 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Source Interactive Resilient Fusion Algorithm Based on RIEKF
Mar 02, 2024
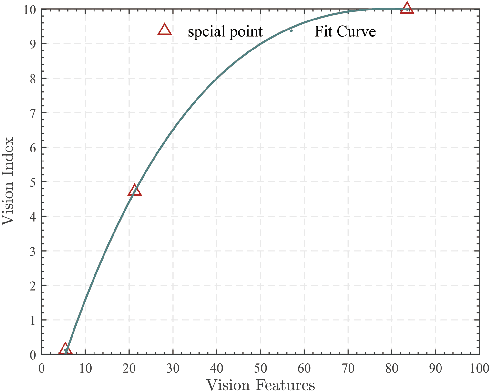
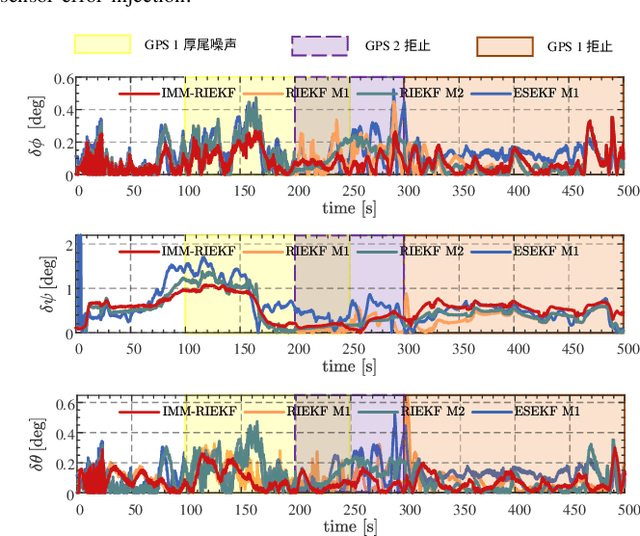
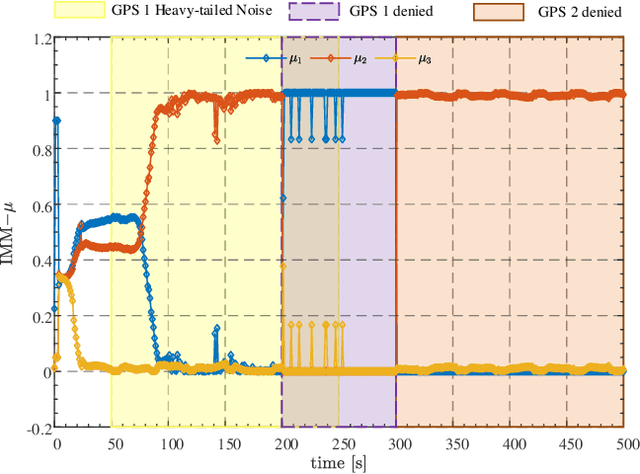
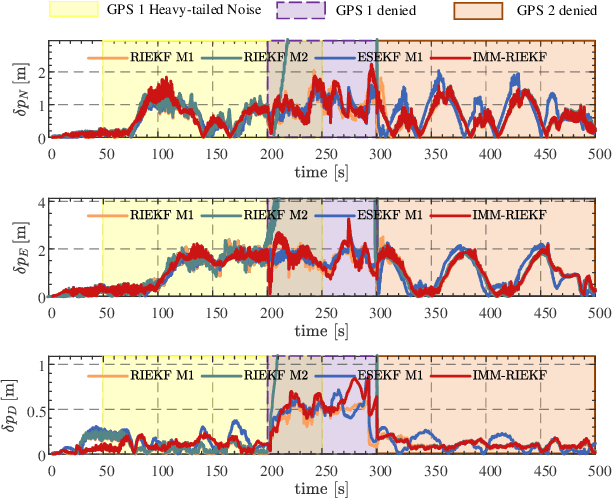
As the number of heterogeneous redundant sensors on unmanned aerial vehicle (UAV) increases, onboard sensors require a more rational and efficient credibility evaluation system and a resilient fusion framework to achieve the essence of seamless sensor group switching. A simple and efficient sensor credibility evaluation system is proposed to guide the selection of the optimal multi-source sensor submodel combination, thereby providing key model prior knowledge for multi-source resilient fusion. Furthermore, a multi-model interactive resilient fusion framework based on RIEKF is proposed, utilizing the defined sensor credibility indexes to guide the design of the model transition probability matrix, thereby reducing the sensitivity of submodel weights to fusion stability and solving the problem of the model transition matrix lacking a basis for adjustment. Model weights are updated in real time through credibility prior information and submodel posterior probabilities, thus leveraging the adaptive resilience advantage between models to achieve seamless switching between submodels in complex environments. Experimental results show that the algorithm presented in this paper, without using any sensor fault diagnosis and isolation logic, without setting any complex detection timing and thresholds, demonstrates a resilience advantage, thereby enhancing the adaptability of the state estimation system in complex environments.
