 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Transfer functions of FXLMS-based Multi-channel Multi-tone Active Noise Equalizers
Jul 03, 2022
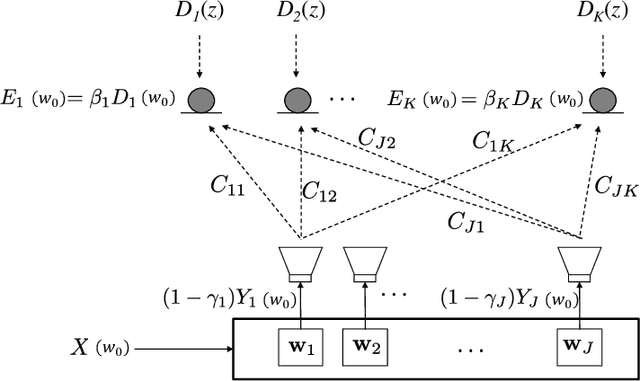
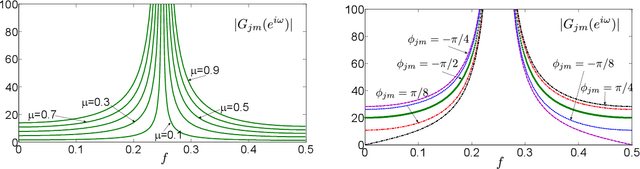
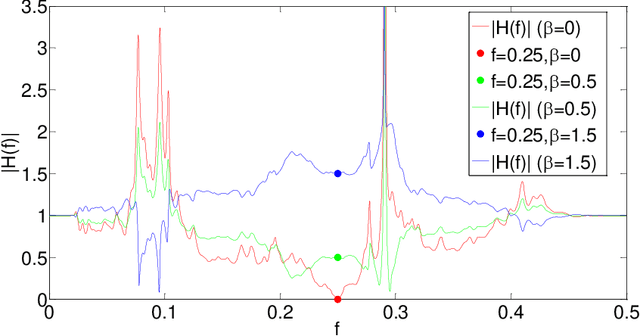
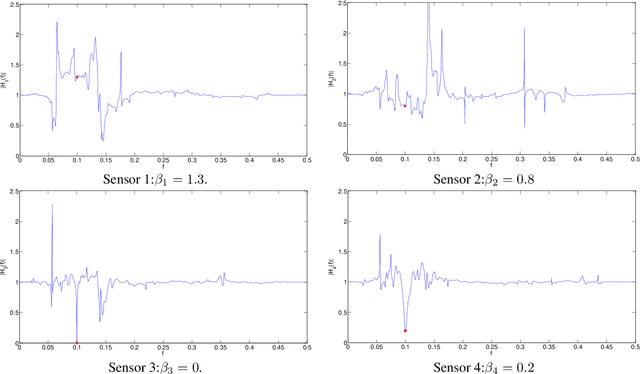
Multi-channel Multi-tone Active Noise Equalizers can achieve different user-selected noise spectrum profiles even at different space positions. They can apply a different equalization factor at each noise frequency component and each control point. Theoretically, the value of the transfer function at the frequencies where the noise signal has energy is determined by the equalizer configuration. In this work, we show how to calculate these transfer functions with a double aim: to verify that at the frequencies of interest the values imposed by the equalizer settings are obtained, and to characterize the behavior of these transfer functions in the rest of the spectrum, as well as to get clues to predict the convergence behaviour of the algorithm. The information provided thanks to these transfer functions serves as a practical alternative to the cumbersome statistical analysis of convergence, whose results are often of no practical use.
