 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fast Rate Generalization Error Bounds: Variations on a Theme
May 13, 2022
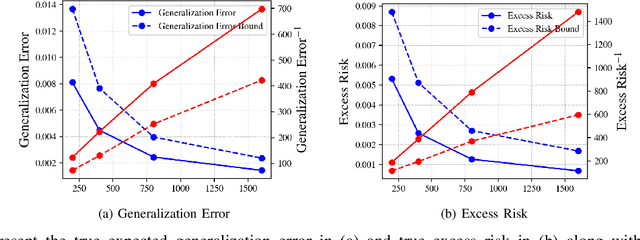


A recent line of works, initiated by Russo and Xu, has shown that the generalization error of a learning algorithm can be upper bounded by information measures. In most of the relevant works, the convergence rate of the expected generalization error is in the form of O(sqrt{lambda/n}) where lambda is some information-theoretic quantities such as the mutual information between the data sample and the learned hypothesis. However, such a learning rate is typically considered to be "slow", compared to a "fast rate" of O(1/n) in many learning scenarios. In this work, we first show that the square root does not necessarily imply a slow rate, and a fast rate (O(1/n)) result can still be obtained using this bound under appropriate assumptions. Furthermore, we identify the key conditions needed for the fast rate generalization error, which we call the (eta,c)-central condition. Under this condition, we give information-theoretic bounds on the generalization error and excess risk, with a convergence rate of O(\lambda/{n}) for specific learning algorithms such as empirical risk minimization. Finally, analytical examples are given to show the effectiveness of the bounds.
TunaOil: A Tuning Algorithm Strategy for Reservoir Simulation Workloads
Aug 04, 2022
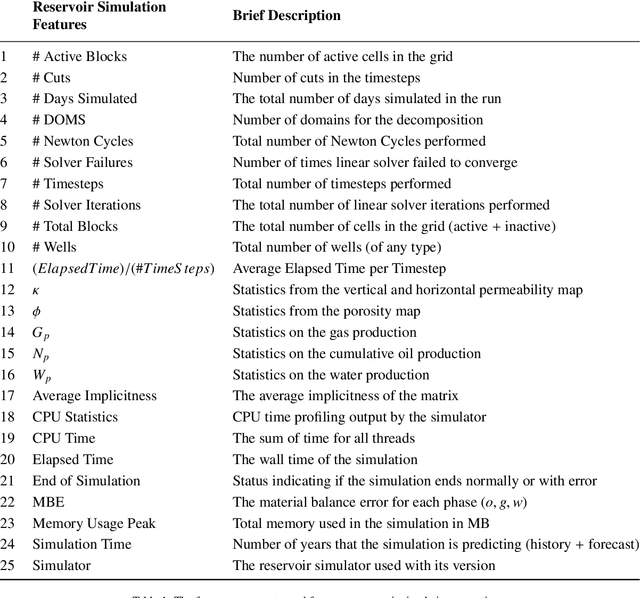
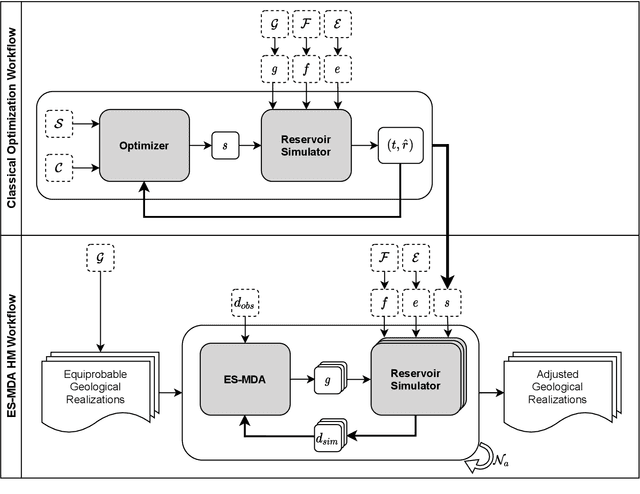
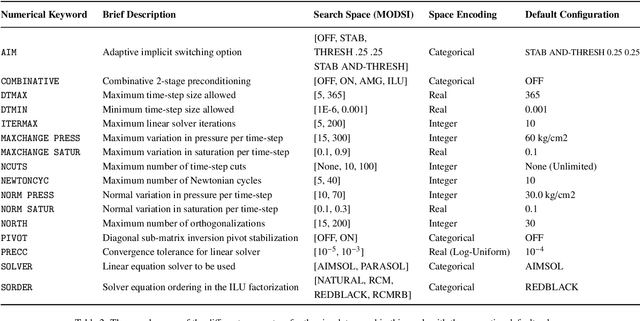
Reservoir simulations for petroleum fields and seismic imaging are known as the most demanding workloads for high-performance computing (HPC) in the oil and gas (O&G) industry. The optimization of the simulator numerical parameters plays a vital role as it could save considerable computational efforts. State-of-the-art optimization techniques are based on running numerous simulations, specific for that purpose, to find good parameter candidates. However, using such an approach is highly costly in terms of time and computing resources. This work presents TunaOil, a new methodology to enhance the search for optimal numerical parameters of reservoir flow simulations using a performance model. In the O&G industry, it