 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards a Data-Driven Requirements Engineering Approach: Automatic Analysis of User Reviews
Jun 29, 2022
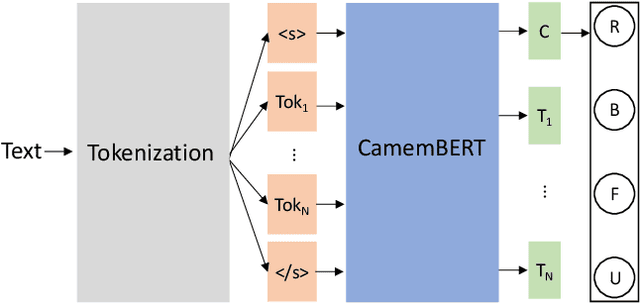

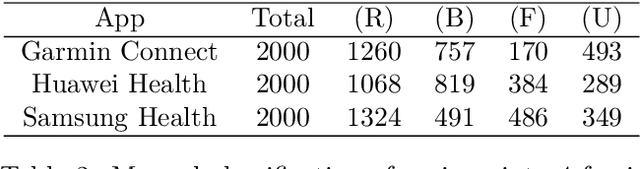

We are concerned by Data Driven Requirements Engineering, and in particular the consideration of user's reviews. These online reviews are a rich source of information for extracting new needs and improvement requests. In this work, we provide an automated analysis using CamemBERT, which is a state-of-the-art language model in French. We created a multi-label classification dataset of 6000 user reviews from three applications in the Health & Fitness field. The results are encouraging and suggest that it's possible to identify automatically the reviews concerning requests for new features. Dataset is available at: https://github.com/Jl-wei/APIA2022-French-user-reviews-classification-dataset.
RAAT: Relation-Augmented Attention Transformer for Relation Modeling in Document-Level Event Extraction
Jun 07, 2022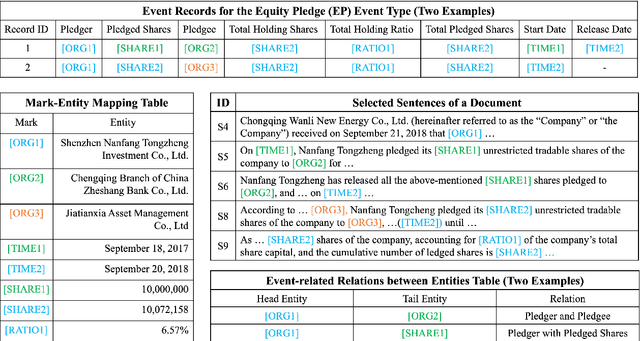
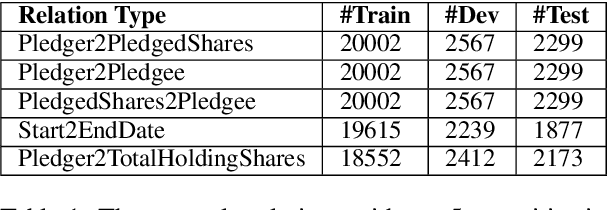
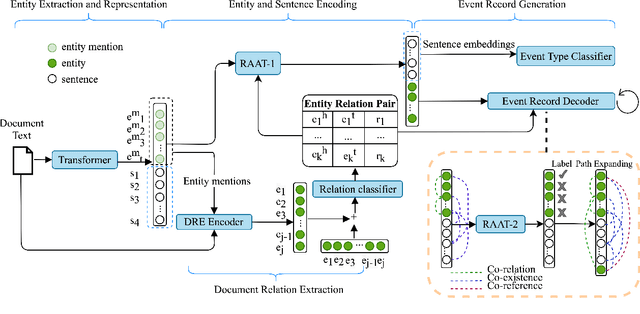
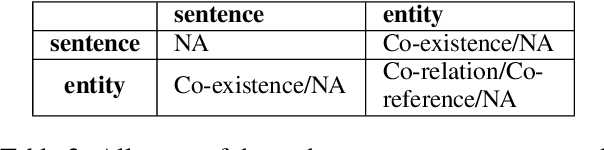
In document-level event extraction (DEE) task, event arguments always scatter across sentences (across-sentence issue) and multiple events may lie in one document (multi-event issue). In this paper, we argue that the relation information of event arguments is of great significance for addressing the above two issues, and propose a new DEE framework which can model the relation dependencies, called Relation-augmented Document-level Event Extraction (ReDEE). More specifically, this framework features a novel and tailored transformer, named as Relation-augmented Attention Transformer (RAAT). RAAT is scalable to capture multi-scale and multi-amount argument relations. To further leverage relation information, we introduce a separate event relation prediction task and adopt multi-task learning method to explicitly enhance event extraction performance. Extensive experiments demonstrate the effectiveness of the proposed method, which can achieve state-of-the-art performance on two public datasets. Our code is available at https://github. com/TencentYoutuResearch/RAAT.