Can Transformers Capture Spatial Relations between Objects?
Mar 01, 2024
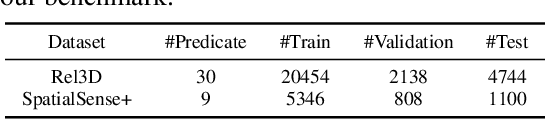


Spatial relationships between objects represent key scene information for humans to understand and interact with the world. To study the capability of current computer vision systems to recognize physically grounded spatial relations, we start by proposing precise relation definitions that permit consistently annotating a benchmark dataset. Despite the apparent simplicity of this task relative to others in the recognition literature, we observe that existing approaches perform poorly on this benchmark. We propose new approaches exploiting the long-range attention capabilities of transformers for this task, and evaluating key design principles. We identify a simple "RelatiViT" architecture and demonstrate that it outperforms all current approaches. To our knowledge, this is the first method to convincingly outperform naive baselines on spatial relation prediction in in-the-wild settings. The code and datasets are available in \url{https://sites.google.com/view/spatial-relation}.
Limits to classification performance by relating Kullback-Leibler divergence to Cohen's Kappa
Mar 03, 2024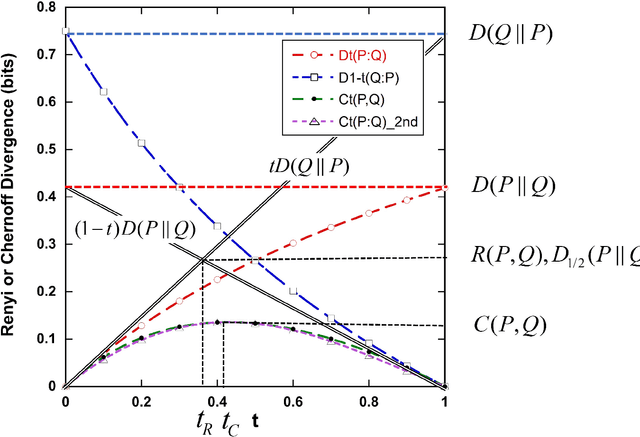
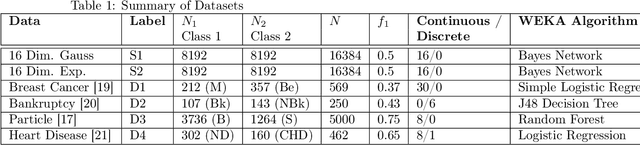
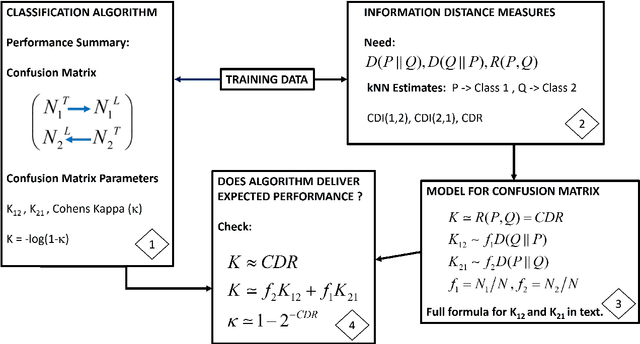

The performance of machine learning classification algorithms are evaluated by estimating metrics, often from the confusion matrix, using training data and cross-validation. However, these do not prove that the best possible performance has been achieved. Fundamental limits to error rates can be estimated using information distance measures. To this end, the confusion matrix has been formulated to comply with the Chernoff-Stein Lemma. This links the error rates to the Kullback-Leibler divergences between the probability density functions describing the two classes. This leads to a key result that relates Cohen's Kappa to the Resistor Average Distance which is the parallel resistor combination of the two Kullback-Leibler divergences. The Resistor Average Distance has units of bits and is estimated from the same training data used by the classification algorithm, using kNN estimates of the KullBack-Leibler divergences. The classification algorithm gives the confusion matrix and Kappa. Theory and methods are discussed in detail and then applied to Monte Carlo data and real datasets. Four very different real datasets - Breast Cancer, Coronary Heart Disease, Bankruptcy, and Particle Identification - are analysed, with both continuous and discrete values, and their classification performance compared to the expected theoretical limit. In all cases this analysis shows that the algorithms could not have performed any better due to the underlying probability density functions for the two classes. Important lessons are learnt on how to predict the performance of algorithms for imbalanced data using training datasets that are approximately balanced. Machine learning is very powerful but classification performance ultimately depends on the quality of the data and the relevance of the variables to the problem.
