 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Comparative Study on Supervised versus Semi-supervised Machine Learning for Anomaly Detection of In-vehicle CAN Network
Jul 21, 2022
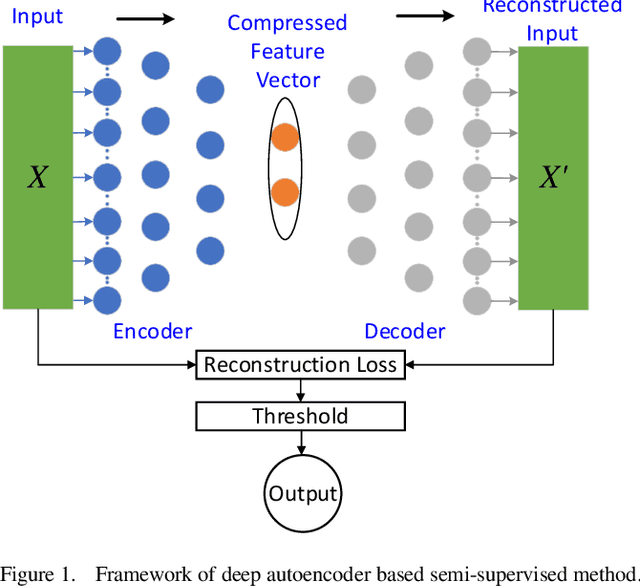
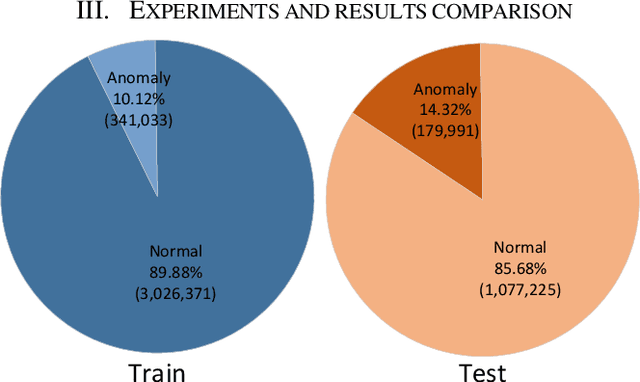
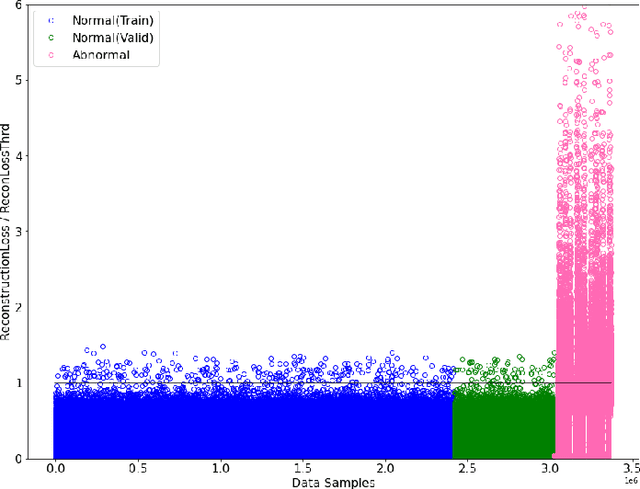
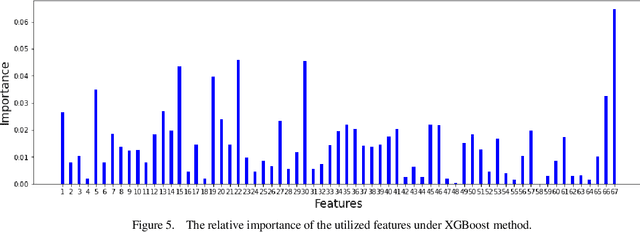
As the central nerve of the intelligent vehicle control system, the in-vehicle network bus is crucial to the security of vehicle driving. One of the best standards for the in-vehicle network is the Controller Area Network (CAN bus) protocol. However, the CAN bus is designed to be vulnerable to various attacks due to its lack of security mechanisms. To enhance the security of in-vehicle networks and promote the research in this area, based upon a large scale of CAN network traffic data with the extracted valuable features, this study comprehensively compared fully-supervised machine learning with semi-supervised machine learning methods for CAN message anomaly detection. Both traditional machine learning models (including single classifier and ensemble models) and neural network based deep learning models are evaluated. Furthermore, this study proposed a deep autoencoder based semi-supervised learning method applied for CAN message anomaly detection and verified its superiority over other semi-supervised methods. Extensive experiments show that the fully-supervised methods generally outperform semi-supervised ones as they are using more information as inputs. Typically the developed XGBoost based model obtained state-of-the-art performance with the best accuracy (98.65%), precision (0.9853), and ROC AUC (0.9585) beating other methods reported in the literature.
