 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Learning for Discovery
May 30, 2022
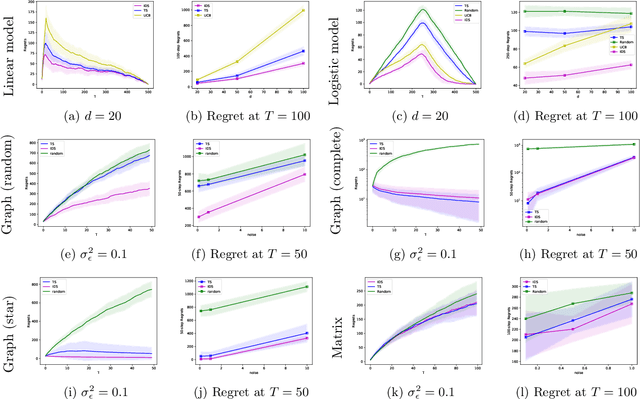
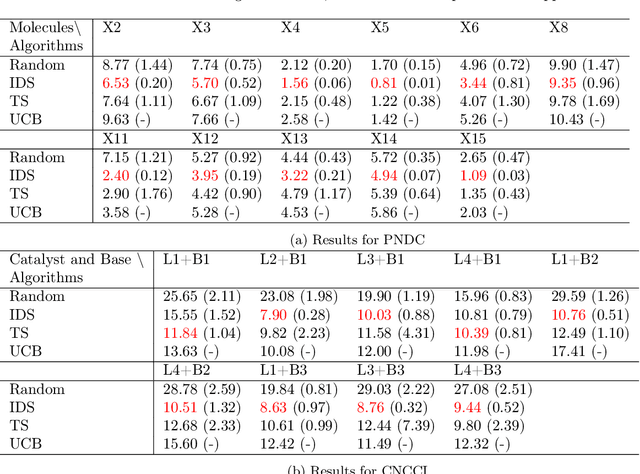
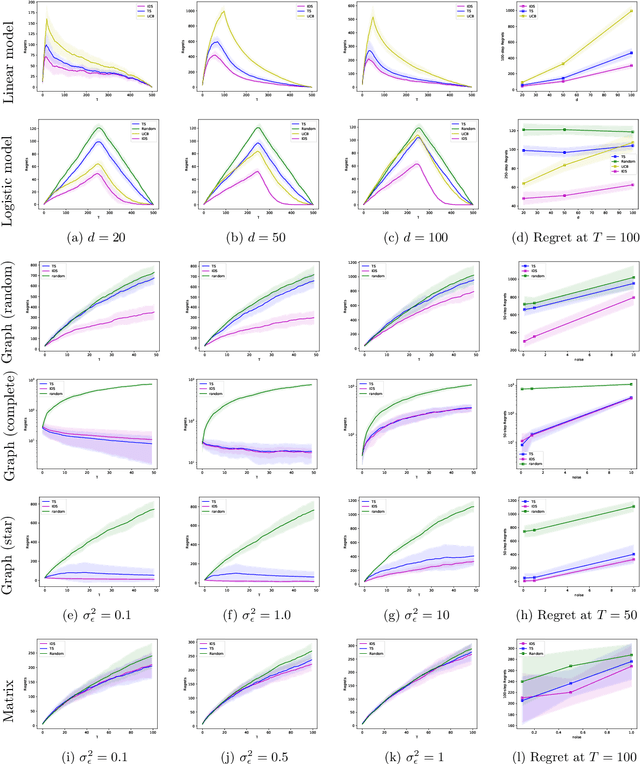
In this paper, we study a sequential decision-making problem, called Adaptive Sampling for Discovery (ASD). Starting with a large unlabeled dataset, algorithms for ASD adaptively label the points with the goal to maximize the sum of responses. This problem has wide applications to real-world discovery problems, for example drug discovery with the help of machine learning models. ASD algorithms face the well-known exploration-exploitation dilemma. The algorithm needs to choose points that yield information to improve model estimates but it also needs to exploit the model. We rigorously formulate the problem and propose a general information-directed sampling (IDS) algorithm. We provide theoretical guarantees for the performance of IDS in linear, graph and low-rank models. The benefits of IDS are shown in both simulation experiments and real-data experiments for discovering chemical reaction conditions.
