 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reconstruct from Top View: A 3D Lane Detection Approach based on Geometry Structure Prior
Jun 21, 2022
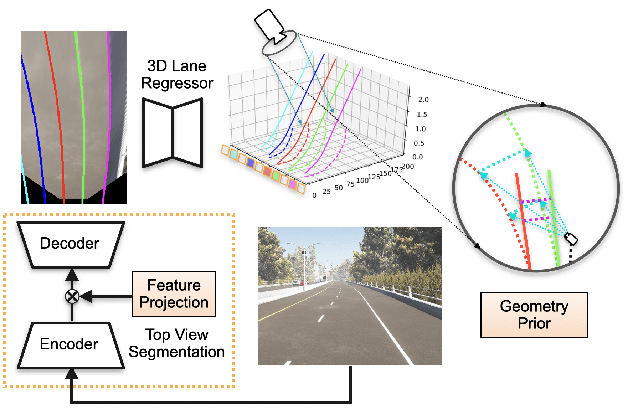
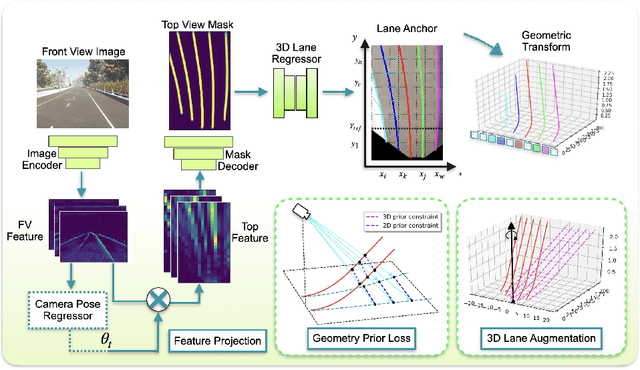
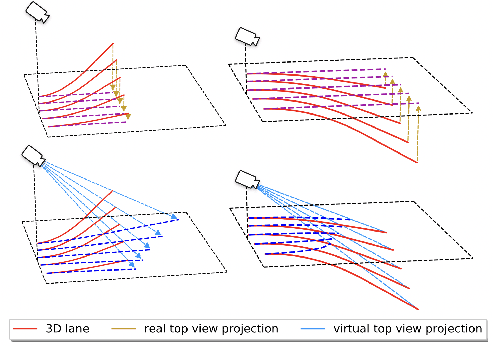
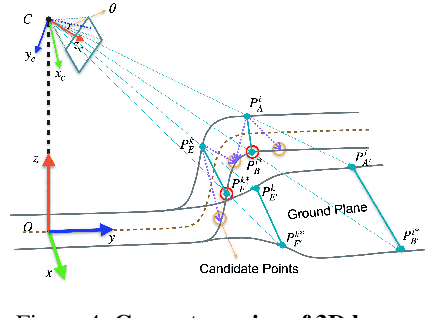
In this paper, we propose an advanced approach in targeting the problem of monocular 3D lane detection by leveraging geometry structure underneath the process of 2D to 3D lane reconstruction. Inspired by previous methods, we first analyze the geometry heuristic between the 3D lane and its 2D representation on the ground and propose to impose explicit supervision based on the structure prior, which makes it achievable to build inter-lane and intra-lane relationships to facilitate the reconstruction of 3D lanes from local to global. Second, to reduce the structure loss in 2D lane representation, we directly extract top view lane information from front view images, which tremendously eases the confusion of distant lane features in previous methods. Furthermore, we propose a novel task-specific data augmentation method by synthesizing new training data for both segmentation and reconstruction tasks in our pipeline, to counter the imbalanced data distribution of camera pose and ground slope to improve generalization on unseen data. Our work marks the first attempt to employ the geometry prior information into DNN-based 3D lane detection and makes it achievable for detecting lanes in an extra-long distance, doubling the original detection range. The proposed method can be smoothly adopted by other frameworks without extra costs. Experimental results show that our work outperforms state-of-the-art approaches by 3.8% F-Score on Apollo 3D synthetic dataset at real-time speed of 82 FPS without introducing extra parameters.
