 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning from Noisy Labels for Entity-Centric Information Extraction
Apr 17, 2021
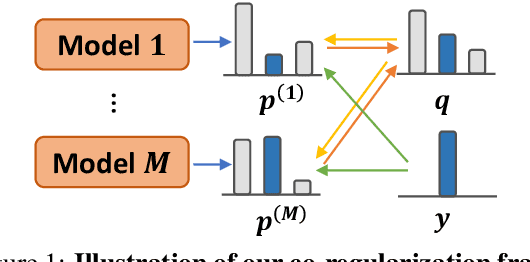
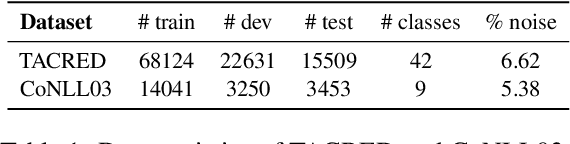
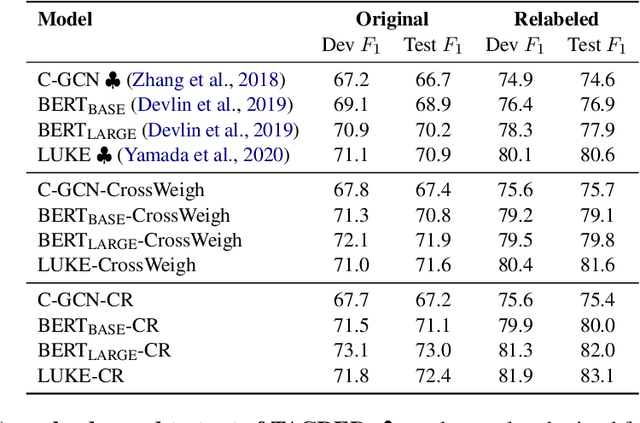
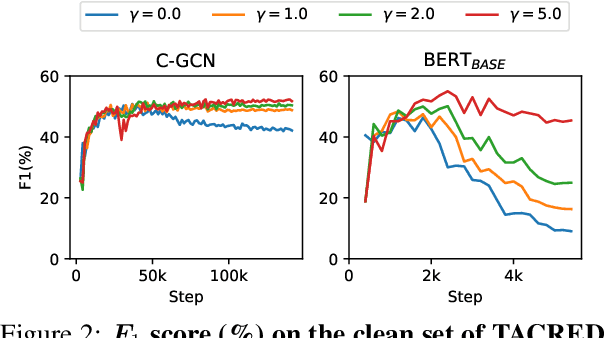
Recent efforts for information extraction have relied on many deep neural models. However, any such models can easily overfit noisy labels and suffer from performance degradation. While it is very costly to filter noisy labels in large learning resources, recent studies show that such labels take more training steps to be memorized and are more frequently forgotten than clean labels, therefore are identifiable in training. Motivated by such properties, we propose a simple co-regularization framework for entity-centric information extraction, which consists of several neural models with different parameter initialization. These models are jointly optimized with task-specific loss, and are regularized to generate similar predictions based on an agreement loss, which prevents overfitting on noisy labels. In the end, we can take any of the trained models for inference. Extensive experiments on two widely used but noisy benchmarks for information extraction, TACRED and CoNLL03, demonstrate the effectiveness of our framework.
