 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Frequency Permutation Subsets for Joint Radar and Communication
Jul 21, 2022
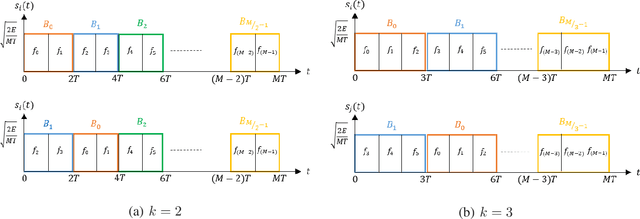
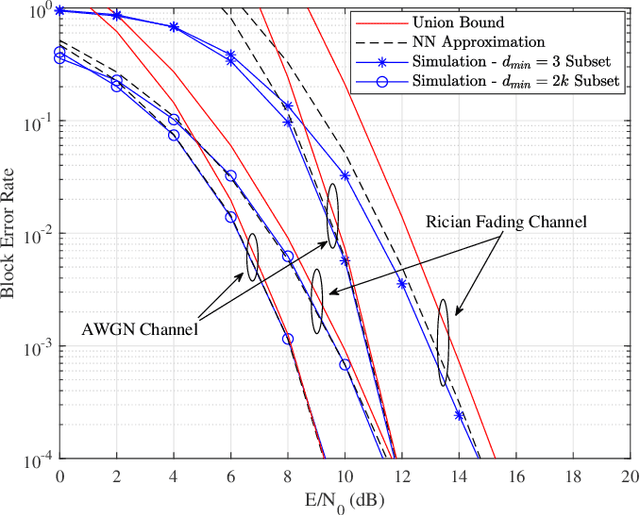
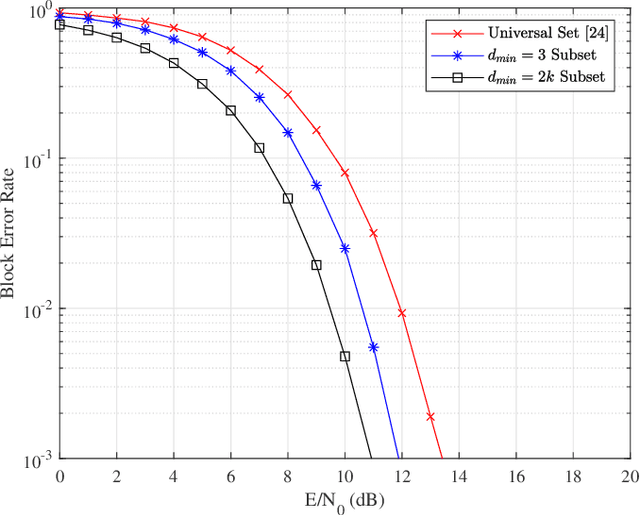
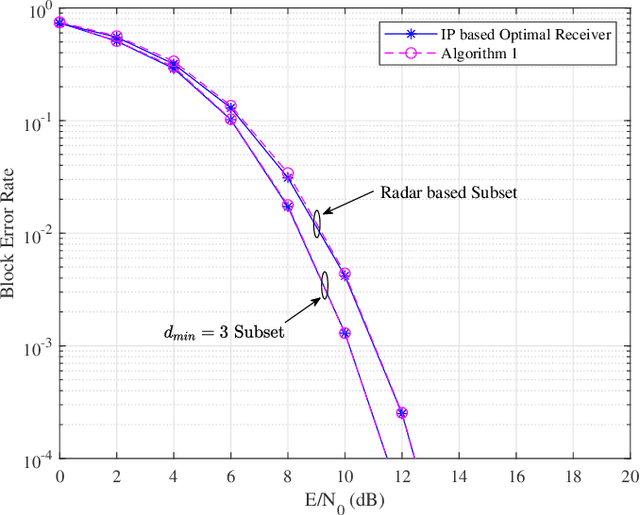
This paper focuses on waveform design for joint radar and communication systems and presents a new subset selection process to improve the communication error rate performance and global accuracy of radar sensing of the random stepped frequency permutation waveform. An optimal communication receiver based on integer programming is proposed to handle any subset of permutations followed by a more efficient sub-optimal receiver based on the Hungarian algorithm. Considering optimum maximum likelihood detection, the block error rate is analyzed under both additive white Gaussian noise and correlated Rician fading. We propose two methods to select a permutation subset with an improved block error rate and an efficient encoding scheme to map the information symbols to selected permutations under these subsets. From the radar perspective, the ambiguity function is analyzed with regards to the local and the global accuracy of target detection. Furthermore, a subset selection method to reduce the maximum sidelobe height is proposed by extending the properties of Costas arrays. Finally, the process of remapping the frequency tones to the symbol set used to generate permutations is introduced as a method to improve both the communication and radar performances of the selected permutation subset.