Canonical Cortical Graph Neural Networks and its Application for Speech Enhancement in Future Audio-Visual Hearing Aids
Jun 06, 2022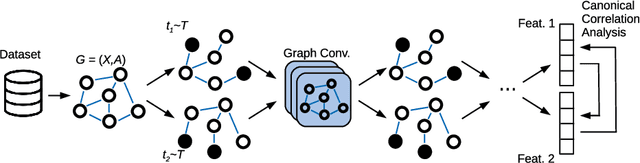
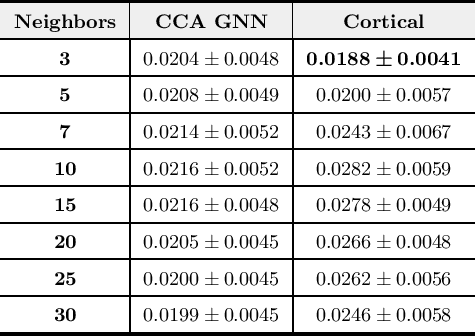
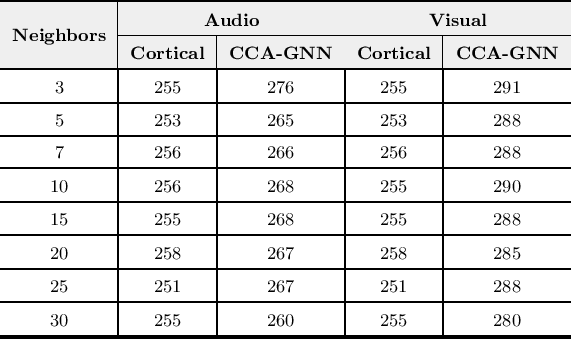
Despite the recent success of machine learning algorithms, most of these models still face several drawbacks when considering more complex tasks requiring interaction between different sources, such as multimodal input data and logical time sequence. On the other hand, the biological brain is highly sharpened in this sense, empowered to automatically manage and integrate such a stream of information through millions of years of evolution. In this context, this paper finds inspiration from recent discoveries on cortical circuits in the brain to propose a more biologically plausible self-supervised machine learning approach that combines multimodal information using intra-layer modulations together with canonical correlation analysis (CCA), as well as a memory mechanism to keep track of temporal data, the so-called Canonical Cortical Graph Neural networks. The approach outperformed recent state-of-the-art results considering both better clean audio reconstruction and energy efficiency, described by a reduced and smother neuron firing rate distribution, suggesting the model as a suitable approach for speech enhancement in future audio-visual hearing aid devices.
Going the Extra Mile in Face Image Quality Assessment: A Novel Database and Model
Jul 11, 2022
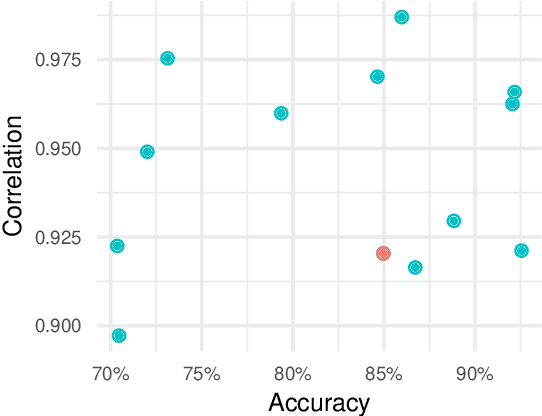

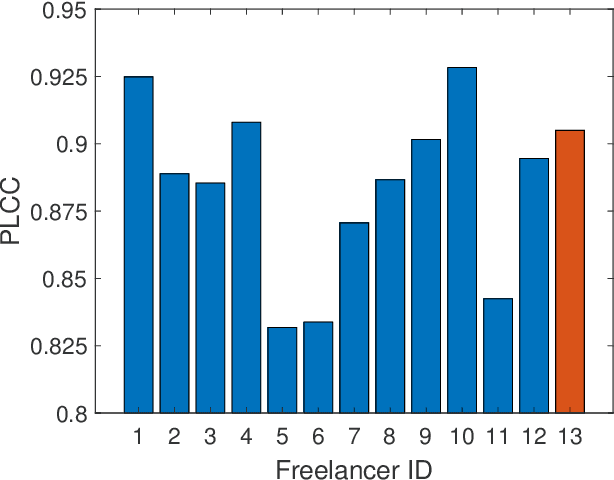
Computer vision models for image quality assessment (IQA) predict the subjective effect of generic image degradation, such as artefacts, blurs, bad exposure, or colors. The scarcity of face images in existing IQA datasets (below 10\%) is limiting the precision of IQA required for accurately filtering low-quality face images or guiding CV models for face image processing, such as super-resolution, image enhancement, and generation. In this paper, we first introduce the largest annotated IQA database to date that contains 20,000 human faces (an order of magnitude larger than all existing rated datasets of faces), of diverse individuals, in highly varied circumstances, quality levels, and distortion types. Based on the database, we further propose a novel deep learning model, which re-purposes generative prior features for predicting subjective face quality. By exploiting rich statistics encoded in well-trained generative models, we obtain generative prior information of the images and serve them as latent references to facilitate the blind IQA task. Experimental results demonstrate the superior prediction accuracy of the proposed model on the face IQA task.
