 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploiting Global Contextual Information for Document-level Named Entity Recognition
Jun 02, 2021
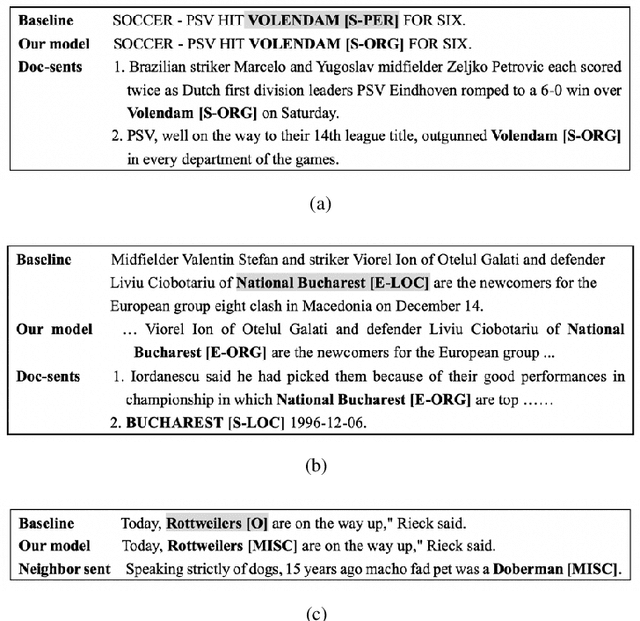
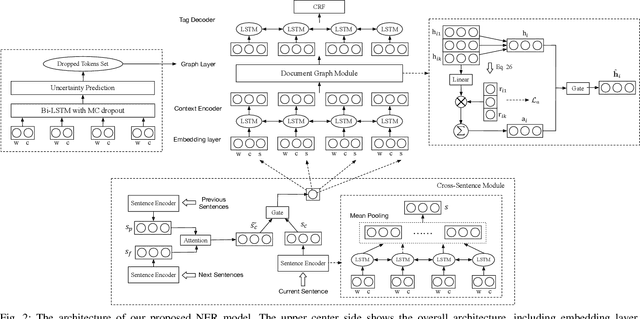

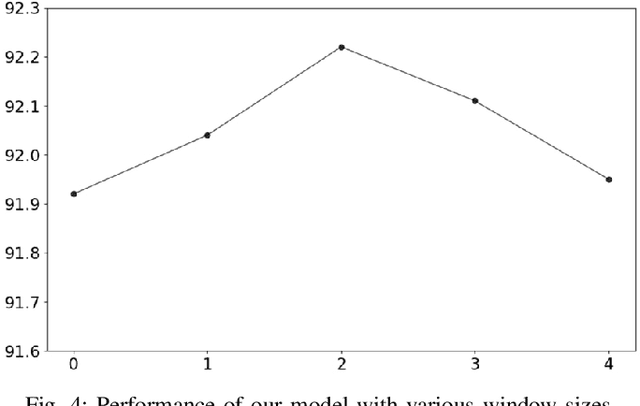
Most existing named entity recognition (NER) approaches are based on sequence labeling models, which focus on capturing the local context dependencies. However, the way of taking one sentence as input prevents the modeling of non-sequential global context, which is useful especially when local context information is limited or ambiguous. To this end, we propose a model called Global Context enhanced Document-level NER (GCDoc) to leverage global contextual information from two levels, i.e., both word and sentence. At word-level, a document graph is constructed to model a wider range of dependencies between words, then obtain an enriched contextual representation for each word via graph neural networks (GNN). To avoid the interference of noise information, we further propose two strategies. First we apply the epistemic uncertainty theory to find out tokens whose representations are less reliable, thereby helping prune the document graph. Then a selective auxiliary classifier is proposed to effectively learn the weight of edges in document graph and reduce the importance of noisy neighbour nodes. At sentence-level, for appropriately modeling wider context beyond single sentence, we employ a cross-sentence module which encodes adjacent sentences and fuses it with the current sentence representation via attention and gating mechanisms. Extensive experiments on two benchmark NER datasets (CoNLL 2003 and Ontonotes 5.0 English dataset) demonstrate the effectiveness of our proposed model. Our model reaches F1 score of 92.22 (93.40 with BERT) on CoNLL 2003 dataset and 88.32 (90.49 with BERT) on Ontonotes 5.0 dataset, achieving new state-of-the-art performance.
