 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hitless memory-reconfigurable photonic reservoir computing architecture
Jul 13, 2022
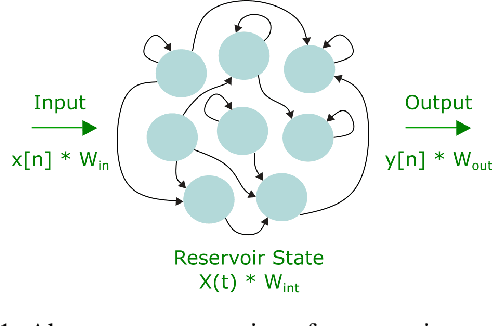
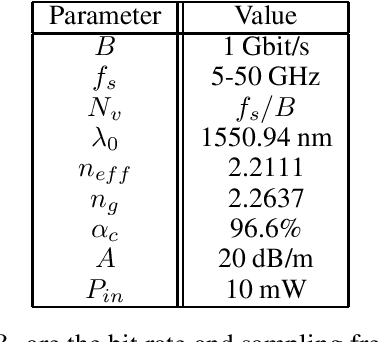
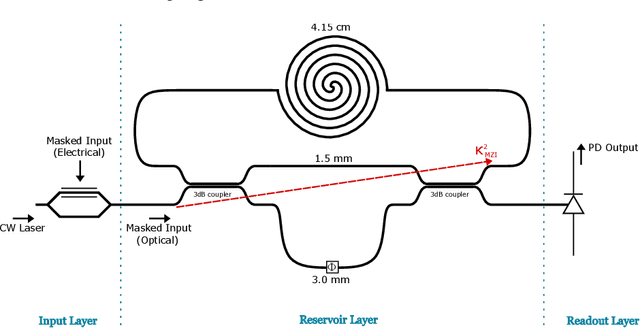

Reservoir computing is an analog bio-inspired computation model for efficiently processing time-dependent signals, the photonic implementations of which promise a combination of massive parallel information processing, low power consumption, and high speed operation. However, most implementations, especially for the case of time-delay reservoir computing (TDRC), require signal attenuation in the reservoir to achieve the desired system dynamics for a specific task, often resulting in large amounts of power being coupled outside of the system. We propose a novel TDRC architecture based on an asymmetric Mach-Zehnder interferometer (MZI) integrated in a resonant cavity which allows the memory capacity of the system to be tuned without the need for an optical attenuator block. Furthermore, this can be leveraged to find the optimal value for the specific components of the total memory capacity metric. We demonstrate this approach on the temporal bitwise XOR task and conclude that this way of memory capacity reconfiguration allows optimal performance to be achieved for memory-specific tasks.
RIS-Assisted MIMO Communication Systems: Model-based versus Autoencoder Approaches
Jul 17, 2022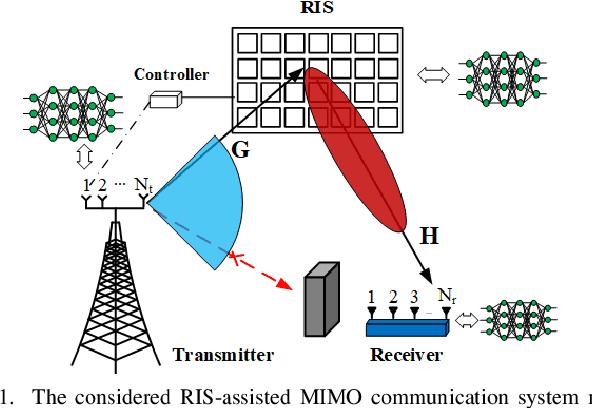
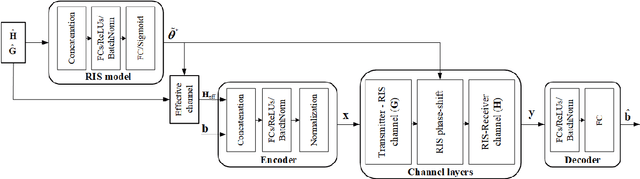
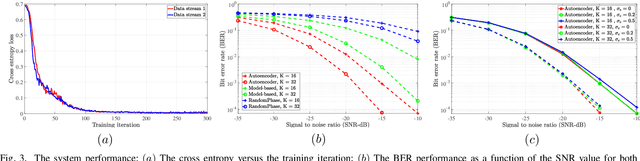

This paper considers reconfigurable intelligent surface (RIS)-assisted point-to-point multiple-input multiple-output (MIMO) communication systems, where a transmitter communicates with a receiver through an RIS. Based on the main target of reducing the bit error rate (BER) and therefore enhancing the communication reliability, we study different model-based and data-driven (autoencoder) approaches. In particular, we consider a model-based approach that optimizes both active and passive optimization