Towards Optimizing OCR for Accessibility
Jun 24, 2022



Visual cues such as structure, emphasis, and icons play an important role in efficient information foraging by sighted individuals and make for a pleasurable reading experience. Blind, low-vision and other print-disabled individuals miss out on these cues since current OCR and text-to-speech software ignore them, resulting in a tedious reading experience. We identify four semantic goals for an enjoyable listening experience, and identify syntactic visual cues that help make progress towards these goals. Empirically, we find that preserving even one or two visual cues in aural form significantly enhances the experience for listening to print content.
Upper Limb Movement Recognition utilising EEG and EMG Signals for Rehabilitative Robotics
Jul 25, 2022
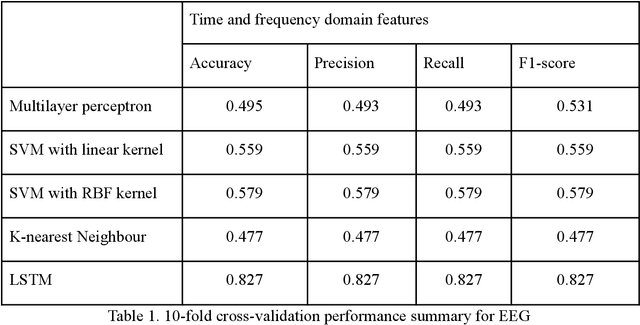
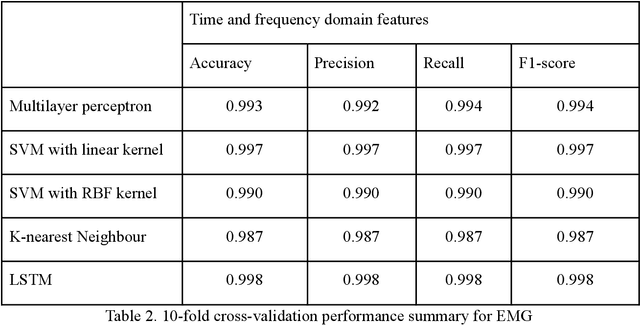
Upper limb movement classification, which maps input signals to the target activities, is one of the crucial areas in the control of rehabilitative robotics. Classifiers are trained for the rehabilitative system to comprehend the desires of the patient whose upper limbs do not function properly. Electromyography (EMG) signals and Electroencephalography (EEG) signals are used widely for upper limb movement classification. By analysing the classification results of the real-time EEG and EMG signals, the system can understand the intention of the user and predict the events that one would like to carry out. Accordingly, it will provide external help to the user to assist one to perform the activities. However, not all users process effective EEG and EMG signals due to the noisy environment. The noise in the real-time data collection process contaminates the effectiveness of the data. Moreover, not all patients process strong EMG signals due to muscle damage and neuromuscular disorder. To address these issues, we would like to propose a novel decision-level multisensor fusion technique. In short, the system will integrate EEG signals with EMG signals, retrieve effective information from both sources to understand and predict the desire of the user, and thus provide assistance. By testing out the proposed technique on a publicly available WAY-EEG-GAL dataset, which contains EEG and EMG signals that were recorded simultaneously, we manage to conclude the feasibility and effectiveness of the novel system.
Snipper: A Spatiotemporal Transformer for Simultaneous Multi-Person 3D Pose Estimation Tracking and Forecasting on a Video Snippet
Jul 13, 2022
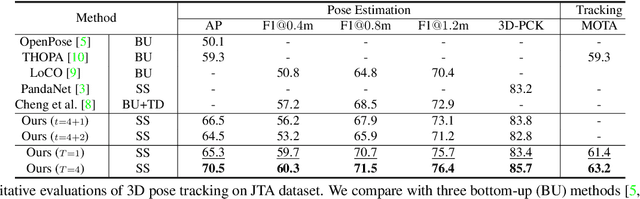
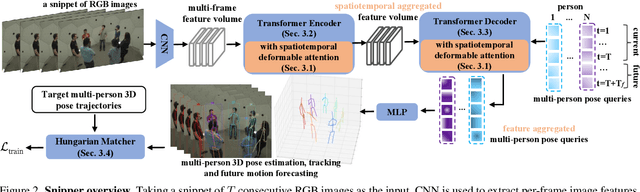
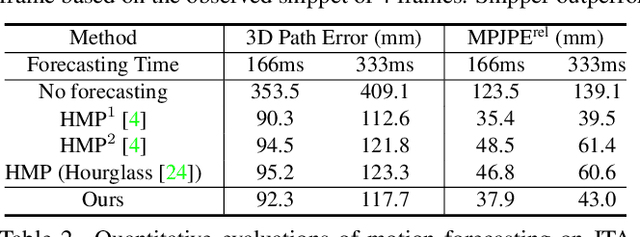
