 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semi-unsupervised Learning for Time Series Classification
Jul 13, 2022
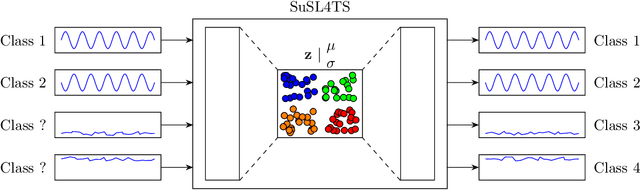


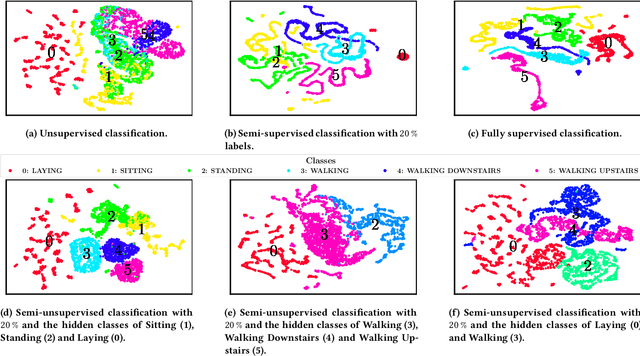
Time series are ubiquitous and therefore inherently hard to analyze and ultimately to label or cluster. With the rise of the Internet of Things (IoT) and its smart devices, data is collected in large amounts any given second. The collected data is rich in information, as one can detect accidents (e.g. cars) in real time, or assess injury/sickness over a given time span (e.g. health devices). Due to its chaotic nature and massive amounts of datapoints, timeseries are hard to label manually. Furthermore new classes within the data could emerge over time (contrary to e.g. handwritten digits), which would require relabeling the data. In this paper we present SuSL4TS, a deep generative Gaussian mixture model for semi-unsupervised learning, to classify time series data. With our approach we can alleviate manual labeling steps, since we can detect sparsely labeled classes (semi-supervised) and identify emerging classes hidden in the data (unsupervised). We demonstrate the efficacy of our approach with established time series classification datasets from different domains.
Content-aware Scalable Deep Compressed Sensing
Jul 19, 2022To more efficiently address image compressed sensing (CS) problems, we present a novel content-aware scalable network dubbed CASNet which collectively achieves adaptive sampling rate allocation, fine granular scalability and high-quality reconstruction. We first adopt a data-driven saliency detector to evaluate the importances of different image regions and propose a saliency-based block ratio aggregation (BRA) strategy for sampling rate allocation. A unified learnable generating matrix is then developed to produce sampling matrix of any CS ratio with an ordered structure. Being equipped with the optimization-inspired recovery subnet guided by saliency information and a multi-block training scheme preventing blocking artifacts, CASNet jointly reconstructs the image blocks sampled at various sampling rates with one single model. To accelerate training convergence and improve network robustness, we propose an SVD-based initialization scheme and a random transformation enhancement (RTE) strategy, which are extensible without introducing extra parameters. All the CASNet components can be combined and learned end-to-end. We further provide a four-stage implementation for evaluation and practical deployments. Experiments demonstrate that CASNet outperforms other CS networks by a large margin, validating the collaboration and mutual supports among its components and strategies. Codes are available at https://github.com/Guaishou74851/CASNet.
