 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Data-Driven Representations for Testing Independence: Modeling, Analysis and Connection with Mutual Information Estimation
Oct 27, 2021
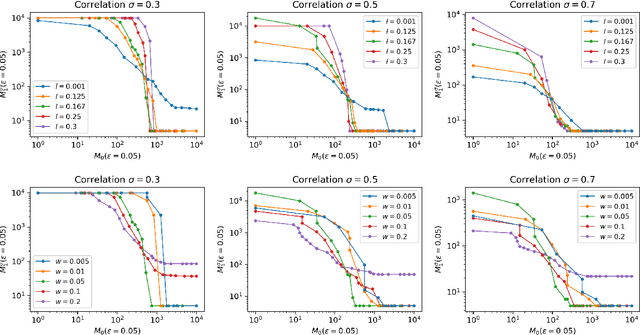
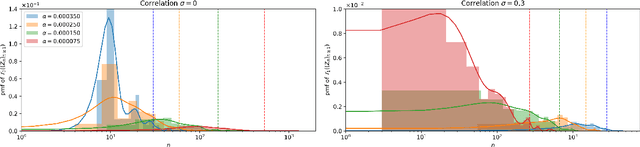
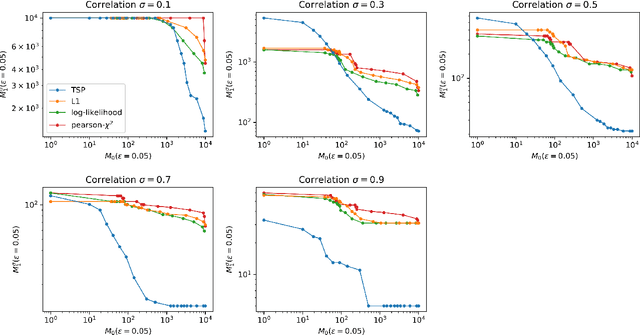
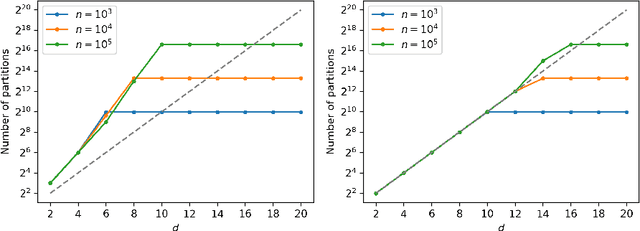
This work addresses testing the independence of two continuous and finite-dimensional random variables from the design of a data-driven partition. The empirical log-likelihood statistic is adopted to approximate the sufficient statistics of an oracle test against independence (that knows the two hypotheses). It is shown that approximating the sufficient statistics of the oracle test offers a learning criterion for designing a data-driven partition that connects with the problem of mutual information estimation. Applying these ideas in the context of a data-dependent tree-structured partition (TSP), we derive conditions on the TSP's parameters to achieve a strongly consistent distribution-free test of independence over the family of probabilities equipped with a density. Complementing this result, we present finite-length results that show our TSP scheme's capacity to detect the scenario of independence structurally with the data-driven partition as well as new sampling complexity bounds for this detection. Finally, some experimental analyses provide evidence regarding our scheme's advantage for testing independence compared with some strategies that do not use data-driven representations.