Towards Evading the Limits of Randomized Smoothing: A Theoretical Analysis
Jun 03, 2022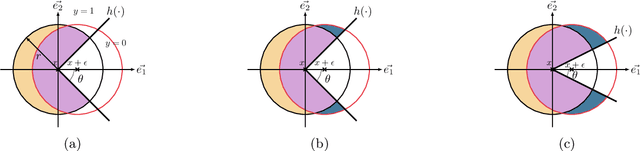
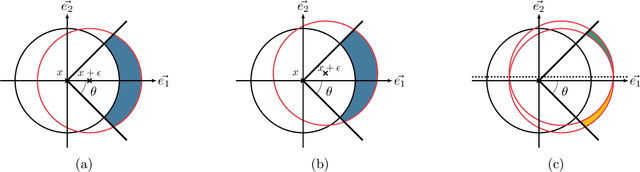
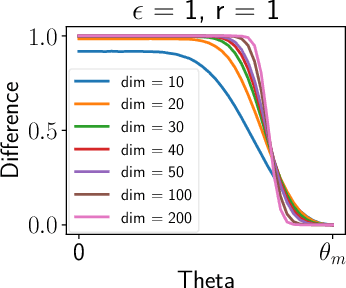
Randomized smoothing is the dominant standard for provable defenses against adversarial examples. Nevertheless, this method has recently been proven to suffer from important information theoretic limitations. In this paper, we argue that these limitations are not intrinsic, but merely a byproduct of current certification methods. We first show that these certificates use too little information about the classifier, and are in particular blind to the local curvature of the decision boundary. This leads to severely sub-optimal robustness guarantees as the dimension of the problem increases. We then show that it is theoretically possible to bypass this issue by collecting more information about the classifier. More precisely, we show that it is possible to approximate the optimal certificate with arbitrary precision, by probing the decision boundary with several noise distributions. Since this process is executed at certification time rather than at test time, it entails no loss in natural accuracy while enhancing the quality of the certificates. This result fosters further research on classifier-specific certification and demonstrates that randomized smoothing is still worth investigating. Although classifier-specific certification may induce more computational cost, we also provide some theoretical insight on how to mitigate it.
Learning Time Series from Scale Information
Mar 18, 2021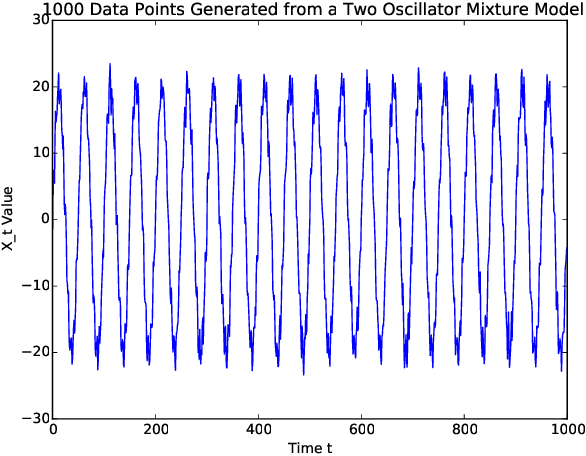
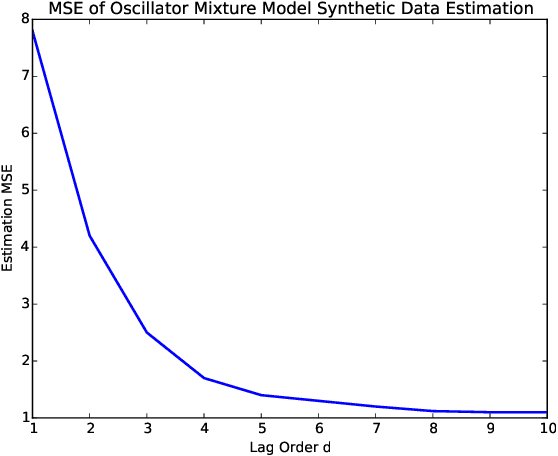
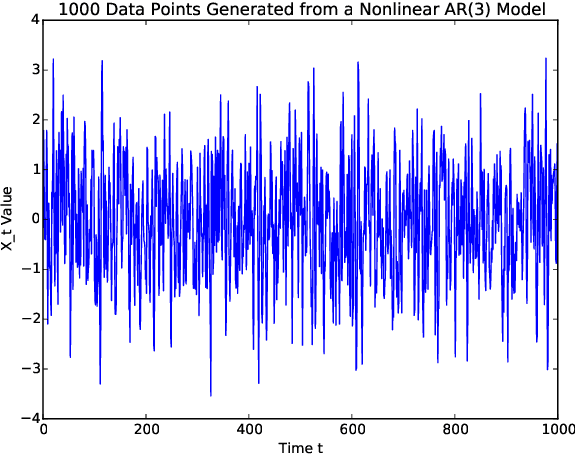
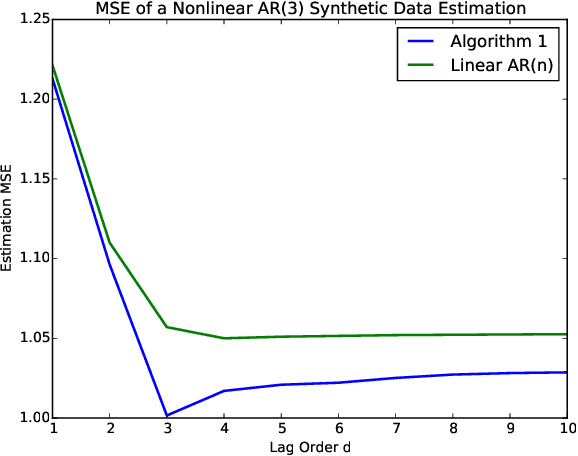
