 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Open Terminology Management and Sharing Toolkit for Federation of Terminology Databases
Jul 14, 2022
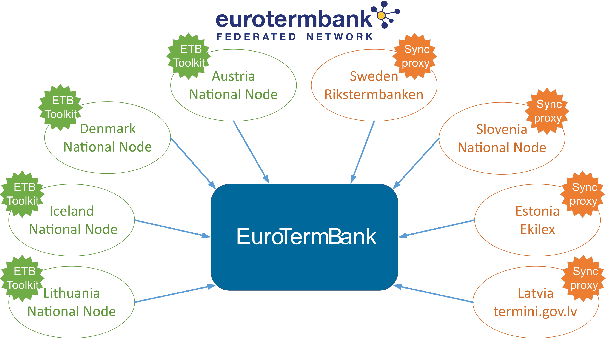
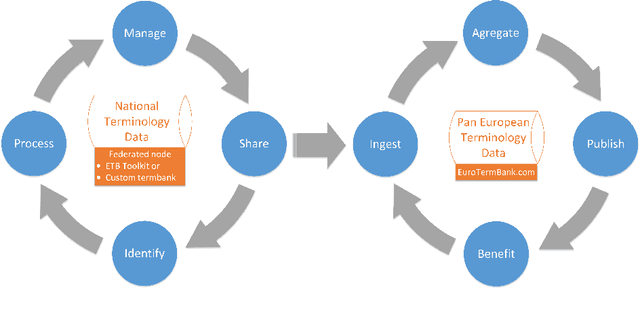
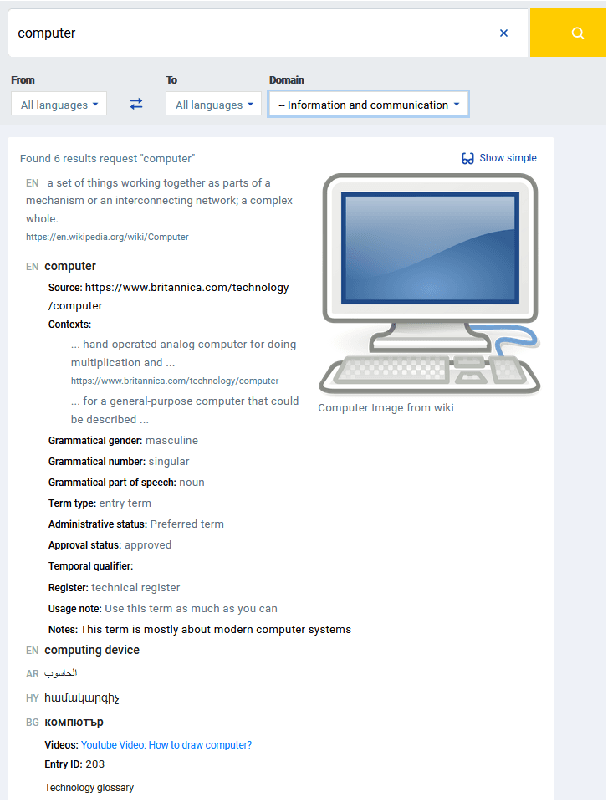
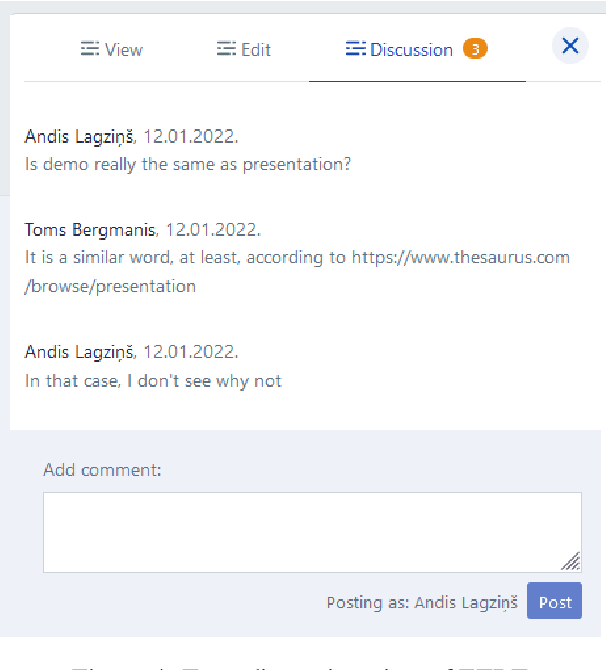
Consolidated access to current and reliable terms from different subject fields and languages is necessary for content creators and translators. Terminology is also needed in AI applications such as machine translation, speech recognition, information extraction, and other natural language processing tools. In this work, we facilitate standards-based sharing and management of terminology resources by providing an open terminology management solution - the EuroTermBank Toolkit. It allows organisations to manage and search their terms, create term collections, and share them within and outside the organisation by participating in the network of federated databases. The data curated in the federated databases are automatically shared with EuroTermBank, the largest multilingual terminology resource in Europe, allowing translators and language service providers as well as researchers and students to access terminology resources in their most current version.
