 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ICC: Quantifying Image Caption Concreteness for Multimodal Dataset Curation
Mar 02, 2024
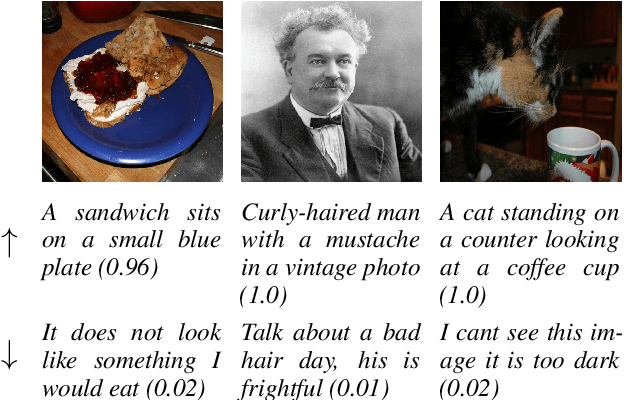
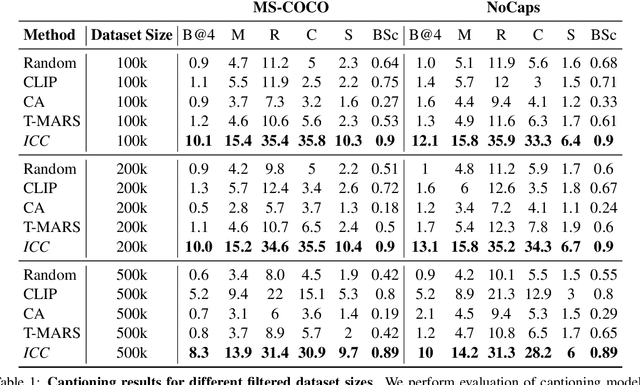

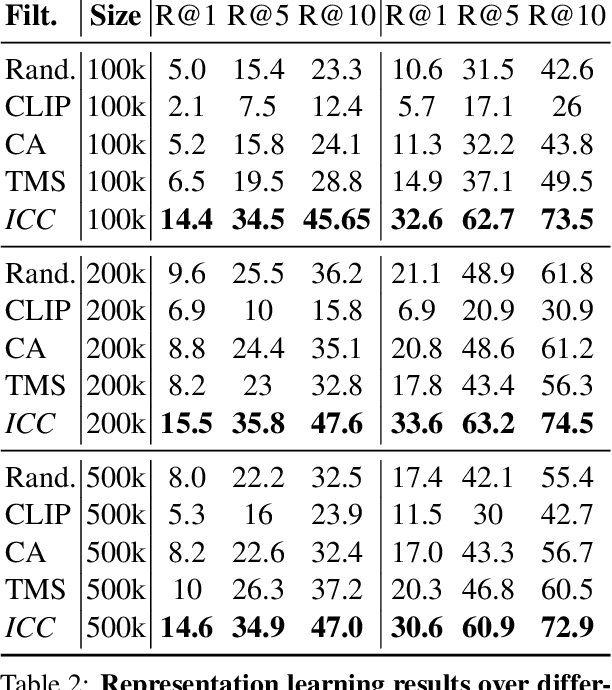
Web-scale training on paired text-image data is becoming increasingly central to multimodal learning, but is challenged by the highly noisy nature of datasets in the wild. Standard data filtering approaches succeed in removing mismatched text-image pairs, but permit semantically related but highly abstract or subjective text. These approaches lack the fine-grained ability to isolate the most concrete samples that provide the strongest signal for learning in a noisy dataset. In this work, we propose a new metric, image caption concreteness, that evaluates caption text without an image reference to measure its concreteness and relevancy for use in multimodal learning. Our approach leverages strong foundation models for measuring visual-semantic information loss in multimodal representations. We demonstrate that this strongly correlates with human evaluation of concreteness in both single-word and sentence-level texts. Moreover, we show that curation using ICC complements existing approaches: It succeeds in selecting the highest quality samples from multimodal web-scale datasets to allow for efficient training in resource-constrained settings.
