 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Survey of Task-Based Machine Learning Content Extraction Services for VIDINT
Jul 09, 2022


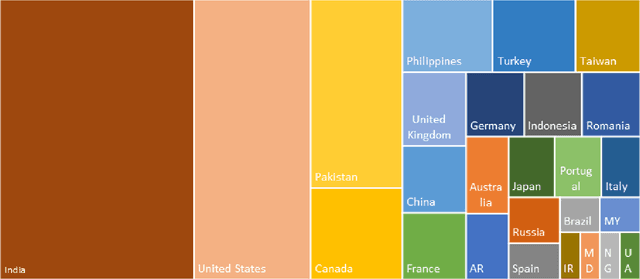
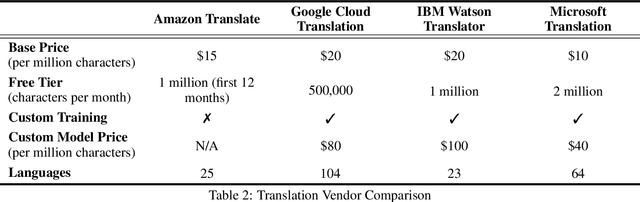
This paper provides a comparison of current video content extraction tools with a focus on comparing commercial task-based machine learning services. Video intelligence (VIDINT) data has become a critical intelligence source in the past decade. The need for AI-based analytics and automation tools to extract and structure content from video has quickly become a priority for organizations needing to search, analyze and exploit video at scale. With rapid growth in machine learning technology, the maturity of machine transcription, machine translation, topic tagging, and object recognition tasks are improving at an exponential rate, breaking performance records in speed and accuracy as new applications evolve. Each section of this paper reviews and compares products, software resources and video analytics capabilities based on tasks relevant to extracting information from video with machine learning techniques.
Robust Landmark-based Stent Tracking in X-ray Fluoroscopy
Jul 22, 2022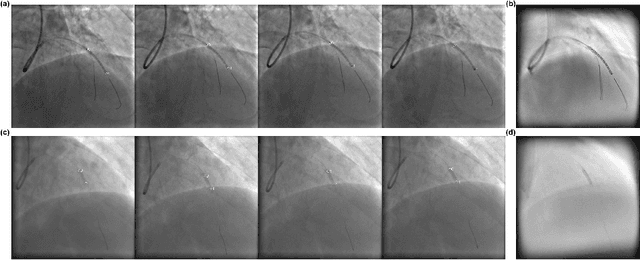
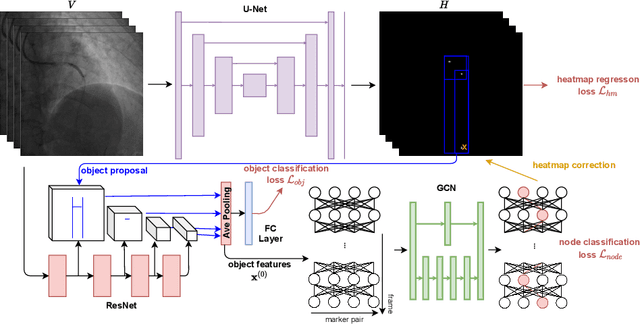
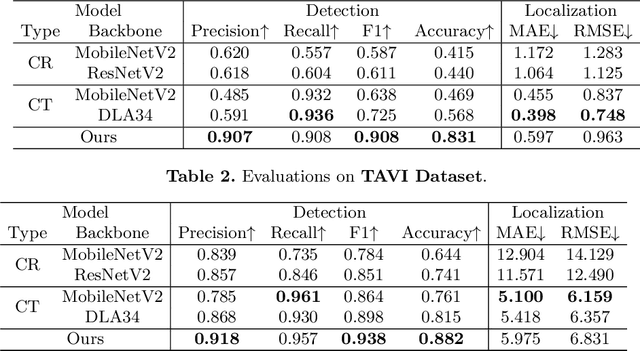
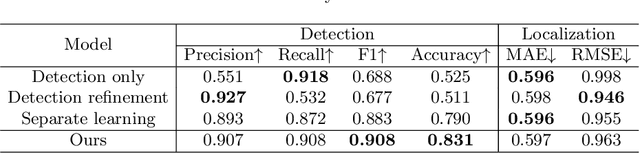
In clinical procedures of angioplasty (i.e., open clogged coronary arteries), devices such as balloons and stents need to be placed and expanded in arteries under the guidance of X-ray fluoroscopy. Due to the limitation of X-ray dose, the resulting images are often noisy. To check the correct placement of these devices, typically multiple motion-compensated frames are averaged to enhance the view. Therefore, device tracking is a necessary procedure for this purpose. Even though angioplasty devices are designed to have radiopaque markers for the ease of tracking, current methods struggle to deliver satisfactory results due to the small marker size and complex scenes in angioplasty. In this paper, we propose an end-to-end deep learning framework for single stent tracking, which consists of three hierarchical modules: U-Net based landmark detection, ResNet based stent proposal and feature extraction, and graph convolutional neural network (GCN) based stent tracking that temporally aggregates both spatial information and appearance features. The experiments show that our method performs significantly better in detection compared with the state-of-the-art point-based tracking models. In addition, its fast inference speed satisfies clinical requirements.
