 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sparse Attentive Memory Network for Click-through Rate Prediction with Long Sequences
Aug 08, 2022
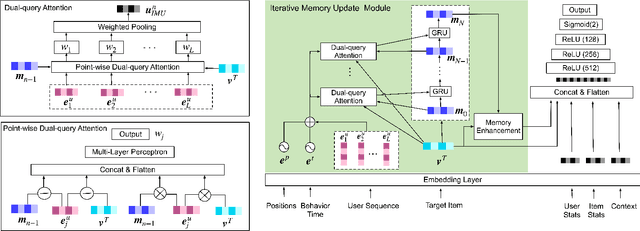
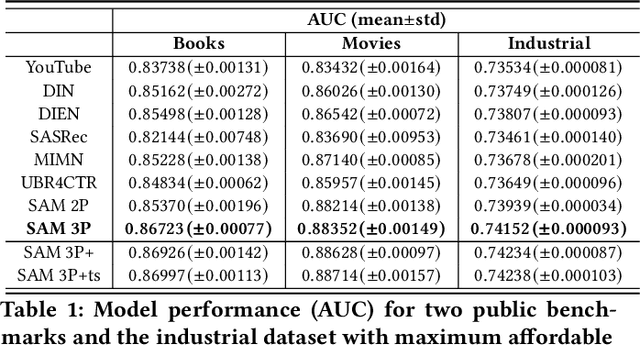
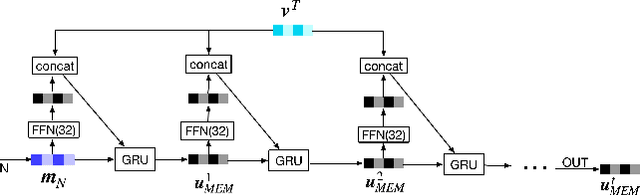
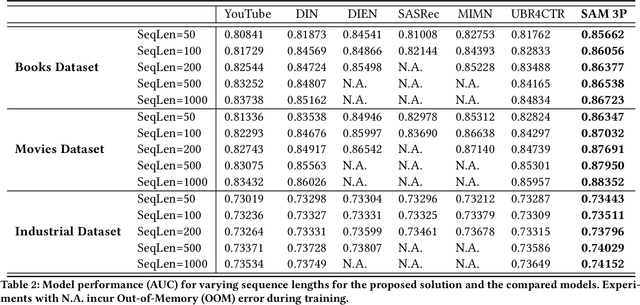
Sequential recommendation predicts users' next behaviors with their historical interactions. Recommending with longer sequences improves recommendation accuracy and increases the degree of personalization. As sequences get longer, existing works have not yet addressed the following two main challenges. Firstly, modeling long-range intra-sequence dependency is difficult with increasing sequence lengths. Secondly, it requires efficient memory and computational speeds. In this paper, we propose a Sparse Attentive Memory (SAM) network for long sequential user behavior modeling. SAM supports efficient training and real-time inference for user behavior sequences with lengths on the scale of thousands. In SAM, we model the target item as the query and the long sequence as the knowledge database, where the former continuously elicits relevant information from the latter. SAM simultaneously models target-sequence dependencies and long-range intra-sequence dependencies with O(L) complexity and O(1) number of sequential updates, which can only be achieved by the self-attention mechanism with O(L^2) complexity. Extensive empirical results demonstrate that our proposed solution is effective not only in long user behavior modeling but also on short sequences modeling. Implemented on sequences of length 1000, SAM is successfully deployed on one of the largest international E-commerce platforms. This inference time is within 30ms, with a substantial 7.30% click-through rate improvement for the online A/B test. To the best of our knowledge, it is the first end-to-end long user sequence modeling framework that models intra-sequence and target-sequence dependencies with the aforementioned degree of efficiency and successfully deployed on a large-scale real-time industrial recommender system.