HyGNN: Drug-Drug Interaction Prediction via Hypergraph Neural Network
Jun 25, 2022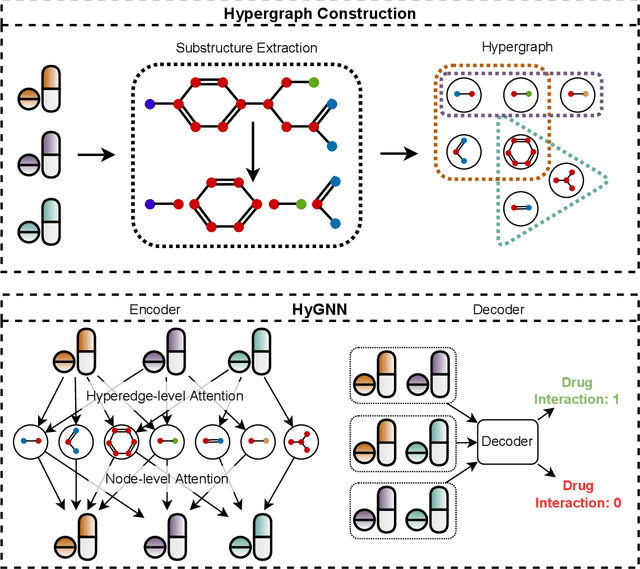
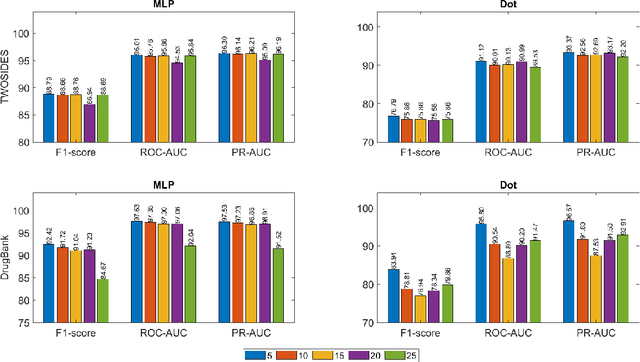
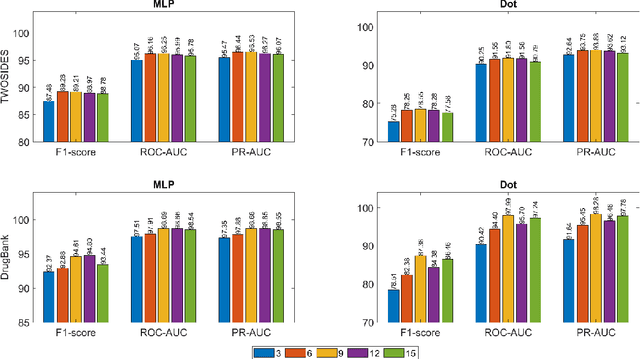
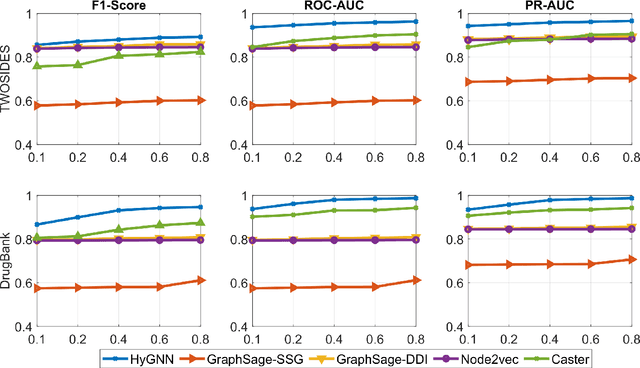
Drug-Drug Interactions (DDIs) may hamper the functionalities of drugs, and in the worst scenario, they may lead to adverse drug reactions (ADRs). Predicting all DDIs is a challenging and critical problem. Most existing computational models integrate drug-centric information from different sources and leverage them as features in machine learning classifiers to predict DDIs. However, these models have a high chance of failure, especially for the new drugs when all the information is not available. This paper proposes a novel Hypergraph Neural Network (HyGNN) model based on only the SMILES string of drugs, available for any drug, for the DDI prediction problem. To capture the drug similarities, we create a hypergraph from drugs' chemical substructures extracted from the SMILES strings. Then, we develop HyGNN consisting of a novel attention-based hypergraph edge encoder to get the representation of drugs as hyperedges and a decoder to predict the interactions between drug pairs. Furthermore, we conduct extensive experiments to evaluate our model and compare it with several state-of-the-art methods. Experimental results demonstrate that our proposed HyGNN model effectively predicts DDIs and impressively outperforms the baselines with a maximum ROC-AUC and PR-AUC of 97.9% and 98.1%, respectively.
