 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spectral Bias Outside the Training Set for Deep Networks in the Kernel Regime
Jun 06, 2022

We provide quantitative bounds measuring the $L^2$ difference in function space between the trajectory of a finite-width network trained on finitely many samples from the idealized kernel dynamics of infinite width and infinite data. An implication of the bounds is that the network is biased to learn the top eigenfunctions of the Neural Tangent Kernel not just on the training set but over the entire input space. This bias depends on the model architecture and input distribution alone and thus does not depend on the target function which does not need to be in the RKHS of the kernel. The result is valid for deep architectures with fully connected, convolutional, and residual layers. Furthermore the width does not need to grow polynomially with the number of samples in order to obtain high probability bounds up to a stopping time. The proof exploits the low-effective-rank property of the Fisher Information Matrix at initialization, which implies a low effective dimension of the model (far smaller than the number of parameters). We conclude that local capacity control from the low effective rank of the Fisher Information Matrix is still underexplored theoretically.
Probability trees and the value of a single intervention
May 18, 2022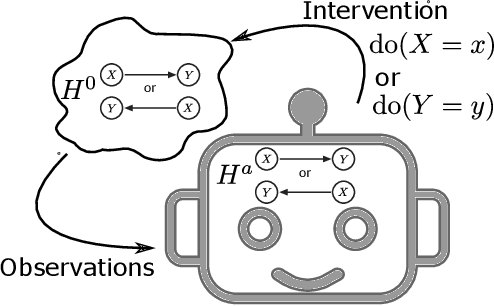
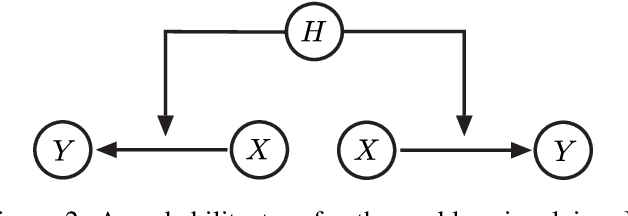
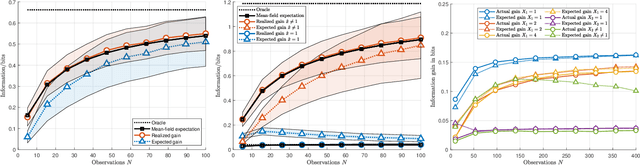
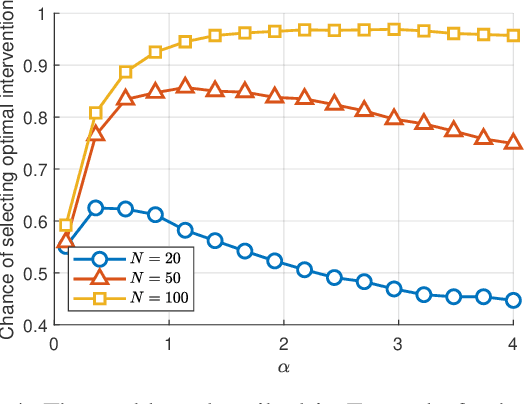
The most fundamental problem in statistical causality is determining causal relationships from limited data. Probability trees, which combine prior causal structures with Bayesian updates, have been suggested as a possible solution. In this work, we quantify the information gain from a single intervention and show that both the anticipated information gain, prior to making an intervention, and the expected gain from an intervention have simple expressions. This results in an active-learning method that simply selects the intervention with the highest anticipated gain, which we illustrate through several examples. Our work demonstrates how probability trees, and Bayesian estimation of their parameters, offer a simple yet viable approach to fast causal induction.