Learning for Expressive Task-Related Sentence Representations
May 24, 2022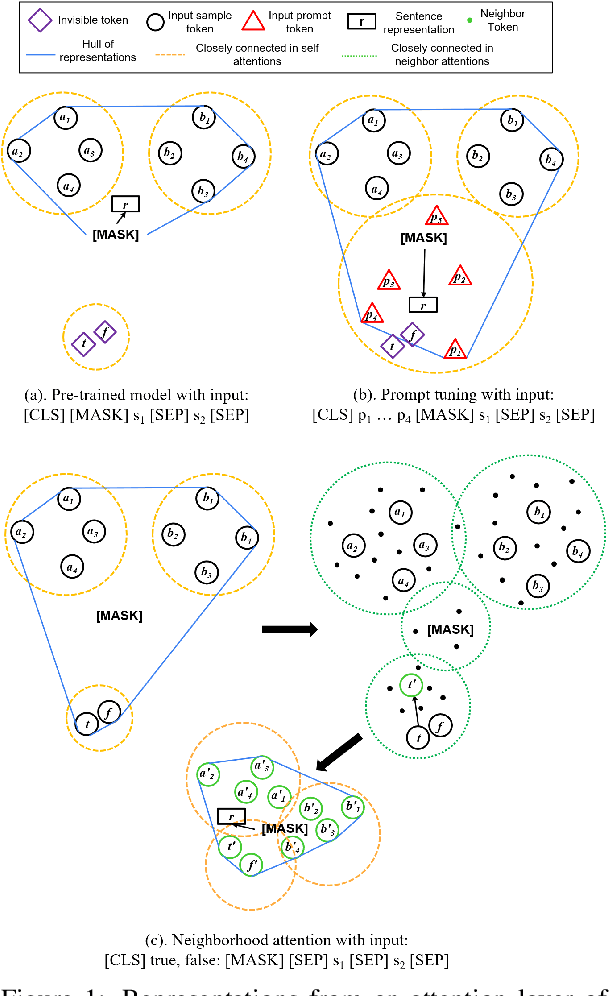
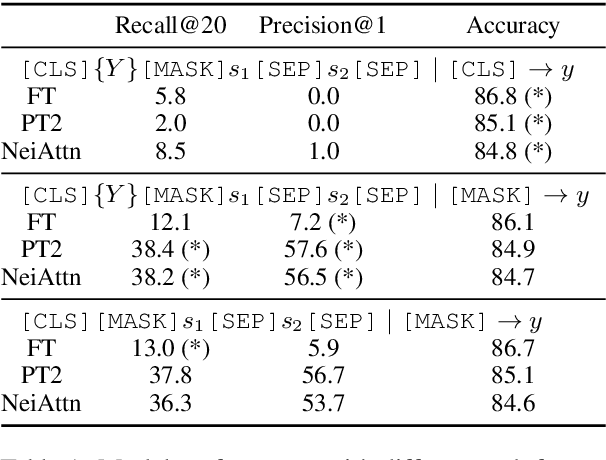
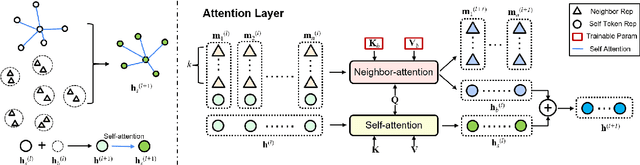

NLP models learn sentence representations for downstream tasks by tuning a model which is pre-trained by masked language modeling. However, after tuning, the learned sentence representations may be skewed heavily toward label space and thus are not expressive enough to represent whole samples, which should contain task-related information of both sentence inputs and labels. In this work, we learn expressive sentence representations for supervised tasks which (1). contain task-related information in the sentence inputs, and (2). enable correct label predictions. To achieve this goal, we first propose a new objective which explicitly points out the label token space in the input, and predicts categories of labels via an added [MASK] token. This objective encourages fusing the semantic information of both the label and sentence. Then we develop a neighbor attention module, added on a frozen pre-trained model, to build connections between label/sentence tokens via their neighbors. The propagation can be further guided by the regularization on neighborhood representations to encourage expressiveness. Experimental results show that, despite tuning only 5% additional parameters over a frozen pre-trained model, our model can achieve classification results comparable to the SOTA while maintaining strong expressiveness as well.