Deep Squared Euclidean Approximation to the Levenshtein Distance for DNA Storage
Jul 11, 2022
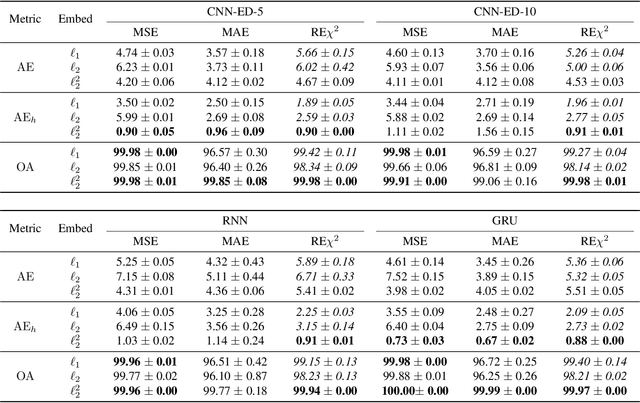
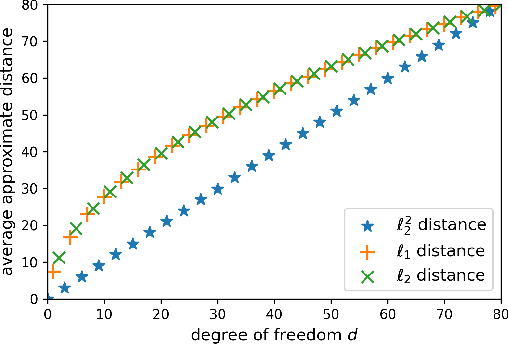
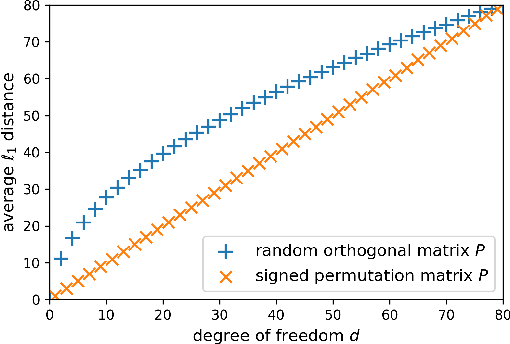
Storing information in DNA molecules is of great interest because of its advantages in longevity, high storage density, and low maintenance cost. A key step in the DNA storage pipeline is to efficiently cluster the retrieved DNA sequences according to their similarities. Levenshtein distance is the most suitable metric on the similarity between two DNA sequences, but it is inferior in terms of computational complexity and less compatible with mature clustering algorithms. In this work, we propose a novel deep squared Euclidean embedding for DNA sequences using Siamese neural network, squared Euclidean embedding, and chi-squared regression. The Levenshtein distance is approximated by the squared Euclidean distance between the embedding vectors, which is fast calculated and clustering algorithm friendly. The proposed approach is analyzed theoretically and experimentally. The results show that the proposed embedding is efficient and robust.
Spatio-Temporal Deformable Attention Network for Video Deblurring
Jul 22, 2022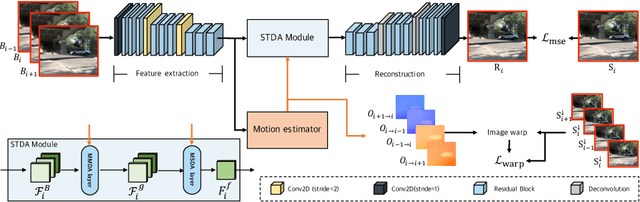

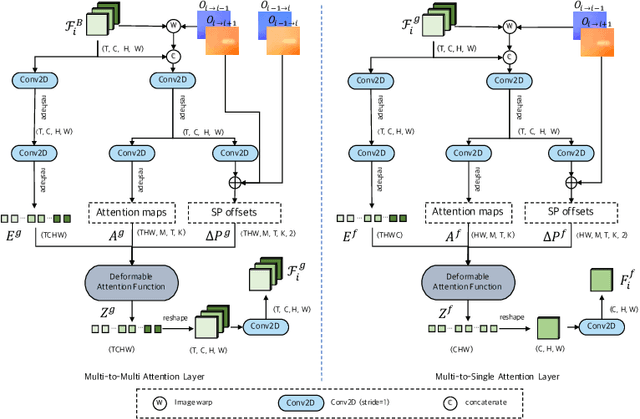

The key success factor of the video deblurring methods is to compensate for the blurry pixels of the mid-frame with the sharp pixels of the adjacent video frames. Therefore, mainstream methods align the adjacent frames based on the estimated optical flows and fuse the alignment frames for restoration. However, these methods sometimes generate unsatisfactory results because they rarely consider the blur levels of pixels, which may introduce blurry pixels from video frames. Actually, not all the pixels in the video frames are sharp and beneficial for deblurring. To address this problem, we propose the spatio-temporal deformable attention network (STDANet) for video delurring, which extracts the information of sharp pixels by considering the pixel-wise blur levels of the video frames. Specifically, STDANet is an encoder-decoder network combined with the motion estimator and spatio-temporal deformable attention (STDA) module, where motion estimator predicts coarse optical flows that are used as base offsets to find the corresponding sharp pixels in STDA module. Experimental results indicate that the proposed STDANet performs favorably against state-of-the-art methods on the GoPro, DVD, and BSD datasets.