Hard Attention Control By Mutual Information Maximization
Mar 10, 2021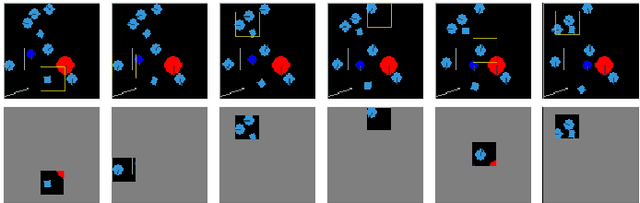

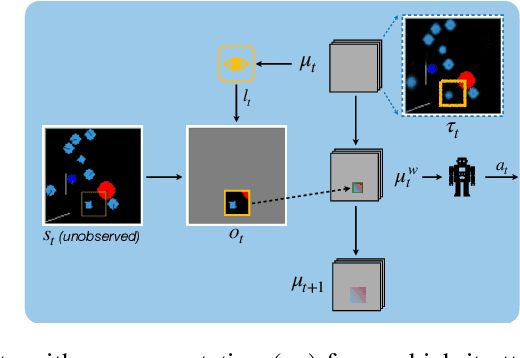
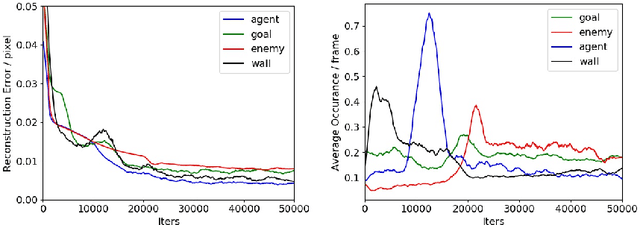
Biological agents have adopted the principle of attention to limit the rate of incoming information from the environment. One question that arises is if an artificial agent has access to only a limited view of its surroundings, how can it control its attention to effectively solve tasks? We propose an approach for learning how to control a hard attention window by maximizing the mutual information between the environment state and the attention location at each step. The agent employs an internal world model to make predictions about its state and focuses attention towards where the predictions may be wrong. Attention is trained jointly with a dynamic memory architecture that stores partial observations and keeps track of the unobserved state. We demonstrate that our approach is effective in predicting the full state from a sequence of partial observations. We also show that the agent's internal representation of the surroundings, a live mental map, can be used for control in two partially observable reinforcement learning tasks. Videos of the trained agent can be found at https://sites.google.com/view/hard-attention-control.
Anomaly-aware multiple instance learning for rare anemia disorder classification
Jul 04, 2022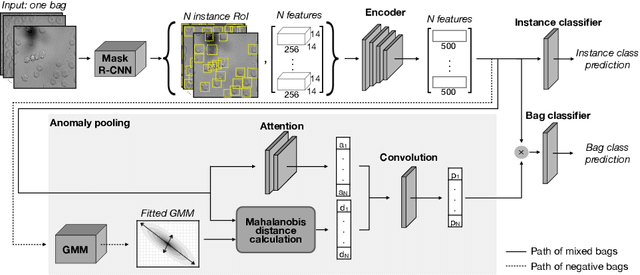

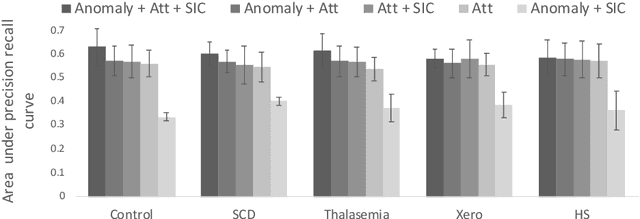
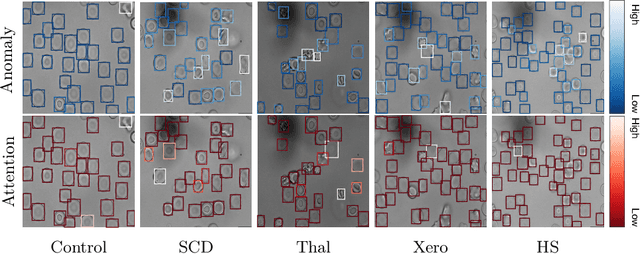
Deep learning-based classification of rare anemia disorders is challenged by the lack of training data and instance-level annotations. Multiple Instance Learning (MIL) has shown to be an effective solution, yet it suffers from low accuracy and limited explainability. Although the inclusion of attention mechanisms has addressed these issues, their effectiveness highly depends on the amount and diversity of cells in the training samples. Consequently, the poor machine learning performance on rare anemia disorder classification from blood samples remains unresolved. In this paper, we propose an interpretable pooling method for MIL to address these limitations. By benefiting from instance-level information of negative bags (i.e., homogeneous benign cells from healthy individuals), our approach increases the contribution of anomalous instances. We show that our strategy outperforms standard MIL classification algorithms and provides a meaningful explanation behind its decisions. Moreover, it can denote anomalous instances of rare blood diseases that are not seen during the training phase.