Sequentially obtained dataset usually exhibits different behavior at different data resolutions/scales. Instead of inferring from data at each scale individually, it is often more informative to interpret the data as an ensemble of time series from different scales. This naturally motivated us to propose a new concept referred to as the scale-based inference. The basic idea is that more accurate prediction can be made by exploiting scale information of a time series. We first propose a nonparametric predictor based on $k$-nearest neighbors with an optimally chosen $k$ for a single time series. Based on that, we focus on a specific but important type of scale information, the resolution/sampling rate of time series data. We then propose an algorithm to sequentially predict time series using past data at various resolutions. We prove that asymptotically the algorithm produces the mean prediction error that is no larger than the best possible algorithm at any single resolution, under some optimally chosen parameters. Finally, we establish the general formulations for scale inference, and provide further motivating examples. Experiments on both synthetic and real data illustrate the potential applicability of our approaches to a wide range of time series models.
D3C2-Net: Dual-Domain Deep Convolutional Coding Network for Compressive Sensing
Jul 27, 2022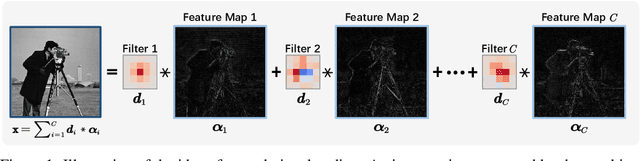

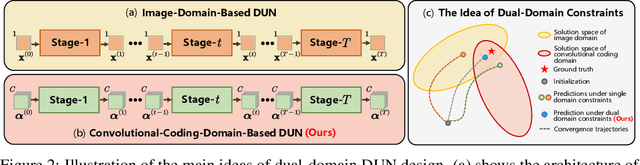
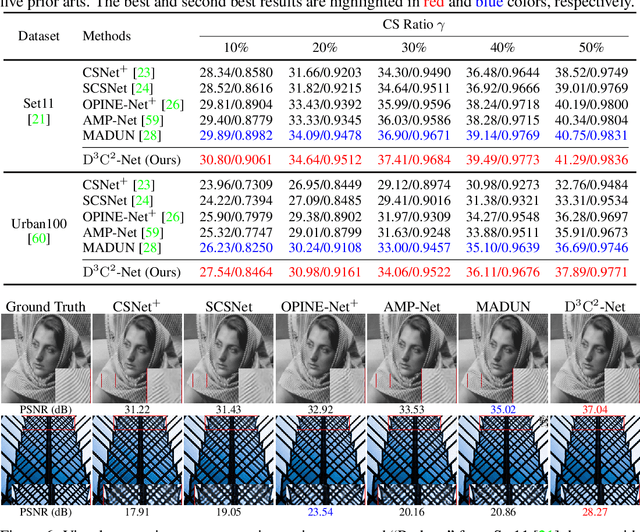
Mapping optimization algorithms into neural networks, deep unfolding networks (DUNs) have achieved impressive success in compressive sensing (CS). From the perspective of optimization, DUNs inherit a well-defined and interpretable structure from iterative steps. However, from the viewpoint of neural network design, most existing DUNs are inherently established based on traditional image-domain unfolding, which takes one-channel images as inputs and outputs between adjacent stages, resulting in insufficient information transmission capability and inevitable loss of the image details. In this paper, to break the above bottleneck, we first propose a generalized dual-domain