 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Inception Transformer
May 26, 2022
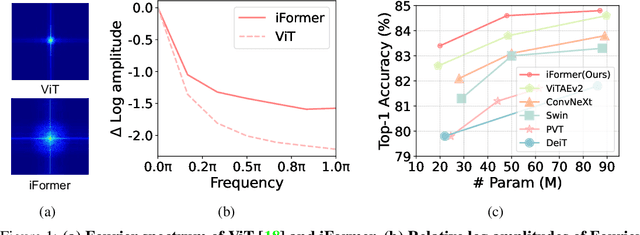
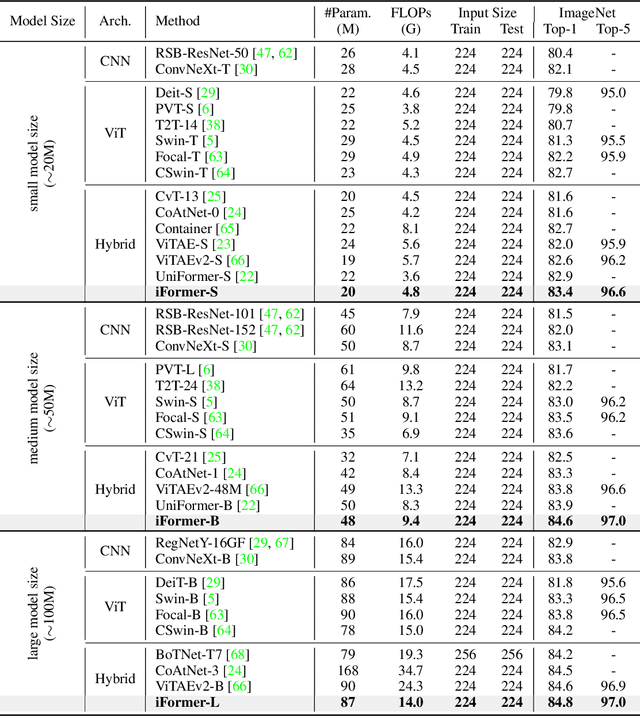
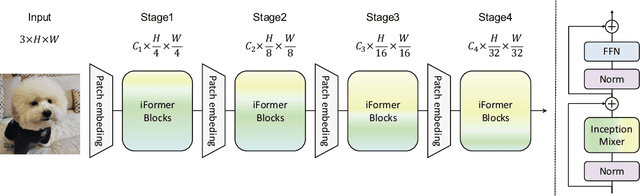
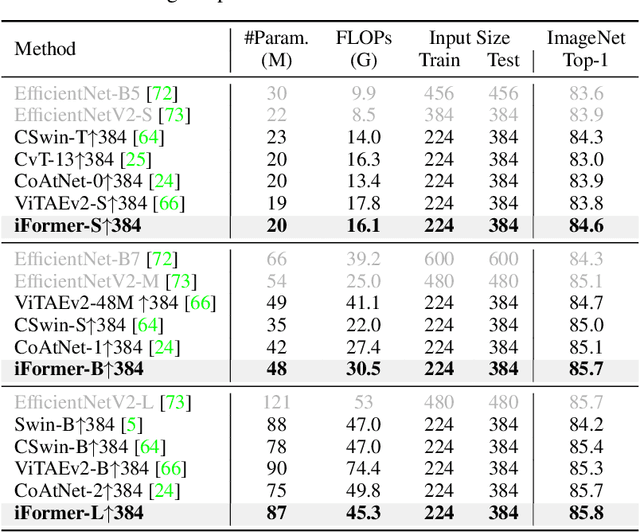
Recent studies show that Transformer has strong capability of building long-range dependencies, yet is incompetent in capturing high frequencies that predominantly convey local information. To tackle this issue, we present a novel and general-purpose Inception Transformer, or iFormer for short, that effectively learns comprehensive features with both high- and low-frequency information in visual data. Specifically, we design an Inception mixer to explicitly graft the advantages of convolution and max-pooling for capturing the high-frequency information to Transformers. Different from recent hybrid frameworks, the Inception mixer brings greater efficiency through a channel splitting mechanism to adopt parallel convolution/max-pooling path and self-attention path as high- and low-frequency mixers, while having the flexibility to model discriminative information scattered within a wide frequency range. Considering that bottom layers play more roles in capturing high-frequency details while top layers more in modeling low-frequency global information, we further introduce a frequency ramp structure, i.e. gradually decreasing the dimensions fed to the high-frequency mixer and increasing those to the low-frequency mixer, which can effectively trade-off high- and low-frequency components across different layers. We benchmark the iFormer on a series of vision tasks, and showcase that it achieves impressive performance on image classification, COCO detection and ADE20K segmentation. For example, our iFormer-S hits the top-1 accuracy of 83.4% on ImageNet-1K, much higher than DeiT-S by 3.6%, and even slightly better than much bigger model Swin-B (83.3%) with only 1/4 parameters and 1/3 FLOPs. Code and models will be released at https://github.com/sail-sg/iFormer.