Using Mixed-Effect Models to Learn Bayesian Networks from Related Data Sets
Jun 08, 2022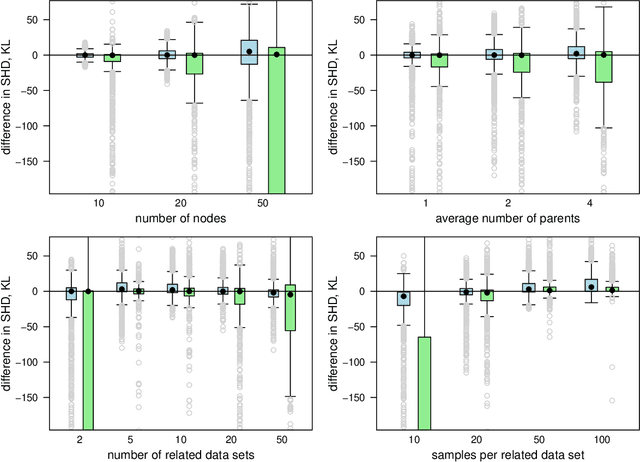
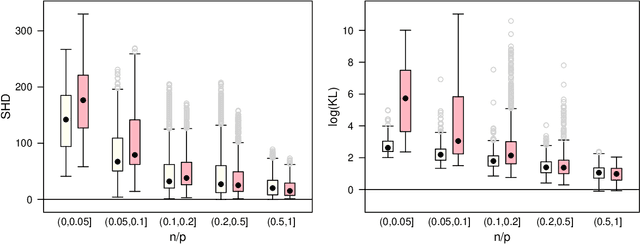
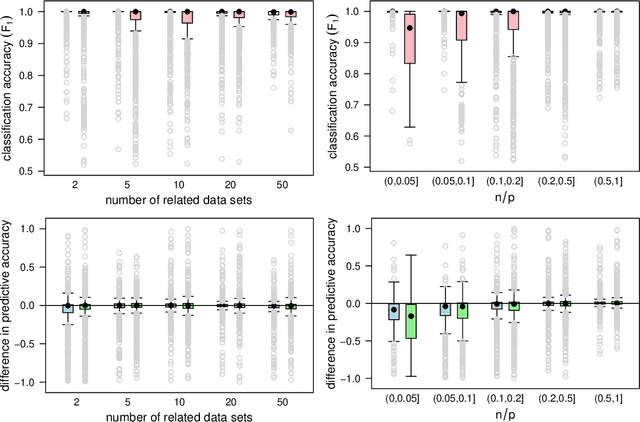
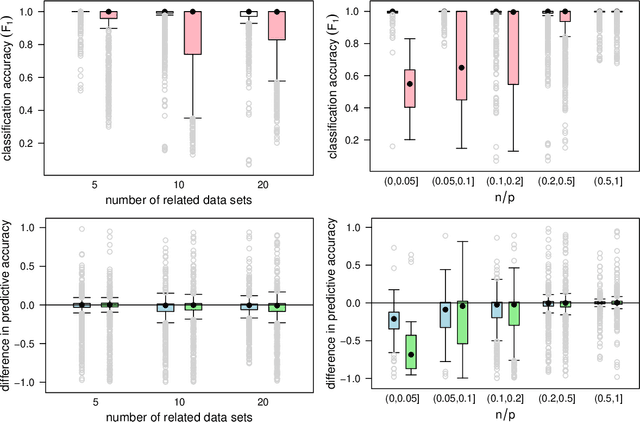
We commonly assume that data are a homogeneous set of observations when learning the structure of Bayesian networks. However, they often comprise different data sets that are related but not homogeneous because they have been collected in different ways or from different populations. In our previous work (Azzimonti, Corani and Scutari, 2021), we proposed a closed-form Bayesian Hierarchical Dirichlet score for discrete data that pools information across related data sets to learn a single encompassing network structure, while taking into account the differences in their probabilistic structures. In this paper, we provide an analogous solution for learning a Bayesian network from continuous data using mixed-effects models to pool information across the related data sets. We study its structural, parametric, predictive and classification accuracy and we show that it outperforms both conditional Gaussian Bayesian networks (that do not perform any pooling) and classical Gaussian Bayesian networks (that disregard the heterogeneous nature of the data). The improvement is marked for low sample sizes and for unbalanced data sets.