MIA 2022 Shared Task Submission: Leveraging Entity Representations, Dense-Sparse Hybrids, and Fusion-in-Decoder for Cross-Lingual Question Answering
Jul 18, 2022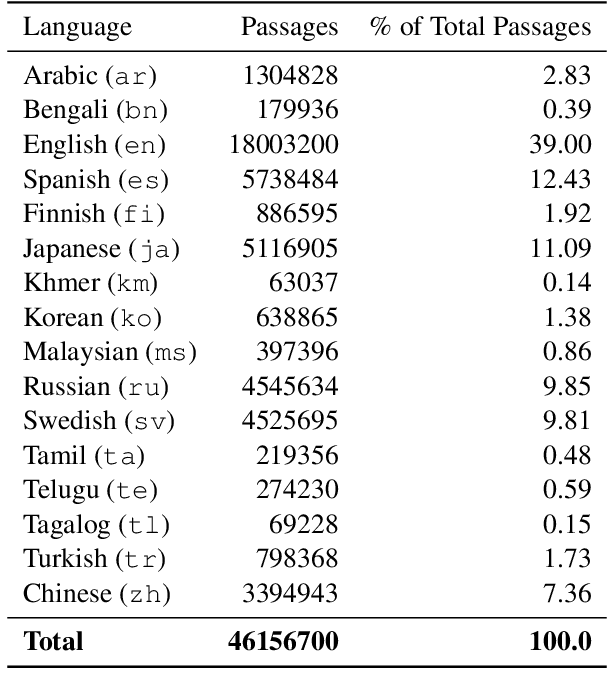
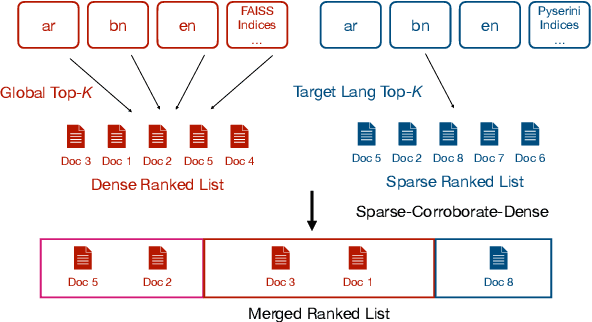


We describe our two-stage system for the Multilingual Information Access (MIA) 2022 Shared Task on Cross-Lingual Open-Retrieval Question Answering. The first stage consists of multilingual passage retrieval with a hybrid dense and sparse retrieval strategy. The second stage consists of a reader which outputs the answer from the top passages returned by the first stage. We show the efficacy of using a multilingual language model with entity representations in pretraining, sparse retrieval signals to help dense retrieval, and Fusion-in-Decoder. On the development set, we obtain 43.46 F1 on XOR-TyDi QA and 21.99 F1 on MKQA, for an average F1 score of 32.73. On the test set, we obtain 40.93 F1 on XOR-TyDi QA and 22.29 F1 on MKQA, for an average F1 score of 31.61. We improve over the official baseline by over 4 F1 points on both the development and test sets.