Grounding Visual Representations with Texts for Domain Generalization
Jul 21, 2022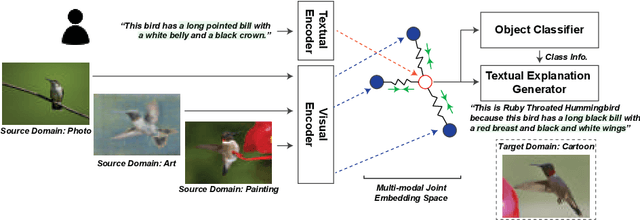
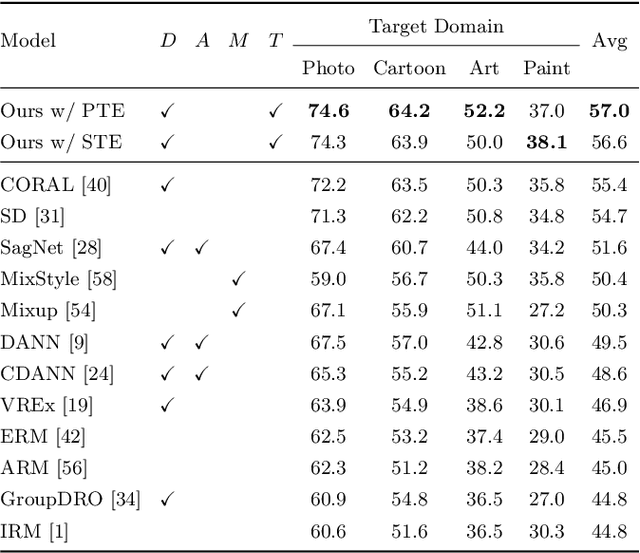
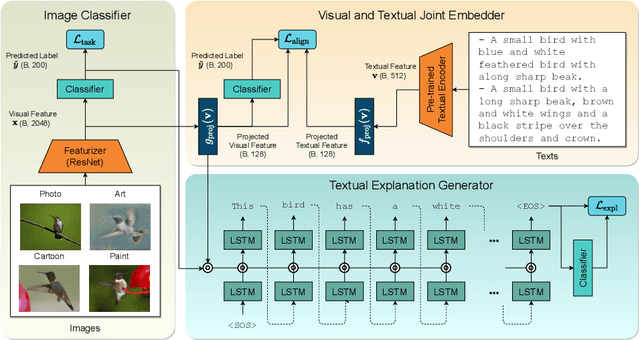
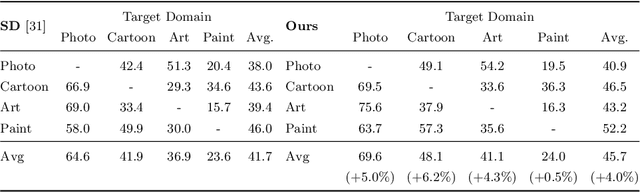
Reducing the representational discrepancy between source and target domains is a key component to maximize the model generalization. In this work, we advocate for leveraging natural language supervision for the domain generalization task. We introduce two modules to ground visual representations with texts containing typical reasoning of humans: (1) Visual and Textual Joint Embedder and (2) Textual Explanation Generator. The former learns the image-text joint embedding space where we can ground high-level class-discriminative information into the model. The latter leverages an explainable model and generates explanations justifying the rationale behind its decision. To the best of our knowledge, this is the first work to leverage the vision-and-language cross-modality approach for the domain generalization task. Our experiments with a newly created CUB-DG benchmark dataset demonstrate that cross-modality supervision can be successfully used to ground domain-invariant visual representations and improve the model generalization. Furthermore, in the large-scale DomainBed benchmark, our proposed method achieves state-of-the-art results and ranks 1st in average performance for five multi-domain datasets. The dataset and codes are available at https://github.com/mswzeus/GVRT.
