 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Recipe2Vec: Multi-modal Recipe Representation Learning with Graph Neural Networks
May 24, 2022
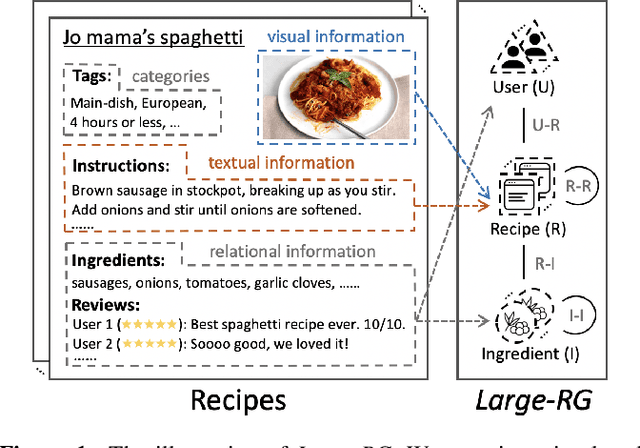
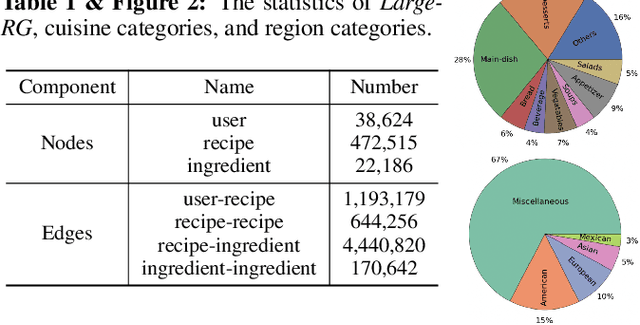
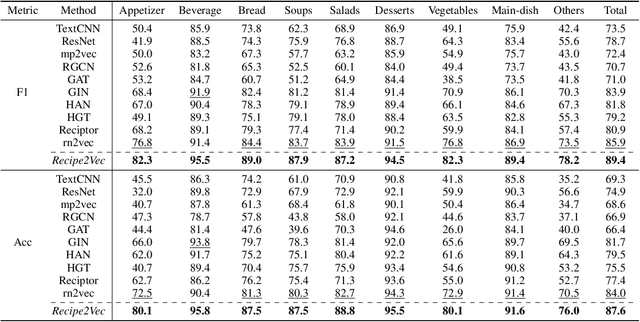
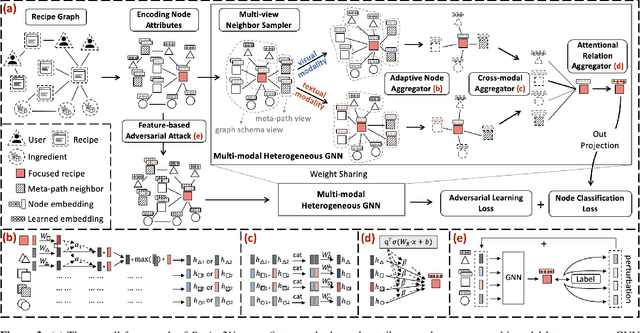
Learning effective recipe representations is essential in food studies. Unlike what has been developed for image-based recipe retrieval or learning structural text embeddings, the combined effect of multi-modal information (i.e., recipe images, text, and relation data) receives less attention. In this paper, we formalize the problem of multi-modal recipe representation learning to integrate the visual, textual, and relational information into recipe embeddings. In particular, we first present Large-RG, a new recipe graph data with over half a million nodes, making it the largest recipe graph to date. We then propose Recipe2Vec, a novel graph neural network based recipe embedding model to capture multi-modal information. Additionally, we introduce an adversarial attack strategy to ensure stable learning and improve performance. Finally, we design a joint objective function of node classification and adversarial learning to optimize the model. Extensive experiments demonstrate that Recipe2Vec outperforms state-of-the-art baselines on two classic food study tasks, i.e., cuisine category classification and region prediction. Dataset and codes are available at https://github.com/meettyj/Recipe2Vec.