Scene Graph for Embodied Exploration in Cluttered Scenario
Jul 16, 2022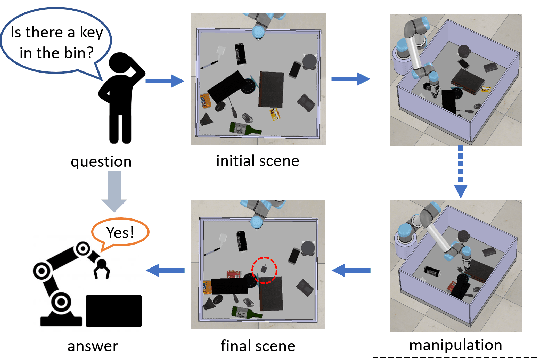
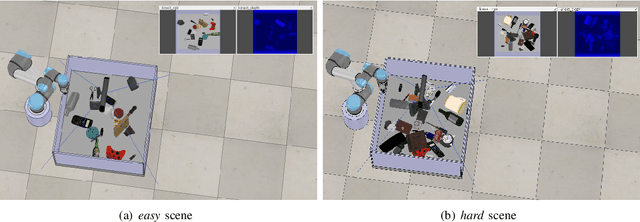
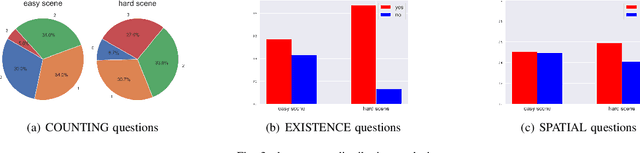
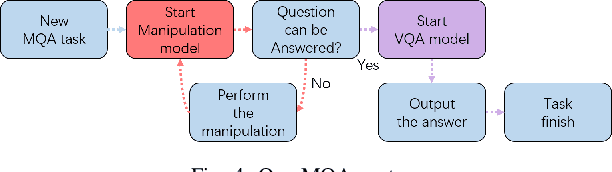
The ability to handle objects in cluttered environment has been long anticipated by robotic community. However, most of works merely focus on manipulation instead of rendering hidden semantic information in cluttered objects. In this work, we introduce the scene graph for embodied exploration in cluttered scenarios to solve this problem. To validate our method in cluttered scenario, we adopt the Manipulation Question Answering (MQA) tasks as our test benchmark, which requires an embodied robot to have the active exploration ability and semantic understanding ability of vision and language.As a general solution framework to the task, we propose an imitation learning method to generate manipulations for exploration. Meanwhile, a VQA model based on dynamic scene graph is adopted to comprehend a series of RGB frames from wrist camera of manipulator along with every step of manipulation is conducted to answer questions in our framework.The experiments on of MQA dataset with different interaction requirements demonstrate that our proposed framework is effective for MQA task a representative of tasks in cluttered scenario.
Learning to Query Internet Text for Informing Reinforcement Learning Agents
May 25, 2022
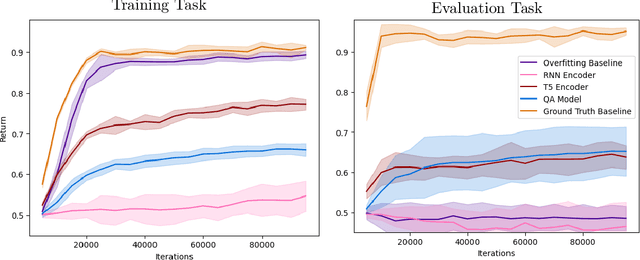

Generalization to out of distribution tasks in reinforcement learning is a challenging problem. One successful approach improves generalization by conditioning policies on task or environment descriptions that provide information about the current transition or reward functions. Previously, these descriptions were often expressed as generated or crowd sourced text. In this work, we begin to tackle the problem of extracting useful information from natural language found in the wild (e.g. internet forums, documentation, and wikis). These natural, pre-existing sources are especially challenging, noisy, and large and present novel challenges compared to previous approaches. We propose to address these challenges by training reinforcement learning agents to learn to query these sources as a human would, and we experiment with how and when an agent should query. To address the \textit{how}, we demonstrate that pretrained QA models perform well at executing zero-shot queries in our target domain. Using information retrieved by a QA model, we train an agent to learn \textit{when} it should execute queries. We show that our method correctly learns to execute queries to maximize reward in a reinforcement learning setting.