A Correlation-Ratio Transfer Learning and Variational Stein's Paradox
Jun 10, 2022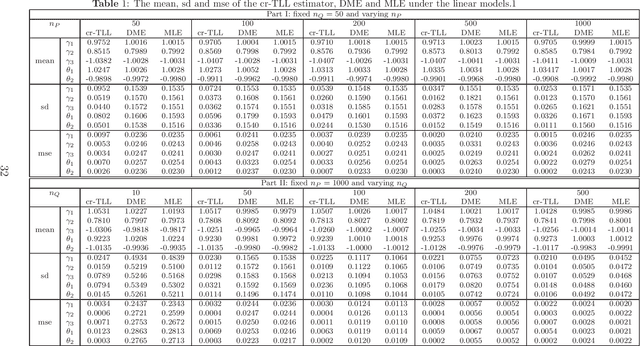
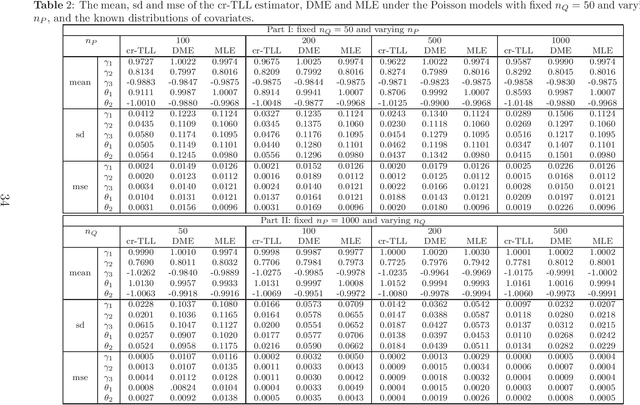
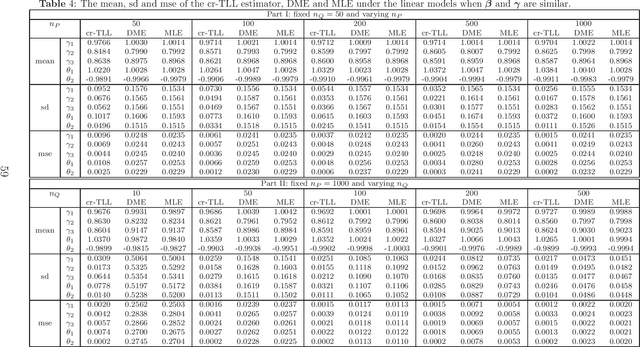
A basic condition for efficient transfer learning is the similarity between a target model and source models. In practice, however, the similarity condition is difficult to meet or is even violated. Instead of the similarity condition, a brand-new strategy, linear correlation-ratio, is introduced in this paper to build an accurate relationship between the models. Such a correlation-ratio can be easily estimated by historical data or a part of sample. Then, a correlation-ratio transfer learning likelihood is established based on the correlation-ratio combination. On the practical side, the new framework is applied to some application scenarios, especially the areas of data streams and medical studies. Methodologically, some techniques are suggested for transferring the information from simple source models to a relatively complex target model. Theoretically, some favorable properties, including the global convergence rate, are achieved, even for the case where the source models are not similar to the target model. All in all, it can be seen from the theories and experimental results that the inference on the target model is significantly improved by the information from similar or dissimilar source models. In other words, a variational Stein's paradox is illustrated in the context of transfer learning.
Big Learning: A Universal Machine Learning Paradigm?