REVIVE: Regional Visual Representation Matters in Knowledge-Based Visual Question Answering
Jun 02, 2022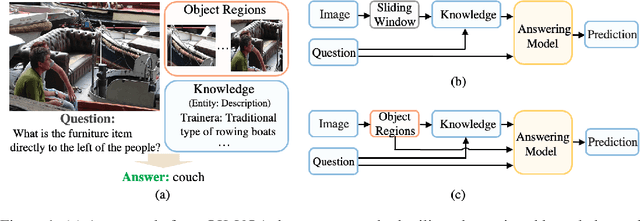
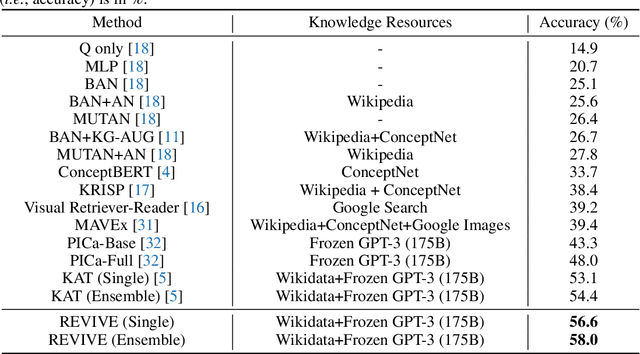
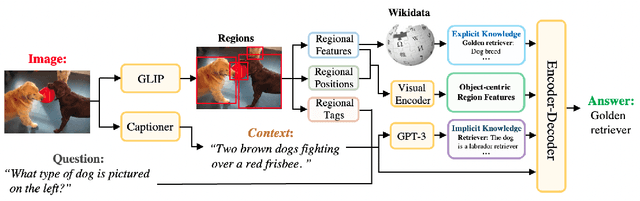

This paper revisits visual representation in knowledge-based visual question answering (VQA) and demonstrates that using regional information in a better way can significantly improve the performance. While visual representation is extensively studied in traditional VQA, it is under-explored in knowledge-based VQA even though these two tasks share the common spirit, i.e., rely on visual input to answer the question. Specifically, we observe that in most state-of-the-art knowledge-based VQA methods: 1) visual features are extracted either from the whole image or in a sliding window manner for retrieving knowledge, and the important relationship within/among object regions is neglected; 2) visual features are not well utilized in the final answering model, which is counter-intuitive to some extent. Based on these observations, we propose a new knowledge-based VQA method REVIVE, which tries to utilize the explicit information of object regions not only in the knowledge retrieval stage but also in the answering model. The key motivation is that object regions and inherent relationships are important for knowledge-based VQA. We perform extensive experiments on the standard OK-VQA dataset and achieve new state-of-the-art performance, i.e., 58.0% accuracy, surpassing previous state-of-the-art method by a large margin (+3.6%). We also conduct detailed analysis and show the necessity of regional information in different framework components for knowledge-based VQA.
