 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
REVIVE: Regional Visual Representation Matters in Knowledge-Based Visual Question Answering
Jun 02, 2022
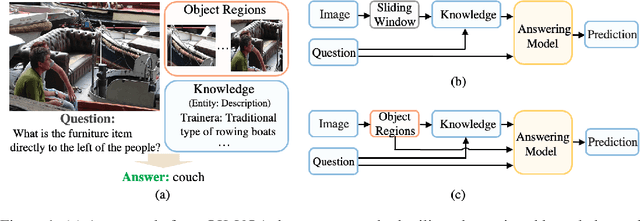
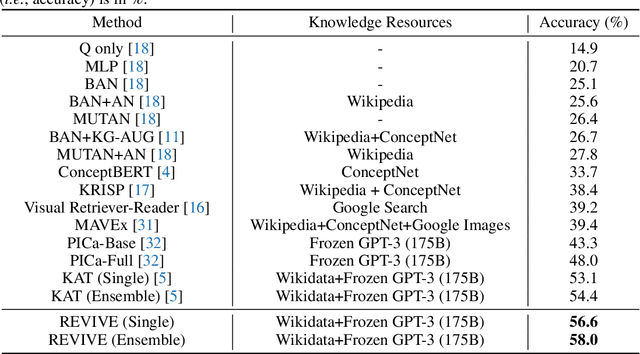
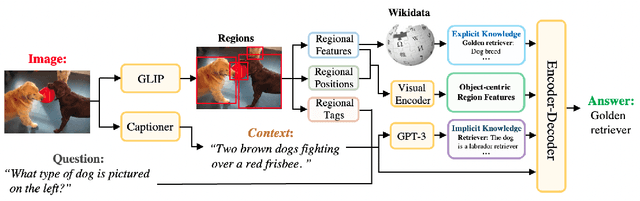

This paper revisits visual representation in knowledge-based visual question answering (VQA) and demonstrates that using regional information in a better way can significantly improve the performance. While visual representation is extensively studied in traditional VQA, it is under-explored in knowledge-based VQA even though these two tasks share the common spirit, i.e., rely on visual input to answer the question. Specifically, we observe that in most state-of-the-art knowledge-based VQA methods: 1) visual features are extracted either from the whole image or in a sliding window manner for retrieving knowledge, and the important relationship within/among object regions is neglected; 2) visual features are not well utilized in the final answering model, which is counter-intuitive to some extent. Based on these observations, we propose a new knowledge-based VQA method REVIVE, which tries to utilize the explicit information of object regions not only in the knowledge retrieval stage but also in the answering model. The key motivation is that object regions and inherent relationships are important for knowledge-based VQA. We perform extensive experiments on the standard OK-VQA dataset and achieve new state-of-the-art performance, i.e., 58.0% accuracy, surpassing previous state-of-the-art method by a large margin (+3.6%). We also conduct detailed analysis and show the necessity of regional information in different framework components for knowledge-based VQA.
Deep Diffusion Models for Seismic Processing
Jul 21, 2022



Seismic data processing involves techniques to deal with undesired effects that occur during acquisition and pre-processing. These effects mainly comprise coherent artefacts such as multiples, non-coherent signals such as electrical noise, and loss of signal information at the receivers that leads to incomplete traces. In the past years, there has been a remarkable increase of machine-learning-based solutions that have addressed the aforementioned issues. In particular, deep-learning practitioners have usually relied on heavily fine-tuned, customized discriminative algorithms. Although, these methods can provide solid results, they seem to lack semantic understanding of the provided data. Motivated by this limitation, in this work, we employ a generative solution, as it can explicitly model complex data distributions and hence, yield to a better decision-making process. In particular, we introduce diffusion models for three seismic applications: demultiple, denoising and interpolation. To that end, we run experiments on synthetic and on real data, and we compare the diffusion performance with standardized algorithms. We believe that our pioneer study not only demonstrates the capability of diffusion models, but also opens the door to future research to integrate generative models in seismic workflows.