AutoTransition: Learning to Recommend Video Transition Effects
Jul 27, 2022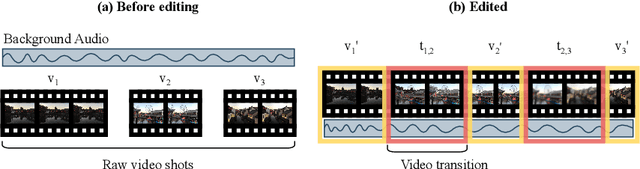
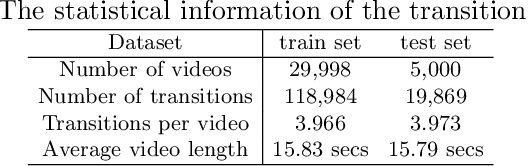
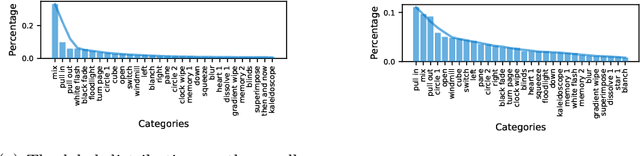
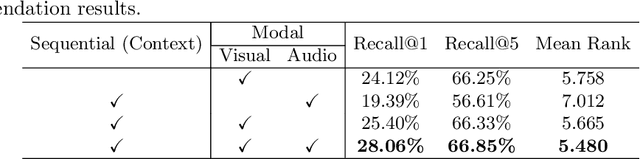
Video transition effects are widely used in video editing to connect shots for creating cohesive and visually appealing videos. However, it is challenging for non-professionals to choose best transitions due to the lack of cinematographic knowledge and design skills. In this paper, we present the premier work on performing automatic video transitions recommendation (VTR): given a sequence of raw video shots and companion audio, recommend video transitions for each pair of neighboring shots. To solve this task, we collect a large-scale video transition dataset using publicly available video templates on editing softwares. Then we formulate VTR as a multi-modal retrieval problem from vision/audio to video transitions and propose a novel multi-modal matching framework which consists of two parts. First we learn the embedding of video transitions through a video transition classification task. Then we propose a model to learn the matching correspondence from vision/audio inputs to video transitions. Specifically, the proposed model employs a multi-modal transformer to fuse vision and audio information, as well as capture the context cues in sequential transition outputs. Through both quantitative and qualitative experiments, we clearly demonstrate the effectiveness of our method. Notably, in the comprehensive user study, our method receives comparable scores compared with professional editors while improving the video editing efficiency by \textbf{300\scalebox{1.25}{$\times$}}. We hope our work serves to inspire other researchers to work on this new task. The dataset and codes are public at \url{https://github.com/acherstyx/AutoTransition}.
Efficient Robotic Manipulation Through Offline-to-Online Reinforcement Learning and Goal-Aware State Information
Oct 21, 2021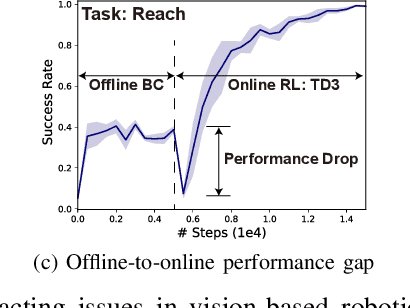
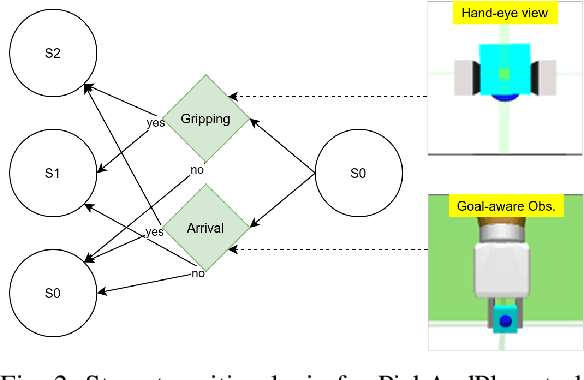
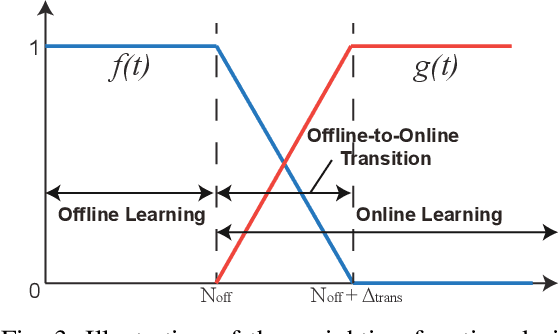
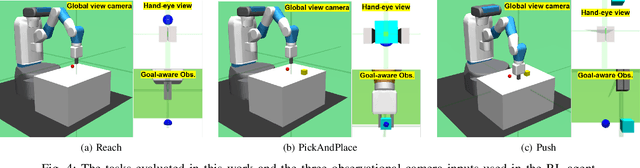