Decision SincNet: Neurocognitive models of decision making that predict cognitive processes from neural signals
Aug 04, 2022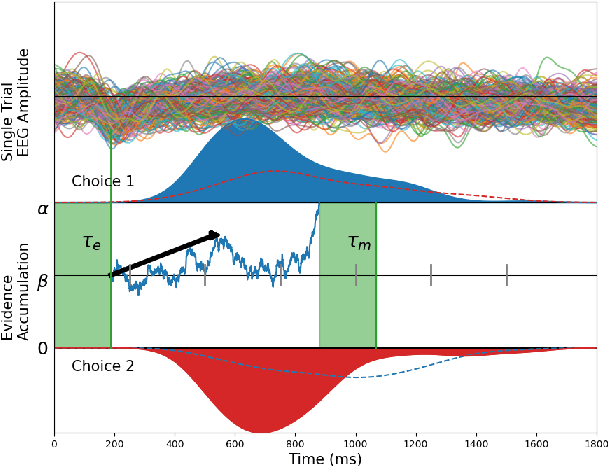
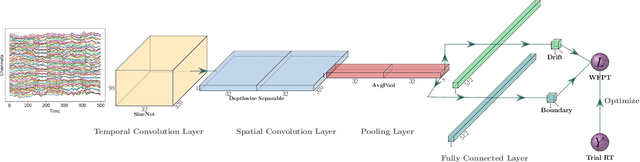
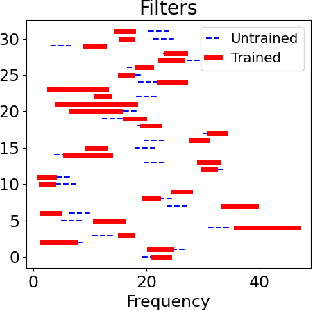
Human decision making behavior is observed with choice-response time data during psychological experiments. Drift-diffusion models of this data consist of a Wiener first-passage time (WFPT) distribution and are described by cognitive parameters: drift rate, boundary separation, and starting point. These estimated parameters are of interest to neuroscientists as they can be mapped to features of cognitive processes of decision making (such as speed, caution, and bias) and related to brain activity. The observed patterns of RT also reflect the variability of cognitive processes from trial to trial mediated by neural dynamics. We adapted a SincNet-based shallow neural network architecture to fit the Drift-Diffusion model using EEG signals on every experimental trial. The model consists of a SincNet layer, a depthwise spatial convolution layer, and two separate FC layers that predict drift rate and boundary for each trial in-parallel. The SincNet layer parametrized the kernels in order to directly learn the low and high cutoff frequencies of bandpass filters that are applied to the EEG data to predict drift and boundary parameters. During training, model parameters were updated by minimizing the negative log likelihood function of WFPT distribution given trial RT. We developed separate decision SincNet models for each participant performing a two-alternative forced-choice task. Our results showed that single-trial estimates of drift and boundary performed better at predicting RTs than the median estimates in both training and test data sets, suggesting that our model can successfully use EEG features to estimate meaningful single-trial Diffusion model parameters. Furthermore, the shallow SincNet architecture identified time windows of information processing related to evidence accumulation and caution and the EEG frequency bands that reflect these processes within each participant.
Super-Wideband Massive MIMO
Aug 02, 2022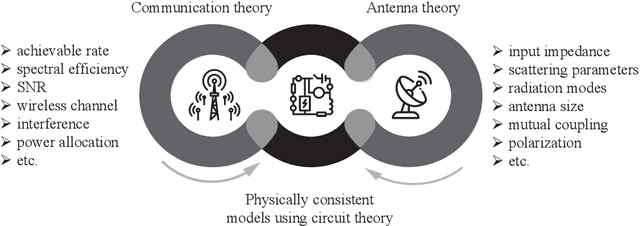
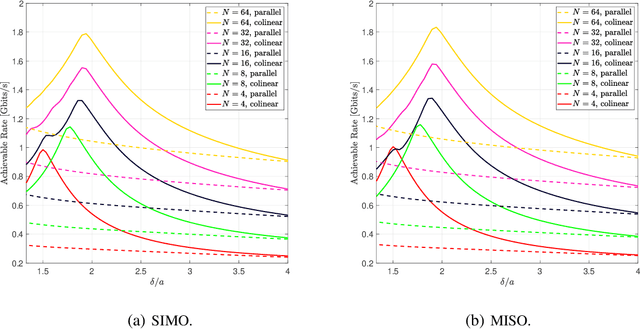
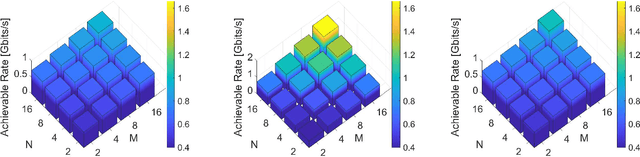
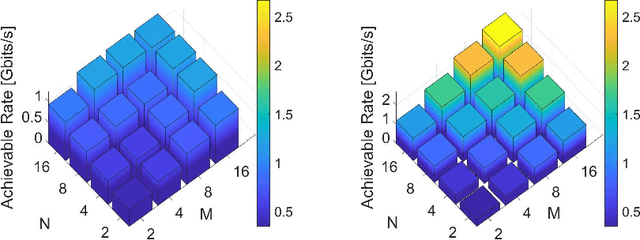