variables. We further propose a novel end-to-end data-driven framework, which leverages the recent advances in machine learning. The neural networks presented for conventional signal processing modules are jointly trained with the channel effects to minimize the bit error detection. Numerical results demonstrate that the proposed data-driven approach can learn to encode the transmitted signal via different channel realizations dynamically. In addition, the data-driven approach not only offers a significant gain in the BER performance compared to the other state-of-the-art benchmarks but also guarantees the performance when perfect channel information is unavailable.
Probing the Robustness of Independent Mechanism Analysis for Representation Learning
Jul 13, 2022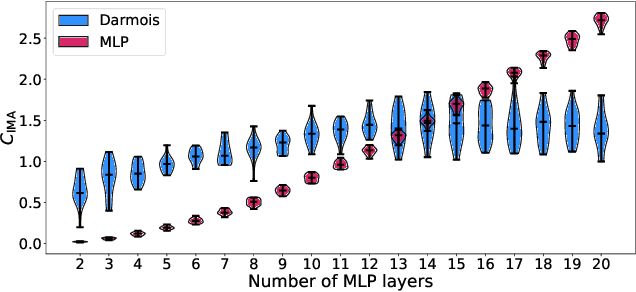

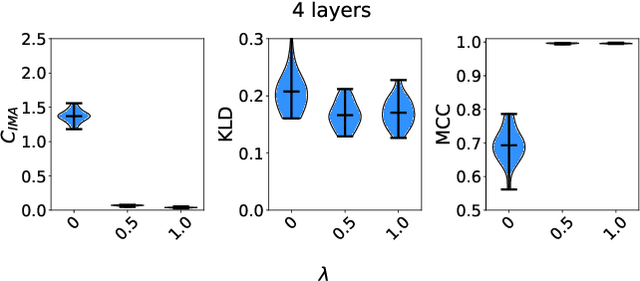
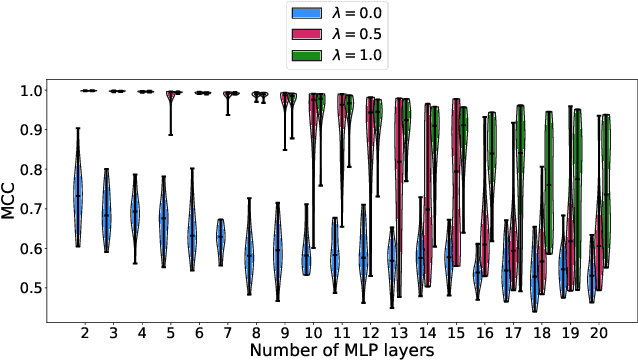
One aim of representation learning is to recover the original latent code that generated the data, a task which requires additional information or inductive biases. A recently proposed approach termed Independent Mechanism Analysis (IMA) postulates that each latent source should influence the observed mixtures independently, complementing standard nonlinear independent component analysis, and taking inspiration from the principle of independent causal mechanisms. While it was shown in theory and experiments that IMA helps recovering the true latents, the method's performance was so far only characterized when the modeling assumptions are exactly satisfied. Here, we test the method's robustness to violations of the underlying assumptions. We find that the benefits of IMA-based regularization for recovering the true sources extend to mixing functions with various degrees of violation of the IMA principle, while standard regularizers do not provide the same merits. Moreover, we show that unregularized maximum likelihood recovers mixing functions which systematically deviate from the IMA principle, and provide an argument elucidating the benefits of IMA-based regularization.