HALC: Object Hallucination Reduction via Adaptive Focal-Contrast Decoding
Mar 01, 2024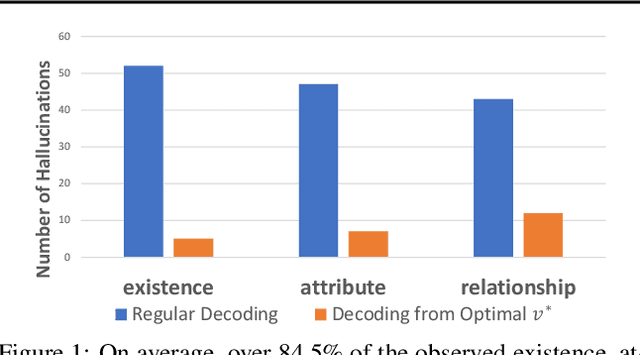
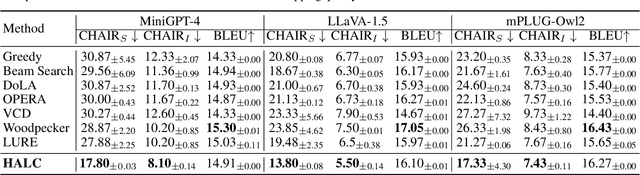
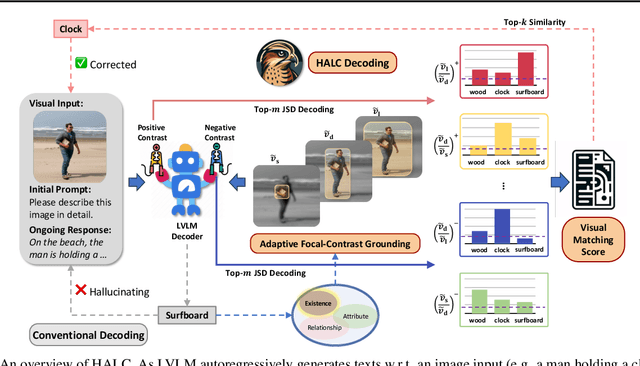
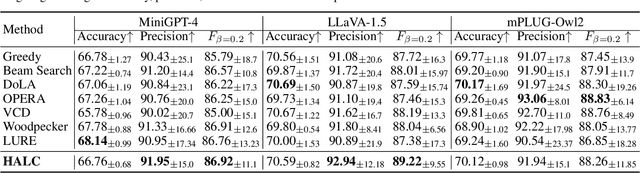
While large vision-language models (LVLMs) have demonstrated impressive capabilities in interpreting multi-modal contexts, they invariably suffer from object hallucinations (OH). We introduce HALC, a novel decoding algorithm designed to mitigate OH in LVLMs. HALC leverages distinct fine-grained optimal visual information in vision-language tasks and operates on both local and global contexts simultaneously. Specifically, HALC integrates a robust auto-focal grounding mechanism (locally) to correct hallucinated tokens on the fly, and a specialized beam search algorithm (globally) to significantly reduce OH while preserving text generation quality. Additionally, HALC can be integrated into any LVLMs as a plug-and-play module without extra training. Extensive experimental studies demonstrate the effectiveness of HALC in reducing OH, outperforming state-of-the-arts across four benchmarks.
Brain-inspired and Self-based Artificial Intelligence
Feb 29, 2024The question "Can machines think?" and the Turing Test to assess whether machines could achieve human-level intelligence is one of the roots of AI. With the philosophical argument "I think, therefore I am", this paper challenge the idea of a "thinking machine" supported by current AIs since there is no sense of self in them. Current artificial intelligence is only seemingly intelligent information processing and does not truly understand or be subjectively aware of oneself and perceive the world with the self as human intelligence does. In this paper, we introduce a Brain-inspired and Self-based Artificial Intelligence (BriSe AI) paradigm. This BriSe AI paradigm is dedicated to coordinating various cognitive functions and learning strategies in a self-organized manner to build human-level AI models and robotic applications. Specifically, BriSe AI emphasizes the crucial role of the Self in shaping the future AI, rooted with a practical hierarchical Self framework, including Perception and Learning, Bodily Self, Autonomous Self, Social Self, and Conceptual Self. The hierarchical framework of the Self highlights self-based environment perception, self-bodily modeling, autonomous interaction with the environment, social interaction and collaboration with others, and even more abstract understanding of the Self. Furthermore, the positive mutual promotion and support among multiple levels of Self, as well as between Self and learning, enhance the BriSe AI's conscious understanding of information and flexible adaptation to complex environments, serving as a driving force propelling BriSe AI towards real Artificial General Intelligence.