Prototypical Contrast Adaptation for Domain Adaptive Semantic Segmentation
Jul 14, 2022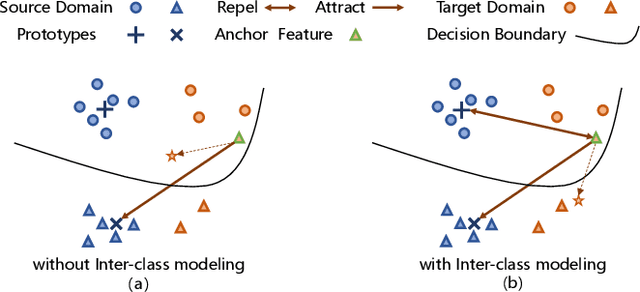
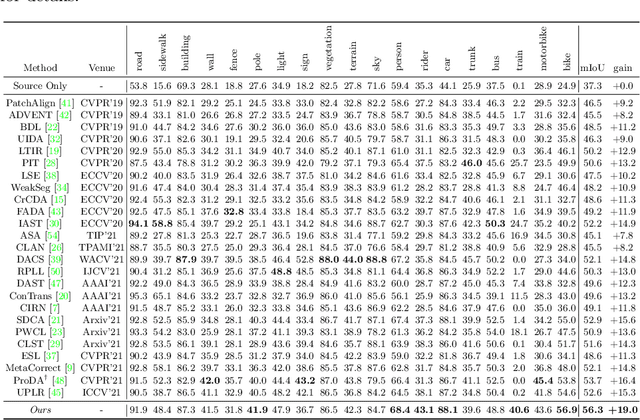
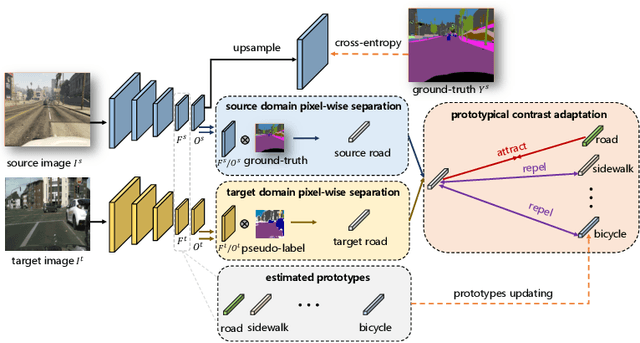
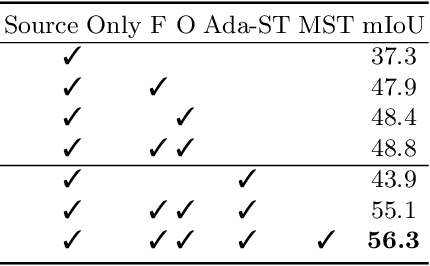
Unsupervised Domain Adaptation (UDA) aims to adapt the model trained on the labeled source domain to an unlabeled target domain. In this paper, we present Prototypical Contrast Adaptation (ProCA), a simple and efficient contrastive learning method for unsupervised domain adaptive semantic segmentation. Previous domain adaptation methods merely consider the alignment of the intra-class representational distributions across various domains, while the inter-class structural relationship is insufficiently explored, resulting in the aligned representations on the target domain might not be as easily discriminated as done on the source domain anymore. Instead, ProCA incorporates inter-class information into class-wise prototypes, and adopts the class-centered distribution alignment for adaptation. By considering the same class prototypes as positives and other class prototypes as negatives to achieve class-centered distribution alignment, ProCA achieves state-of-the-art performance on classical domain adaptation tasks, {\em i.e., GTA5 $\to$ Cityscapes \text{and} SYNTHIA $\to$ Cityscapes}. Code is available at \href{https://github.com/jiangzhengkai/ProCA}{ProCA}
Point-to-Voxel Knowledge Distillation for LiDAR Semantic Segmentation
Jun 05, 2022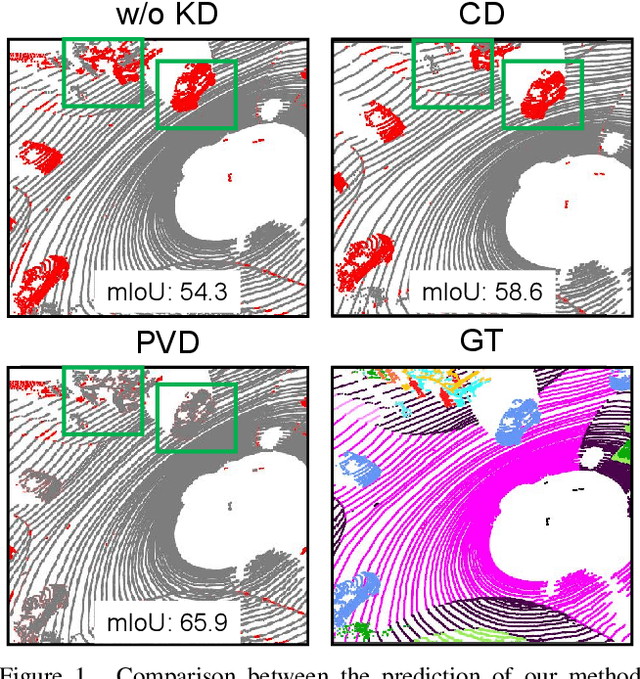
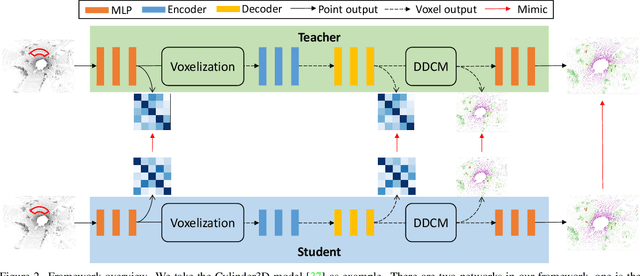
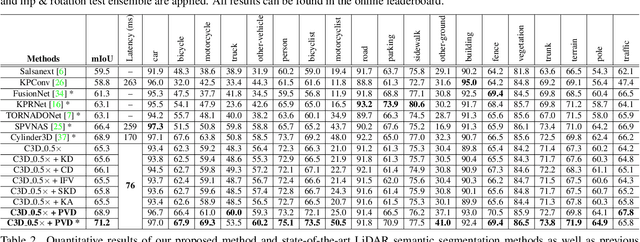
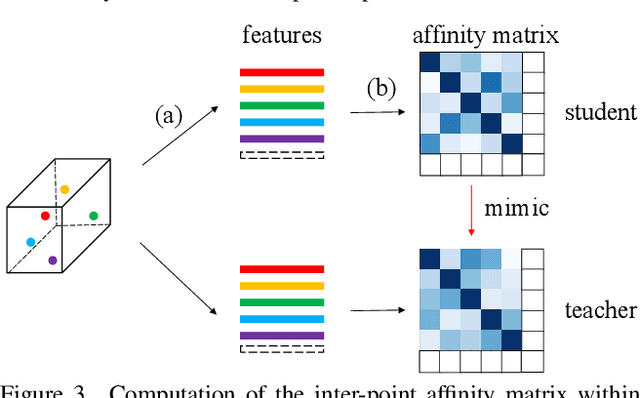