Pose Uncertainty Aware Movement Synchrony Estimation via Spatial-Temporal Graph Transformer
Aug 01, 2022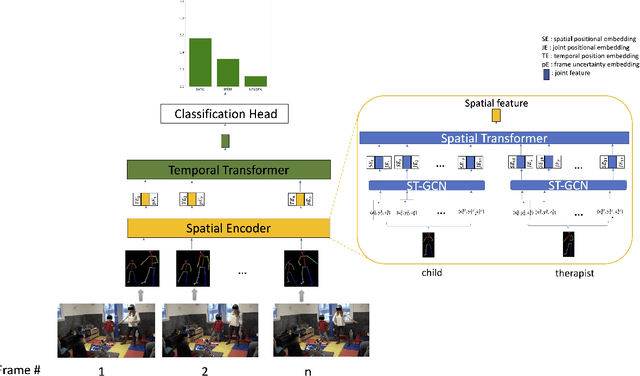
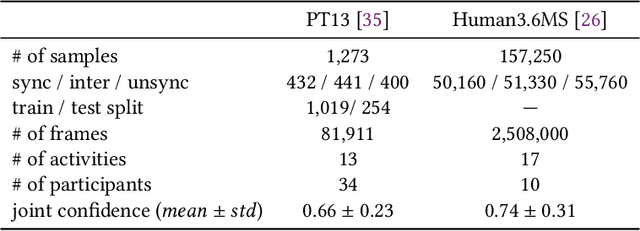
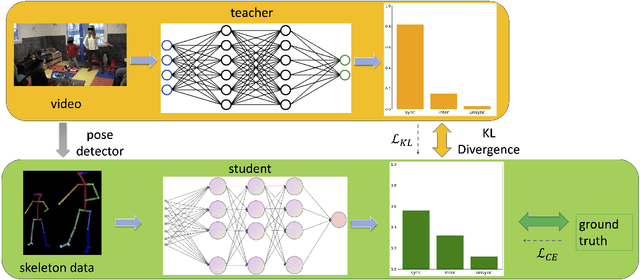
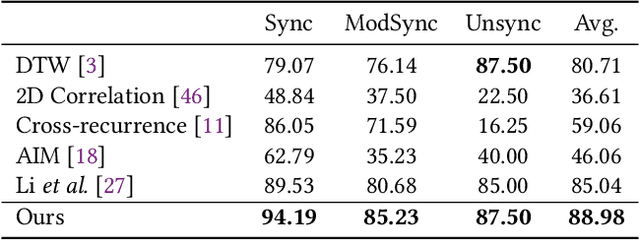
Movement synchrony reflects the coordination of body movements between interacting dyads. The estimation of movement synchrony has been automated by powerful deep learning models such as transformer networks. However, instead of designing a specialized network for movement synchrony estimation, previous transformer-based works broadly adopted architectures from other tasks such as human activity recognition. Therefore, this paper proposed a skeleton-based graph transformer for movement synchrony estimation. The proposed model applied ST-GCN, a spatial-temporal graph convolutional neural network for skeleton feature extraction, followed by a spatial transformer for spatial feature generation. The spatial transformer is guided by a uniquely designed joint position embedding shared between the same joints of interacting individuals. Besides, we incorporated a temporal similarity matrix in temporal attention computation considering the periodic intrinsic of body movements. In addition, the confidence score associated with each joint reflects the uncertainty of a pose, while previous works on movement synchrony estimation have not sufficiently emphasized this point. Since transformer networks demand a significant amount of data to train, we constructed a dataset for movement synchrony estimation using Human3.6M, a benchmark dataset for human activity recognition, and pretrained our model on it using contrastive learning. We further applied knowledge distillation to alleviate information loss introduced by pose detector failure in a privacy-preserving way. We compared our method with representative approaches on PT13, a dataset collected from autism therapy interventions. Our method achieved an overall accuracy of 88.98% and surpassed its counterparts by a wide margin while maintaining data privacy.