Stochastic Functional Analysis and Multilevel Vector Field Anomaly Detection
Jul 11, 2022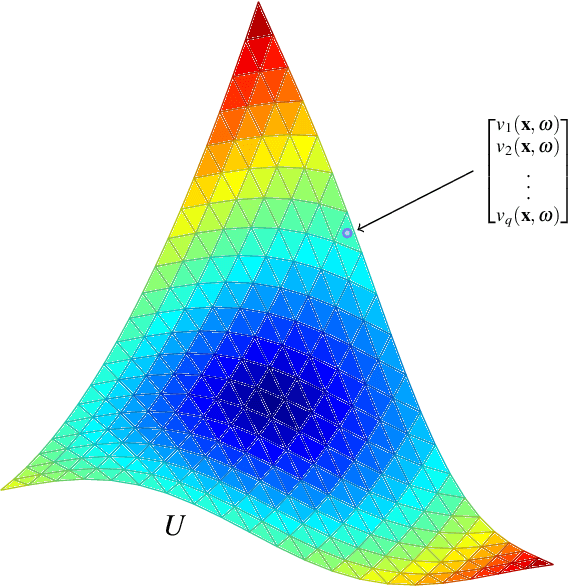
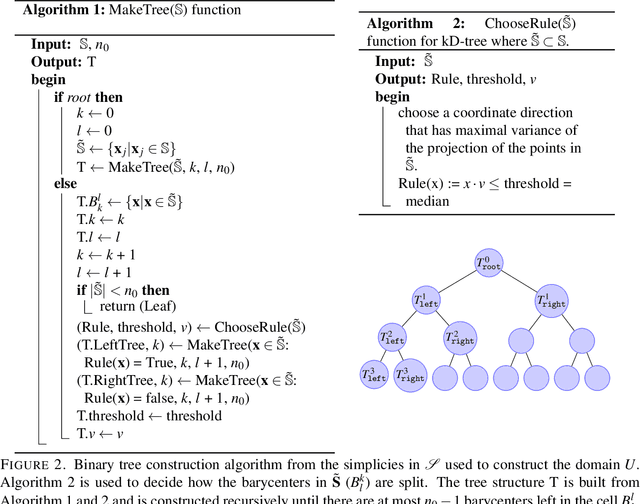
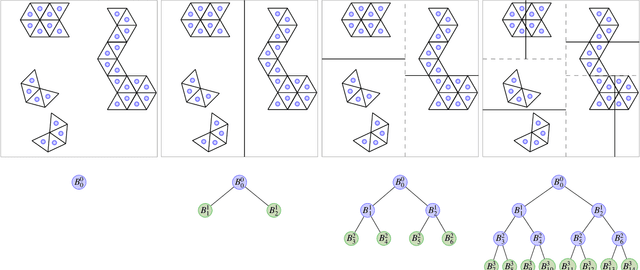
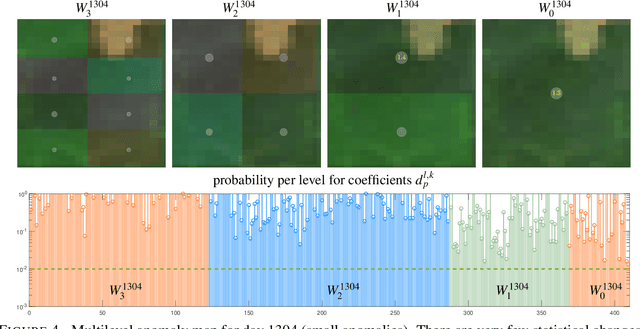
Massive vector field datasets are common in multi-spectral optical and radar sensors and modern multimodal MRI data, among many other areas of application. In this paper we develop a novel stochastic functional analysis approach for detecting anomalies based on the covariance structure of nominal stochastic behavior across a domain with multi-band vector field data. An optimal vector field Karhunen-Loeve (KL) expansion is applied to such random field data. A series of multilevel orthogonal functional subspaces is constructed from the geometry of the domain, adapted from the KL expansion. Detection is achieved by examining the projection of the random field on the multilevel basis. The anomalies can be quantified in suitable normed spaces based on local and global information. In addition, reliable hypothesis tests are formed with controllable distributions that do not require prior assumptions on probability distributions of the data. Only the covariance function is needed, which makes for significantly simpler estimates. Furthermore this approach allows stochastic vector-based fusion of anomalies without any loss of information. The method is applied to the important problem of deforestation and degradation in the Amazon forest. This is a complex non-monotonic process, as forests can degrade and recover. This particular problem is further compounded by the presence of clouds that are hard to remove with current masking algorithms. Using multi-spectral satellite data from Sentinel 2, the multilevel filter is constructed and anomalies are treated as deviations from the initial state of the forest. Forest anomalies are quantified with robust hypothesis tests and distinguished from false variations such as cloud cover. Our approach shows the advantage of using multiple bands of data in a vectorized complex, leading to better anomaly detection beyond the capabilities of scalar-based methods.