This article addresses the problem of distilling knowledge from a large teacher model to a slim student network for LiDAR semantic segmentation. Directly employing previous distillation approaches yields inferior results due to the intrinsic challenges of point cloud, i.e., sparsity, randomness and varying density. To tackle the aforementioned problems, we propose the Point-to-Voxel Knowledge Distillation (PVD), which transfers the hidden knowledge from both point level and voxel level. Specifically, we first leverage both the pointwise and voxelwise output distillation to complement the sparse supervision signals. Then, to better exploit the structural information, we divide the whole point cloud into several supervoxels and design a difficulty-aware sampling strategy to more frequently sample supervoxels containing less-frequent classes and faraway objects. On these supervoxels, we propose inter-point and inter-voxel affinity distillation, where the similarity information between points and voxels can help the student model better capture the structural information of the surrounding environment. We conduct extensive experiments on two popular LiDAR segmentation benchmarks, i.e., nuScenes and SemanticKITTI. On both benchmarks, our PVD consistently outperforms previous distillation approaches by a large margin on three representative backbones, i.e., Cylinder3D, SPVNAS and MinkowskiNet. Notably, on the challenging nuScenes and SemanticKITTI datasets, our method can achieve roughly 75% MACs reduction and 2x speedup on the competitive Cylinder3D model and rank 1st on the SemanticKITTI leaderboard among all published algorithms. Our code is available at https://github.com/cardwing/Codes-for-PVKD.