Equivariant Representation Learning via Class-Pose Decomposition
Jul 07, 2022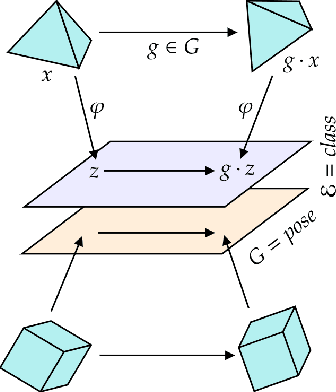
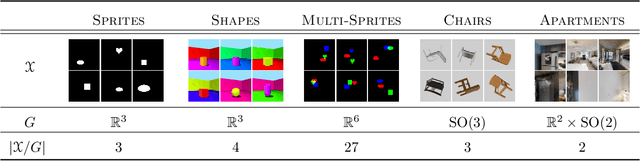
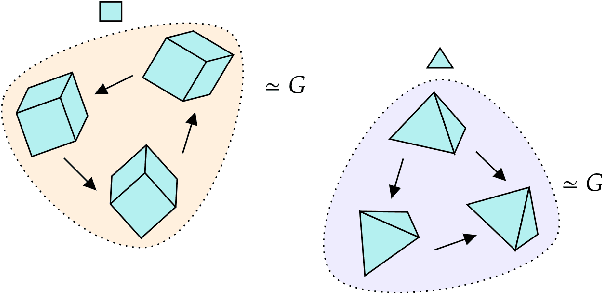
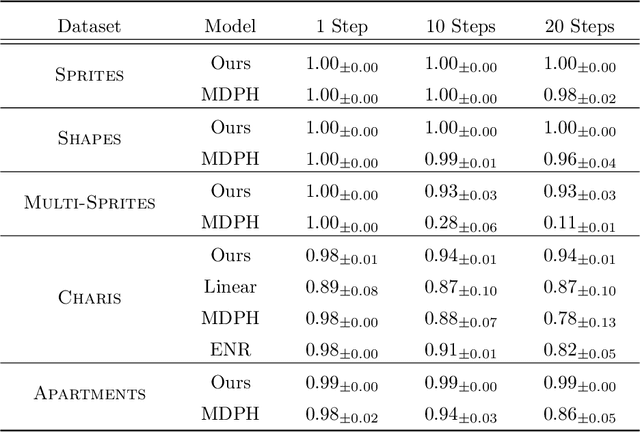
We introduce a general method for learning representations that are equivariant to symmetries of data. The central idea is to to decompose the latent space in an invariant factor and the symmetry group itself. The components semantically correspond to intrinsic data classes and poses respectively. The learner is self-supervised and infers these semantics based on relative symmetry information. The approach is motivated by theoretical results from group theory and guarantees representations that are lossless, interpretable and disentangled. We empirically investigate the approach via experiments involving datasets with a variety of symmetries. Results show that our representations capture the geometry of data and outperform other equivariant representation learning frameworks.
Contrastive Image Synthesis and Self-supervised Feature Adaptation for Cross-Modality Biomedical Image Segmentation
Jul 27, 2022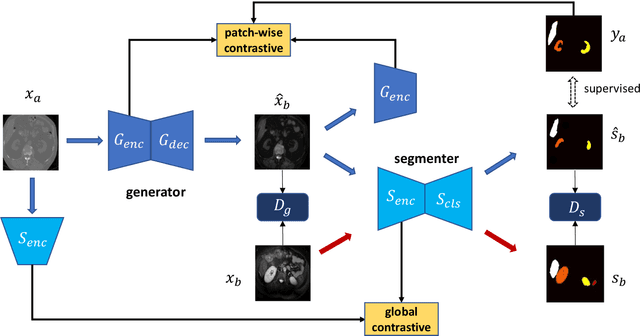
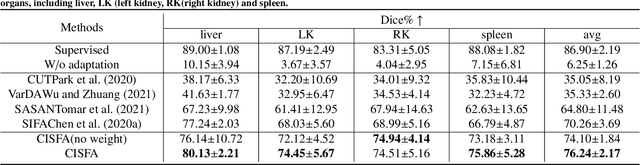
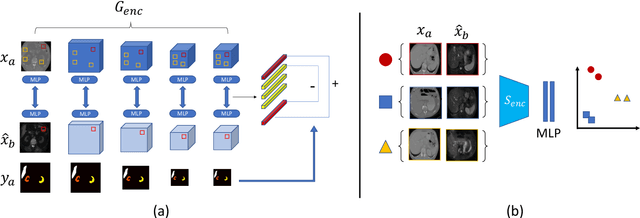
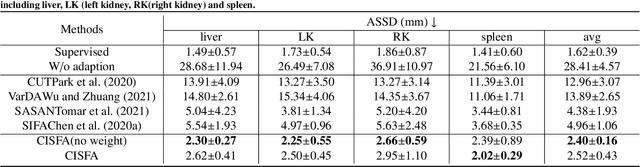
This work presents a novel framework CISFA (Contrastive Image synthesis and Self-supervised Feature Adaptation)that builds on image domain translation and unsupervised feature adaptation for cross-modality biomedical image segmentation. Different from existing works, we use a one-sided generative model and add a weighted patch-wise contrastive loss between sampled patches of the input image and the corresponding synthetic image, which serves as shape constraints. Moreover, we notice that the generated images and input images share similar structural information but are in different modalities. As such, we enforce contrastive losses on the generated images and the input images to train the encoder of a segmentation model to minimize the discrepancy between paired images in the learned embedding space. Compared with existing works that rely on adversarial learning for feature adaptation, such a method enables the encoder to learn domain-independent features in a more explicit way. We extensively evaluate our methods on segmentation tasks containing CT and MRI images for abdominal cavities and whole hearts. Experimental results show that the proposed framework not only outputs synthetic images with less distortion of organ shapes, but also outperforms state-of-the-art domain adaptation methods by a large margin.