is common to use ensembles of models in different workflows to reduce the uncertainty associated with forecasting O&G production. We leverage the runs of those ensembles in such workflows to extract information from each simulation and optimize the numerical parameters in their subsequent runs. To validate the methodology, we implemented it in a history matching (HM) process that uses a Kalman filter algorithm to adjust an ensemble of reservoir models to match the observed data from the real field. We mine past execution logs from many simulations with different numerical configurations and build a machine learning model based on extracted features from the data. These features include properties of the reservoir models themselves, such as the number of active cells, to statistics of the simulation's behavior, such as the number of iterations of the linear solver. A sampling technique is used to query the oracle to find the numerical parameters that can reduce the elapsed time without significantly impacting the quality of the results. Our experiments show that the predictions can improve the overall HM workflow runtime on average by 31%.
MIA 2022 Shared Task: Evaluating Cross-lingual Open-Retrieval Question Answering for 16 Diverse Languages
Jul 02, 2022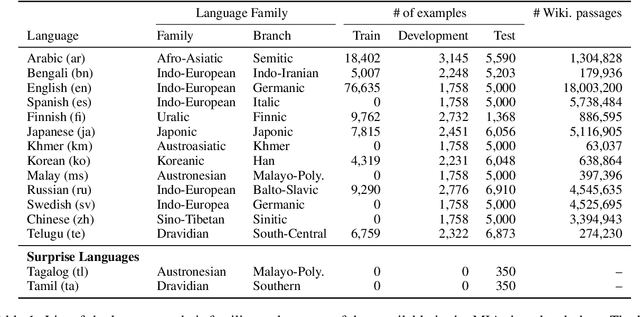
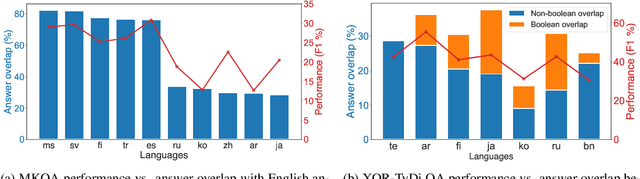
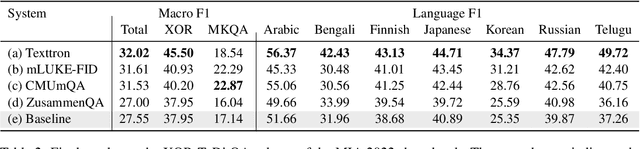
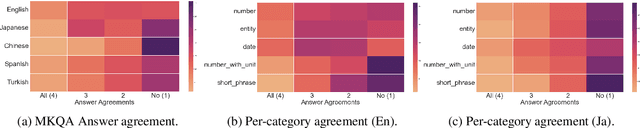
We present the results of the Workshop on Multilingual Information Access (MIA) 2022 Shared Task, evaluating cross-lingual open-retrieval question answering (QA) systems in 16 typologically diverse languages. In this task, we adapted two large-scale cross-lingual open-retrieval QA datasets in 14 typologically diverse languages, and newly annotated open-retrieval QA data in 2 underrepresented languages: Tagalog and Tamil. Four teams submitted their systems. The best system leveraging iteratively mined diverse negative examples and larger pretrained models achieves 32.2 F1, outperforming our baseline by 4.5 points. The second best system uses entity-aware contextualized representations for document retrieval, and achieves significant improvements in Tamil (20.8 F1), whereas most of the other systems yield nearly zero scores.
