 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Push--Pull with Device Sampling
Jun 08, 2022
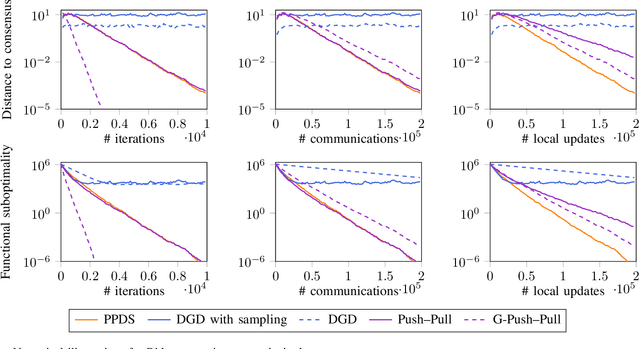
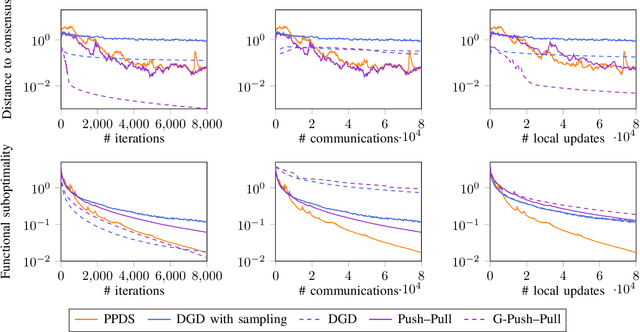
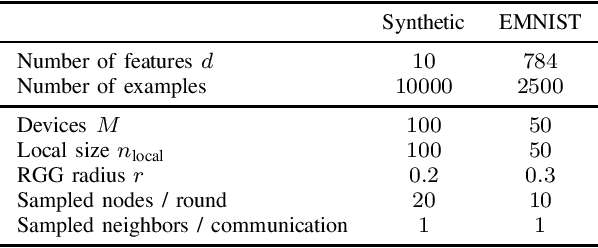
We consider decentralized optimization problems in which a number of agents collaborate to minimize the average of their local functions by exchanging over an underlying communication graph. Specifically, we place ourselves in an asynchronous model where only a random portion of nodes perform computation at each iteration, while the information exchange can be conducted between all the nodes and in an asymmetric fashion. For this setting, we propose an algorithm that combines gradient tracking and variance reduction over the entire network. This enables each node to track the average of the gradients of the objective functions. Our theoretical analysis shows that the algorithm converges linearly, when the local objective functions are strongly convex, under mild connectivity conditions on the expected mixing matrices. In particular, our result does not require the mixing matrices to be doubly stochastic. In the experiments, we investigate a broadcast mechanism that transmits information from computing nodes to their neighbors, and confirm the linear convergence of our method on both synthetic and real-world datasets.
SYNERgy between SYNaptic consolidation and Experience Replay for general continual learning
Jun 08, 2022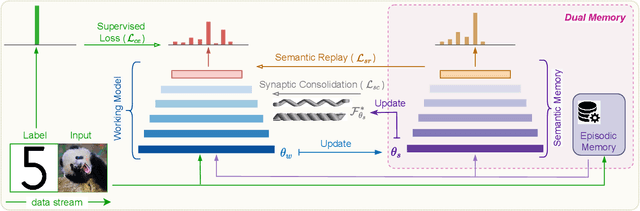
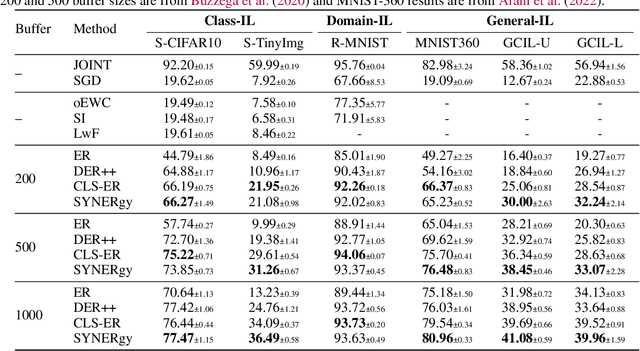
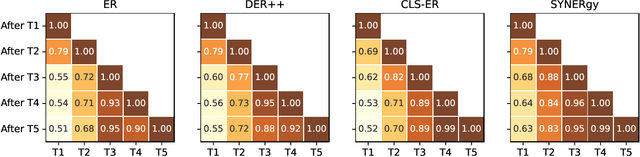
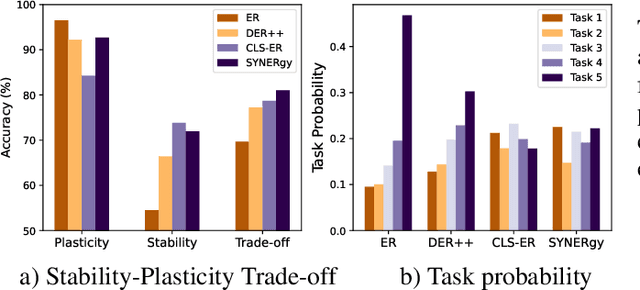
Continual learning (CL) in the brain is facilitated by a complex set of mechanisms. This includes the interplay of multiple memory systems for consolidating information as posited by the complementary learning systems (CLS) theory and synaptic consolidation for protecting the acquired knowledge from erasure. Thus, we propose a general CL method that creates