Effort Informed Roadmaps (EIRM*): Efficient Asymptotically Optimal Multiquery Planning by Actively Reusing Validation Effort
May 17, 2022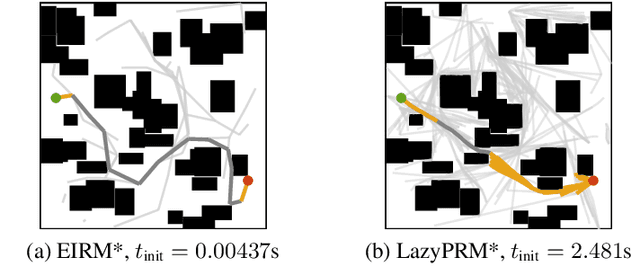
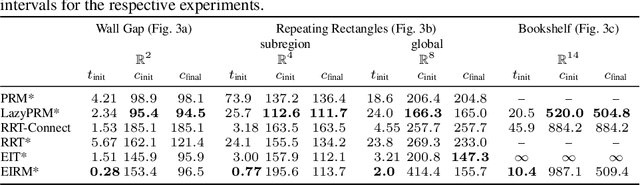
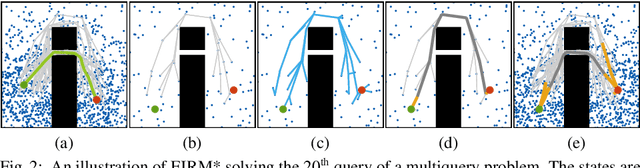
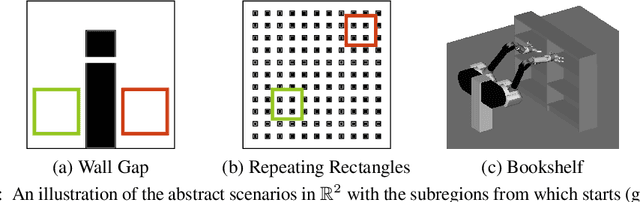
Multiquery planning algorithms find paths between various different starts and goals in a single search space. They are designed to do so efficiently by reusing information across planning queries. This information may be computed before or during the search and often includes knowledge of valid paths. Using known valid paths to solve an individual planning query takes less computational effort than finding a completely new solution. This allows multiquery algorithms, such as PRM*, to outperform single-query algorithms, such as RRT*, on many problems but their relative performance depends on how much information is reused. Despite this, few multiquery planners explicitly seek to maximize path reuse and, as a result, many do not consistently outperform single-query alternatives. This paper presents Effort Informed Roadmaps (EIRM*), an almost-surely asymptotically optimal multiquery planning algorithm that explicitly prioritizes reusing computational effort. EIRM* uses an asymmetric bidirectional search to identify existing paths that may help solve an individual planning query and then uses this information to order its search and reduce computational effort. This allows it to find initial solutions up to an order-of-magnitude faster than state-of-the-art planning algorithms on the tested abstract and robotic multiquery planning problems.