ARED: Argentina Real Estate Dataset
Mar 01, 2024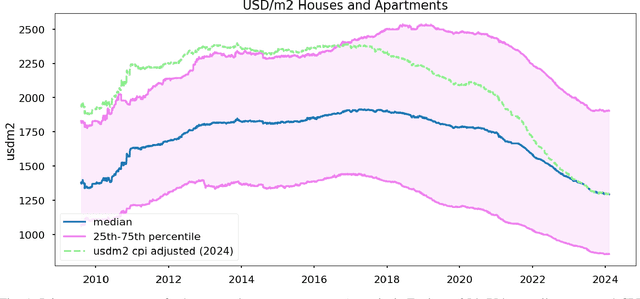
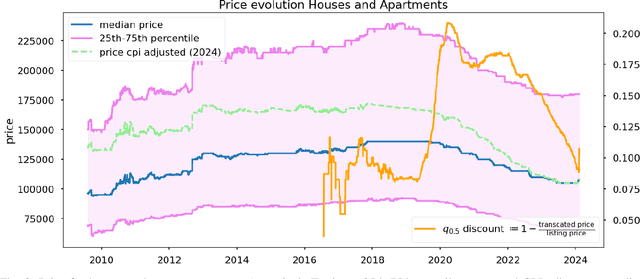
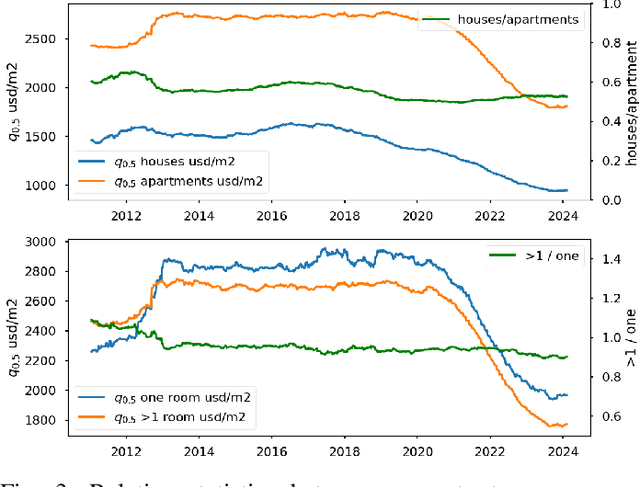
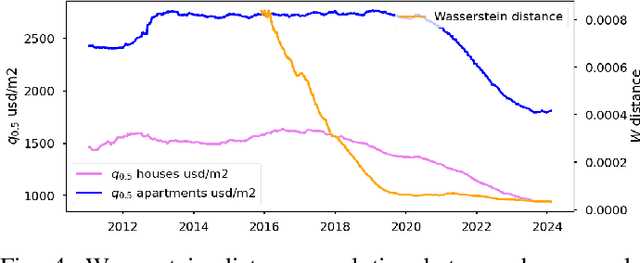
The Argentinian real estate market presents a unique case study characterized by its unstable and rapidly shifting macroeconomic circumstances over the past decades. Despite the existence of a few datasets for price prediction, there is a lack of mixed modality datasets specifically focused on Argentina. In this paper, the first edition of ARED is introduced. A comprehensive real estate price prediction dataset series, designed for the Argentinian market. This edition contains information solely for Jan-Feb 2024. It was found that despite the short time range captured by this zeroth edition (44 days), time dependent phenomena has been occurring mostly on a market level (market as a whole). Nevertheless future editions of this dataset, will most likely contain historical data. Each listing in ARED comprises descriptive features, and variable-length sets of images.
RORA: Robust Free-Text Rationale Evaluation
Feb 28, 2024Free-text rationales play a pivotal role in explainable NLP, bridging the knowledge and reasoning gaps behind a model's decision-making. However, due to the diversity of potential reasoning paths and a corresponding lack of definitive ground truth, their evaluation remains a challenge. Existing evaluation metrics rely on the degree to which a rationale supports a target label, but we find these fall short in evaluating rationales that inadvertently leak the labels. To address this problem, we propose RORA, a Robust free-text Rationale evaluation against label leakage. RORA quantifies the new information supplied by a rationale to justify the label. This is achieved by assessing the conditional V-information \citep{hewitt-etal-2021-conditional} with a predictive family robust against leaky features that can be exploited by a small model. RORA consistently outperforms existing approaches in evaluating human-written, synthetic, or model-generated rationales, particularly demonstrating robustness against label leakage. We also show that RORA aligns well with human judgment, providing a more reliable and accurate measurement across diverse free-text rationales.