a synergy between SYNaptic consolidation and dual memory Experience Replay (SYNERgy). Our method maintains a semantic memory that accumulates and consolidates information across the tasks and interacts with the episodic memory for effective replay. It further employs synaptic consolidation by tracking the importance of parameters during the training trajectory and anchoring them to the consolidated parameters in the semantic memory. To the best of our knowledge, our study is the first to employ dual memory experience replay in conjunction with synaptic consolidation that is suitable for general CL whereby the network does not utilize task boundaries or task labels during training or inference. Our evaluation on various challenging CL scenarios and characteristics analyses demonstrate the efficacy of incorporating both synaptic consolidation and CLS theory in enabling effective CL in DNNs.
TGRMPT: A Head-Shoulder Aided Multi-Person Tracker and a New Large-Scale Dataset for Tour-Guide Robot
Jul 08, 2022

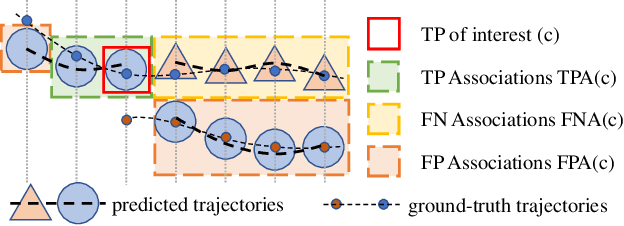
A service robot serving safely and politely needs to track the surrounding people robustly, especially for Tour-Guide Robot (TGR). However, existing multi-object tracking (MOT) or multi-person tracking (MPT) methods are not applicable to TGR for the following reasons: 1. lacking relevant large-scale datasets; 2. lacking applicable metrics to evaluate trackers. In this work, we target the visual perceptual tasks for TGR and present the TGRDB dataset, a novel large-scale multi-person tracking dataset containing roughly 5.6 hours of annotated videos and over 450 long-term trajectories. Besides, we propose a more applicable metric to evaluate trackers using our dataset. As part of our work, we present TGRMPT, a novel MPT system that incorporates information from head shoulder and whole body, and achieves state-of-the-art performance. We have released our codes and dataset in https://github.com/wenwenzju/TGRMPT.
