 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Privacy-Aware Adversarial Network in Human Mobility Prediction
Aug 09, 2022
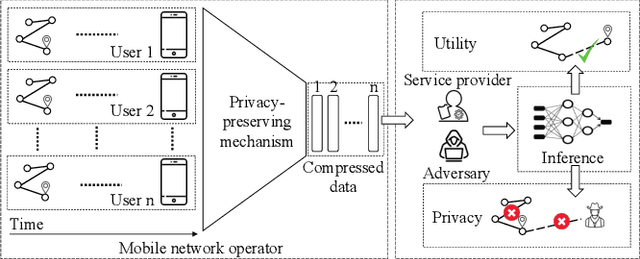
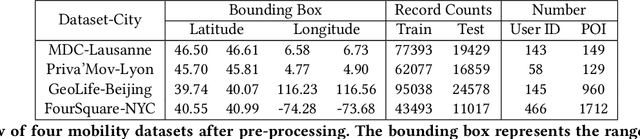
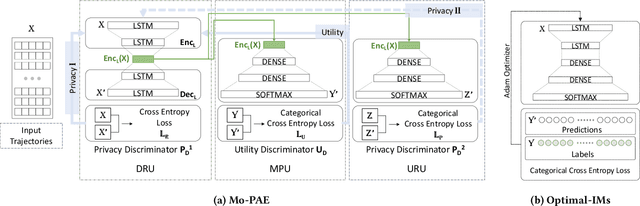
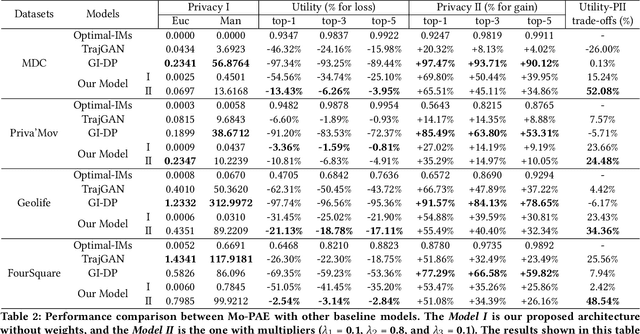
As mobile devices and location-based services are increasingly developed in different smart city scenarios and applications, many unexpected privacy leakages have arisen due to geolocated data collection and sharing. User re-identification and other sensitive inferences are major privacy threats when geolocated data are shared with cloud-assisted applications. Significantly, four spatio-temporal points are enough to uniquely identify 95\% of the individuals, which exacerbates personal information leakages. To tackle malicious purposes such as user re-identification, we propose an LSTM-based adversarial mechanism with representation learning to attain a privacy-preserving feature representation of the original geolocated data (i.e., mobility data) for a sharing purpose. These representations aim to maximally reduce the chance of user re-identification and full data reconstruction with a minimal utility budget (i.e., loss). We train the mechanism by quantifying privacy-utility trade-off of mobility datasets in terms of trajectory reconstruction risk, user re-identification risk, and mobility predictability. We report an exploratory analysis that enables the user to assess this trade-off with a specific loss function and its weight parameters. The extensive comparison results on four representative mobility datasets demonstrate the superiority of our proposed architecture in mobility privacy protection and the efficiency of the proposed privacy-preserving features extractor. We show that the privacy of mobility traces attains decent protection at the cost of marginal mobility utility. Our results also show that by exploring the Pareto optimal setting, we can simultaneously increase both privacy (45%) and utility (32%).