End-to-end learning robotic manipulation with high data efficiency is one of the key challenges in robotics. The latest methods that utilize human demonstration data and unsupervised representation learning has proven to be a promising direction to improve RL learning efficiency. The use of demonstration data also allows "warming-up" the RL policies using offline data with imitation learning or the recently emerged offline reinforcement learning algorithms. However, existing works often treat offline policy learning and online exploration as two separate processes, which are often accompanied by severe performance drop during the offline-to-online transition. Furthermore, many robotic manipulation tasks involve complex sub-task structures, which are very challenging to be solved in RL with sparse reward. In this work, we propose a unified offline-to-online RL framework that resolves the transition performance drop issue. Additionally, we introduce goal-aware state information to the RL agent, which can greatly reduce task complexity and accelerate policy learning. Combined with an advanced unsupervised representation learning module, our framework achieves great training efficiency and performance compared with the state-of-the-art methods in multiple robotic manipulation tasks.
Patching Leaks in the Charformer for Efficient Character-Level Generation
May 27, 2022

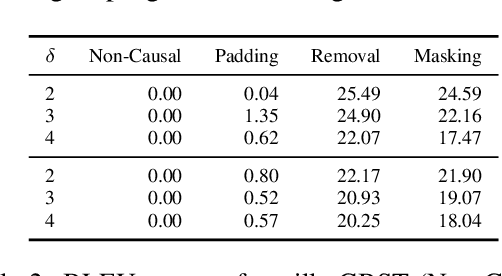
Character-based representations have important advantages over subword-based ones for morphologically rich languages. They come with increased robustness to noisy input and do not need a separate tokenization step. However, they also have a crucial disadvantage: they notably increase the length of text sequences. The GBST method from Charformer groups (aka downsamples) characters to solve this, but allows information to leak when applied to a Transformer decoder. We solve this information leak issue, thereby enabling character grouping in the decoder. We show that Charformer downsampling has no apparent benefits in NMT over previous downsampling methods in terms of translation quality, however it can be trained roughly 30% faster. Promising performance on English--Turkish translation indicate the potential of character-level models for morphologically-rich languages.
Better Call the Plumber: Orchestrating Dynamic Information Extraction Pipelines
Feb 22, 2021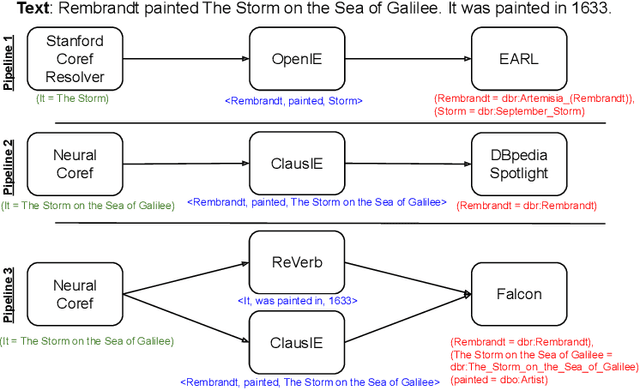
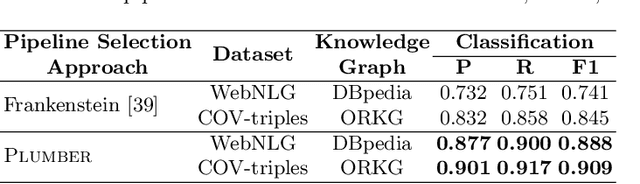
