 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bird's Eye: Probing for Linguistic Graph Structures with a Simple Information-Theoretic Approach
May 16, 2021
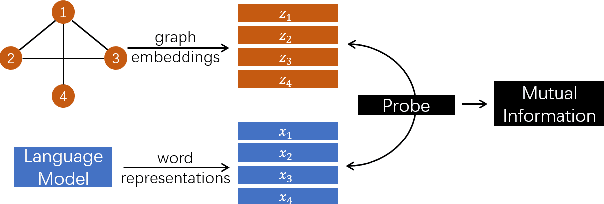
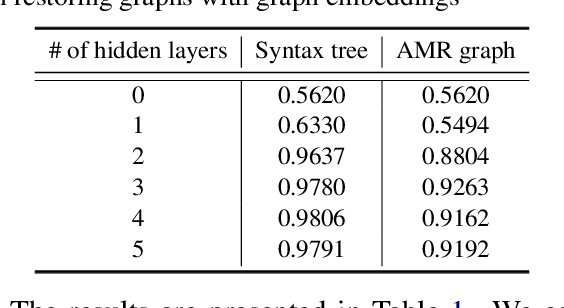
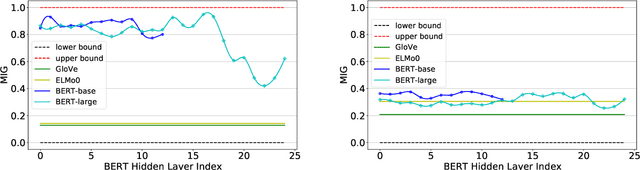
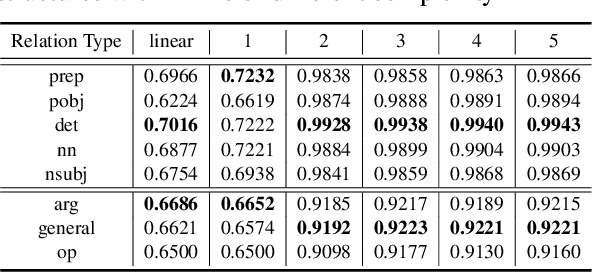
NLP has a rich history of representing our prior understanding of language in the form of graphs. Recent work on analyzing contextualized text representations has focused on hand-designed probe models to understand how and to what extent do these representations encode a particular linguistic phenomenon. However, due to the inter-dependence of various phenomena and randomness of training probe models, detecting how these representations encode the rich information in these linguistic graphs remains a challenging problem. In this paper, we propose a new information-theoretic probe, Bird's Eye, which is a fairly simple probe method for detecting if and how these representations encode the information in these linguistic graphs. Instead of using classifier performance, our probe takes an information-theoretic view of probing and estimates the mutual information between the linguistic graph embedded in a continuous space and the contextualized word representations. Furthermore, we also propose an approach to use our probe to investigate localized linguistic information in the linguistic graphs using perturbation analysis. We call this probing setup Worm's Eye. Using these probes, we analyze BERT models on their ability to encode a syntactic and a semantic graph structure, and find that these models encode to some degree both syntactic as well as semantic information; albeit syntactic information to a greater extent.