Current Challenges and Future Directions in Podcast Information Access
Jun 17, 2021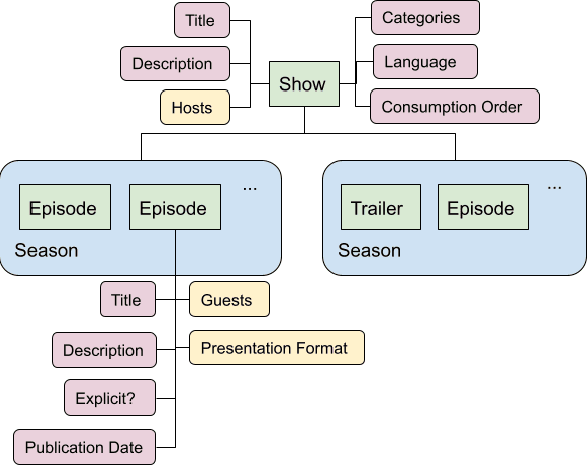
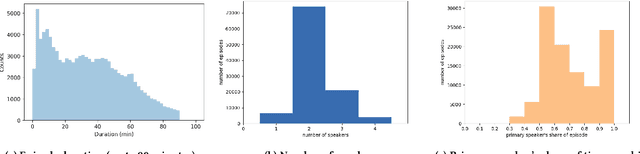
Podcasts are spoken documents across a wide-range of genres and styles, with growing listenership across the world, and a rapidly lowering barrier to entry for both listeners and creators. The great strides in search and recommendation in research and industry have yet to see impact in the podcast space, where recommendations are still largely driven by word of mouth. In this perspective paper, we highlight the many differences between podcasts and other media, and discuss our perspective on challenges and future research directions in the domain of podcast information access.
Persian Natural Language Inference: A Meta-learning approach
May 18, 2022
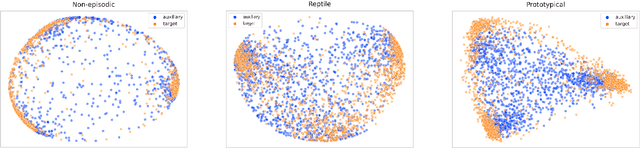
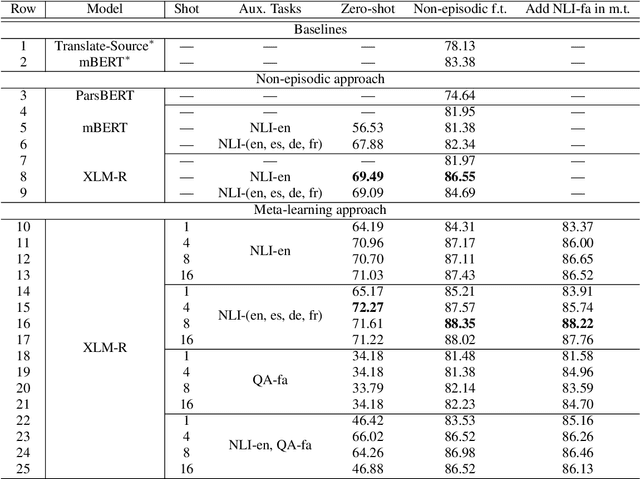
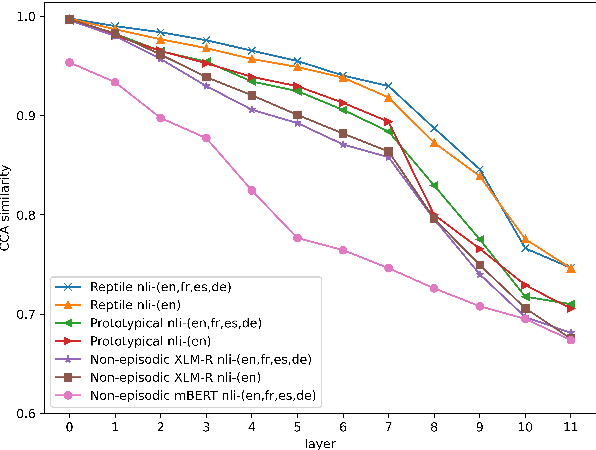
Incorporating information from other languages can improve the results of tasks in low-resource languages. A powerful method of building functional natural language processing systems for low-resource languages is to combine multilingual pre-trained representations with cross-lingual transfer learning. In general, however, shared representations are learned separately, either across tasks or across languages. This paper proposes a meta-learning approach for inferring natural language in Persian. Alternately, meta-learning uses different task information (such as QA in Persian) or other language information (such as natural language inference in English). Also, we investigate the role of task augmentation strategy for forming additional high-quality tasks. We evaluate the proposed method using four languages and an auxiliary task. Compared to the baseline approach, the proposed model consistently outperforms it, improving accuracy by roughly six percent. We also examine the effect of finding appropriate initial parameters using zero-shot evaluation and CCA similarity.