Adaptive Feature Fusion for Cooperative Perception using LiDAR Point Clouds
Jul 30, 2022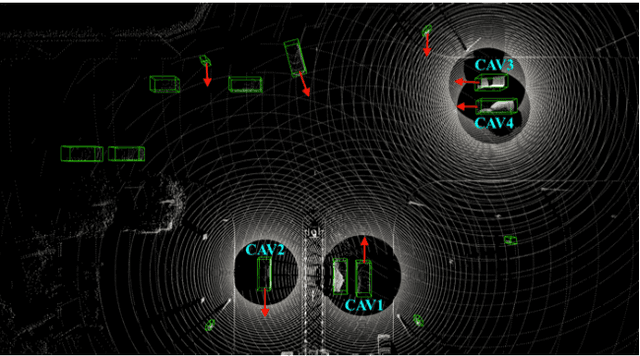
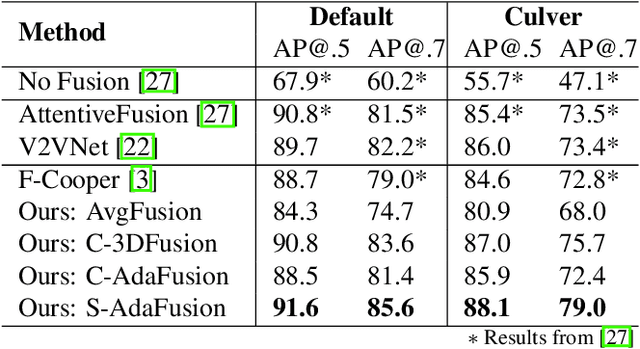
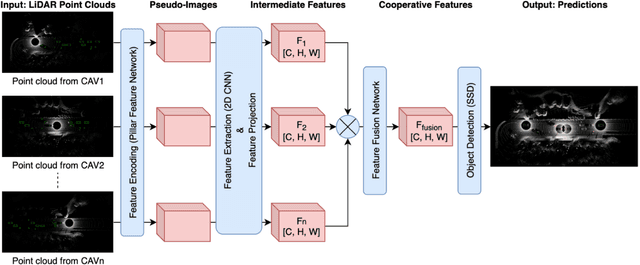
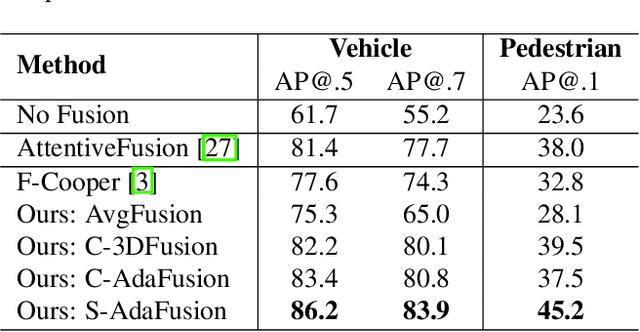
Cooperative perception allows a Connected Autonomous Vehicle (CAV) to interact with the other CAVs in the vicinity to enhance perception of surrounding objects to increase safety and reliability. It can compensate for the limitations of the conventional vehicular perception such as blind spots, low resolution, and weather effects. An effective feature fusion model for the intermediate fusion methods of cooperative perception can improve feature selection and information aggregation to further enhance the perception accuracy. We propose adaptive feature fusion models with trainable feature selection modules. One of our proposed models Spatial-wise Adaptive feature Fusion (S-AdaFusion) outperforms all other state-of-the-art models on the two subsets of OPV2V dataset: default CARLA towns for vehicle detection and the Culver City for domain adaptation. In addition, previous studies have only tested cooperative perception for vehicle detection. A pedestrian, however, is much more likely to be seriously injured in a traffic accident. We evaluate the performance of cooperative perception for both vehicle and pedestrian detection using the CODD dataset. Our architecture achieves higher Average Precision (AP) than other existing models for both vehicle and pedestrian detection on the CODD dataset. The experiments demonstrate that cooperative perception also can improve the pedestrian detection accuracy compared to the conventional perception process.