Re-creation of Creations: A New Paradigm for Lyric-to-Melody Generation
Aug 12, 2022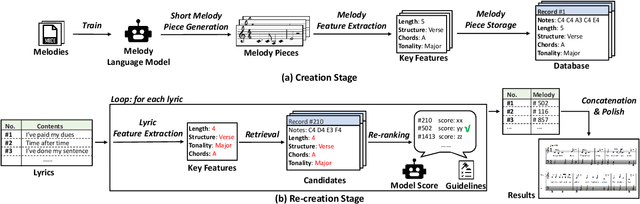
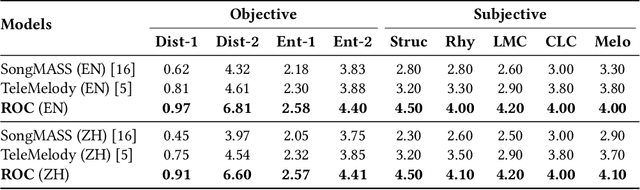
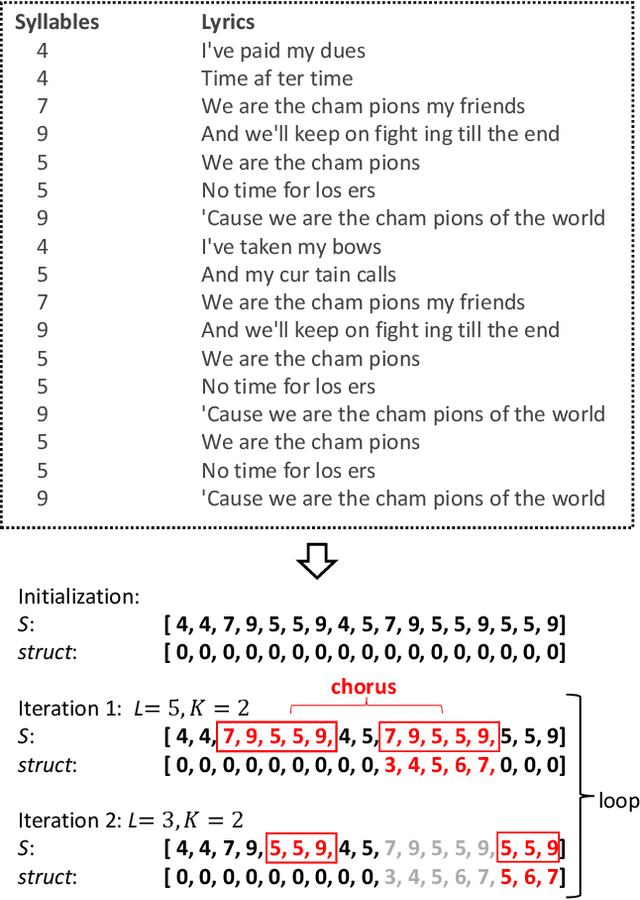
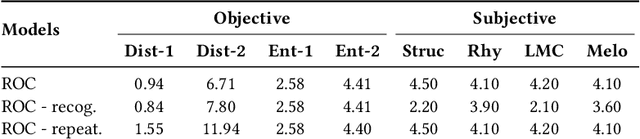
Lyric-to-melody generation is an important task in songwriting, and is also quite challenging due to its distinctive characteristics: the generated melodies should not only follow good musical patterns, but also align with features in lyrics such as rhythms and structures. These characteristics cannot be well handled by neural generation models that learn lyric-to-melody mapping in an end-to-end way, due to several issues: (1) lack of aligned lyric-melody training data to sufficiently learn lyric-melody feature alignment; (2) lack of controllability in generation to explicitly guarantee the lyric-melody feature alignment. In this paper, we propose Re-creation of Creations (ROC), a new paradigm for lyric-to-melody generation that addresses the above issues through a generation-retrieval pipeline. Specifically, our paradigm has two stages: (1) creation stage, where a huge amount of music pieces are generated by a neural-based melody language model and indexed in a database through several key features (e.g., chords, tonality, rhythm, and structural information including chorus or verse); (2) re-creation stage, where melodies are recreated by retrieving music pieces from the database according to the key features from lyrics and concatenating best music pieces based on composition guidelines and melody language model scores. Our new paradigm has several advantages: (1) It only needs unpaired melody data to train melody language model, instead of paired lyric-melody data in previous models. (2) It achieves good lyric-melody feature alignment in lyric-to-melody generation. Experiments on English and Chinese datasets demonstrate that ROC outperforms previous neural based lyric-to-melody generation models on both objective and subjective metrics. We provide our code in supplementary material and provide demos on github.
