 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Position Information in Transformers: An Overview
Feb 22, 2021
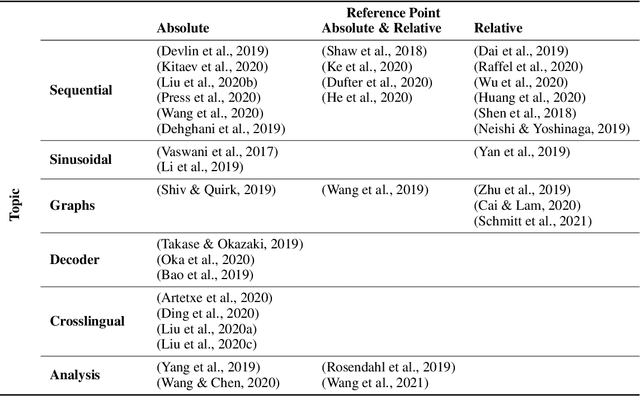

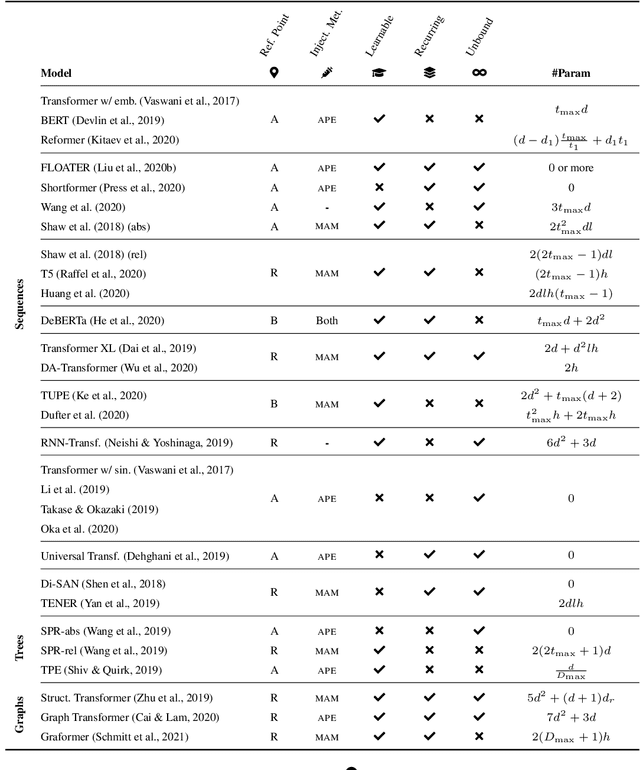
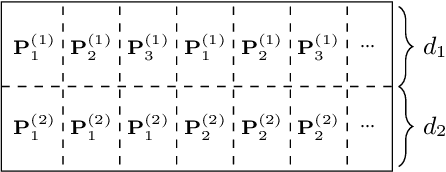
Transformers are arguably the main workhorse in recent Natural Language Processing research. By definition a Transformer is invariant with respect to reorderings of the input. However, language is inherently sequential and word order is essential to the semantics and syntax of an utterance. In this paper, we provide an overview of common methods to incorporate position information into Transformer models. The objectives of this survey are to i) showcase that position information in Transformer is a vibrant and extensive research area; ii) enable the reader to compare existing methods by providing a unified notation and meaningful clustering; iii) indicate what characteristics of an application should be taken into account when selecting a position encoding; iv) provide stimuli for future research.