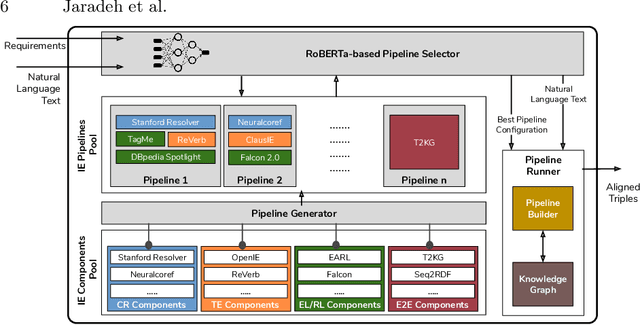
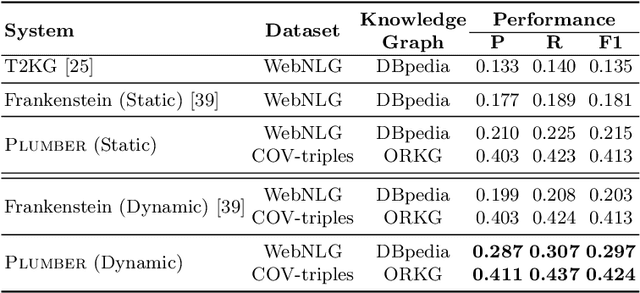
In the last decade, a large number of Knowledge Graph (KG) information extraction approaches were proposed. Albeit effective, these efforts are disjoint, and their collective strengths and weaknesses in effective KG information extraction (IE) have not been studied in the literature. We propose Plumber, the first framework that brings together the research community's disjoint IE efforts. The Plumber architecture comprises 33 reusable components for various KG information extraction subtasks, such as coreference resolution, entity linking, and relation extraction. Using these components,Plumber dynamically generates suitable information extraction pipelines and offers overall 264 distinct pipelines.We study the optimization problem of choosing suitable pipelines based on input sentences. To do so, we train a transformer-based classification model that extracts contextual embeddings from the input and finds an appropriate pipeline. We study the efficacy of Plumber for extracting the KG triples using standard datasets over two KGs: DBpedia, and Open Research Knowledge Graph (ORKG). Our results demonstrate the effectiveness of Plumber in dynamically generating KG information extraction pipelines,outperforming all baselines agnostics of the underlying KG. Furthermore,we provide an analysis of collective failure cases, study the similarities and synergies among integrated components, and discuss their limitations.
Visual Perturbation-aware Collaborative Learning for Overcoming the Language Prior Problem
Jul 24, 2022
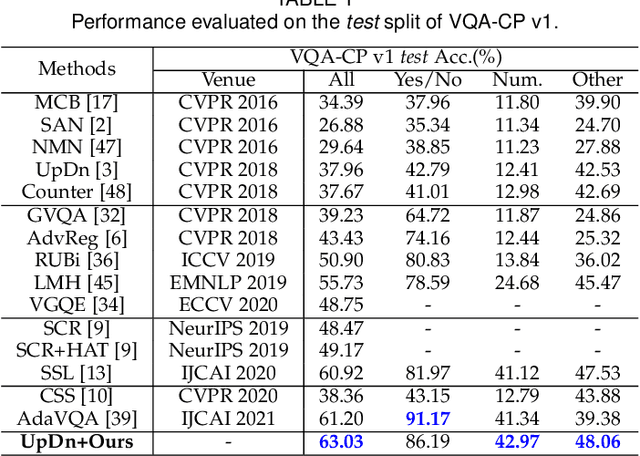
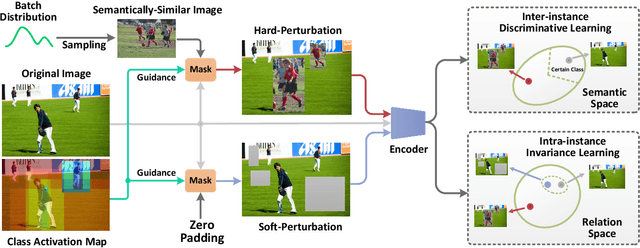
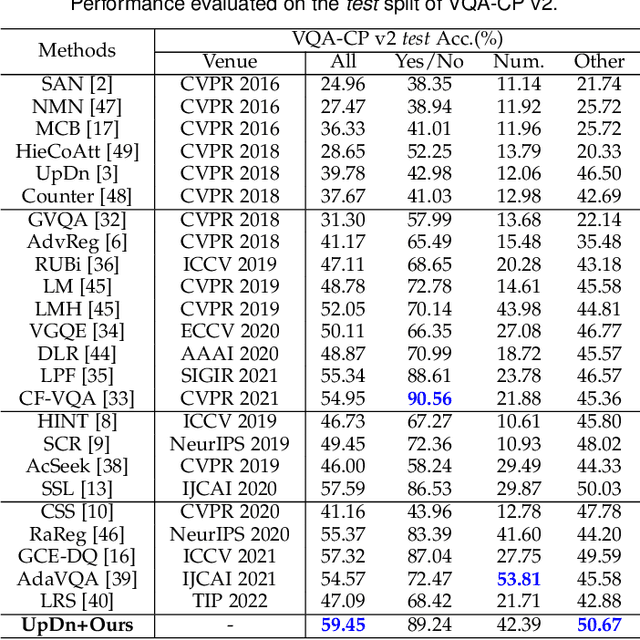
Several studies have recently pointed that existing Visual Question Answering (VQA) models heavily suffer from the language prior problem, which refers to capturing superficial statistical correlations between the question type and the answer whereas ignoring the image contents. Numerous efforts have been dedicated to strengthen the image dependency by creating the delicate models or introducing the extra visual annotations. However, these methods cannot sufficiently explore how the visual cues explicitly affect the learned answer representation, which is vital for language