Spatio-Temporal U-Net for Cerebral Artery and Vein Segmentation in Digital Subtraction Angiography
Aug 03, 2022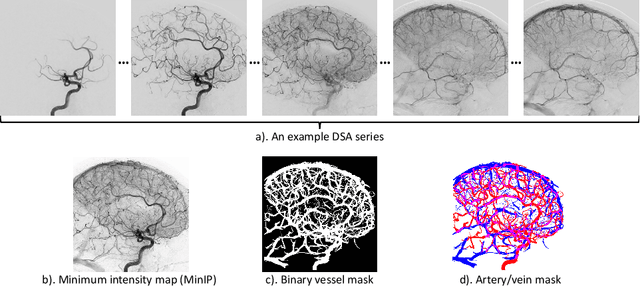
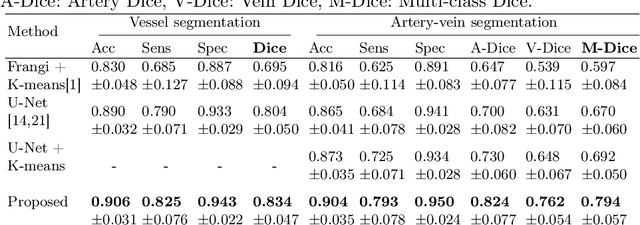
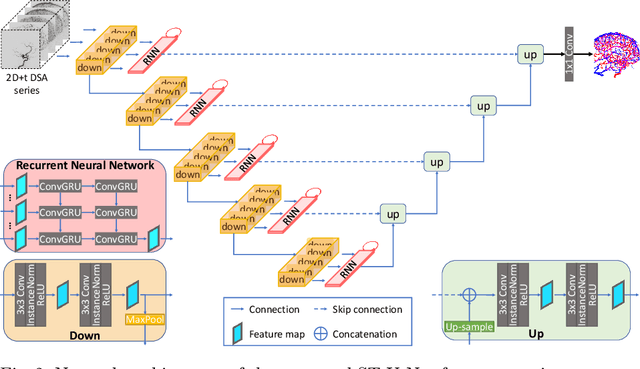
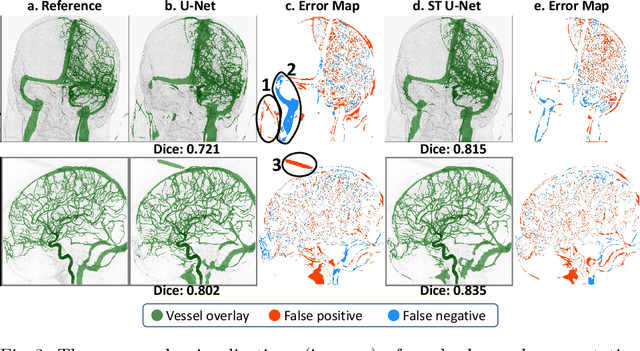
X-ray digital subtraction angiography (DSA) is widely used for vessel and/or flow visualization and interventional guidance during endovascular treatment of patients with a stroke or aneurysm. To assist in peri-operative decision making as well as post-operative prognosis, automatic DSA analysis algorithms are being developed to obtain relevant image-based information. Such analyses include detection of vascular disease, evaluation of perfusion based on time intensity curves (TIC), and quantitative biomarker extraction for automated treatment evaluation in endovascular thrombectomy. Methodologically, such vessel-based analysis tasks may be facilitated by automatic and accurate artery-vein segmentation algorithms. The present work describes to the best of our knowledge the first study that addresses automatic artery-vein segmentation in DSA using deep learning. We propose a novel spatio-temporal U-Net (ST U-Net) architecture which integrates convolutional gated recurrent units (ConvGRU) in the contracting branch of U-Net. The network encodes a 2D+t DSA series of variable length and decodes it into a 2D segmentation image. On a multi-center routinely acquired dataset, the proposed method significantly outperformed U-Net (P<0.001) and traditional Frangi-based K-means clustering (P$<$0.001). Particularly in artery-vein segmentation, ST U-Net achieved a Dice coefficient of 0.794, surpassing the existing state-of-the-art methods by a margin of 12\%-20\%. Code will be made publicly available upon acceptance.