Aerial Monocular 3D Object Detection
Aug 08, 2022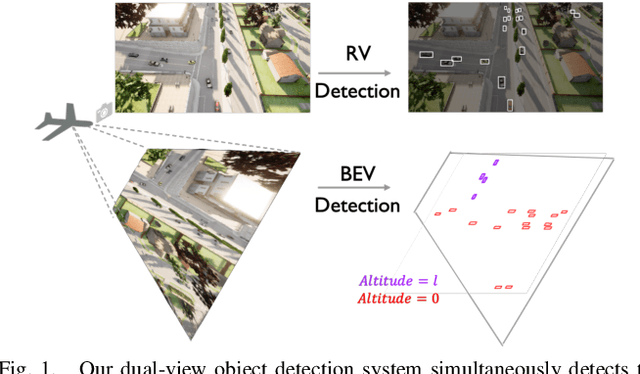

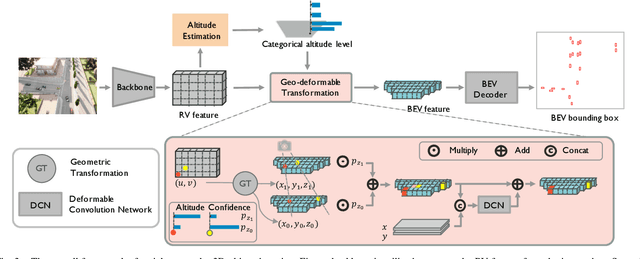
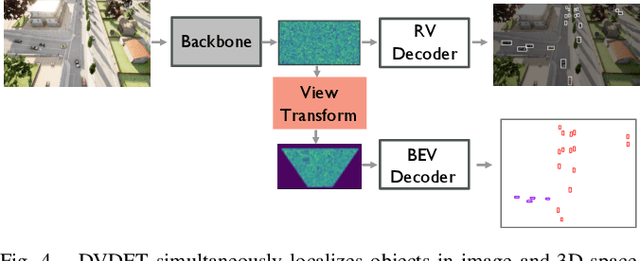
Drones equipped with cameras can significantly enhance human ability to perceive the world because of their remarkable maneuverability in 3D space. Ironically, object detection for drones has always been conducted in the 2D image space, which fundamentally limits their ability to understand 3D scenes. Furthermore, existing 3D object detection methods developed for autonomous driving cannot be directly applied to drones due to the lack of deformation modeling, which is essential for the distant aerial perspective with sensitive distortion and small objects. To fill the gap, this work proposes a dual-view detection system named DVDET to achieve aerial monocular object detection in both the 2D image space and the 3D physical space. To address the severe view deformation issue, we propose a novel trainable geo-deformable transformation module that can properly warp information from the drone's perspective to the BEV. Compared to the monocular methods for cars, our transformation includes a learnable deformable network for explicitly revising the severe deviation. To address the dataset challenge, we propose a new large-scale simulation dataset named AM3D-Sim, generated by the co-simulation of AirSIM and CARLA, and a new real-world aerial dataset named AM3D-Real, collected by DJI Matrice 300 RTK, in both datasets, high-quality annotations for 3D object detection are provided. Extensive experiments show that i) aerial monocular 3D object detection is feasible; ii) the model pre-trained on the simulation dataset benefits real-world performance, and iii) DVDET also benefits monocular 3D object detection for cars. To encourage more researchers to investigate this area, we will release the dataset and related code in https://sjtu-magic.github.io/dataset/AM3D/.