reliance alleviation. Moreover, they generally emphasize the class-level discrimination of the learned answer representation, which overlooks the more fine-grained instance-level patterns and demands further optimization. In this paper, we propose a novel collaborative learning scheme from the viewpoint of visual perturbation calibration, which can better investigate the fine-grained visual effects and mitigate the language prior problem by learning the instance-level characteristics. Specifically, we devise a visual controller to construct two sorts of curated images with different perturbation extents, based on which the collaborative learning of intra-instance invariance and inter-instance discrimination is implemented by two well-designed discriminators. Besides, we implement the information bottleneck modulator on latent space for further bias alleviation and representation calibration. We impose our visual perturbation-aware framework to three orthodox baselines and the experimental results on two diagnostic VQA-CP benchmark datasets evidently demonstrate its effectiveness. In addition, we also justify its robustness on the balanced VQA benchmark.
TransNorm: Transformer Provides a Strong Spatial Normalization Mechanism for a Deep Segmentation Model
Jul 27, 2022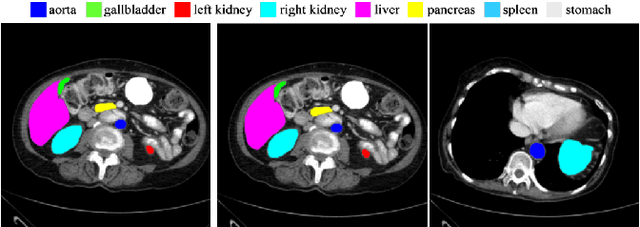

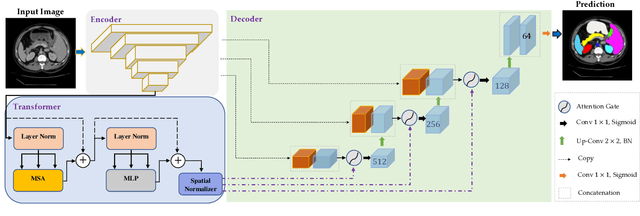
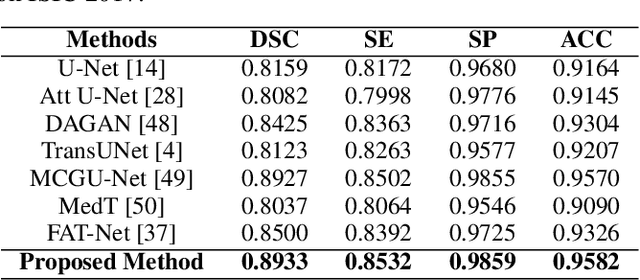
In the past few years, convolutional neural networks (CNNs), particularly U-Net, have been the prevailing technique in the medical image processing era. Specifically, the seminal U-Net, as well as its alternatives, have successfully managed to address a wide variety of medical image segmentation tasks. However, these architectures are intrinsically imperfect as they fail to exhibit long-range interactions and spatial dependencies leading to a severe performance drop in the segmentation of medical images with variable shapes and structures. Transformers, preliminary proposed for sequence-to-sequence prediction, have arisen as surrogate architectures to precisely model global information assisted by the self-attention mechanism. Despite being feasibly designed, utilizing a pure Transformer for image segmentation purposes can result in limited localization capacity stemming from inadequate low-level features. Thus, a