Nonlinear Equalization for Optical Communications Based on Entropy-Regularized Mean Square Error
Jun 02, 2022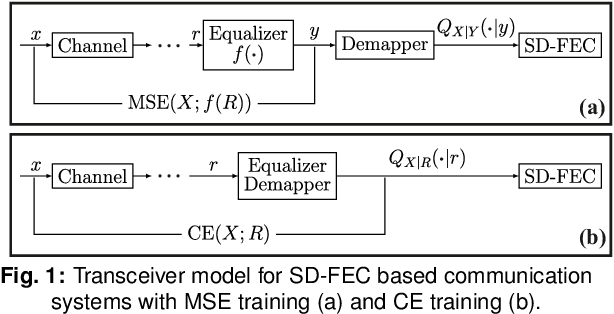
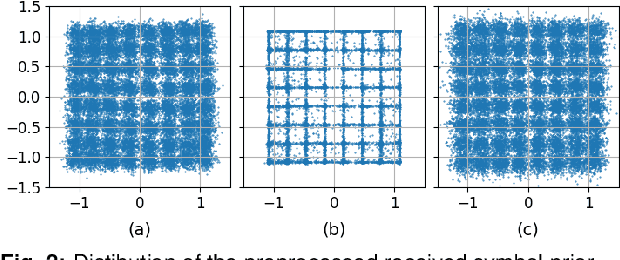
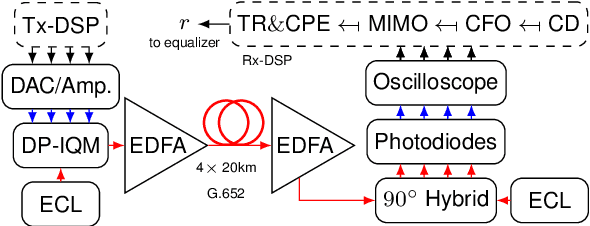
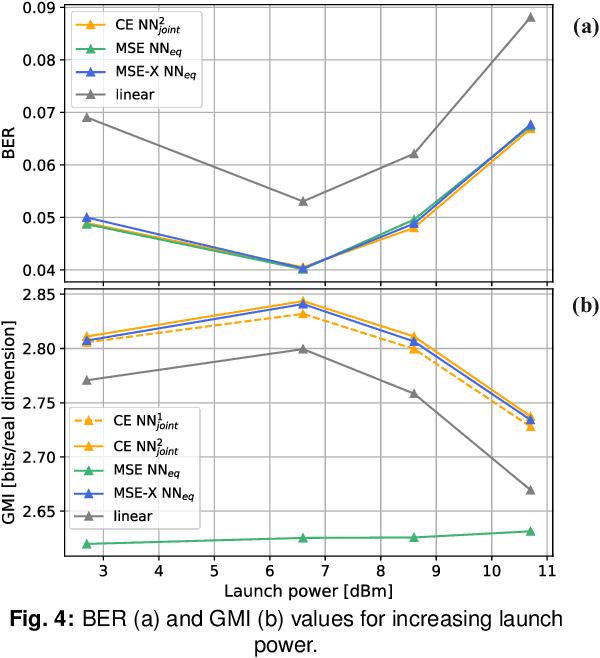
An entropy-regularized mean square error (MSE-X) cost function is proposed for nonlinear equalization of short-reach optical channels. For a coherent optical transmission experiment, MSE-X achieves the same bit error rate as the standard MSE cost function and a significantly higher achievable information rate.