CSSAM:Code Search via Attention Matching of Code Semantics and Structures
Aug 08, 2022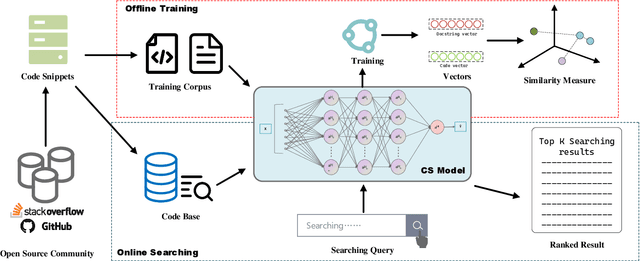
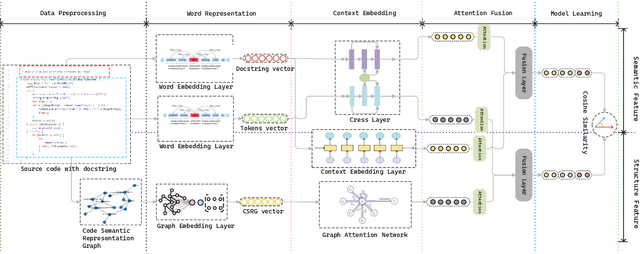

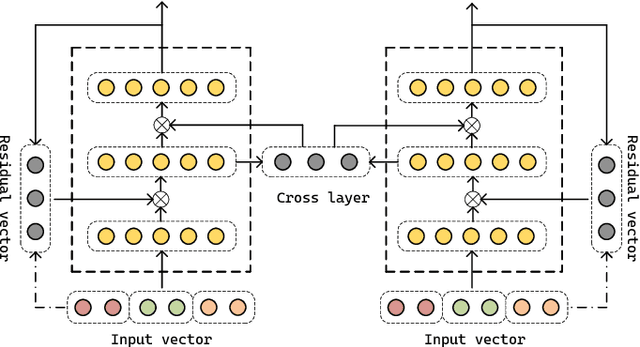
Despite the continuous efforts in improving both the effectiveness and efficiency of code search, two issues remained unsolved. First, programming languages have inherent strong structural linkages, and feature mining of code as text form would omit the structural information contained inside it. Second, there is a potential semantic relationship between code and query, it is challenging to align code and text across sequences so that vectors are spatially consistent during similarity matching. To tackle both issues, in this paper, a code search model named CSSAM (Code Semantics and Structures Attention Matching) is proposed. By introducing semantic and structural matching mechanisms, CSSAM effectively extracts and fuses multidimensional code features. Specifically, the cross and residual layer was developed to facilitate high-latitude spatial alignment of code and query at the token level. By leveraging the residual interaction, a matching module is designed to preserve more code semantics and descriptive features, that enhances the adhesion between the code and its corresponding query text. Besides, to improve the model's comprehension of the code's inherent structure, a code representation structure named CSRG (Code Semantic Representation Graph) is proposed for jointly representing abstract syntax tree nodes and the data flow of the codes. According to the experimental results on two publicly available datasets containing 540k and 330k code segments, CSSAM significantly outperforms the baselines in terms of achieving the highest SR@1/5/10, MRR, and NDCG@50 on both datasets respectively. Moreover, the ablation study is conducted to quantitatively measure the impact of each key component of CSSAM on the efficiency and effectiveness of code search, which offers the insights into the improvement of advanced code search solutions.
Information algebras of coherent sets of gambles in general possibility spaces
May 25, 2021In this paper, we show that coherent sets of gambles can be embedded into the algebraic structure of information algebra. This leads firstly, to a new perspective of the algebraic and logical structure of desirability and secondly, it connects desirability, hence imprecise probabilities, to other formalism in computer science sharing the same underlying structure. Both the domain-free and the labeled view of the information algebra of coherent sets of gambles are presented, considering general possibility spaces.
Structural Prior Guided Generative Adversarial Transformers for Low-Light Image Enhancement
Jul 19, 2022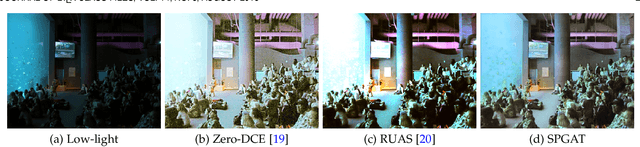
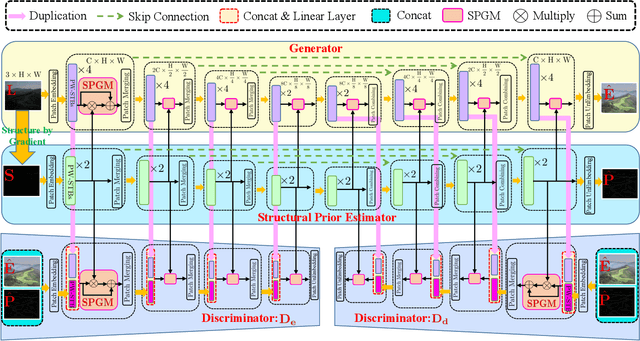


We propose an effective Structural Prior guided Generative Adversarial Transformer (SPGAT) to solve low-light image enhancement. Our SPGAT mainly contains a generator with two discriminators and a structural prior estimator (SPE). The generator is based on a U-shaped Transformer which is used to explore non-local information for better clear image restoration. The SPE is used to explore useful structures from images to guide the generator for better structural detail estimation. To generate more realistic images, we develop a new structural prior guided adversarial learning method by building the skip connections between the generator and discriminators so that the discriminators can better discriminate between real and fake features. Finally, we propose a parallel windows-based Swin Transformer block to aggregate different level hierarchical features for high-quality image restoration. Experimental results demonstrate that the proposed SPGAT performs favorably against recent state-of-the-art methods on both synthetic and real-world datasets.