Inter-model Interpretability: Self-supervised Models as a Case Study
Jul 31, 2022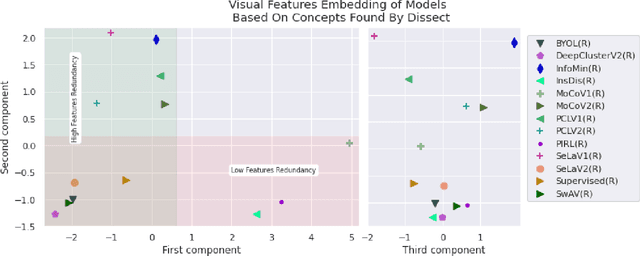
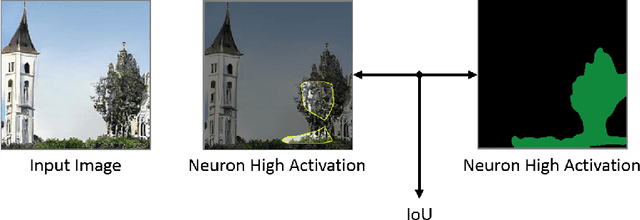

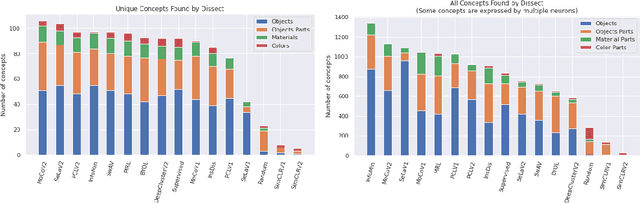
Since early machine learning models, metrics such as accuracy and precision have been the de facto way to evaluate and compare trained models. However, a single metric number doesn't fully capture the similarities and differences between models, especially in the computer vision domain. A model with high accuracy on a certain dataset might provide a lower accuracy on another dataset, without any further insights. To address this problem we build on a recent interpretability technique called Dissect to introduce \textit{inter-model interpretability}, which determines how models relate or complement each other based on the visual concepts they have learned (such as objects and materials). Towards this goal, we project 13 top-performing self-supervised models into a Learned Concepts Embedding (LCE) space that reveals proximities among models from the perspective of learned concepts. We further crossed this information with the performance of these models on four computer vision tasks and 15 datasets. The experiment allowed us to categorize the models into three categories and revealed for the first time the type of visual concepts different tasks requires. This is a step forward for designing cross-task learning algorithms.
Learning Semantics-Aware Locomotion Skills from Human Demonstration
Jun 27, 2022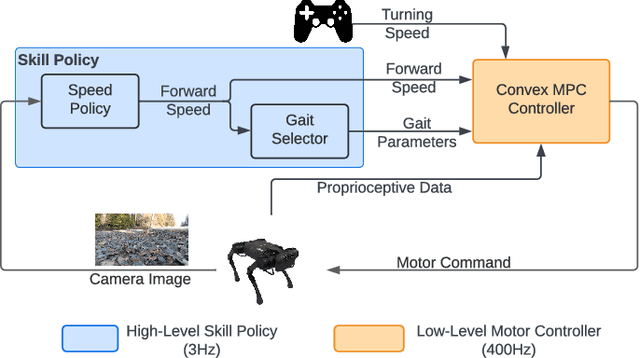
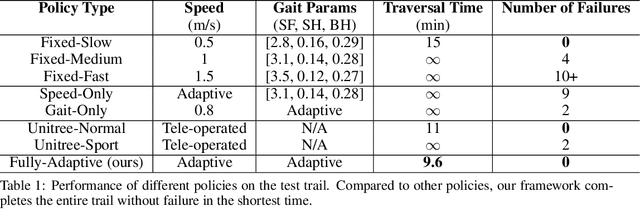
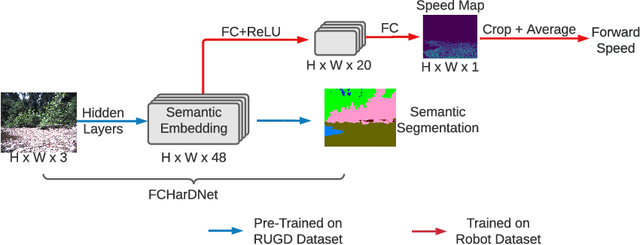
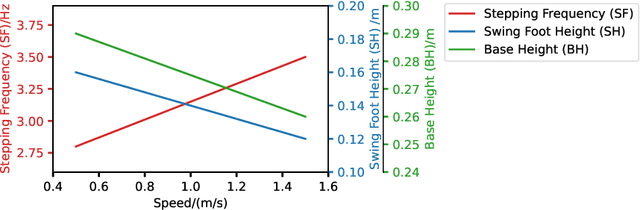
The semantics of the environment, such as the terrain type and property, reveals important information for legged robots to adjust their behaviors. In this work, we present a framework that learns semantics-aware locomotion skills from perception for quadrupedal robots, such that the robot can traverse through complex offroad terrains with appropriate speeds and gaits using perception information. Due to the lack of high-fidelity outdoor simulation, our framework needs to be trained directly in the real world, which brings unique challenges in data efficiency and safety. To ensure sample efficiency, we pre-train the perception model with an off-road driving dataset. To avoid the risks of real-world policy exploration, we leverage human demonstration to train a speed policy that selects a desired forward speed from camera image. For maximum traversability, we pair the speed policy with a gait selector, which selects a robust locomotion gait for each forward speed. Using only 40 minutes of human demonstration data, our framework learns to adjust the speed and gait of the robot based on perceived terrain semantics, and enables the robot to walk over 6km without failure at close-to-optimal speed.