Optimized processing order for 3D hole filling in video sequences using frequency selective extrapolation
Jul 20, 2022
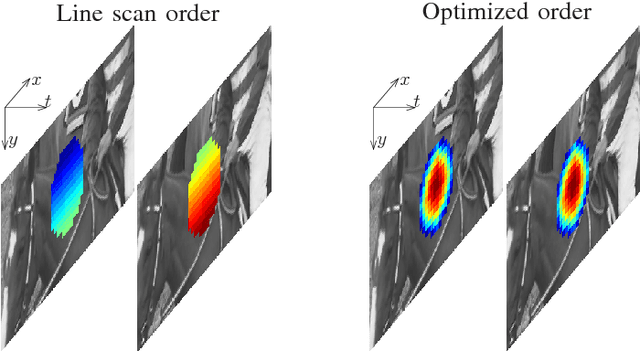

A problem often arising in video communication is the reconstruction of missing or distorted areas in a video sequence. Such holes of unavailable pixels may be caused for example by transmission errors of coded video data or undesired objects like logos. In order to close the holes given neighboring available content, a signal extrapolation has to be performed. The best quality can be achieved, if spatial as well as temporal information is used for the reconstruction. However, the question always is in which order to process the extrapolation to obtain the best result. In this paper, an optimized processing order is introduced for improving the extrapolation quality of Three-dimensional Frequency Selective Extrapolation. Using the proposed optimized order, holes in video sequences can be closed from the outer margin to the center, leading to a higher reconstruction quality, and visually noticeable gains of more than 0.5 dB PSNR are possible.
Paired Cross-Modal Data Augmentation for Fine-Grained Image-to-Text Retrieval
Jul 29, 2022
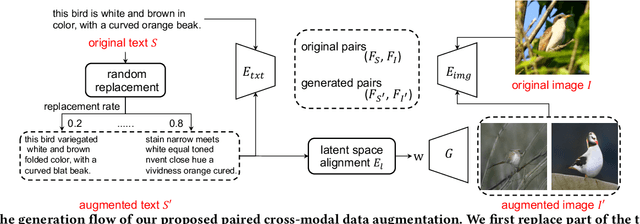
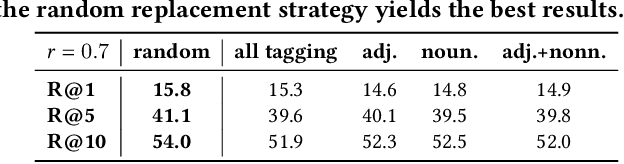
This paper investigates an open research problem of generating text-image pairs to improve the training of fine-grained image-to-text cross-modal retrieval task, and proposes a novel framework for paired data augmentation by uncovering the hidden semantic information of StyleGAN2 model. Specifically, we first train a StyleGAN2 model on the given dataset. We then project the real images back to the latent space of StyleGAN2 to obtain the latent codes. To make the generated images manipulatable, we further introduce a latent space alignment module to learn the alignment between StyleGAN2 latent codes and the corresponding textual caption features. When we do online paired data augmentation, we first generate augmented text through random token replacement, then pass the augmented text into the latent space alignment module to output the latent codes, which are finally fed to StyleGAN2 to generate the augmented images. We evaluate the efficacy of our augmented data approach on two public cross-modal retrieval datasets, in which the promising experimental results demonstrate the augmented text-image pair data can be trained together with the original data to boost the image-to-text cross-modal retrieval performance.