Beware the Rationalization Trap! When Language Model Explainability Diverges from our Mental Models of Language
Jul 14, 2022
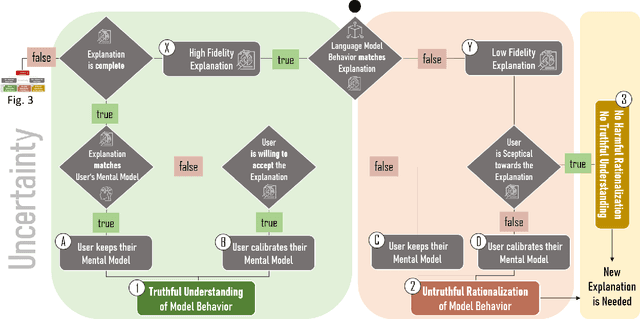
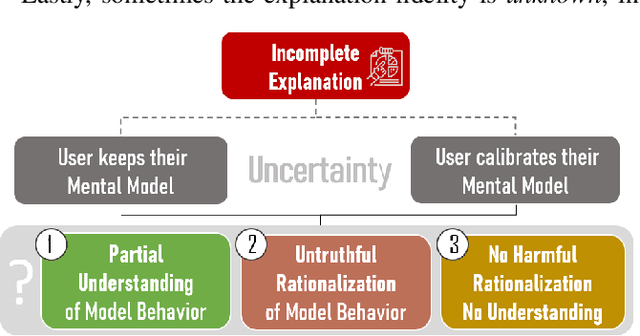
Language models learn and represent language differently than humans; they learn the form and not the meaning. Thus, to assess the success of language model explainability, we need to consider the impact of its divergence from a user's mental model of language. In this position paper, we argue that in order to avoid harmful rationalization and achieve truthful understanding of language models, explanation processes must satisfy three main conditions: (1) explanations have to truthfully represent the model behavior, i.e., have a high fidelity; (2) explanations must be complete, as missing information distorts the truth; and (3) explanations have to take the user's mental model into account, progressively verifying a person's knowledge and adapting their understanding. We introduce a decision tree model to showcase potential reasons why current explanations fail to reach their objectives. We further emphasize the need for human-centered design to explain the model from multiple perspectives, progressively adapting explanations to changing user expectations.
Content Popularity Prediction in Fog-RANs: A Clustered Federated Learning Based Approach
Jun 13, 2022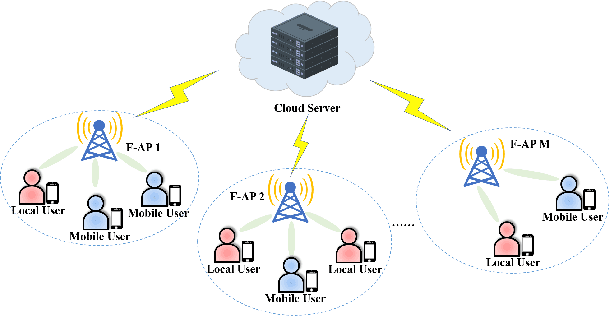
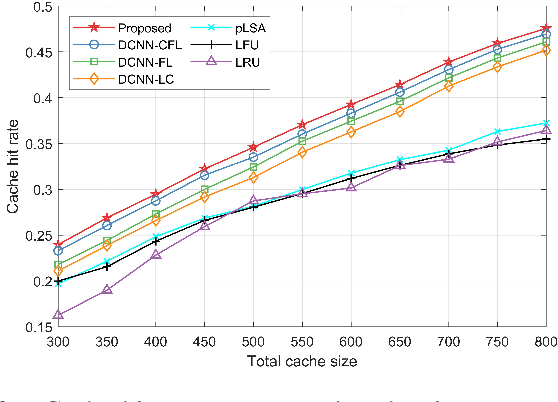
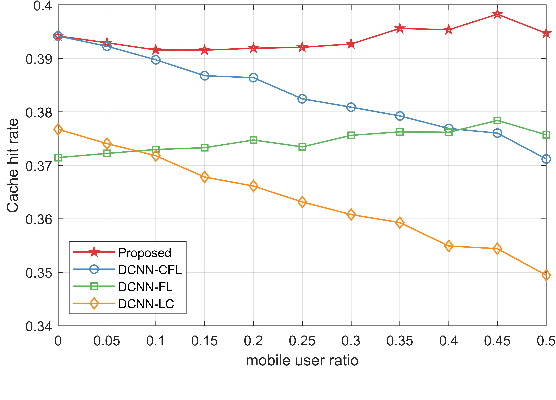
In this paper, the content popularity prediction problem in fog radio access networks (F-RANs) is investigated. Based on clustered federated learning, we propose a novel mobility-aware popularity prediction policy, which integrates content popularities in terms of local users and mobile users. For local users, the content popularity is predicted by learning the hidden representations of local users and