GOCA: Guided Online Cluster Assignment for Self-Supervised Video Representation Learning
Jul 20, 2022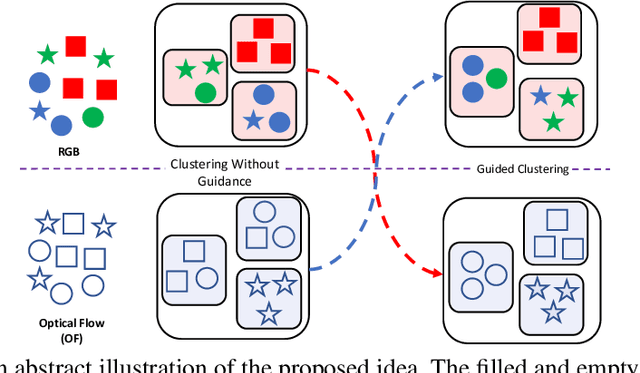
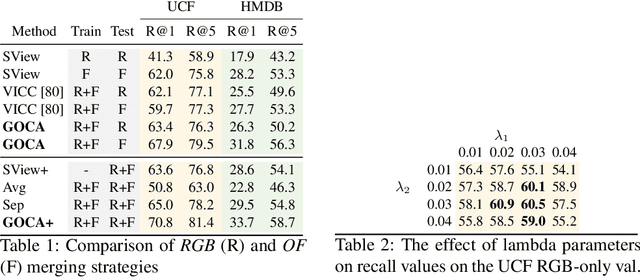
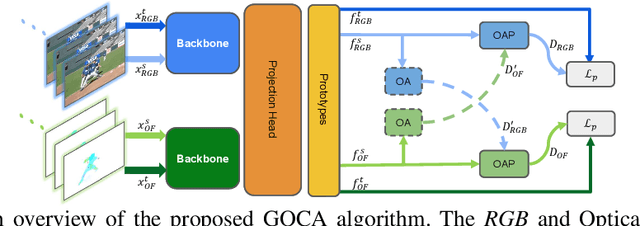

Clustering is a ubiquitous tool in unsupervised learning. Most of the existing self-supervised representation learning methods typically cluster samples based on visually dominant features. While this works well for image-based self-supervision, it often fails for videos, which require understanding motion rather than focusing on background. Using optical flow as complementary information to RGB can alleviate this problem. However, we observe that a naive combination of the two views does not provide meaningful gains. In this paper, we propose a principled way to combine two views. Specifically, we propose a novel clustering strategy where we use the initial cluster assignment of each view as prior to guide the final cluster assignment of the other view. This idea will enforce similar cluster structures for both views, and the formed clusters will be semantically abstract and robust to noisy inputs coming from each individual view. Additionally, we propose a novel regularization strategy to address the feature collapse problem, which is common in cluster-based self-supervised learning methods. Our extensive evaluation shows the effectiveness of our learned representations on downstream tasks, e.g., video retrieval and action recognition. Specifically, we outperform the state of the art by 7% on UCF and 4% on HMDB for video retrieval, and 5% on UCF and 6% on HMDB for video classification