Context-aware Proposal Network for Temporal Action Detection
Jun 18, 2022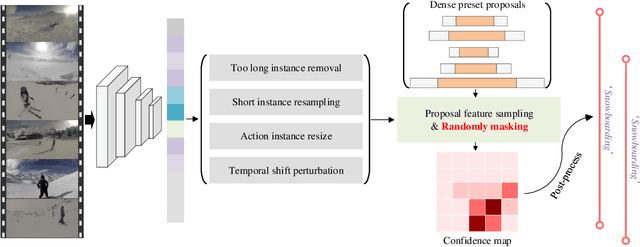
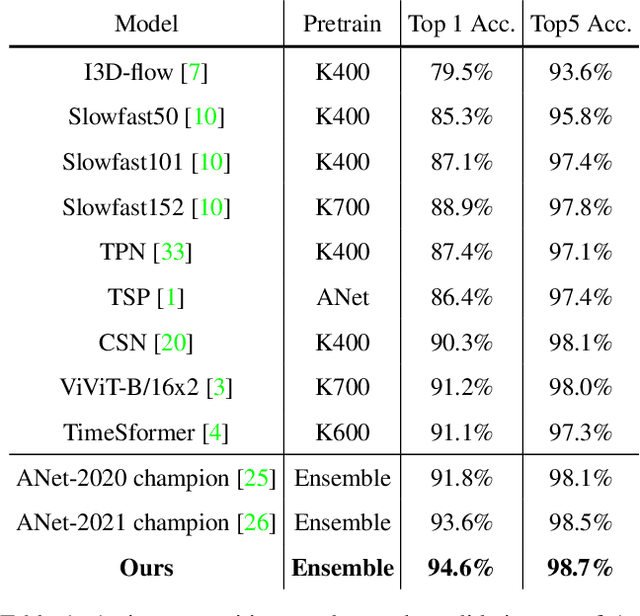

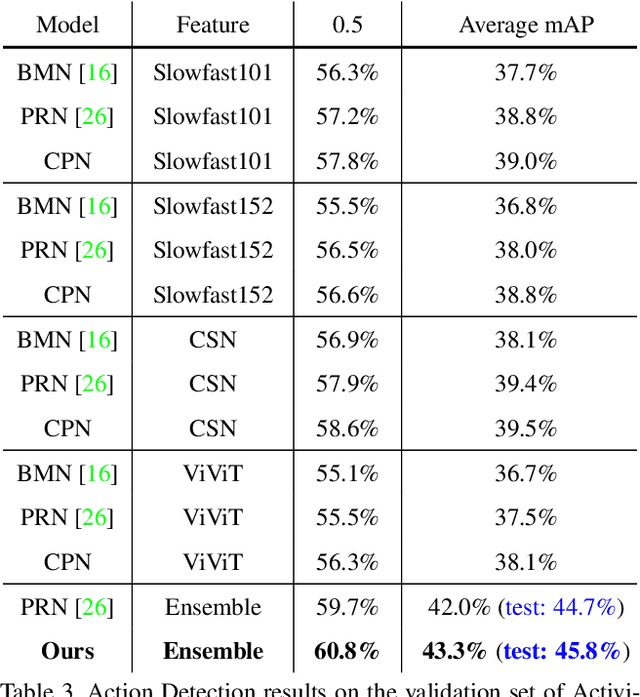
This technical report presents our first place winning solution for temporal action detection task in CVPR-2022 AcitivityNet Challenge. The task aims to localize temporal boundaries of action instances with specific classes in long untrimmed videos. Recent mainstream attempts are based on dense boundary matchings and enumerate all possible combinations to produce proposals. We argue that the generated proposals contain rich contextual information, which may benefits detection confidence prediction. To this end, our method mainly consists of the following three steps: 1) action classification and feature extraction by Slowfast, CSN, TimeSformer, TSP, I3D-flow, VGGish-audio, TPN and ViViT; 2) proposal generation. Our proposed Context-aware Proposal Network (CPN) builds on top of BMN, GTAD and PRN to aggregate contextual information by randomly masking some proposal features. 3) action detection. The final detection prediction is calculated by assigning the proposals with corresponding video-level classifcation results. Finally, we ensemble the results under different feature combination settings and achieve 45.8% performance on the test set, which improves the champion result in CVPR-2021 ActivityNet Challenge by 1.1% in terms of average mAP.