DCAN: Diversified News Recommendation with Coverage-Attentive Networks
Jun 02, 2022
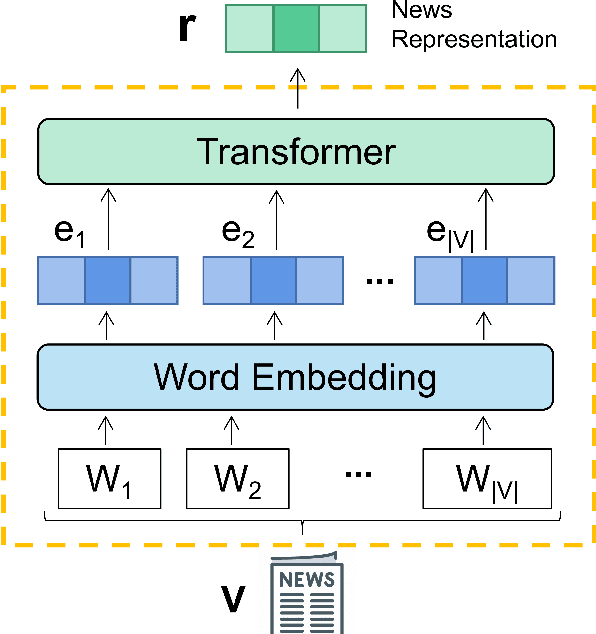
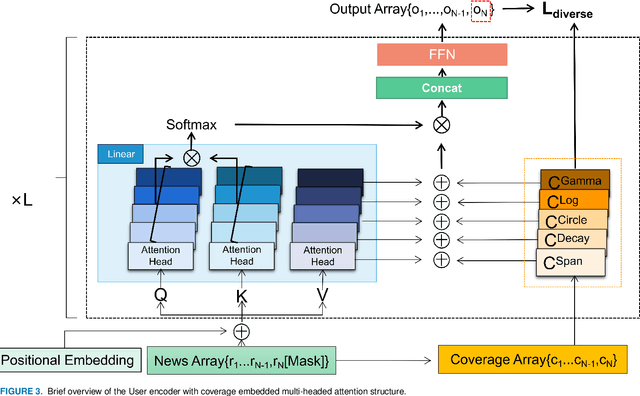
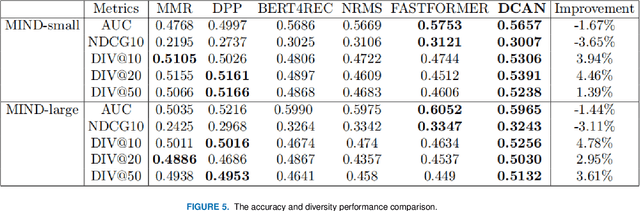
Self-attention based models are widely used in news recommendation tasks. However, previous Attention architecture does not constrain repeated information in the user's historical behavior, which limits the power of hidden representation and leads to some problems such as information redundancy and filter bubbles. To solve this problem, we propose a personalized news recommendation model called DCAN.It captures multi-grained user-news matching signals through news encoders and user encoders. We keep updating a coverage vector to track the history of news attention and augment the vector in 4 types of ways. Then we fed the augmented Coverage vector into the Multi-headed Self-attention model to help adjust the future attention and added the Coverage regulation to the loss function(CRL), which enabled the recommendation system to consider more about differentiated information. Extensive experiments on Microsoft News Recommendation Dataset (MIND) show that our model significantly improve the diversity of news recommendations with minimal sacrifice in accuracy.