Depth-aware Glass Surface Detection with Cross-modal Context Mining
Jun 22, 2022

Glass surfaces are becoming increasingly ubiquitous as modern buildings tend to use a lot of glass panels. This however poses substantial challenges on the operations of autonomous systems such as robots, self-driving cars and drones, as the glass panels can become transparent obstacles to the navigation.Existing works attempt to exploit various cues, including glass boundary context or reflections, as a prior. However, they are all based on input RGB images.We observe that the transmission of 3D depth sensor light through glass surfaces often produces blank regions in the depth maps, which can offer additional insights to complement the RGB image features for glass surface detection. In this paper, we propose a novel framework for glass surface detection by incorporating RGB-D information, with two novel modules: (1) a cross-modal context mining (CCM) module to adaptively learn individual and mutual context features from RGB and depth information, and (2) a depth-missing aware attention (DAA) module to explicitly exploit spatial locations where missing depths occur to help detect the presence of glass surfaces. In addition, we propose a large-scale RGB-D glass surface detection dataset, called \textit{RGB-D GSD}, for RGB-D glass surface detection. Our dataset comprises 3,009 real-world RGB-D glass surface images with precise annotations. Extensive experimental results show that our proposed model outperforms state-of-the-art methods.
Comparing the latent space of generative models
Jul 14, 2022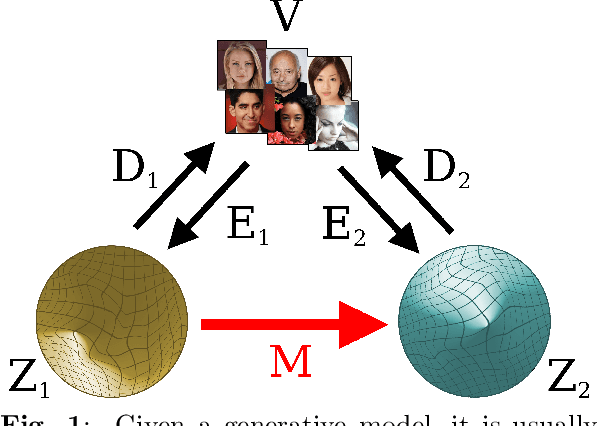


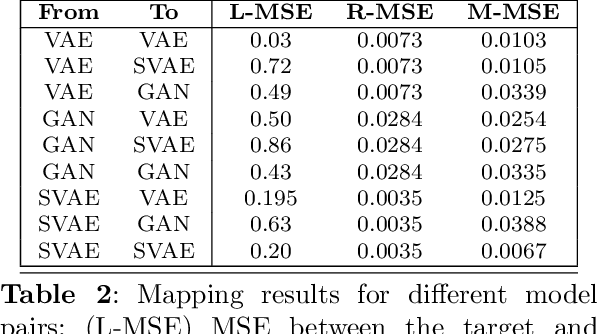
Different encodings of datapoints in the latent space of latent-vector generative models may result in more or less effective and disentangled characterizations of the different explanatory factors of variation behind the data. Many works have been recently devoted to the explorationof the latent space of specific models, mostly focused on the study of how features are disentangled and of how trajectories producing desired alterations of data in the visible space can be found. In this work we address the more general problem of comparing the latent spaces of different models, looking for transformations between them. We confined the investigation to the familiar and largely investigated case of generative models for the data manifold of human faces. The surprising, preliminary result reported in this article is that (provided models have not been taught or explicitly conceived to act differently) a simple linear mapping is enough to pass from a latent space to another while preserving most of the information.