Blocked and Hierarchical Disentangled Representation From Information Theory Perspective
Jan 21, 2021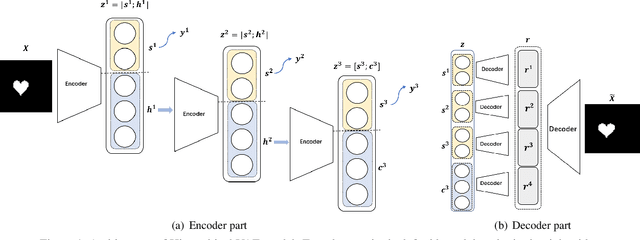

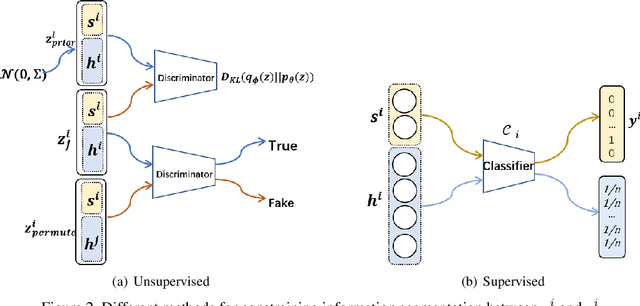
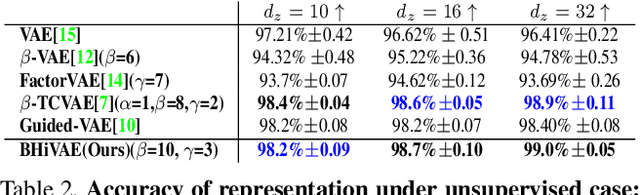
We propose a novel and theoretical model, blocked and hierarchical variational autoencoder (BHiVAE), to get better-disentangled representation. It is well known that information theory has an excellent explanatory meaning for the network, so we start to solve the disentanglement problem from the perspective of information theory. BHiVAE mainly comes from the information bottleneck theory and information maximization principle. Our main idea is that (1) Neurons block not only one neuron node is used to represent attribute, which can contain enough information; (2) Create a hierarchical structure with different attributes on different layers, so that we can segment the information within each layer to ensure that the final representation is disentangled. Furthermore, we present supervised and unsupervised BHiVAE, respectively, where the difference is mainly reflected in the separation of information between different blocks. In supervised BHiVAE, we utilize the label information as the standard to separate blocks. In unsupervised BHiVAE, without extra information, we use the Total Correlation (TC) measure to achieve independence, and we design a new prior distribution of the latent space to guide the representation learning. It also exhibits excellent disentanglement results in experiments and superior classification accuracy in representation learning.