Jul 08, 2022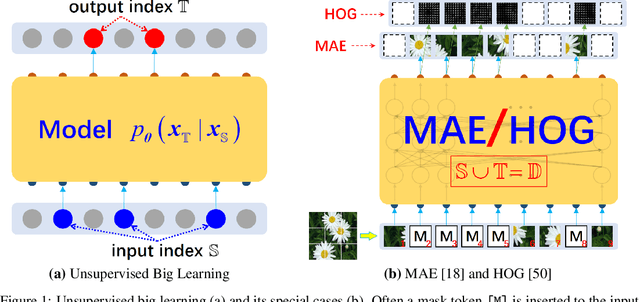

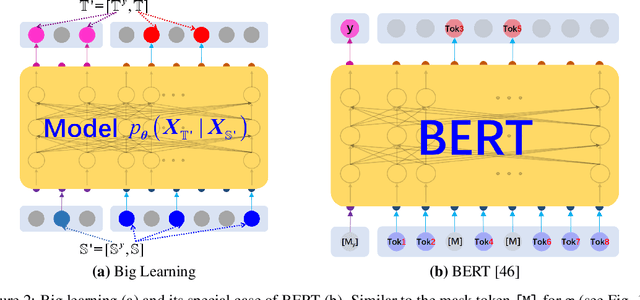

Recent breakthroughs based on big/foundation models reveal a vague avenue for artificial intelligence, that is, bid data, big/foundation models, big learning, $\cdots$. Following that avenue, here we elaborate on the newly introduced big learning. Specifically, big learning comprehensively exploits the available information inherent in large-scale complete/incomplete data, by simultaneously learning to model many-to-all joint/conditional/marginal data distributions (thus named big learning) with one universal foundation model. We reveal that big learning is what existing foundation models are implicitly doing; accordingly, our big learning provides high-level guidance for flexible design and improvements of foundation models, accelerating the true self-learning on the Internet. Besides, big learning ($i$) is equipped with marvelous flexibility for both training data and training-task customization; ($ii$) potentially delivers all joint/conditional/marginal data capabilities after training; ($iii$) significantly reduces the training-test gap with improved model generalization; and ($iv$) unifies conventional machine learning paradigms e.g. supervised learning, unsupervised learning, generative learning, etc. and enables their flexible cooperation, manifesting a universal learning paradigm.
Transport-Oriented Feature Aggregation for Speaker Embedding Learning
Jun 26, 2022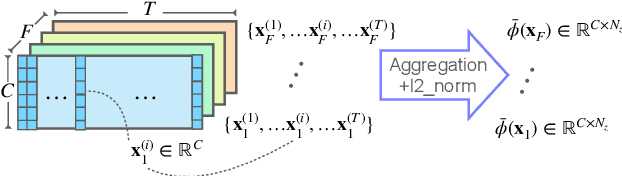

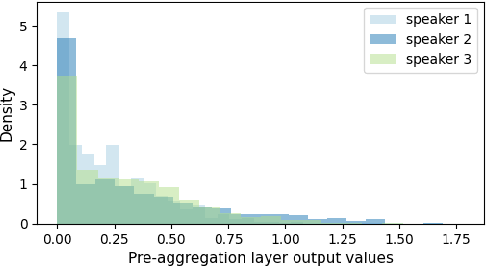
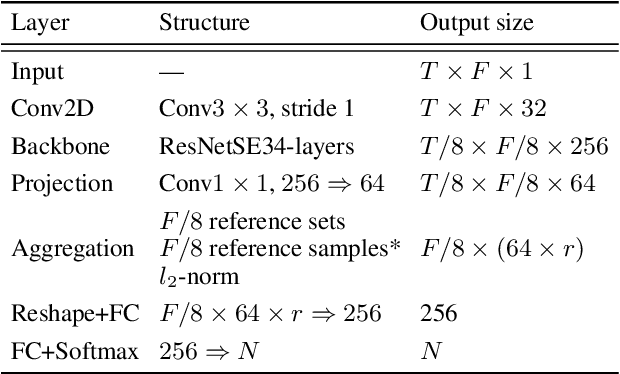
Pooling is needed to aggregate frame-level features into utterance-level representations for speaker modeling. Given the success of statistics-based pooling methods, we hypothesize that speaker characteristics are well represented in the statistical distribution over the pre-aggregation layer's output, and propose to use transport-oriented feature aggregation for deriving speaker embeddings. The aggregated representation encodes the geometric structure of the underlying feature distribution, which is expected to contain valuable speaker-specific information that may not be represented by the commonly used statistical measures like mean and variance. The original transport-oriented feature aggregation is also extended to a weighted-frame version to incorporate the attention mechanism. Experiments on speaker verification with the Voxceleb dataset show improvement over statistics pooling and its attentive variant.