Cross-modal Prototype Driven Network for Radiology Report Generation
Jul 11, 2022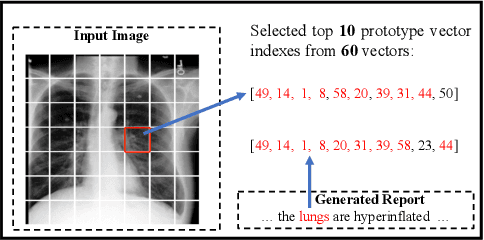
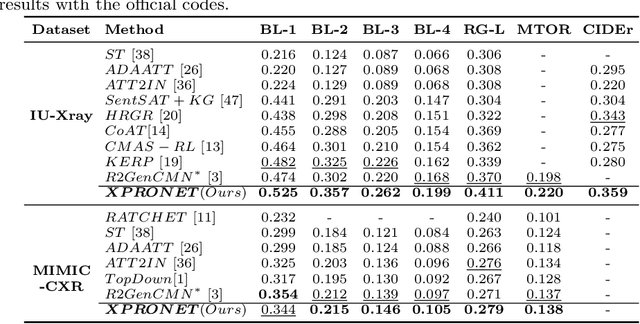
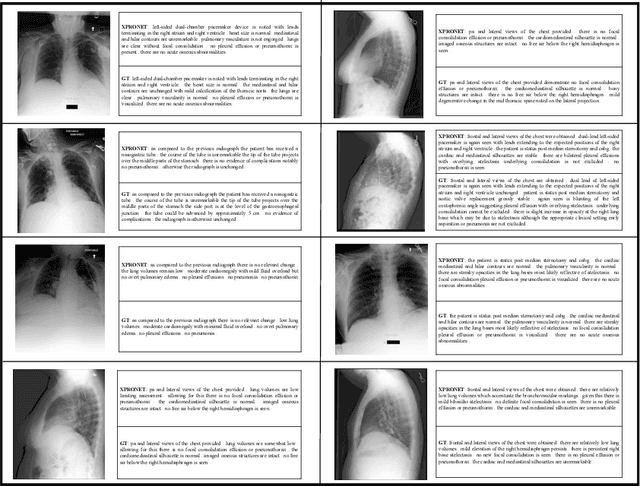
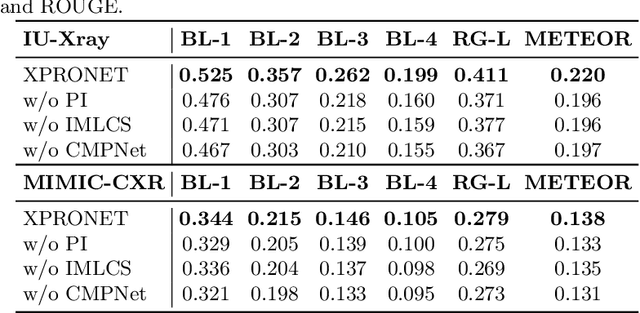
Radiology report generation (RRG) aims to describe automatically a radiology image with human-like language and could potentially support the work of radiologists, reducing the burden of manual reporting. Previous approaches often adopt an encoder-decoder architecture and focus on single-modal feature learning, while few studies explore cross-modal feature interaction. Here we propose a Cross-modal PROtotype driven NETwork (XPRONET) to promote cross-modal pattern learning and exploit it to improve the task of radiology report generation. This is achieved by three well-designed, fully differentiable and complementary modules: a shared cross-modal prototype matrix to record the cross-modal prototypes; a cross-modal prototype network to learn the cross-modal prototypes and embed the cross-modal information into the visual and textual features; and an improved multi-label contrastive loss to enable and enhance multi-label prototype learning. XPRONET obtains substantial improvements on the IU-Xray and MIMIC-CXR benchmarks, where its performance exceeds recent state-of-the-art approaches by a large margin on IU-Xray and comparable performance on MIMIC-CXR.