Explaining Dynamic Graph Neural Networks via Relevance Back-propagation
Jul 22, 2022
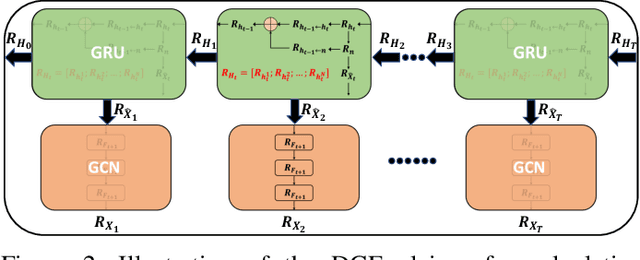
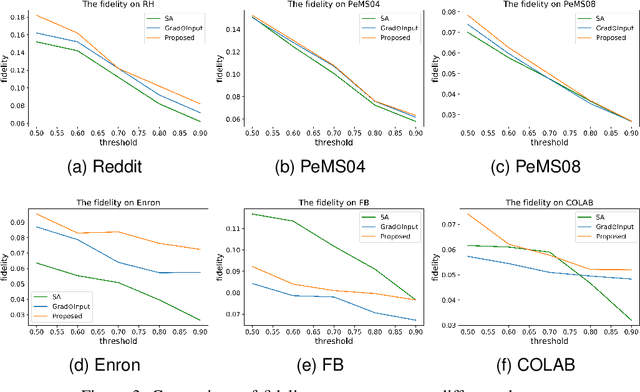
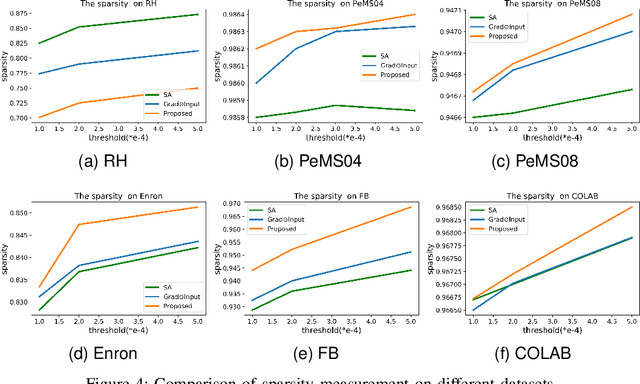
Graph Neural Networks (GNNs) have shown remarkable effectiveness in capturing abundant information in graph-structured data. However, the black-box nature of GNNs hinders users from understanding and trusting the models, thus leading to difficulties in their applications. While recent years witness the prosperity of the studies on explaining GNNs, most of them focus on static graphs, leaving the explanation of dynamic GNNs nearly unexplored. It is challenging to explain dynamic GNNs, due to their unique characteristic of time-varying graph structures. Directly using existing models designed for static graphs on dynamic graphs is not feasible because they ignore temporal dependencies among the snapshots. In this work, we propose DGExplainer to provide reliable explanation on dynamic GNNs. DGExplainer redistributes the output activation score of a dynamic GNN to the relevances of the neurons of its previous layer, which iterates until the relevance scores of the input neuron are obtained. We conduct quantitative and qualitative experiments on real-world datasets to demonstrate the effectiveness of the proposed framework for identifying important nodes for link prediction and node regression for dynamic GNNs.