Towards Complex Document Understanding By Discrete Reasoning
Jul 25, 2022
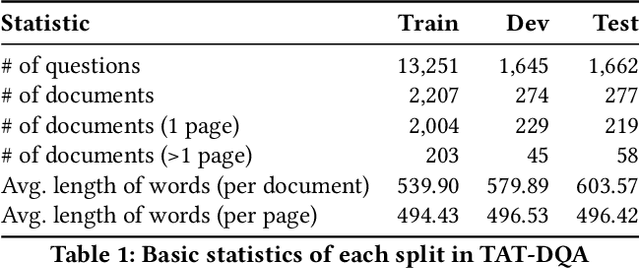
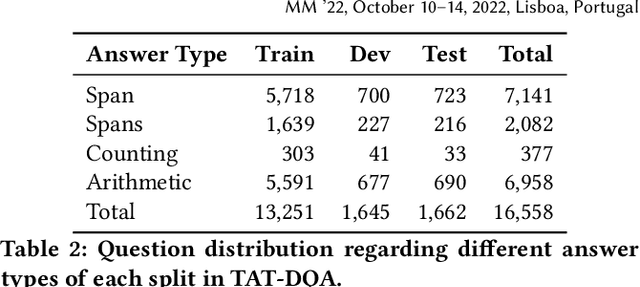
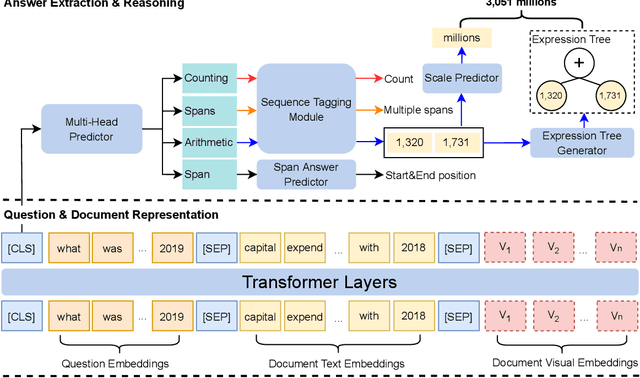
Document Visual Question Answering (VQA) aims to understand visually-rich documents to answer questions in natural language, which is an emerging research topic for both Natural Language Processing and Computer Vision. In this work, we introduce a new Document VQA dataset, named TAT-DQA, which consists of 3,067 document pages comprising semi-structured table(s) and unstructured text as well as 16,558 question-answer pairs by extending the TAT-QA dataset. These documents are sampled from real-world financial reports and contain lots of numbers, which means discrete reasoning capability is demanded to answer questions on this dataset. Based on TAT-DQA, we further develop a novel model named MHST that takes into account the information in multi-modalities, including text, layout and visual image, to intelligently address different types of questions with corresponding strategies, i.e., extraction or reasoning. Extensive experiments show that the MHST model significantly outperforms the baseline methods, demonstrating its effectiveness. However, the performance still lags far behind that of expert humans. We expect that our new TAT-DQA dataset would facilitate the research on deep understanding of visually-rich documents combining vision and language, especially for scenarios that require discrete reasoning. Also, we hope the proposed model would inspire researchers to design more advanced Document VQA models in future.
An Information-theoretic Approach to Distribution Shifts
Jun 07, 2021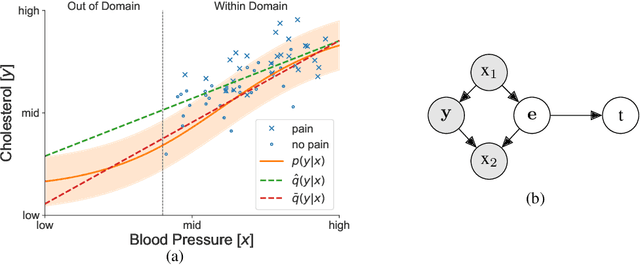
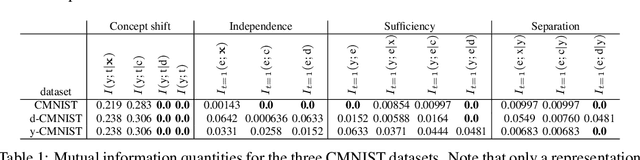
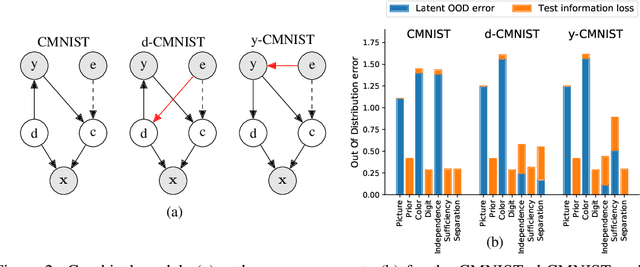
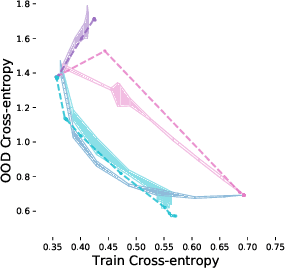
Safely deploying machine learning models to the real world is often a challenging process. Models trained with data obtained from a specific geographic location tend to fail when queried with data obtained elsewhere, agents trained in a simulation can struggle to adapt when deployed in the real world or novel environments, and neural networks that are fit to a subset of the population might carry some selection bias into their decision process. In this work, we describe the problem of data shift from a novel information-theoretic perspective by (i) identifying and describing the different sources of error, (ii) comparing some of the most promising objectives explored in the recent domain generalization, and fair classification literature. From our theoretical analysis and empirical evaluation, we conclude that the model selection procedure needs to be guided by careful considerations regarding the observed data, the factors used for correction, and the structure of the data-generating process.