Point-to-Voxel Knowledge Distillation for LiDAR Semantic Segmentation
Jun 05, 2022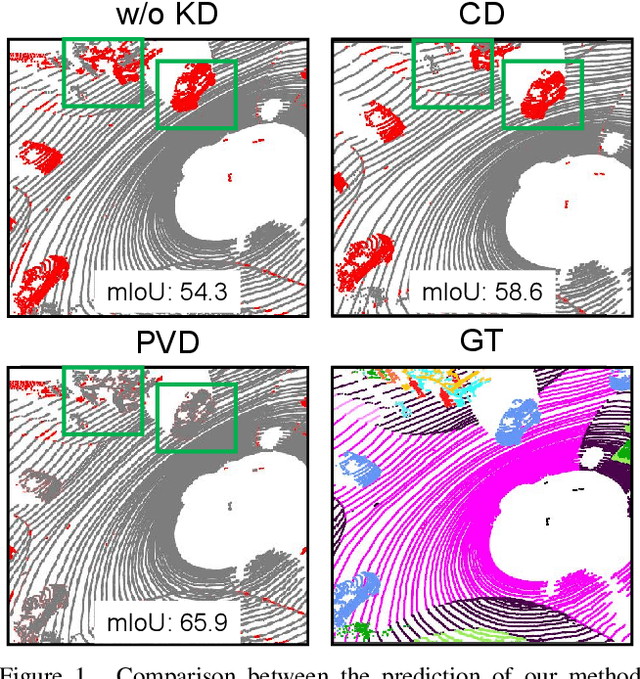
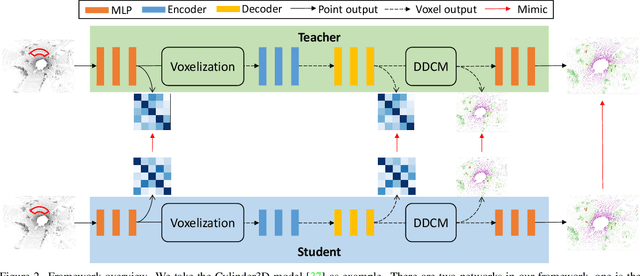
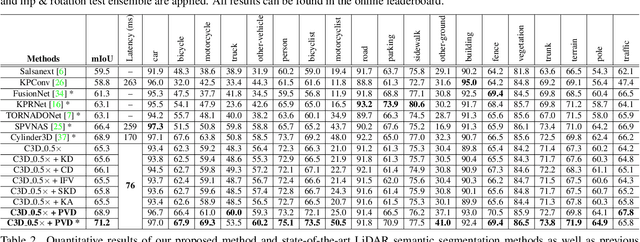
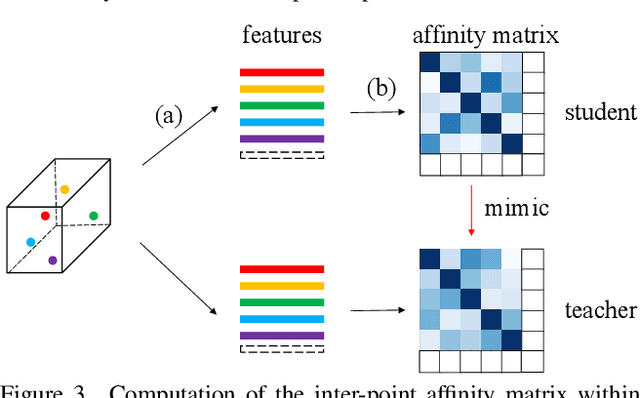
This article addresses the problem of distilling knowledge from a large teacher model to a slim student network for LiDAR semantic segmentation. Directly employing previous distillation approaches yields inferior results due to the intrinsic challenges of point cloud, i.e., sparsity, randomness and varying density. To tackle the aforementioned problems, we propose the Point-to-Voxel Knowledge Distillation (PVD), which transfers the hidden knowledge from both point level and voxel level. Specifically, we first leverage both the pointwise and voxelwise output distillation to complement the sparse supervision signals. Then, to better exploit the structural information, we divide the whole point cloud into several supervoxels and design a difficulty-aware sampling strategy to more frequently sample supervoxels containing less-frequent classes and faraway objects. On these supervoxels, we propose inter-point and inter-voxel affinity distillation, where the similarity information between points and voxels can help the student model better capture the structural information of the surrounding environment. We conduct extensive experiments on two popular LiDAR segmentation benchmarks, i.e., nuScenes and SemanticKITTI. On both benchmarks, our PVD consistently outperforms previous distillation approaches by a large margin on three representative backbones, i.e., Cylinder3D, SPVNAS and MinkowskiNet. Notably, on the challenging nuScenes and SemanticKITTI datasets, our method can achieve roughly 75% MACs reduction and 2x speedup on the competitive Cylinder3D model and rank 1st on the SemanticKITTI leaderboard among all published algorithms. Our code is available at https://github.com/cardwing/Codes-for-PVKD.