Multi-task Learning by Leveraging the Semantic Information
Mar 03, 2021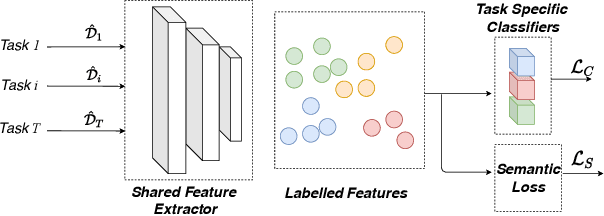


One crucial objective of multi-task learning is to align distributions across tasks so that the information between them can be transferred and shared. However, existing approaches only focused on matching the marginal feature distribution while ignoring the semantic information, which may hinder the learning performance. To address this issue, we propose to leverage the label information in multi-task learning by exploring the semantic conditional relations among tasks. We first theoretically analyze the generalization bound of multi-task learning based on the notion of Jensen-Shannon divergence, which provides new insights into the value of label information in multi-task learning. Our analysis also leads to a concrete algorithm that jointly matches the semantic distribution and controls label distribution divergence. To confirm the effectiveness of the proposed method, we first compare the algorithm with several baselines on some benchmarks and then test the algorithms under label space shift conditions. Empirical results demonstrate that the proposed method could outperform most baselines and achieve state-of-the-art performance, particularly showing the benefits under the label shift conditions.
MEAT: Maneuver Extraction from Agent Trajectories
Jun 10, 2022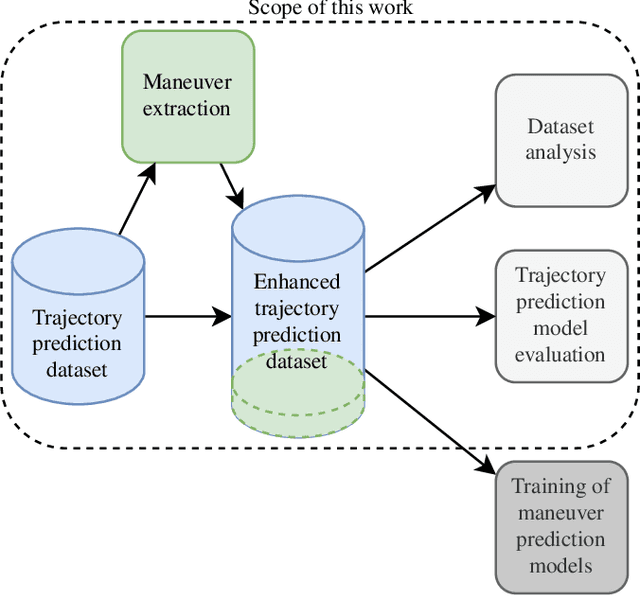
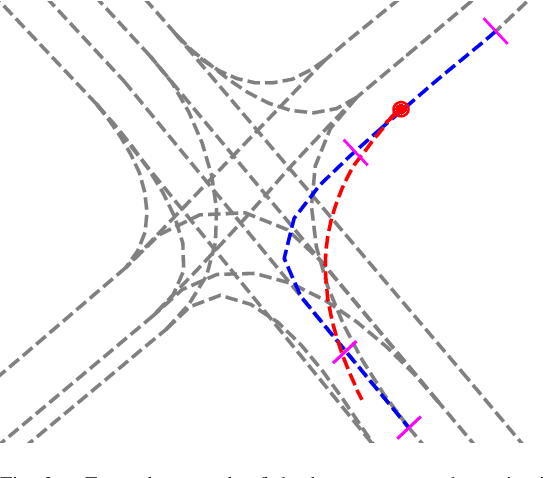
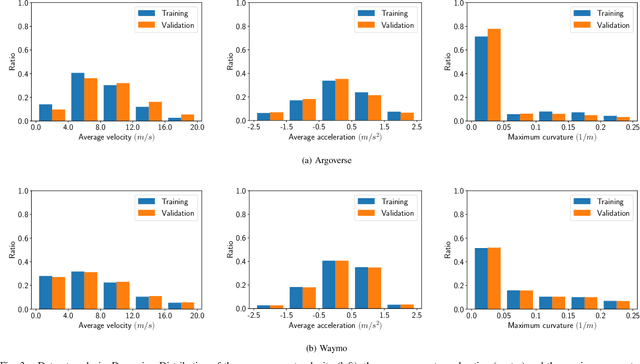
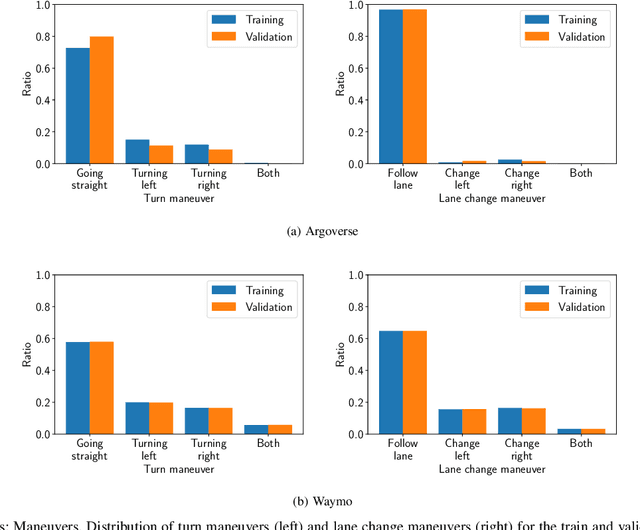
Advances in learning-based trajectory prediction are enabled by large-scale datasets. However, in-depth analysis of such datasets is limited. Moreover, the evaluation of prediction models is limited to metrics averaged over all samples in the dataset. We propose an automated methodology that allows to extract maneuvers (e.g., left turn, lane change) from agent trajectories in such datasets. The methodology considers information about