Multiple RISs Assisted Cell-Free Networks With Two-timescale CSI: Performance Analysis and System Design
Aug 12, 2022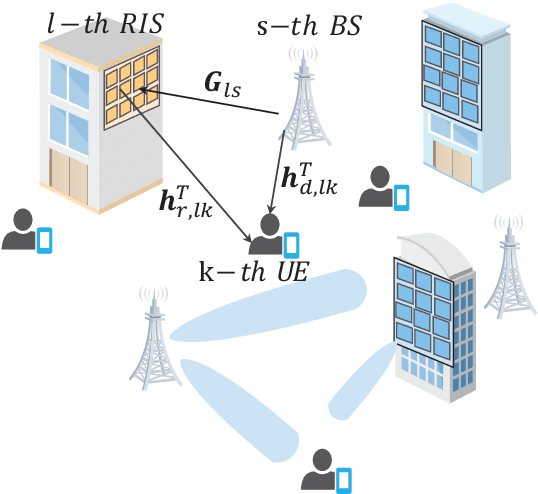
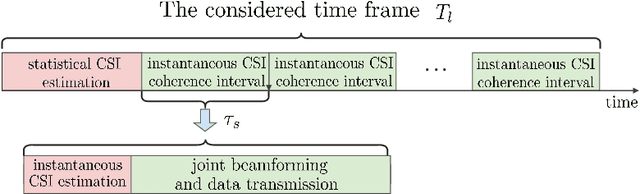
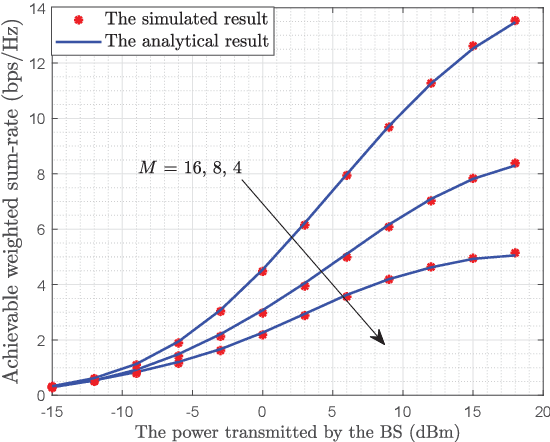
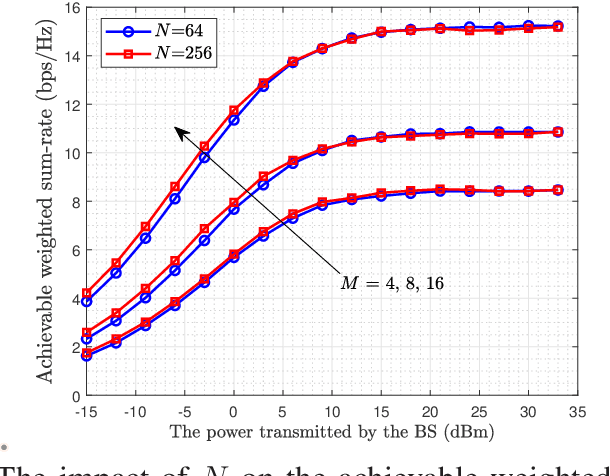
Reconfigurable intelligent surface (RIS) can be employed in a cell-free system to create favorable propagation conditions from base stations (BSs) to users via configurable elements. However, prior works on RIS-aided cell-free system designs mainly rely on the instantaneous channel state information (CSI), which may incur substantial overhead due to extremely high dimensions of estimated channels. To mitigate this issue, a low-complexity algorithm via the two-timescale transmission protocol is proposed in this paper, where the joint beamforming at BSs and RISs is facilitated via alternating optimization framework to maximize the average weighted sum-rate. Specifically, the passive beamformers at RISs are optimized through the statistical CSI, and the transmit beamformers at BSs are based on the instantaneous CSI of effective channels. In this manner, a closed-form expression for the achievable weighted sum-rate is derived, which enables the evaluation of the impact of key parameters on system performance. To gain more insights, a special case without line-of-sight (LoS) components is further investigated, where a power gain on the order of $\mathcal{O}(M)$ is achieved, with $M$ being the BS antennas number. Numerical results validate the tightness of our derived analytical expression and show the fast convergence of the proposed algorithm. Findings illustrate that the performance of the proposed algorithm with two-timescale CSI is comparable to that with instantaneous CSI in low or moderate SNR regime. The impact of key system parameters such as the number of RIS elements, CSI settings and Rician factor is also evaluated. Moreover, the remarkable advantages from the adoption of the cell-free paradigm and the deployment of RISs are demonstrated intuitively.