line of research strives to design robust variants of Transformer-based U-Net. In this paper, we propose Trans-Norm, a novel deep segmentation framework which concomitantly consolidates a Transformer module into both encoder and skip-connections of the standard U-Net. We argue that the expedient design of skip-connections can be crucial for accurate segmentation as it can assist in feature fusion between the expanding and contracting paths. In this respect, we derive a Spatial Normalization mechanism from the Transformer module to adaptively recalibrate the skip connection path. Extensive experiments across three typical tasks for medical image segmentation demonstrate the effectiveness of TransNorm. The codes and trained models are publicly available at https://github.com/rezazad68/transnorm.
Single Stage Virtual Try-on via Deformable Attention Flows
Jul 19, 2022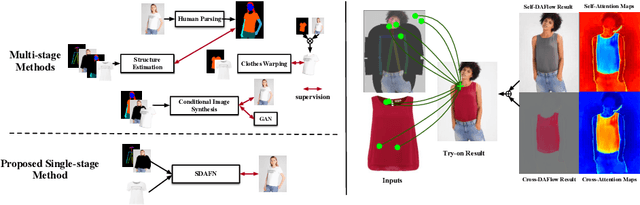

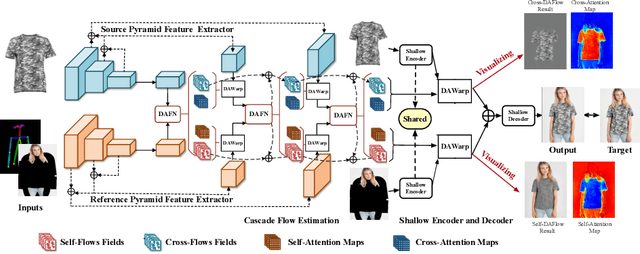
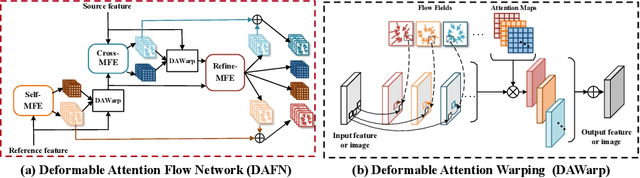
Virtual try-on aims to generate a photo-realistic fitting result given an in-shop garment and a reference person image. Existing methods usually build up multi-stage frameworks to deal with clothes warping and body blending respectively, or rely heavily on intermediate parser-based labels which may be noisy or even inaccurate. To solve the above challenges, we propose a single-stage try-on framework by developing a novel Deformable Attention Flow (DAFlow), which applies the deformable attention scheme to multi-flow estimation. With pose keypoints as the guidance only, the self- and cross-deformable attention flows are estimated for the reference person and the garment images, respectively. By sampling multiple flow fields, the feature-level and pixel-level information from different semantic areas are simultaneously extracted and merged through the attention mechanism. It enables clothes warping and body synthesizing at the same time which leads to photo-realistic results in an end-to-end manner. Extensive experiments on two try-on datasets demonstrate that our proposed method achieves state-of-the-art performance both qualitatively and quantitatively. Furthermore, additional experiments on the other two image editing tasks illustrate the versatility of our method for multi-view synthesis and image animation.