Weakly Supervised Object Localization via Transformer with Implicit Spatial Calibration
Jul 21, 2022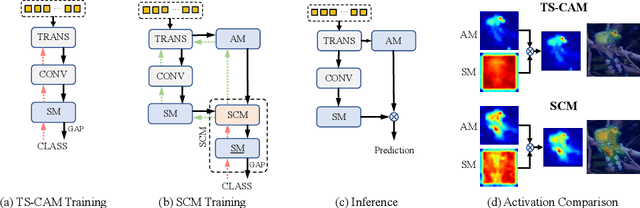
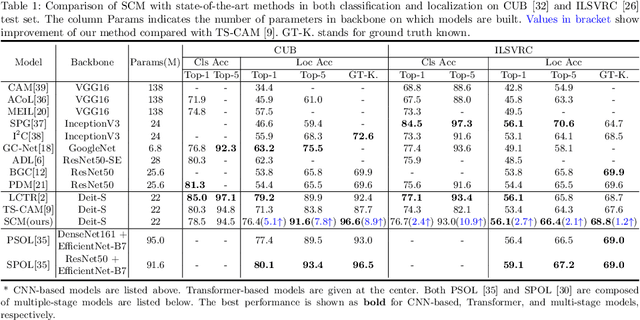
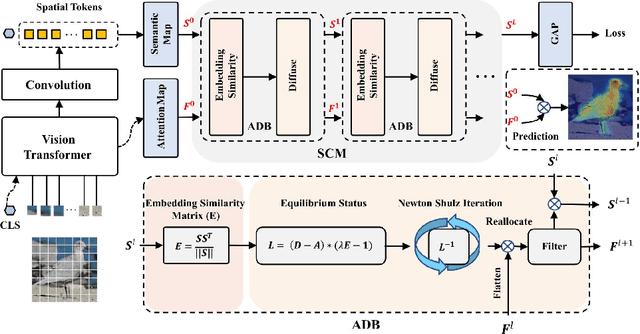
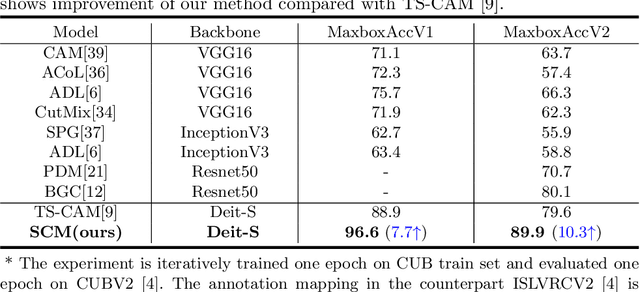
Weakly Supervised Object Localization (WSOL), which aims to localize objects by only using image-level labels, has attracted much attention because of its low annotation cost in real applications. Recent studies leverage the advantage of self-attention in visual Transformer for long-range dependency to re-active semantic regions, aiming to avoid partial activation in traditional class activation mapping (CAM). However, the long-range modeling in Transformer neglects the inherent spatial coherence of the object, and it usually diffuses the semantic-aware regions far from the object boundary, making localization results significantly larger or far smaller. To address such an issue, we introduce a simple yet effective Spatial Calibration Module (SCM) for accurate WSOL, incorporating semantic similarities of patch tokens and their spatial relationships into a unified diffusion model. Specifically, we introduce a learnable parameter to dynamically adjust the semantic correlations and spatial context intensities for effective information propagation. In practice, SCM is designed as an external module of Transformer, and can be removed during inference to reduce the computation cost. The object-sensitive localization ability is implicitly embedded into the Transformer encoder through optimization in the training phase. It enables the generated attention maps to capture the sharper object boundaries and filter the object-irrelevant background area. Extensive experimental results demonstrate the effectiveness of the proposed method, which significantly outperforms its counterpart TS-CAM on both CUB-200 and ImageNet-1K benchmarks. The code is available at https://github.com/164140757/SCM.