Multilevel Hierarchical Network with Multiscale Sampling for Video Question Answering
May 09, 2022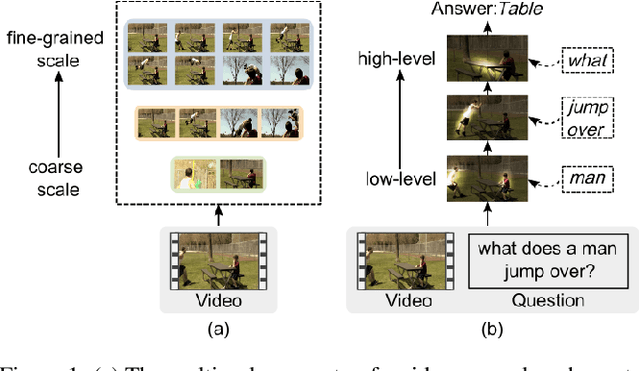
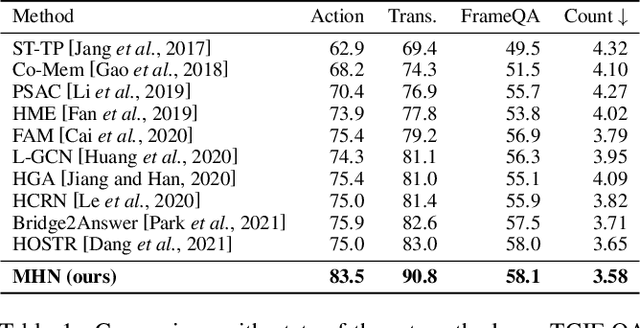
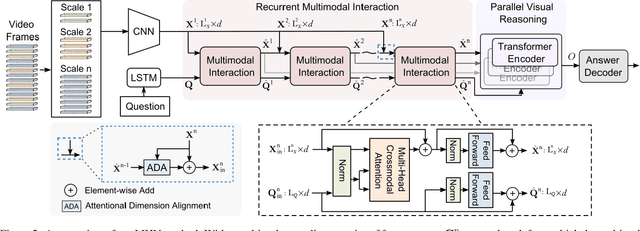
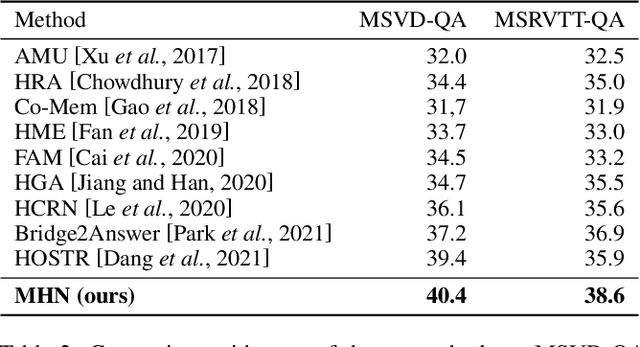
Video question answering (VideoQA) is challenging given its multimodal combination of visual understanding and natural language processing. While most existing approaches ignore the visual appearance-motion information at different temporal scales, it is unknown how to incorporate the multilevel processing capacity of a deep learning model with such multiscale information. Targeting these issues, this paper proposes a novel Multilevel Hierarchical Network (MHN) with multiscale sampling for VideoQA. MHN comprises two modules, namely Recurrent Multimodal Interaction (RMI) and Parallel Visual Reasoning (PVR). With a multiscale sampling, RMI iterates the interaction of appearance-motion information at each scale and the question embeddings to build the multilevel question-guided visual representations. Thereon, with a shared transformer encoder, PVR infers the visual cues at each level in parallel to fit with answering different question types that may rely on the visual information at relevant levels. Through extensive experiments on three VideoQA datasets, we demonstrate improved performances than previous state-of-the-arts and justify the effectiveness of each part of our method.