DeepRecon: Joint 2D Cardiac Segmentation and 3D Volume Reconstruction via A Structure-Specific Generative Method
Jun 14, 2022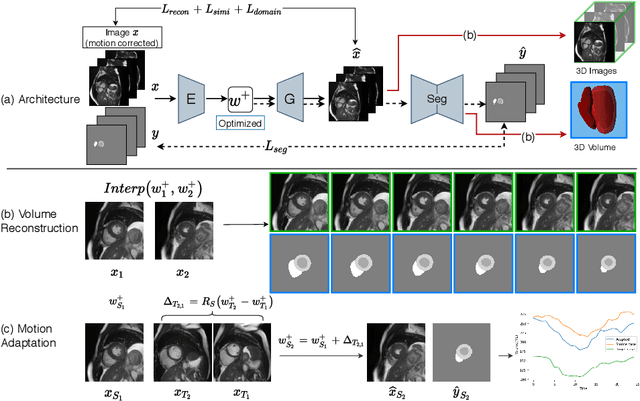
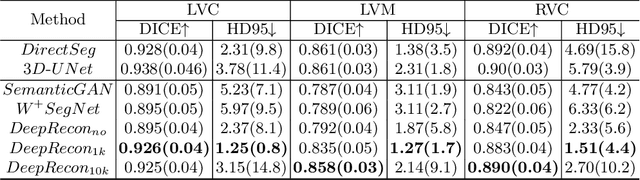
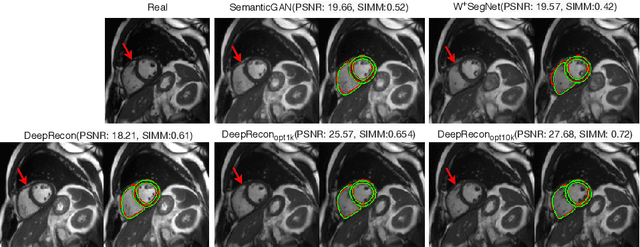
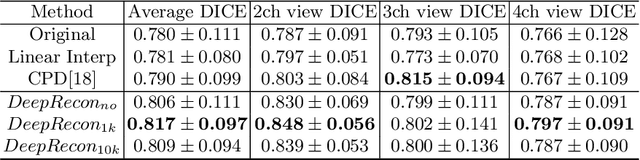
Joint 2D cardiac segmentation and 3D volume reconstruction are fundamental to building statistical cardiac anatomy models and understanding functional mechanisms from motion patterns. However, due to the low through-plane resolution of cine MR and high inter-subject variance, accurately segmenting cardiac images and reconstructing the 3D volume are challenging. In this study, we propose an end-to-end latent-space-based framework, DeepRecon, that generates multiple clinically essential outcomes, including accurate image segmentation, synthetic high-resolution 3D image, and 3D reconstructed volume. Our method identifies the optimal latent representation of the cine image that contains accurate semantic information for cardiac structures. In particular, our model jointly generates synthetic images with accurate semantic information and segmentation of the cardiac structures using the optimal latent representation. We further explore downstream applications of 3D shape reconstruction and 4D motion pattern adaptation by the different latent-space manipulation strategies.The simultaneously generated high-resolution images present a high interpretable value to assess the cardiac shape and motion.Experimental results demonstrate the effectiveness of our approach on multiple fronts including 2D segmentation, 3D reconstruction, downstream 4D motion pattern adaption performance.