Retrieval-Enhanced Machine Learning
May 02, 2022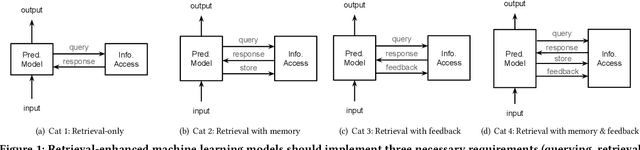
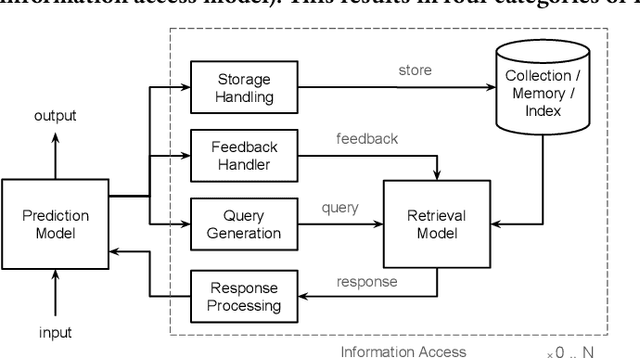
Although information access systems have long supported people in accomplishing a wide range of tasks, we propose broadening the scope of users of information access systems to include task-driven machines, such as machine learning models. In this way, the core principles of indexing, representation, retrieval, and ranking can be applied and extended to substantially improve model generalization, scalability, robustness, and interpretability. We describe a generic retrieval-enhanced machine learning (REML) framework, which includes a number of existing models as special cases. REML challenges information retrieval conventions, presenting opportunities for novel advances in core areas, including optimization. The REML research agenda lays a foundation for a new style of information access research and paves a path towards advancing machine learning and artificial intelligence.
Audio-visual scene classification via contrastive event-object alignment and semantic-based fusion
Aug 03, 2022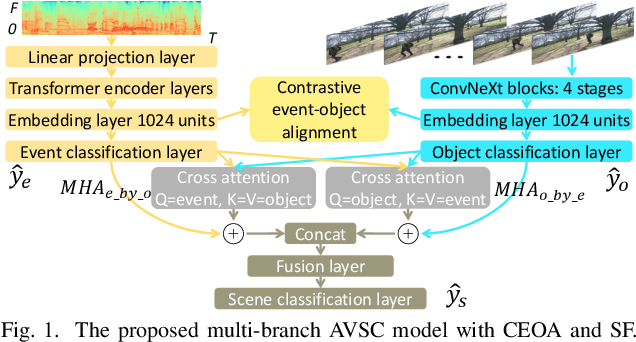

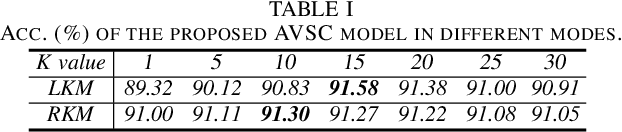
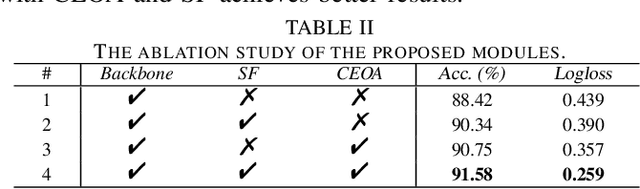
Previous works on scene classification are mainly based on audio or visual signals, while humans perceive the environmental scenes through multiple senses. Recent studies on audio-visual scene classification separately fine-tune the largescale audio and image pre-trained models on the target dataset, then either fuse the intermediate representations of the audio model and the visual model, or fuse the coarse-grained decision of both models at the clip level. Such methods ignore the detailed audio events and visual objects in audio-visual scenes (AVS), while humans often identify different scenes through audio events and visual objects within and the congruence between them. To exploit the fine-grained information of audio events and visual objects in AVS, and coordinate the implicit relationship between audio events and visual objects, this paper proposes a multibranch model equipped with contrastive event-object alignment (CEOA) and semantic-based fusion (SF) for AVSC. CEOA aims to align the learned embeddings of audio events and visual objects by comparing the difference between audio-visual event-object pairs. Then, visual objects associated with certain audio events and vice versa are accentuated by cross-attention and undergo SF for semantic-level fusion. Experiments show that: 1) the proposed AVSC model equipped with CEOA and SF outperforms the results of audio-only and visual-only models, i.e., the audio-visual results are better than the results from a single modality. 2) CEOA aligns the embeddings of audio events and related visual objects on a fine-grained level, and the SF effectively integrates both; 3) Compared with other large-scale integrated systems, the proposed model shows competitive performance, even without using additional datasets and data augmentation tricks.