MedFuse: Multi-modal fusion with clinical time-series data and chest X-ray images
Jul 14, 2022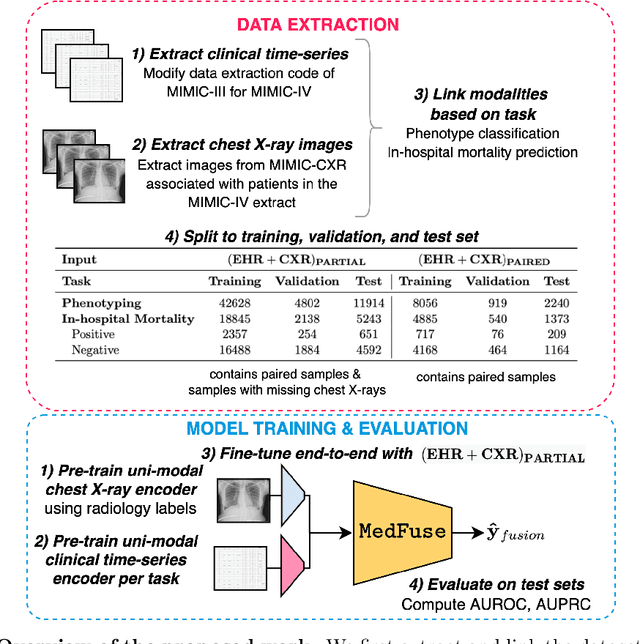
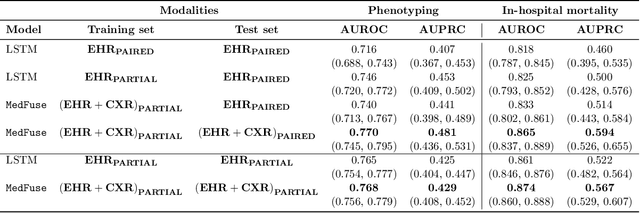
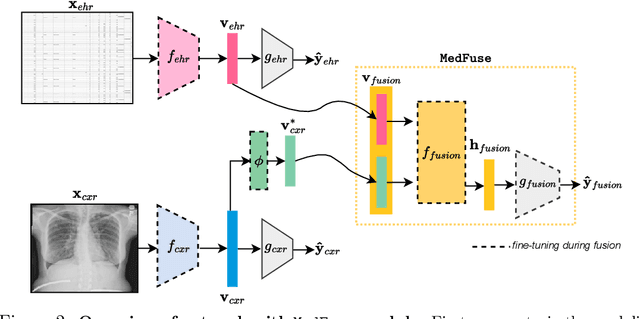
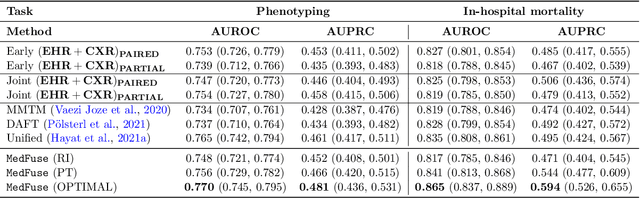
Multi-modal fusion approaches aim to integrate information from different data sources. Unlike natural datasets, such as in audio-visual applications, where samples consist of "paired" modalities, data in healthcare is often collected asynchronously. Hence, requiring the presence of all modalities for a given sample is not realistic for clinical tasks and significantly limits the size of the dataset during training. In this paper, we propose MedFuse, a conceptually simple yet promising LSTM-based fusion module that can accommodate uni-modal as well as multi-modal input. We evaluate the fusion method and introduce new benchmark results for in-hospital mortality prediction and phenotype classification, using clinical time-series data in the MIMIC-IV dataset and corresponding chest X-ray images in MIMIC-CXR. Compared to more complex multi-modal fusion strategies, MedFuse provides a performance improvement by a large margin on the fully paired test set. It also remains robust across the partially paired test set containing samples with missing chest X-ray images. We release our code for reproducibility and to enable the evaluation of competing models in the future.