Multi-person pose understanding from RGB videos includes three complex tasks: pose estimation, tracking and motion forecasting. Among these three tasks, pose estimation and tracking are correlated, and tracking is crucial to motion forecasting. Most existing works either focus on a single task or employ cascaded methods to solve each individual task separately. In this paper, we propose Snipper, a framework to perform multi-person 3D pose estimation, tracking and motion forecasting simultaneously in a single inference. Specifically, we first propose a deformable attention mechanism to aggregate spatiotemporal information from video snippets. Building upon this deformable attention, a visual transformer is learned to encode the spatiotemporal features from multi-frame images and to decode informative pose features to update multi-person pose queries. Last, these queries are regressed to predict multi-person pose trajectories and future motions in one forward pass. In the experiments, we show the effectiveness of Snipper on three challenging public datasets where a generic model rivals specialized state-of-art baselines for pose estimation, tracking, and forecasting. Code is available at https://github.com/JimmyZou/Snipper
Large-Kernel Attention for 3D Medical Image Segmentation
Jul 19, 2022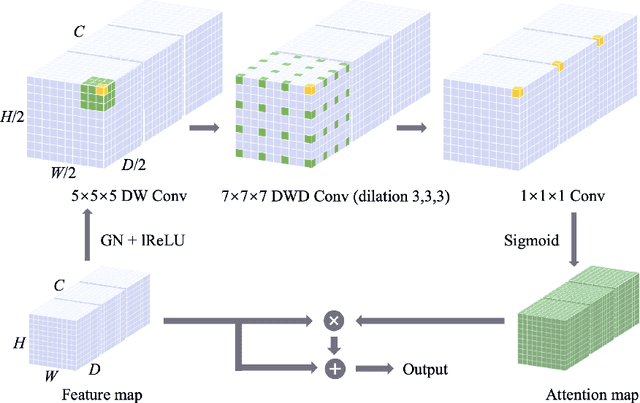
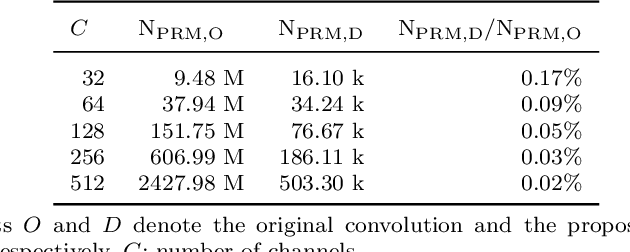
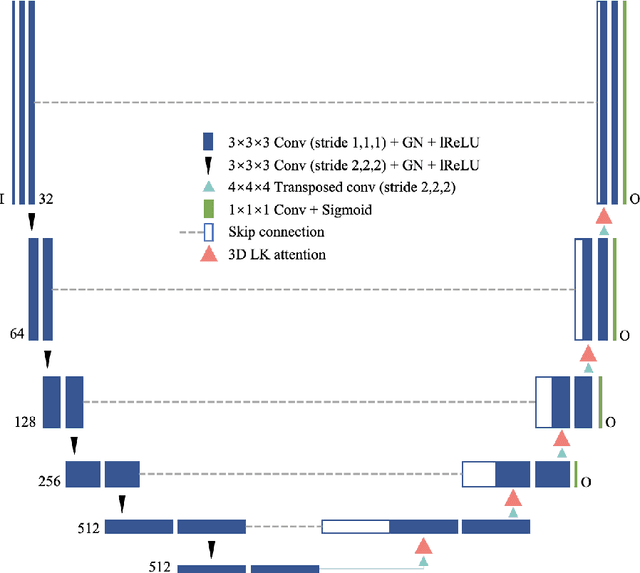

Automatic segmentation of multiple organs and tumors from 3D medical images such as magnetic resonance imaging (MRI) and computed tomography (CT) scans using deep learning methods can aid in diagnosing and treating cancer. However, organs often overlap and are complexly connected, characterized by extensive anatomical variation and low contrast. In addition, the diversity of tumor shape, location, and appearance, coupled with the dominance of background voxels, makes accurate 3D medical image segmentation difficult. In this paper, a novel large-kernel (LK) attention module is proposed to address these problems to achieve accurate multi-organ segmentation and tumor segmentation. The advantages of convolution and self-attention are combined in the proposed LK attention module, including local contextual information, long-range dependence, and channel adaptation. The module also decomposes the LK convolution to optimize the computational cost and can be easily incorporated into FCNs such as U-Net. Comprehensive ablation experiments demonstrated the feasibility of convolutional decomposition and explored the most efficient and effective network design. Among them, the best Mid-type LK attention-based U-Net network was evaluated on CT-ORG and BraTS 2020 datasets, achieving state-of-the-art segmentation performance. The performance improvement due to the proposed LK attention module was also statistically validated.