We present a unified model for connected antenna arrays with a massive (but finite) number of tightly integrated (i.e., coupled) antennas in a compact space within the context of massive multiple-input multiple-output (MIMO) communication. We refer to this system as tightly-coupled massive MIMO. From an information-theoretic perspective, scaling the design of tightly-coupled massive MIMO systems in terms of the number of antennas, the operational bandwidth, and form factor was not addressed in prior art and hence not clearly understood. We investigate this open research problem using a physically consistent modeling approach for far-field (FF) MIMO communication based on multi-port circuit theory. In doing so, we turn mutual coupling (MC) from a foe to a friend of MIMO systems design, thereby challenging a basic percept in antenna systems engineering that promotes MC mitigation/compensation. We show that tight MC widens the operational bandwidth of antenna arrays thereby unleashing a missing MIMO gain that we coin "bandwidth gain". Furthermore, we derive analytically the asymptotically optimum spacing-to-antenna-size ratio by establishing a condition for tight coupling in the limit of large-size antenna arrays with quasi-continuous apertures. We also optimize the antenna array size while maximizing the achievable rate under fixed transmit power and inter-element spacing. Then, we study the impact of MC on the achievable rate of MIMO systems under light-of-sight (LoS) and Rayleigh fading channels. These results reveal new insights into the design of tightly-coupled massive antenna arrays as opposed to the widely-adopted "disconnected" designs that disregard MC by putting faith in the half-wavelength spacing rule.
Reduced-order modeling for parameterized large-eddy simulations of atmospheric pollutant dispersion
Aug 02, 2022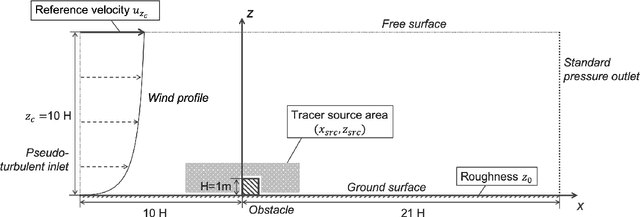
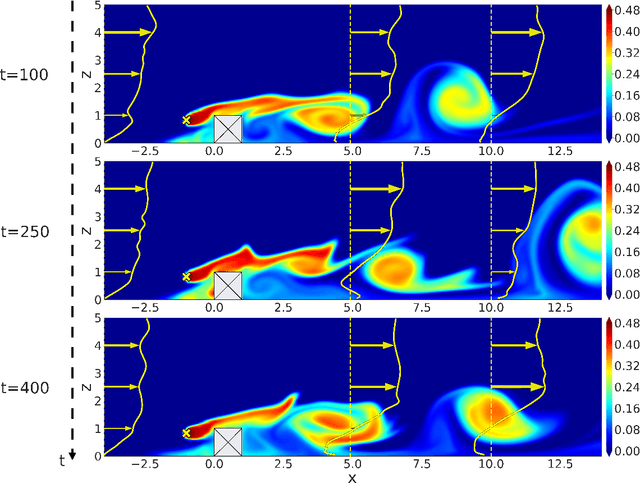
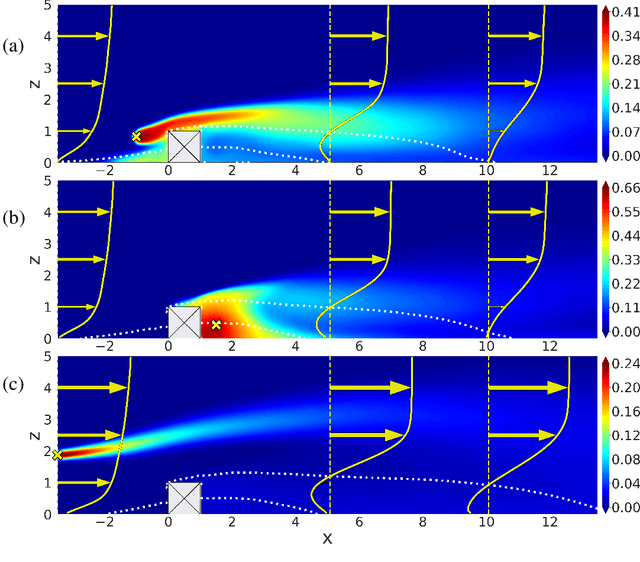
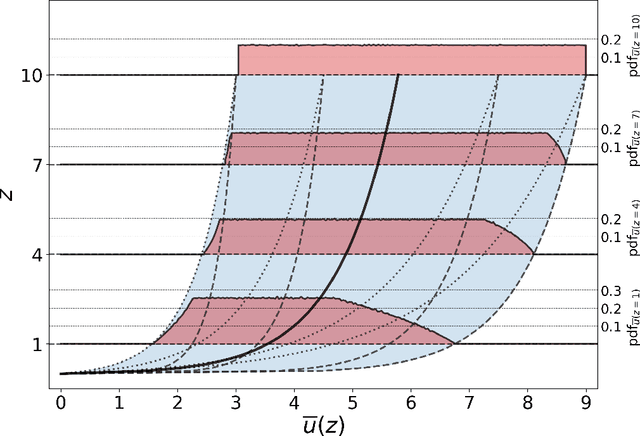
Mapping near-field pollutant concentration is essential to track accidental toxic plume dispersion in urban areas. By solving a large part of the turbulence spectrum, large-eddy simulations (LES) have the potential to accurately represent pollutant concentration spatial variability. Finding a way to synthesize this large amount of information to improve the accuracy of lower-fidelity operational models (e.g. providing better turbulence closure terms) is particularly appealing. This is a challenge in multi-query contexts, where LES become prohibitively costly to deploy to understand how plume flow and tracer dispersion change with various atmospheric and