Neural Posterior Estimation with Differentiable Simulators
Jul 12, 2022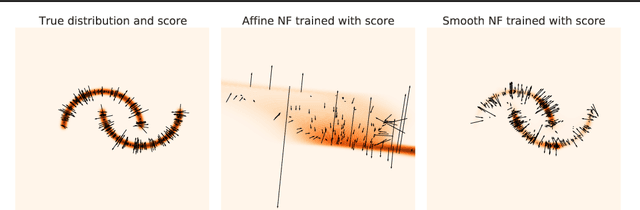
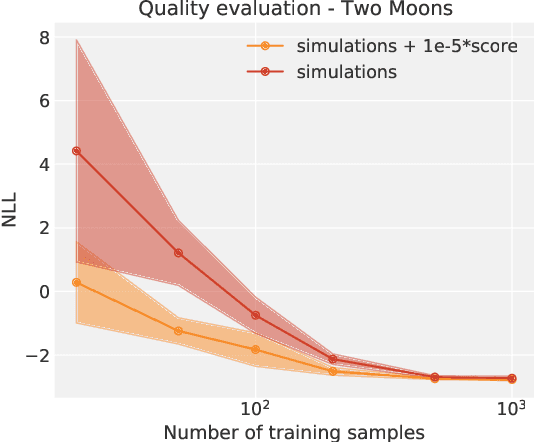
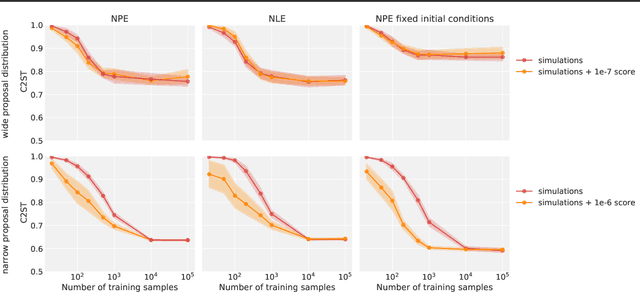
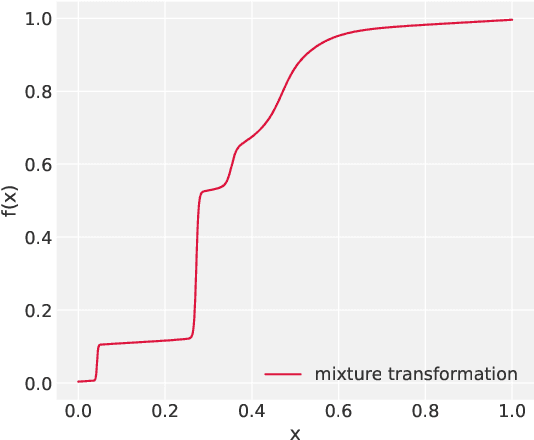
Simulation-Based Inference (SBI) is a promising Bayesian inference framework that alleviates the need for analytic likelihoods to estimate posterior distributions. Recent advances using neural density estimators in SBI algorithms have demonstrated the ability to achieve high-fidelity posteriors, at the expense of a large number of simulations ; which makes their application potentially very time-consuming when using complex physical simulations. In this work we focus on boosting the sample-efficiency of posterior density estimation using the gradients of the simulator. We present a new method to perform Neural Posterior Estimation (NPE) with a differentiable simulator. We demonstrate how gradient information helps constrain the shape of the posterior and improves sample-efficiency.