Super-resolution image display using diffractive decoders
Jun 15, 2022
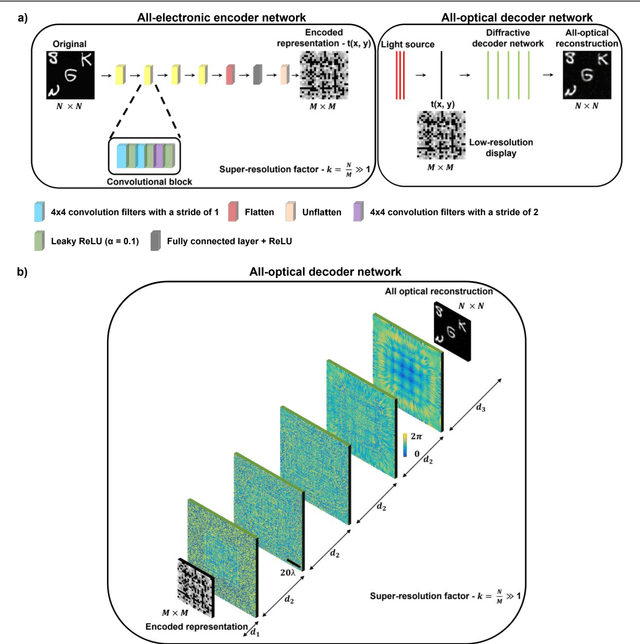
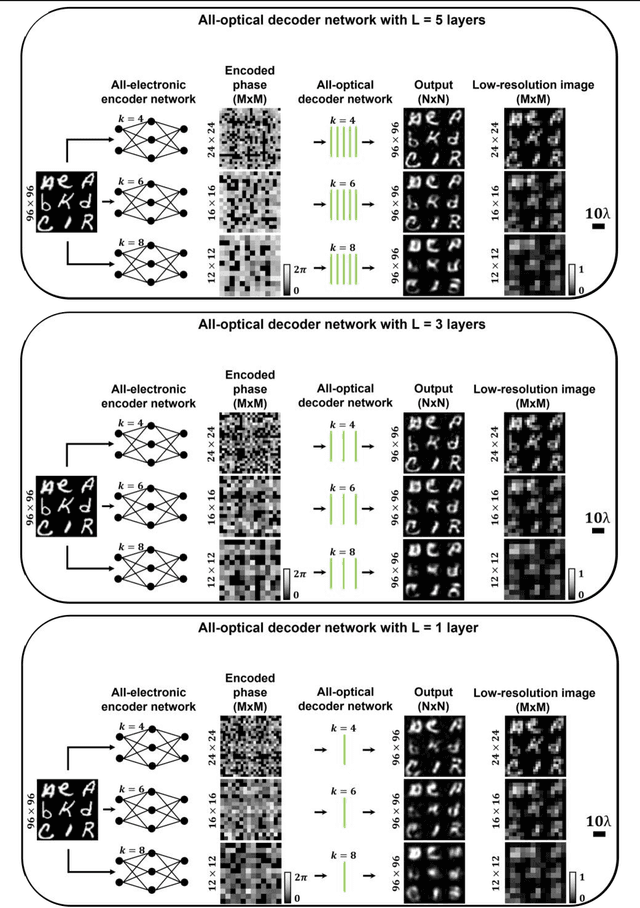
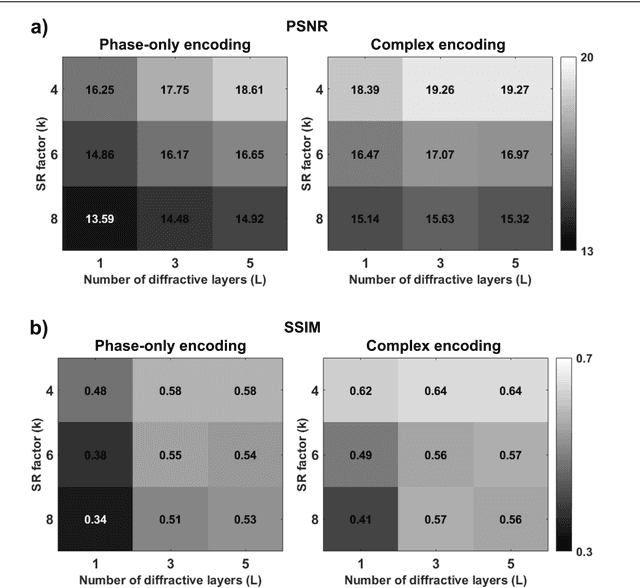
High-resolution synthesis/projection of images over a large field-of-view (FOV) is hindered by the restricted space-bandwidth-product (SBP) of wavefront modulators. We report a deep learning-enabled diffractive display design that is based on a jointly-trained pair of an electronic encoder and a diffractive optical decoder to synthesize/project super-resolved images using low-resolution wavefront modulators. The digital encoder, composed of a trained convolutional neural network (CNN), rapidly pre-processes the high-resolution images of interest so that their spatial information is encoded into low-resolution (LR) modulation patterns, projected via a low SBP wavefront modulator. The diffractive decoder processes this LR encoded information using thin transmissive layers that are structured using deep learning to all-optically synthesize and project super-resolved images at its output FOV. Our results indicate that this diffractive image display can achieve a super-resolution factor of ~4, demonstrating a ~16-fold increase in SBP. We also experimentally validate the success of this diffractive super-resolution display using 3D-printed diffractive decoders that operate at the THz spectrum. This diffractive image decoder can be scaled to operate at visible wavelengths and inspire the design of large FOV and high-resolution displays that are compact, low-power, and computationally efficient.
Explainable AI (XAI) in Biomedical Signal and Image Processing: Promises and Challenges
Jul 09, 2022Artificial intelligence has become pervasive across disciplines and fields, and biomedical image and signal processing is no exception. The growing and widespread interest on the topic has triggered a vast research activity that is reflected in an exponential research effort. Through study of massive and diverse biomedical