Smart Mat Used for Prevention of Hospital-Acquired Pressure Injuries
Jul 08, 2022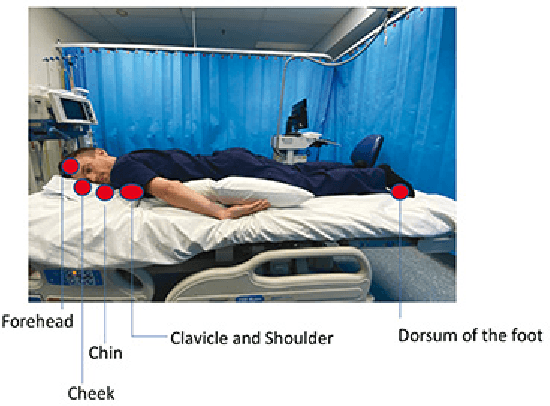

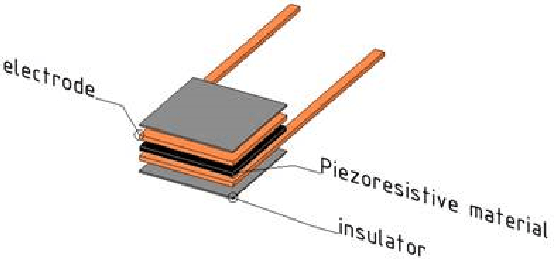
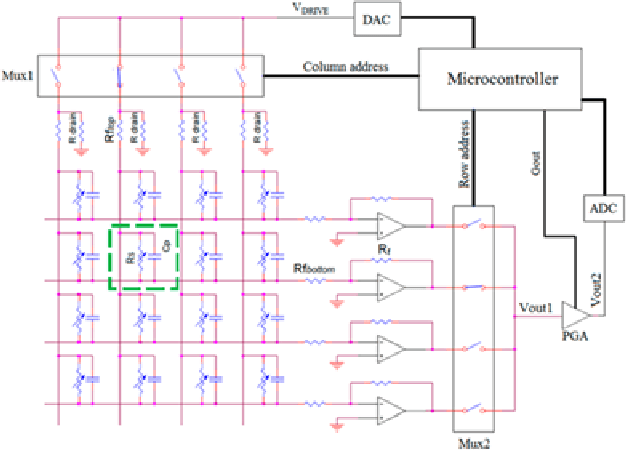
This work develops a smart mat for monitoring body positions. We use Velostat as a force sensor resistance (FSR) to construct a sensor matrix over the mat to receive the pressure distribution of the patient's body, and then upload the processed distribution information to the PC for data visualization through Arduino. Data visualization on the PC side is compiled through Python language to realize the functions of patient body pressure distribution monitoring, long-term pressure alarm and posture prediction. The purpose of this work is to relieve the work stress on medical staff caused by pressure injuries during the treatment and care of patients during the pandemic. This paper includes the literature review on similar previous works and combines the test results to design the structure and circuit of the smart mat.
Multi-Scale User Behavior Network for Entire Space Multi-Task Learning
Aug 03, 2022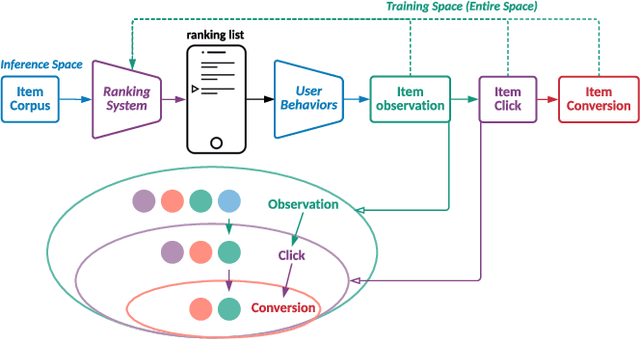

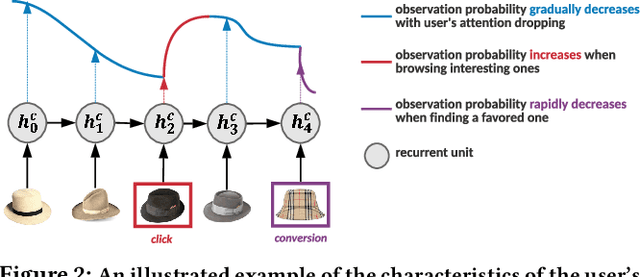
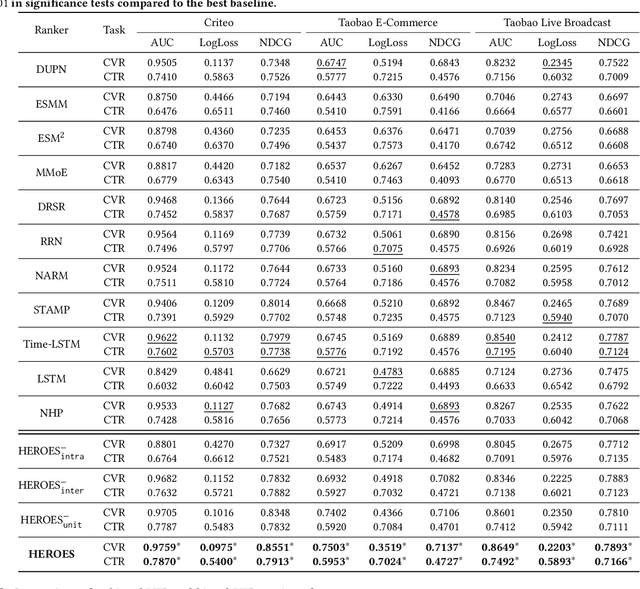
Modelling the user's multiple behaviors is an essential part of modern e-commerce, whose widely adopted application is to jointly optimize click-through rate (CTR) and conversion rate (CVR) predictions. Most of existing methods overlook the effect of two key characteristics of the user's behaviors: for each item list, (i) contextual dependence refers to that the user's behaviors on any item are not purely determinated by the item itself but also are influenced by the user's previous behaviors (e.g., clicks, purchases) on other items in the same sequence; (ii) multiple time scales means that users are likely to click frequently but purchase periodically. To this end, we develop a new multi-scale user behavior network named Hierarchical rEcurrent Ranking On the Entire Space (HEROES) which incorporates the contextual information to estimate the user multiple behaviors in a multi-scale fashion. Concretely, we introduce a hierarchical framework, where the lower layer models the user's engagement behaviors