GPPF: A General Perception Pre-training Framework via Sparsely Activated Multi-Task Learning
Aug 04, 2022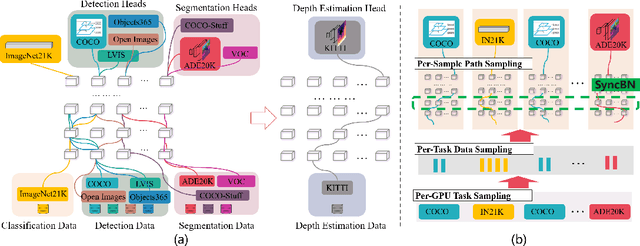
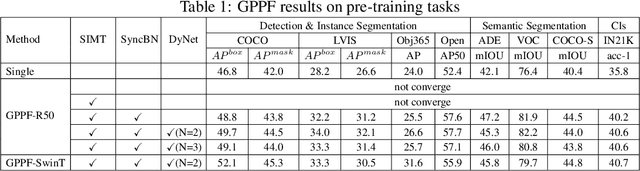
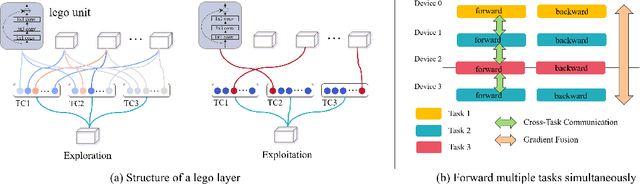
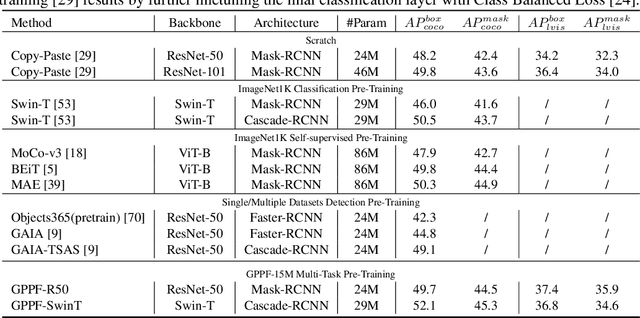
Pre-training over mixtured multi-task, multi-domain, and multi-modal data remains an open challenge in vision perception pre-training. In this paper, we propose GPPF, a General Perception Pre-training Framework, that pre-trains a task-level dynamic network, which is composed by knowledge "legos" in each layers, on labeled multi-task and multi-domain datasets. By inspecting humans' innate ability to learn in complex environment, we recognize and transfer three critical elements to deep networks: (1) simultaneous exposure to diverse cross-task and cross-domain information in each batch. (2) partitioned knowledge storage in separate lego units driven by knowledge sharing. (3) sparse activation of a subset of lego units for both pre-training and downstream tasks. Noteworthy, the joint training of disparate vision tasks is non-trivial due to their differences in input shapes, loss functions, output formats, data distributions, etc. Therefore, we innovatively develop a plug-and-play multi-task training algorithm, which supports Single Iteration Multiple Tasks (SIMT) concurrently training. SIMT lays the foundation of pre-training with large-scale multi-task multi-domain datasets and is proved essential for stable training in our GPPF experiments. Excitingly, the exhaustive experiments show that, our GPPF-R50 model achieves significant improvements of 2.5-5.8 over a strong baseline of the 8 pre-training tasks in GPPF-15M and harvests a range of SOTAs over the 22 downstream tasks with similar computation budgets. We also validate the generalization ability of GPPF to SOTA vision transformers with consistent improvements. These solid experimental results fully prove the effective knowledge learning, storing, sharing, and transfer provided by our novel GPPF framework.