Using Graph Neural Networks for Program Termination
Jul 28, 2022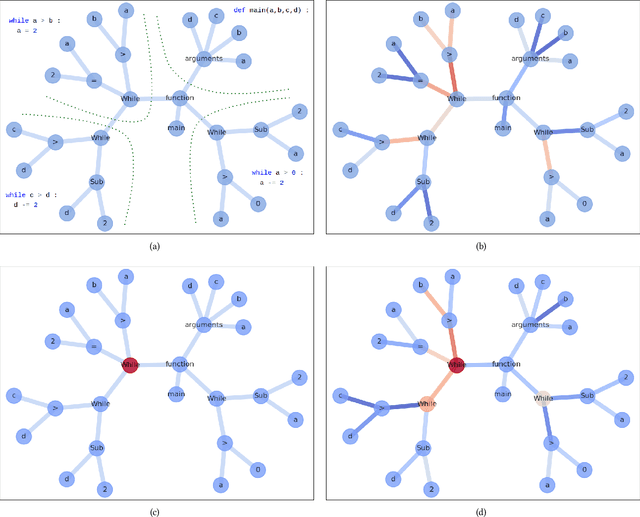
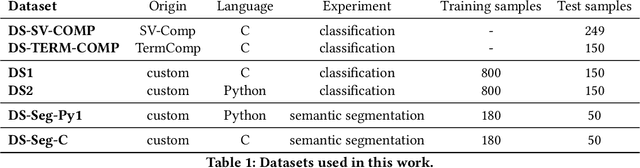
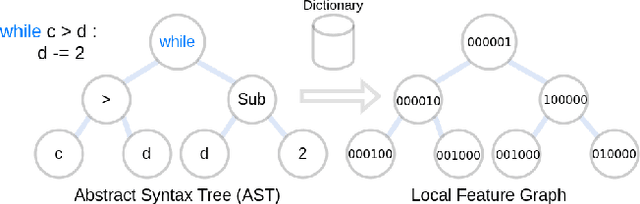
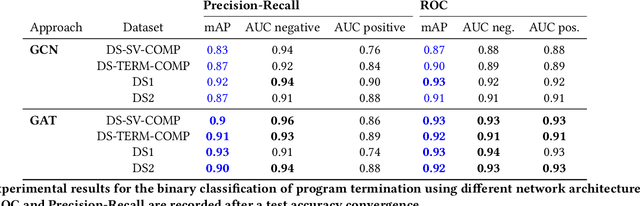
Termination analyses investigate the termination behavior of programs, intending to detect nontermination, which is known to cause a variety of program bugs (e.g. hanging programs, denial-of-service vulnerabilities). Beyond formal approaches, various attempts have been made to estimate the termination behavior of programs using neural networks. However, the majority of these approaches continue to rely on formal methods to provide strong soundness guarantees and consequently suffer from similar limitations. In this paper, we move away from formal methods and embrace the stochastic nature of machine learning models. Instead of aiming for rigorous guarantees that can be interpreted by solvers, our objective is to provide an estimation of a program's termination behavior and of the likely reason for nontermination (when applicable) that a programmer can use for debugging purposes. Compared to previous approaches using neural networks for program termination, we also take advantage of the graph representation of programs by employing Graph Neural Networks. To further assist programmers in understanding and debugging nontermination bugs, we adapt the notions of attention and semantic segmentation, previously used for other application domains, to programs. Overall, we designed and implemented classifiers for program termination based on Graph Convolutional Networks and Graph Attention Networks, as well as a semantic segmentation Graph Neural Network that localizes AST nodes likely to cause nontermination. We also illustrated how the information provided by semantic segmentation can be combined with program slicing to further aid debugging.
Transfer Learning in Information Criteria-based Feature Selection
Jul 06, 2021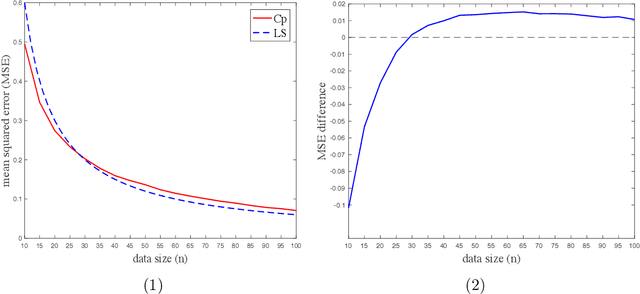
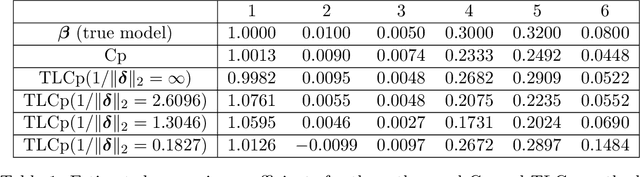
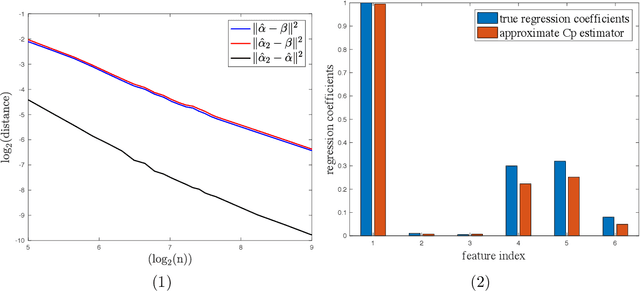
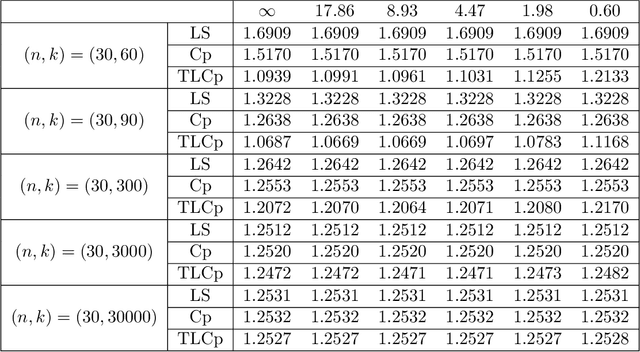