data, machine and deep learning models have revolutionized various tasks such as modeling, segmentation, registration, classification and synthesis, outperforming traditional techniques. However, the difficulty in translating the results into biologically/clinically interpretable information is preventing their full exploitation in the field. Explainable AI (XAI) attempts to fill this translational gap by providing means to make the models interpretable and providing explanations. Different solutions have been proposed so far and are gaining increasing interest from the community. This paper aims at providing an overview on XAI in biomedical data processing and points to an upcoming Special Issue on Deep Learning in Biomedical Image and Signal Processing of the IEEE Signal Processing Magazine that is going to appear in March 2022.
Semi-unsupervised Learning for Time Series Classification
Jul 13, 2022


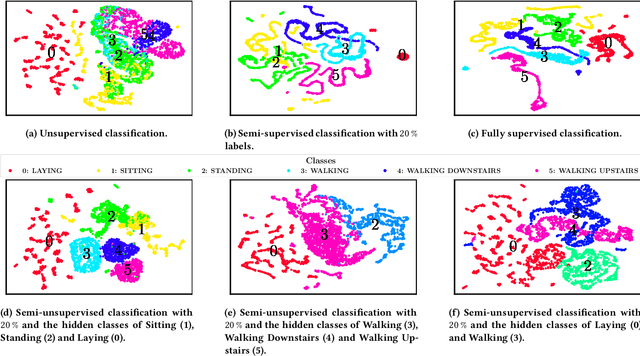
Time series are ubiquitous and therefore inherently hard to analyze and ultimately to label or cluster. With the rise of the Internet of Things (IoT) and its smart devices, data is collected in large amounts any given second. The collected data is rich in information, as one can detect accidents (e.g. cars) in real time, or assess injury/sickness over a given time span (e.g. health devices). Due to its chaotic nature and massive amounts of datapoints, timeseries are hard to label manually. Furthermore new classes within the data could emerge over time (contrary to e.g. handwritten digits), which would require relabeling the data. In this paper we present SuSL4TS, a deep generative Gaussian mixture model for semi-unsupervised learning, to classify time series data. With our approach we can alleviate manual labeling steps, since we can detect sparsely labeled classes (semi-supervised) and identify emerging classes hidden in the data (unsupervised). We demonstrate the efficacy of our approach with established time series classification datasets from different domains.