From Rewriting to Remembering: Common Ground for Conversational QA Models
Apr 08, 2022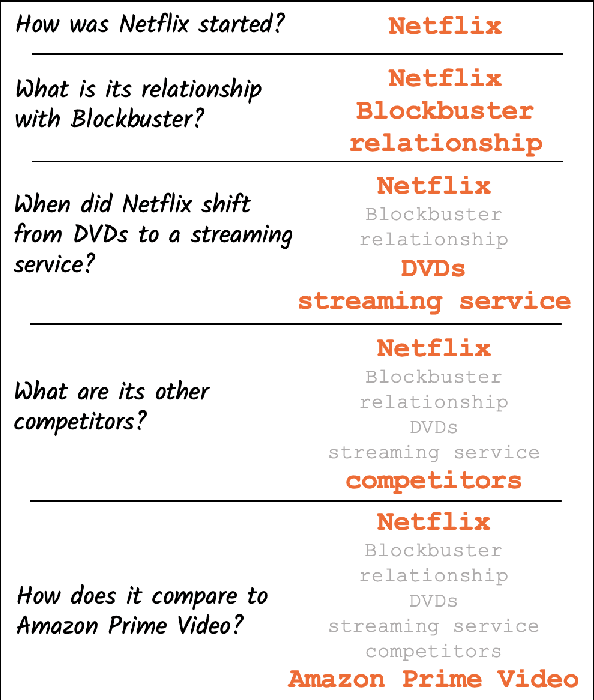
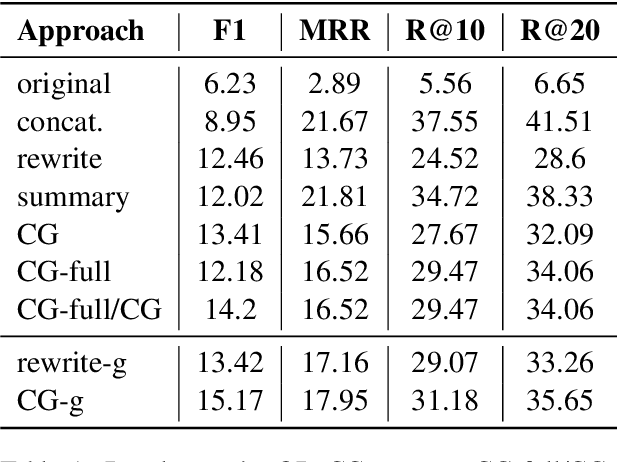


In conversational QA, models have to leverage information in previous turns to answer upcoming questions. Current approaches, such as Question Rewriting, struggle to extract relevant information as the conversation unwinds. We introduce the Common Ground (CG), an approach to accumulate conversational information as it emerges and select the relevant information at every turn. We show that CG offers a more efficient and human-like way to exploit conversational information compared to existing approaches, leading to improvements on Open Domain Conversational QA.