This paper investigates the effectiveness of transfer learning based on Mallows' Cp. We propose a procedure that combines transfer learning with Mallows' Cp (TLCp) and prove that it outperforms the conventional Mallows' Cp criterion in terms of accuracy and stability. Our theoretical results indicate that, for any sample size in the target domain, the proposed TLCp estimator performs better than the Cp estimator by the mean squared error (MSE) metric in the case of orthogonal predictors, provided that i) the dissimilarity between the tasks from source domain and target domain is small, and ii) the procedure parameters (complexity penalties) are tuned according to certain explicit rules. Moreover, we show that our transfer learning framework can be extended to other feature selection criteria, such as the Bayesian information criterion. By analyzing the solution of the orthogonalized Cp, we identify an estimator that asymptotically approximates the solution of the Cp criterion in the case of non-orthogonal predictors. Similar results are obtained for the non-orthogonal TLCp. Finally, simulation studies and applications with real data demonstrate the usefulness of the TLCp scheme.
Learning to Query Internet Text for Informing Reinforcement Learning Agents
May 25, 2022
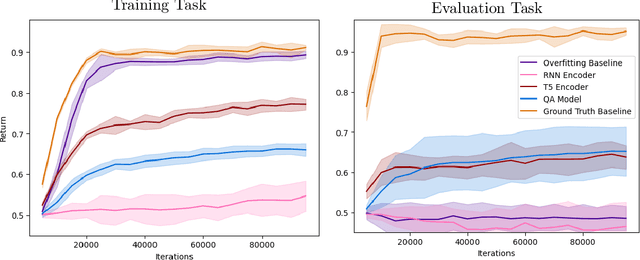

Generalization to out of distribution tasks in reinforcement learning is a challenging problem. One successful approach improves generalization by conditioning policies on task or environment descriptions that provide information about the current transition or reward functions. Previously, these descriptions were often expressed as generated or crowd sourced text. In this work, we begin to tackle the problem of extracting useful information from natural language found in the wild (e.g. internet forums, documentation, and wikis). These natural, pre-existing sources are especially challenging, noisy, and large and present novel challenges compared to previous approaches. We propose to address these challenges by training reinforcement learning agents to learn to query these sources as a human would, and we experiment with how and when an agent should query. To address the \textit{how}, we demonstrate that pretrained QA models perform well at executing zero-shot queries in our target domain. Using information retrieved by a QA model, we train an agent to learn \textit{when} it should execute queries. We show that our method correctly learns to execute queries to maximize reward in a reinforcement learning setting.