Multimodal Transformer for Automatic 3D Annotation and Object Detection
Jul 20, 2022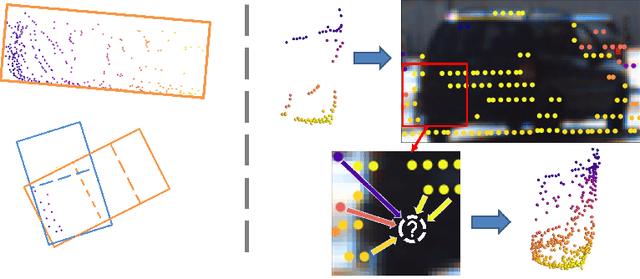
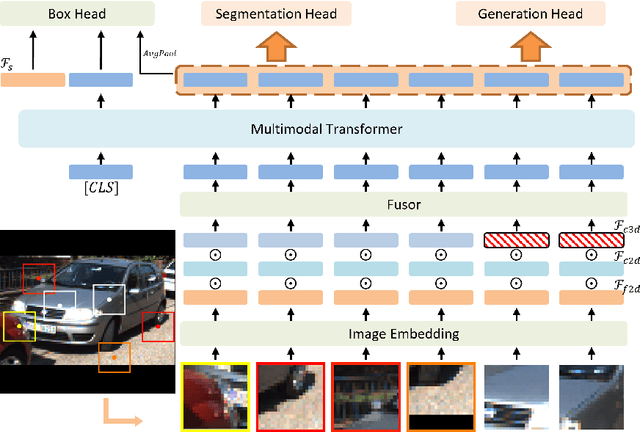
Despite a growing number of datasets being collected for training 3D object detection models, significant human effort is still required to annotate 3D boxes on LiDAR scans. To automate the annotation and facilitate the production of various customized datasets, we propose an end-to-end multimodal transformer (MTrans) autolabeler, which leverages both LiDAR scans and images to generate precise 3D box annotations from weak 2D bounding boxes. To alleviate the pervasive sparsity problem that hinders existing autolabelers, MTrans densifies the sparse point clouds by generating new 3D points based on 2D image information. With a multi-task design, MTrans segments the foreground/background, densifies LiDAR point clouds, and regresses 3D boxes simultaneously. Experimental results verify the effectiveness of the MTrans for improving the quality of the generated labels. By enriching the sparse point clouds, our method achieves 4.48\% and 4.03\% better 3D AP on KITTI moderate and hard samples, respectively, versus the state-of-the-art autolabeler. MTrans can also be extended to improve the accuracy for 3D object detection, resulting in a remarkable 89.45\% AP on KITTI hard samples. Codes are at \url{https://github.com/Cliu2/MTrans}.