I Don't Need $\mathbf{u}$: Identifiable Non-Linear ICA Without Side Information
Jun 09, 2021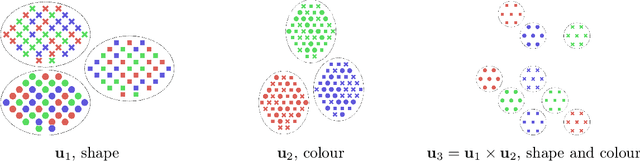
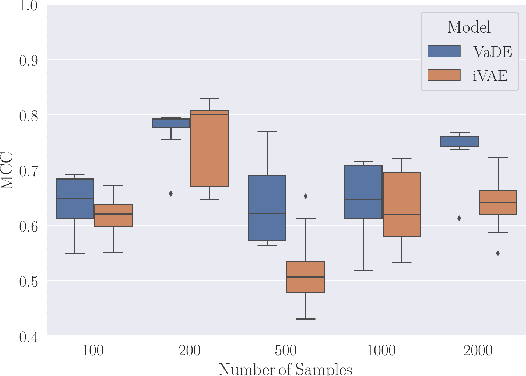

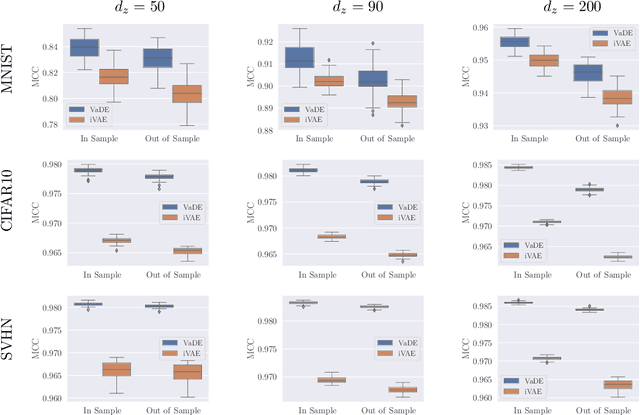
In this work we introduce a new approach for identifiable non-linear ICA models. Recently there has been a renaissance in identifiability results in deep generative models, not least for non-linear ICA. These prior works, however, have assumed access to a sufficiently-informative auxiliary set of observations, denoted $\mathbf{u}$. We show here how identifiability can be obtained in the absence of this side-information, rendering possible fully-unsupervised identifiable non-linear ICA. While previous theoretical results have established the impossibility of identifiable non-linear ICA in the presence of infinitely-flexible universal function approximators, here we rely on the intrinsically-finite modelling capacity of any particular chosen parameterisation of a deep generative model. In particular, we focus on generative models which perform clustering in their latent space -- a model structure which matches previous identifiable models, but with the learnt clustering providing a synthetic form of auxiliary information. We evaluate our proposals using VAEs, on synthetic and image datasets, and find that the learned clusterings function effectively: deep generative models with latent clusterings are empirically identifiable, to the same degree as models which rely on side information.
BoT-SORT: Robust Associations Multi-Pedestrian Tracking
Jun 29, 2022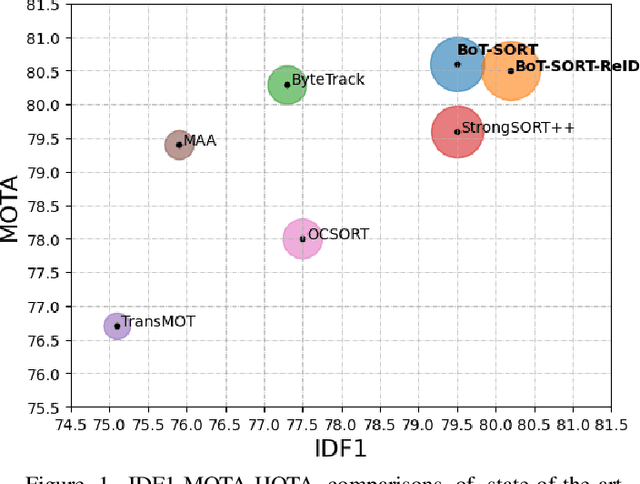

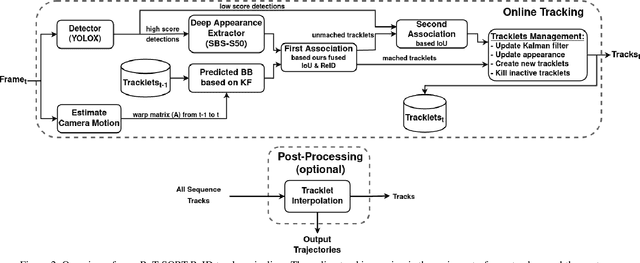
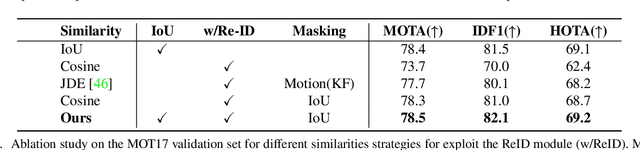