Improved Pancreatic Tumor Detection by Utilizing Clinically-Relevant Secondary Features
Aug 06, 2022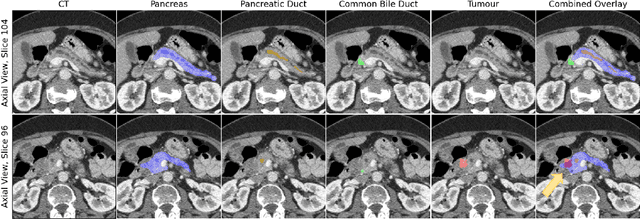
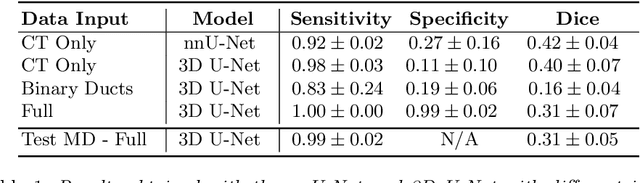
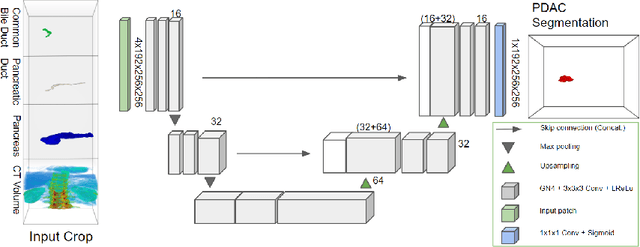

Pancreatic cancer is one of the global leading causes of cancer-related deaths. Despite the success of Deep Learning in computer-aided diagnosis and detection (CAD) methods, little attention has been paid to the detection of Pancreatic Cancer. We propose a method for detecting pancreatic tumor that utilizes clinically-relevant features in the surrounding anatomical structures, thereby better aiming to exploit the radiologist's knowledge compared to other, conventional deep learning approaches. To this end, we collect a new dataset consisting of 99 cases with pancreatic ductal adenocarcinoma (PDAC) and 97 control cases without any pancreatic tumor. Due to the growth pattern of pancreatic cancer, the tumor may not be always visible as a hypodense lesion, therefore experts refer to the visibility of secondary external features that may indicate the presence of the tumor. We propose a method based on a U-Net-like Deep CNN that exploits the following external secondary features: the pancreatic duct, common bile duct and the pancreas, along with a processed CT scan. Using these features, the model segments the pancreatic tumor if it is present. This segmentation for classification and localization approach achieves a performance of 99% sensitivity (one case missed) and 99% specificity, which realizes a 5% increase in sensitivity over the previous state-of-the-art method. The model additionally provides location information with reasonable accuracy and a shorter inference time compared to previous PDAC detection methods. These results offer a significant performance improvement and highlight the importance of incorporating the knowledge of the clinical expert when developing novel CAD methods.