MIA 2022 Shared Task Submission: Leveraging Entity Representations, Dense-Sparse Hybrids, and Fusion-in-Decoder for Cross-Lingual Question Answering
Jul 06, 2022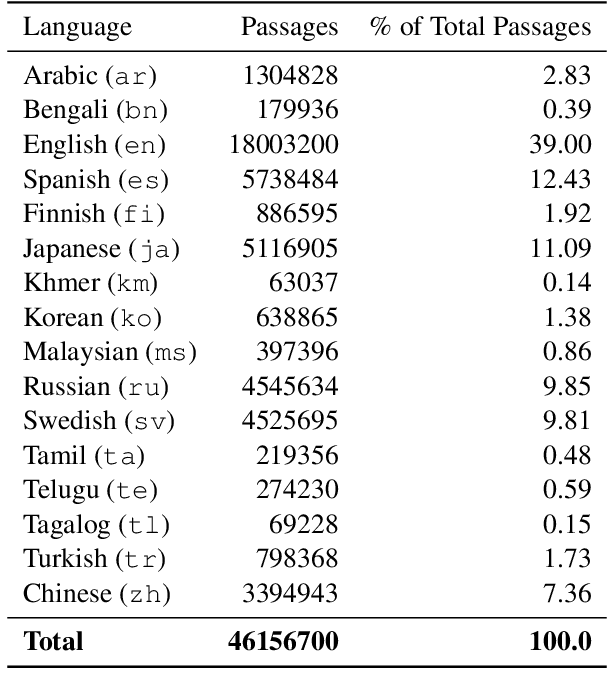
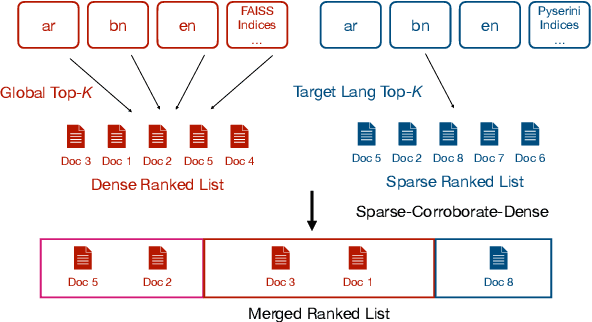


We describe our two-stage system for the Multilingual Information Access (MIA) 2022 Shared Task on Cross-Lingual Open-Retrieval Question Answering. The first stage consists of multilingual passage retrieval with a hybrid dense and sparse retrieval strategy. The second stage consists of a reader which outputs the answer from the top passages returned by the first stage. We show the efficacy of using entity representations, sparse retrieval signals to help dense retrieval, and Fusion-in-Decoder. On the development set, we obtain 43.46 F1 on XOR-TyDi QA and 21.99 F1 on MKQA, for an average F1 score of 32.73. On the test set, we obtain 40.93 F1 on XOR-TyDi QA and 22.29 F1 on MKQA, for an average F1 score of 31.61. We improve over the official baseline by over 4 F1 points on both the development and test sets.
Eliminating Gradient Conflict in Reference-based Line-Art Colorization
Jul 20, 2022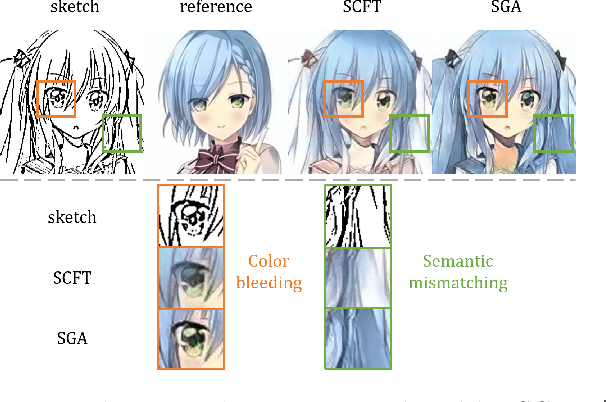
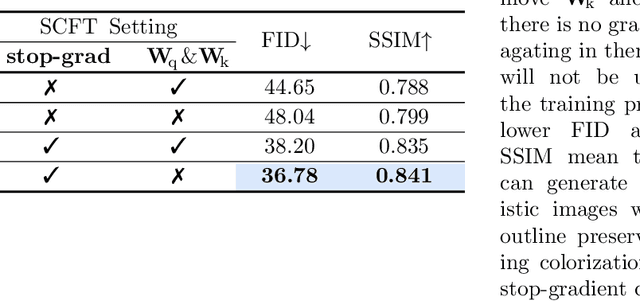
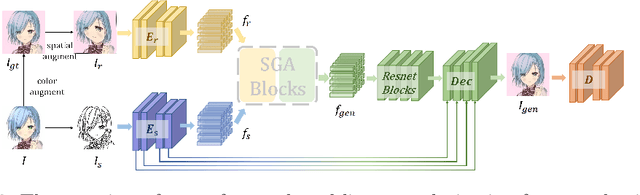
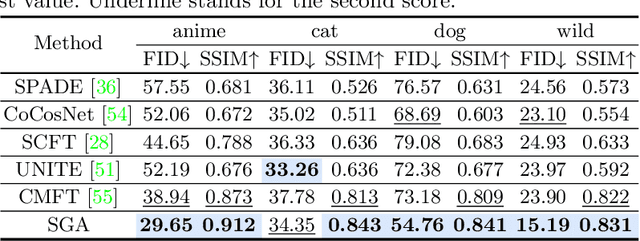
Reference-based line-art colorization is a challenging task in computer vision. The color, texture, and shading are rendered based on an abstract sketch, which heavily relies on the precise long-range dependency modeling between the sketch and reference. Popular techniques to bridge the cross-modal information and model the long-range dependency employ the attention mechanism. However, in the context of reference-based line-art colorization, several techniques would intensify the existing training difficulty of attention, for instance, self-supervised training protocol and GAN-based losses. To understand the instability in training, we detect the gradient flow of attention and observe gradient conflict among