Introducing 4D Geometric Shell Shaping
Jun 07, 2022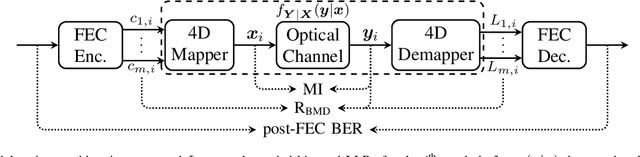
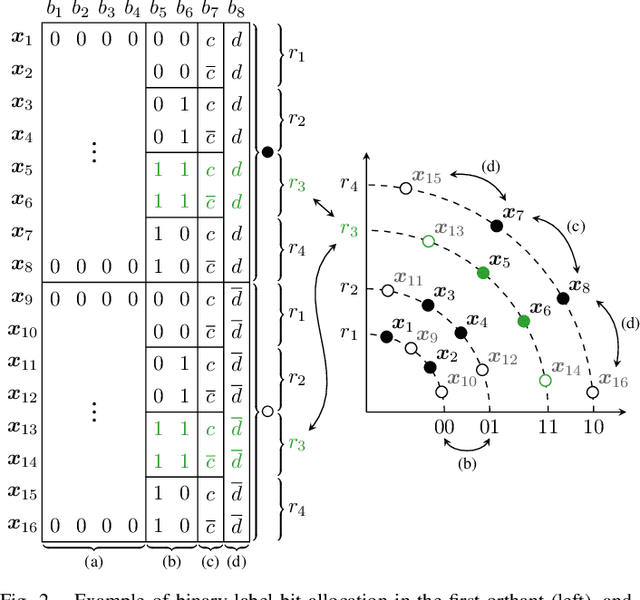
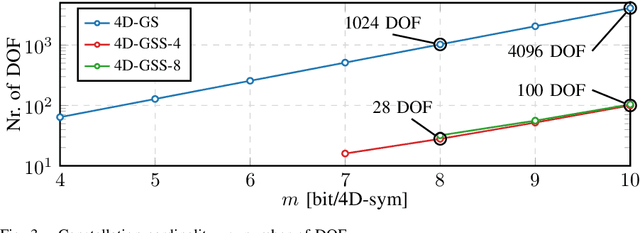

Four dimensional geometric shell shaping (4D-GSS) is introduced and evaluated for reach increase and nonlinearity tolerance in terms of achievable information rates and post-FEC bit-error rate. A format is designed with a spectral efficiency of 8 bit/4D-sym and is compared against polarization-multiplexed 16QAM (PM-16QAM) and probabilistically shaped PM-16QAM (PS-PM-16QAM) in a 400ZR-compatible transmission setup with high amount of nonlinearities. Numerical simulations for a single-span, single-channel show that 4D-GSS achieves increased nonlinear tolerance and reach increase against PM-16QAM and PS-PM-16QAM when optimized for bit-metric decoding (RBMD). In terms of RBMD, gains are small with a reach increase of 1.6% compared to PM-16QAM. When optimizing for mutual information, a larger reach increase of 3% is achieved compared to PM-16QAM. Moreover, the introduced GSS scheme provides a scalable framework for designing well-structured 4D modulation formats with low complexity.