Enhancing Data Provenance and Model Transparency in Federated Learning Systems -- A Database Approach
Mar 03, 2024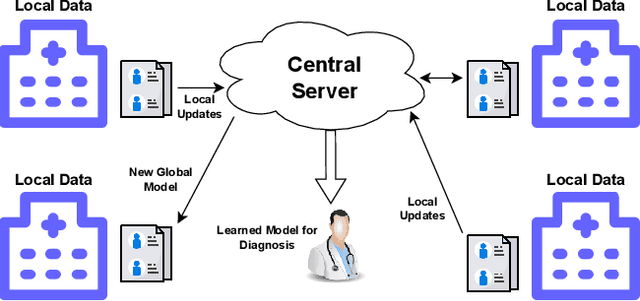
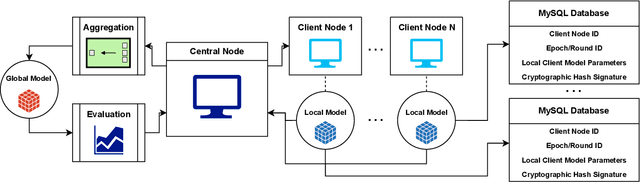
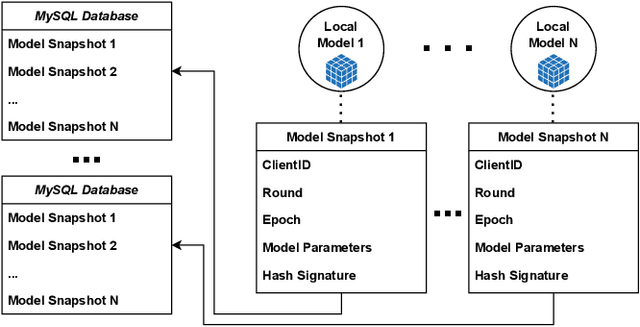
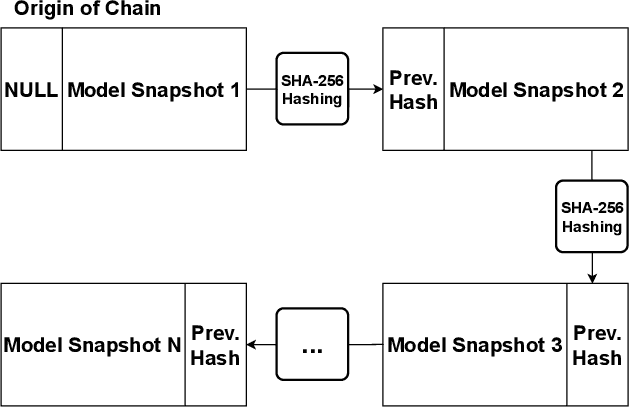
Federated Learning (FL) presents a promising paradigm for training machine learning models across decentralized edge devices while preserving data privacy. Ensuring the integrity and traceability of data across these distributed environments, however, remains a critical challenge. The ability to create transparent artificial intelligence, such as detailing the training process of a machine learning model, has become an increasingly prominent concern due to the large number of sensitive (hyper)parameters it utilizes; thus, it is imperative to strike a reasonable balance between openness and the need to protect sensitive information. In this paper, we propose one of the first approaches to enhance data provenance and model transparency in federated learning systems. Our methodology leverages a combination of cryptographic techniques and efficient model management to track the transformation of data throughout the FL process, and seeks to increase the reproducibility and trustworthiness of a trained FL model. We demonstrate the effectiveness of our approach through experimental evaluations on diverse FL scenarios, showcasing its ability to tackle accountability and explainability across the board. Our findings show that our system can greatly enhance data transparency in various FL environments by storing chained cryptographic hashes and client model snapshots in our proposed design for data decoupled FL. This is made possible by also employing multiple optimization techniques which enables comprehensive data provenance without imposing substantial computational loads. Extensive experimental results suggest that integrating a database subsystem into federated learning systems can improve data provenance in an efficient manner, encouraging secure FL adoption in privacy-sensitive applications and paving the way for future advancements in FL transparency and security features.
Wisdom of the Silicon Crowd: LLM Ensemble Prediction Capabilities Match Human Crowd Accuracy
Feb 29, 2024Human forecasting accuracy in practice relies on the 'wisdom of the crowd' effect, in which predictions about future events are significantly improved by aggregating across a crowd of individual forecasters. Past work on the forecasting ability of large language models (LLMs) suggests that frontier LLMs, as individual forecasters, underperform compared to the gold standard of a human crowd forecasting tournament aggregate. In Study 1, we expand this research by using an LLM ensemble approach consisting of a crowd of twelve