VIRATrustData: A Trust-Annotated Corpus of Human-Chatbot Conversations About COVID-19 Vaccines
May 24, 2022
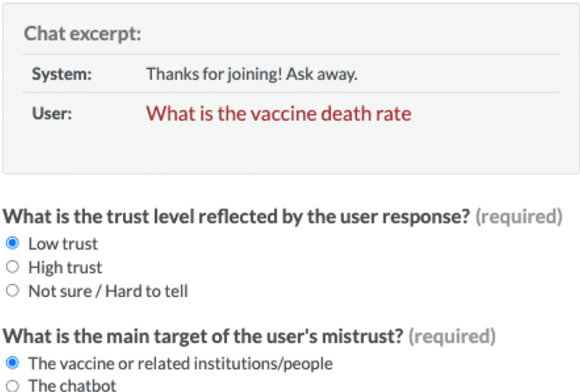
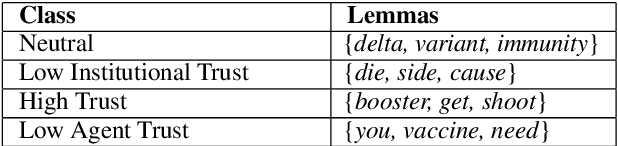
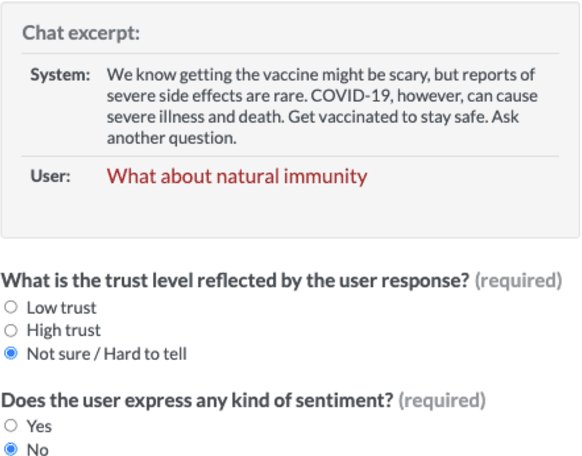
Public trust in medical information is crucial for successful application of public health policies such as vaccine uptake. This is especially true when the information is offered remotely, by chatbots, which have become increasingly popular in recent years. Here, we explore the challenging task of human-bot turn-level trust classification. We rely on a recently released data of observationally-collected (rather than crowdsourced) dialogs with VIRA chatbot, a COVID-19 Vaccine Information Resource Assistant. These dialogs are centered around questions and concerns about COVID-19 vaccines, where trust is particularly acute. We annotated $3k$ VIRA system-user conversational turns for Low Institutional Trust or Low Agent Trust vs. Neutral or High Trust. We release the labeled dataset, VIRATrustData, the first of its kind to the best of our knowledge. We demonstrate how this task is non-trivial and compare several models that predict the different levels of trust.
A Superimposed Divide-and-Conquer Image Recognition Method for SEM Images of Nanoparticles on The Surface of Monocrystalline silicon with High Aggregation Degree
Jun 04, 2022


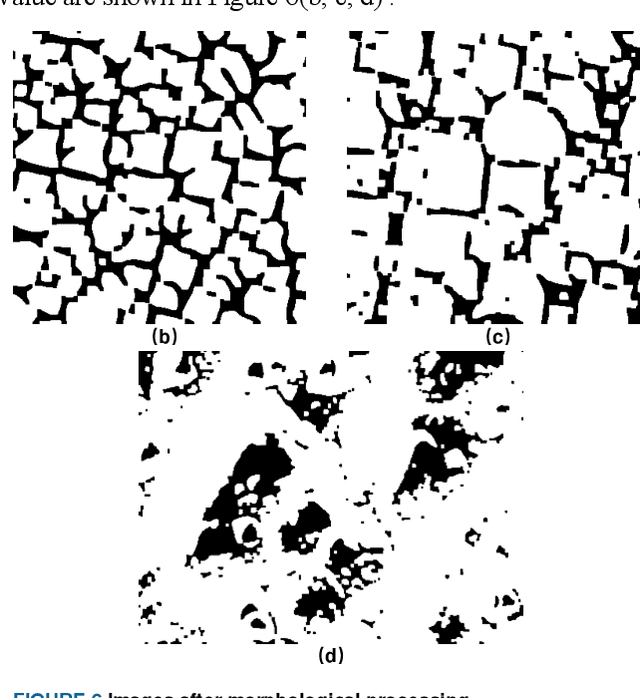
The nanoparticle size and distribution information in the SEM images of silicon crystals are generally counted by manual methods. The realization of automatic machine recognition is significant in materials science. This paper proposed a superposition partitioning image recognition method to realize automatic recognition and information statistics of silicon crystal nanoparticle SEM images. Especially for the complex and highly aggregated characteristics of silicon crystal particle size, an accurate recognition step and contour statistics method based on morphological processing are given. This method has technical reference value for the recognition of Monocrystalline silicon surface nanoparticle images under different SEM shooting conditions. Besides, it outperforms other methods in terms of recognition accuracy and algorithm efficiency.