The Lighter The Better: Rethinking Transformers in Medical Image Segmentation Through Adaptive Pruning
Jun 29, 2022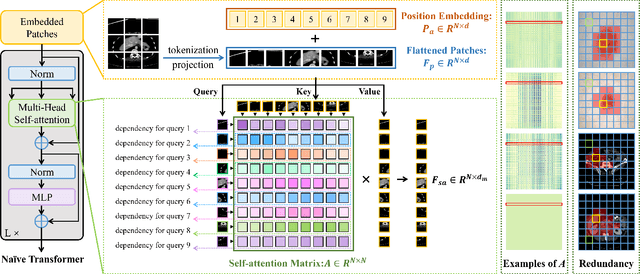
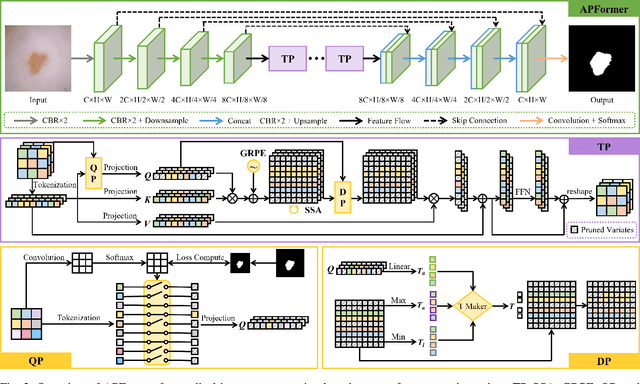

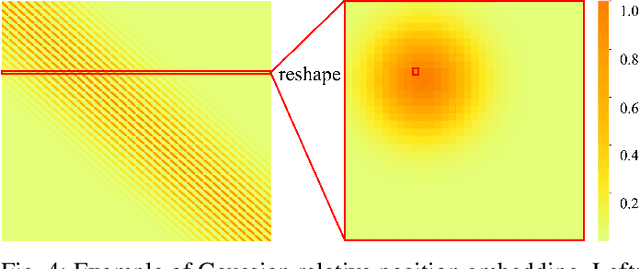
Vision transformers have recently set off a new wave in the field of medical image analysis due to their remarkable performance on various computer vision tasks. However, recent hybrid-/transformer-based approaches mainly focus on the benefits of transformers in capturing long-range dependency while ignoring the issues of their daunting computational complexity, high training costs, and redundant dependency. In this paper, we propose to employ adaptive pruning to transformers for medical image segmentation and propose a lightweight and effective hybrid network APFormer. To our best knowledge, this is the first work on transformer pruning for medical image analysis tasks. The key features of APFormer mainly are self-supervised self-attention (SSA) to improve the convergence of dependency establishment, Gaussian-prior relative position embedding (GRPE) to foster the learning of position information, and adaptive pruning to eliminate redundant computations and perception information. Specifically, SSA and GRPE consider the well-converged dependency distribution and the Gaussian heatmap distribution separately as the prior knowledge of self-attention and position embedding to ease the training of transformers and lay a solid foundation for the following pruning operation. Then, adaptive transformer pruning, both query-wise and dependency-wise, is performed by adjusting the gate control parameters for both complexity reduction and performance improvement. Extensive experiments on two widely-used datasets demonstrate the prominent segmentation performance of APFormer against the state-of-the-art methods with much fewer parameters and lower GFLOPs. More importantly, we prove, through ablation studies, that adaptive pruning can work as a plug-n-play module for performance improvement on other hybrid-/transformer-based methods. Code is available at https://github.com/xianlin7/APFormer.
Finstreder: Simple and fast Spoken Language Understanding with Finite State Transducers using modern Speech-to-Text models
Jun 29, 2022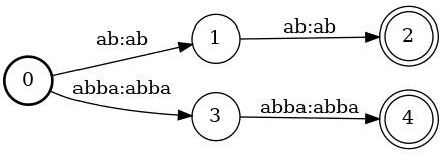
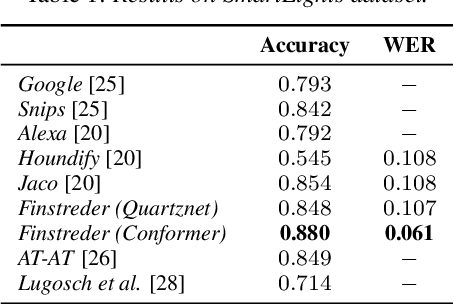
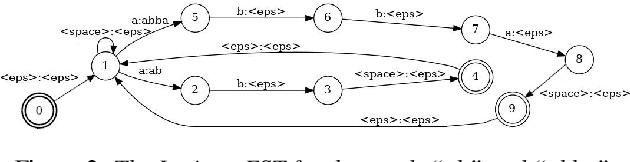
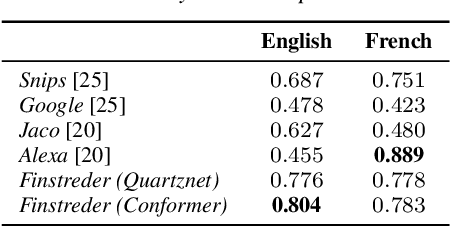
In Spoken Language Understanding (SLU) the task is to extract important information from audio commands, like the intent of what a user wants the system to do and special entities like locations or numbers. This paper presents a simple method for embedding intents and entities into Finite State Transducers, and, in combination with a pretrained general-purpose Speech-to-Text model, allows building SLU-models without any additional training. Building those models is very fast and only takes a few seconds. It is also completely language independent. With a comparison on different benchmarks it is shown that this method can outperform multiple other, more resource demanding SLU approaches.