contents. Initial features of local users and contents are generated by incorporating neighbor information with self information. Then, dual-channel neural network (DCNN) model is introduced to learn the hidden representations by producing deep latent features from initial features. For mobile users, the content popularity is predicted via user preference learning. In order to distinguish regional variations of content popularity, clustered federated learning (CFL) is employed, which enables fog access points (F-APs) with similar regional types to benefit from one another and provides a more specialized DCNN model for each F-AP. Simulation results show that our proposed policy achieves significant performance improvement over the traditional policies.
ProtoInfoMax: Prototypical Networks with Mutual Information Maximization for Out-of-Domain Detection
Sep 10, 2021

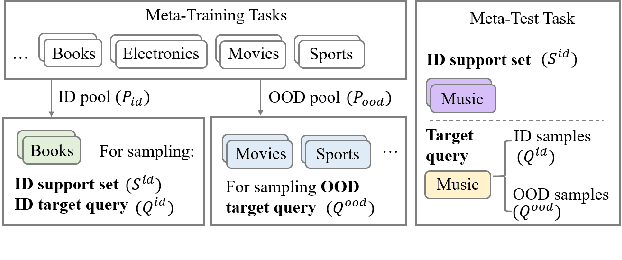
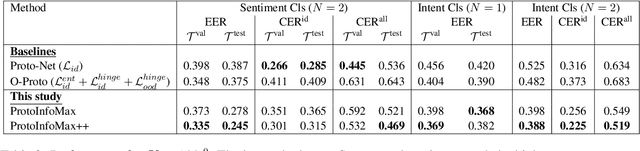
The ability to detect Out-of-Domain (OOD) inputs has been a critical requirement in many real-world NLP applications. For example, intent classification in dialogue systems. The reason is that the inclusion of unsupported OOD inputs may lead to catastrophic failure of systems. However, it remains an empirical question whether current methods can tackle such problems reliably in a realistic scenario where zero OOD training data is available. In this study, we propose ProtoInfoMax, a new architecture that extends Prototypical Networks to simultaneously process in-domain and OOD sentences via Mutual Information Maximization (InfoMax) objective. Experimental results show that our proposed method can substantially improve performance up to 20% for OOD detection in low resource settings of text classification. We also show that ProtoInfoMax is less prone to typical overconfidence errors of Neural Networks, leading to more reliable prediction results.