Contrastive Learning for Unsupervised Domain Adaptation of Time Series
Jun 13, 2022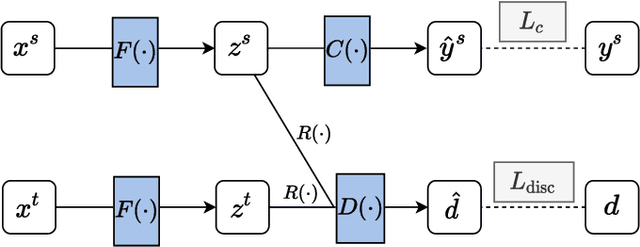

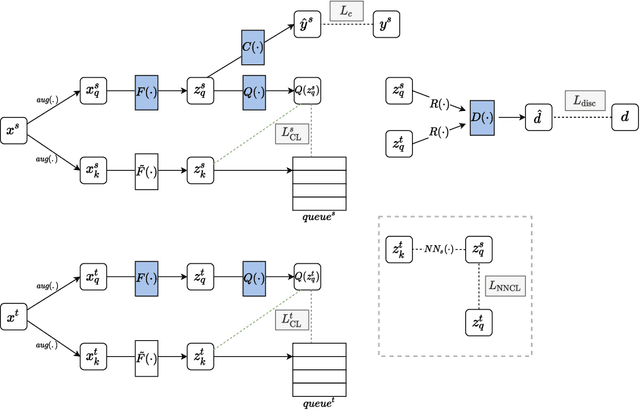
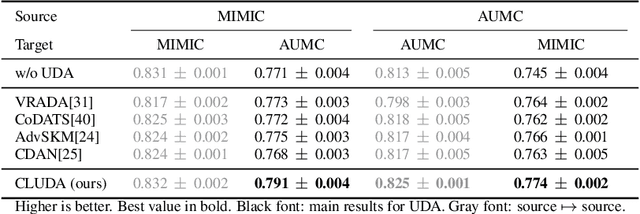
Unsupervised domain adaptation (UDA) aims at learning a machine learning model using a labeled source domain that performs well on a similar yet different, unlabeled target domain. UDA is important in many applications such as medicine, where it is used to adapt risk scores across different patient cohorts. In this paper, we develop a novel framework for UDA of time series data, called CLUDA. Specifically, we propose a contrastive learning framework to learn domain-invariant semantics in multivariate time series, so that these preserve label information for the prediction task. In our framework, we further capture semantic variation between source and target domain via nearest-neighbor contrastive learning. To the best of our knowledge, ours is the first framework to learn domain-invariant semantic information for UDA of time series data. We evaluate our framework using large-scale, real-world datasets with medical time series (i.e., MIMIC-IV and AmsterdamUMCdb) to demonstrate its effectiveness and show that it achieves state-of-the-art performance for time series UDA.