Empirical Bayes approach to Truth Discovery problems
Jun 09, 2022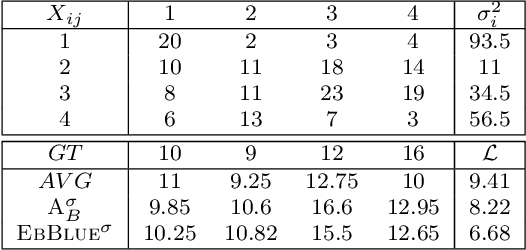
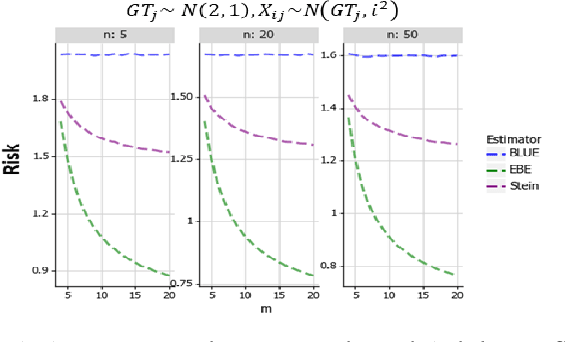
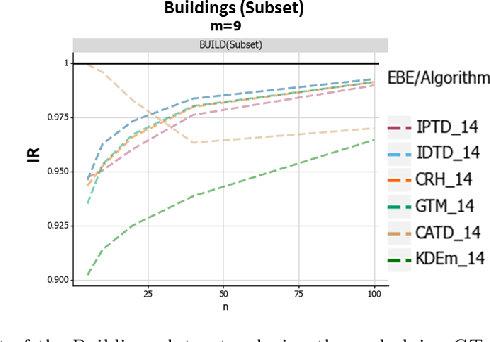
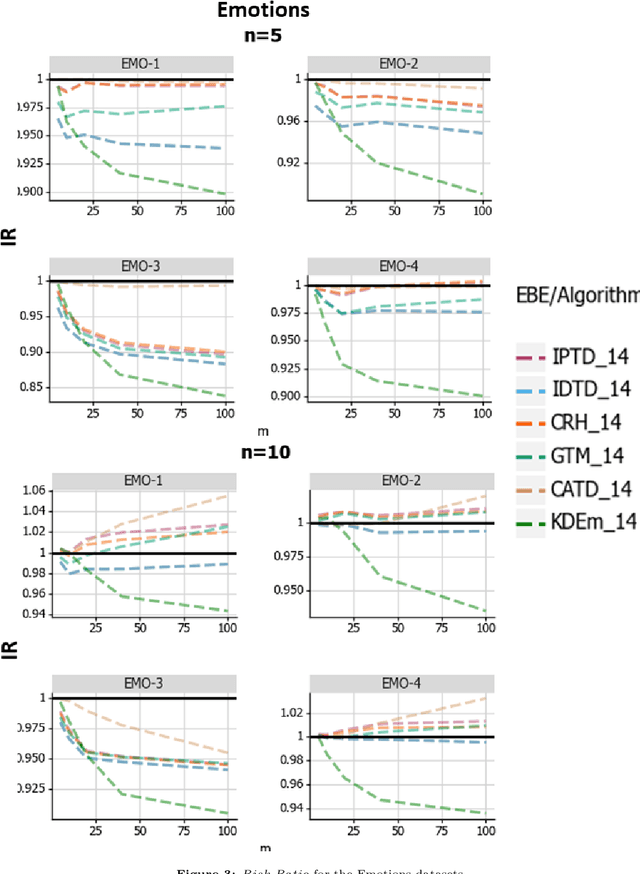
When aggregating information from conflicting sources, one's goal is to find the truth. Most real-value \emph{truth discovery} (TD) algorithms try to achieve this goal by estimating the competence of each source and then aggregating the conflicting information by weighing each source's answer proportionally to her competence. However, each of those algorithms requires more than a single source for such estimation and usually does not consider different estimation methods other than a weighted mean. Therefore, in this work we formulate, prove, and empirically test the conditions for an Empirical Bayes Estimator (EBE) to dominate the weighted mean aggregation. Our main result demonstrates that EBE, under mild conditions, can be used as a second step of any TD algorithm in order to reduce the expected error.