Speaker Anonymization with Phonetic Intermediate Representations
Jul 11, 2022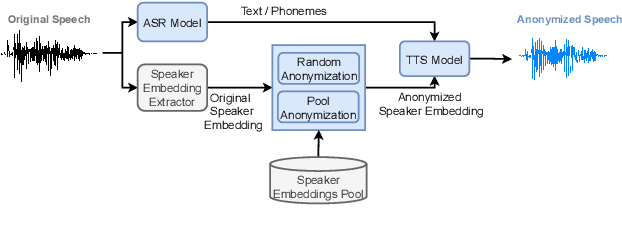
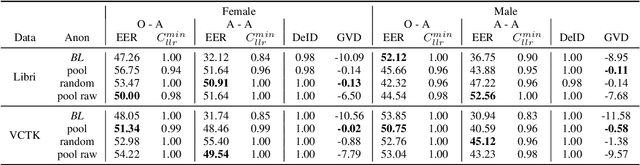
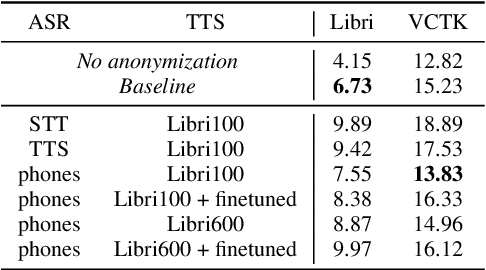

In this work, we propose a speaker anonymization pipeline that leverages high quality automatic speech recognition and synthesis systems to generate speech conditioned on phonetic transcriptions and anonymized speaker embeddings. Using phones as the intermediate representation ensures near complete elimination of speaker identity information from the input while preserving the original phonetic content as much as possible. Our experimental results on LibriSpeech and VCTK corpora reveal two key findings: 1) although automatic speech recognition produces imperfect transcriptions, our neural speech synthesis system can handle such errors, making our system feasible and robust, and 2) combining speaker embeddings from different resources is beneficial and their appropriate normalization is crucial. Overall, our final best system outperforms significantly the baselines provided in the Voice Privacy Challenge 2020 in terms of privacy robustness against a lazy-informed attacker while maintaining high intelligibility and naturalness of the anonymized speech.
Super-Wideband Massive MIMO
Aug 02, 2022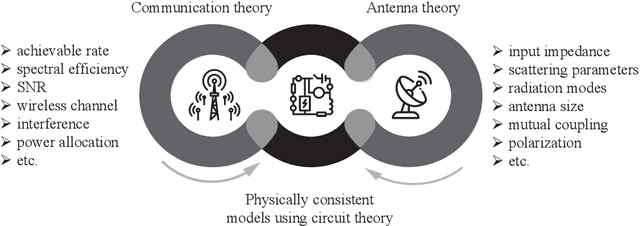
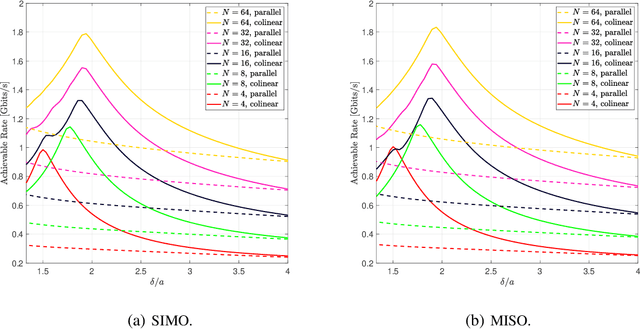
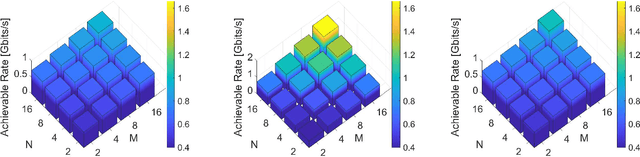
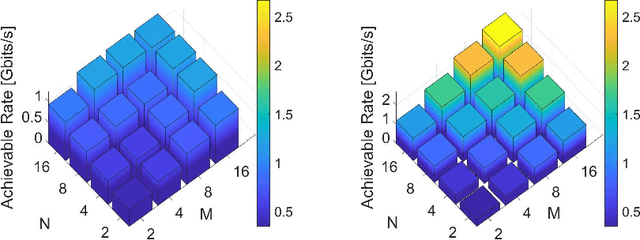
We present a unified model for connected antenna arrays with a massive (but finite) number of tightly integrated (i.e., coupled) antennas in a compact space within the context of massive multiple-input multiple-output (MIMO) communication. We refer to this system as tightly-coupled massive MIMO. From an information-theoretic perspective, scaling the design of tightly-coupled massive MIMO systems in terms of the number of antennas, the operational bandwidth, and form factor was not addressed in prior art and hence not clearly understood. We investigate this open research problem using a physically consistent modeling approach for far-field (FF) MIMO communication based on multi-port circuit theory. In doing so, we turn mutual coupling (MC) from a foe to a friend of MIMO systems design, thereby challenging a basic percept in antenna systems engineering that promotes MC mitigation/compensation. We show that tight MC widens the operational bandwidth of antenna arrays thereby unleashing a missing MIMO gain that we coin "bandwidth gain". Furthermore, we derive analytically the asymptotically optimum spacing-to-antenna-size ratio by establishing a condition for tight coupling in the limit of large-size antenna arrays with quasi-continuous apertures. We also optimize the antenna array size while maximizing the achievable rate under fixed transmit power and inter-element spacing. Then, we study the impact of MC on the achievable rate of MIMO systems under light-of-sight (LoS) and Rayleigh fading channels. These results reveal new insights into the design of tightly-coupled massive antenna arrays as opposed to the widely-adopted "disconnected" designs that disregard MC by putting faith in the half-wavelength spacing rule.