LLMs. We compare the aggregated LLM predictions on 31 binary questions to that of a crowd of 925 human forecasters from a three-month forecasting tournament. Our main analysis shows that the LLM crowd outperforms a simple no-information benchmark and is statistically equivalent to the human crowd. We also observe an acquiescence effect, with mean model predictions being significantly above 50%, despite an almost even split of positive and negative resolutions. Moreover, in Study 2, we test whether LLM predictions (of GPT-4 and Claude 2) can be improved by drawing on human cognitive output. We find that both models' forecasting accuracy benefits from exposure to the median human prediction as information, improving accuracy by between 17% and 28%: though this leads to less accurate predictions than simply averaging human and machine forecasts. Our results suggest that LLMs can achieve forecasting accuracy rivaling that of human crowd forecasting tournaments: via the simple, practically applicable method of forecast aggregation. This replicates the 'wisdom of the crowd' effect for LLMs, and opens up their use for a variety applications throughout society.
A Simple yet Effective Network based on Vision Transformer for Camouflaged Object and Salient Object Detection
Feb 29, 2024Camouflaged object detection (COD) and salient object detection (SOD) are two distinct yet closely-related computer vision tasks widely studied during the past decades. Though sharing the same purpose of segmenting an image into binary foreground and background regions, their distinction lies in the fact that COD focuses on concealed objects hidden in the image, while SOD concentrates on the most prominent objects in the image. Previous works achieved good performance by stacking various hand-designed modules and multi-scale features. However, these carefully-designed complex networks often performed well on one task but not on another. In this work, we propose a simple yet effective network (SENet) based on vision Transformer (ViT), by employing a simple design of an asymmetric ViT-based encoder-decoder structure, we yield competitive results on both tasks, exhibiting greater versatility than meticulously crafted ones. Furthermore, to enhance the Transformer's ability to model local information, which is important for pixel-level binary segmentation tasks, we propose a local information capture module (LICM). We also propose a dynamic weighted loss (DW loss) based on Binary Cross-Entropy (BCE) and Intersection over Union (IoU) loss, which guides the network to pay more attention to those smaller and more difficult-to-find target objects according to their size. Moreover, we explore the issue of joint training of SOD and COD, and propose a preliminary solution to the conflict in joint training, further improving the performance of SOD. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness of our method. The code is available at https://github.com/linuxsino/SENet.