attention branches. This phenomenon motivates us to alleviate the gradient issue by preserving the dominant gradient branch while removing the conflict ones. We propose a novel attention mechanism using this training strategy, Stop-Gradient Attention (SGA), outperforming the attention baseline by a large margin with better training stability. Compared with state-of-the-art modules in line-art colorization, our approach demonstrates significant improvements in Fr\'echet Inception Distance (FID, up to 27.21%) and structural similarity index measure (SSIM, up to 25.67%) on several benchmarks. The code of SGA is available at https://github.com/kunkun0w0/SGA .
Deep Pneumonia: Attention-Based Contrastive Learning for Class-Imbalanced Pneumonia Lesion Recognition in Chest X-rays
Jul 23, 2022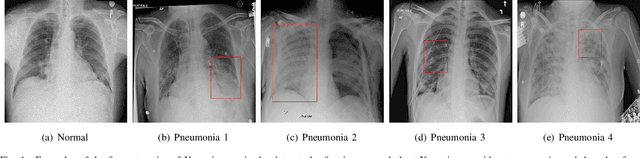
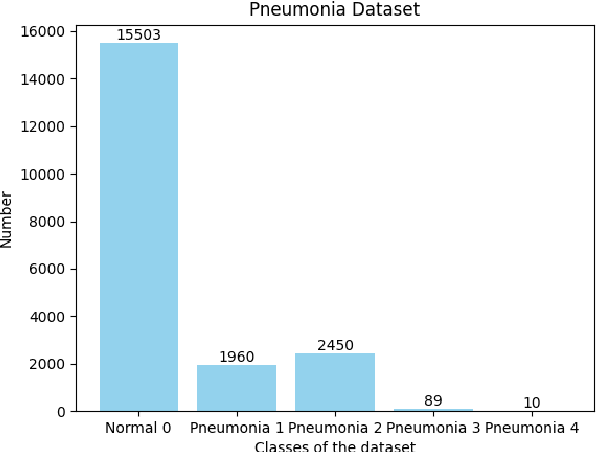
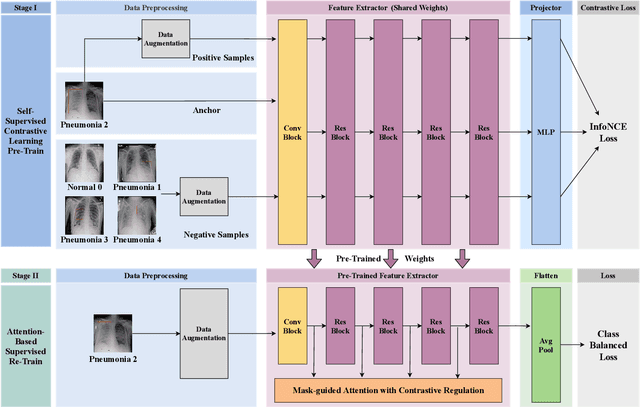
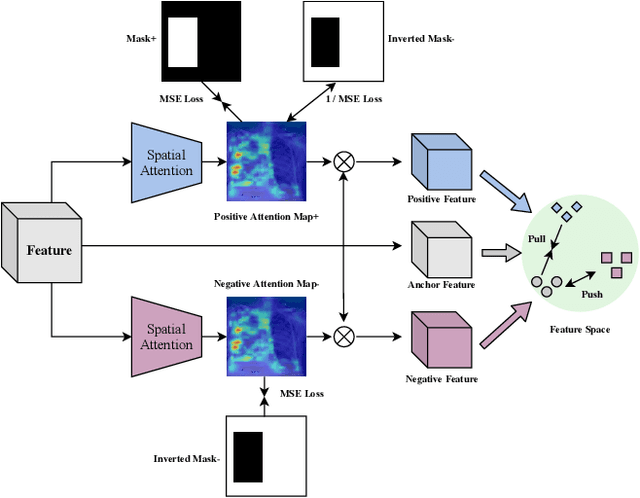
Computer-aided X-ray pneumonia lesion recognition is important for accurate diagnosis of pneumonia. With the emergence of deep learning, the identification accuracy of pneumonia has been greatly improved, but there are still some challenges due to the fuzzy appearance of chest X-rays. In this paper, we propose a deep learning framework named Attention-Based Contrastive Learning for Class-Imbalanced X-Ray Pneumonia Lesion Recognition (denoted as Deep Pneumonia). We adopt self-supervised contrastive learning strategy to pre-train the model without using extra pneumonia data for fully mining the limited available dataset. In order to leverage the location information of the lesion area that the doctor has painstakingly marked, we propose mask-guided hard attention strategy and feature learning with contrastive regulation strategy which are applied on the attention map and the extracted features respectively to guide the model to focus more attention on the lesion area where contains more discriminative features for improving the recognition performance. In