the agent dynamics and information about the lane segments the agent traveled along. Although it is possible to use the resulting maneuvers for training classification networks, we exemplary use them for extensive trajectory dataset analysis and maneuver-specific evaluation of multiple state-of-the-art trajectory prediction models. Additionally, an analysis of the datasets and an evaluation of the prediction models based on the agent dynamics is provided.
Information Theoretic Key Agreement Protocol based on ECG signals
May 14, 2021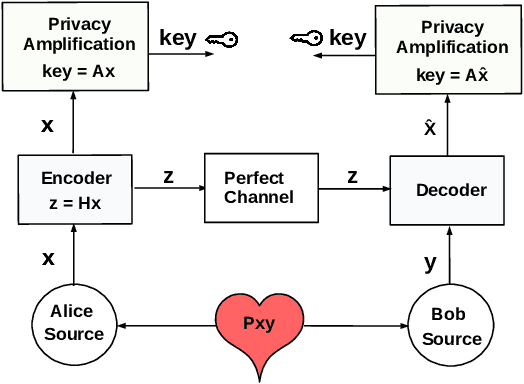
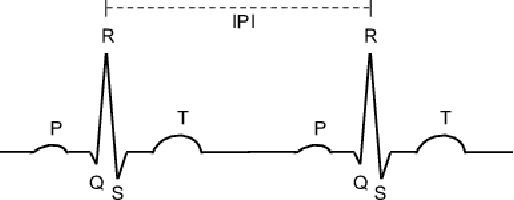
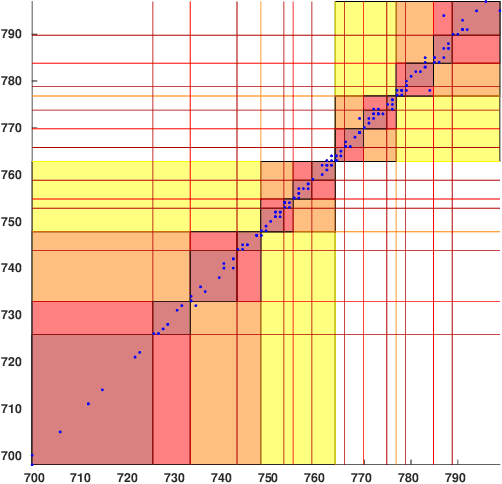
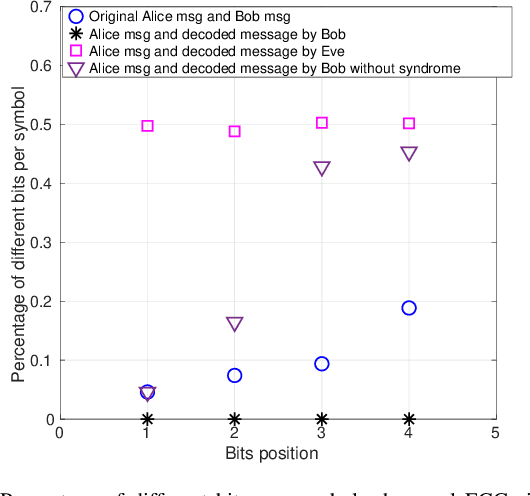
Wireless body area networks (WBANs) are becoming increasingly popular as they allow individuals to continuously monitor their vitals and physiological parameters remotely from the hospital. With the spread of the SARS-CoV-2 pandemic, the availability of portable pulse-oximeters and wearable heart rate detectors has boomed in the market. At the same time, in 2020 we assisted to an unprecedented increase of healthcare breaches, revealing the extreme vulnerability of the current generation of WBANs. Therefore, the development of new security protocols to ensure data protection, authentication, integrity and privacy within WBANs are highly needed. Here, we targeted a WBAN collecting ECG signals from different sensor nodes on the individual's body, we extracted the inter-pulse interval (i.e., R-R interval) sequence from each of them, and we developed a new information theoretic key agreement protocol that exploits the inherent randomness of ECG to ensure authentication between sensor pairs within the WBAN. After proper pre-processing, we provide an analytical solution that ensures robust authentication; we provide a unique information reconciliation matrix, which gives good performance for all ECG sensor pairs; and we can show that a relationship between information reconciliation and privacy amplification matrices can be found. Finally, we show the trade-off between the level of security, in terms of key generation rate, and the complexity of the error correction scheme implemented in the system.