A hierarchical semantic segmentation framework for computer vision-based bridge damage detection
Jul 18, 2022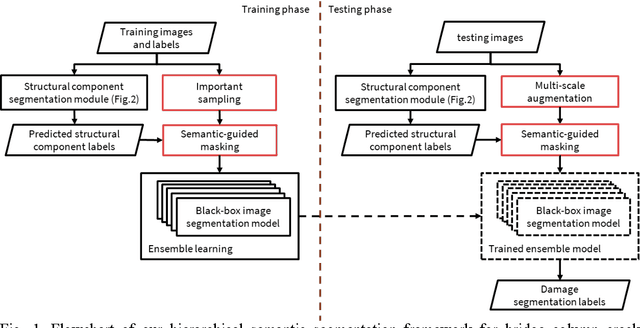
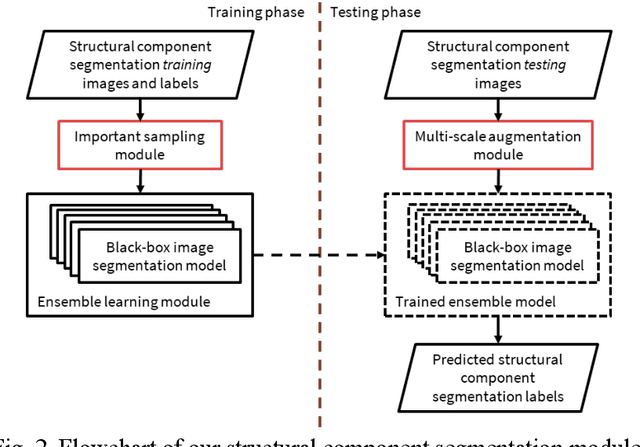


Computer vision-based damage detection using remote cameras and unmanned aerial vehicles (UAVs) enables efficient and low-cost bridge health monitoring that reduces labor costs and the needs for sensor installation and maintenance. By leveraging recent semantic image segmentation approaches, we are able to find regions of critical structural components and recognize damage at the pixel level using images as the only input. However, existing methods perform poorly when detecting small damages (e.g., cracks and exposed rebars) and thin objects with limited image samples, especially when the components of interest are highly imbalanced. To this end, this paper introduces a semantic segmentation framework that imposes the hierarchical semantic relationship between component category and damage types. For example, certain concrete cracks only present on bridge columns and therefore the non-column region will be masked out when detecting such damages. In this way, the damage detection model could focus on learning features from possible damaged regions only and avoid the effects of other irrelevant regions. We also utilize multi-scale augmentation that provides views with different scales that preserves contextual information of each image without losing the ability of handling small and thin objects. Furthermore, the proposed framework employs important sampling that repeatedly samples images containing rare components (e.g., railway sleeper and exposed rebars) to provide more data samples, which addresses the imbalanced data challenge.
Probability trees and the value of a single intervention
May 18, 2022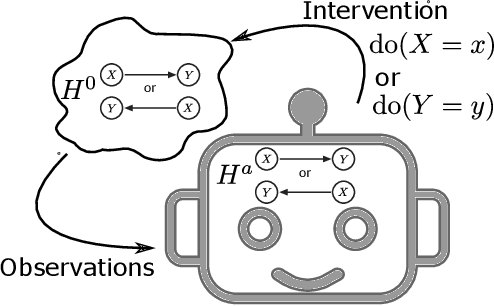
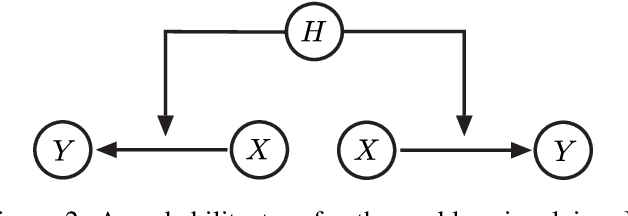
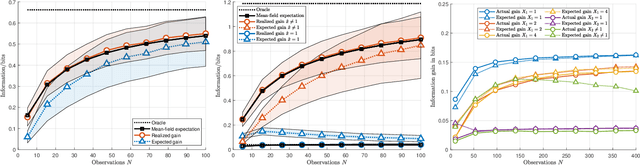
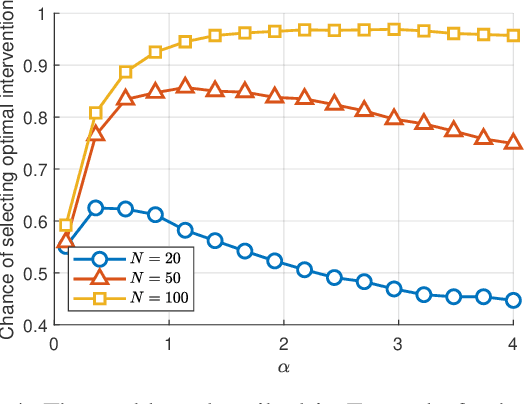
The most fundamental problem in statistical causality is determining causal relationships from limited data. Probability trees, which combine prior causal structures with Bayesian updates, have been suggested as a possible solution. In this work, we quantify the information gain from a single intervention and show that both the anticipated information gain, prior to making an intervention, and the expected gain from an intervention have simple expressions. This results in an active-learning method that simply selects the intervention with the highest anticipated gain, which we illustrate through several examples. Our work demonstrates how probability trees, and Bayesian estimation of their parameters, offer a simple yet viable approach to fast causal induction.