Decision SincNet: Neurocognitive models of decision making that predict cognitive processes from neural signals
Aug 04, 2022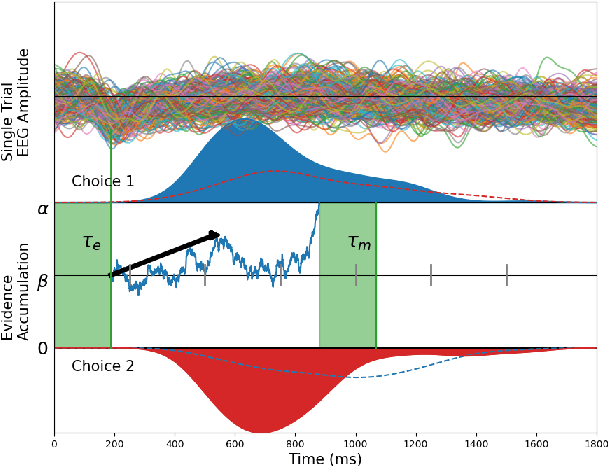
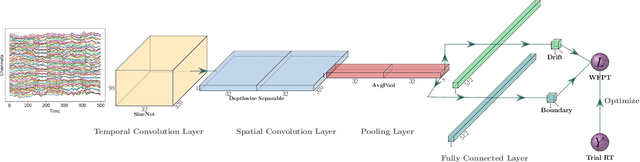
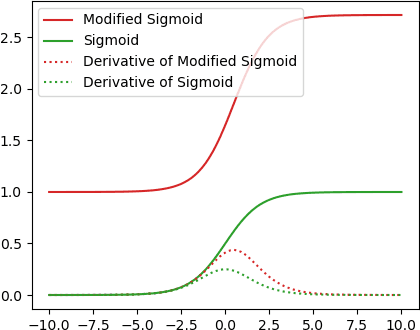
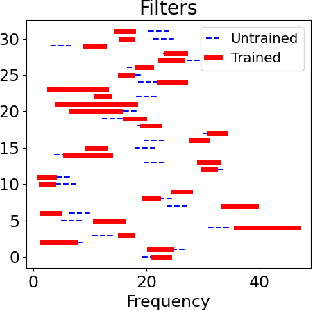
Human decision making behavior is observed with choice-response time data during psychological experiments. Drift-diffusion models of this data consist of a Wiener first-passage time (WFPT) distribution and are described by cognitive parameters: drift rate, boundary separation, and starting point. These estimated parameters are of interest to neuroscientists as they can be mapped to features of cognitive processes of decision making (such as speed, caution, and bias) and related to brain activity. The observed patterns of RT also reflect the variability of cognitive processes from trial to trial mediated by neural dynamics. We adapted a SincNet-based shallow neural network architecture to fit the Drift-Diffusion model using EEG signals on every experimental trial. The model consists of a SincNet layer, a depthwise spatial convolution layer, and two separate FC layers that predict drift rate and boundary for each trial in-parallel. The SincNet layer parametrized the kernels in order to directly learn the low and high cutoff frequencies of bandpass filters that are applied to the EEG data to predict drift and boundary parameters. During training, model parameters were updated by minimizing the negative log likelihood function of WFPT distribution given trial RT. We developed separate decision SincNet models for each participant performing a two-alternative forced-choice task. Our results showed that single-trial estimates of drift and boundary performed better at predicting RTs than the median estimates in both training and test data sets, suggesting that our model can successfully use EEG features to estimate meaningful single-trial Diffusion model parameters. Furthermore, the shallow SincNet architecture identified time windows of information processing related to evidence accumulation and caution and the EEG frequency bands that reflect these processes within each participant.