while the upper layer estimates the user's satisfaction behaviors. The proposed architecture can automatically learn a suitable time scale for each layer to capture the dynamic user's behavioral patterns. Besides the architecture, we also introduce the Hawkes process to form a novel recurrent unit which can not only encode the items' features in the context but also formulate the excitation or discouragement from the user's previous behaviors. We further show that HEROES can be extended to build unbiased ranking systems through combinations with the survival analysis technique. Extensive experiments over three large-scale industrial datasets demonstrate the superiority of our model compared with the state-of-the-art methods.
Robust Scene Inference under Noise-Blur Dual Corruptions
Jul 24, 2022
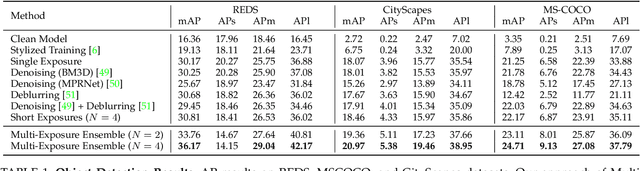
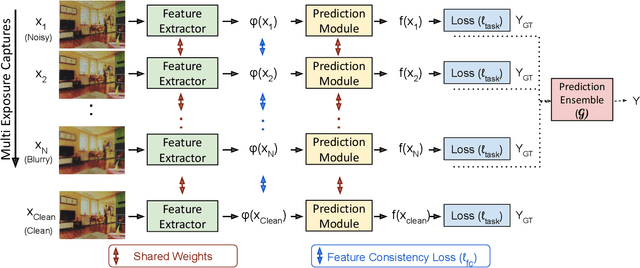
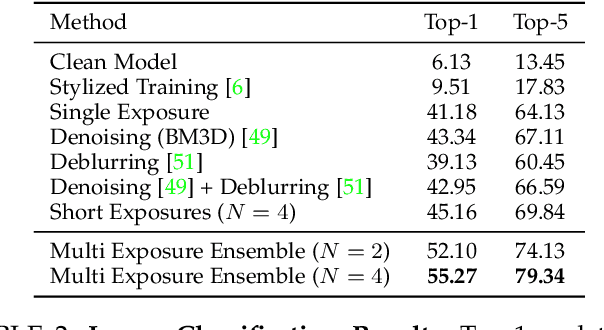
Scene inference under low-light is a challenging problem due to severe noise in the captured images. One way to reduce noise is to use longer exposure during the capture. However, in the presence of motion (scene or camera motion), longer exposures lead to motion blur, resulting in loss of image information. This creates a trade-off between these two kinds of image degradations: motion blur (due to long exposure) vs. noise (due to short exposure), also referred as a dual image corruption pair in this paper. With the rise of cameras capable of capturing multiple exposures of the same scene simultaneously, it is possible to overcome this trade-off. Our key observation is that although the amount and nature of degradation varies for these different image captures, the semantic content remains the same across all images. To this end, we propose a method to leverage these multi exposure captures for robust inference under low-light and motion. Our method builds on a feature consistency loss to encourage similar results from these individual captures, and uses the ensemble of their final predictions for robust visual recognition. We demonstrate the effectiveness of our approach on simulated images as well as real captures with multiple exposures, and across the tasks of object detection and image classification.