A Survey on Leveraging Pre-trained Generative Adversarial Networks for Image Editing and Restoration
Jul 21, 2022

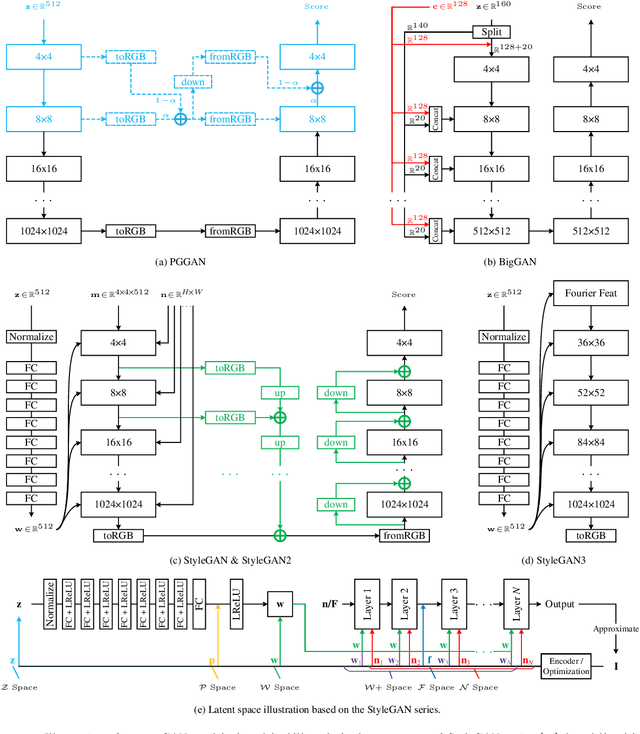

Generative adversarial networks (GANs) have drawn enormous attention due to the simple yet effective training mechanism and superior image generation quality. With the ability to generate photo-realistic high-resolution (e.g., $1024\times1024$) images, recent GAN models have greatly narrowed the gaps between the generated images and the real ones. Therefore, many recent works show emerging interest to take advantage of pre-trained GAN models by exploiting the well-disentangled latent space and the learned GAN priors. In this paper, we briefly review recent progress on leveraging pre-trained large-scale GAN models from three aspects, i.e., 1) the training of large-scale generative adversarial networks, 2) exploring and understanding the pre-trained GAN models, and 3) leveraging these models for subsequent tasks like image restoration and editing. More information about relevant methods and repositories can be found at https://github.com/csmliu/pretrained-GANs.
Maximum Correntropy Value Decomposition for Multi-agent Deep Reinforcemen Learning
Aug 07, 2022



We explore value decomposition solutions for multi-agent deep reinforcement learning in the popular paradigm of centralized training with decentralized execution(CTDE). As the recognized best solution to CTDE, Weighted QMIX is cutting-edge on StarCraft Multi-agent Challenge (SMAC), with a weighting scheme implemented on QMIX to place more emphasis on the optimal joint actions. However, the fixed weight requires manual tuning according to the application scenarios, which painfully prevents Weighted QMIX from being used in broader engineering applications. In this paper, we first demonstrate the flaw of Weighted QMIX using an ordinary One-Step Matrix Game (OMG), that no matter how the weight is chosen, Weighted QMIX struggles to deal with non-monotonic value decomposition problems with a large variance of reward distributions. Then we characterize the problem of value decomposition as an Underfitting One-edged Robust Regression problem and make the first attempt to give a solution to the value decomposition problem from the perspective of information-theoretical learning. We introduce the Maximum Correntropy Criterion (MCC) as a cost function to dynamically adapt the weight to eliminate the effects of minimum in reward distributions. We simplify the implementation and propose a new algorithm called MCVD. A preliminary experiment conducted on OMG shows that MCVD could deal with non-monotonic value decomposition problems with a large tolerance of kernel bandwidth selection. Further experiments are carried out on Cooperative-Navigation and multiple SMAC scenarios, where MCVD exhibits unprecedented ease of implementation, broad applicability, and stability.
Symmetric Network with Spatial Relationship Modeling for Natural Language-based Vehicle Retrieval
Jun 22, 2022


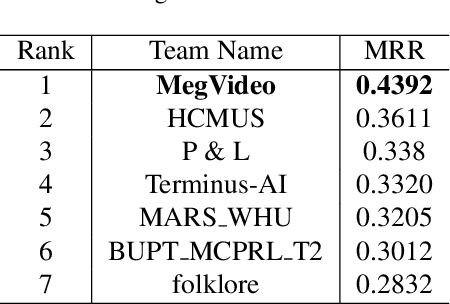
Natural language (NL) based vehicle retrieval aims to search specific vehicle given text description. Different from the image-based vehicle retrieval, NL-based vehicle retrieval requires considering not only vehicle appearance, but also surrounding environment and temporal relations. In this paper, we propose a Symmetric Network with Spatial Relationship Modeling (SSM) method for NL-based vehicle retrieval. Specifically, we design a symmetric network to learn the unified cross-modal representations between text descriptions and vehicle images, where vehicle appearance details and vehicle trajectory global information are preserved. Besides, to make better use of location information, we propose a spatial relationship modeling methods to take surrounding environment and mutual relationship between vehicles into consideration. The qualitative and quantitative experiments verify the effectiveness of the proposed method. We achieve 43.92% MRR accuracy on the test set of the 6th AI City Challenge on natural language-based vehicle retrieval track, yielding the 1st place among all valid submissions on the public leaderboard. The code is available at https://github.com/hbchen121/AICITY2022_Track2_SSM.