Distributed Stochastic Bandit Learning with Context Distributions
Jul 28, 2022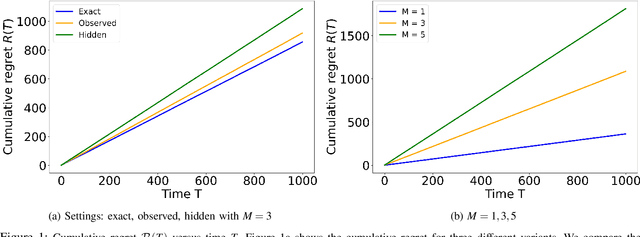
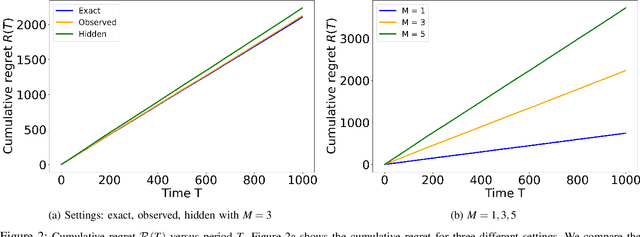
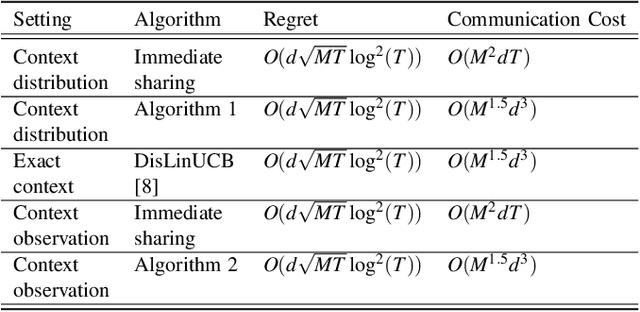
We study the problem of distributed stochastic multi-arm contextual bandit with unknown contexts, in which M agents work collaboratively to choose optimal actions under the coordination of a central server in order to minimize the total regret. In our model, an adversary chooses a distribution on the set of possible contexts and the agents observe only the context distribution and the exact context is unknown to the agents. Such a situation arises, for instance, when the context itself is a noisy measurement or based on a prediction mechanism as in weather forecasting or stock market prediction. Our goal is to develop a distributed algorithm that selects a sequence of optimal actions to maximize the cumulative reward. By performing a feature vector transformation and by leveraging the UCB algorithm, we propose a UCB algorithm for stochastic bandits with context distribution and prove that our algorithm achieves a regret and communications bounds of $O(d\sqrt{MT}log^2T)$ and $O(M^{1.5}d^3)$, respectively, for linearly parametrized reward functions. We also consider a case where the agents observe the actual context after choosing the action. For this setting we presented a modified algorithm that utilizes the additional information to achieve a tighter regret bound. Finally, we validated the performance of our algorithms and compared it with other baseline approaches using extensive simulations on synthetic data and on the real world movielens dataset.