addition, we adopt Class-Balanced Loss instead of traditional Cross-Entropy as the loss function of classification to tackle the problem of serious class imbalance between different classes of pneumonia in the dataset. The experimental results show that our proposed framework can be used as a reliable computer-aided pneumonia diagnosis system to assist doctors to better diagnose pneumonia cases accurately.
Certified Graph Unlearning
Jun 18, 2022

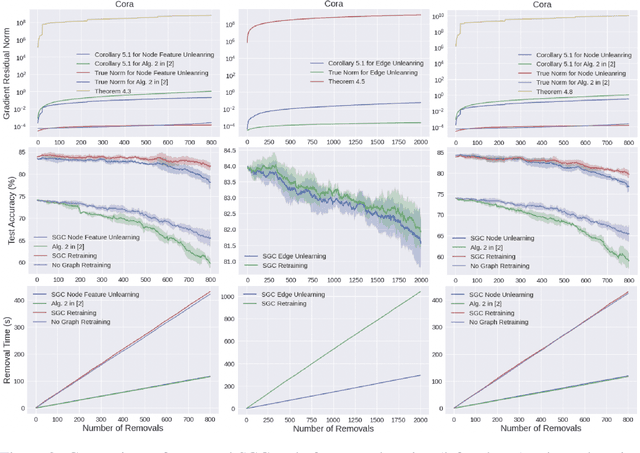
Graph-structured data is ubiquitous in practice and often processed using graph neural networks (GNNs). With the adoption of recent laws ensuring the ``right to be forgotten'', the problem of graph data removal has become of significant importance. To address the problem, we introduce the first known framework for \emph{certified graph unlearning} of GNNs. In contrast to standard machine unlearning, new analytical and heuristic unlearning challenges arise when dealing with complex graph data. First, three different types of unlearning requests need to be considered, including node feature, edge and node unlearning. Second, to establish provable performance guarantees, one needs to address challenges associated with feature mixing during propagation. The underlying analysis is illustrated on the example of simple graph convolutions (SGC) and their generalized PageRank (GPR) extensions, thereby laying the theoretical foundation for certified unlearning of GNNs. Our empirical studies on six benchmark datasets demonstrate excellent performance-complexity trade-offs when compared to complete retraining methods and approaches that do not leverage graph information. For example, when unlearning $20\%$ of the nodes on the Cora dataset, our approach suffers only a $0.1\%$ loss in test accuracy while offering a $4$-fold speed-up compared to complete retraining. Our scheme also outperforms unlearning methods that do not leverage graph information with a $12\%$ increase in test accuracy for a comparable time complexity.