CE-FPN: Enhancing Channel Information for Object Detection
Mar 19, 2021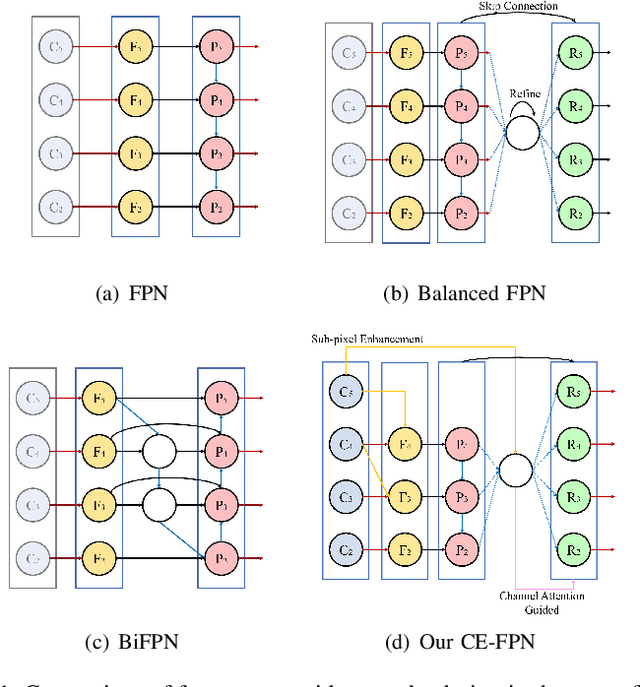
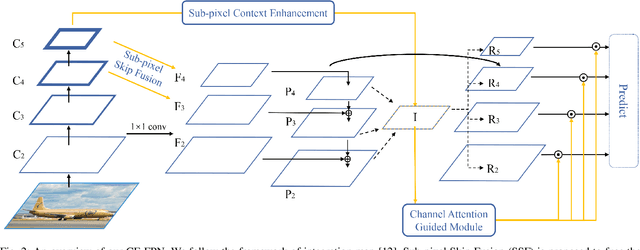
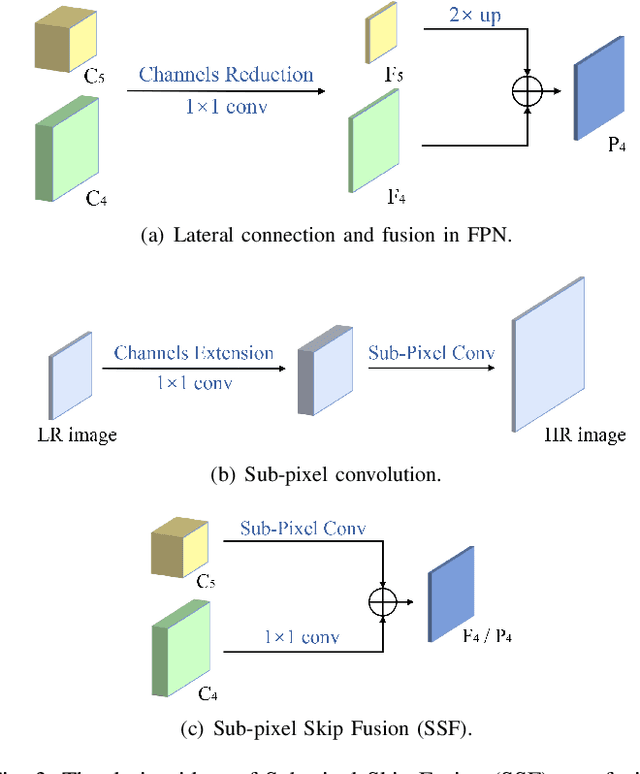
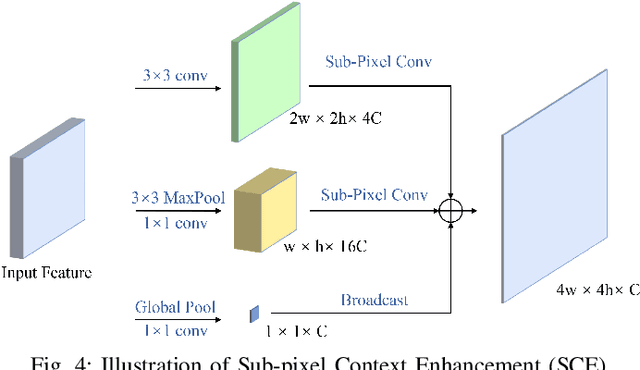
Feature pyramid network (FPN) has been an effective framework to extract multi-scale features in object detection. However, current FPN-based methods mostly suffer from the intrinsic flaw of channel reduction, which brings about the loss of semantical information. And the miscellaneous fused feature maps may cause serious aliasing effects. In this paper, we present a novel channel enhancement feature pyramid network (CE-FPN) with three simple yet effective modules to alleviate these problems. Specifically, inspired by sub-pixel convolution, we propose a sub-pixel skip fusion method to perform both channel enhancement and upsampling. Instead of the original 1x1 convolution and linear upsampling, it mitigates the information loss due to channel reduction. Then we propose a sub-pixel context enhancement module for extracting more feature representations, which is superior to other context methods due to the utilization of rich channel information by sub-pixel convolution. Furthermore, a channel attention guided module