* 8 pages, 3 figures, publised to CVPRW
Nondestructive Quality Control in Powder Metallurgy using Hyperspectral Imaging
Jul 26, 2022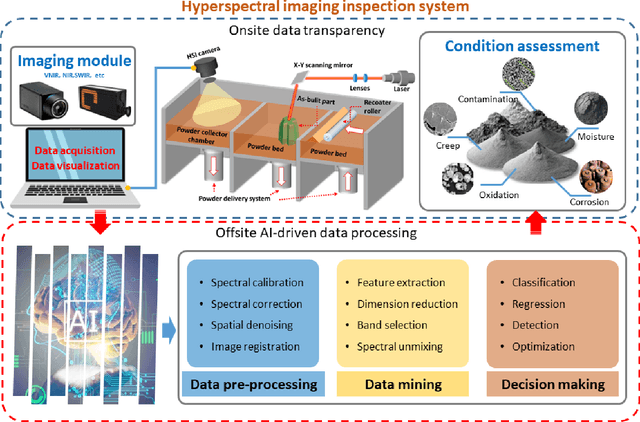


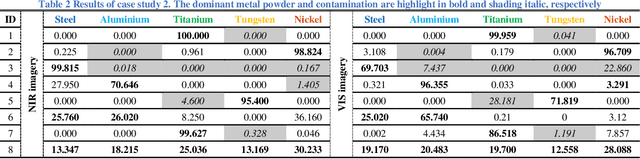
Measuring the purity in the metal powder is critical for preserving the quality of additive manufacturing products. Contamination is one of the most headache problems which can be caused by multiple reasons and lead to the as-built components cracking and malfunctions. Existing methods for metallurgical condition assessment are mostly time-consuming and mainly focus on the physical integrity of structure rather than material composition. Through capturing spectral data from a wide frequency range along with the spatial information, hyperspectral imaging (HSI) can detect minor differences in terms of temperature, moisture and chemical composition. Therefore, HSI can provide a unique way to tackle this challenge. In this paper, with the use of a near-infrared HSI camera, applications of HSI for the non-destructive inspection of metal powders are introduced. Technical assumptions and solutions on three step-by-step case studies are presented in detail, including powder characterization, contamination detection, and band selection analysis. Experimental results have fully demonstrated the great potential of HSI and related AI techniques for NDT of powder metallurgy, especially the potential to satisfy the industrial manufacturing environment.