Representation Gap in Deep Reinforcement Learning
May 29, 2022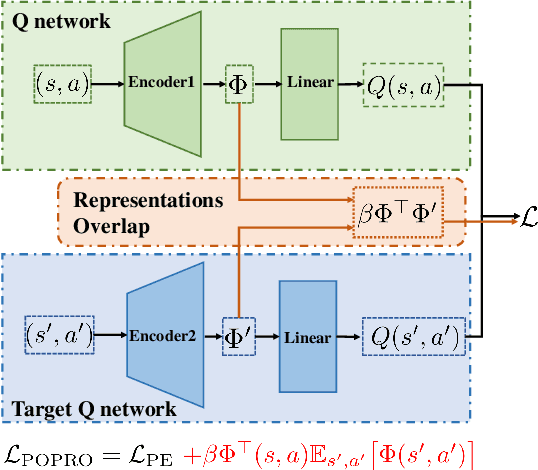
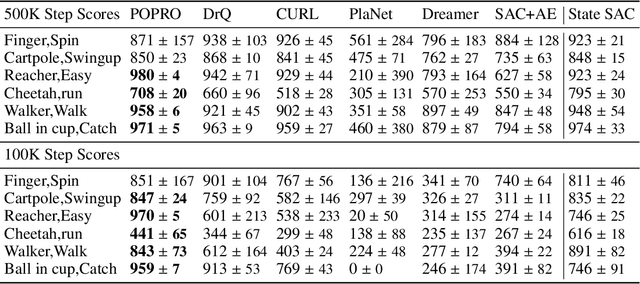
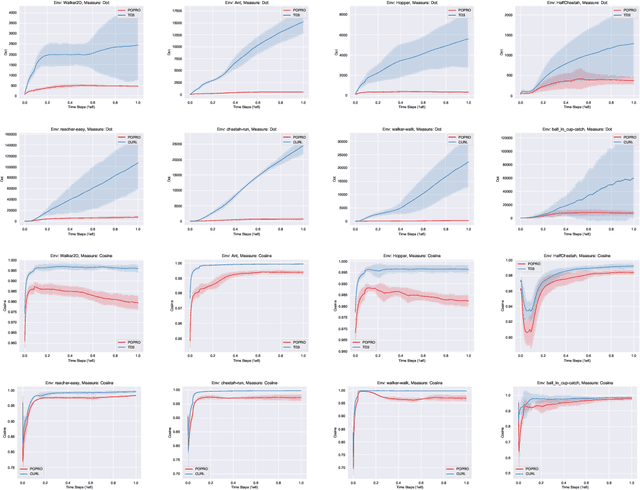
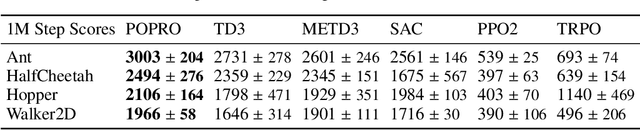
Deep reinforcement learning gives the promise that an agent learns good policy from high-dimensional information. Whereas representation learning removes irrelevant and redundant information and retains pertinent information. We consider the representation capacity of action value function and theoretically reveal its inherent property, \textit{representation gap} with its target action value function. This representation gap is favorable. However, through illustrative experiments, we show that the representation of action value function grows similarly compared with its target value function, i.e. the undesirable inactivity of the representation gap (\textit{representation overlap}). Representation overlap results in a loss of representation capacity, which further leads to sub-optimal learning performance. To activate the representation gap, we propose a simple but effective framework \underline{P}olicy \underline{O}ptimization from \underline{P}reventing \underline{R}epresentation \underline{O}verlaps (POPRO), which regularizes the policy evaluation phase through differing the representation of action value function from its target. We also provide the convergence rate guarantee of POPRO. We evaluate POPRO on gym continuous control suites. The empirical results show that POPRO using pixel inputs outperforms or parallels the sample-efficiency of methods that use state-based features.