High-Resolution Swin Transformer for Automatic Medical Image Segmentation
Jul 23, 2022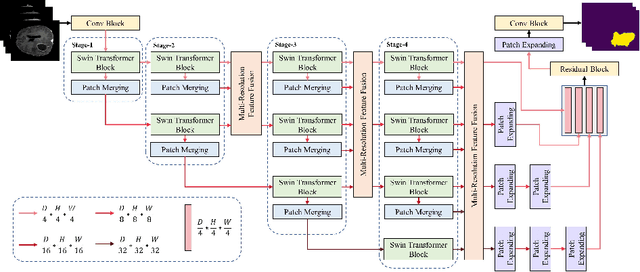
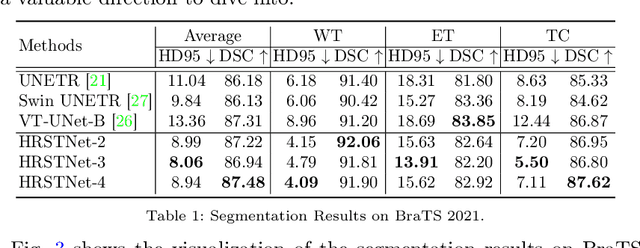
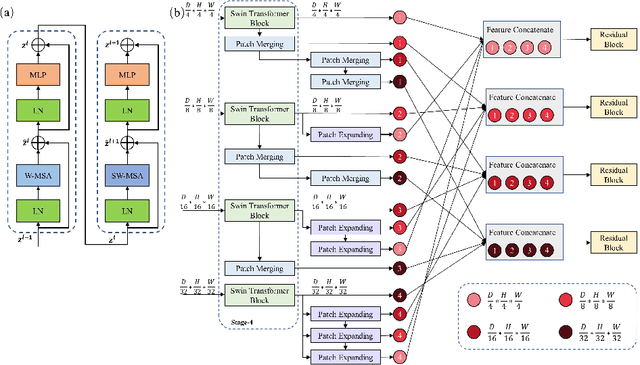
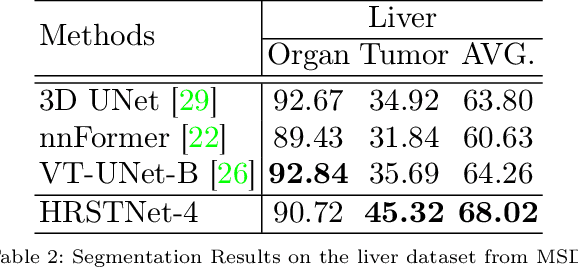
The Resolution of feature maps is critical for medical image segmentation. Most of the existing Transformer-based networks for medical image segmentation are U-Net-like architecture that contains an encoder that utilizes a sequence of Transformer blocks to convert the input medical image from high-resolution representation into low-resolution feature maps and a decoder that gradually recovers the high-resolution representation from low-resolution feature maps. Unlike previous studies, in this paper, we utilize the network design style from the High-Resolution Network (HRNet), replace the convolutional layers with Transformer blocks, and continuously exchange information from the different resolution feature maps that are generated by Transformer blocks. The newly Transformer-based network presented in this paper is denoted as High-Resolution Swin Transformer Network (HRSTNet). Extensive experiments illustrate that HRSTNet can achieve comparable performance with the state-of-the-art Transformer-based U-Net-like architecture on Brain Tumor Segmentation(BraTS) 2021 and the liver dataset from Medical Segmentation Decathlon. The code of HRSTNet will be publicly available at https://github.com/auroua/HRSTNet.
Learning from Noisy Labels for Entity-Centric Information Extraction
Apr 17, 2021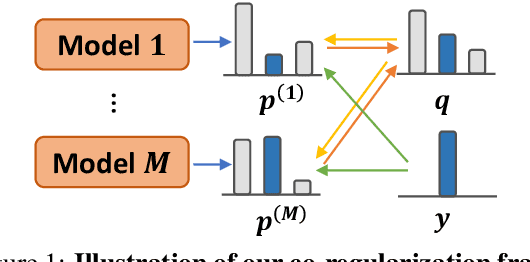
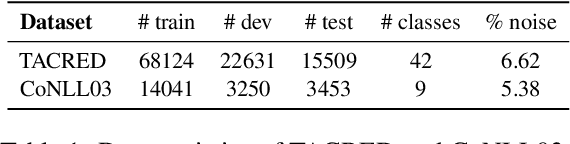
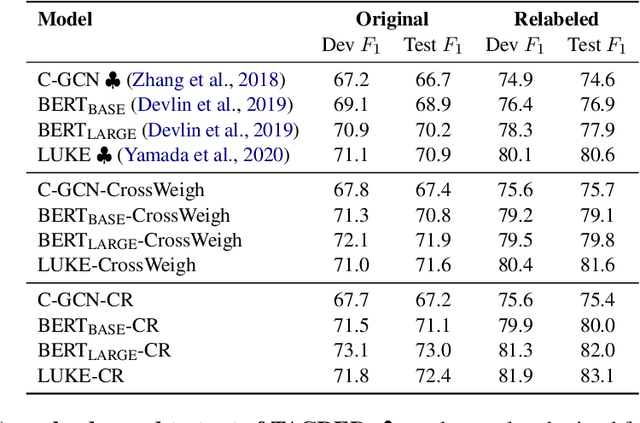
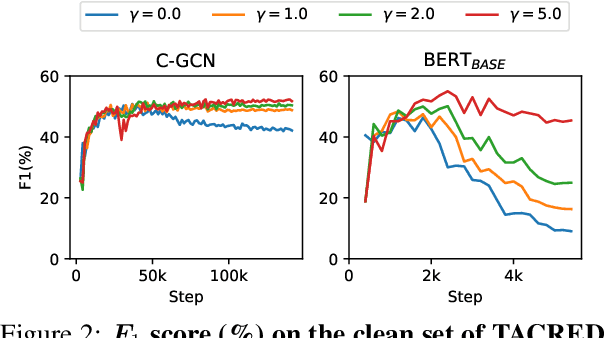
Recent efforts for information extraction have relied on many deep neural models. However, any such models can easily overfit noisy labels and suffer from performance degradation. While it is very costly to filter noisy labels in large learning resources, recent studies show that such labels take more training steps to be memorized and are more frequently forgotten than clean labels, therefore are identifiable in training. Motivated by such properties, we