ORFD: A Dataset and Benchmark for Off-Road Freespace Detection
Jun 26, 2022



Freespace detection is an essential component of autonomous driving technology and plays an important role in trajectory planning. In the last decade, deep learning-based free space detection methods have been proved feasible. However, these efforts were focused on urban road environments and few deep learning-based methods were specifically designed for off-road free space detection due to the lack of off-road benchmarks. In this paper, we present the ORFD dataset, which, to our knowledge, is the first off-road free space detection dataset. The dataset was collected in different scenes (woodland, farmland, grassland, and countryside), different weather conditions (sunny, rainy, foggy, and snowy), and different light conditions (bright light, daylight, twilight, darkness), which totally contains 12,198 LiDAR point cloud and RGB image pairs with the traversable area, non-traversable area and unreachable area annotated in detail. We propose a novel network named OFF-Net, which unifies Transformer architecture to aggregate local and global information, to meet the requirement of large receptive fields for free space detection tasks. We also propose the cross-attention to dynamically fuse LiDAR and RGB image information for accurate off-road free space detection. Dataset and code are publicly available athttps://github.com/chaytonmin/OFF-Net.
Obtaining Causal Information by Merging Datasets with MAXENT
Jul 15, 2021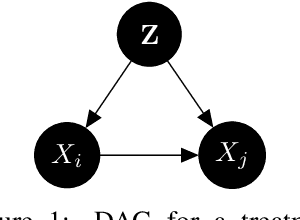
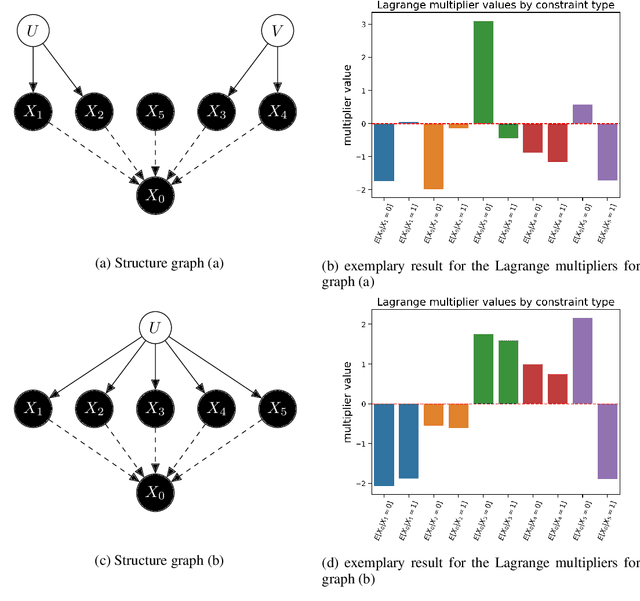
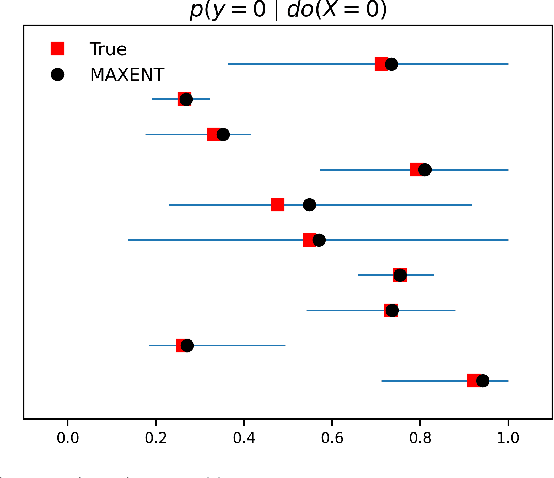
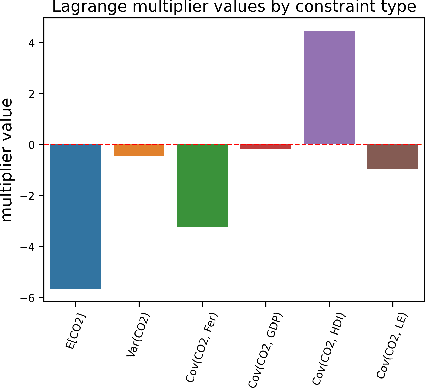