optimization framework, which is general for inverse imaging and integrates the merits of both (1) image-domain and (2) convolutional-coding-domain priors to constrain the feasible region in the solution space. By unfolding the proposed framework into deep neural networks, we further design a novel Dual-Domain Deep Convolutional Coding Network (D3C2-Net) for CS imaging with the capability of transmitting high-throughput feature-level image representation through all the unfolded stages. Experiments on natural and MR images demonstrate that our D3C2-Net achieves higher performance and better accuracy-complexity trade-offs than other state-of-the-arts.
Affective Behaviour Analysis Using Pretrained Model with Facial Priori
Jul 24, 2022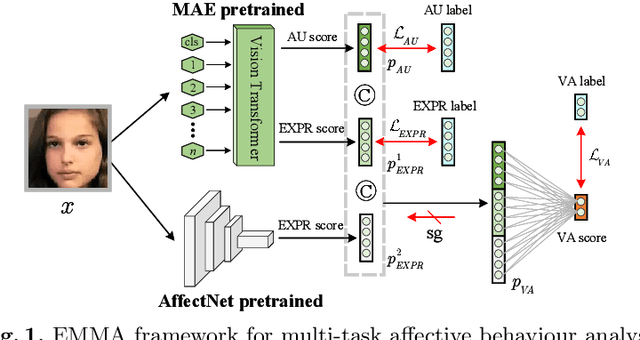
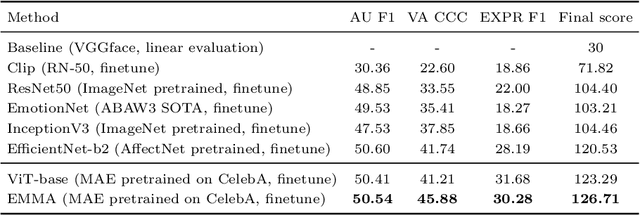
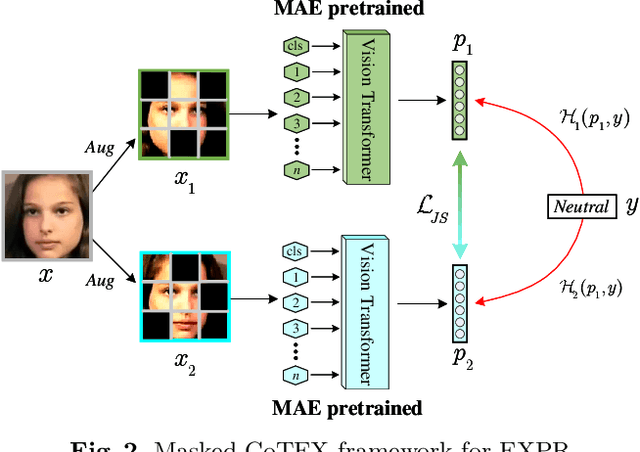

Affective behaviour analysis has aroused researchers' attention due to its broad applications. However, it is labor exhaustive to obtain accurate annotations for massive face images. Thus, we propose to utilize the prior facial information via Masked Auto-Encoder (MAE) pretrained on unlabeled face images. Furthermore, we combine MAE pretrained Vision Transformer (ViT) and AffectNet pretrained CNN to perform multi-task emotion recognition. We notice that expression and action unit (AU) scores are pure and intact features for valence-arousal (VA) regression. As a result, we utilize AffectNet pretrained CNN to extract expression scores concatenating with expression and AU scores from ViT to obtain the final VA features. Moreover, we also propose a co-training framework with two parallel MAE pretrained ViT for expression recognition tasks. In order to make the two views independent, we random mask most patches during the training process. Then, JS divergence is performed to make the predictions of the two views as consistent as possible. The results on ABAW4 show that our methods are effective.