The scope for AI-augmented interpretation of building blueprints in commercial and industrial property insurance
May 05, 2022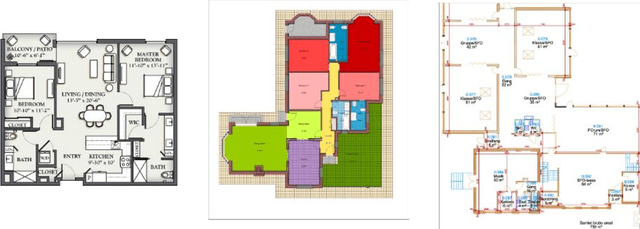
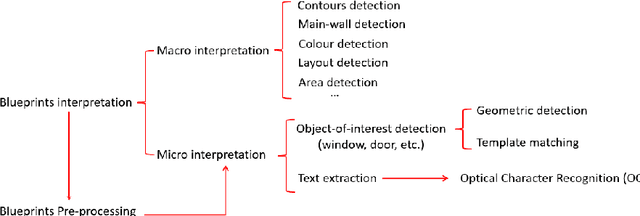

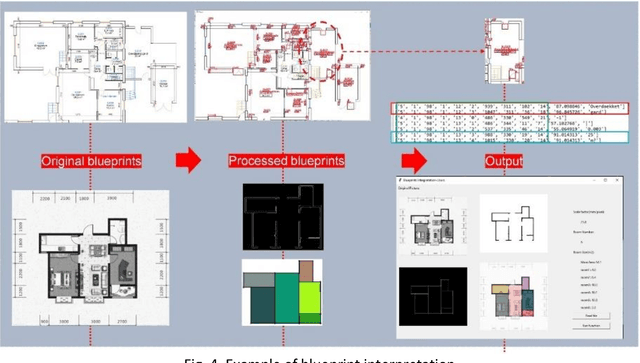
This report, commissioned by the WTW research network, investigates the use of AI in property risk assessment. It (i) reviews existing work on risk assessment in commercial and industrial properties and automated information extraction from building blueprints; and (ii) presents an exploratory 'proof-of concept-solution' exploring the feasibility of using machine learning for the automated extraction of information from building blueprints to support insurance risk assessment.