Association Between Neighborhood Factors and Adult Obesity in Shelby County, Tennessee: Geospatial Machine Learning Approach
Aug 09, 2022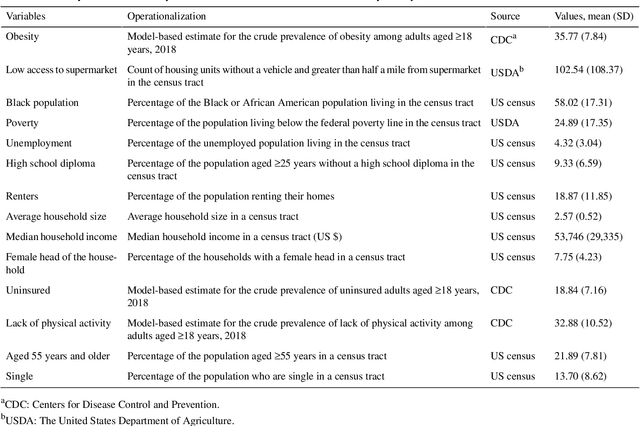
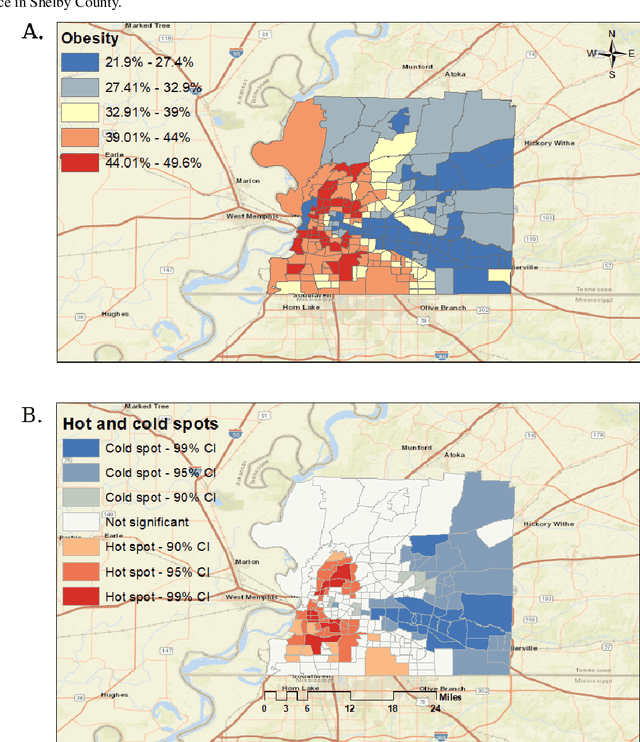

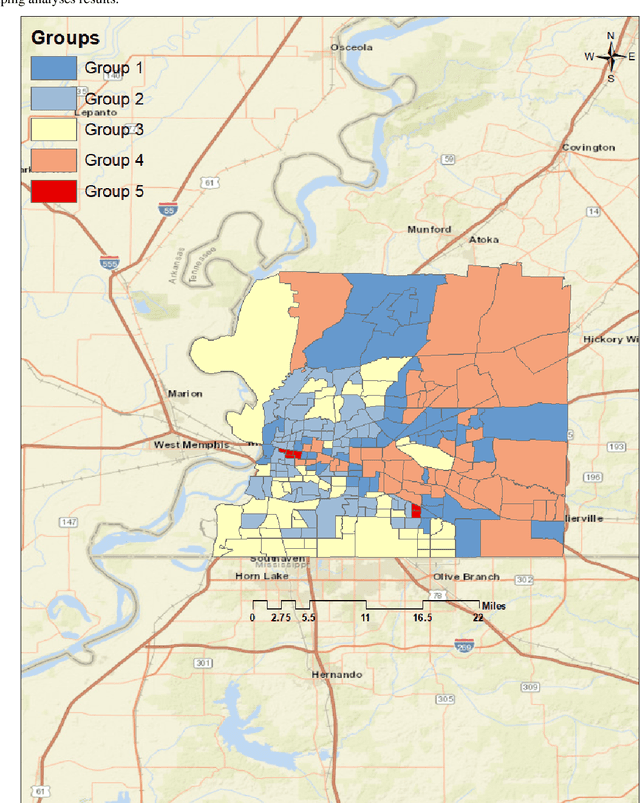
Obesity is a global epidemic causing at least 2.8 million deaths per year. This complex disease is associated with significant socioeconomic burden, reduced work productivity, unemployment, and other social determinants of Health (SDoH) disparities. Objective: The objective of this study was to investigate the effects of SDoH on obesity prevalence among adults in Shelby County, Tennessee, USA using a geospatial machine-learning approach. Obesity prevalence was obtained from publicly available CDC 500 cities database while SDoH indicators were extracted from the U.S. Census and USDA. We examined the geographic distributions of obesity prevalence patterns using Getis-Ord Gi* statistics and calibrated multiple models to study the association between SDoH and adult obesity. Also, unsupervised machine learning was used to conduct grouping analysis to investigate the distribution of obesity prevalence and associated SDoH indicators. Results depicted a high percentage of neighborhoods experiencing high adult obesity prevalence within Shelby County. In the census tract, median household income, as well as the percentage of individuals who were black, home renters, living below the poverty level, fifty-five years or older, unmarried, and uninsured, had a significant association with adult obesity prevalence. The grouping analysis revealed disparities in obesity prevalence amongst disadvantaged neighborhoods. More research is needed that examines linkages between geographical location, SDoH, and chronic diseases. These findings, which depict a significantly higher prevalence of obesity within disadvantaged neighborhoods, and other geospatial information can be leveraged to offer valuable insights informing health decision-making and interventions that mitigate risk factors for increasing obesity prevalence.