* This manuscript will be available in ACL Anthology section EMNLP2021-Findings papers
EEPT: Early Discovery of Emerging Entities in Twitter with Semantic Similarity
Jul 06, 2022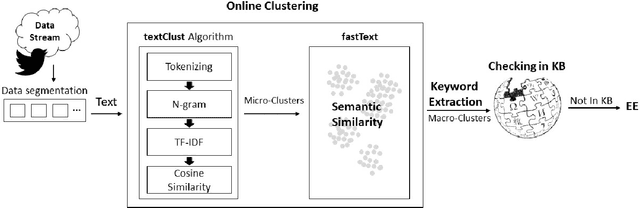
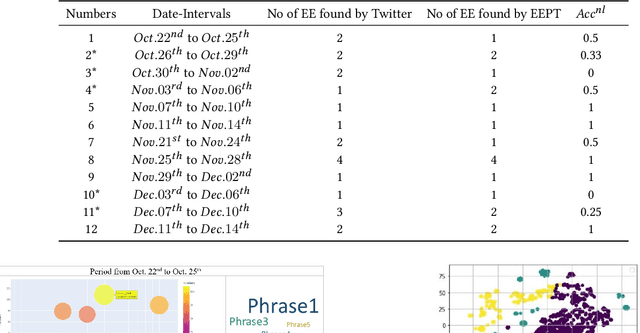
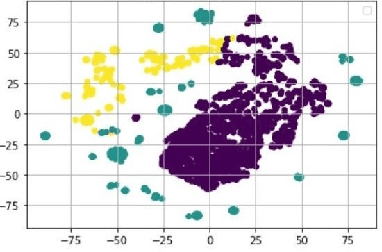
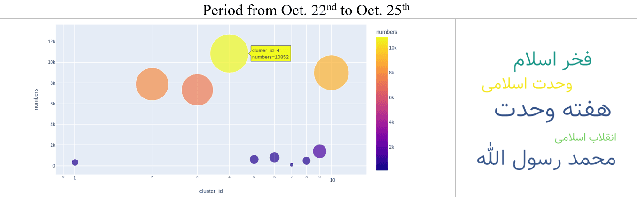
Some events which happen in the future could be important for companies, governments, and even our personal life. Prediction of these events before their establishment is helpful for efficient decision-making. We call such events emerging entities. They have not taken place yet, and there is no information about them in KB. However, some clues exist in different areas, especially on social media. Thus, retrieving these type of entities are possible. This paper proposes a method of early discovery of emerging entities. We use semantic clustering of short messages. To evaluate the performance of our proposal, we devise and utilize a performance evaluation metric. The results show that our proposed method finds those emerging entities of which Twitter trends are not always capable.
Leveraging Advantages of Interactive and Non-Interactive Models for Vector-Based Cross-Lingual Information Retrieval
Nov 03, 2021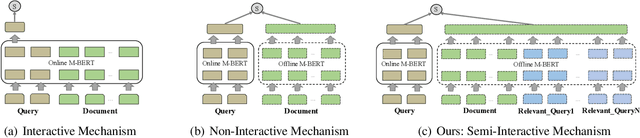
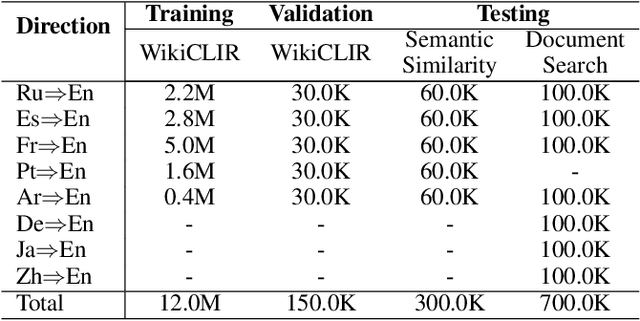
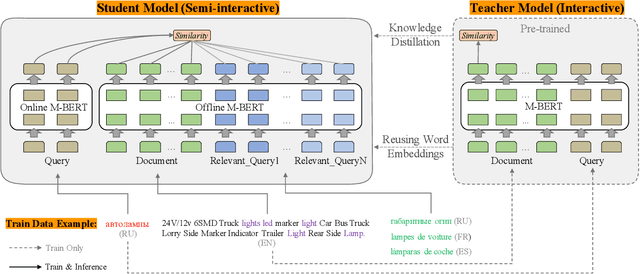

Interactive and non-interactive model are the two de-facto standard frameworks in vector-based cross-lingual information retrieval (V-CLIR), which embed queries and documents in synchronous and asynchronous fashions, respectively. From the retrieval accuracy and computational efficiency perspectives, each model has its own superiority and shortcoming. In this paper, we propose a novel framework to leverage the advantages of these two paradigms. Concretely, we introduce semi-interactive mechanism, which builds our model upon non-interactive architecture but encodes each document together with its associated multilingual queries. Accordingly, cross-lingual features can be better learned like an interactive model. Besides, we further transfer knowledge from a well-trained interactive model to ours by reusing its word embeddings and adopting knowledge distillation. Our model is initialized from a multilingual pre-trained language model M-BERT, and evaluated on two open-resource CLIR datasets derived from Wikipedia and an in-house dataset collected from a real-world search engine. Extensive analyses reveal that our methods significantly boost the retrieval accuracy while maintaining the computational efficiency.