TranSiam: Fusing Multimodal Visual Features Using Transformer for Medical Image Segmentation
Apr 26, 2022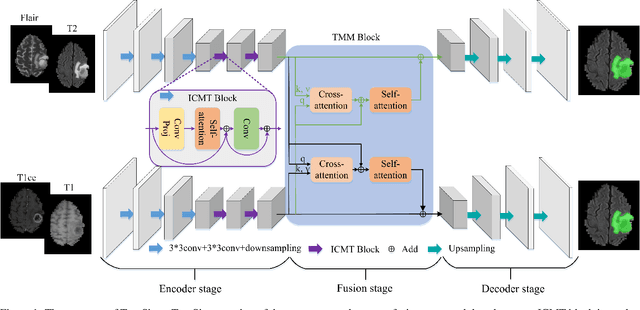
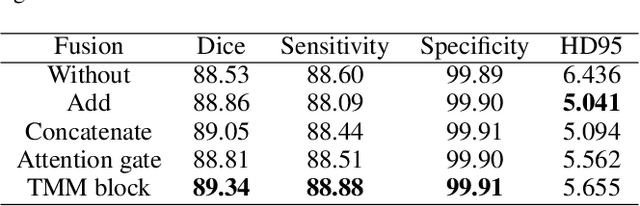
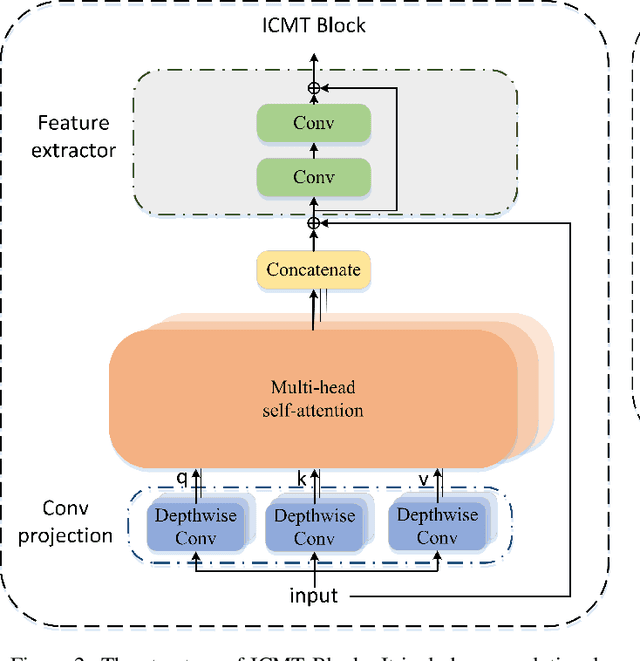
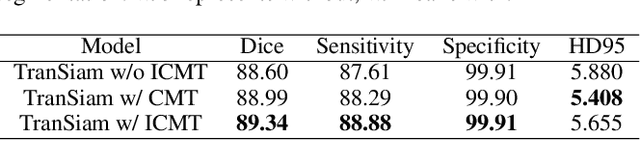
Automatic segmentation of medical images based on multi-modality is an important topic for disease diagnosis. Although the convolutional neural network (CNN) has been proven to have excellent performance in image segmentation tasks, it is difficult to obtain global information. The lack of global information will seriously affect the accuracy of the segmentation results of the lesion area. In addition, there are visual representation differences between multimodal data of the same patient. These differences will affect the results of the automatic segmentation methods. To solve these problems, we propose a segmentation method suitable for multimodal medical images that can capture global information, named TranSiam. TranSiam is a 2D dual path network that extracts features of different modalities. In each path, we utilize convolution to extract detailed information in low level stage, and design a ICMT block to extract global information in high level stage. ICMT block embeds convolution in the transformer, which can extract global information while retaining spatial and detailed information. Furthermore, we design a novel fusion mechanism based on cross attention and selfattention, called TMM block, which can effectively fuse features between different modalities. On the BraTS 2019 and BraTS 2020 multimodal datasets, we have a significant improvement in accuracy over other popular methods.