The goal of multi-object tracking (MOT) is detecting and tracking all the objects in a scene, while keeping a unique identifier for each object. In this paper, we present a new robust state-of-the-art tracker, which can combine the advantages of motion and appearance information, along with camera-motion compensation, and a more accurate Kalman filter state vector. Our new trackers BoT-SORT, and BoT-SORT-ReID rank first in the datasets of MOTChallenge [29, 11] on both MOT17 and MOT20 test sets, in terms of all the main MOT metrics: MOTA, IDF1, and HOTA. For MOT17: 80.5 MOTA, 80.2 IDF1, and 65.0 HOTA are achieved. The source code and the pre-trained models are available at https://github.com/NirAharon/BOT-SORT
Speech enhancement guided by contextual articulatory information
Nov 15, 2020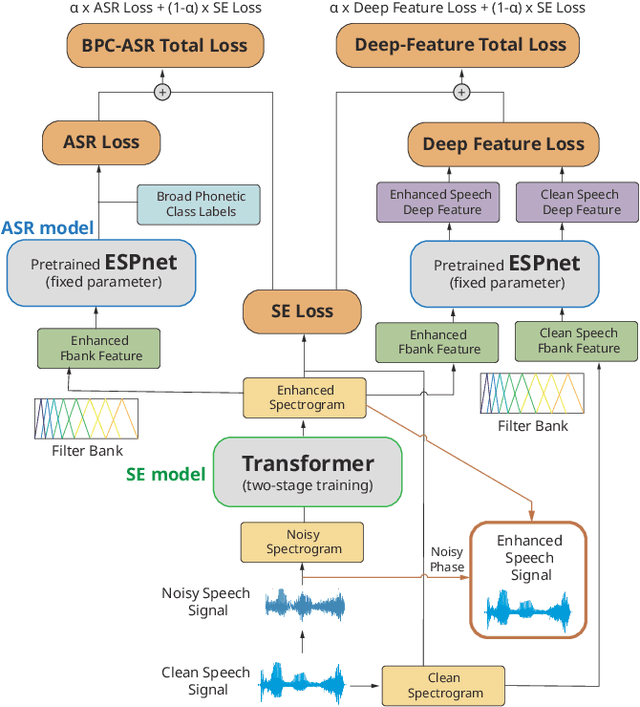
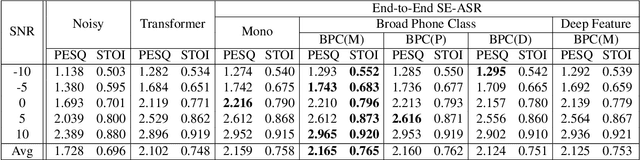
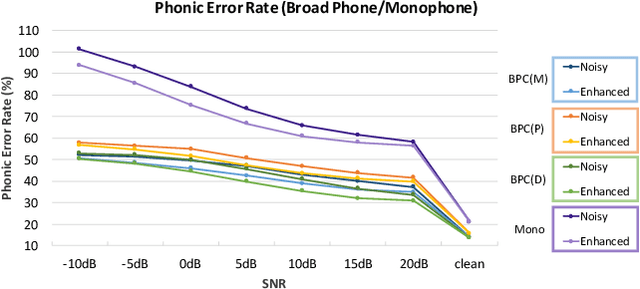
Previous studies have confirmed the effectiveness of leveraging articulatory information to attain improved speech enhancement (SE) performance. By augmenting the original acoustic features with the place/manner of articulatory features, the SE process can be guided to consider the articulatory properties of the input speech when performing enhancement. Hence, we believe that the contextual information of articulatory attributes should include useful information and can further benefit SE. In this study, we propose an SE system that incorporates contextual articulatory information; such information is obtained using broad phone class (BPC) end-to-end automatic speech recognition (ASR). Meanwhile, two training strategies are developed to train the SE system based on the BPC-based ASR: multitask-learning and deep-feature training strategies. Experimental results on the TIMIT dataset confirm that the contextual articulatory information facilitates an SE system in achieving better results. Moreover, in contrast to another SE system that is trained with monophonic ASR, the BPC-based ASR (providing contextual articulatory information) can improve the SE performance more effectively under different signal-to-noise ratios(SNR).