Optimal Multi-robot Formations for Relative Pose Estimation Using Range Measurements
May 27, 2022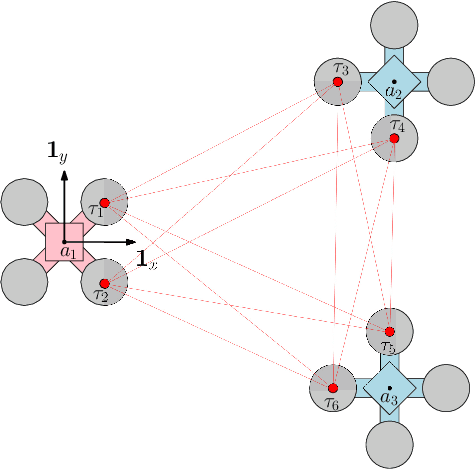
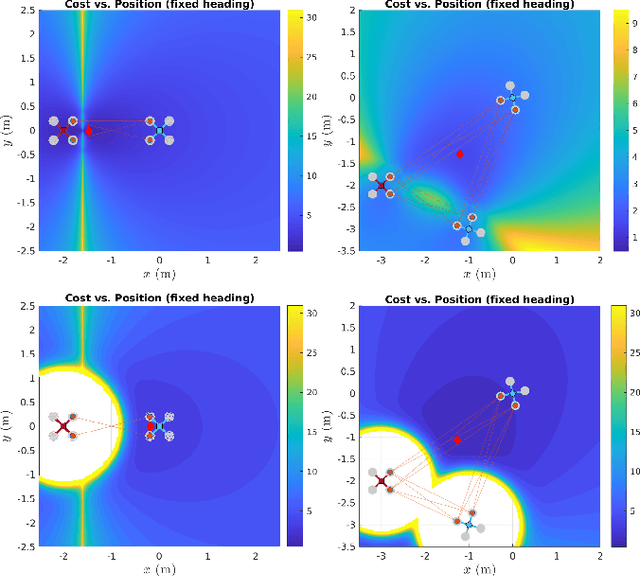
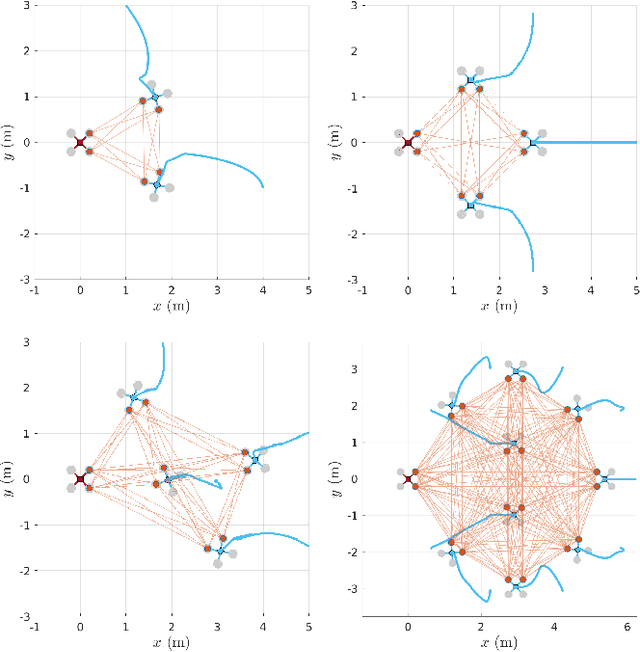
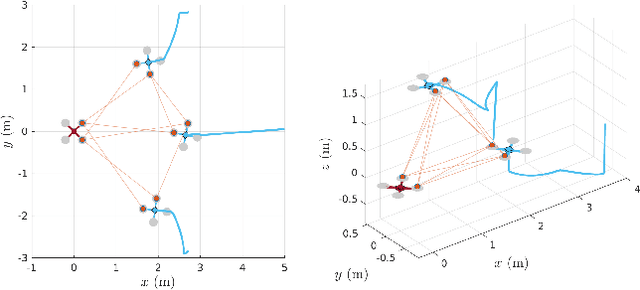
In multi-robot missions, relative position and attitude information between agents is valuable for a variety of tasks such as mapping, planning, and formation control. In this paper, the problem of estimating relative poses from a set of inter-agent range measurements is investigated. Specifically, it is shown that the estimation accuracy is highly dependent on the true relative poses themselves, which prompts the desire to find multi-agent formations that provide the best estimation performance. By direct maximization of Fischer information, it is shown in simulation and experiment that large improvements in estimation accuracy can be obtained by optimizing the formation geometry of a team of robots.