Effective and Differentiated Use of Control Information for Multi-speaker Speech Synthesis
Jul 08, 2021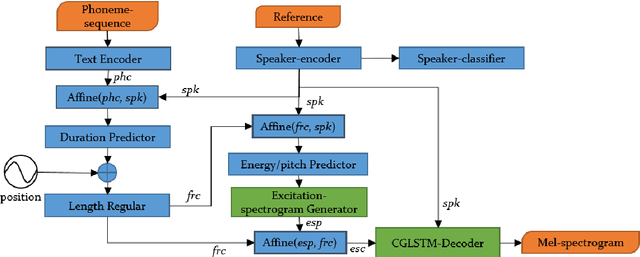

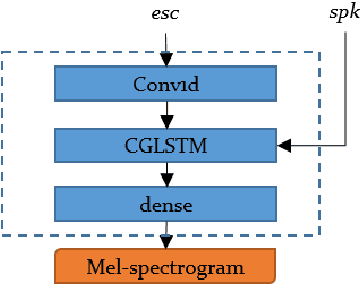
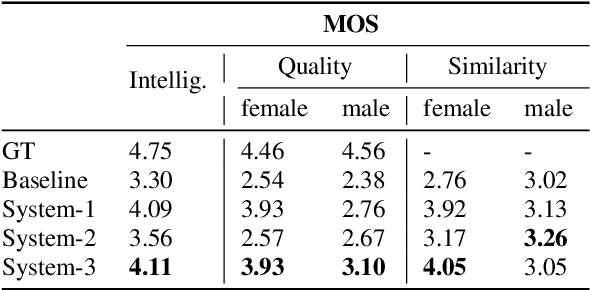
In multi-speaker speech synthesis, data from a number of speakers usually tends to have great diversity due to the fact that the speakers may differ largely in their ages, speaking styles, speeds, emotions, and so on. The diversity of data will lead to the one-to-many mapping problem \cite{Ren2020FastSpeech2F, Kumar2020FewSA}. It is important but challenging to improve the modeling capabilities for multi-speaker speech synthesis. To address the issue, this paper researches into the effective use of control information such as speaker and pitch which are differentiated from text-content information in our encoder-decoder framework: 1) Design a representation of harmonic structure of speech, called excitation spectrogram, from pitch and energy. The excitation spectrogrom is, along with the text-content, fed to the decoder to guide the learning of harmonics of mel-spectrogram. 2) Propose conditional gated LSTM (CGLSTM) whose input/output/forget gates are re-weighted by speaker embedding to control the flow of text-content information in the network. The experiments show significant reduction in reconstruction errors of mel-spectrogram in the training of multi-speaker generative model, and a great improvement is observed in the subjective evaluation of speaker adapted model, e.g, the Mean Opinion Score (MOS) of intelligibility increases by 0.81 points.