On the Scaling Laws of Geographical Representation in Language Models
Feb 29, 2024Language models have long been shown to embed geographical information in their hidden representations. This line of work has recently been revisited by extending this result to Large Language Models (LLMs). In this paper, we propose to fill the gap between well-established and recent literature by observing how geographical knowledge evolves when scaling language models. We show that geographical knowledge is observable even for tiny models, and that it scales consistently as we increase the model size. Notably, we observe that larger language models cannot mitigate the geographical bias that is inherent to the training data.
COCOA: CBT-based Conversational Counseling Agent using Memory Specialized in Cognitive Distortions and Dynamic Prompt
Feb 27, 2024The demand for conversational agents that provide mental health care is consistently increasing. In this work, we develop a psychological counseling agent, referred to as CoCoA, that applies Cognitive Behavioral Therapy (CBT) techniques to identify and address cognitive distortions inherent in the client's statements. Specifically, we construct a memory system to efficiently manage information necessary for counseling while extracting high-level insights about the client from their utterances. Additionally, to ensure that the counseling agent generates appropriate responses, we introduce dynamic prompting to flexibly apply CBT techniques and facilitate the appropriate retrieval of information. We conducted dialogues between CoCoA and characters from Character.ai, creating a dataset for evaluation. Then, we asked GPT to evaluate the constructed counseling dataset, and our model demonstrated a statistically significant difference from other models.
BitDelta: Your Fine-Tune May Only Be Worth One Bit
Feb 28, 2024Large Language Models (LLMs) are typically trained in two phases: pre-training on large internet-scale datasets, and fine-tuning for downstream tasks. Given the higher computational demand of pre-training, it's intuitive to assume that fine-tuning adds less new information to the model, and is thus more compressible. We explore this assumption by decomposing the weights of fine-tuned models into their pre-trained components and an additional delta. We introduce a simple method, BitDelta, which successfully quantizes this delta down to 1 bit without compromising performance. This interesting finding not only highlights the potential redundancy of information added during fine-tuning, but also has significant implications for the multi-tenant serving and multi-tenant storage of fine-tuned models. By enabling the use of a single high-precision base model accompanied by multiple 1-bit deltas, BitDelta dramatically reduces GPU memory requirements by more than 10x, which can also be translated to enhanced generation latency in multi-tenant settings. We validate BitDelta through experiments across Llama-2 and Mistral model families, and on models up to 70B parameters, showcasing minimal performance degradation over all tested settings.
Learning Invariant Inter-pixel Correlations for Superpixel Generation
Feb 28, 2024Deep superpixel algorithms have made remarkable strides by substituting hand-crafted features with learnable ones. Nevertheless, we observe that existing deep superpixel methods, serving as mid-level representation operations, remain sensitive to the statistical properties (e.g., color distribution, high-level semantics) embedded within the training dataset. Consequently, learnable features exhibit constrained discriminative capability, resulting in unsatisfactory pixel grouping performance, particularly in untrainable application scenarios. To address this issue, we propose the Content Disentangle Superpixel (CDS) algorithm to selectively separate the invariant inter-pixel correlations and statistical properties, i.e., style noise. Specifically, We first construct auxiliary modalities that are homologous to the original RGB image but have substantial stylistic variations. Then, driven by mutual information, we propose the local-grid correlation alignment across modalities to reduce the distribution discrepancy of adaptively selected features and learn invariant inter-pixel correlations. Afterwards, we perform global-style mutual information minimization to enforce the separation of invariant content and train data styles. The experimental results on four benchmark datasets demonstrate the superiority of our approach to existing state-of-the-art methods, regarding boundary adherence, generalization, and efficiency. Code and pre-trained model are available at https://github.com/rookiie/CDSpixel.