The scope for AI-augmented interpretation of building blueprints in commercial and industrial property insurance
May 05, 2022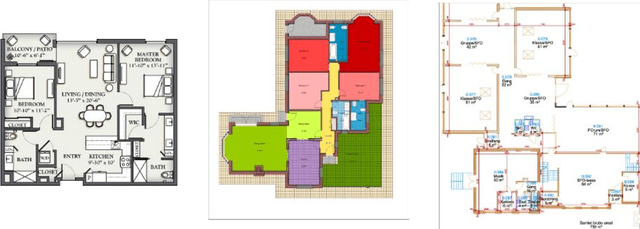
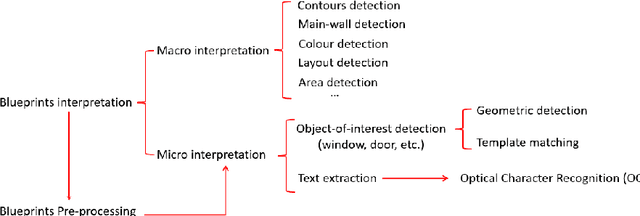

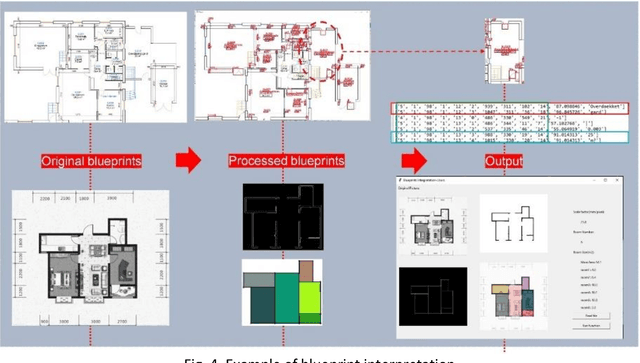
This report, commissioned by the WTW research network, investigates the use of AI in property risk assessment. It (i) reviews existing work on risk assessment in commercial and industrial properties and automated information extraction from building blueprints; and (ii) presents an exploratory 'proof-of concept-solution' exploring the feasibility of using machine learning for the automated extraction of information from building blueprints to support insurance risk assessment.
Behind the Mask: Demographic bias in name detection for PII masking
May 09, 2022
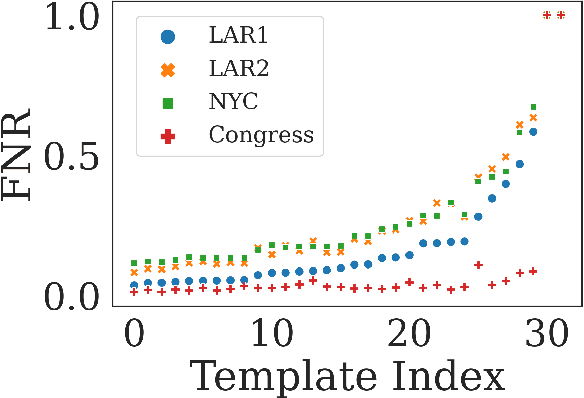
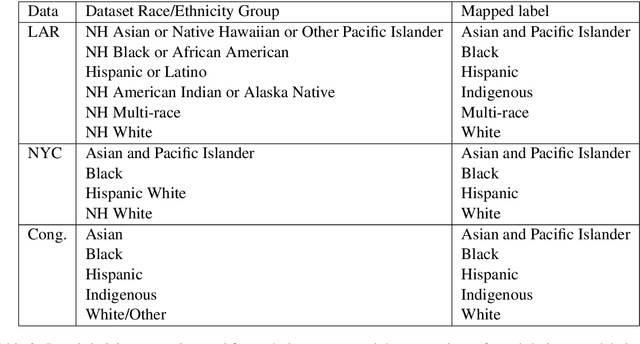
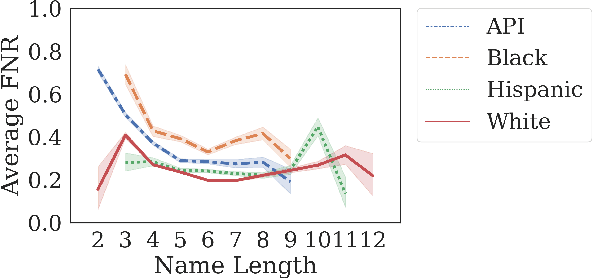
Many datasets contain personally identifiable information, or PII, which poses privacy risks to individuals. PII masking is commonly used to redact personal information such as names, addresses, and phone numbers from text data. Most modern PII masking pipelines involve machine learning algorithms. However, these systems may vary in performance, such that individuals from particular demographic groups bear a higher risk for having their personal information exposed. In this paper, we evaluate the performance of three off-the-shelf PII masking systems on name detection and redaction. We generate data using names and templates from the customer service domain. We find that an open-source RoBERTa-based system shows fewer disparities than the commercial models we test. However, all systems demonstrate significant differences in error rate based on demographics. In particular, the highest error rates occurred for names associated with Black and Asian/Pacific Islander individuals.