Consistent Polyhedral Surrogates for Top-$k$ Classification and Variants
Jul 18, 2022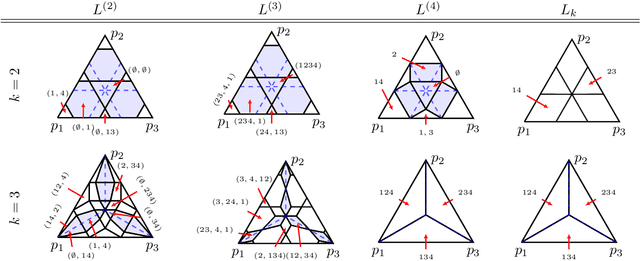
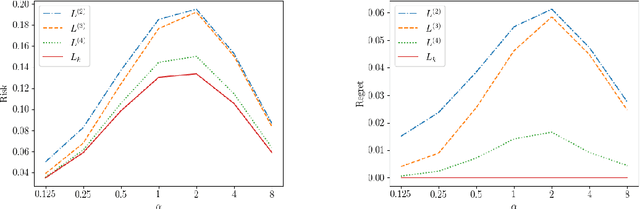

Top-$k$ classification is a generalization of multiclass classification used widely in information retrieval, image classification, and other extreme classification settings. Several hinge-like (piecewise-linear) surrogates have been proposed for the problem, yet all are either non-convex or inconsistent. For the proposed hinge-like surrogates that are convex (i.e., polyhedral), we apply the recent embedding framework of Finocchiaro et al. (2019; 2022) to determine the prediction problem for which the surrogate is consistent. These problems can all be interpreted as variants of top-$k$ classification, which may be better aligned with some applications. We leverage this analysis to derive constraints on the conditional label distributions under which these proposed surrogates become consistent for top-$k$. It has been further suggested that every convex hinge-like surrogate must be inconsistent for top-$k$. Yet, we use the same embedding framework to give the first consistent polyhedral surrogate for this problem.
Temporal and cross-modal attention for audio-visual zero-shot learning
Jul 20, 2022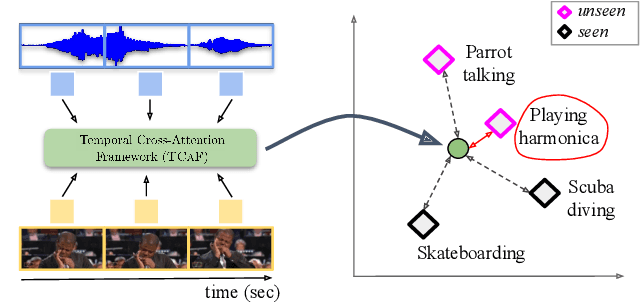
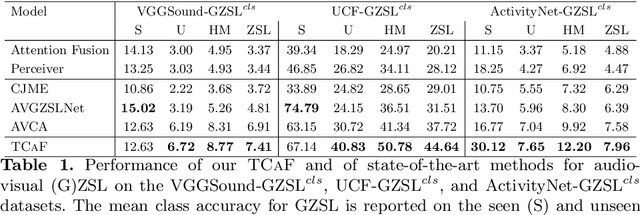


Audio-visual generalised zero-shot learning for video classification requires understanding the relations between the audio and visual information in order to be able to recognise samples from novel, previously unseen classes at test time. The natural semantic and temporal alignment between audio and visual data in video data can be exploited to learn powerful representations that generalise to unseen classes at test time. We propose a multi-modal and Temporal Cross-attention Framework (\modelName) for audio-visual generalised zero-shot learning. Its inputs are temporally aligned audio and visual features that are obtained from pre-trained networks. Encouraging the framework to focus on cross-modal correspondence across time instead of self-attention within the modalities boosts the performance significantly. We show that our proposed framework that ingests temporal features yields state-of-the-art performance on the \ucf, \vgg, and \activity benchmarks for (generalised) zero-shot learning. Code for reproducing all results is available at \url{https://github.com/ExplainableML/TCAF-GZSL}.