Content-aware Scalable Deep Compressed Sensing
Jul 19, 2022To more efficiently address image compressed sensing (CS) problems, we present a novel content-aware scalable network dubbed CASNet which collectively achieves adaptive sampling rate allocation, fine granular scalability and high-quality reconstruction. We first adopt a data-driven saliency detector to evaluate the importances of different image regions and propose a saliency-based block ratio aggregation (BRA) strategy for sampling rate allocation. A unified learnable generating matrix is then developed to produce sampling matrix of any CS ratio with an ordered structure. Being equipped with the optimization-inspired recovery subnet guided by saliency information and a multi-block training scheme preventing blocking artifacts, CASNet jointly reconstructs the image blocks sampled at various sampling rates with one single model. To accelerate training convergence and improve network robustness, we propose an SVD-based initialization scheme and a random transformation enhancement (RTE) strategy, which are extensible without introducing extra parameters. All the CASNet components can be combined and learned end-to-end. We further provide a four-stage implementation for evaluation and practical deployments. Experiments demonstrate that CASNet outperforms other CS networks by a large margin, validating the collaboration and mutual supports among its components and strategies. Codes are available at https://github.com/Guaishou74851/CASNet.
AutoTransition: Learning to Recommend Video Transition Effects
Jul 27, 2022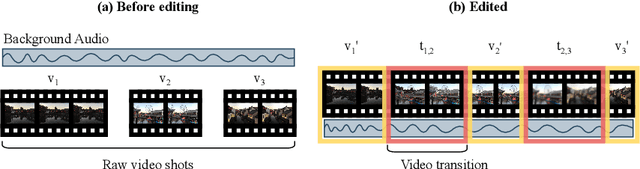
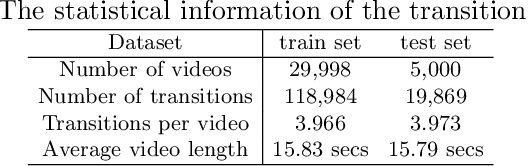
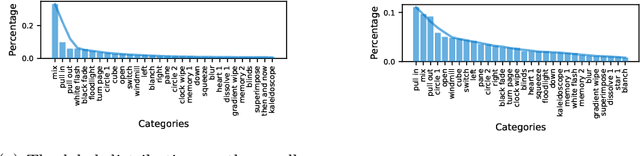
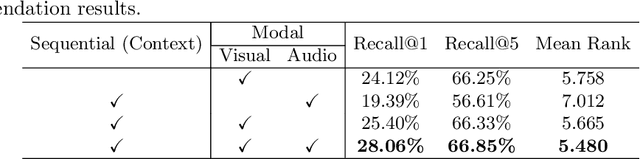
Video transition effects are widely used in video editing to connect shots for creating cohesive and visually appealing videos. However, it is challenging for non-professionals to choose best transitions due to the lack of cinematographic knowledge and design skills. In this paper, we present the premier work on performing automatic video transitions recommendation (VTR): given a sequence of raw video shots and companion audio, recommend video transitions for each pair of neighboring shots. To solve this task, we collect a large-scale video transition dataset using publicly available video templates on editing softwares. Then we formulate VTR as a multi-modal retrieval problem from vision/audio to video transitions and propose a novel multi-modal matching framework which consists of two parts. First we learn the embedding of video transitions through a video transition classification task. Then we propose a model to learn the matching correspondence from vision/audio inputs to video transitions. Specifically, the proposed model employs a multi-modal transformer to fuse vision and audio information, as well as capture the context cues in sequential transition outputs. Through both quantitative and qualitative experiments, we clearly demonstrate the effectiveness of our method. Notably, in the comprehensive user study, our method receives comparable scores compared with professional editors while improving the video editing efficiency by \textbf{300\scalebox{1.25}{$\times$}}. We hope our work serves to inspire other researchers to work on this new task. The dataset and codes are public at \url{https://github.com/acherstyx/AutoTransition}.