Unsupervised Frequent Pattern Mining for CEP
Jul 28, 2022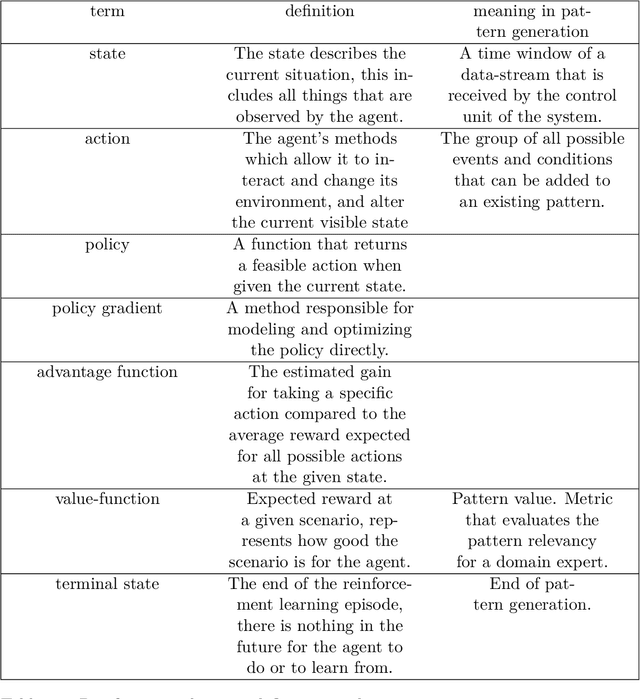
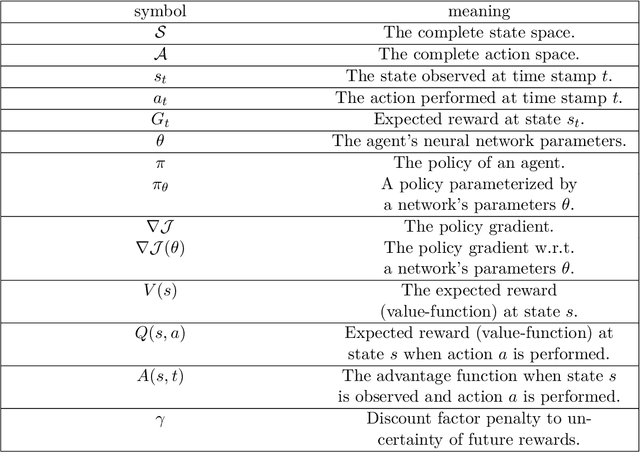
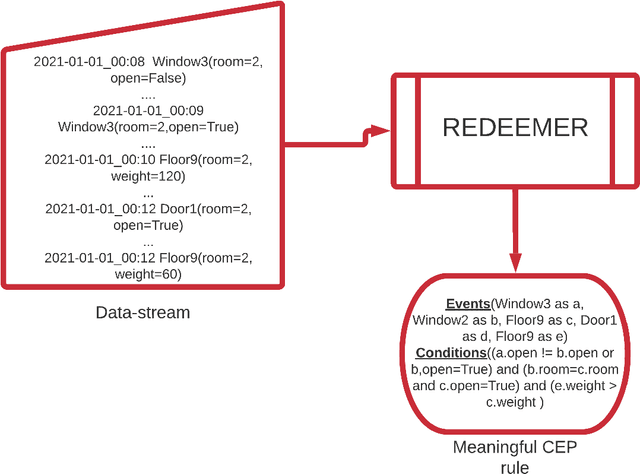
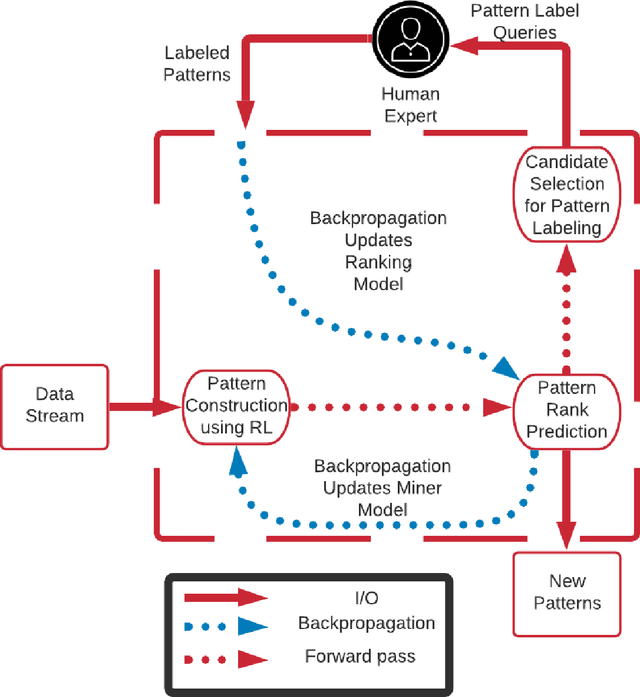
Complex Event Processing (CEP) is a set of methods that allow efficient knowledge extraction from massive data streams using complex and highly descriptive patterns. Numerous applications, such as online finance, healthcare monitoring and fraud detection use CEP technologies to capture critical alerts, potential threats, or vital notifications in real time. As of today, in many fields, patterns are manually defined by human experts. However, desired patterns often contain convoluted relations that are difficult for humans to detect, and human expertise is scarce in many domains. We present REDEEMER (REinforcement baseD cEp pattErn MinER), a novel reinforcement and active learning approach aimed at mining CEP patterns that allow expansion of the knowledge extracted while reducing the human effort required. This approach includes a novel policy gradient method for vast multivariate spaces and a new way to combine reinforcement and active learning for CEP rule learning while minimizing the number of labels needed for training. REDEEMER aims to enable CEP integration in domains that could not utilize it before. To the best of our knowledge, REDEEMER is the first system that suggests new CEP rules that were not observed beforehand, and is the first method aimed for increasing pattern knowledge in fields where experts do not possess sufficient information required for CEP tools. Our experiments on diverse data-sets demonstrate that REDEEMER is able to extend pattern knowledge while outperforming several state-of-the-art reinforcement learning methods for pattern mining.