Semantic Autoencoder and Its Potential Usage for Adversarial Attack
May 31, 2022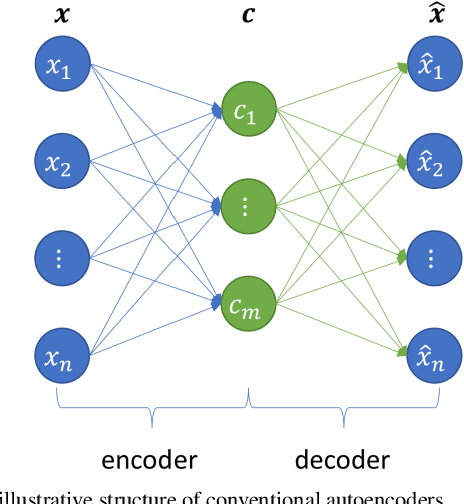
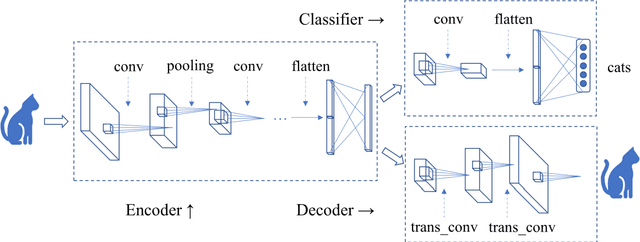
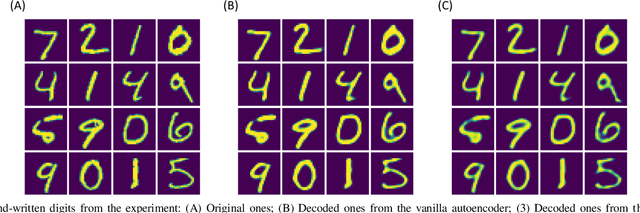
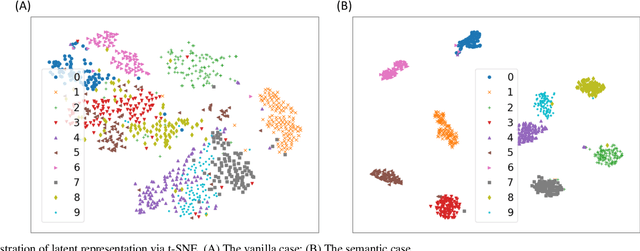
Autoencoder can give rise to an appropriate latent representation of the input data, however, the representation which is solely based on the intrinsic property of the input data, is usually inferior to express some semantic information. A typical case is the potential incapability of forming a clear boundary upon clustering of these representations. By encoding the latent representation that not only depends on the content of the input data, but also the semantic of the input data, such as label information, we propose an enhanced autoencoder architecture named semantic autoencoder. Experiments of representation distribution via t-SNE shows a clear distinction between these two types of encoders and confirm the supremacy of the semantic one, whilst the decoded samples of these two types of autoencoders exhibit faint dissimilarity either objectively or subjectively. Based on this observation, we consider adversarial attacks to learning algorithms that rely on the latent representation obtained via autoencoders. It turns out that latent contents of adversarial samples constructed from semantic encoder with deliberate wrong label information exhibit different distribution compared with that of the original input data, while both of these samples manifest very marginal difference. This new way of attack set up by our work is worthy of attention due to the necessity to secure the widespread deep learning applications.
Pose Uncertainty Aware Movement Synchrony Estimation via Spatial-Temporal Graph Transformer
Aug 01, 2022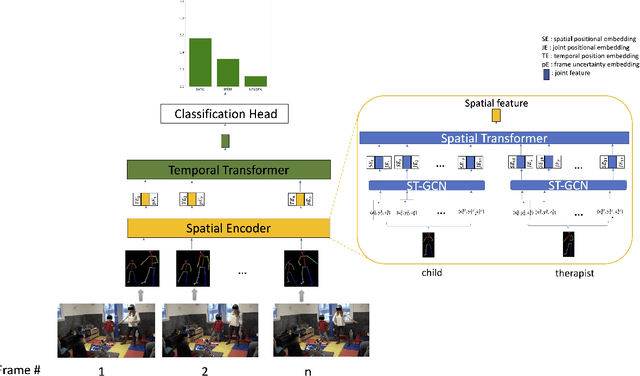
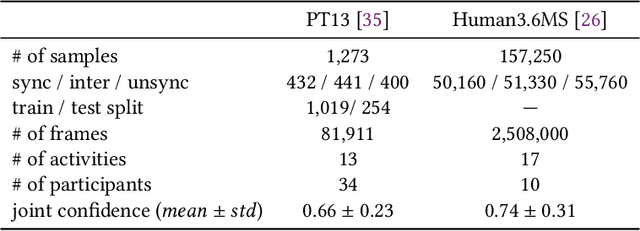
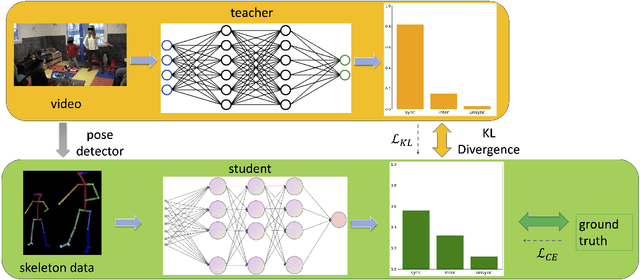
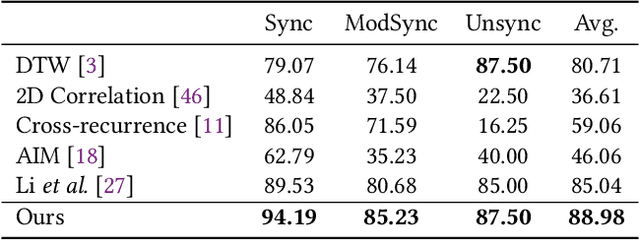