FuseFormer: Fusing Fine-Grained Information in Transformers for Video Inpainting
Sep 07, 2021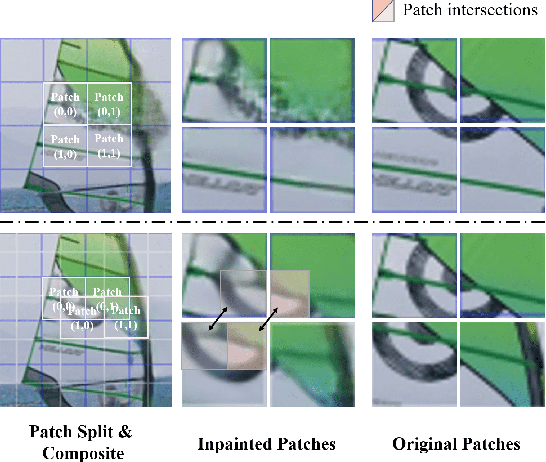
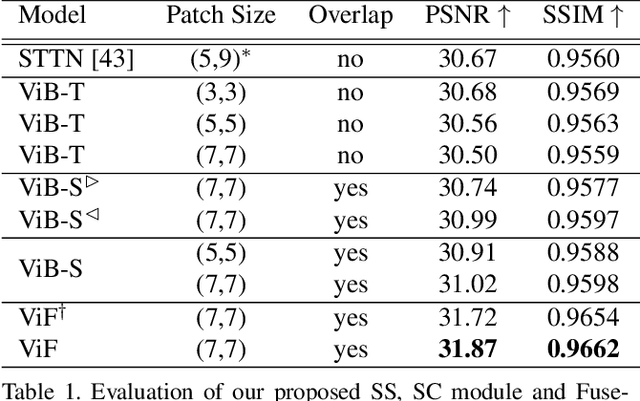
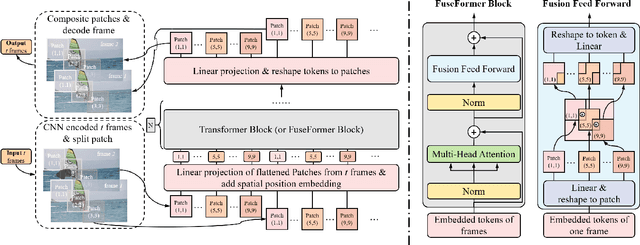
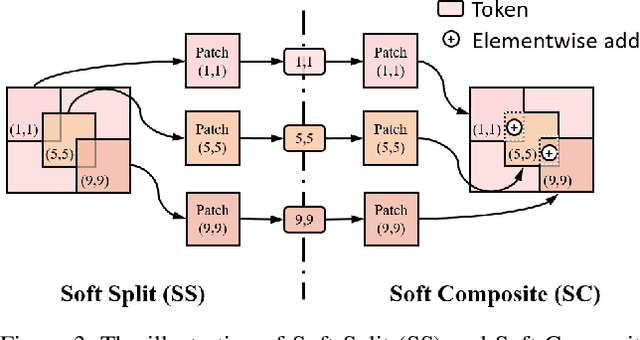
Transformer, as a strong and flexible architecture for modelling long-range relations, has been widely explored in vision tasks. However, when used in video inpainting that requires fine-grained representation, existed method still suffers from yielding blurry edges in detail due to the hard patch splitting. Here we aim to tackle this problem by proposing FuseFormer, a Transformer model designed for video inpainting via fine-grained feature fusion based on novel Soft Split and Soft Composition operations. The soft split divides feature map into many patches with given overlapping interval. On the contrary, the soft composition operates by stitching different patches into a whole feature map where pixels in overlapping regions are summed up. These two modules are first used in tokenization before Transformer layers and de-tokenization after Transformer layers, for effective mapping between tokens and features. Therefore, sub-patch level information interaction is enabled for more effective feature propagation between neighboring patches, resulting in synthesizing vivid content for hole regions in videos. Moreover, in FuseFormer, we elaborately insert the soft composition and soft split into the feed-forward network, enabling the 1D linear layers to have the capability of modelling 2D structure. And, the sub-patch level feature fusion ability is further enhanced. In both quantitative and qualitative evaluations, our proposed FuseFormer surpasses state-of-the-art methods. We also conduct detailed analysis to examine its superiority.