* 12 Pages, 3 Figures, 5 Tables
NLOS Ranging Mitigation with Neural Network Model for UWB Localization
Jun 22, 2022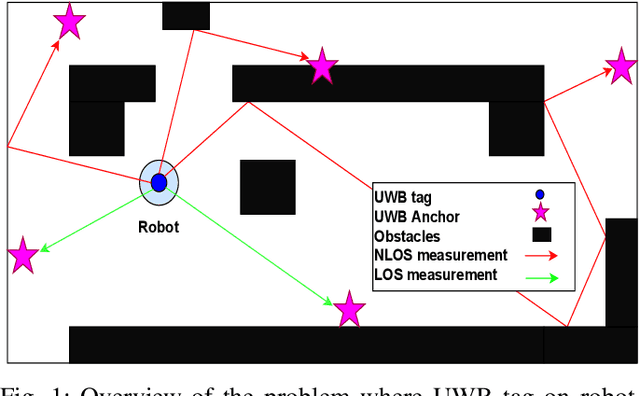
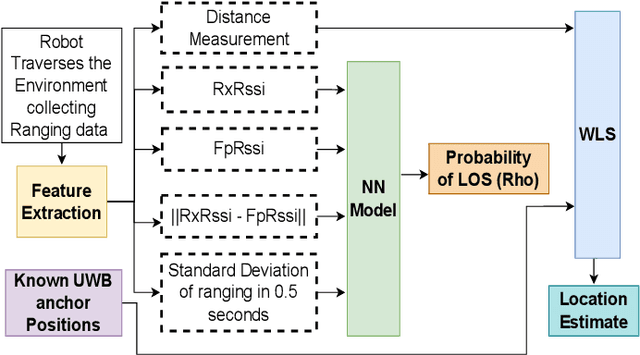
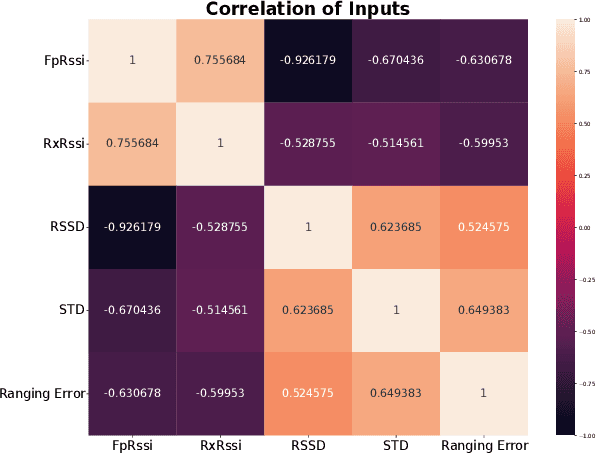
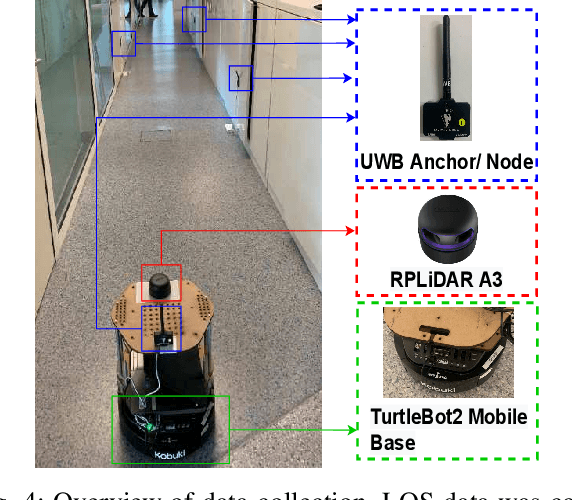
Localization of robots is vital for navigation and path planning, such as in cases where a map of the environment is needed. Ultra-Wideband (UWB) for indoor location systems has been gaining popularity over the years with the introduction of low-cost UWB modules providing centimetre-level accuracy. However, in the presence of obstacles in the environment, Non-Line-Of-Sight (NLOS) measurements from the UWB will produce inaccurate results. As low-cost UWB devices do not provide channel information, we propose an approach to decide if a measurement is within Line-Of-Sight (LOS) or not by using some signal strength information provided by low-cost UWB modules through a Neural Network (NN) model. The result of this model is the probability of a ranging measurement being LOS which was used for localization through the Weighted-Least-Square (WLS) method. Our approach improves localization accuracy by 16.93% on the lobby testing data and 27.97% on the corridor testing data using the NN model trained with all extracted inputs from the office training data.