Forming Trees with Treeformers
Jul 14, 2022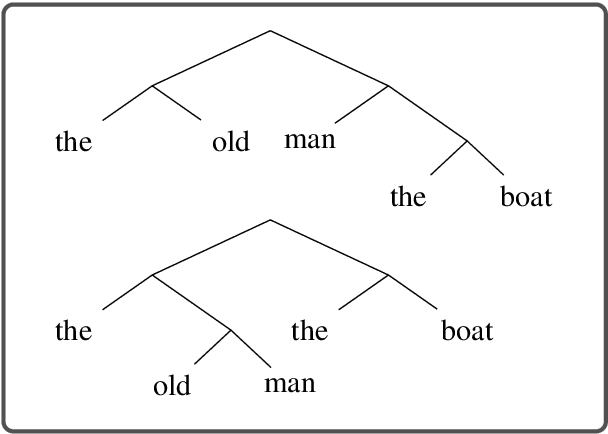
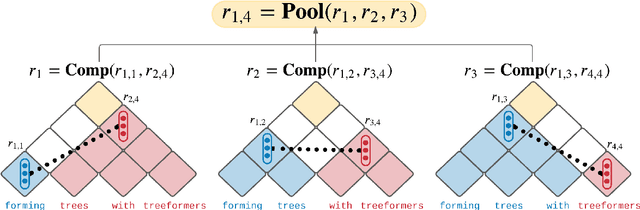
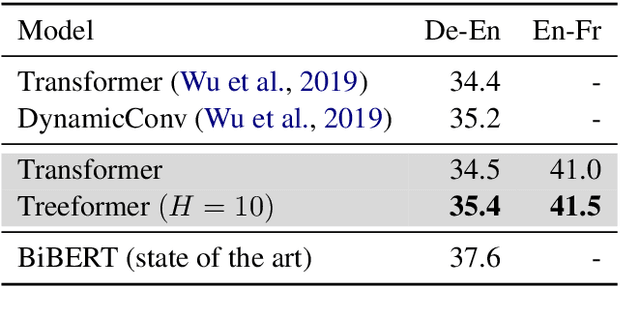
Popular models such as Transformers and LSTMs use tokens as its unit of information. That is, each token is encoded into a vector representation, and those vectors are used directly in a computation. However, humans frequently consider spans of tokens (i.e., phrases) instead of their constituent tokens. In this paper we introduce Treeformer, an architecture inspired by the CKY algorithm and Transformer which learns a composition operator and pooling function in order to construct hierarchical encodings for phrases and sentences. Our extensive experiments demonstrate the benefits of incorporating a hierarchical structure into the Transformer, and show significant improvements compared to a baseline Transformer in machine translation, abstractive summarization, and various natural language understanding tasks.
Learning Implicit Templates for Point-Based Clothed Human Modeling
Jul 14, 2022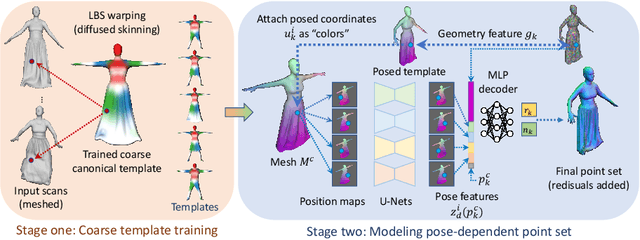
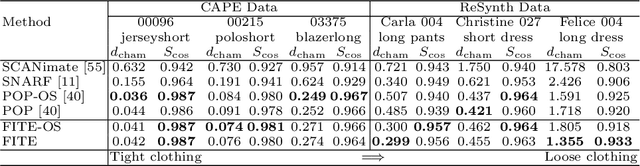
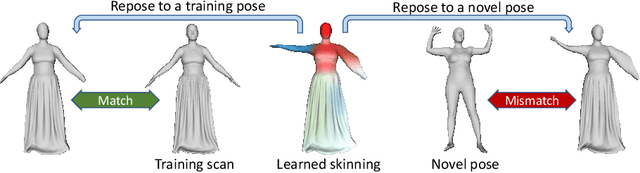
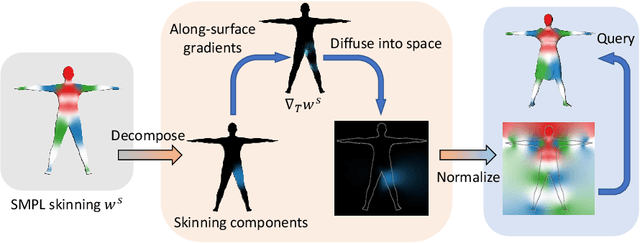
We present FITE, a First-Implicit-Then-Explicit framework for modeling human avatars in clothing. Our framework first learns implicit surface templates representing the coarse clothing topology, and then employs the templates to guide the generation of point sets which further capture pose-dependent clothing deformations such as wrinkles. Our pipeline incorporates the merits of both implicit and explicit representations, namely, the ability to handle varying topology and the ability to efficiently capture fine details. We also propose diffused skinning to facilitate template training especially for loose clothing, and projection-based pose-encoding to extract pose information from mesh templates without predefined UV map or connectivity. Our code is publicly available at https://github.com/jsnln/fite.