propose a simple co-regularization framework for entity-centric information extraction, which consists of several neural models with different parameter initialization. These models are jointly optimized with task-specific loss, and are regularized to generate similar predictions based on an agreement loss, which prevents overfitting on noisy labels. In the end, we can take any of the trained models for inference. Extensive experiments on two widely used but noisy benchmarks for information extraction, TACRED and CoNLL03, demonstrate the effectiveness of our framework.
Effective and Differentiated Use of Control Information for Multi-speaker Speech Synthesis
Jul 08, 2021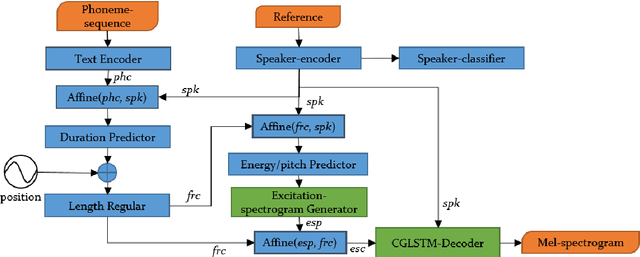

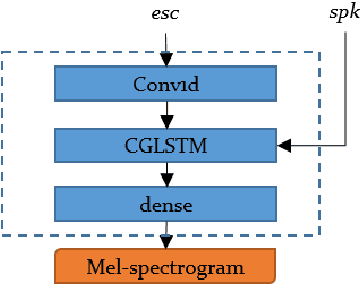
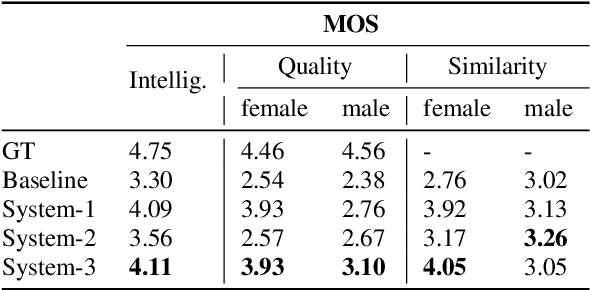
In multi-speaker speech synthesis, data from a number of speakers usually tends to have great diversity due to the fact that the speakers may differ largely in their ages, speaking styles, speeds, emotions, and so on. The diversity of data will lead to the one-to-many mapping problem \cite{Ren2020FastSpeech2F, Kumar2020FewSA}. It is important but challenging to improve the modeling capabilities for multi-speaker speech synthesis. To address the issue, this paper researches into the effective use of control information such as speaker and pitch which are differentiated from text-content information in our encoder-decoder framework: 1) Design a representation of harmonic structure of speech, called excitation spectrogram, from pitch and energy. The excitation spectrogrom is, along with the text-content, fed to the decoder to guide the learning of harmonics of mel-spectrogram. 2) Propose conditional gated LSTM (CGLSTM) whose input/output/forget gates are re-weighted by speaker embedding to control the flow of text-content information in the network. The experiments show significant reduction in reconstruction errors of mel-spectrogram in the training of multi-speaker generative model, and a great improvement is observed in the subjective evaluation of speaker adapted model, e.g, the Mean Opinion Score (MOS) of intelligibility increases by 0.81 points.