Frequency Permutation Subsets for Joint Radar and Communication
Jul 21, 2022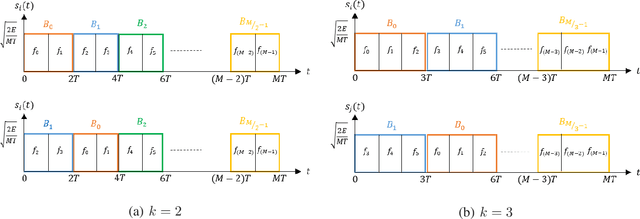
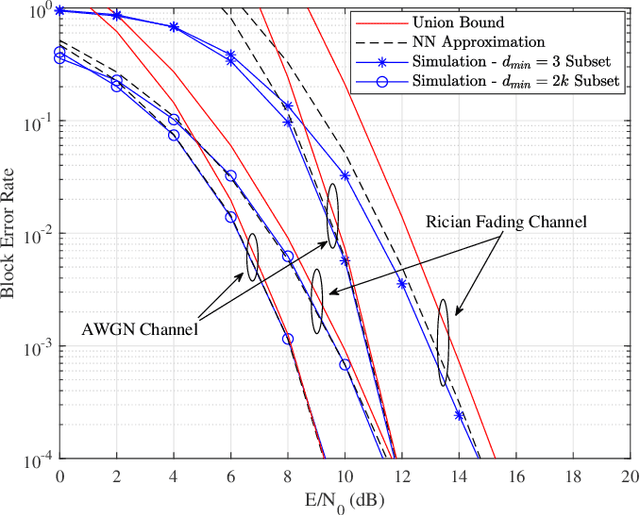
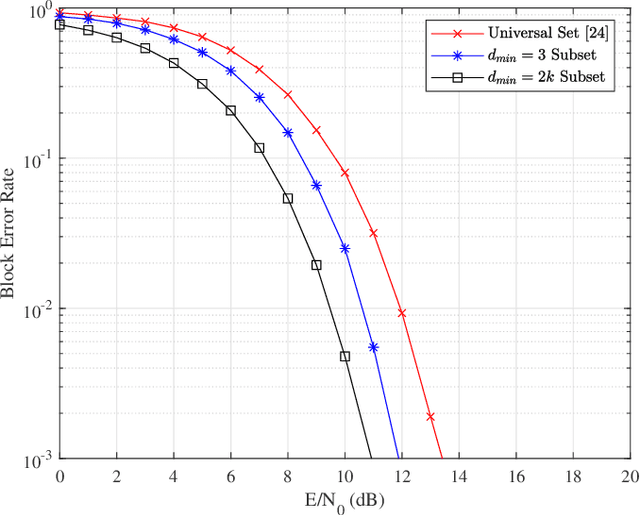
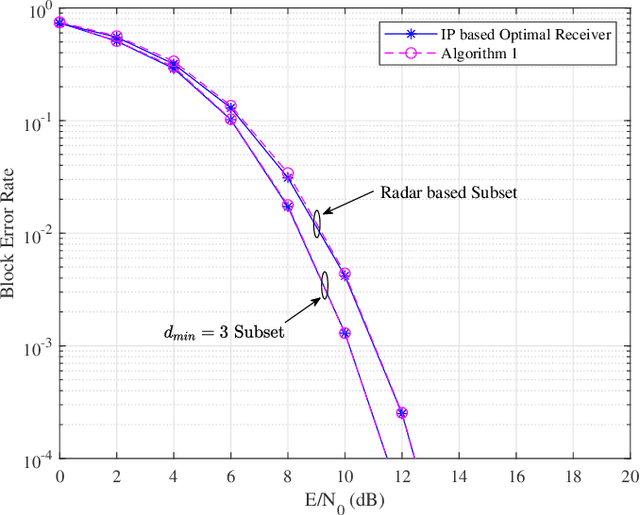
This paper focuses on waveform design for joint radar and communication systems and presents a new subset selection process to improve the communication error rate performance and global accuracy of radar sensing of the random stepped frequency permutation waveform. An optimal communication receiver based on integer programming is proposed to handle any subset of permutations followed by a more efficient sub-optimal receiver based on the Hungarian algorithm. Considering optimum maximum likelihood detection, the block error rate is analyzed under both additive white Gaussian noise and correlated Rician fading. We propose two methods to select a permutation subset with an improved block error rate and an efficient encoding scheme to map the information symbols to selected permutations under these subsets. From the radar perspective, the ambiguity function is analyzed with regards to the local and the global accuracy of target detection. Furthermore, a subset selection method to reduce the maximum sidelobe height is proposed by extending the properties of Costas arrays. Finally, the