Multimodal Dialogue State Tracking
Jun 16, 2022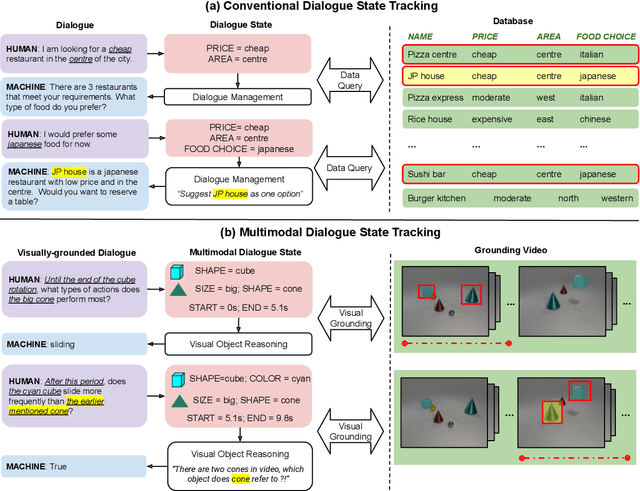
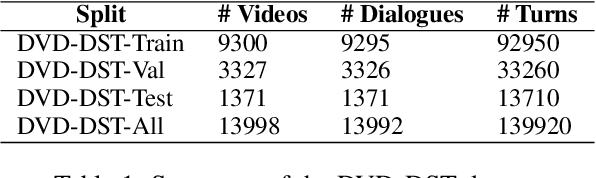
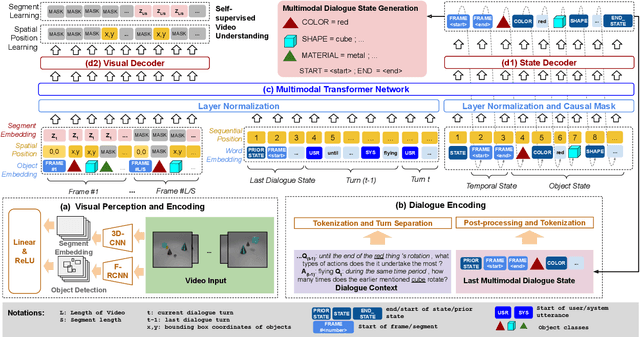
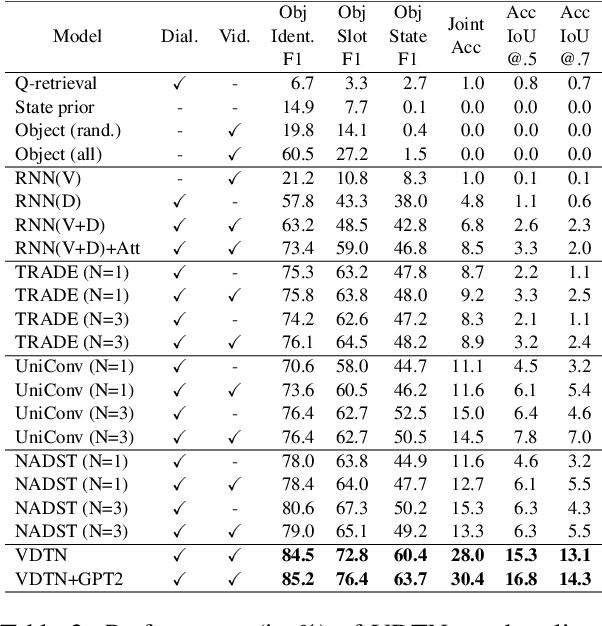
Designed for tracking user goals in dialogues, a dialogue state tracker is an essential component in a dialogue system. However, the research of dialogue state tracking has largely been limited to unimodality, in which slots and slot values are limited by knowledge domains (e.g. restaurant domain with slots of restaurant name and price range) and are defined by specific database schema. In this paper, we propose to extend the definition of dialogue state tracking to multimodality. Specifically, we introduce a novel dialogue state tracking task to track the information of visual objects that are mentioned in video-grounded dialogues. Each new dialogue utterance may introduce a new video segment, new visual objects, or new object attributes, and a state tracker is required to update these information slots accordingly. We created a new synthetic benchmark and designed a novel baseline, Video-Dialogue Transformer Network (VDTN), for this task. VDTN combines both object-level features and segment-level features and learns contextual dependencies between videos and dialogues to generate multimodal dialogue states. We optimized VDTN for a state generation task as well as a self-supervised video understanding task which recovers video segment or object representations. Finally, we trained VDTN to use the decoded states in a response prediction task. Together with comprehensive ablation and qualitative analysis, we discovered interesting insights towards building more capable multimodal dialogue systems.