Movement synchrony reflects the coordination of body movements between interacting dyads. The estimation of movement synchrony has been automated by powerful deep learning models such as transformer networks. However, instead of designing a specialized network for movement synchrony estimation, previous transformer-based works broadly adopted architectures from other tasks such as human activity recognition. Therefore, this paper proposed a skeleton-based graph transformer for movement synchrony estimation. The proposed model applied ST-GCN, a spatial-temporal graph convolutional neural network for skeleton feature extraction, followed by a spatial transformer for spatial feature generation. The spatial transformer is guided by a uniquely designed joint position embedding shared between the same joints of interacting individuals. Besides, we incorporated a temporal similarity matrix in temporal attention computation considering the periodic intrinsic of body movements. In addition, the confidence score associated with each joint reflects the uncertainty of a pose, while previous works on movement synchrony estimation have not sufficiently emphasized this point. Since transformer networks demand a significant amount of data to train, we constructed a dataset for movement synchrony estimation using Human3.6M, a benchmark dataset for human activity recognition, and pretrained our model on it using contrastive learning. We further applied knowledge distillation to alleviate information loss introduced by pose detector failure in a privacy-preserving way. We compared our method with representative approaches on PT13, a dataset collected from autism therapy interventions. Our method achieved an overall accuracy of 88.98% and surpassed its counterparts by a wide margin while maintaining data privacy.
Improving Cross-Modal Alignment in Vision Language Navigation via Syntactic Information
Apr 19, 2021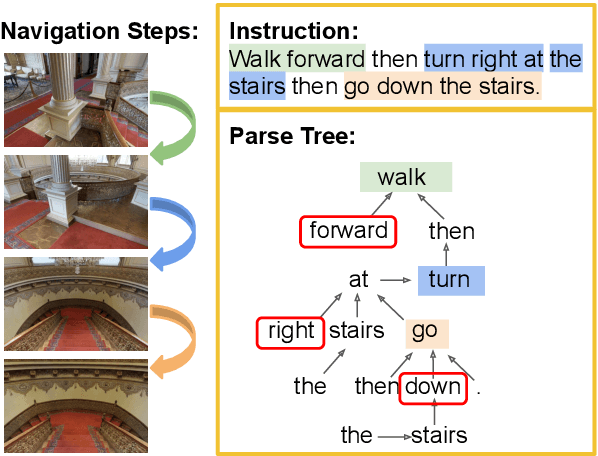

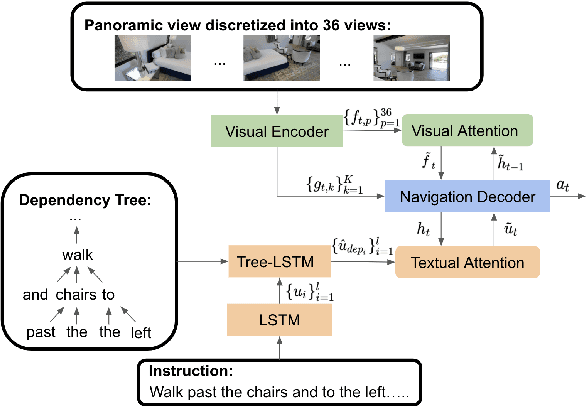
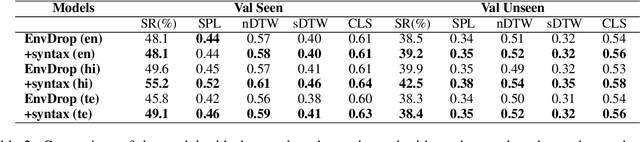
Vision language navigation is the task that requires an agent to navigate through a 3D environment based on natural language instructions. One key challenge in this task is to ground instructions with the current visual information that the agent perceives. Most of the existing work employs soft attention over individual words to locate the instruction required for the next action. However, different words have different