Image Reconstruction of Multi Branch Feature Multiplexing Fusion Network with Mixed Multi-layer Attention
May 27, 2022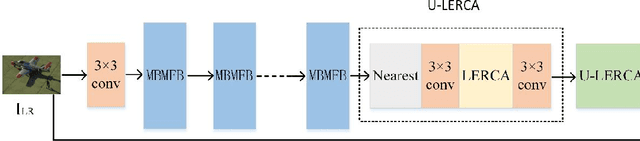
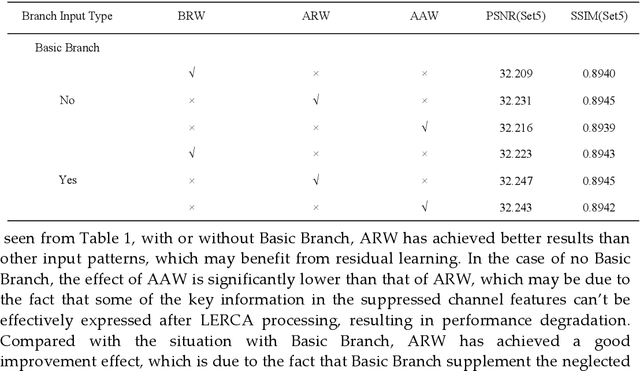
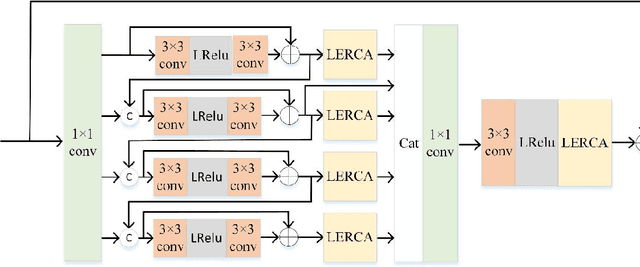

Image super-resolution reconstruction achieves better results than traditional methods with the help of the powerful nonlinear representation ability of convolution neural network. However, some existing algorithms also have some problems, such as insufficient utilization of phased features, ignoring the importance of early phased feature fusion to improve network performance, and the inability of the network to pay more attention to high-frequency information in the reconstruction process. To solve these problems, we propose a multi-branch feature multiplexing fusion network with mixed multi-layer attention (MBMFN), which realizes the multiple utilization of features and the multistage fusion of different levels of features. To further improve the networks performance, we propose a lightweight enhanced residual channel attention (LERCA), which can not only effectively avoid the loss of channel information but also make the network pay more attention to the key channel information and benefit from it. Finally, the attention mechanism is introduced into the reconstruction process to strengthen the restoration of edge texture and other details. A large number of experiments on several benchmark sets show that, compared with other advanced reconstruction algorithms, our algorithm produces highly competitive objective indicators and restores more image detail texture information.