Graph Neural Network Bandits
Jul 13, 2022
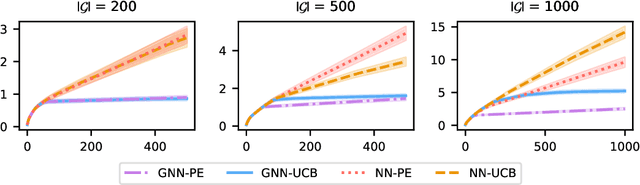
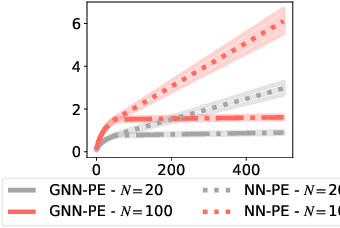
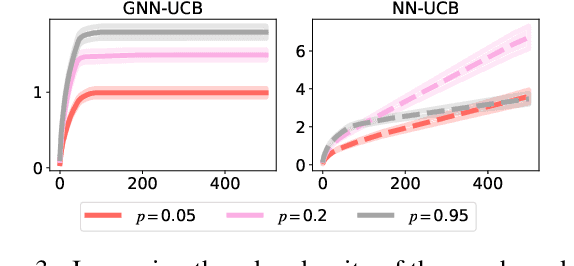
We consider the bandit optimization problem with the reward function defined over graph-structured data. This problem has important applications in molecule design and drug discovery, where the reward is naturally invariant to graph permutations. The key challenges in this setting are scaling to large domains, and to graphs with many nodes. We resolve these challenges by embedding the permutation invariance into our model. In particular, we show that graph neural networks (GNNs) can be used to estimate the reward function, assuming it resides in the Reproducing Kernel Hilbert Space of a permutation-invariant additive kernel. By establishing a novel connection between such kernels and the graph neural tangent kernel (GNTK), we introduce the first GNN confidence bound and use it to design a phased-elimination algorithm with sublinear regret. Our regret bound depends on the GNTK's maximum information gain, which we also provide a bound for. While the reward function depends on all $N$ node features, our guarantees are independent of the number of graph nodes $N$. Empirically, our approach exhibits competitive performance and scales well on graph-structured domains.
Patching Leaks in the Charformer for Efficient Character-Level Generation
May 27, 2022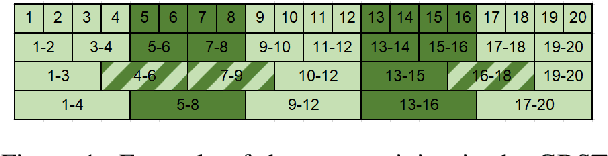

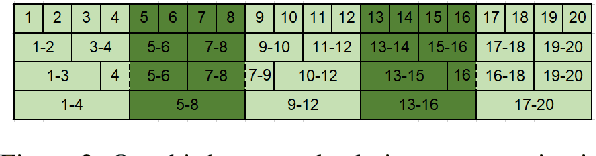
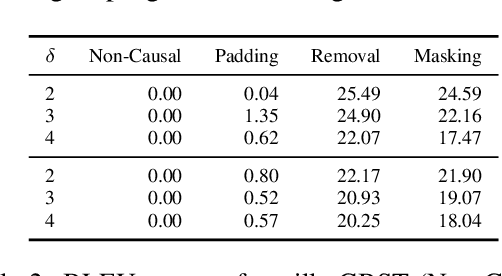
Character-based representations have important advantages over subword-based ones for morphologically rich languages. They come with increased robustness to noisy input and do not need a separate tokenization step. However, they also have a crucial disadvantage: they notably increase the length of text sequences. The GBST method from Charformer groups (aka downsamples) characters to solve this, but allows information to leak when applied to a Transformer decoder. We solve this information leak issue, thereby enabling character grouping in the decoder. We show that Charformer downsampling has no apparent benefits in NMT over previous downsampling methods in terms of translation quality, however it can be trained roughly 30% faster. Promising performance on English--Turkish translation indicate the potential of character-level models for morphologically-rich languages.