Deep Upper Confidence Bound Algorithm for Contextual Bandit Ranking of Information Selection
Oct 08, 2021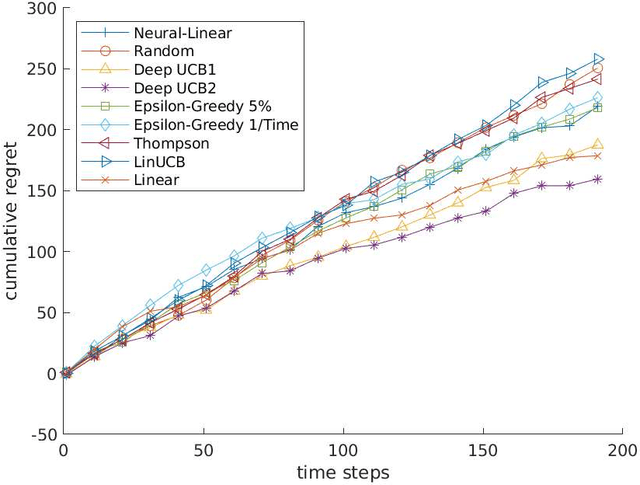
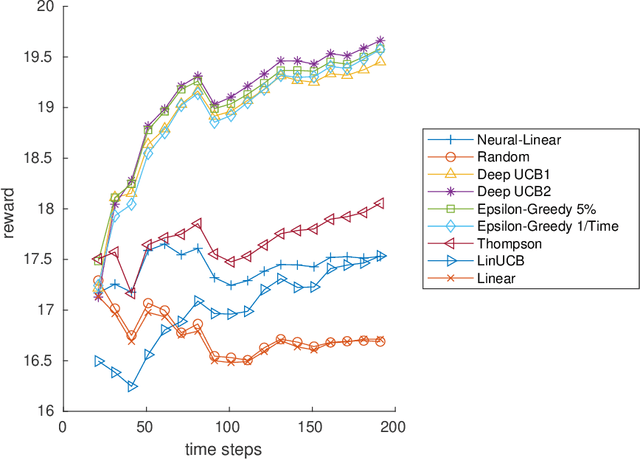
Contextual multi-armed bandits (CMAB) have been widely used for learning to filter and prioritize information according to a user's interest. In this work, we analyze top-K ranking under the CMAB framework where the top-K arms are chosen iteratively to maximize a reward. The context, which represents a set of observable factors related to the user, is used to increase prediction accuracy compared to a standard multi-armed bandit. Contextual bandit methods have mostly been studied under strict linearity assumptions, but we drop that assumption and learn non-linear stochastic reward functions with deep neural networks. We introduce a novel algorithm called the Deep Upper Confidence Bound (UCB) algorithm. Deep UCB balances exploration and exploitation with a separate neural network to model the learning convergence. We compare the performance of many bandit algorithms varying K over real-world data sets with high-dimensional data and non-linear reward functions. Empirical results show that the performance of Deep UCB often outperforms though it is sensitive to the problem and reward setup. Additionally, we prove theoretical regret bounds on Deep UCB giving convergence to optimality for the weak class of CMAB problems.