process of remapping the frequency tones to the symbol set used to generate permutations is introduced as a method to improve both the communication and radar performances of the selected permutation subset.
Prototypical Contrast Adaptation for Domain Adaptive Semantic Segmentation
Jul 14, 2022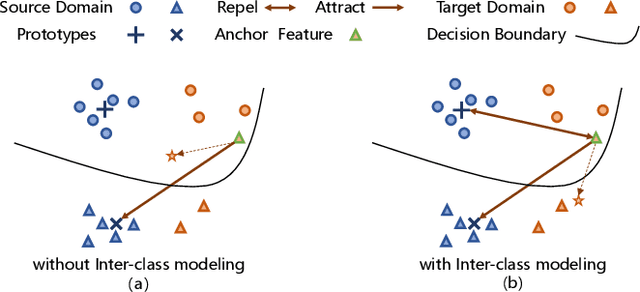
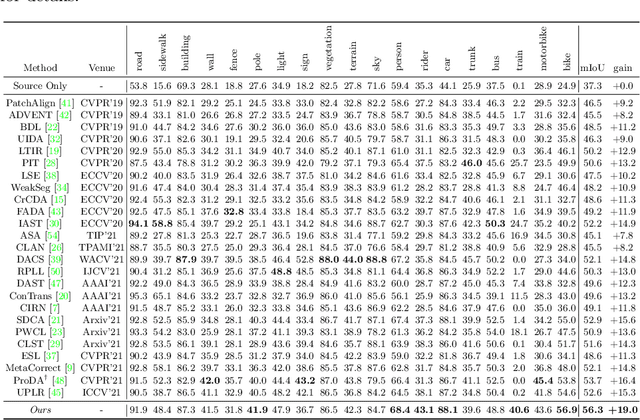
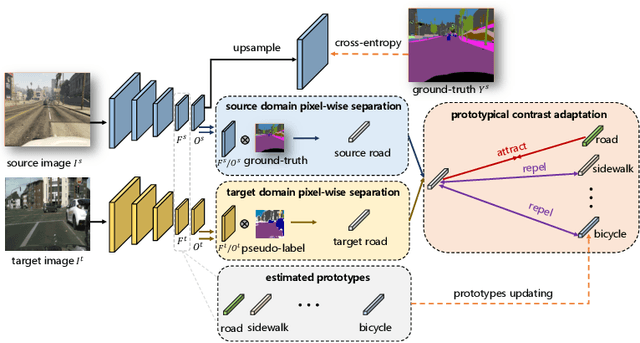
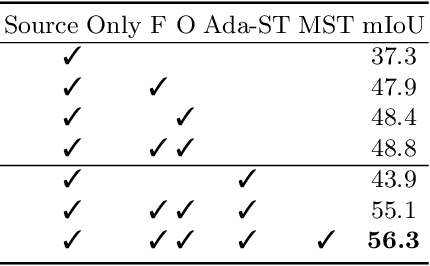
Unsupervised Domain Adaptation (UDA) aims to adapt the model trained on the labeled source domain to an unlabeled target domain. In this paper, we present Prototypical Contrast Adaptation (ProCA), a simple and efficient contrastive learning method for unsupervised domain adaptive semantic segmentation. Previous domain adaptation methods merely consider the alignment of the intra-class representational distributions across various domains, while the inter-class structural relationship is insufficiently explored, resulting in the aligned representations on the target domain might not be as easily discriminated as done on the source domain anymore. Instead, ProCA incorporates inter-class information into class-wise prototypes, and adopts the class-centered distribution alignment for adaptation. By considering the same class prototypes as positives and other class