source parameters. To overcome this issue, we propose a non-intrusive reduced-order model combining proper orthogonal decomposition (POD) and Gaussian process regression (GPR) to predict LES field statistics of interest associated with tracer concentrations. GPR hyperpararameters are optimized component-by-component through a maximum a posteriori (MAP) procedure informed by POD. We provide a detailed analysis of the reducedorder model performance on a two-dimensional case study corresponding to a turbulent atmospheric boundary-layer flow over a surface-mounted obstacle. We show that near-source concentration heterogeneities upstream of the obstacle require a large number of POD modes to be well captured. We also show that the component-by-component optimization allows to capture the range of spatial scales in the POD modes, especially the shorter concentration patterns in the high-order modes. The reduced-order model predictions remain acceptable if the learning database is made of at least fifty to hundred LES snapshot providing a first estimation of the required budget to move towards more realistic atmospheric dispersion applications.
Towards Explainability in NLP: Analyzing and Calculating Word Saliency through Word Properties
Jul 17, 2022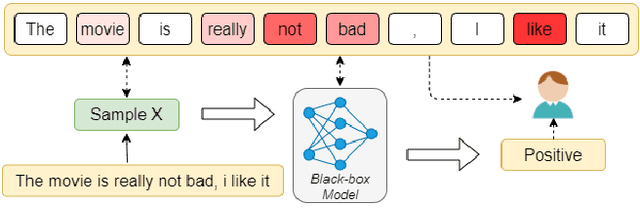
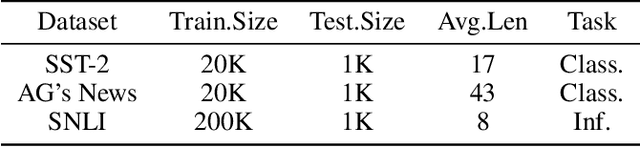

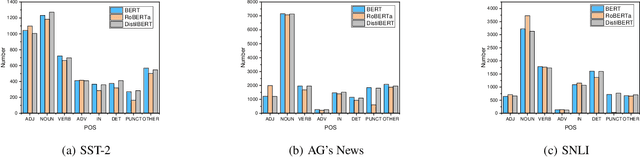
The wide use of black-box models in natural language processing brings great challenges to the understanding of the decision basis, the trustworthiness of the prediction results, and the improvement of the model performance. The words in text samples have properties that reflect their semantics and contextual information, such as the part of speech, the position, etc. These properties may have certain relationships with the word saliency, which is of great help for studying the explainability of the model predictions. In this paper, we explore the relationships between the word saliency and the word properties. According to the analysis results, we further establish a mapping model, Seq2Saliency, from the words in a text sample and their properties to the saliency values based on the idea of sequence tagging. In addition, we establish a new dataset called PrSalM, which contains each word in the text samples, the word properties, and the word saliency values. The experimental evaluations are conducted to analyze the saliency of words with different properties. The effectiveness of the Seq2Saliency model is verified.