Securing Optimized Code Against Power Side Channels
Jul 06, 2022
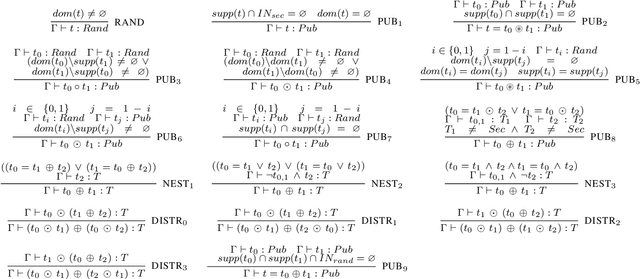


Side-channel attacks impose a serious threat to cryptographic algorithms, including widely employed ones, such as AES and RSA, taking advantage of the algorithm implementation in hardware or software to extract secret information via timing and/or power side-channels. Software masking is a software mitigation approach against power side-channel attacks, aiming at hiding the secret-revealing dependencies from the power footprint of a vulnerable implementation. However, this type of software mitigation often depends on general-purpose compilers, which do not preserve non-functional properties. Moreover, microarchitectural features, such as the memory bus and register reuse, may also reveal secret information. These abstractions are not visible at the high-level implementation of the program. Instead, they are decided at compile time. To remedy these problems, security engineers often sacrifice code efficiency by turning off compiler optimization and/or performing local, post-compilation transformations. This paper proposes SecConCG, a constraint-based compiler approach that generates optimized yet secure code. SecConCG controls the quality of the mitigated program by efficiently searching the best possible low-level implementation according to a processor cost model. In our experiments with ten masked implementations on MIPS32 and ARM Cortex M0, SecConCG speeds up the generated code from 10% to 10x compared to non-optimized secure code at a small overhead of up to 7% compared to non-secure optimized code. For security and compiler researchers, this paper proposes a formal model to generate secure low-level code. For software engineers, SecConCG provides a practical approach to optimize code that preserves security properties.
Measuring Data Leakage in Machine-Learning Models with Fisher Information
Feb 23, 2021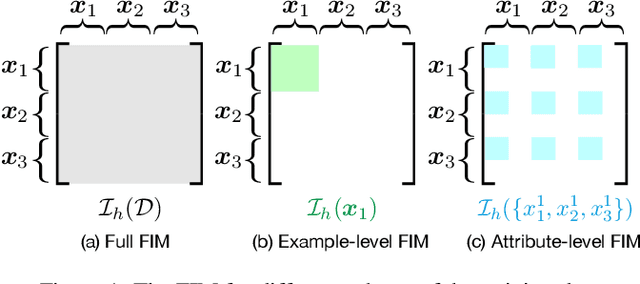
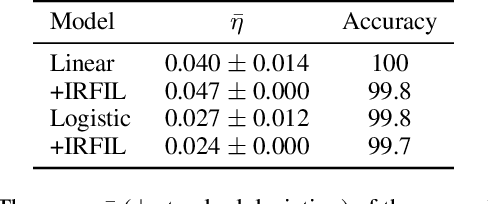
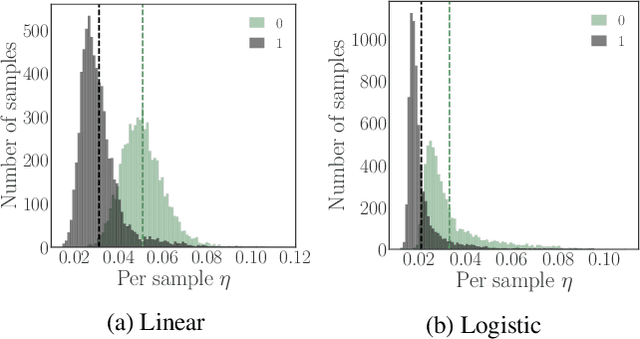

Machine-learning models contain information about the data they were trained on. This information leaks either through the model itself or through predictions made by the model. Consequently, when the training data contains sensitive attributes, assessing the amount of information leakage is paramount. We propose a method to quantify this leakage using the Fisher information of the model about the data. Unlike the worst-case a priori guarantees of differential privacy, Fisher information loss measures leakage with respect to specific examples, attributes, or sub-populations within the dataset. We motivate Fisher information loss through the Cram\'{e}r-Rao bound and delineate the implied threat model. We provide efficient methods to compute Fisher information loss for output-perturbed generalized linear models. Finally, we empirically validate Fisher information loss as a useful measure of information leakage.