The investigation of the question "which treatment has a causal effect on a target variable?" is of particular relevance in a large number of scientific disciplines. This challenging task becomes even more difficult if not all treatment variables were or even cannot be observed jointly with the target variable. Another similarly important and challenging task is to quantify the causal influence of a treatment on a target in the presence of confounders. In this paper, we discuss how causal knowledge can be obtained without having observed all variables jointly, but by merging the statistical information from different datasets. We first show how the maximum entropy principle can be used to identify edges among random variables when assuming causal sufficiency and an extended version of faithfulness. Additionally, we derive bounds on the interventional distribution and the average causal effect of a treatment on a target variable in the presence of confounders. In both cases we assume that only subsets of the variables have been observed jointly.
Online Continual Learning with Contrastive Vision Transformer
Jul 24, 2022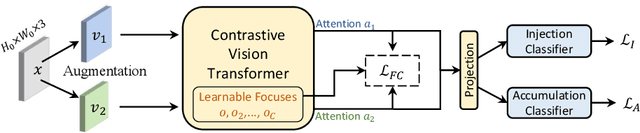
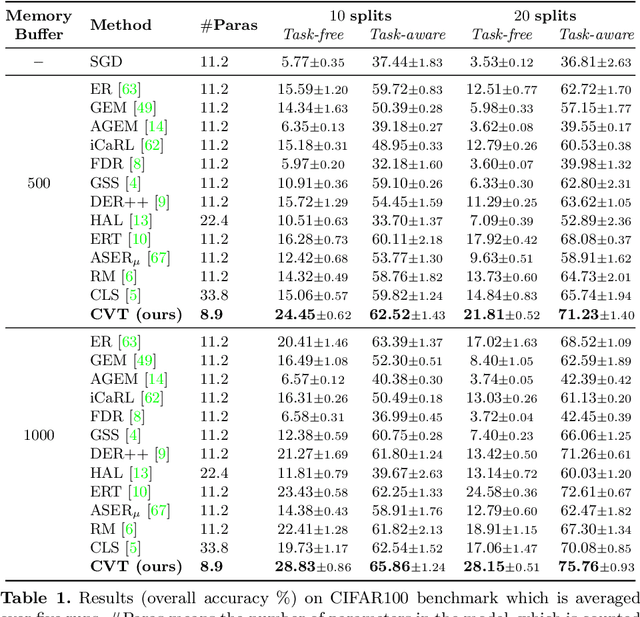
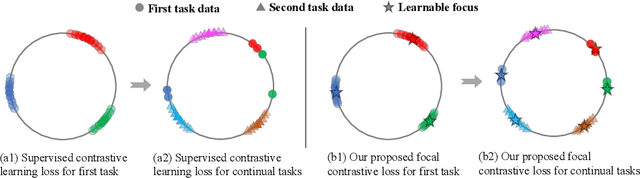
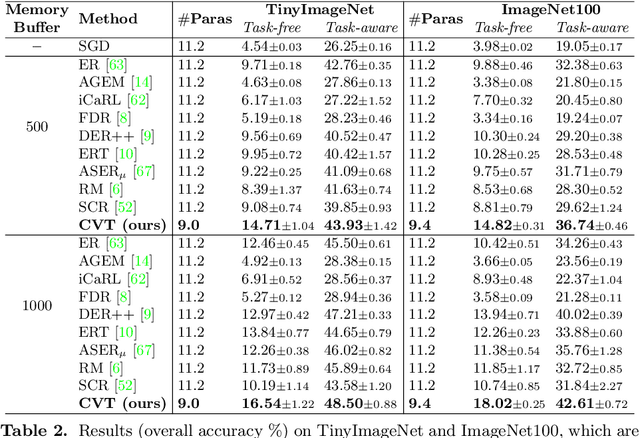
Online continual learning (online CL) studies the problem of learning sequential tasks from an online data stream without task boundaries, aiming to adapt to new data while alleviating catastrophic forgetting on the past tasks. This paper proposes a framework Contrastive Vision Transformer (CVT), which designs a focal contrastive learning strategy based on a transformer architecture, to achieve a better stability-plasticity trade-off for online CL. Specifically, we design a new external attention mechanism for online CL that implicitly captures previous tasks' information. Besides, CVT contains learnable focuses for each class, which could accumulate the knowledge of previous classes to alleviate forgetting. Based on the learnable focuses, we design a focal contrastive loss to