Optimizing Video Prediction via Video Frame Interpolation
Jun 27, 2022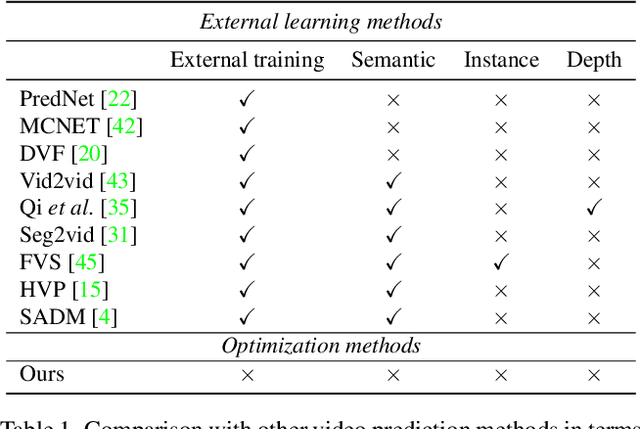
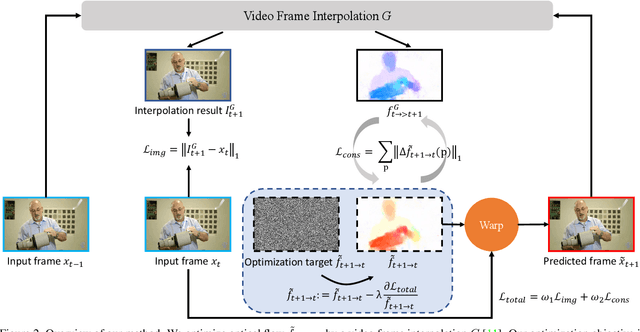
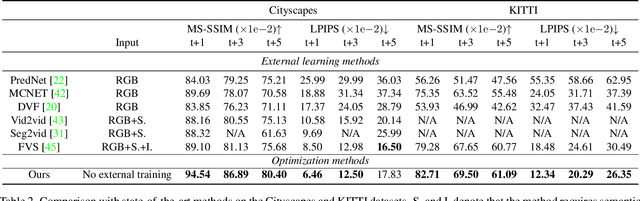

Video prediction is an extrapolation task that predicts future frames given past frames, and video frame interpolation is an interpolation task that estimates intermediate frames between two frames. We have witnessed the tremendous advancement of video frame interpolation, but the general video prediction in the wild is still an open question. Inspired by the photo-realistic results of video frame interpolation, we present a new optimization framework for video prediction via video frame interpolation, in which we solve an extrapolation problem based on an interpolation model. Our video prediction framework is based on optimization with a pretrained differentiable video frame interpolation module without the need for a training dataset, and thus there is no domain gap issue between training and test data. Also, our approach does not need any additional information such as semantic or instance maps, which makes our framework applicable to any video. Extensive experiments on the Cityscapes, KITTI, DAVIS, Middlebury, and Vimeo90K datasets show that our video prediction results are robust in general scenarios, and our approach outperforms other video prediction methods that require a large amount of training data or extra semantic information.
A Novel ECG Denoising Scheme Using the Ensemble Kalman Filter
Jul 24, 2022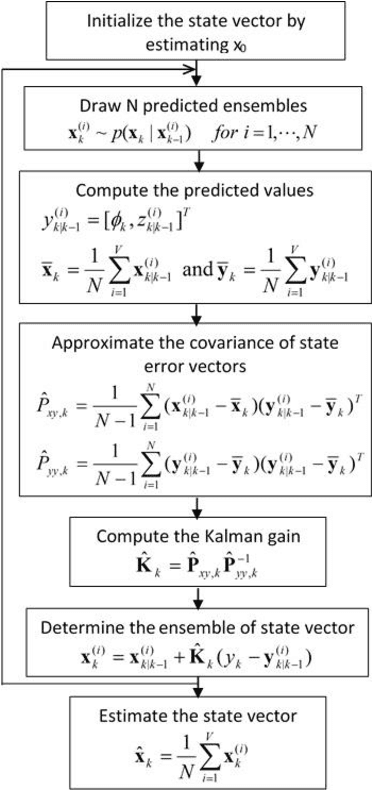
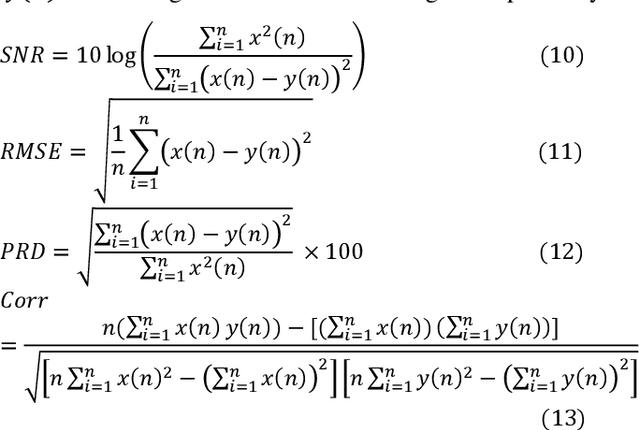
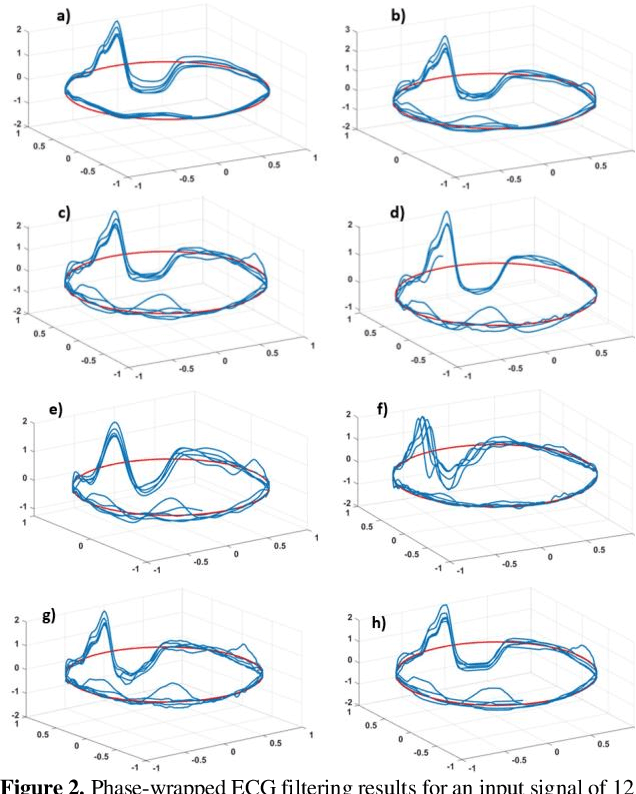
Monitoring of electrocardiogram (ECG) provides vital information as well as any cardiovascular anomalies. Recent advances in the technology of wearable electronics have enabled compact devices to acquire personal physiological signals in the home setting; however, signals are usually contaminated with high level noise. Thus, an efficient ECG filtering scheme is