is introduced to optimize the final integrated features on each level, which alleviates the aliasing effect only with a few computational burdens. Our experiments show that CE-FPN achieves competitive performance compared to state-of-the-art FPN-based detectors on MS COCO benchmark.
Better Neural Machine Translation by Extracting Linguistic Information from BERT
Apr 07, 2021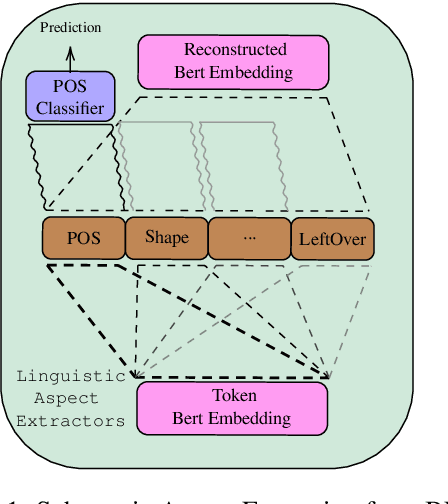

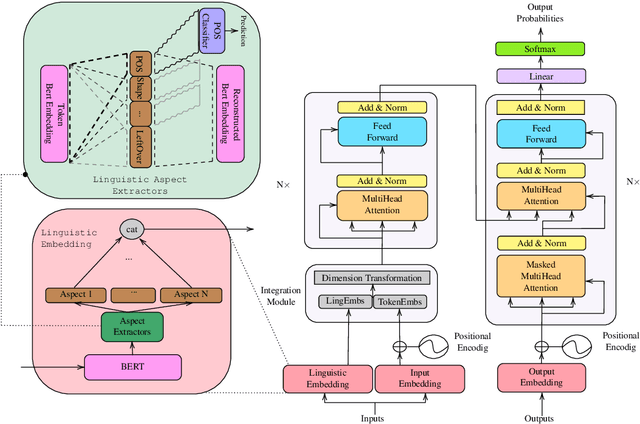
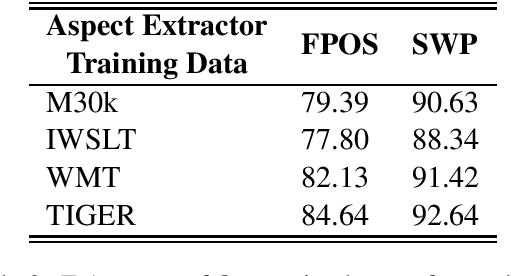
Adding linguistic information (syntax or semantics) to neural machine translation (NMT) has mostly focused on using point estimates from pre-trained models. Directly using the capacity of massive pre-trained contextual word embedding models such as BERT (Devlin et al., 2019) has been marginally useful in NMT because effective fine-tuning is difficult to obtain for NMT without making training brittle and unreliable. We augment NMT by extracting dense fine-tuned vector-based linguistic information from BERT instead of using point estimates. Experimental results show that our method of incorporating linguistic information helps NMT to generalize better in a variety of training contexts and is no more difficult to train than conventional Transformer-based NMT.