Comparing the latent space of generative models
Jul 14, 2022


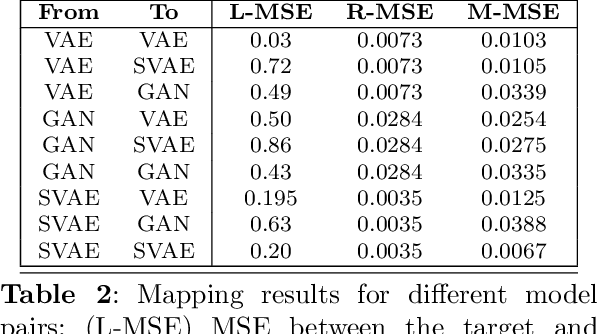
Different encodings of datapoints in the latent space of latent-vector generative models may result in more or less effective and disentangled characterizations of the different explanatory factors of variation behind the data. Many works have been recently devoted to the explorationof the latent space of specific models, mostly focused on the study of how features are disentangled and of how trajectories producing desired alterations of data in the visible space can be found. In this work we address the more general problem of comparing the latent spaces of different models, looking for transformations between them. We confined the investigation to the familiar and largely investigated case of generative models for the data manifold of human faces. The surprising, preliminary result reported in this article is that (provided models have not been taught or explicitly conceived to act differently) a simple linear mapping is enough to pass from a latent space to another while preserving most of the information.
Depth-aware Glass Surface Detection with Cross-modal Context Mining
Jun 22, 2022
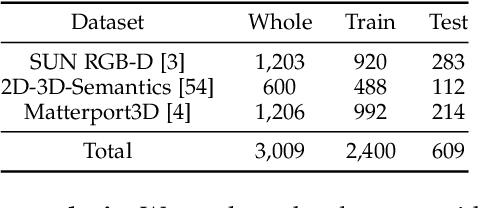

Glass surfaces are becoming increasingly ubiquitous as modern buildings tend to use a lot of glass panels. This however poses substantial challenges on the operations of autonomous systems such as robots, self-driving cars and drones, as the glass panels can become transparent obstacles to the navigation.Existing works attempt to exploit various cues, including glass boundary context or reflections, as a prior. However, they are all based on input RGB images.We observe that the transmission of 3D depth sensor light through glass surfaces often produces blank regions in the depth maps, which can offer additional insights to complement the RGB image features for glass surface detection. In this paper, we propose a novel framework for glass surface detection by incorporating RGB-D information, with two novel modules: (1) a cross-modal context mining (CCM) module to adaptively learn individual and mutual context features from RGB and depth information, and (2) a depth-missing aware attention (DAA) module to explicitly exploit spatial locations where missing depths occur to help detect the presence of glass surfaces. In addition, we propose a large-scale RGB-D glass surface detection dataset, called \textit{RGB-D GSD}, for RGB-D glass surface detection. Our dataset comprises 3,009 real-world RGB-D glass surface images with precise annotations. Extensive experimental results show that our proposed model outperforms state-of-the-art methods.