Troll Tweet Detection Using Contextualized Word Representations
Jul 17, 2022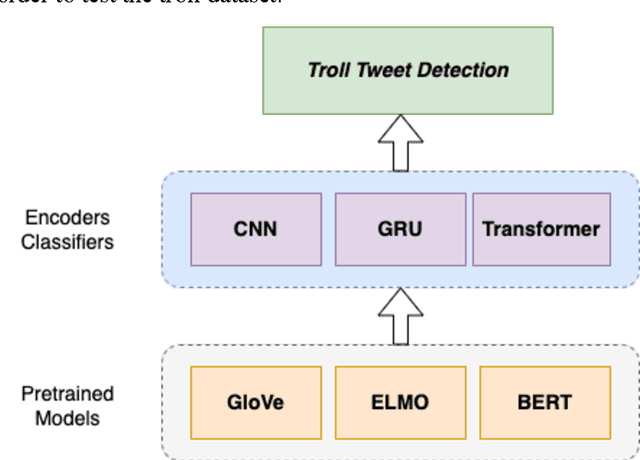
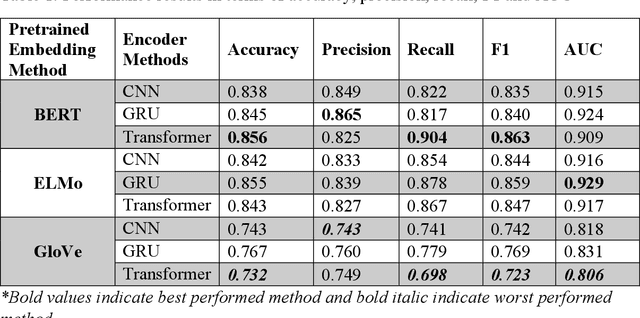

In recent years, many troll accounts have emerged to manipulate social media opinion. Detecting and eradicating trolling is a critical issue for social-networking platforms because businesses, abusers, and nation-state-sponsored troll farms use false and automated accounts. NLP techniques are used to extract data from social networking text, such as Twitter tweets. In many text processing applications, word embedding representation methods, such as BERT, have performed better than prior NLP techniques, offering novel breaks to precisely comprehend and categorize social-networking information for various tasks. This paper implements and compares nine deep learning-based troll tweet detection architectures, with three models for each BERT, ELMo, and GloVe word embedding model. Precision, recall, F1 score, AUC, and classification accuracy are used to evaluate each architecture. From the experimental results, most architectures using BERT models improved troll tweet detection. A customized ELMo-based architecture with a GRU classifier has the highest AUC for detecting troll messages. The proposed architectures can be used by various social-based systems to detect troll messages in the future.
OSFormer: One-Stage Camouflaged Instance Segmentation with Transformers
Jul 05, 2022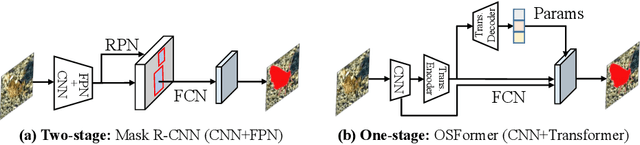
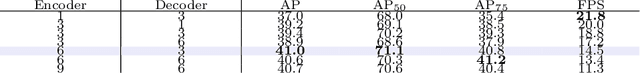

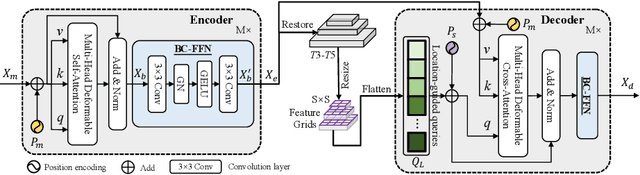
We present OSFormer, the first one-stage transformer framework for camouflaged instance segmentation (CIS). OSFormer is based on two key designs. First, we design a location-sensing transformer (LST) to obtain the location label and instance-aware parameters by introducing the location-guided queries and the blend-convolution feedforward network. Second, we develop a coarse-to-fine fusion (CFF) to merge diverse context information from the LST encoder and CNN backbone. Coupling these two components enables OSFormer to efficiently blend local features and long-range context dependencies for predicting camouflaged instances. Compared with two-stage frameworks, our OSFormer reaches 41% AP and achieves good convergence efficiency without requiring enormous training data, i.e., only 3,040 samples under 60 epochs. Code link: https://github.com/PJLallen/OSFormer.