Physics Embedded Neural Network Vehicle Model and Applications in Risk-Aware Autonomous Driving Using Latent Features
Jul 16, 2022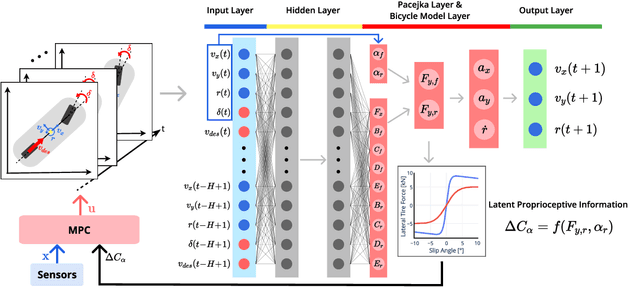
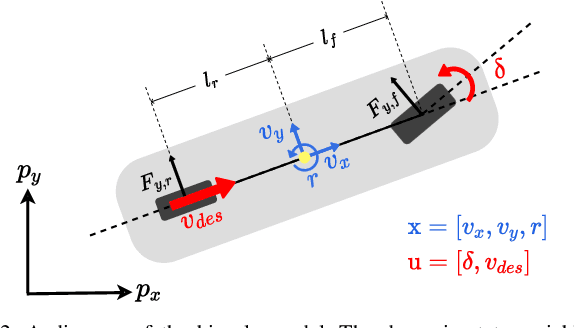
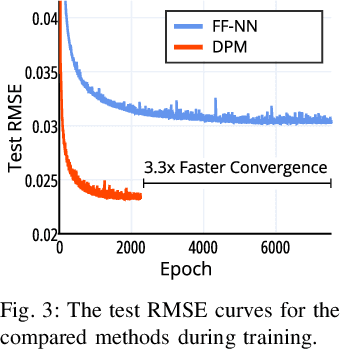
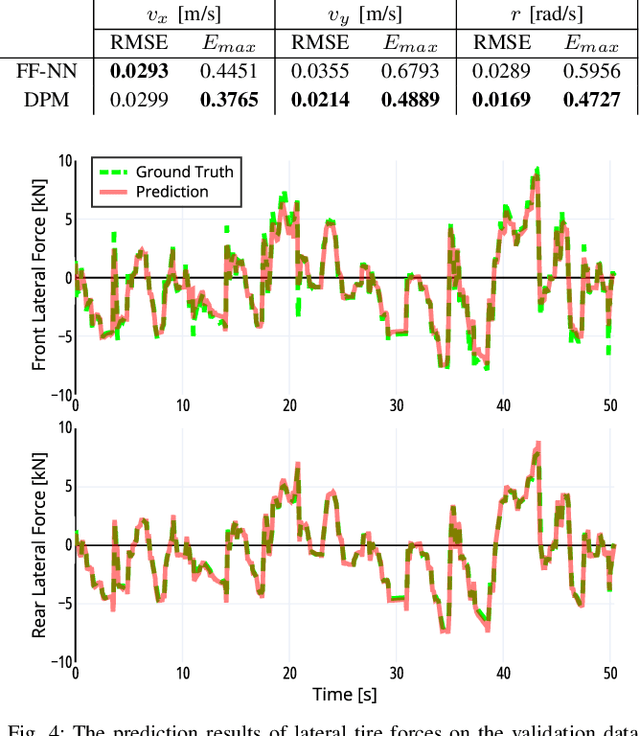
Non-holonomic vehicle motion has been studied extensively using physics-based models. Common approaches when using these models interpret the wheel/ground interactions using a linear tire model and thus may not fully capture the nonlinear and complex dynamics under various environments. On the other hand, neural network models have been widely employed in this domain, demonstrating powerful function approximation capabilities. However, these black-box learning strategies completely abandon the existing knowledge of well-known physics. In this paper, we seamlessly combine deep learning with a fully differentiable physics model to endow the neural network with available prior knowledge. The proposed model shows better generalization performance than the vanilla neural network model by a large margin. We also show that the latent features of our model can accurately represent lateral tire forces without the need for any additional training. Lastly, We develop a risk-aware model predictive controller using proprioceptive information derived from the latent features. We validate our idea in two autonomous driving tasks under unknown friction, outperforming the baseline control framework.
