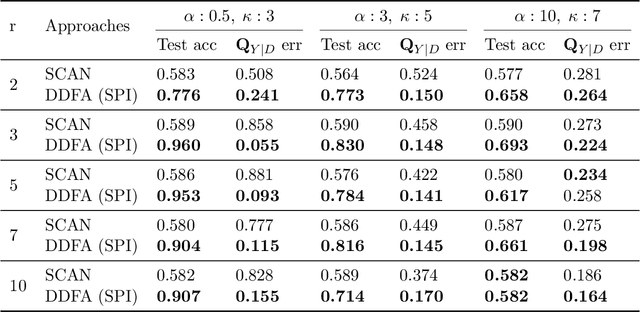
What sorts of structure might enable a learner to discover classes from unlabeled data? Traditional approaches rely on feature-space similarity and heroic assumptions on the data. In this paper, we introduce unsupervised learning under Latent Label Shift (LLS), where we have access to unlabeled data from multiple domains such that the label marginals $p_d(y)$ can shift across domains but the class conditionals $p(\mathbf{x}|y)$ do not. This work instantiates a new principle for identifying classes: elements that shift together group together. For finite input spaces, we establish an isomorphism between LLS and topic modeling: inputs correspond to words, domains to documents, and labels to topics. Addressing continuous data, we prove that when each label's support contains a separable region, analogous to an anchor word, oracle access to $p(d|\mathbf{x})$ suffices to identify $p_d(y)$ and $p_d(y|\mathbf{x})$ up to permutation. Thus motivated, we introduce a practical algorithm that leverages domain-discriminative models as follows: (i) push examples through domain discriminator $p(d|\mathbf{x})$; (ii) discretize the data by clustering examples in $p(d|\mathbf{x})$ space; (iii) perform non-negative matrix factorization on the discrete data; (iv) combine the recovered $p(y|d)$ with the discriminator outputs $p(d|\mathbf{x})$ to compute $p_d(y|x) \; \forall d$. With semi-synthetic experiments, we show that our algorithm can leverage domain information to improve state of the art unsupervised classification methods. We reveal a failure mode of standard unsupervised classification methods when feature-space similarity does not indicate true groupings, and show empirically that our method better handles this case. Our results establish a deep connection between distribution shift and topic modeling, opening promising lines for future work.