Temporal Information and Event Markup Language: TIE-ML Markup Process and Schema Version 1.0
Sep 28, 2021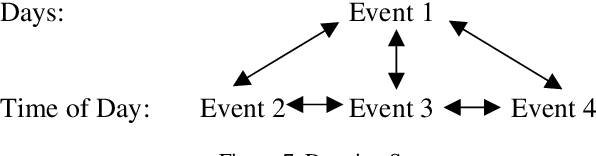

Temporal Information and Event Markup Language (TIE-ML) is a markup strategy and annotation schema to improve the productivity and accuracy of temporal and event related annotation of corpora to facilitate machine learning based model training. For the annotation of events, temporal sequencing, and durations, it is significantly simpler by providing an extremely reduced tag set for just temporal relations and event enumeration. In comparison to other standards, as for example the Time Markup Language (TimeML), it is much easier to use by dropping sophisticated formalisms, theoretical concepts, and annotation approaches. Annotations of corpora using TimeML can be mapped to TIE-ML with a loss, and TIE-ML annotations can be fully mapped to TimeML with certain under-specification.
Point-to-Voxel Knowledge Distillation for LiDAR Semantic Segmentation
Jun 05, 2022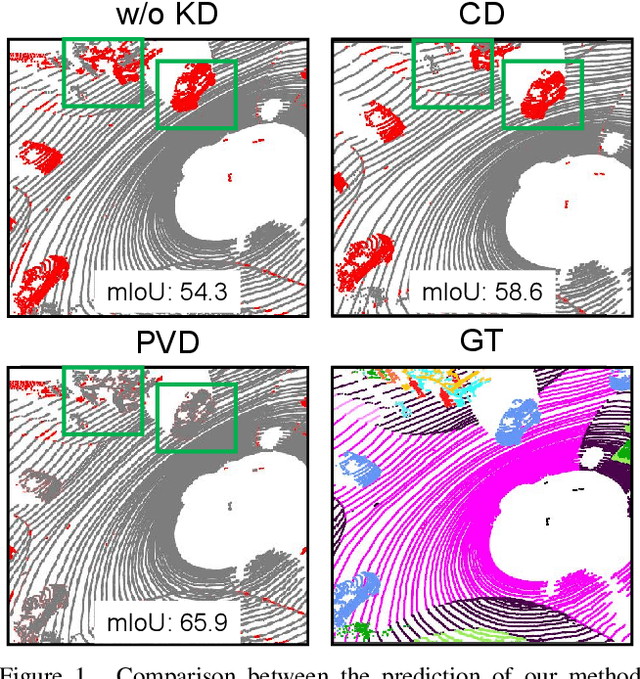
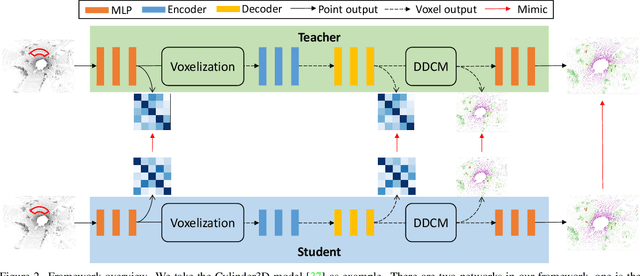
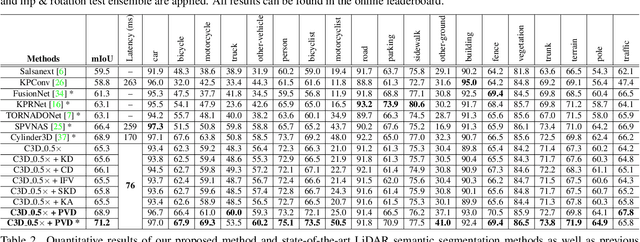
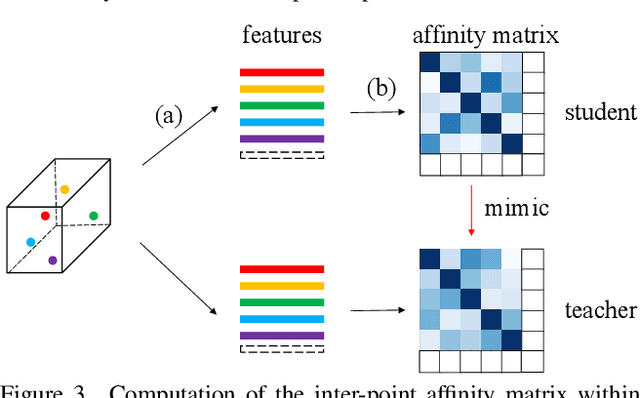
This article addresses the problem of distilling knowledge from a large teacher model to a slim student network for LiDAR semantic segmentation. Directly employing previous distillation approaches yields inferior results due to the intrinsic challenges of point cloud, i.e., sparsity, randomness and varying density. To tackle the aforementioned problems, we propose the Point-to-Voxel Knowledge Distillation (PVD), which transfers the hidden knowledge from both point level and voxel level. Specifically, we first leverage both the pointwise and voxelwise output distillation to complement the sparse supervision signals. Then, to better exploit the structural information, we divide the whole point cloud into several supervoxels and design a difficulty-aware sampling strategy to more frequently sample supervoxels containing less-frequent classes and faraway objects. On these supervoxels, we propose inter-point and inter-voxel affinity distillation, where the similarity information between points and voxels can help the student model better capture the structural information of the surrounding environment. We conduct extensive experiments on two popular LiDAR segmentation benchmarks, i.e., nuScenes and SemanticKITTI. On both benchmarks, our PVD consistently outperforms previous distillation approaches by a large margin on three representative backbones, i.e., Cylinder3D, SPVNAS and MinkowskiNet. Notably, on the challenging nuScenes and SemanticKITTI datasets, our method can achieve roughly 75% MACs reduction and 2x speedup on the competitive Cylinder3D model and rank 1st on the SemanticKITTI leaderboard among all published algorithms. Our code is available at https://github.com/cardwing/Codes-for-PVKD.