Bilingual Mutual Information Based Adaptive Training for Neural Machine Translation
May 27, 2021


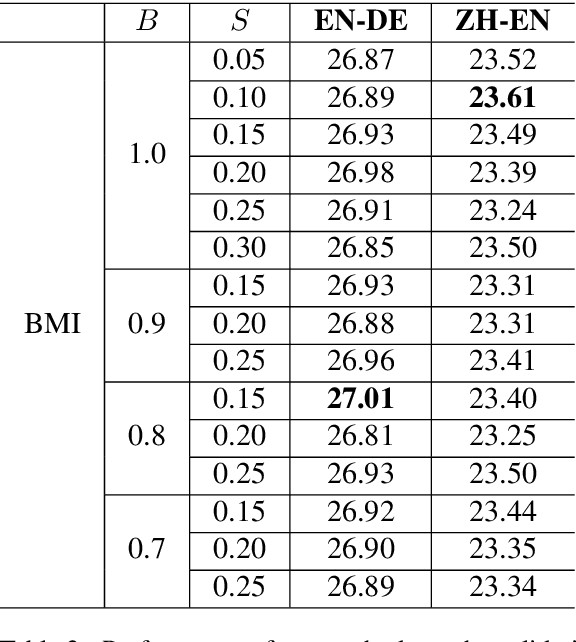
Recently, token-level adaptive training has achieved promising improvement in machine translation, where the cross-entropy loss function is adjusted by assigning different training weights to different tokens, in order to alleviate the token imbalance problem. However, previous approaches only use static word frequency information in the target language without considering the source language, which is insufficient for bilingual tasks like machine translation. In this paper, we propose a novel bilingual mutual information (BMI) based adaptive objective, which measures the learning difficulty for each target token from the perspective of bilingualism, and assigns an adaptive weight accordingly to improve token-level adaptive training. This method assigns larger training weights to tokens with higher BMI, so that easy tokens are updated with coarse granularity while difficult tokens are updated with fine granularity. Experimental results on WMT14 English-to-German and WMT19 Chinese-to-English demonstrate the superiority of our approach compared with the Transformer baseline and previous token-level adaptive training approaches. Further analyses confirm that our method can improve the lexical diversity.
UniCon+: ICTCAS-UCAS Submission to the AVA-ActiveSpeaker Task at ActivityNet Challenge 2022
Jun 22, 2022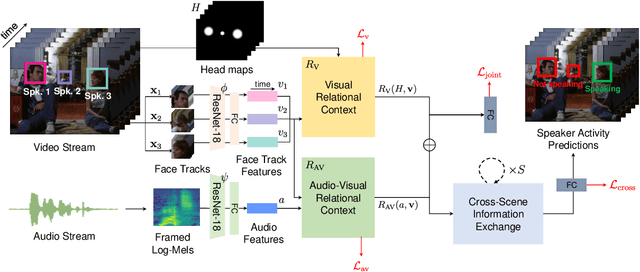
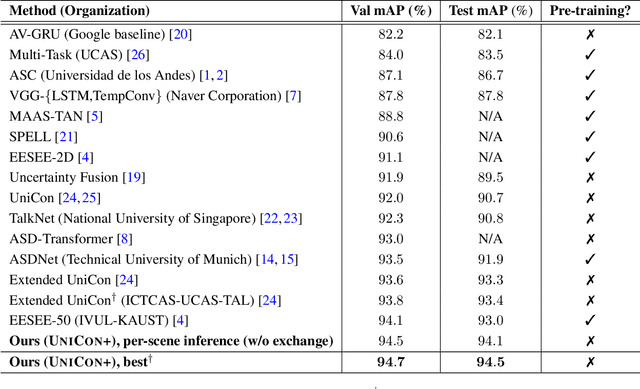
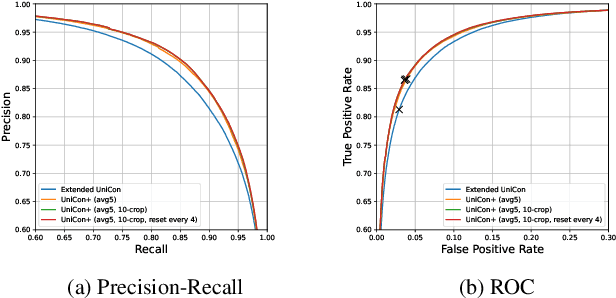
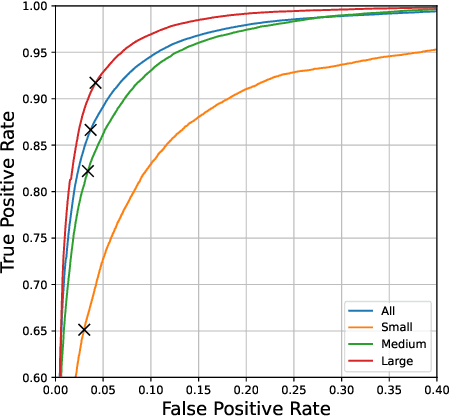
This report presents a brief description of our winning solution to the AVA Active Speaker Detection (ASD) task at ActivityNet Challenge 2022. Our underlying model UniCon+ continues to build on our previous work, the Unified Context Network (UniCon) and Extended UniCon which are designed for robust scene-level ASD. We augment the architecture with a simple GRU-based module that allows information of recurring identities to flow across scenes through read and update operations. We report a best result of 94.47% mAP on the AVA-ActiveSpeaker test set, which continues to rank first on this year's challenge leaderboard and significantly pushes the state-of-the-art.