FiLM: Frequency improved Legendre Memory Model for Long-term Time Series Forecasting
May 18, 2022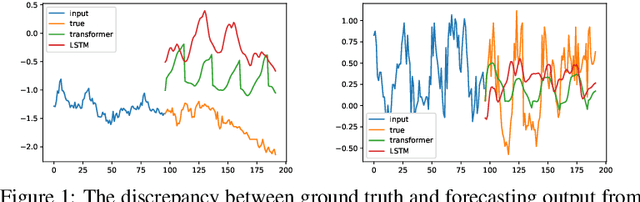
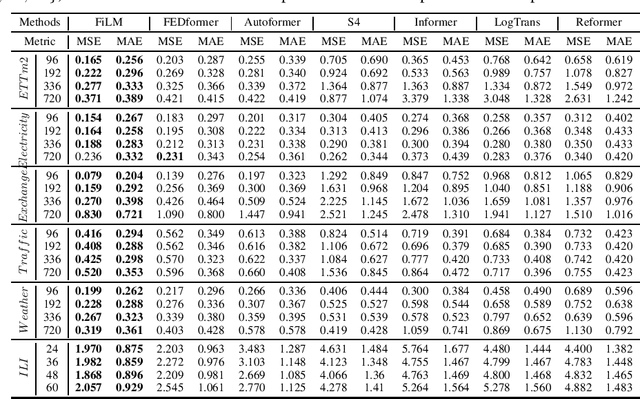
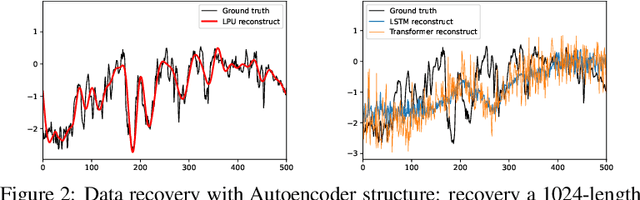
Recent studies have shown the promising performance of deep learning models (e.g., RNN and Transformer) for long-term time series forecasting. These studies mostly focus on designing deep models to effectively combine historical information for long-term forecasting. However, the question of how to effectively represent historical information for long-term forecasting has not received enough attention, limiting our capacity to exploit powerful deep learning models. The main challenge in time series representation is how to handle the dilemma between accurately preserving historical information and reducing the impact of noisy signals in the past. To this end, we design a \textbf{F}requency \textbf{i}mproved \textbf{L}egendre \textbf{M}emory model, or {\bf FiLM} for short: it introduces Legendre Polynomial projections to preserve historical information accurately and Fourier projections plus low-rank approximation to remove noisy signals. Our empirical studies show that the proposed FiLM improves the accuracy of state-of-the-art models by a significant margin (\textbf{19.2\%}, \textbf{22.6\%}) in multivariate and univariate long-term forecasting, respectively. In addition, dimensionality reduction introduced by low-rank approximation leads to a dramatic improvement in computational efficiency. We also demonstrate that the representation module developed in this work can be used as a general plug-in to improve the performance of most deep learning modules for long-term forecasting. Code will be released soon