Contrastive Graph Multimodal Model for Text Classification in Videos
Jun 06, 2022
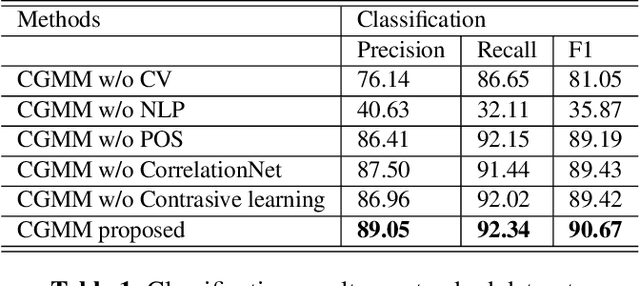
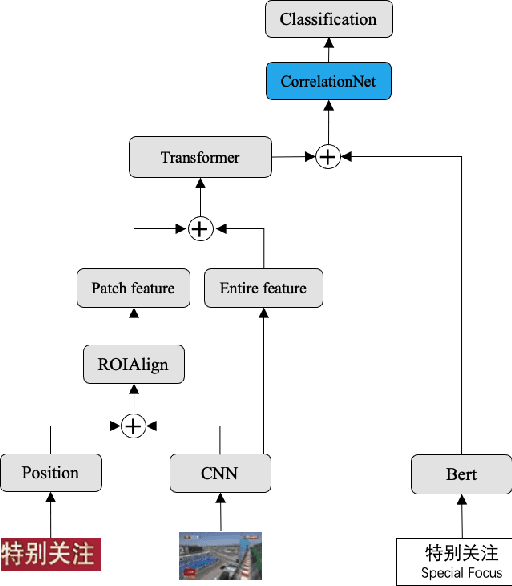
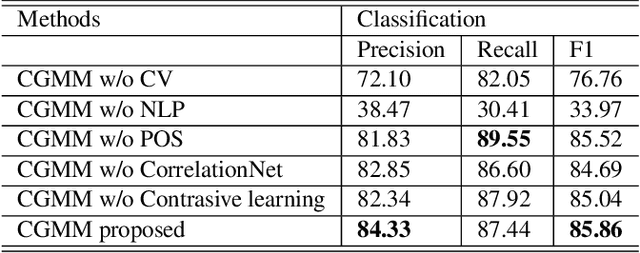
The extraction of text information in videos serves as a critical step towards semantic understanding of videos. It usually involved in two steps: (1) text recognition and (2) text classification. To localize texts in videos, we can resort to large numbers of text recognition methods based on OCR technology. However, to our knowledge, there is no existing work focused on the second step of video text classification, which will limit the guidance to downstream tasks such as video indexing and browsing. In this paper, we are the first to address this new task of video text classification by fusing multimodal information to deal with the challenging scenario where different types of video texts may be confused with various colors, unknown fonts and complex layouts. In addition, we tailor a specific module called CorrelationNet to reinforce feature representation by explicitly extracting layout information. Furthermore, contrastive learning is utilized to explore inherent connections between samples using plentiful unlabeled videos. Finally, we construct a new well-defined industrial dataset from the news domain, called TI-News, which is dedicated to building and evaluating video text recognition and classification applications. Extensive experiments on TI-News demonstrate the effectiveness of our method.