Behind the Mask: Demographic bias in name detection for PII masking
May 09, 2022
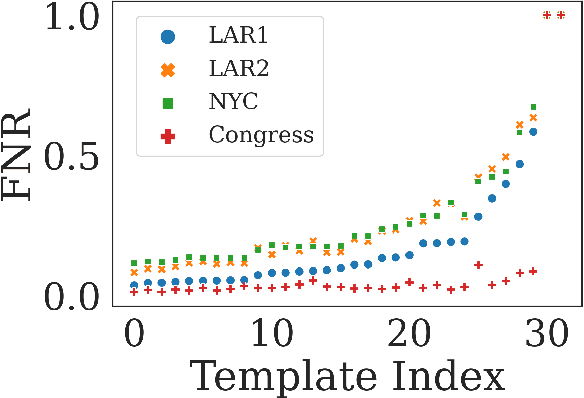
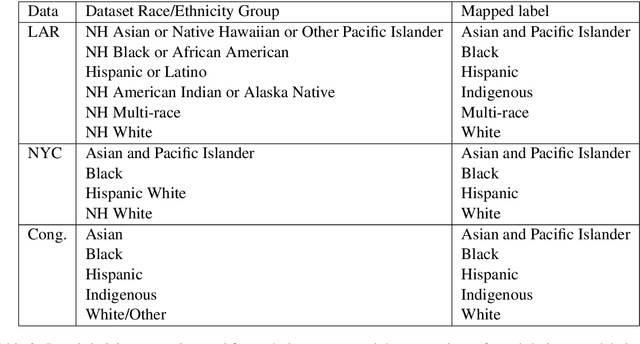
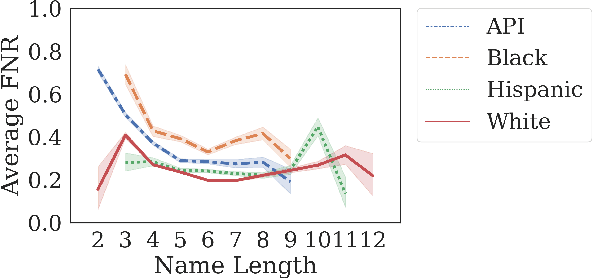
Many datasets contain personally identifiable information, or PII, which poses privacy risks to individuals. PII masking is commonly used to redact personal information such as names, addresses, and phone numbers from text data. Most modern PII masking pipelines involve machine learning algorithms. However, these systems may vary in performance, such that individuals from particular demographic groups bear a higher risk for having their personal information exposed. In this paper, we evaluate the performance of three off-the-shelf PII masking systems on name detection and redaction. We generate data using names and templates from the customer service domain. We find that an open-source RoBERTa-based system shows fewer disparities than the commercial models we test. However, all systems demonstrate significant differences in error rate based on demographics. In particular, the highest error rates occurred for names associated with Black and Asian/Pacific Islander individuals.