Cyclist Trajectory Forecasts by Incorporation of Multi-View Video Information
Jun 30, 2021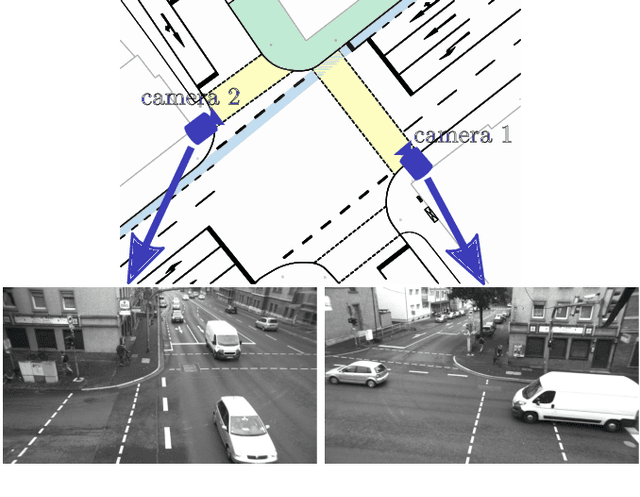

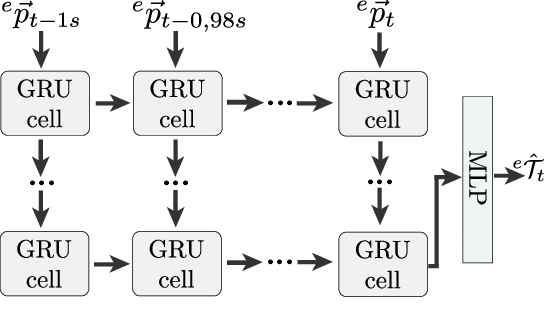
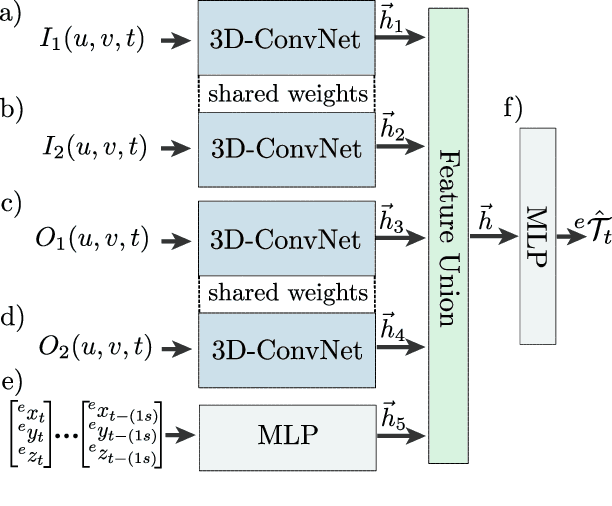
This article presents a novel approach to incorporate visual cues from video-data from a wide-angle stereo camera system mounted at an urban intersection into the forecast of cyclist trajectories. We extract features from image and optical flow (OF) sequences using 3D convolutional neural networks (3D-ConvNet) and combine them with features extracted from the cyclist's past trajectory to forecast future cyclist positions. By the use of additional information, we are able to improve positional accuracy by about 7.5 % for our test dataset and by up to 22 % for specific motion types compared to a method solely based on past trajectories. Furthermore, we compare the use of image sequences to the use of OF sequences as additional information, showing that OF alone leads to significant improvements in positional accuracy. By training and testing our methods using a real-world dataset recorded at a heavily frequented public intersection and evaluating the methods' runtimes, we demonstrate the applicability in real traffic scenarios. Our code and parts of our dataset are made publicly available.