Robust Landmark-based Stent Tracking in X-ray Fluoroscopy
Jul 22, 2022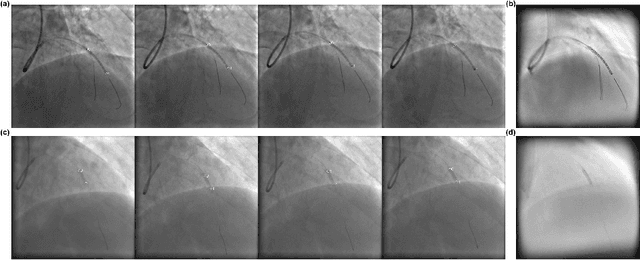
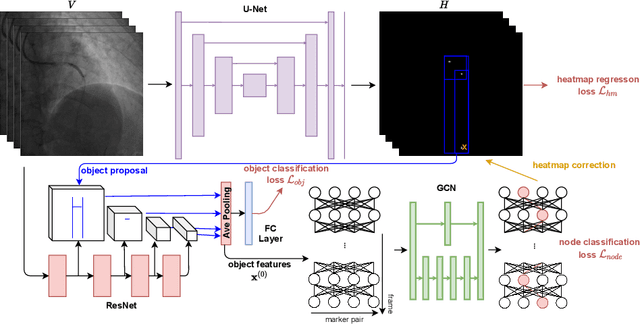
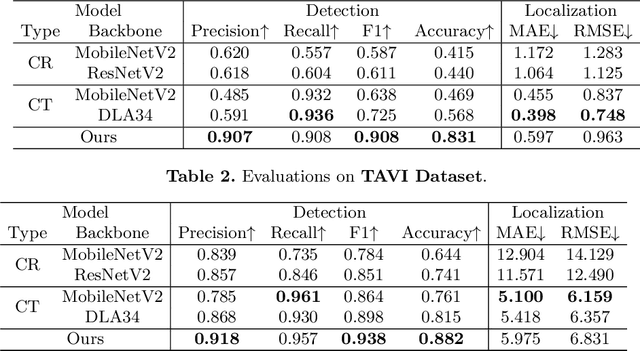
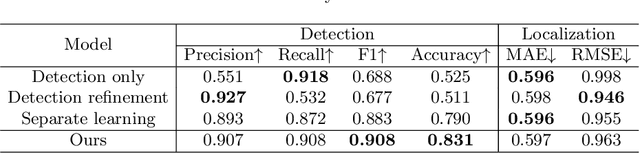
In clinical procedures of angioplasty (i.e., open clogged coronary arteries), devices such as balloons and stents need to be placed and expanded in arteries under the guidance of X-ray fluoroscopy. Due to the limitation of X-ray dose, the resulting images are often noisy. To check the correct placement of these devices, typically multiple motion-compensated frames are averaged to enhance the view. Therefore, device tracking is a necessary procedure for this purpose. Even though angioplasty devices are designed to have radiopaque markers for the ease of tracking, current methods struggle to deliver satisfactory results due to the small marker size and complex scenes in angioplasty. In this paper, we propose an end-to-end deep learning framework for single stent tracking, which consists of three hierarchical modules: U-Net based landmark detection, ResNet based stent proposal and feature extraction, and graph convolutional neural network (GCN) based stent tracking that temporally aggregates both spatial information and appearance features. The experiments show that our method performs significantly better in detection compared with the state-of-the-art point-based tracking models. In addition, its fast inference speed satisfies clinical requirements.
Towards Complex Document Understanding By Discrete Reasoning
Jul 25, 2022
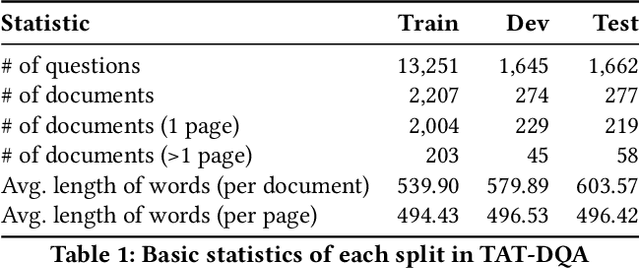
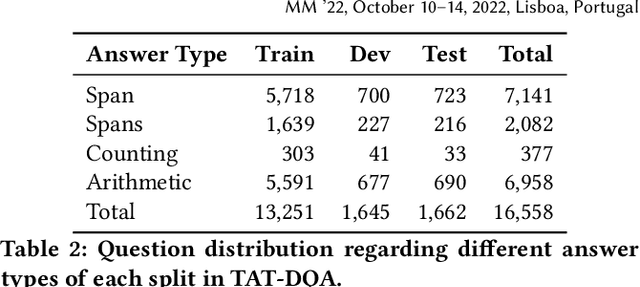
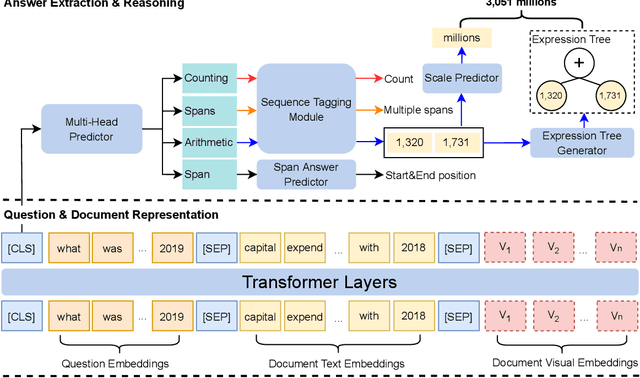
Document Visual Question Answering (VQA) aims to understand visually-rich documents to answer questions in natural language, which is an emerging research topic for both Natural Language Processing and Computer Vision. In this work, we introduce a new Document VQA dataset, named TAT-DQA, which consists of 3,067 document pages comprising semi-structured table(s) and unstructured text as well as 16,558 question-answer pairs by extending the TAT-QA dataset. These documents are sampled from real-world financial reports and contain lots of numbers, which means discrete reasoning capability is demanded to answer questions on this dataset. Based on TAT-DQA, we further develop a novel model named MHST that takes into account the information in multi-modalities, including text, layout and visual image, to intelligently address different types of questions with corresponding strategies, i.e., extraction or reasoning. Extensive experiments show that the MHST model significantly outperforms the baseline methods, demonstrating its effectiveness. However, the performance still lags far behind that of expert humans. We expect that our new TAT-DQA dataset would facilitate the research on deep understanding of visually-rich documents combining vision and language, especially for scenarios that require discrete reasoning. Also, we hope the proposed model would inspire researchers to design more advanced Document VQA models in future.