prototypes as negatives to achieve class-centered distribution alignment, ProCA achieves state-of-the-art performance on classical domain adaptation tasks, {\em i.e., GTA5 $\to$ Cityscapes \text{and} SYNTHIA $\to$ Cityscapes}. Code is available at \href{https://github.com/jiangzhengkai/ProCA}{ProCA}
Smart Mat Used for Prevention of Hospital-Acquired Pressure Injuries
Jul 08, 2022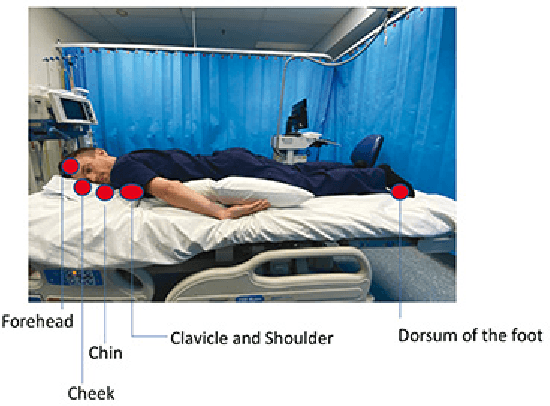

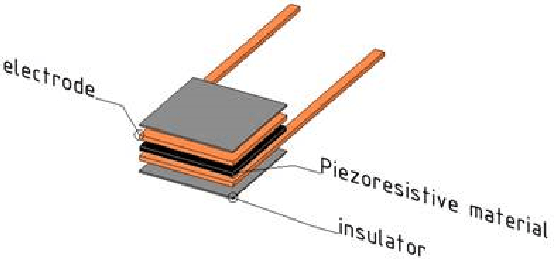
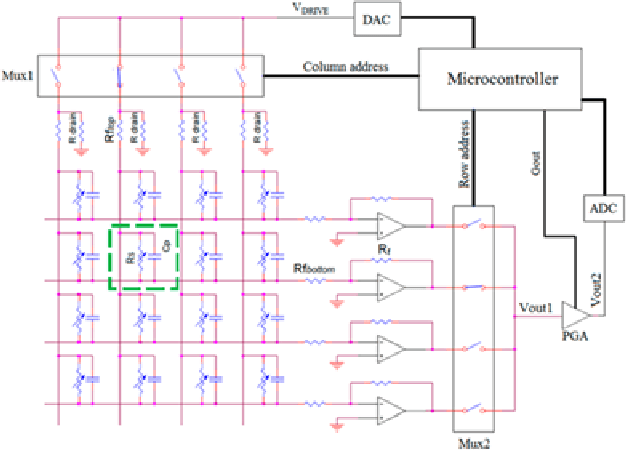
This work develops a smart mat for monitoring body positions. We use Velostat as a force sensor resistance (FSR) to construct a sensor matrix over the mat to receive the pressure distribution of the patient's body, and then upload the processed distribution information to the PC for data visualization through Arduino. Data visualization on the PC side is compiled through Python language to realize the functions of patient body pressure distribution monitoring, long-term pressure alarm and posture prediction. The purpose of this work is to relieve the work stress on medical staff caused by pressure injuries during the treatment and care of patients during the pandemic. This paper includes the literature review on similar previous works and combines the test results to design the structure and circuit of the smart mat.