rebalance contrastive learning between new and past classes and consolidate previously learned representations. Moreover, CVT contains a dual-classifier structure for decoupling learning current classes and balancing all observed classes. The extensive experimental results show that our approach achieves state-of-the-art performance with even fewer parameters on online CL benchmarks and effectively alleviates the catastrophic forgetting.
D3C2-Net: Dual-Domain Deep Convolutional Coding Network for Compressive Sensing
Jul 27, 2022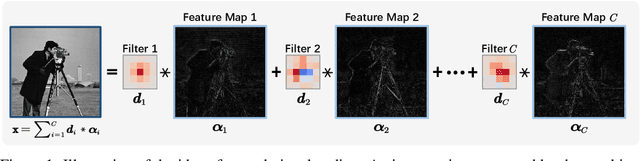

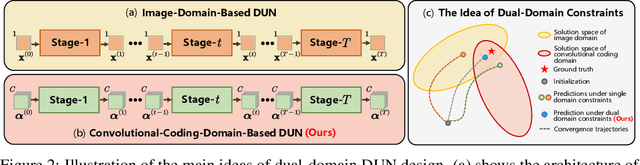
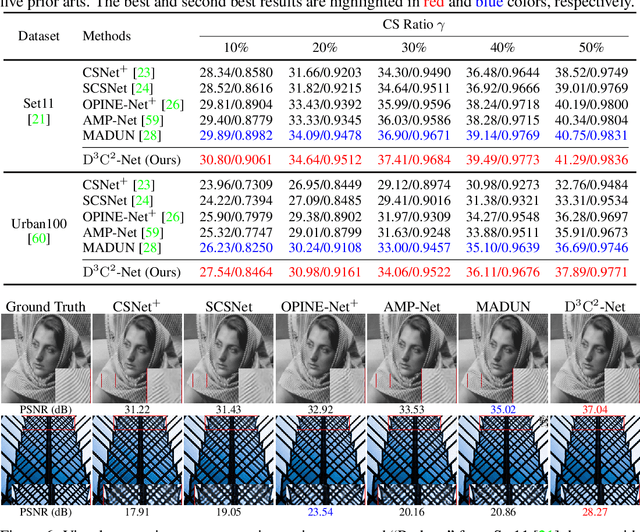
Mapping optimization algorithms into neural networks, deep unfolding networks (DUNs) have achieved impressive success in compressive sensing (CS). From the perspective of optimization, DUNs inherit a well-defined and interpretable structure from iterative steps. However, from the viewpoint of neural network design, most existing DUNs are inherently established based on traditional image-domain unfolding, which takes one-channel images as inputs and outputs between adjacent stages, resulting in insufficient information transmission capability and inevitable loss of the image details. In this paper, to break the above bottleneck, we first propose a generalized dual-domain optimization framework, which is general for inverse imaging and integrates the merits of both (1) image-domain and (2) convolutional-coding-domain priors to constrain the feasible region in the solution space. By unfolding the proposed framework into deep neural networks, we further design a novel Dual-Domain Deep Convolutional Coding Network (D3C2-Net) for CS imaging with the capability of transmitting high-throughput feature-level image representation through all the unfolded stages. Experiments on natural and MR images demonstrate that our D3C2-Net achieves higher performance and better accuracy-complexity trade-offs than other state-of-the-arts.