a dire need. In this paper, a novel method using Ensemble Kalman Filter (EnKF) is developed for denoising ECG signals. We also intensively explore various filtering algorithms, including Savitzky-Golay (SG) filter, Ensemble Empirical mode decomposition (EEMD), Normalized Least-Mean-Square (NLMS), Recursive least squares (RLS) filter, Total variation denoising (TVD), Wavelet and extended Kalman filter (EKF) for comparison. Data from the MIT-BIH Noise Stress Test database were used. The proposed methodology shows the average signal to noise ratio (SNR) of 10.96, the Percentage Root Difference of 150.45, and the correlation coefficient of 0.959 from the modified MIT-BIH database with added motion artifacts.
Verification system based on long-range iris and Graph Siamese Neural Networks
Jul 28, 2022
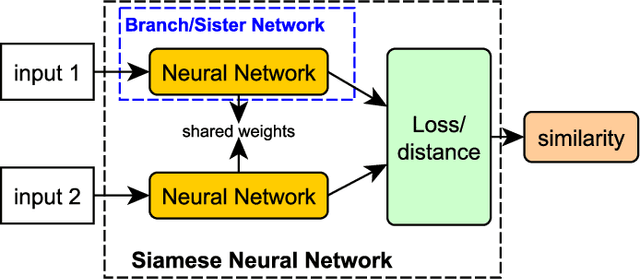

Biometric systems represent valid solutions in tasks like user authentication and verification, since they are able to analyze physical and behavioural features with high precision. However, especially when physical biometrics are used, as is the case of iris recognition, they require specific hardware such as retina scanners, sensors, or HD cameras to achieve relevant results. At the same time, they require the users to be very close to the camera to extract high-resolution information. For this reason, in this work, we propose a novel approach that uses long-range (LR) distance images for implementing an iris verification system. More specifically, we present a novel methodology for converting LR iris images into graphs and then use Graph Siamese Neural Networks (GSNN) to predict whether two graphs belong to the same person. In this study, we not only describe this methodology but also evaluate how the spectral components of these images can be used for improving the graph extraction and the final classification task. Results demonstrate the suitability of this approach, encouraging the community to explore graph application in biometric systems.