Distributed Stochastic Bandit Learning with Context Distributions
Jul 28, 2022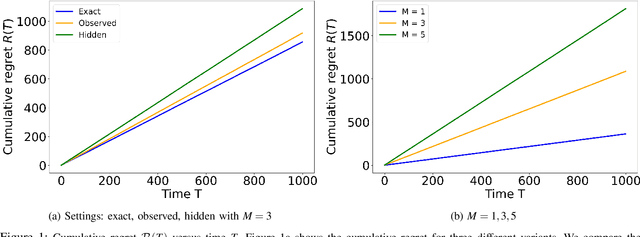
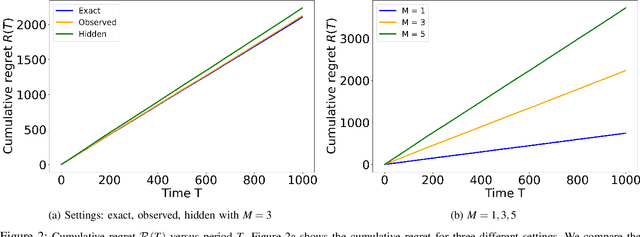
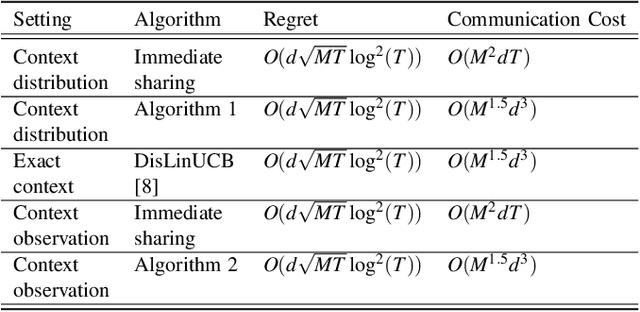
We study the problem of distributed stochastic multi-arm contextual bandit with unknown contexts, in which M agents work collaboratively to choose optimal actions under the coordination of a central server in order to minimize the total regret. In our model, an adversary chooses a distribution on the set of possible contexts and the agents observe only the context distribution and the exact context is unknown to the agents. Such a situation arises, for instance, when the context itself is a noisy measurement or based on a prediction mechanism as in weather forecasting or stock market prediction. Our goal is to develop a distributed algorithm that selects a sequence of optimal actions to maximize the cumulative reward. By performing a feature vector transformation and by leveraging the UCB algorithm, we propose a UCB algorithm for stochastic bandits with context distribution and prove that our algorithm achieves a regret and communications bounds of $O(d\sqrt{MT}log^2T)$ and $O(M^{1.5}d^3)$, respectively, for linearly parametrized reward functions. We also consider a case where the agents observe the actual context after choosing the action. For this setting we presented a modified algorithm that utilizes the additional information to achieve a tighter regret bound. Finally, we validated the performance of our algorithms and compared it with other baseline approaches using extensive simulations on synthetic data and on the real world movielens dataset.
Implicit semantic-based personalized micro-videos recommendation
May 06, 2022

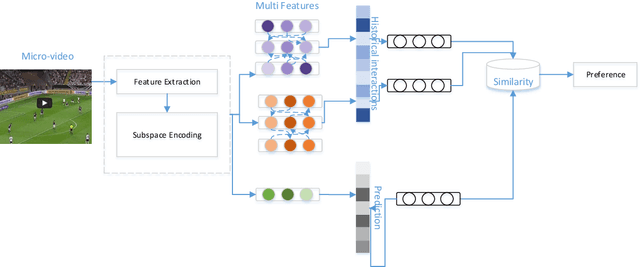
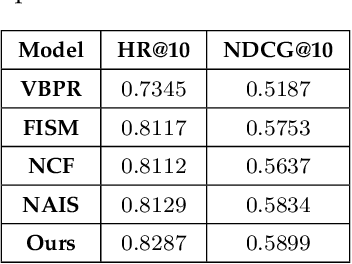
With the rapid development of mobile Internet and big data, a huge amount of data is generated in the network, but the data that users are really interested in a very small portion. To extract the information that users are interested in from the huge amount of data, the information overload problem needs to be solved. In the era of mobile internet, the user's characteristics and other information should be combined in the massive amount of data to quickly and accurately recommend content to the user, as far as possible to meet the user's personalized needs. Therefore, there is an urgent need to realize high-speed and effective retrieval in tens of thousands of micro-videos. Video data content contains complex meanings, and there are intrinsic connections between video data. For multimodal information, subspace coding learning is introduced to build a coding network from public potential representations to multimodal feature information, taking into account the consistency and complementarity of information under each modality to obtain a public representation of the complete eigenvalue. An end-to-end reordering model based on deep learning and attention mechanism, called interest-related product similarity model based on multimodal data, is proposed for providing top-N recommendations. The multimodal feature learning module, interest-related network module and product similarity recommendation module together form the new model.By conducting extensive experiments on publicly accessible datasets, the results demonstrate the state-of-the-art performance of our proposed algorithm and its effectiveness.