Dynamic Scene Deblurring Base on Continuous Cross-Layer Attention Transmission
Jun 23, 2022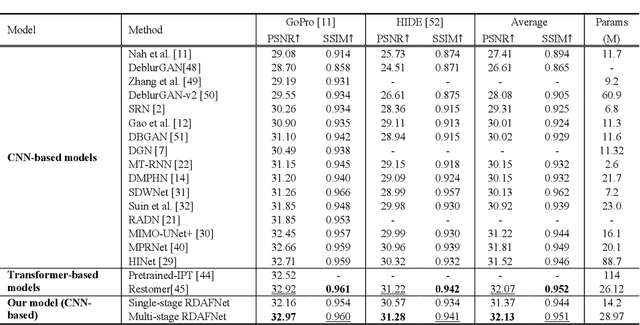
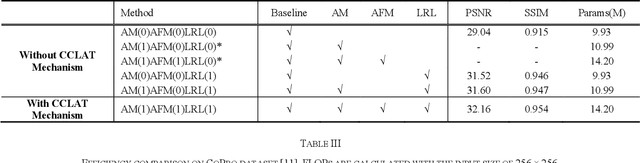

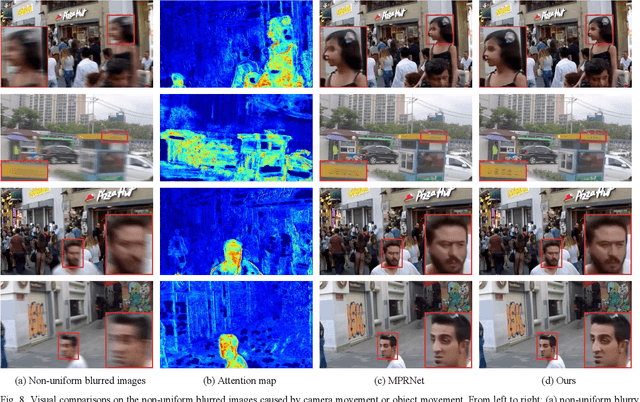
The deep convolutional neural networks (CNNs) using attention mechanism have achieved great success for dynamic scene deblurring. In most of these networks, only the features refined by the attention maps can be passed to the next layer and the attention maps of different layers are separated from each other, which does not make full use of the attention information from different layers in the CNN. To address this problem, we introduce a new continuous cross-layer attention transmission (CCLAT) mechanism that can exploit hierarchical attention information from all the convolutional layers. Based on the CCLAT mechanism, we use a very simple attention module to construct a novel residual dense attention fusion block (RDAFB). In RDAFB, the attention maps inferred from the outputs of the preceding RDAFB and each layer are directly connected to the subsequent ones, leading to a CRLAT mechanism. Taking RDAFB as the building block, we design an effective architecture for dynamic scene deblurring named RDAFNet. The experiments on benchmark datasets show that the proposed model outperforms the state-of-the-art deblurring approaches, and demonstrate the effectiveness of CCLAT mechanism. The source code is available on: https://github.com/xjmz6/RDAFNet.