FiLM: Frequency improved Legendre Memory Model for Long-term Time Series Forecasting
May 18, 2022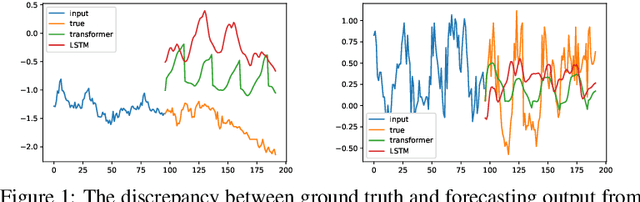
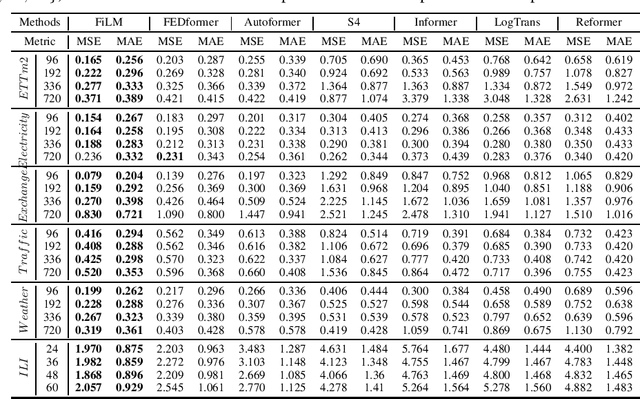
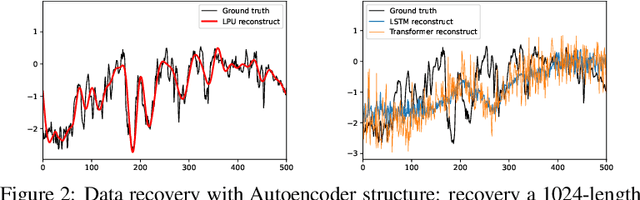
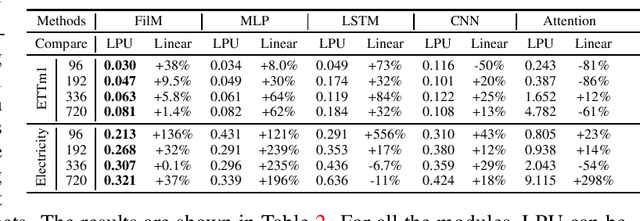
Recent studies have shown the promising performance of deep learning models (e.g., RNN and Transformer) for long-term time series forecasting. These studies mostly focus on designing deep models to effectively combine historical information for long-term forecasting. However, the question of how to effectively represent historical information for long-term forecasting has not received enough attention, limiting our capacity to exploit powerful deep learning models. The main challenge in time series representation is how to handle the dilemma between accurately preserving historical information and reducing the impact of noisy signals in the past. To this end, we design a \textbf{F}requency \textbf{i}mproved \textbf{L}egendre \textbf{M}emory model, or {\bf FiLM} for short: it introduces Legendre Polynomial projections to preserve historical information accurately and Fourier projections plus low-rank approximation to remove noisy signals. Our empirical studies show that the proposed FiLM improves the accuracy of state-of-the-art models by a significant margin (\textbf{19.2\%}, \textbf{22.6\%}) in multivariate and univariate long-term forecasting, respectively. In addition, dimensionality reduction introduced by low-rank approximation leads to a dramatic improvement in computational efficiency. We also demonstrate that the representation module developed in this work can be used as a general plug-in to improve the performance of most deep learning modules for long-term forecasting. Code will be released soon