functions in a sentence (e.g., modifiers convey attributes, verbs convey actions). Syntax information like dependencies and phrase structures can aid the agent to locate important parts of the instruction. Hence, in this paper, we propose a navigation agent that utilizes syntax information derived from a dependency tree to enhance alignment between the instruction and the current visual scenes. Empirically, our agent outperforms the baseline model that does not use syntax information on the Room-to-Room dataset, especially in the unseen environment. Besides, our agent achieves the new state-of-the-art on Room-Across-Room dataset, which contains instructions in 3 languages (English, Hindi, and Telugu). We also show that our agent is better at aligning instructions with the current visual information via qualitative visualizations. Code and models: https://github.com/jialuli-luka/SyntaxVLN
Class-incremental Novel Class Discovery
Jul 18, 2022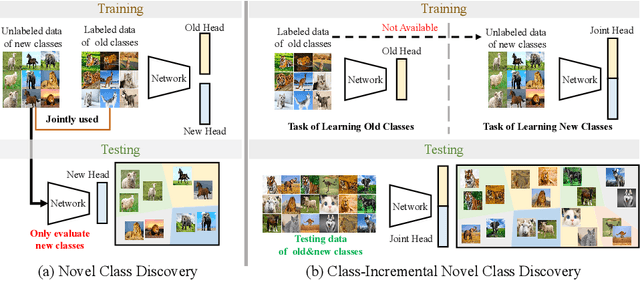
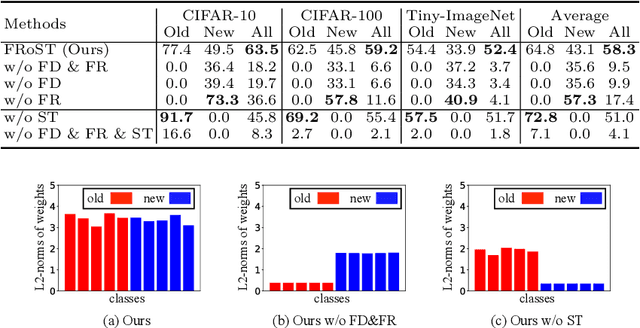
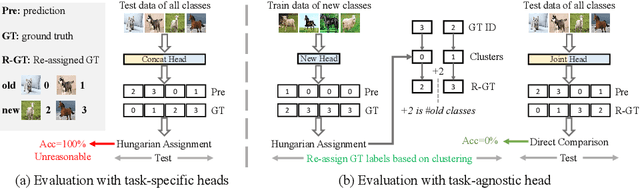

We study the new task of class-incremental Novel Class Discovery (class-iNCD), which refers to the problem of discovering novel categories in an unlabelled data set by leveraging a pre-trained model that has been trained on a labelled data set containing disjoint yet related categories. Apart from discovering novel classes, we also aim at preserving the ability of the model to recognize previously seen base categories. Inspired by rehearsal-based incremental learning methods, in this paper we propose a novel approach for class-iNCD which prevents forgetting of past information about the base classes by jointly exploiting base class feature prototypes and feature-level knowledge distillation. We also propose a self-training clustering strategy that simultaneously clusters novel categories and trains a joint classifier for both the base and novel classes. This makes our method able to operate in a class-incremental setting. Our experiments, conducted on three common benchmarks, demonstrate that our method significantly outperforms state-of-the-art approaches. Code is available at https://github.com/OatmealLiu/class-iNCD