Reduced-order modeling for parameterized large-eddy simulations of atmospheric pollutant dispersion
Aug 02, 2022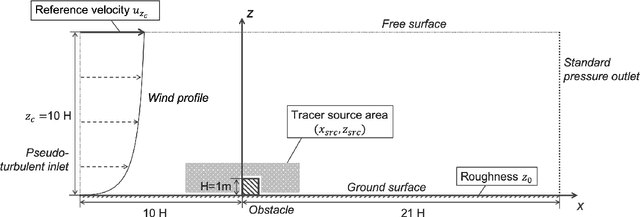
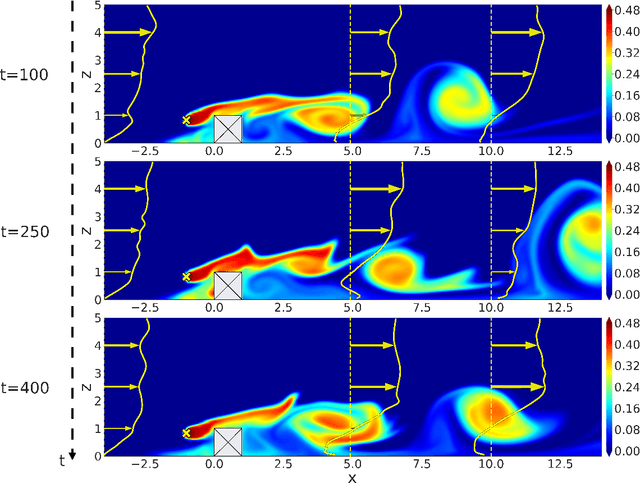
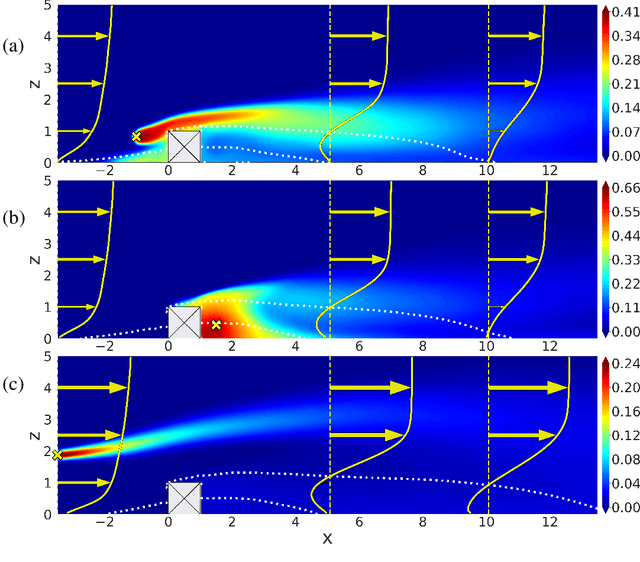
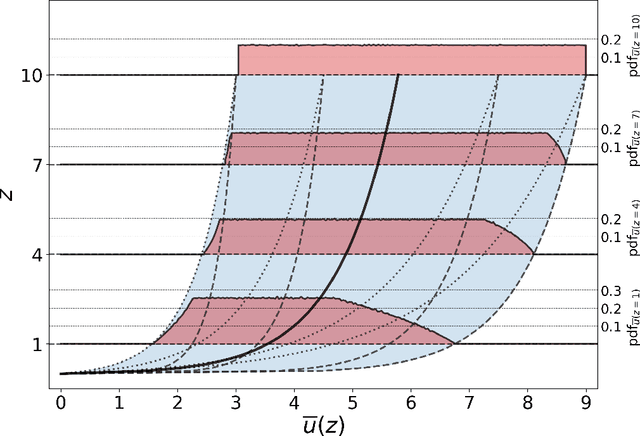
Mapping near-field pollutant concentration is essential to track accidental toxic plume dispersion in urban areas. By solving a large part of the turbulence spectrum, large-eddy simulations (LES) have the potential to accurately represent pollutant concentration spatial variability. Finding a way to synthesize this large amount of information to improve the accuracy of lower-fidelity operational models (e.g. providing better turbulence closure terms) is particularly appealing. This is a challenge in multi-query contexts, where LES become prohibitively costly to deploy to understand how plume flow and tracer dispersion change with various atmospheric and source parameters. To overcome this issue, we propose a non-intrusive reduced-order model combining proper orthogonal decomposition (POD) and Gaussian process regression (GPR) to predict LES field statistics of interest associated with tracer concentrations. GPR hyperpararameters are optimized component-by-component through a maximum a posteriori (MAP) procedure informed by POD. We provide a detailed analysis of the reducedorder model performance on a two-dimensional case study corresponding to a turbulent atmospheric boundary-layer flow over a surface-mounted obstacle. We show that near-source concentration heterogeneities upstream of the obstacle require a large number of POD modes to be well captured. We also show that the component-by-component optimization allows to capture the range of spatial scales in the POD modes, especially the shorter concentration patterns in the high-order modes. The reduced-order model predictions remain acceptable if the learning database is made of at least fifty to hundred LES snapshot providing a first estimation of the required budget to move towards more realistic atmospheric dispersion applications.