On a Generalized Framework for Time-Aware Knowledge Graphs
Jul 20, 2022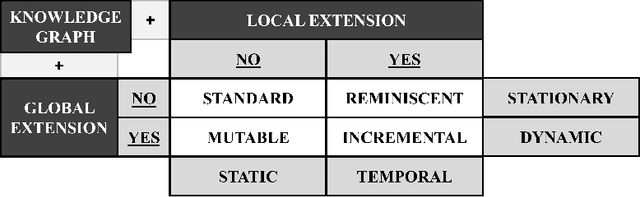

Knowledge graphs have emerged as an effective tool for managing and standardizing semistructured domain knowledge in a human- and machine-interpretable way. In terms of graph-based domain applications, such as embeddings and graph neural networks, current research is increasingly taking into account the time-related evolution of the information encoded within a graph. Algorithms and models for stationary and static knowledge graphs are extended to make them accessible for time-aware domains, where time-awareness can be interpreted in different ways. In particular, a distinction needs to be made between the validity period and the traceability of facts as objectives of time-related knowledge graph extensions. In this context, terms and definitions such as dynamic and temporal are often used inconsistently or interchangeably in the literature. Therefore, with this paper we aim to provide a short but well-defined overview of time-aware knowledge graph extensions and thus faciliate future research in this field as well.
PAC: Assisted Value Factorisation with Counterfactual Predictions in Multi-Agent Reinforcement Learning
Jun 22, 2022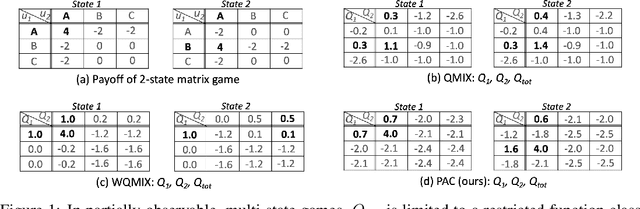
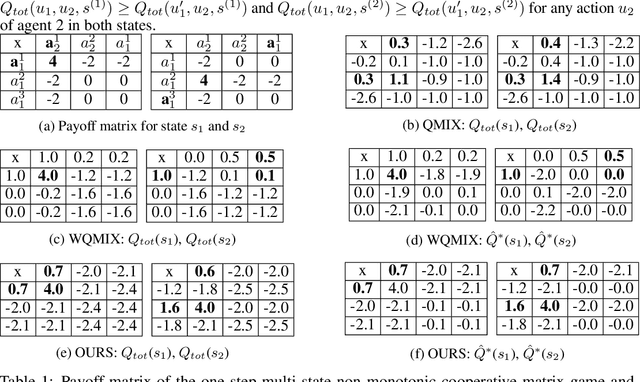
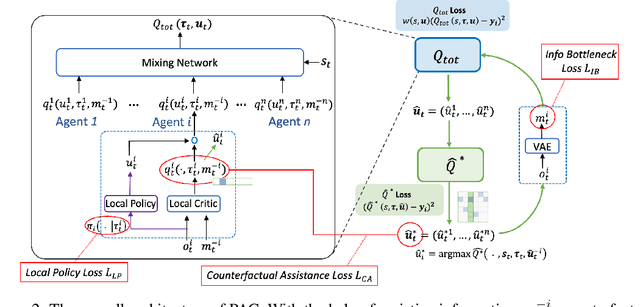

Multi-agent reinforcement learning (MARL) has witnessed significant progress with the development of value function factorization methods. It allows optimizing a joint action-value function through the maximization of factorized per-agent utilities due to monotonicity. In this paper, we show that in partially observable MARL problems, an agent's ordering over its own actions could impose concurrent constraints (across different states) on the representable function class, causing significant estimation error during training. We tackle this limitation and propose PAC, a new framework leveraging Assistive information generated from Counterfactual Predictions of optimal joint action selection, which enable explicit assistance to value function factorization through a novel counterfactual loss. A variational inference-based information encoding method is developed to collect and encode the counterfactual predictions from an estimated baseline. To enable decentralized execution, we also derive factorized per-agent policies inspired by a maximum-entropy MARL framework. We evaluate the proposed PAC on multi-agent predator-prey and a set of StarCraft II micromanagement tasks. Empirical results demonstrate improved results of PAC over state-of-the-art value-based and policy-based multi-agent reinforcement learning algorithms on all benchmarks.