Effectiveness of French Language Models on Abstractive Dialogue Summarization Task
Jul 17, 2022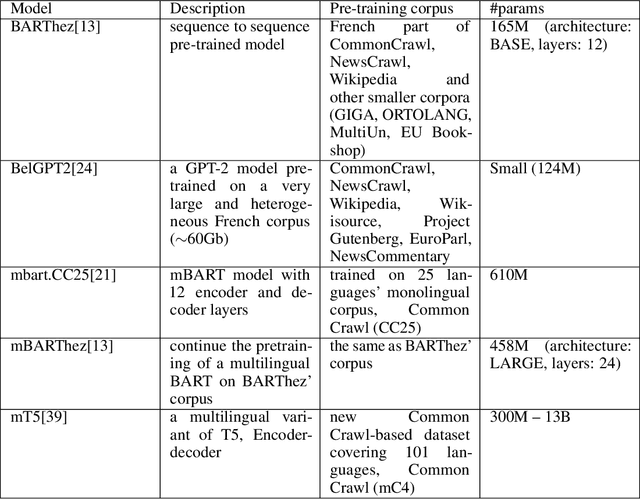
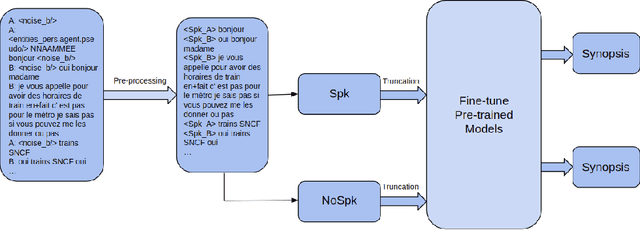


Pre-trained language models have established the state-of-the-art on various natural language processing tasks, including dialogue summarization, which allows the reader to quickly access key information from long conversations in meetings, interviews or phone calls. However, such dialogues are still difficult to handle with current models because the spontaneity of the language involves expressions that are rarely present in the corpora used for pre-training the language models. Moreover, the vast majority of the work accomplished in this field has been focused on English. In this work, we present a study on the summarization of spontaneous oral dialogues in French using several language specific pre-trained models: BARThez, and BelGPT-2, as well as multilingual pre-trained models: mBART, mBARThez, and mT5. Experiments were performed on the DECODA (Call Center) dialogue corpus whose task is to generate abstractive synopses from call center conversations between a caller and one or several agents depending on the situation. Results show that the BARThez models offer the best performance far above the previous state-of-the-art on DECODA. We further discuss the limits of such pre-trained models and the challenges that must be addressed for summarizing spontaneous dialogues.