Reconstruct from Top View: A 3D Lane Detection Approach based on Geometry Structure Prior
Jun 21, 2022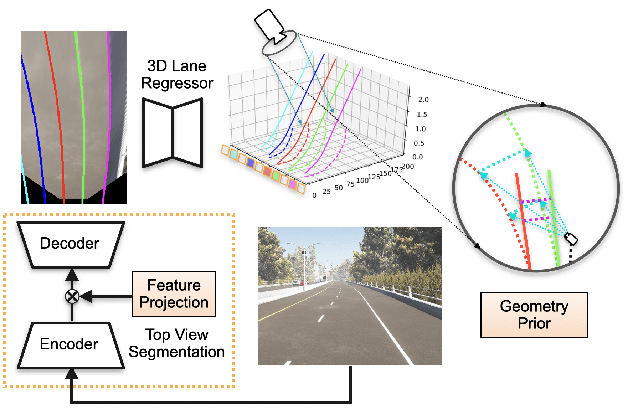
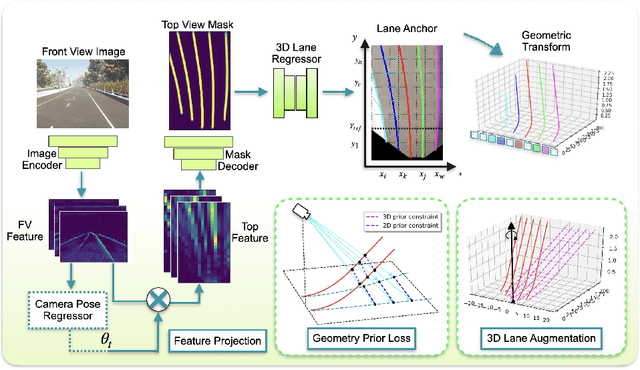
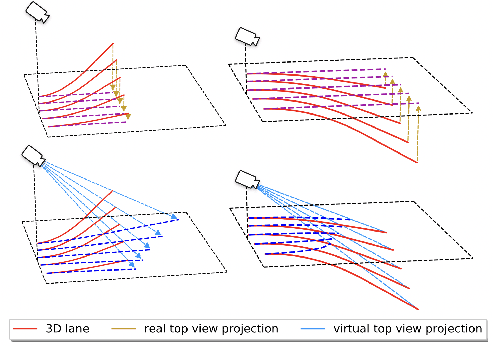
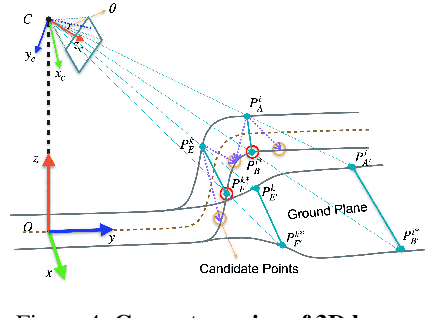
In this paper, we propose an advanced approach in targeting the problem of monocular 3D lane detection by leveraging geometry structure underneath the process of 2D to 3D lane reconstruction. Inspired by previous methods, we first analyze the geometry heuristic between the 3D lane and its 2D representation on the ground and propose to impose explicit supervision based on the structure prior, which makes it achievable to build inter-lane and intra-lane relationships to facilitate the reconstruction of 3D lanes from local to global. Second, to reduce the structure loss in 2D lane representation, we directly extract top view lane information from front view images, which tremendously eases the confusion of distant lane features in previous methods. Furthermore, we propose a novel task-specific data augmentation method by synthesizing new training data for both segmentation and reconstruction tasks in our pipeline, to counter the imbalanced data distribution of camera pose and ground slope to improve generalization on unseen data. Our work marks the first attempt to employ the geometry prior information into DNN-based 3D lane detection and makes it achievable for detecting lanes in an extra-long distance, doubling the original detection range. The proposed method can be smoothly adopted by other frameworks without extra costs. Experimental results show that our work outperforms state-of-the-art approaches by 3.8% F-Score on Apollo 3D synthetic dataset at real-time speed of 82 FPS without introducing extra parameters.