Information Bottleneck-Based Hebbian Learning Rule Naturally Ties Working Memory and Synaptic Updates
Nov 24, 2021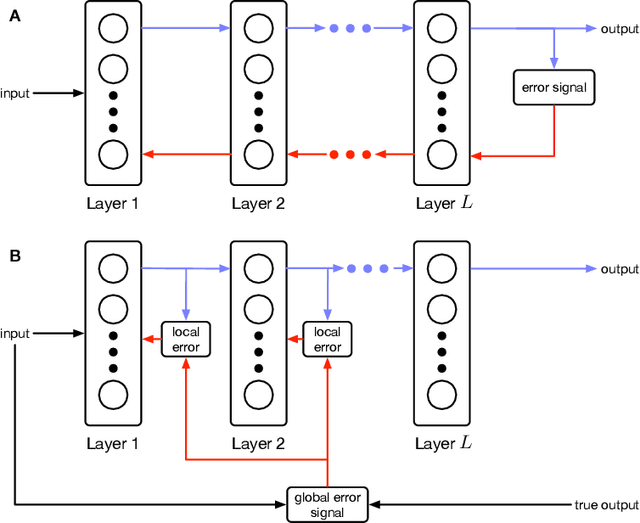
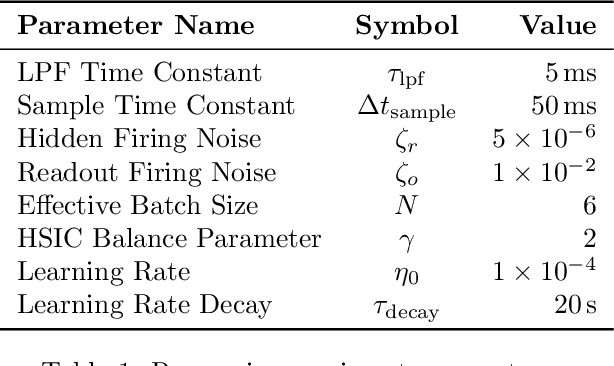
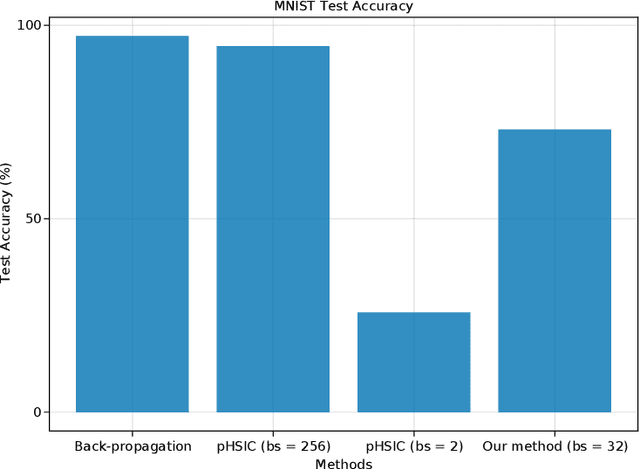
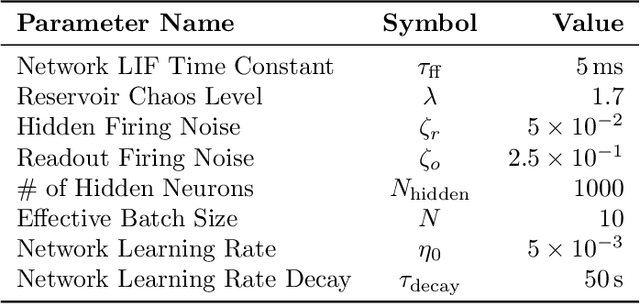
Artificial neural networks have successfully tackled a large variety of problems by training extremely deep networks via back-propagation. A direct application of back-propagation to spiking neural networks contains biologically implausible components, like the weight transport problem or separate inference and learning phases. Various methods address different components individually, but a complete solution remains intangible. Here, we take an alternate approach that avoids back-propagation and its associated issues entirely. Recent work in deep learning proposed independently training each layer of a network via the information bottleneck (IB). Subsequent studies noted that this layer-wise approach circumvents error propagation across layers, leading to a biologically plausible paradigm. Unfortunately, the IB is computed using a batch of samples. The prior work addresses this with a weight update that only uses two samples (the current and previous sample). Our work takes a different approach by decomposing the weight update into a local and global component. The local component is Hebbian and only depends on the current sample. The global component computes a layer-wise modulatory signal that depends on a batch of samples. We show that this modulatory signal can be learned by an auxiliary circuit with working memory (WM) like a reservoir. Thus, we can use batch sizes greater than two, and the batch size determines the required capacity of the WM. To the best of our knowledge, our rule is the first biologically plausible mechanism to directly couple synaptic updates with a WM of the task. We evaluate our rule on synthetic datasets and image classification datasets like MNIST, and we explore the effect of the WM capacity on learning performance. We hope our work is a first-step towards understanding the mechanistic role of memory in learning.