AttX: Attentive Cross-Connections for Fusion of Wearable Signals in Emotion Recognition
Jun 09, 2022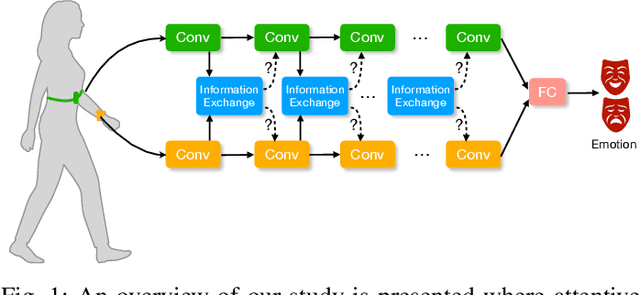
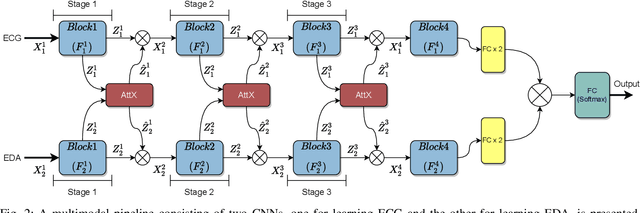
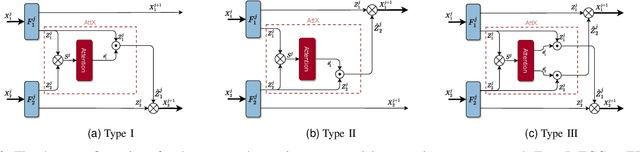
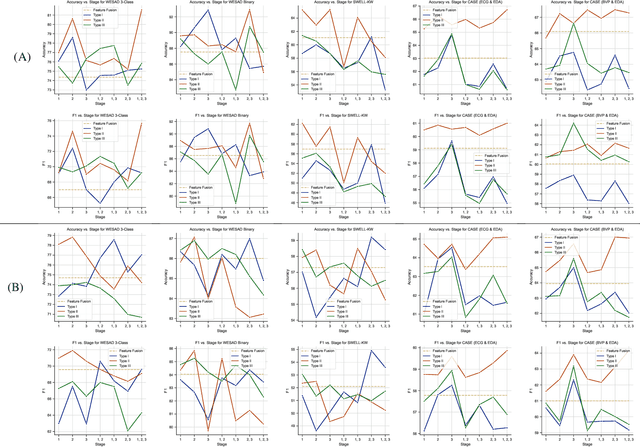
We propose cross-modal attentive connections, a new dynamic and effective technique for multimodal representation learning from wearable data. Our solution can be integrated into any stage of the pipeline, i.e., after any convolutional layer or block, to create intermediate connections between individual streams responsible for processing each modality. Additionally, our method benefits from two properties. First, it can share information uni-directionally (from one modality to the other) or bi-directionally. Second, it can be integrated into multiple stages at the same time to further allow network gradients to be exchanged in several touch-points. We perform extensive experiments on three public multimodal wearable datasets, WESAD, SWELL-KW, and CASE, and demonstrate that our method can effectively regulate and share information between different modalities to learn better representations. Our experiments further demonstrate that once integrated into simple CNN-based multimodal solutions (2, 3, or 4 modalities), our method can result in superior or competitive performance to state-of-the-art and outperform a variety of baseline uni-modal and classical multimodal methods.
Towards Unified Conversational Recommender Systems via Knowledge-Enhanced Prompt Learning
Jun 19, 2022
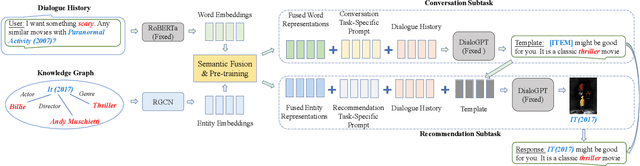
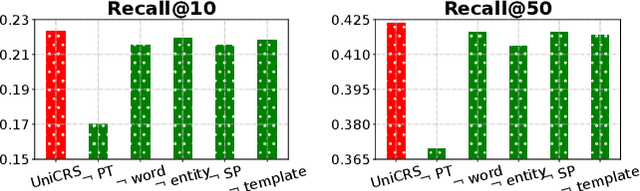
Conversational recommender systems (CRS) aim to proactively elicit user preference and recommend high-quality items through natural language conversations. Typically, a CRS consists of a recommendation module to predict preferred items for users and a conversation module to generate appropriate responses. To develop an effective CRS, it is essential to seamlessly integrate the two modules. Existing works either design semantic alignment strategies, or share knowledge resources and representations between the two modules. However, these approaches still rely on different architectures or techniques to develop the two modules, making it difficult for effective module integration. To address this problem, we propose a unified CRS model named UniCRS based on knowledge-enhanced prompt learning. Our approach unifies the recommendation and conversation subtasks into the prompt learning paradigm, and utilizes knowledge-enhanced prompts based on a fixed pre-trained language model (PLM) to fulfill both subtasks in a unified approach. In the prompt design, we include fused knowledge representations, task-specific soft tokens, and the dialogue context, which can provide sufficient contextual information to adapt the PLM for the CRS task. Besides, for the recommendation subtask, we also incorporate the generated response template as an important part of the prompt, to enhance the information interaction between the two subtasks. Extensive experiments on two public CRS datasets have demonstrated the effectiveness of our approach.