An Improved Normed-Deformable Convolution for Crowd Counting
Jun 16, 2022



In recent years, crowd counting has become an important issue in computer vision. In most methods, the density maps are generated by convolving with a Gaussian kernel from the ground-truth dot maps which are marked around the center of human heads. Due to the fixed geometric structures in CNNs and indistinct head-scale information, the head features are obtained incompletely. Deformable convolution is proposed to exploit the scale-adaptive capabilities for CNN features in the heads. By learning the coordinate offsets of the sampling points, it is tractable to improve the ability to adjust the receptive field. However, the heads are not uniformly covered by the sampling points in the deformable convolution, resulting in loss of head information. To handle the non-uniformed sampling, an improved Normed-Deformable Convolution (\textit{i.e.,}NDConv) implemented by Normed-Deformable loss (\textit{i.e.,}NDloss) is proposed in this paper. The offsets of the sampling points which are constrained by NDloss tend to be more even. Then, the features in the heads are obtained more completely, leading to better performance. Especially, the proposed NDConv is a light-weight module which shares similar computation burden with Deformable Convolution. In the extensive experiments, our method outperforms state-of-the-art methods on ShanghaiTech A, ShanghaiTech B, UCF\_QNRF, and UCF\_CC\_50 dataset, achieving 61.4, 7.8, 91.2, and 167.2 MAE, respectively. The code is available at https://github.com/bingshuangzhuzi/NDConv
Self-Supervised Deep Subspace Clustering with Entropy-norm
Jun 10, 2022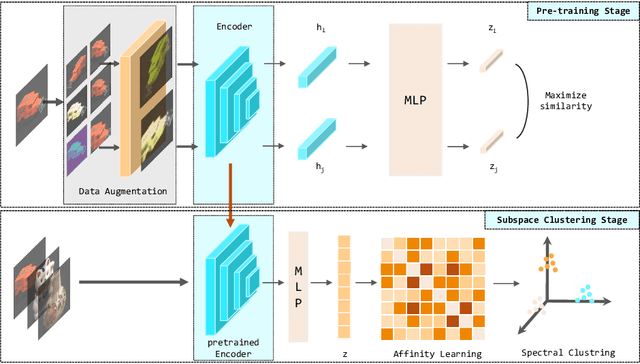
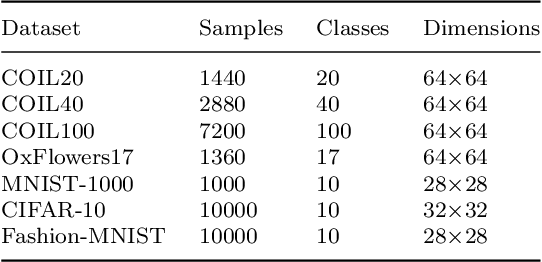
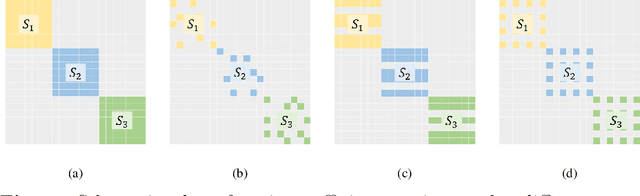

Auto-Encoder based deep subspace clustering (DSC) is widely used in computer vision, motion segmentation and image processing. However, it suffers from the following three issues in the self-expressive matrix learning process: the first one is less useful information for learning self-expressive weights due to the simple reconstruction loss; the second one is that the construction of the self-expression layer associated with the sample size requires high-computational cost; and the last one is the limited connectivity of the existing regularization terms. In order to address these issues, in this paper we propose a novel model named Self-Supervised deep Subspace Clustering with Entropy-norm (S$^{3}$CE). Specifically, S$^{3}$CE exploits a self-supervised contrastive network to gain a more effetive feature vector. The local structure and dense connectivity of the original data benefit from the self-expressive layer and additional entropy-norm constraint. Moreover, a new module with data enhancement is designed to help S$^{3}$CE focus on the key information of data, and improve the clustering performance of positive and negative instances through spectral clustering. Extensive experimental results demonstrate the superior performance of S$^{3}$CE in comparison to the state-of-the-art approaches.