Efficient textual explanations for complex road and traffic scenarios based on semantic segmentation
May 26, 2022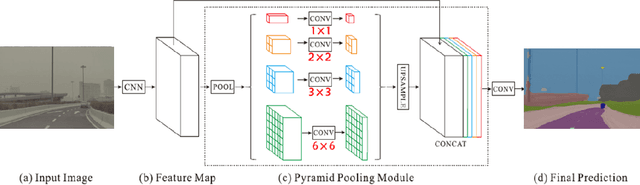

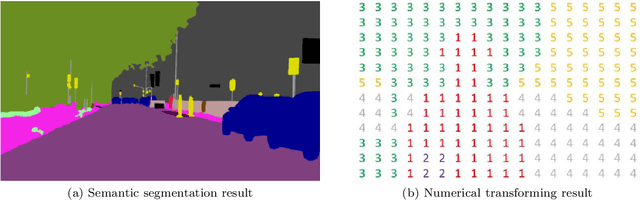
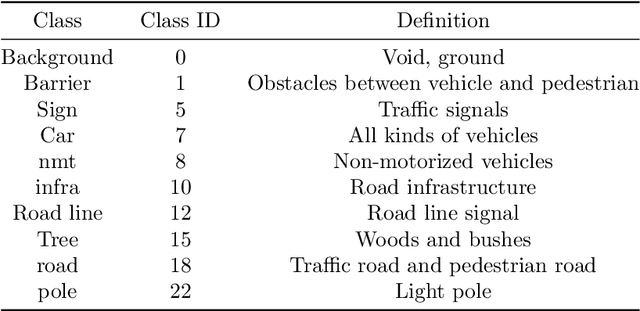
The complex driving environment brings great challenges to the visual perception of autonomous vehicles. The accuracy of visual perception drops off sharply under diverse weather conditions and uncertain traffic flow. Black box model makes it difficult to interpret the mechanisms of visual perception. To enhance the user acceptance and reliability of the visual perception system, a textual explanation of the scene evolvement is essential. It analyzes the geometry and topology structure in the complex environment and offers clues to decision and control. However, the existing scene explanation has been implemented as a separate model. It cannot detect comprehensive textual information and requires a high computational load and time consumption. Thus, this study proposed a comprehensive and efficient textual explanation model for complex road and traffic scenarios. From 336k video frames of the driving environment, critical images of complex road and traffic scenarios were selected into a dataset. Through transfer learning, this study established an accurate and efficient segmentation model to gain semantic information. Based on the XGBoost algorithm, a comprehensive model was developed. The model obtained textual information including road types, the motion of conflict objects, and scenario complexity. The approach was verified on the real-world road. It improved the perception accuracy of critical traffic elements to 78.8%. The time consumption reached 13 minutes for each epoch, which was 11.5 times more efficient compared with the pre-trained network. The textual information analyzed from the model was also accordant with reality. The findings explain how autonomous vehicle detects the driving environment, which lays a foundation for subsequent decision and control. It can improve the perception ability by enriching the prior knowledge and judgments for complex traffic situations.