ORFD: A Dataset and Benchmark for Off-Road Freespace Detection
Jun 20, 2022



Freespace detection is an essential component of autonomous driving technology and plays an important role in trajectory planning. In the last decade, deep learning-based free space detection methods have been proved feasible. However, these efforts were focused on urban road environments and few deep learning-based methods were specifically designed for off-road free space detection due to the lack of off-road benchmarks. In this paper, we present the ORFD dataset, which, to our knowledge, is the first off-road free space detection dataset. The dataset was collected in different scenes (woodland, farmland, grassland, and countryside), different weather conditions (sunny, rainy, foggy, and snowy), and different light conditions (bright light, daylight, twilight, darkness), which totally contains 12,198 LiDAR point cloud and RGB image pairs with the traversable area, non-traversable area and unreachable area annotated in detail. We propose a novel network named OFF-Net, which unifies Transformer architecture to aggregate local and global information, to meet the requirement of large receptive fields for free space detection tasks. We also propose the cross-attention to dynamically fuse LiDAR and RGB image information for accurate off-road free space detection. Dataset and code are publicly available athttps://github.com/chaytonmin/OFF-Net.
Depth-Adapted CNNs for RGB-D Semantic Segmentation
Jun 08, 2022
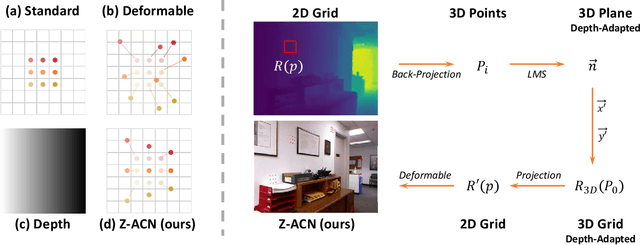
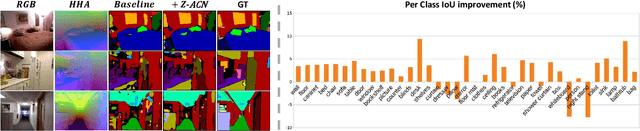
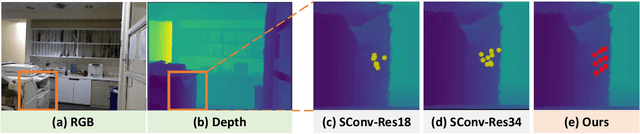
Recent RGB-D semantic segmentation has motivated research interest thanks to the accessibility of complementary modalities from the input side. Existing works often adopt a two-stream architecture that processes photometric and geometric information in parallel, with few methods explicitly leveraging the contribution of depth cues to adjust the sampling position on RGB images. In this paper, we propose a novel framework to incorporate the depth information in the RGB convolutional neural network (CNN), termed Z-ACN (Depth-Adapted CNN). Specifically, our Z-ACN generates a 2D depth-adapted offset which is fully constrained by low-level features to guide the feature extraction on RGB images. With the generated offset, we introduce two intuitive and effective operations to replace basic CNN operators: depth-adapted convolution and depth-adapted average pooling. Extensive experiments on both indoor and outdoor semantic segmentation tasks demonstrate the effectiveness of our approach.