A Self-matching Training Method with Annotation Embedding Models for Ontology Subsumption Prediction
Feb 28, 2024Recently, ontology embeddings representing entities in a low-dimensional space have been proposed for ontology completion. However, the ontology embeddings for concept subsumption prediction do not address the difficulties of similar and isolated entities and fail to extract the global information of annotation axioms from an ontology. In this paper, we propose a self-matching training method for the two ontology embedding models: Inverted-index Matrix Embedding (InME) and Co-occurrence Matrix Embedding (CoME). The two embeddings capture the global and local information in annotation axioms by means of the occurring locations of each word in a set of axioms and the co-occurrences of words in each axiom. The self-matching training method increases the robustness of the concept subsumption prediction when predicted superclasses are similar to subclasses and are isolated to other entities in an ontology. Our evaluation experiments show that the self-matching training method with InME outperforms the existing ontology embeddings for the GO and FoodOn ontologies and that the method with the concatenation of CoME and OWL2Vec* outperforms them for the HeLiS ontology.
Lemur: Log Parsing with Entropy Sampling and Chain-of-Thought Merging
Feb 28, 2024Logs produced by extensive software systems are integral to monitoring system behaviors. Advanced log analysis facilitates the detection, alerting, and diagnosis of system faults. Log parsing, which entails transforming raw log messages into structured templates, constitutes a critical phase in the automation of log analytics. Existing log parsers fail to identify the correct templates due to reliance on human-made rules. Besides, These methods focus on statistical features while ignoring semantic information in log messages. To address these challenges, we introduce a cutting-edge \textbf{L}og parsing framework with \textbf{E}ntropy sampling and Chain-of-Thought \textbf{M}erging (Lemur). Specifically, to discard the tedious manual rules. We propose a novel sampling method inspired by information entropy, which efficiently clusters typical logs. Furthermore, to enhance the merging of log templates, we design a chain-of-thought method for large language models (LLMs). LLMs exhibit exceptional semantic comprehension, deftly distinguishing between parameters and invariant tokens. We have conducted experiments on large-scale public datasets. Extensive evaluation demonstrates that Lemur achieves the state-of-the-art performance and impressive efficiency.
An Analysis of Capacity-Distortion Trade-Offs in Memoryless ISAC Systems
Feb 26, 2024This manuscript investigates the information-theoretic limits of integrated sensing and communications (ISAC), aiming for simultaneous reliable communication and precise channel state estimation. We model such a system with a state-dependent discrete memoryless channel (SD-DMC) with present or absent channel feedback and generalized side information at the transmitter and the receiver, where the joint task of message decoding and state estimation is performed at the receiver. The relationship between the achievable communication rate and estimation error, the capacity-distortion (C-D) trade-off, is characterized across different causality levels of the side information. This framework is shown to be capable of modeling various practical scenarios by assigning the side information with different meanings, including monostatic and bistatic radar systems. The analysis is then extended to the two-user degraded broadcast channel, and we derive an achievable C-D region that is tight under certain conditions. To solve the optimization problem arising in the computation of C-D functions/regions, we propose a proximal block coordinate descent (BCD) method, prove its convergence to a stationary point, and derive a stopping criterion. Finally, several representative examples are studied to demonstrate the versatility of our framework and the effectiveness of the proposed algorithm.
A Model-Based Approach for Improving Reinforcement Learning Efficiency Leveraging Expert Observations
Feb 29, 2024This paper investigates how to incorporate expert observations (without explicit information on expert actions) into a deep reinforcement learning setting to improve sample efficiency. First, we formulate an augmented policy loss combining a maximum entropy reinforcement learning objective with a behavioral cloning loss that leverages a forward dynamics model. Then, we propose an algorithm that automatically adjusts the weights of each component in the augmented loss function. Experiments on a variety of continuous control tasks demonstrate that the proposed algorithm outperforms various benchmarks by effectively utilizing available expert observations.
Investigating Gender Fairness in Machine Learning-driven Personalized Care for Chronic Pain
Feb 29, 2024This study investigates gender fairness in personalized pain care recommendations using machine learning algorithms. Leveraging a contextual bandits framework, personalized recommendations are formulated and evaluated using LinUCB algorithm on a dataset comprising interactions with $164$ patients across $10$ sessions each. Results indicate that while adjustments to algorithm parameters influence the quality of pain care recommendations, this impact remains consistent across genders. However, when certain patient information, such as self-reported pain measurements, is absent, the quality of pain care recommendations for women is notably inferior to that for men.